 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
RenderIH: A Large-scale Synthetic Dataset for 3D Interacting Hand Pose Estimation
Sep 27, 2023

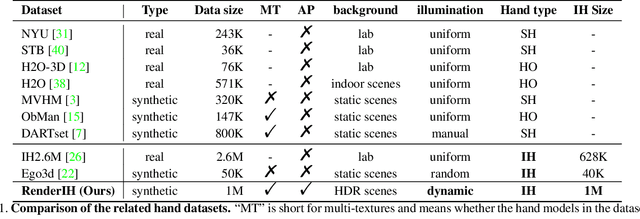
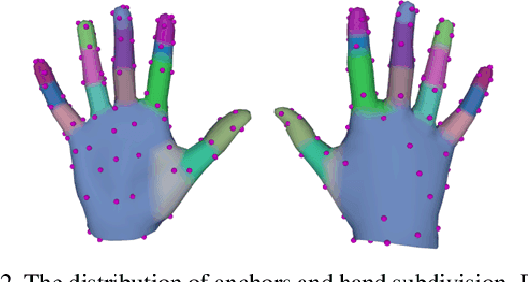

The current interacting hand (IH) datasets are relatively simplistic in terms of background and texture, with hand joints being annotated by a machine annotator, which may result in inaccuracies, and the diversity of pose distribution is limited. However, the variability of background, pose distribution, and texture can greatly influence the generalization ability. Therefore, we present a large-scale synthetic dataset RenderIH for interacting hands with accurate and diverse pose annotations. The dataset contains 1M photo-realistic images with varied backgrounds, perspectives, and hand textures. To generate natural and diverse interacting poses, we propose a new pose optimization algorithm. Additionally, for better pose estimation accuracy, we introduce a transformer-based pose estimation network, TransHand, to leverage the correlation between interacting hands and verify the effectiveness of RenderIH in improving results. Our dataset is model-agnostic and can improve more accuracy of any hand pose estimation method in comparison to other real or synthetic datasets. Experiments have shown that pretraining on our synthetic data can significantly decrease the error from 6.76mm to 5.79mm, and our Transhand surpasses contemporary methods. Our dataset and code are available at https://github.com/adwardlee/RenderIH.
Photo Rater: Photographs Auto-Selector with Deep Learning
Nov 26, 2022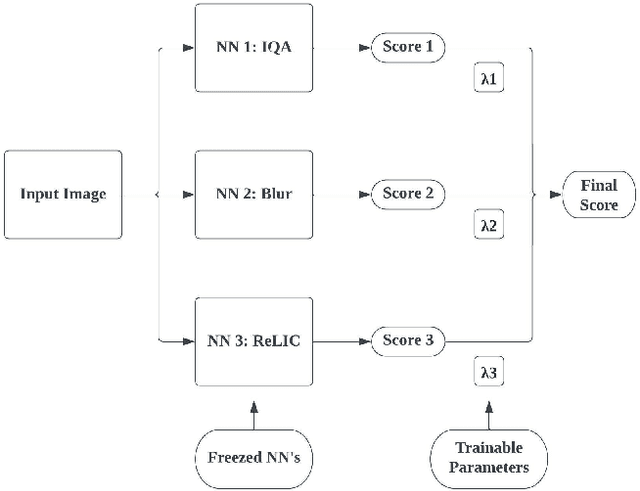


Photo Rater is a computer vision project that uses neural networks to help photographers select the best photo among those that are taken based on the same scene. This process is usually referred to as "culling" in photography, and it can be tedious and time-consuming if done manually. Photo Rater utilizes three separate neural networks to complete such a task: one for general image quality assessment, one for classifying whether the photo is blurry (either due to unsteady hands or out-of-focusness), and one for assessing general aesthetics (including the composition of the photo, among others). After feeding the image through each neural network, Photo Rater outputs a final score for each image, ranking them based on this score and presenting it to the user.
Detecting internal disorders in fruit by CT. Part 1: Joint 2D to 3D image registration workflow for comparing multiple slice photographs and CT scans of apple fruit
Oct 03, 2023A large percentage of apples are affected by internal disorders after long-term storage, which makes them unacceptable in the supply chain. CT imaging is a promising technique for in-line detection of these disorders. Therefore, it is crucial to understand how different disorders affect the image features that can be observed in CT scans. This paper presents a workflow for creating datasets of image pairs of photographs of apple slices and their corresponding CT slices. By having CT and photographic images of the same part of the apple, the complementary information in both images can be used to study the processes underlying internal disorders and how internal disorders can be measured in CT images. The workflow includes data acquisition, image segmentation, image registration, and validation methods. The image registration method aligns all available slices of an apple within a single optimization problem, assuming that the slices are parallel. This method outperformed optimizing the alignment separately for each slice. The workflow was applied to create a dataset of 1347 slice photographs and their corresponding CT slices. The dataset was acquired from 107 'Kanzi' apples that had been stored in controlled atmosphere (CA) storage for 8 months. In this dataset, the distance between annotations in the slice photograph and the matching CT slice was, on average, $1.47 \pm 0.40$ mm. Our workflow allows collecting large datasets of accurately aligned photo-CT image pairs, which can help distinguish internal disorders with a similar appearance on CT. With slight modifications, a similar workflow can be applied to other fruits or MRI instead of CT scans.
ExBluRF: Efficient Radiance Fields for Extreme Motion Blurred Images
Sep 21, 2023

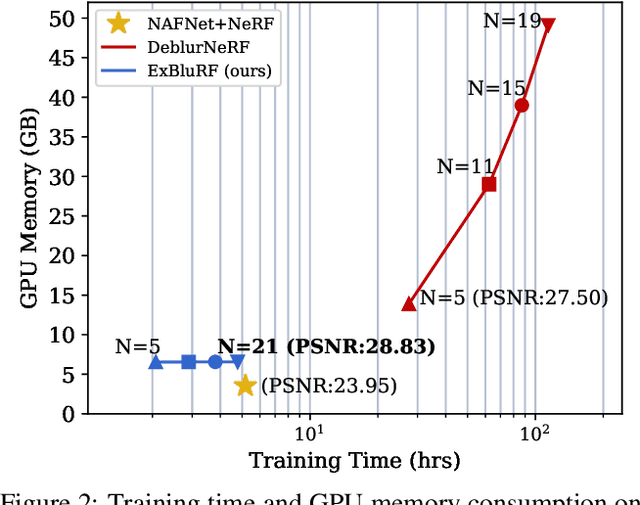
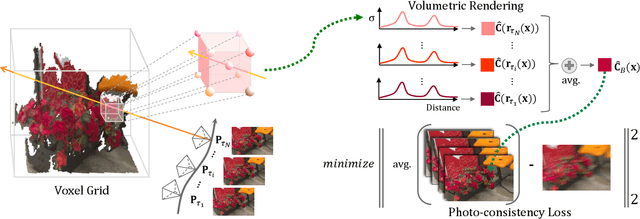
We present ExBluRF, a novel view synthesis method for extreme motion blurred images based on efficient radiance fields optimization. Our approach consists of two main components: 6-DOF camera trajectory-based motion blur formulation and voxel-based radiance fields. From extremely blurred images, we optimize the sharp radiance fields by jointly estimating the camera trajectories that generate the blurry images. In training, multiple rays along the camera trajectory are accumulated to reconstruct single blurry color, which is equivalent to the physical motion blur operation. We minimize the photo-consistency loss on blurred image space and obtain the sharp radiance fields with camera trajectories that explain the blur of all images. The joint optimization on the blurred image space demands painfully increasing computation and resources proportional to the blur size. Our method solves this problem by replacing the MLP-based framework to low-dimensional 6-DOF camera poses and voxel-based radiance fields. Compared with the existing works, our approach restores much sharper 3D scenes from challenging motion blurred views with the order of 10 times less training time and GPU memory consumption.
POLAR3D: Augmenting NASA's POLAR Dataset for Data-Driven Lunar Perception and Rover Simulation
Sep 21, 2023



We report on an effort that led to POLAR3D, a set of digital assets that enhance the POLAR dataset of stereo images generated by NASA to mimic lunar lighting conditions. Our contributions are twofold. First, we have annotated each photo in the POLAR dataset, providing approximately 23 000 labels for rocks and their shadows. Second, we digitized several lunar terrain scenarios available in the POLAR dataset. Specifically, by utilizing both the lunar photos and the POLAR's LiDAR point clouds, we constructed detailed obj files for all identifiable assets. POLAR3D is the set of digital assets comprising of rock/shadow labels and obj files associated with the digital twins of lunar terrain scenarios. This new dataset can be used for training perception algorithms for lunar exploration and synthesizing photorealistic images beyond the original POLAR collection. Likewise, the obj assets can be integrated into simulation environments to facilitate realistic rover operations in a digital twin of a POLAR scenario. POLAR3D is publicly available to aid perception algorithm development, camera simulation efforts, and lunar simulation exercises.POLAR3D is publicly available at https://github.com/uwsbel/POLAR-digital.
IFT: Image Fusion Transformer for Ghost-free High Dynamic Range Imaging
Sep 26, 2023Multi-frame high dynamic range (HDR) imaging aims to reconstruct ghost-free images with photo-realistic details from content-complementary but spatially misaligned low dynamic range (LDR) images. Existing HDR algorithms are prone to producing ghosting artifacts as their methods fail to capture long-range dependencies between LDR frames with large motion in dynamic scenes. To address this issue, we propose a novel image fusion transformer, referred to as IFT, which presents a fast global patch searching (FGPS) module followed by a self-cross fusion module (SCF) for ghost-free HDR imaging. The FGPS searches the patches from supporting frames that have the closest dependency to each patch of the reference frame for long-range dependency modeling, while the SCF conducts intra-frame and inter-frame feature fusion on the patches obtained by the FGPS with linear complexity to input resolution. By matching similar patches between frames, objects with large motion ranges in dynamic scenes can be aligned, which can effectively alleviate the generation of artifacts. In addition, the proposed FGPS and SCF can be integrated into various deep HDR methods as efficient plug-in modules. Extensive experiments on multiple benchmarks show that our method achieves state-of-the-art performance both quantitatively and qualitatively.
Learning Dense Correspondences between Photos and Sketches
Jul 24, 2023Humans effortlessly grasp the connection between sketches and real-world objects, even when these sketches are far from realistic. Moreover, human sketch understanding goes beyond categorization -- critically, it also entails understanding how individual elements within a sketch correspond to parts of the physical world it represents. What are the computational ingredients needed to support this ability? Towards answering this question, we make two contributions: first, we introduce a new sketch-photo correspondence benchmark, $\textit{PSC6k}$, containing 150K annotations of 6250 sketch-photo pairs across 125 object categories, augmenting the existing Sketchy dataset with fine-grained correspondence metadata. Second, we propose a self-supervised method for learning dense correspondences between sketch-photo pairs, building upon recent advances in correspondence learning for pairs of photos. Our model uses a spatial transformer network to estimate the warp flow between latent representations of a sketch and photo extracted by a contrastive learning-based ConvNet backbone. We found that this approach outperformed several strong baselines and produced predictions that were quantitatively consistent with other warp-based methods. However, our benchmark also revealed systematic differences between predictions of the suite of models we tested and those of humans. Taken together, our work suggests a promising path towards developing artificial systems that achieve more human-like understanding of visual images at different levels of abstraction. Project page: https://photo-sketch-correspondence.github.io
LoGoPrompt: Synthetic Text Images Can Be Good Visual Prompts for Vision-Language Models
Sep 22, 2023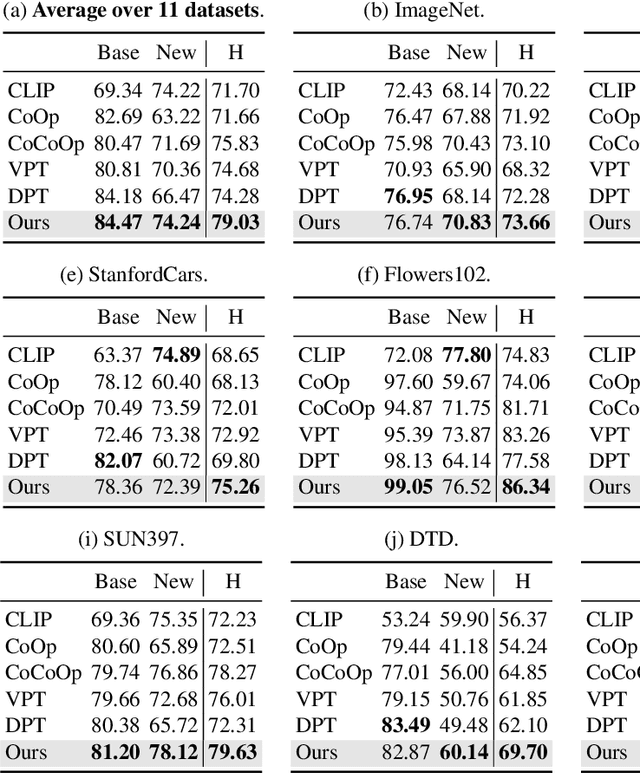

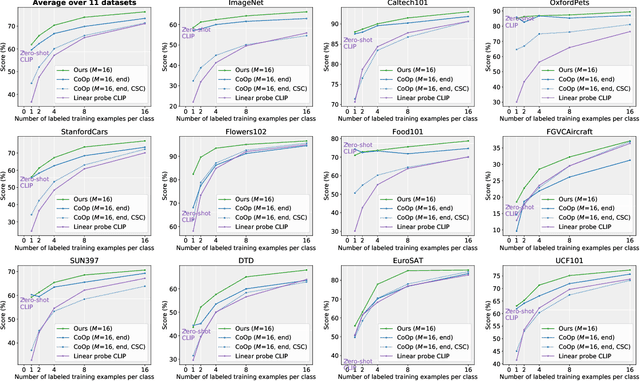
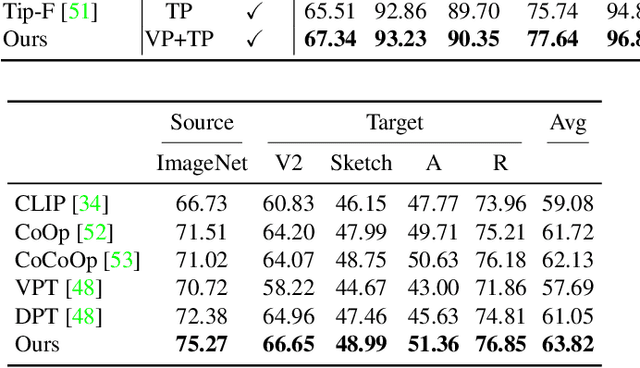
Prompt engineering is a powerful tool used to enhance the performance of pre-trained models on downstream tasks. For example, providing the prompt "Let's think step by step" improved GPT-3's reasoning accuracy to 63% on MutiArith while prompting "a photo of" filled with a class name enables CLIP to achieve $80$\% zero-shot accuracy on ImageNet. While previous research has explored prompt learning for the visual modality, analyzing what constitutes a good visual prompt specifically for image recognition is limited. In addition, existing visual prompt tuning methods' generalization ability is worse than text-only prompting tuning. This paper explores our key insight: synthetic text images are good visual prompts for vision-language models! To achieve that, we propose our LoGoPrompt, which reformulates the classification objective to the visual prompt selection and addresses the chicken-and-egg challenge of first adding synthetic text images as class-wise visual prompts or predicting the class first. Without any trainable visual prompt parameters, experimental results on 16 datasets demonstrate that our method consistently outperforms state-of-the-art methods in few-shot learning, base-to-new generalization, and domain generalization.
Angle Range and Identity Similarity Enhanced Gaze and Head Redirection based on Synthetic data
Sep 11, 2023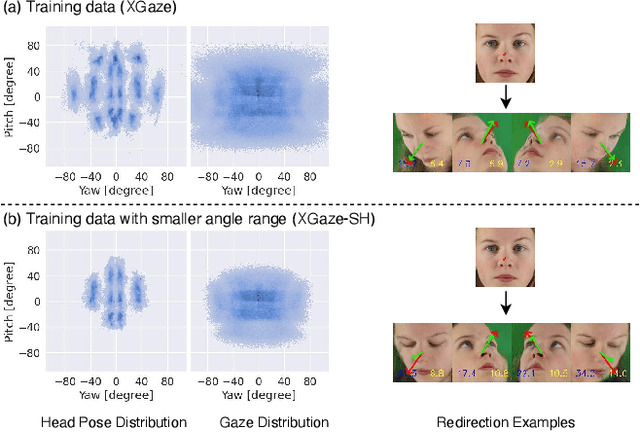

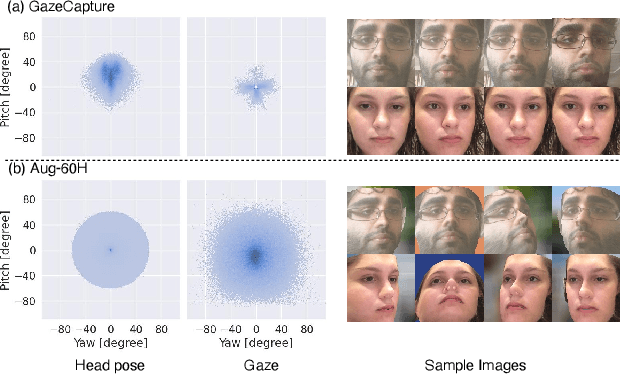
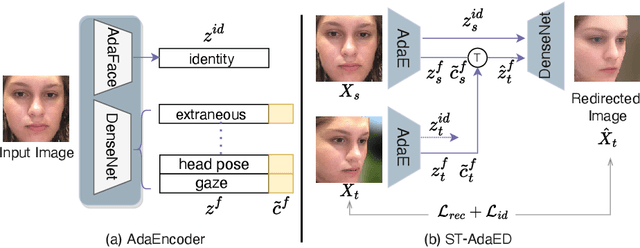
In this paper, we propose a method for improving the angular accuracy and photo-reality of gaze and head redirection in full-face images. The problem with current models is that they cannot handle redirection at large angles, and this limitation mainly comes from the lack of training data. To resolve this problem, we create data augmentation by monocular 3D face reconstruction to extend the head pose and gaze range of the real data, which allows the model to handle a wider redirection range. In addition to the main focus on data augmentation, we also propose a framework with better image quality and identity preservation of unseen subjects even training with synthetic data. Experiments show that our method significantly improves redirection performance in terms of redirection angular accuracy while maintaining high image quality, especially when redirecting to large angles.
Photo-zSNthesis: Converting Type Ia Supernova Lightcurves to Redshift Estimates via Deep Learning
May 19, 2023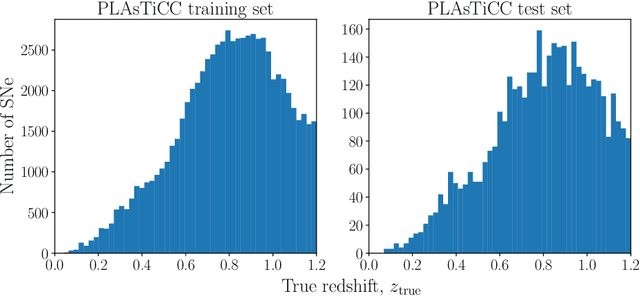

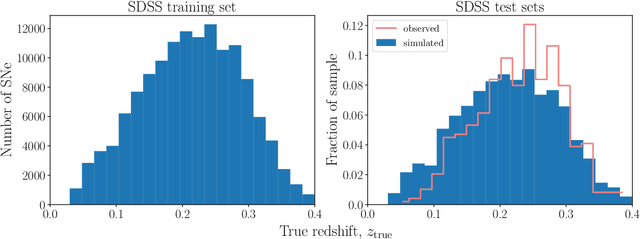
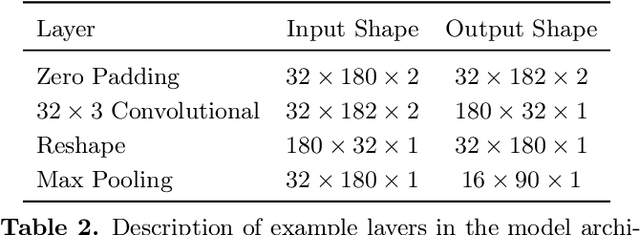
Upcoming photometric surveys will discover tens of thousands of Type Ia supernovae (SNe Ia), vastly outpacing the capacity of our spectroscopic resources. In order to maximize the science return of these observations in the absence of spectroscopic information, we must accurately extract key parameters, such as SN redshifts, with photometric information alone. We present Photo-zSNthesis, a convolutional neural network-based method for predicting full redshift probability distributions from multi-band supernova lightcurves, tested on both simulated Sloan Digital Sky Survey (SDSS) and Vera C. Rubin Legacy Survey of Space and Time (LSST) data as well as observed SDSS SNe. We show major improvements over predictions from existing methods on both simulations and real observations as well as minimal redshift-dependent bias, which is a challenge due to selection effects, e.g. Malmquist bias. The PDFs produced by this method are well-constrained and will maximize the cosmological constraining power of photometric SNe Ia samples.