 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
PAg-NeRF: Towards fast and efficient end-to-end panoptic 3D representations for agricultural robotics
Sep 11, 2023
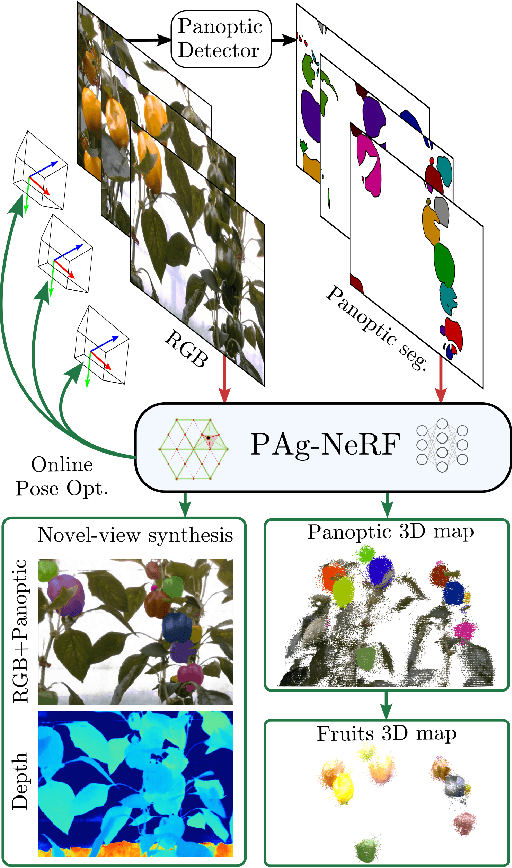

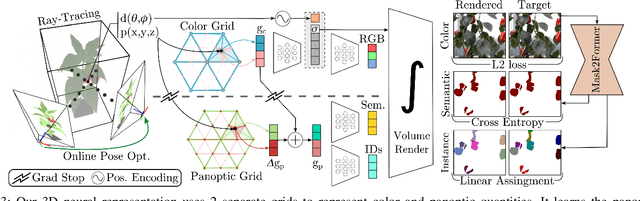

Precise scene understanding is key for most robot monitoring and intervention tasks in agriculture. In this work we present PAg-NeRF which is a novel NeRF-based system that enables 3D panoptic scene understanding. Our representation is trained using an image sequence with noisy robot odometry poses and automatic panoptic predictions with inconsistent IDs between frames. Despite this noisy input, our system is able to output scene geometry, photo-realistic renders and 3D consistent panoptic representations with consistent instance IDs. We evaluate this novel system in a very challenging horticultural scenario and in doing so demonstrate an end-to-end trainable system that can make use of noisy robot poses rather than precise poses that have to be pre-calculated. Compared to a baseline approach the peak signal to noise ratio is improved from 21.34dB to 23.37dB while the panoptic quality improves from 56.65% to 70.08%. Furthermore, our approach is faster and can be tuned to improve inference time by more than a factor of 2 while being memory efficient with approximately 12 times fewer parameters.
TwinTex: Geometry-aware Texture Generation for Abstracted 3D Architectural Models
Sep 20, 2023Coarse architectural models are often generated at scales ranging from individual buildings to scenes for downstream applications such as Digital Twin City, Metaverse, LODs, etc. Such piece-wise planar models can be abstracted as twins from 3D dense reconstructions. However, these models typically lack realistic texture relative to the real building or scene, making them unsuitable for vivid display or direct reference. In this paper, we present TwinTex, the first automatic texture mapping framework to generate a photo-realistic texture for a piece-wise planar proxy. Our method addresses most challenges occurring in such twin texture generation. Specifically, for each primitive plane, we first select a small set of photos with greedy heuristics considering photometric quality, perspective quality and facade texture completeness. Then, different levels of line features (LoLs) are extracted from the set of selected photos to generate guidance for later steps. With LoLs, we employ optimization algorithms to align texture with geometry from local to global. Finally, we fine-tune a diffusion model with a multi-mask initialization component and a new dataset to inpaint the missing region. Experimental results on many buildings, indoor scenes and man-made objects of varying complexity demonstrate the generalization ability of our algorithm. Our approach surpasses state-of-the-art texture mapping methods in terms of high-fidelity quality and reaches a human-expert production level with much less effort. Project page: https://vcc.tech/research/2023/TwinTex.
Source Camera Identification and Detection in Digital Videos through Blind Forensics
Sep 06, 2023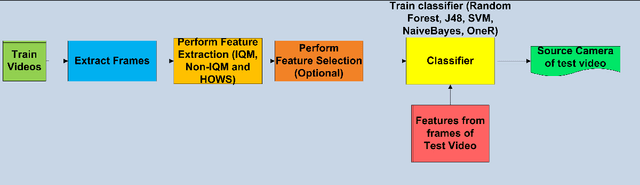

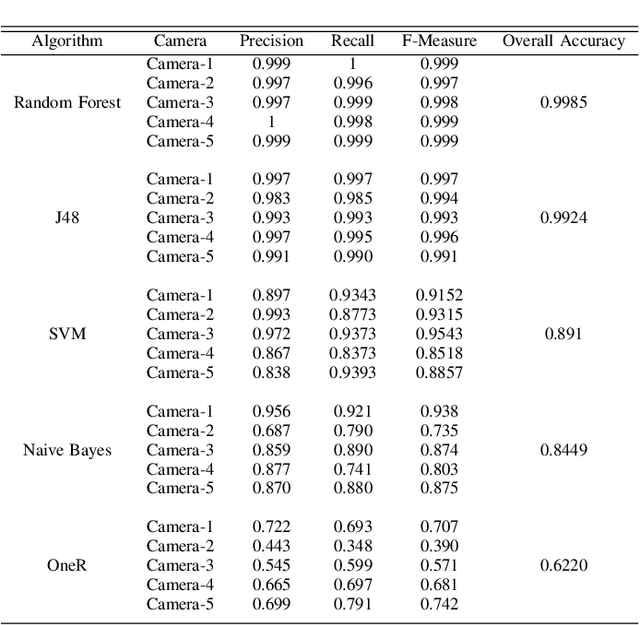
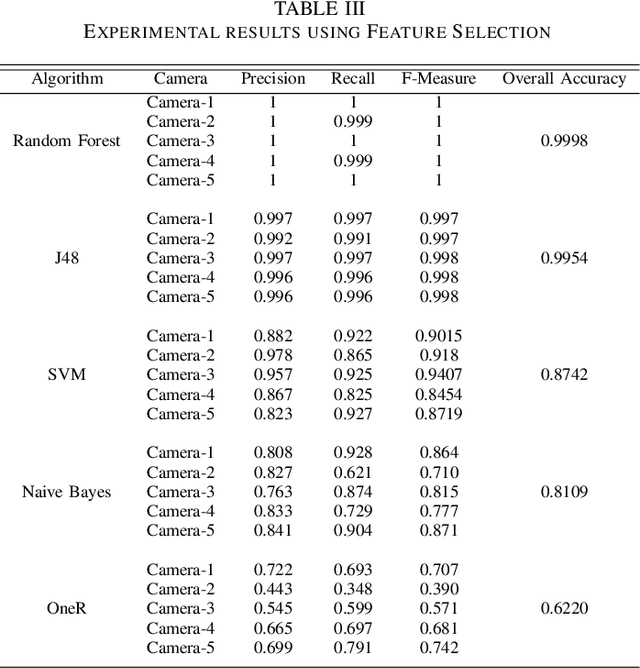
Source camera identification in digital videos is the problem of associating an unknown digital video with its source device, within a closed set of possible devices. The existing techniques in source detection of digital videos try to find a fingerprint of the actual source in the video in form of PRNU (Photo Response Non--Uniformity), and match it against the SPN (Sensor Pattern Noise) of each possible device. The highest correlation indicates the correct source. We investigate the problem of identifying a video source through a feature based approach using machine learning. In this paper, we present a blind forensic technique of video source authentication and identification, based on feature extraction, feature selection and subsequent source classification. The main aim is to determine whether a claimed source for a video is actually its original source. If not, we identify its original source. Our experimental results prove the efficiency of the proposed method compared to traditional fingerprint based technique.
Closing the Loop on Runtime Monitors with Fallback-Safe MPC
Sep 18, 2023When we rely on deep-learned models for robotic perception, we must recognize that these models may behave unreliably on inputs dissimilar from the training data, compromising the closed-loop system's safety. This raises fundamental questions on how we can assess confidence in perception systems and to what extent we can take safety-preserving actions when external environmental changes degrade our perception model's performance. Therefore, we present a framework to certify the safety of a perception-enabled system deployed in novel contexts. To do so, we leverage robust model predictive control (MPC) to control the system using the perception estimates while maintaining the feasibility of a safety-preserving fallback plan that does not rely on the perception system. In addition, we calibrate a runtime monitor using recently proposed conformal prediction techniques to certifiably detect when the perception system degrades beyond the tolerance of the MPC controller, resulting in an end-to-end safety assurance. We show that this control framework and calibration technique allows us to certify the system's safety with orders of magnitudes fewer samples than required to retrain the perception network when we deploy in a novel context on a photo-realistic aircraft taxiing simulator. Furthermore, we illustrate the safety-preserving behavior of the MPC on simulated examples of a quadrotor. We open-source our simulation platform and provide videos of our results at our project page: https://tinyurl.com/fallback-safe-mpc.
PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models
Sep 11, 2023
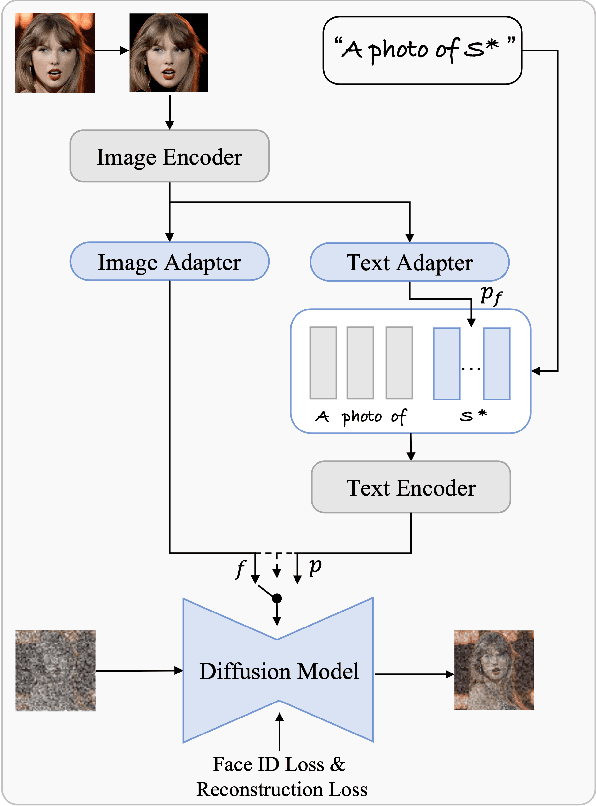
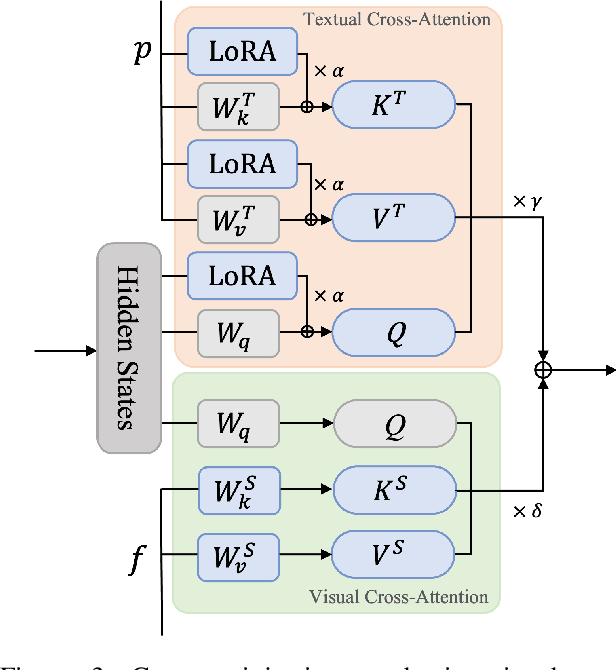
Personalized text-to-image generation has emerged as a powerful and sought-after tool, empowering users to create customized images based on their specific concepts and prompts. However, existing approaches to personalization encounter multiple challenges, including long tuning times, large storage requirements, the necessity for multiple input images per identity, and limitations in preserving identity and editability. To address these obstacles, we present PhotoVerse, an innovative methodology that incorporates a dual-branch conditioning mechanism in both text and image domains, providing effective control over the image generation process. Furthermore, we introduce facial identity loss as a novel component to enhance the preservation of identity during training. Remarkably, our proposed PhotoVerse eliminates the need for test time tuning and relies solely on a single facial photo of the target identity, significantly reducing the resource cost associated with image generation. After a single training phase, our approach enables generating high-quality images within only a few seconds. Moreover, our method can produce diverse images that encompass various scenes and styles. The extensive evaluation demonstrates the superior performance of our approach, which achieves the dual objectives of preserving identity and facilitating editability. Project page: https://photoverse2d.github.io/
Unsupervised Scene Sketch to Photo Synthesis
Sep 06, 2022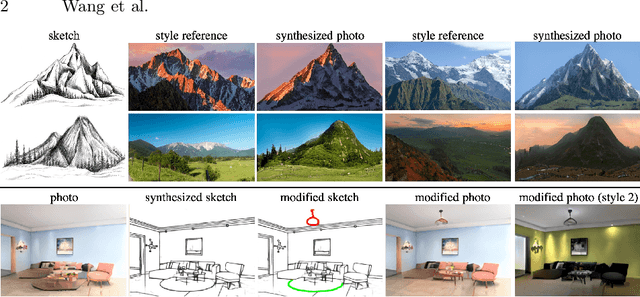
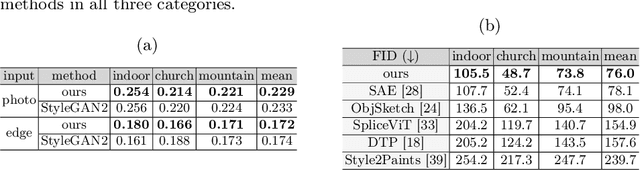
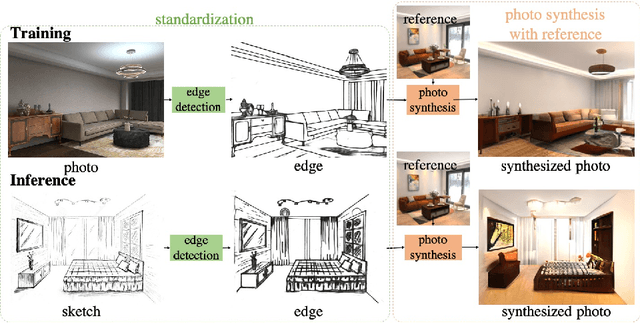

Sketches make an intuitive and powerful visual expression as they are fast executed freehand drawings. We present a method for synthesizing realistic photos from scene sketches. Without the need for sketch and photo pairs, our framework directly learns from readily available large-scale photo datasets in an unsupervised manner. To this end, we introduce a standardization module that provides pseudo sketch-photo pairs during training by converting photos and sketches to a standardized domain, i.e. the edge map. The reduced domain gap between sketch and photo also allows us to disentangle them into two components: holistic scene structures and low-level visual styles such as color and texture. Taking this advantage, we synthesize a photo-realistic image by combining the structure of a sketch and the visual style of a reference photo. Extensive experimental results on perceptual similarity metrics and human perceptual studies show the proposed method could generate realistic photos with high fidelity from scene sketches and outperform state-of-the-art photo synthesis baselines. We also demonstrate that our framework facilitates a controllable manipulation of photo synthesis by editing strokes of corresponding sketches, delivering more fine-grained details than previous approaches that rely on region-level editing.
Chasing Consistency in Text-to-3D Generation from a Single Image
Sep 07, 2023

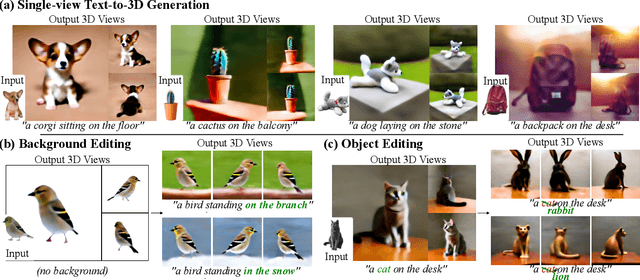
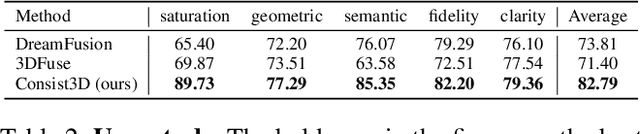
Text-to-3D generation from a single-view image is a popular but challenging task in 3D vision. Although numerous methods have been proposed, existing works still suffer from the inconsistency issues, including 1) semantic inconsistency, 2) geometric inconsistency, and 3) saturation inconsistency, resulting in distorted, overfitted, and over-saturated generations. In light of the above issues, we present Consist3D, a three-stage framework Chasing for semantic-, geometric-, and saturation-Consistent Text-to-3D generation from a single image, in which the first two stages aim to learn parameterized consistency tokens, and the last stage is for optimization. Specifically, the semantic encoding stage learns a token independent of views and estimations, promoting semantic consistency and robustness. Meanwhile, the geometric encoding stage learns another token with comprehensive geometry and reconstruction constraints under novel-view estimations, reducing overfitting and encouraging geometric consistency. Finally, the optimization stage benefits from the semantic and geometric tokens, allowing a low classifier-free guidance scale and therefore preventing oversaturation. Experimental results demonstrate that Consist3D produces more consistent, faithful, and photo-realistic 3D assets compared to previous state-of-the-art methods. Furthermore, Consist3D also allows background and object editing through text prompts.
Point2Pix: Photo-Realistic Point Cloud Rendering via Neural Radiance Fields
Mar 29, 2023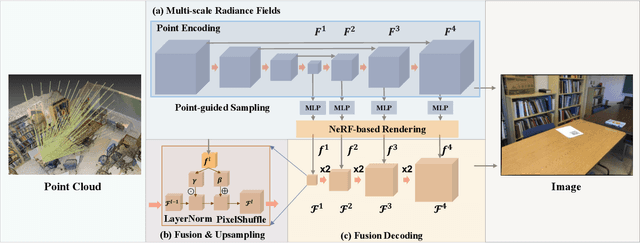
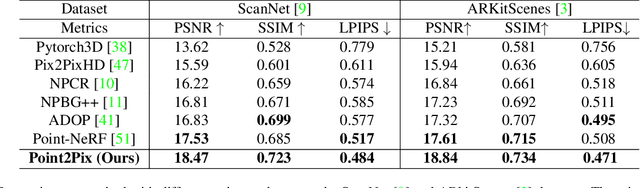
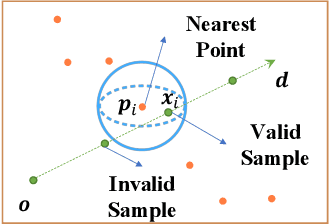
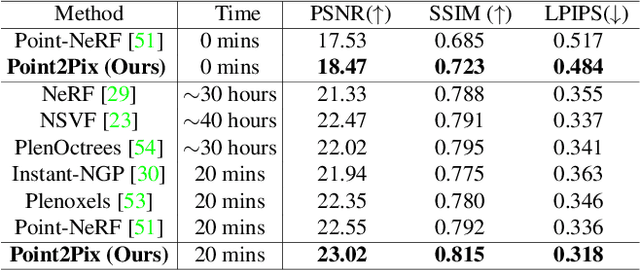
Synthesizing photo-realistic images from a point cloud is challenging because of the sparsity of point cloud representation. Recent Neural Radiance Fields and extensions are proposed to synthesize realistic images from 2D input. In this paper, we present Point2Pix as a novel point renderer to link the 3D sparse point clouds with 2D dense image pixels. Taking advantage of the point cloud 3D prior and NeRF rendering pipeline, our method can synthesize high-quality images from colored point clouds, generally for novel indoor scenes. To improve the efficiency of ray sampling, we propose point-guided sampling, which focuses on valid samples. Also, we present Point Encoding to build Multi-scale Radiance Fields that provide discriminative 3D point features. Finally, we propose Fusion Encoding to efficiently synthesize high-quality images. Extensive experiments on the ScanNet and ArkitScenes datasets demonstrate the effectiveness and generalization.
LoGoPrompt: Synthetic Text Images Can Be Good Visual Prompts for Vision-Language Models
Sep 03, 2023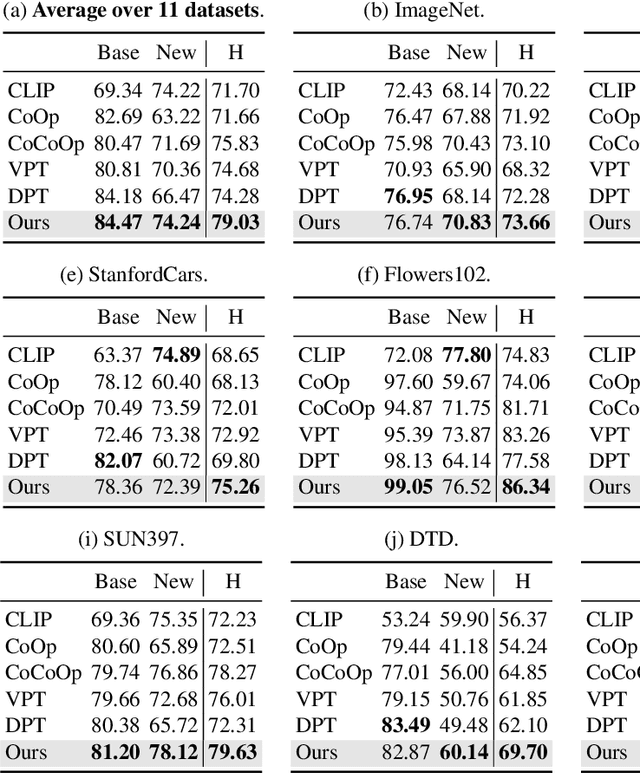

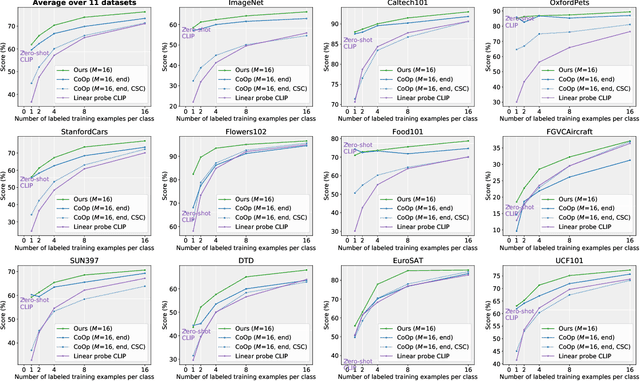
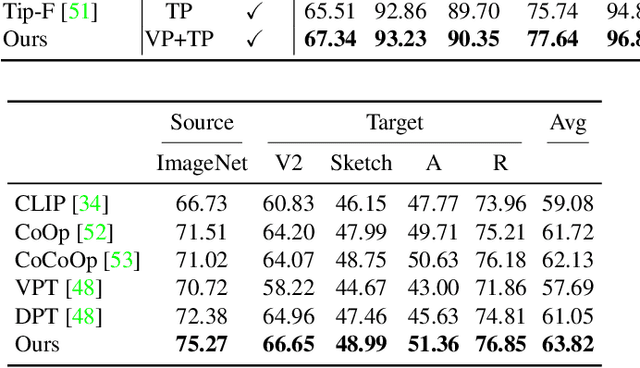
Prompt engineering is a powerful tool used to enhance the performance of pre-trained models on downstream tasks. For example, providing the prompt ``Let's think step by step" improved GPT-3's reasoning accuracy to 63% on MutiArith while prompting ``a photo of" filled with a class name enables CLIP to achieve $80$\% zero-shot accuracy on ImageNet. While previous research has explored prompt learning for the visual modality, analyzing what constitutes a good visual prompt specifically for image recognition is limited. In addition, existing visual prompt tuning methods' generalization ability is worse than text-only prompting tuning. This paper explores our key insight: synthetic text images are good visual prompts for vision-language models! To achieve that, we propose our LoGoPrompt, which reformulates the classification objective to the visual prompt selection and addresses the chicken-and-egg challenge of first adding synthetic text images as class-wise visual prompts or predicting the class first. Without any trainable visual prompt parameters, experimental results on 16 datasets demonstrate that our method consistently outperforms state-of-the-art methods in few-shot learning, base-to-new generalization, and domain generalization.