 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
InpaintNeRF360: Text-Guided 3D Inpainting on Unbounded Neural Radiance Fields
May 24, 2023

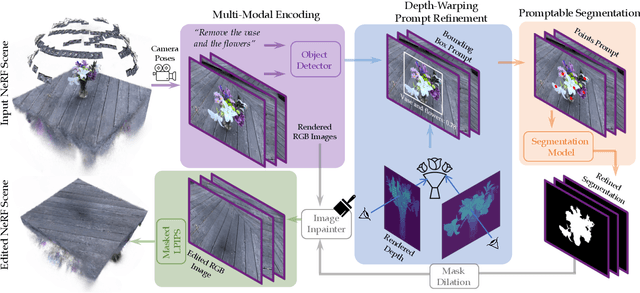
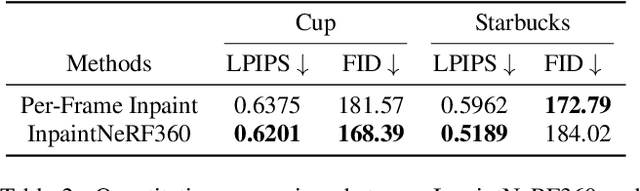

Neural Radiance Fields (NeRF) can generate highly realistic novel views. However, editing 3D scenes represented by NeRF across 360-degree views, particularly removing objects while preserving geometric and photometric consistency, remains a challenging problem due to NeRF's implicit scene representation. In this paper, we propose InpaintNeRF360, a unified framework that utilizes natural language instructions as guidance for inpainting NeRF-based 3D scenes.Our approach employs a promptable segmentation model by generating multi-modal prompts from the encoded text for multiview segmentation. We apply depth-space warping to enforce viewing consistency in the segmentations, and further refine the inpainted NeRF model using perceptual priors to ensure visual plausibility. InpaintNeRF360 is capable of simultaneously removing multiple objects or modifying object appearance based on text instructions while synthesizing 3D viewing-consistent and photo-realistic inpainting. Through extensive experiments on both unbounded and frontal-facing scenes trained through NeRF, we demonstrate the effectiveness of our approach and showcase its potential to enhance the editability of implicit radiance fields.
Adding 3D Geometry Control to Diffusion Models
Jun 13, 2023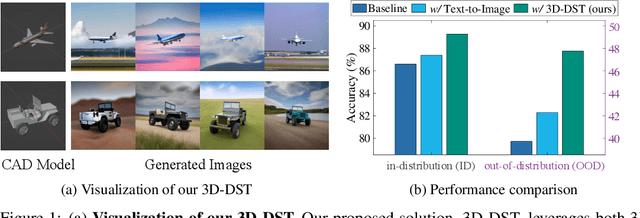
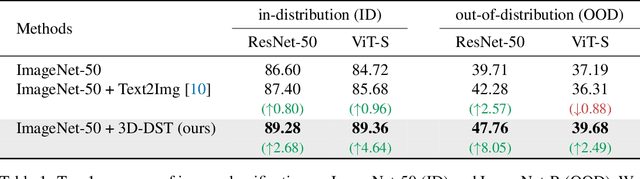
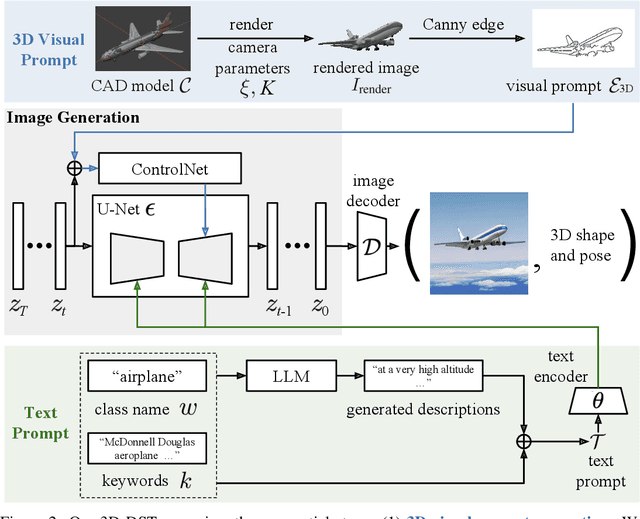
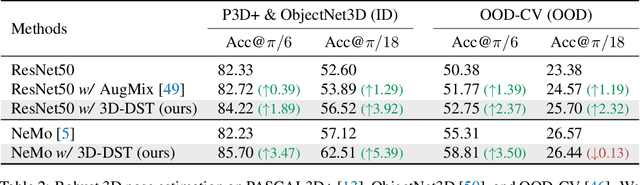
Diffusion models have emerged as a powerful method of generative modeling across a range of fields, capable of producing stunning photo-realistic images from natural language descriptions. However, these models lack explicit control over the 3D structure of the objects in the generated images. In this paper, we propose a novel method that incorporates 3D geometry control into diffusion models, making them generate even more realistic and diverse images. To achieve this, our method exploits ControlNet, which extends diffusion models by using visual prompts in addition to text prompts. We generate images of 3D objects taken from a 3D shape repository (e.g., ShapeNet and Objaverse), render them from a variety of poses and viewing directions, compute the edge maps of the rendered images, and use these edge maps as visual prompts to generate realistic images. With explicit 3D geometry control, we can easily change the 3D structures of the objects in the generated images and obtain ground-truth 3D annotations automatically. This allows us to use the generated images to improve a lot of vision tasks, e.g., classification and 3D pose estimation, in both in-distribution (ID) and out-of-distribution (OOD) settings. We demonstrate the effectiveness of our method through extensive experiments on ImageNet-50, ImageNet-R, PASCAL3D+, ObjectNet3D, and OOD-CV datasets. The results show that our method significantly outperforms existing methods across multiple benchmarks (e.g., 4.6 percentage points on ImageNet-50 using ViT and 3.5 percentage points on PASCAL3D+ and ObjectNet3D using NeMo).
Understanding Aesthetics with Language: A Photo Critique Dataset for Aesthetic Assessment
Jun 17, 2022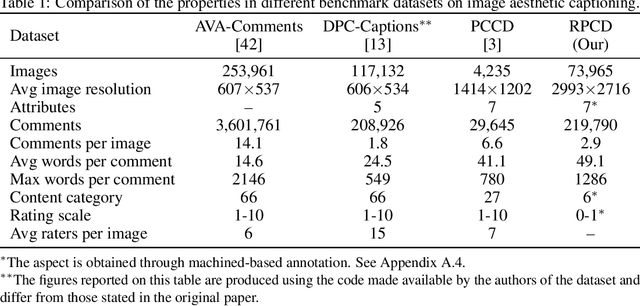

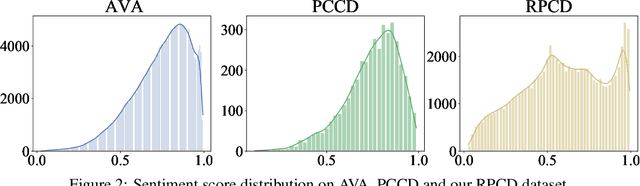
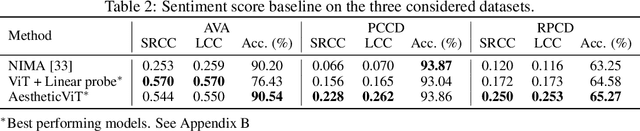
Computational inference of aesthetics is an ill-defined task due to its subjective nature. Many datasets have been proposed to tackle the problem by providing pairs of images and aesthetic scores based on human ratings. However, humans are better at expressing their opinion, taste, and emotions by means of language rather than summarizing them in a single number. In fact, photo critiques provide much richer information as they reveal how and why users rate the aesthetics of visual stimuli. In this regard, we propose the Reddit Photo Critique Dataset (RPCD), which contains tuples of image and photo critiques. RPCD consists of 74K images and 220K comments and is collected from a Reddit community used by hobbyists and professional photographers to improve their photography skills by leveraging constructive community feedback. The proposed dataset differs from previous aesthetics datasets mainly in three aspects, namely (i) the large scale of the dataset and the extension of the comments criticizing different aspects of the image, (ii) it contains mostly UltraHD images, and (iii) it can easily be extended to new data as it is collected through an automatic pipeline. To the best of our knowledge, in this work, we propose the first attempt to estimate the aesthetic quality of visual stimuli from the critiques. To this end, we exploit the polarity of the sentiment of criticism as an indicator of aesthetic judgment. We demonstrate how sentiment polarity correlates positively with the aesthetic judgment available for two aesthetic assessment benchmarks. Finally, we experiment with several models by using the sentiment scores as a target for ranking images. Dataset and baselines are available (https://github.com/mediatechnologycenter/aestheval).
Federated Few-shot Learning
Jun 17, 2023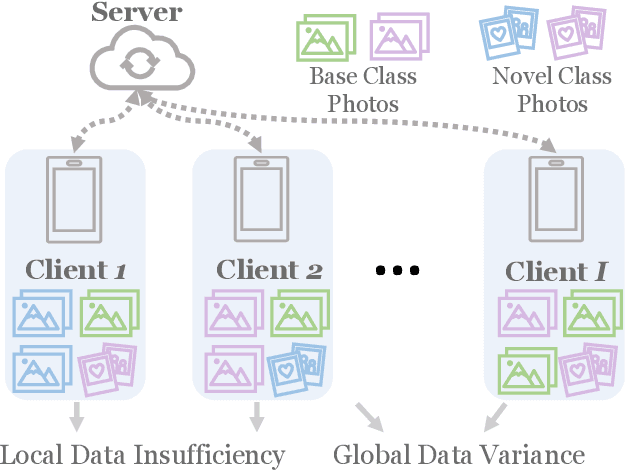
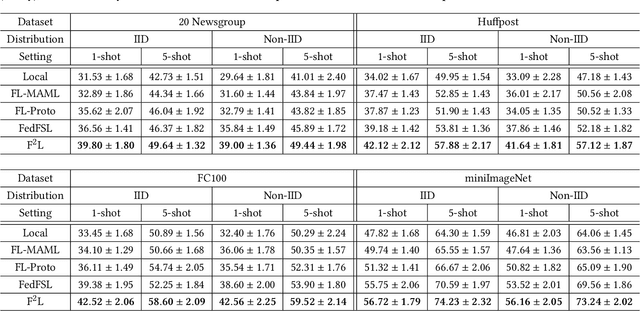
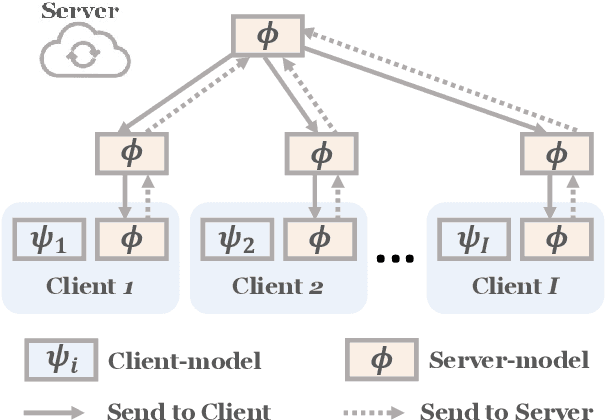

Federated Learning (FL) enables multiple clients to collaboratively learn a machine learning model without exchanging their own local data. In this way, the server can exploit the computational power of all clients and train the model on a larger set of data samples among all clients. Although such a mechanism is proven to be effective in various fields, existing works generally assume that each client preserves sufficient data for training. In practice, however, certain clients may only contain a limited number of samples (i.e., few-shot samples). For example, the available photo data taken by a specific user with a new mobile device is relatively rare. In this scenario, existing FL efforts typically encounter a significant performance drop on these clients. Therefore, it is urgent to develop a few-shot model that can generalize to clients with limited data under the FL scenario. In this paper, we refer to this novel problem as \emph{federated few-shot learning}. Nevertheless, the problem remains challenging due to two major reasons: the global data variance among clients (i.e., the difference in data distributions among clients) and the local data insufficiency in each client (i.e., the lack of adequate local data for training). To overcome these two challenges, we propose a novel federated few-shot learning framework with two separately updated models and dedicated training strategies to reduce the adverse impact of global data variance and local data insufficiency. Extensive experiments on four prevalent datasets that cover news articles and images validate the effectiveness of our framework compared with the state-of-the-art baselines. Our code is provided\footnote{\href{https://github.com/SongW-SW/F2L}{https://github.com/SongW-SW/F2L}}.
Sketch2Saliency: Learning to Detect Salient Objects from Human Drawings
Mar 30, 2023
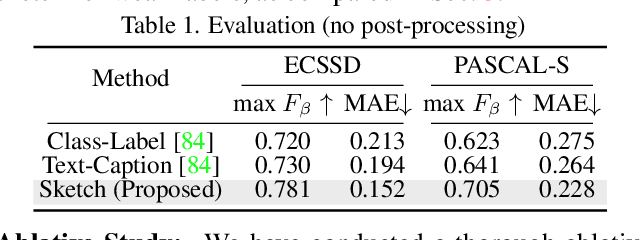

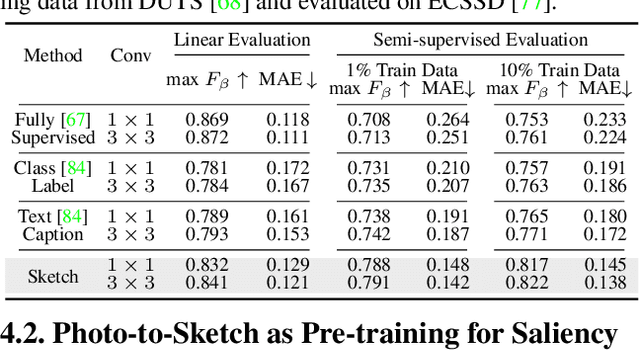
Human sketch has already proved its worth in various visual understanding tasks (e.g., retrieval, segmentation, image-captioning, etc). In this paper, we reveal a new trait of sketches - that they are also salient. This is intuitive as sketching is a natural attentive process at its core. More specifically, we aim to study how sketches can be used as a weak label to detect salient objects present in an image. To this end, we propose a novel method that emphasises on how "salient object" could be explained by hand-drawn sketches. To accomplish this, we introduce a photo-to-sketch generation model that aims to generate sequential sketch coordinates corresponding to a given visual photo through a 2D attention mechanism. Attention maps accumulated across the time steps give rise to salient regions in the process. Extensive quantitative and qualitative experiments prove our hypothesis and delineate how our sketch-based saliency detection model gives a competitive performance compared to the state-of-the-art.
Inserting Anybody in Diffusion Models via Celeb Basis
Jun 01, 2023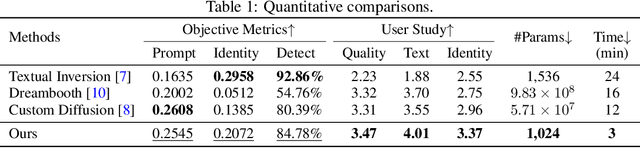
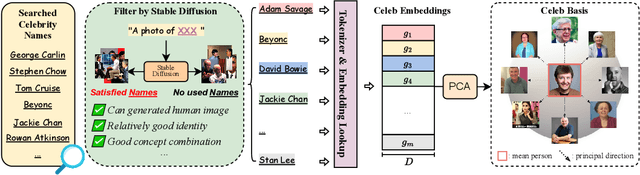
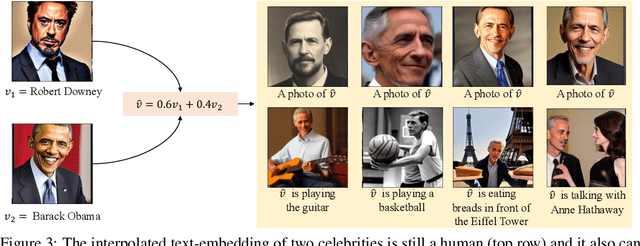
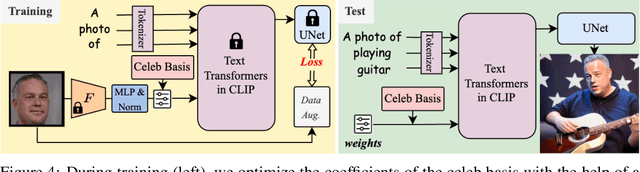
Exquisite demand exists for customizing the pretrained large text-to-image model, $\textit{e.g.}$, Stable Diffusion, to generate innovative concepts, such as the users themselves. However, the newly-added concept from previous customization methods often shows weaker combination abilities than the original ones even given several images during training. We thus propose a new personalization method that allows for the seamless integration of a unique individual into the pre-trained diffusion model using just $\textbf{one facial photograph}$ and only $\textbf{1024 learnable parameters}$ under $\textbf{3 minutes}$. So as we can effortlessly generate stunning images of this person in any pose or position, interacting with anyone and doing anything imaginable from text prompts. To achieve this, we first analyze and build a well-defined celeb basis from the embedding space of the pre-trained large text encoder. Then, given one facial photo as the target identity, we generate its own embedding by optimizing the weight of this basis and locking all other parameters. Empowered by the proposed celeb basis, the new identity in our customized model showcases a better concept combination ability than previous personalization methods. Besides, our model can also learn several new identities at once and interact with each other where the previous customization model fails to. The code will be released.
Inferring and Leveraging Parts from Object Shape for Improving Semantic Image Synthesis
May 31, 2023
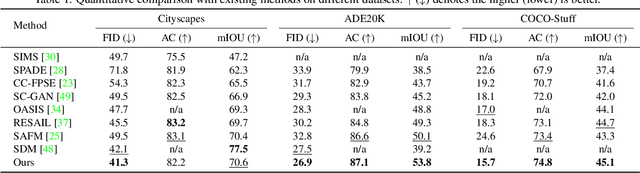
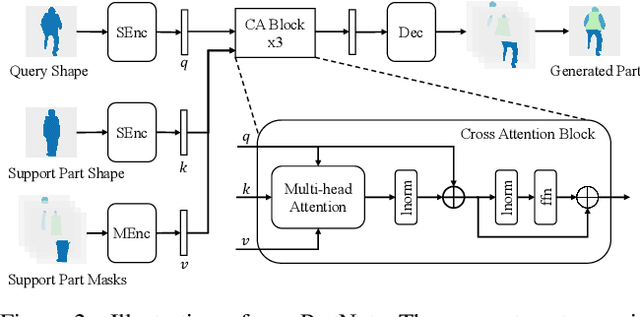
Despite the progress in semantic image synthesis, it remains a challenging problem to generate photo-realistic parts from input semantic map. Integrating part segmentation map can undoubtedly benefit image synthesis, but is bothersome and inconvenient to be provided by users. To improve part synthesis, this paper presents to infer Parts from Object ShapE (iPOSE) and leverage it for improving semantic image synthesis. However, albeit several part segmentation datasets are available, part annotations are still not provided for many object categories in semantic image synthesis. To circumvent it, we resort to few-shot regime to learn a PartNet for predicting the object part map with the guidance of pre-defined support part maps. PartNet can be readily generalized to handle a new object category when a small number (e.g., 3) of support part maps for this category are provided. Furthermore, part semantic modulation is presented to incorporate both inferred part map and semantic map for image synthesis. Experiments show that our iPOSE not only generates objects with rich part details, but also enables to control the image synthesis flexibly. And our iPOSE performs favorably against the state-of-the-art methods in terms of quantitative and qualitative evaluation. Our code will be publicly available at https://github.com/csyxwei/iPOSE.
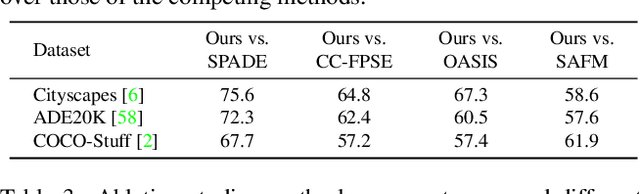
Interactive Data Synthesis for Systematic Vision Adaptation via LLMs-AIGCs Collaboration
May 22, 2023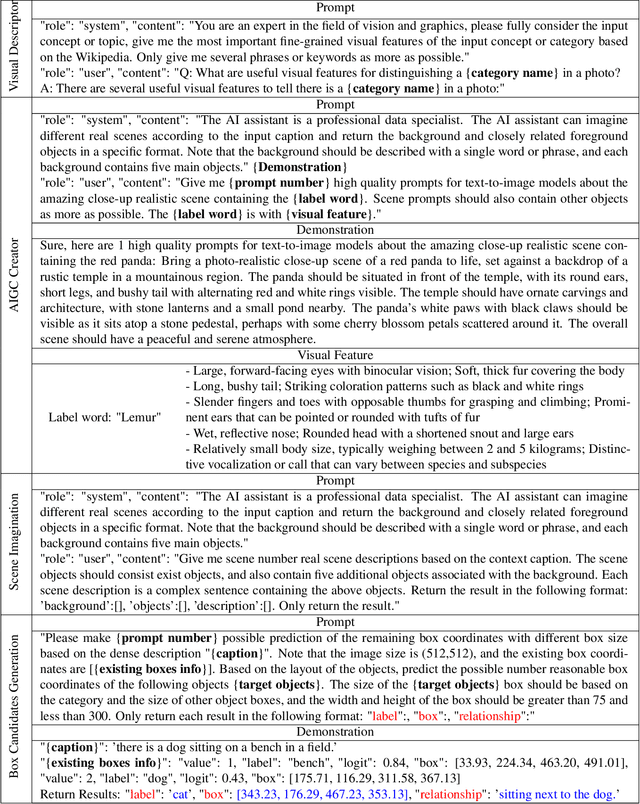
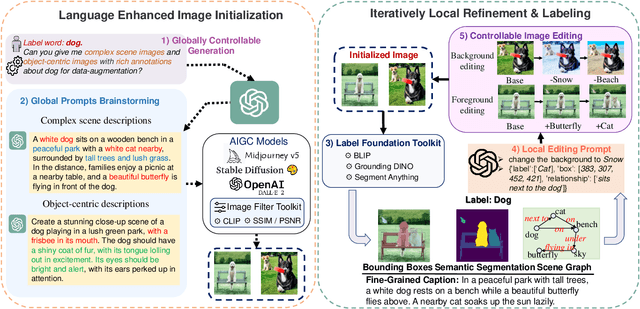
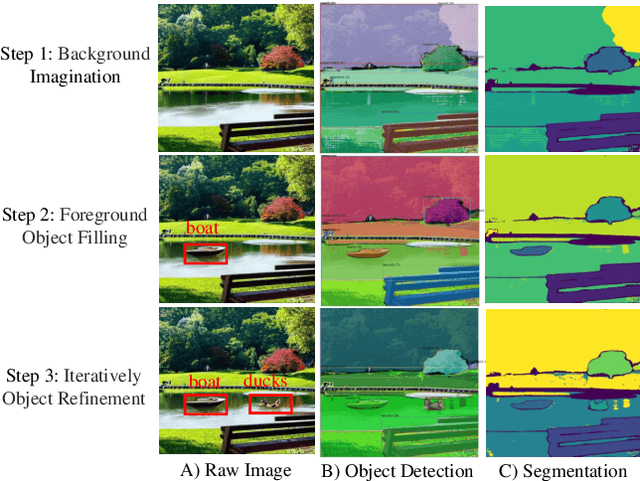

Recent text-to-image generation models have shown promising results in generating high-fidelity photo-realistic images. In parallel, the problem of data scarcity has brought a growing interest in employing AIGC technology for high-quality data expansion. However, this paradigm requires well-designed prompt engineering that cost-less data expansion and labeling remain under-explored. Inspired by LLM's powerful capability in task guidance, we propose a new paradigm of annotated data expansion named as ChatGenImage. The core idea behind it is to leverage the complementary strengths of diverse models to establish a highly effective and user-friendly pipeline for interactive data augmentation. In this work, we extensively study how LLMs communicate with AIGC model to achieve more controllable image generation and make the first attempt to collaborate them for automatic data augmentation for a variety of downstream tasks. Finally, we present fascinating results obtained from our ChatGenImage framework and demonstrate the powerful potential of our synthetic data for systematic vision adaptation. Our codes are available at https://github.com/Yuqifan1117/Labal-Anything-Pipeline.
Cross-domain Collaborative Learning for Recognizing Multiple Retinal Diseases from Wide-Field Fundus Images
May 14, 2023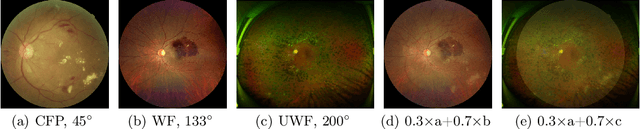
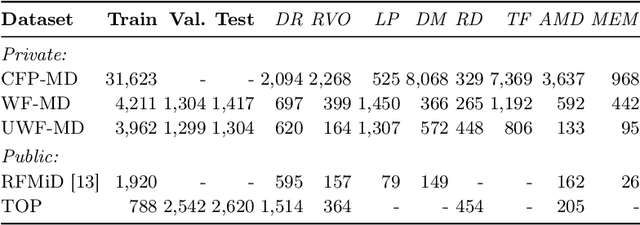
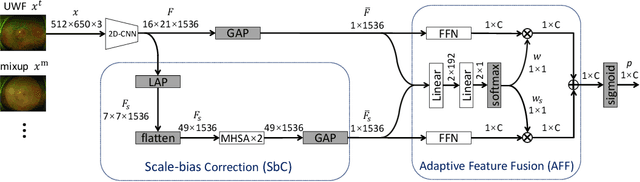
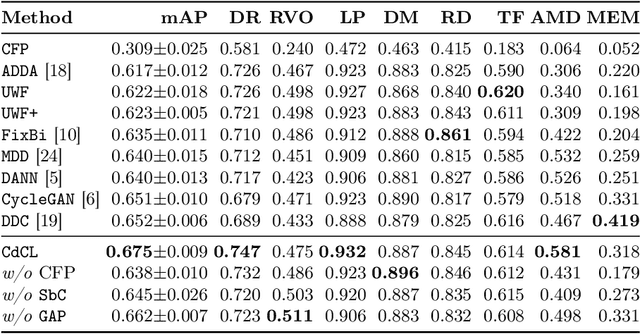
This paper addresses the emerging task of recognizing multiple retinal diseases from wide-field (WF) and ultra-wide-field (UWF) fundus images. For an effective reuse of existing labeled color fundus photo (CFP) data, we propose Cross-domain Collaborative Learning (CdCL). Inspired by the success of fixed-ratio based mixup in unsupervised domain adaptation, we re-purpose this strategy for the current task. Due to the intrinsic disparity between the field-of-view of CFP and WF/UWF images, a scale bias naturally exists in a mixup sample that the anatomic structure from a CFP image will be considerably larger than its WF/UWF counterpart. The CdCL method resolves the issue by Scale-bias Correction, which employs Transformers for producing scale-invariant features. As demonstrated by extensive experiments on multiple datasets covering both WF and UWF images, the proposed method compares favorably against a number of competitive baselines.
PanoContext-Former: Panoramic Total Scene Understanding with a Transformer
May 21, 2023
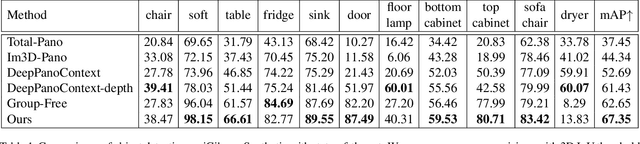
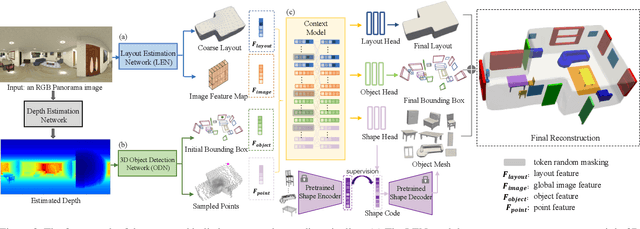

Panoramic image enables deeper understanding and more holistic perception of $360^\circ$ surrounding environment, which can naturally encode enriched scene context information compared to standard perspective image. Previous work has made lots of effort to solve the scene understanding task in a bottom-up form, thus each sub-task is processed separately and few correlations are explored in this procedure. In this paper, we propose a novel method using depth prior for holistic indoor scene understanding which recovers the objects' shapes, oriented bounding boxes and the 3D room layout simultaneously from a single panorama. In order to fully utilize the rich context information, we design a transformer-based context module to predict the representation and relationship among each component of the scene. In addition, we introduce a real-world dataset for scene understanding, including photo-realistic panoramas, high-fidelity depth images, accurately annotated room layouts, and oriented object bounding boxes and shapes. Experiments on the synthetic and real-world datasets demonstrate that our method outperforms previous panoramic scene understanding methods in terms of both layout estimation and 3D object detection.