 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Photoemission Orbital Tomography Using Robust Sparse PhaseLift
Jul 24, 2023

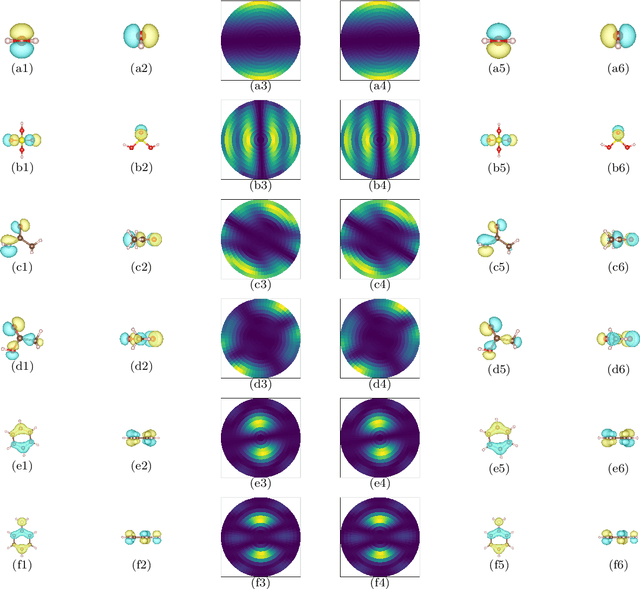

Photoemission orbital tomography (POT) from photoelectron momentum maps (PMMs) has enabled detailed analysis of the shape and energy of molecular orbitals in the adsorbed state. This study proposes a new POT method based on the PhaseLift. Molecular orbitals, including three-dimensional phases, can be identified from a single PMM by actively providing atomic positions and basis. Moreover, our method is robust to noise and can perfectly discriminate adsorption-induced molecular deformations with an accuracy of 0.05 [angstrom]. Our new method enables simultaneous analysis of the three-dimensional shapes of molecules and molecular orbitals and thus paves the way for advanced quantum-mechanical interpretation of adsorption-induced electronic state changes and photo-excited inter-molecular interactions.
Scaling Data Generation in Vision-and-Language Navigation
Aug 09, 2023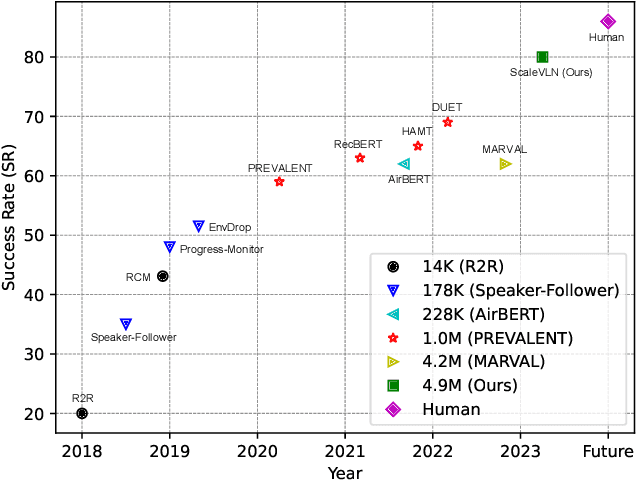
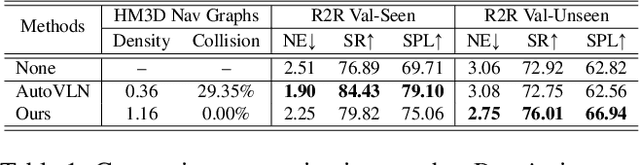
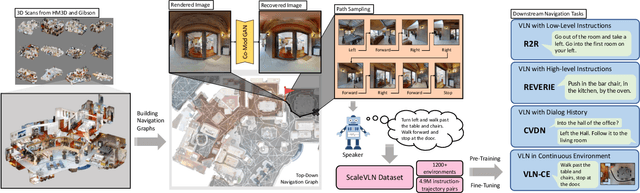
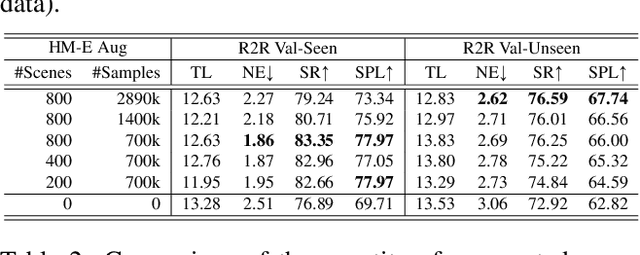
Recent research in language-guided visual navigation has demonstrated a significant demand for the diversity of traversable environments and the quantity of supervision for training generalizable agents. To tackle the common data scarcity issue in existing vision-and-language navigation datasets, we propose an effective paradigm for generating large-scale data for learning, which applies 1200+ photo-realistic environments from HM3D and Gibson datasets and synthesizes 4.9 million instruction trajectory pairs using fully-accessible resources on the web. Importantly, we investigate the influence of each component in this paradigm on the agent's performance and study how to adequately apply the augmented data to pre-train and fine-tune an agent. Thanks to our large-scale dataset, the performance of an existing agent can be pushed up (+11% absolute with regard to previous SoTA) to a significantly new best of 80% single-run success rate on the R2R test split by simple imitation learning. The long-lasting generalization gap between navigating in seen and unseen environments is also reduced to less than 1% (versus 8% in the previous best method). Moreover, our paradigm also facilitates different models to achieve new state-of-the-art navigation results on CVDN, REVERIE, and R2R in continuous environments.
Instruct-Video2Avatar: Video-to-Avatar Generation with Instructions
Jun 05, 2023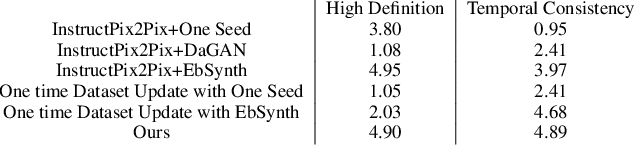
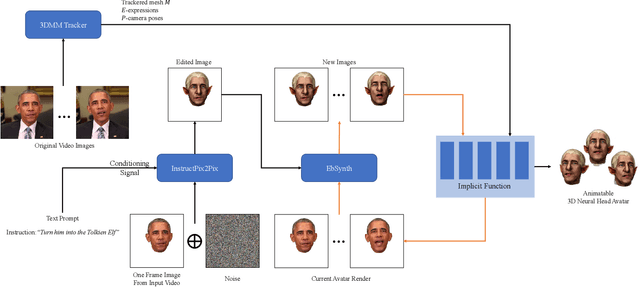


We propose a method for synthesizing edited photo-realistic digital avatars with text instructions. Given a short monocular RGB video and text instructions, our method uses an image-conditioned diffusion model to edit one head image and uses the video stylization method to accomplish the editing of other head images. Through iterative training and update (three times or more), our method synthesizes edited photo-realistic animatable 3D neural head avatars with a deformable neural radiance field head synthesis method. In quantitative and qualitative studies on various subjects, our method outperforms state-of-the-art methods.
BEVControl: Accurately Controlling Street-view Elements with Multi-perspective Consistency via BEV Sketch Layout
Aug 07, 2023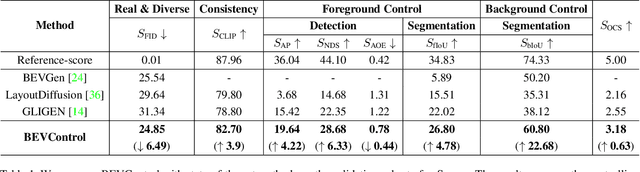
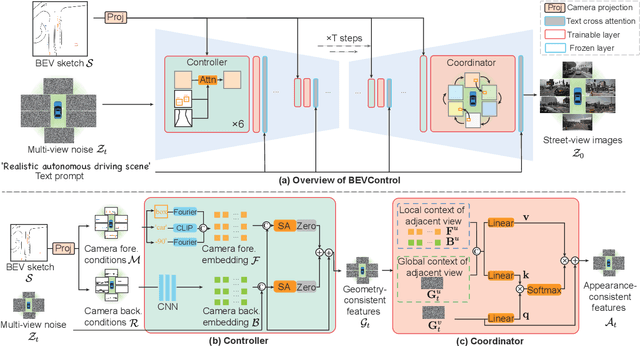
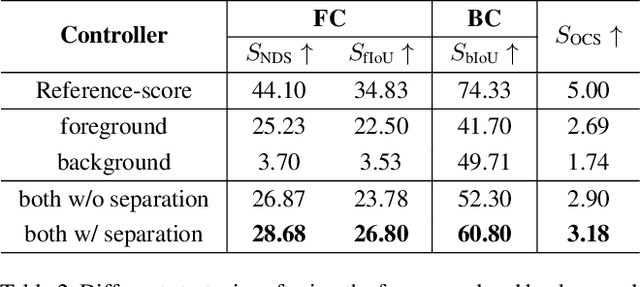
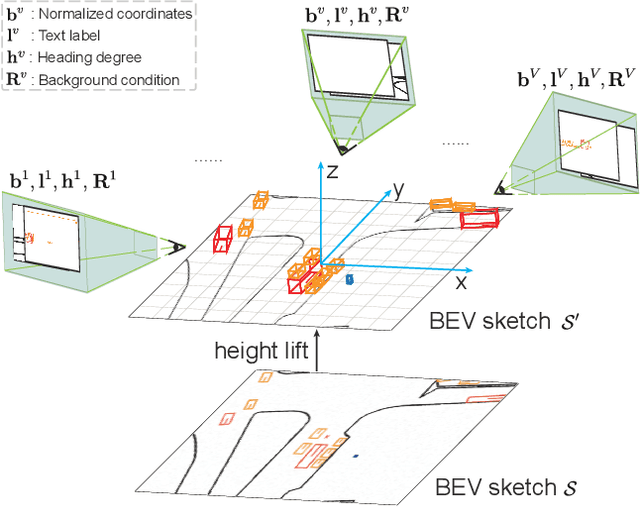
Using synthesized images to boost the performance of perception models is a long-standing research challenge in computer vision. It becomes more eminent in visual-centric autonomous driving systems with multi-view cameras as some long-tail scenarios can never be collected. Guided by the BEV segmentation layouts, the existing generative networks seem to synthesize photo-realistic street-view images when evaluated solely on scene-level metrics. However, once zoom-in, they usually fail to produce accurate foreground and background details such as heading. To this end, we propose a two-stage generative method, dubbed BEVControl, that can generate accurate foreground and background contents. In contrast to segmentation-like input, it also supports sketch style input, which is more flexible for humans to edit. In addition, we propose a comprehensive multi-level evaluation protocol to fairly compare the quality of the generated scene, foreground object, and background geometry. Our extensive experiments show that our BEVControl surpasses the state-of-the-art method, BEVGen, by a significant margin, from 5.89 to 26.80 on foreground segmentation mIoU. In addition, we show that using images generated by BEVControl to train the downstream perception model, it achieves on average 1.29 improvement in NDS score.
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving
Jul 27, 2023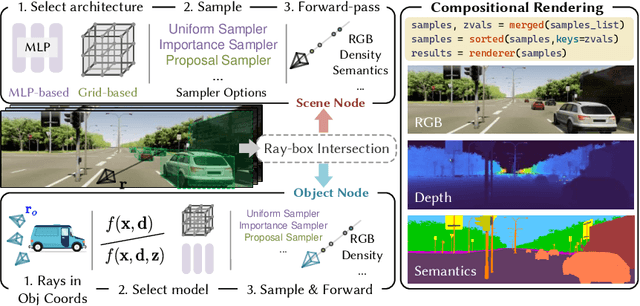

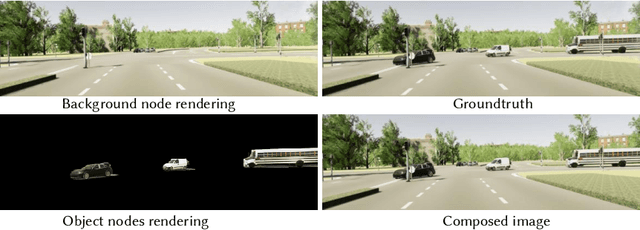
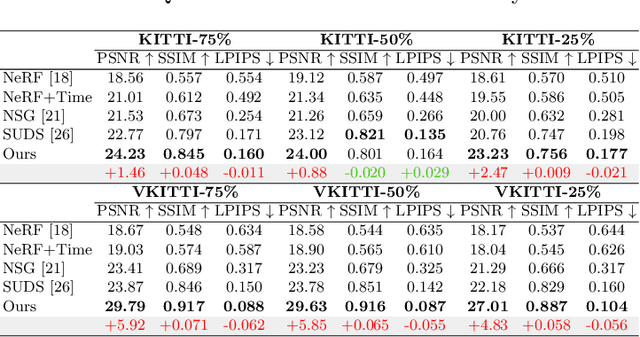
Nowadays, autonomous cars can drive smoothly in ordinary cases, and it is widely recognized that realistic sensor simulation will play a critical role in solving remaining corner cases by simulating them. To this end, we propose an autonomous driving simulator based upon neural radiance fields (NeRFs). Compared with existing works, ours has three notable features: (1) Instance-aware. Our simulator models the foreground instances and background environments separately with independent networks so that the static (e.g., size and appearance) and dynamic (e.g., trajectory) properties of instances can be controlled separately. (2) Modular. Our simulator allows flexible switching between different modern NeRF-related backbones, sampling strategies, input modalities, etc. We expect this modular design to boost academic progress and industrial deployment of NeRF-based autonomous driving simulation. (3) Realistic. Our simulator set new state-of-the-art photo-realism results given the best module selection. Our simulator will be open-sourced while most of our counterparts are not. Project page: https://open-air-sun.github.io/mars/.
Soft-IntroVAE for Continuous Latent space Image Super-Resolution
Jul 18, 2023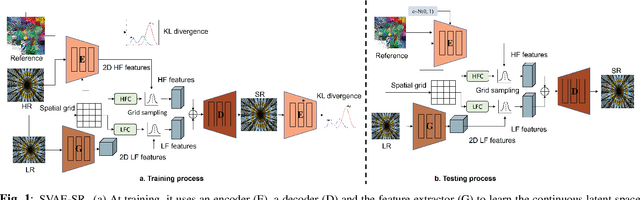
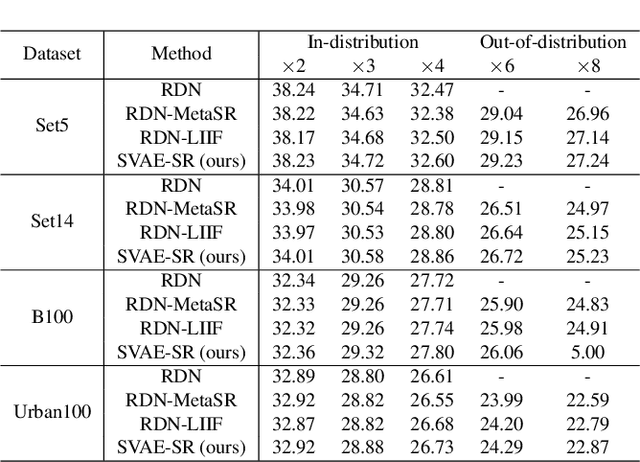
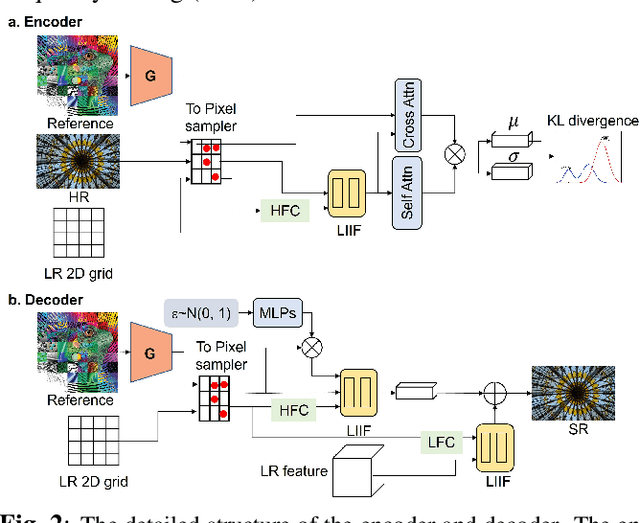
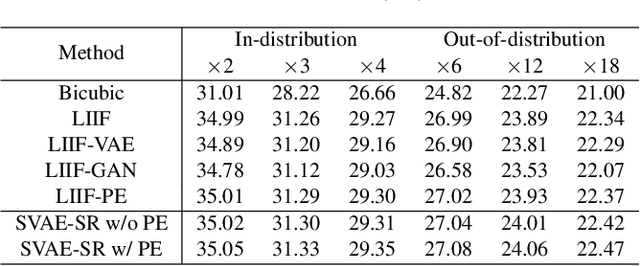
Continuous image super-resolution (SR) recently receives a lot of attention from researchers, for its practical and flexible image scaling for various displays. Local implicit image representation is one of the methods that can map the coordinates and 2D features for latent space interpolation. Inspired by Variational AutoEncoder, we propose a Soft-introVAE for continuous latent space image super-resolution (SVAE-SR). A novel latent space adversarial training is achieved for photo-realistic image restoration. To further improve the quality, a positional encoding scheme is used to extend the original pixel coordinates by aggregating frequency information over the pixel areas. We show the effectiveness of the proposed SVAE-SR through quantitative and qualitative comparisons, and further, illustrate its generalization in denoising and real-image super-resolution.
* 5 pages, 4 figures
ChildGAN: Large Scale Synthetic Child Facial Data Using Domain Adaptation in StyleGAN
Jul 25, 2023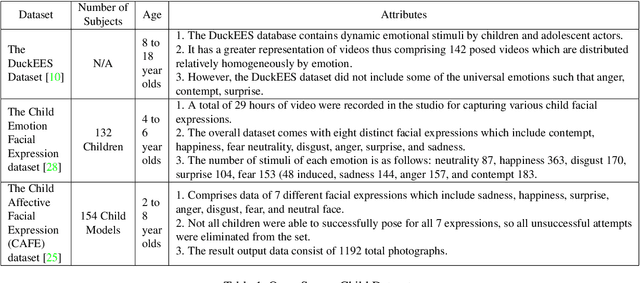
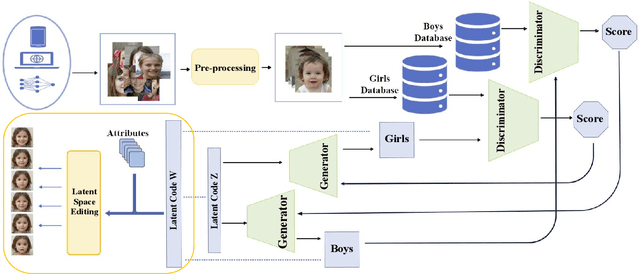
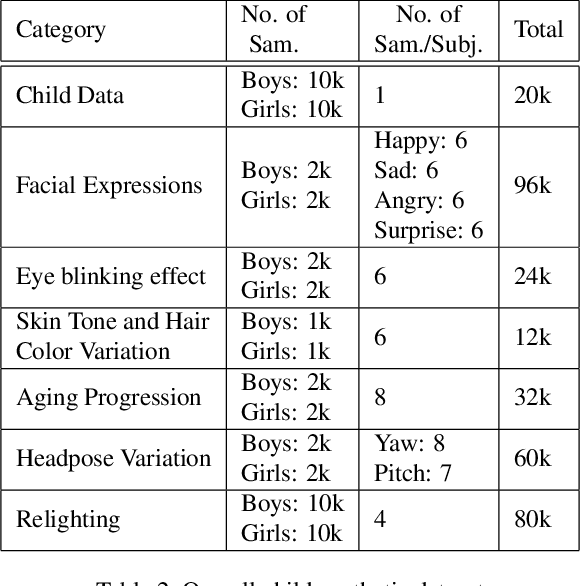

In this research work, we proposed a novel ChildGAN, a pair of GAN networks for generating synthetic boys and girls facial data derived from StyleGAN2. ChildGAN is built by performing smooth domain transfer using transfer learning. It provides photo-realistic, high-quality data samples. A large-scale dataset is rendered with a variety of smart facial transformations: facial expressions, age progression, eye blink effects, head pose, skin and hair color variations, and variable lighting conditions. The dataset comprises more than 300k distinct data samples. Further, the uniqueness and characteristics of the rendered facial features are validated by running different computer vision application tests which include CNN-based child gender classifier, face localization and facial landmarks detection test, identity similarity evaluation using ArcFace, and lastly running eye detection and eye aspect ratio tests. The results demonstrate that synthetic child facial data of high quality offers an alternative to the cost and complexity of collecting a large-scale dataset from real children.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Jul 27, 2023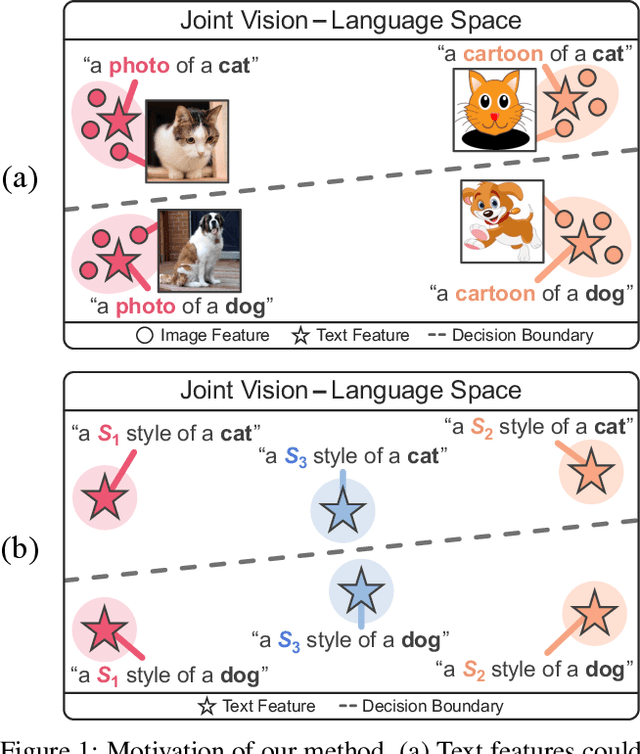
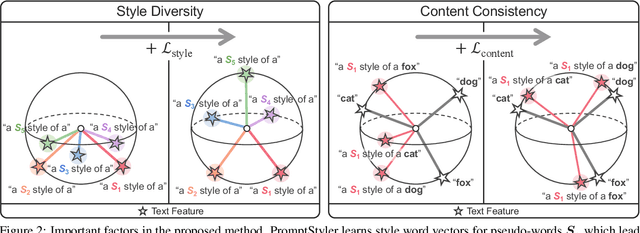
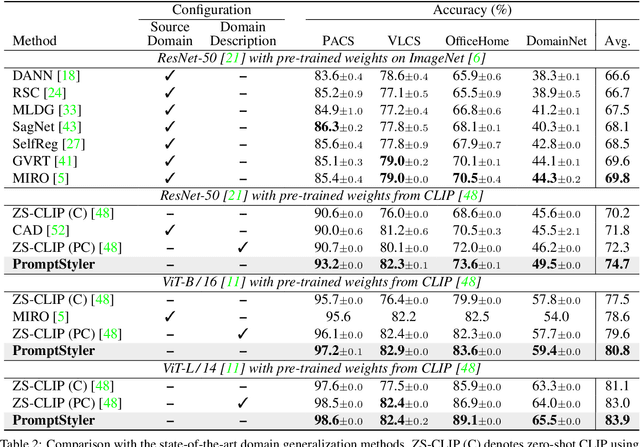
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Inspired by this, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. Our method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, although it does not require any images and takes just ~30 minutes for training using a single GPU.
Car-Driver Drowsiness Assessment through 1D Temporal Convolutional Networks
Jul 27, 2023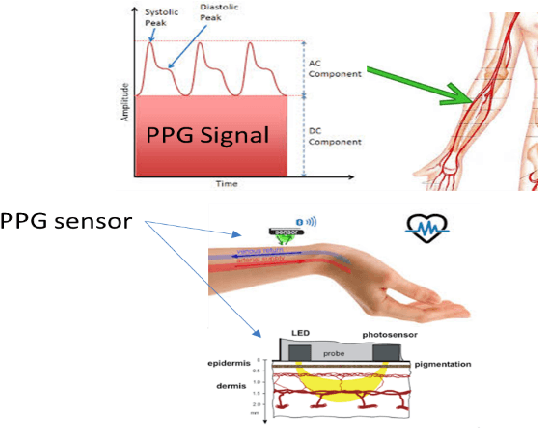
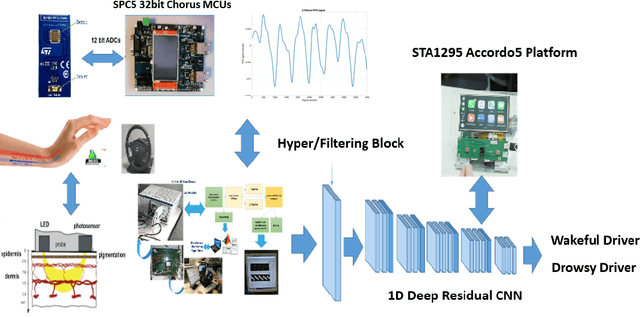
Recently, the scientific progress of Advanced Driver Assistance System solutions (ADAS) has played a key role in enhancing the overall safety of driving. ADAS technology enables active control of vehicles to prevent potentially risky situations. An important aspect that researchers have focused on is the analysis of the driver attention level, as recent reports confirmed a rising number of accidents caused by drowsiness or lack of attentiveness. To address this issue, various studies have suggested monitoring the driver physiological state, as there exists a well-established connection between the Autonomic Nervous System (ANS) and the level of attention. For our study, we designed an innovative bio-sensor comprising near-infrared LED emitters and photo-detectors, specifically a Silicon PhotoMultiplier device. This allowed us to assess the driver physiological status by analyzing the associated PhotoPlethysmography (PPG) signal.Furthermore, we developed an embedded time-domain hyper-filtering technique in conjunction with a 1D Temporal Convolutional architecture that embdes a progressive dilation setup. This integrated system enables near real-time classification of driver drowsiness, yielding remarkable accuracy levels of approximately 96%.