 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Text-Guided Scene Sketch-to-Photo Synthesis
Feb 14, 2023
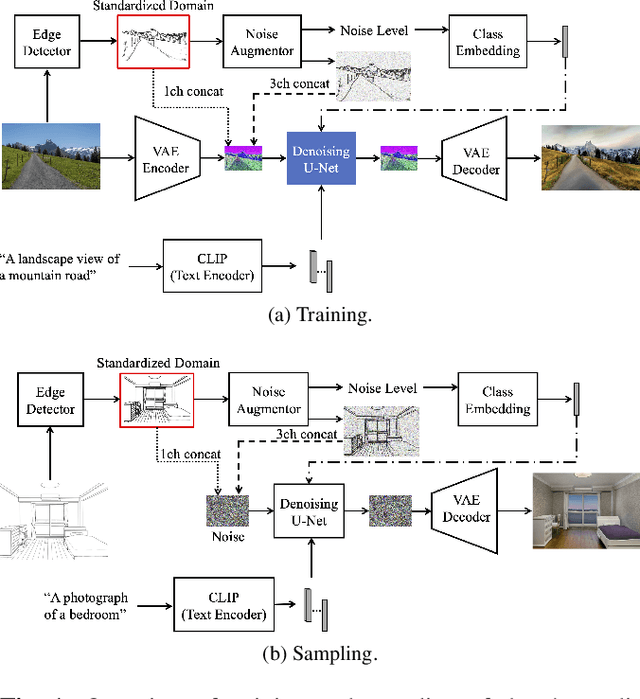
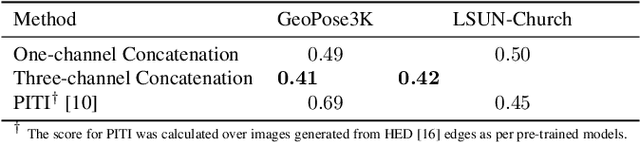


We propose a method for scene-level sketch-to-photo synthesis with text guidance. Although object-level sketch-to-photo synthesis has been widely studied, whole-scene synthesis is still challenging without reference photos that adequately reflect the target style. To this end, we leverage knowledge from recent large-scale pre-trained generative models, resulting in text-guided sketch-to-photo synthesis without the need for reference images. To train our model, we use self-supervised learning from a set of photographs. Specifically, we use a pre-trained edge detector that maps both color and sketch images into a standardized edge domain, which reduces the gap between photograph-based edge images (during training) and hand-drawn sketch images (during inference). We implement our method by fine-tuning a latent diffusion model (i.e., Stable Diffusion) with sketch and text conditions. Experiments show that the proposed method translates original sketch images that are not extracted from color images into photos with compelling visual quality.
Guiding Instruction-based Image Editing via Multimodal Large Language Models
Sep 29, 2023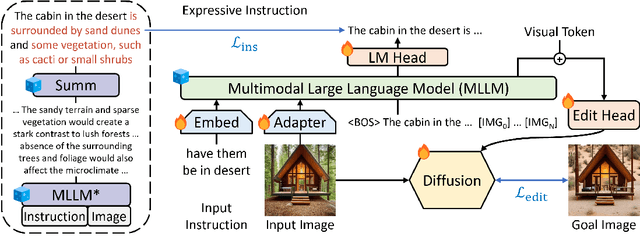
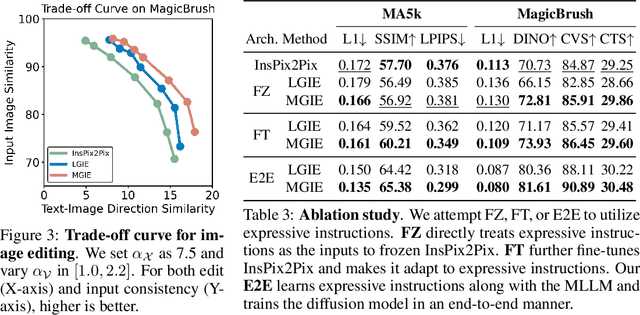
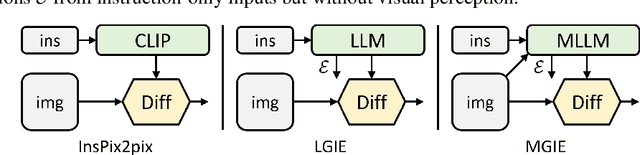
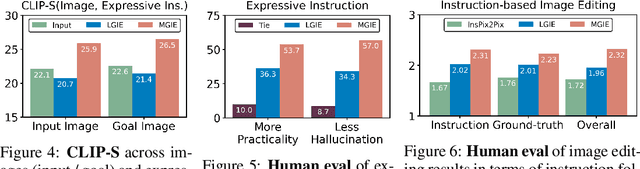
Instruction-based image editing improves the controllability and flexibility of image manipulation via natural commands without elaborate descriptions or regional masks. However, human instructions are sometimes too brief for current methods to capture and follow. Multimodal large language models (MLLMs) show promising capabilities in cross-modal understanding and visual-aware response generation via LMs. We investigate how MLLMs facilitate edit instructions and present MLLM-Guided Image Editing (MGIE). MGIE learns to derive expressive instructions and provides explicit guidance. The editing model jointly captures this visual imagination and performs manipulation through end-to-end training. We evaluate various aspects of Photoshop-style modification, global photo optimization, and local editing. Extensive experimental results demonstrate that expressive instructions are crucial to instruction-based image editing, and our MGIE can lead to a notable improvement in automatic metrics and human evaluation while maintaining competitive inference efficiency.
ILSH: The Imperial Light-Stage Head Dataset for Human Head View Synthesis
Oct 06, 2023This paper introduces the Imperial Light-Stage Head (ILSH) dataset, a novel light-stage-captured human head dataset designed to support view synthesis academic challenges for human heads. The ILSH dataset is intended to facilitate diverse approaches, such as scene-specific or generic neural rendering, multiple-view geometry, 3D vision, and computer graphics, to further advance the development of photo-realistic human avatars. This paper details the setup of a light-stage specifically designed to capture high-resolution (4K) human head images and describes the process of addressing challenges (preprocessing, ethical issues) in collecting high-quality data. In addition to the data collection, we address the split of the dataset into train, validation, and test sets. Our goal is to design and support a fair view synthesis challenge task for this novel dataset, such that a similar level of performance can be maintained and expected when using the test set, as when using the validation set. The ILSH dataset consists of 52 subjects captured using 24 cameras with all 82 lighting sources turned on, resulting in a total of 1,248 close-up head images, border masks, and camera pose pairs.
sign.mt: Real-Time Multilingual Sign Language Translation Application
Oct 08, 2023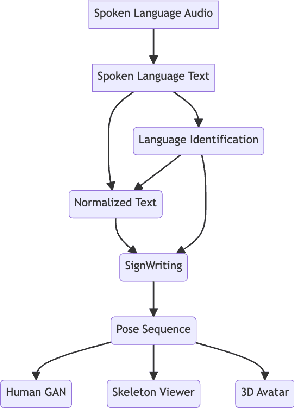
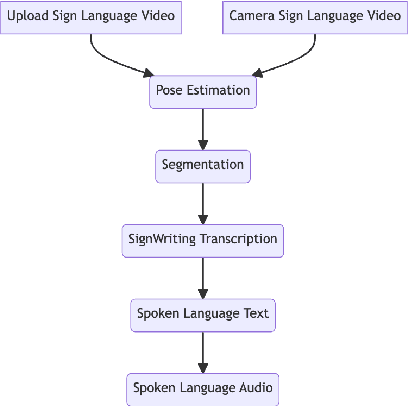
This demo paper presents sign.mt, an open-source application pioneering real-time multilingual bi-directional translation between spoken and signed languages. Harnessing state-of-the-art open-source models, this tool aims to address the communication divide between the hearing and the deaf, facilitating seamless translation in both spoken-to-signed and signed-to-spoken translation directions. Promising reliable and unrestricted communication, sign.mt offers offline functionality, crucial in areas with limited internet connectivity. It further enhances user engagement by offering customizable photo-realistic sign language avatars, thereby encouraging a more personalized and authentic user experience. Licensed under CC BY-NC-SA 4.0, sign.mt signifies an important stride towards open, inclusive communication. The app can be used, and modified for personal and academic uses, and even supports a translation API, fostering integration into a wider range of applications. However, it is by no means a finished product. We invite the NLP community to contribute towards the evolution of sign.mt. Whether it be the integration of more refined models, the development of innovative pipelines, or user experience improvements, your contributions can propel this project to new heights. Available at https://sign.mt, it stands as a testament to what we can achieve together, as we strive to make communication accessible to all.
Semantically-aware Mask CycleGAN for Translating Artistic Portraits to Photo-realistic Visualizations
Jun 11, 2023

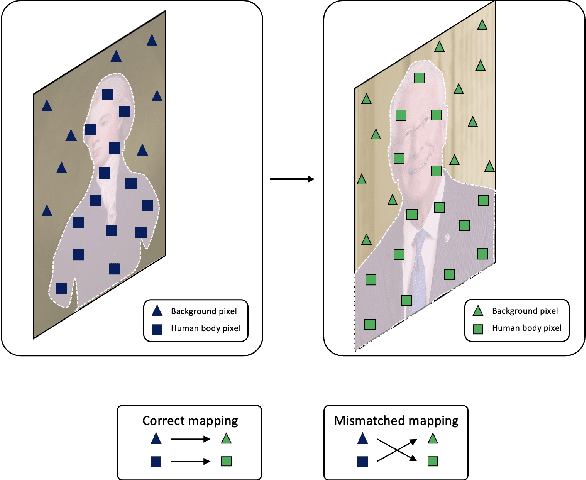

Image-to-image translation (I2I) is defined as a computer vision task where the aim is to transfer images in a source domain to a target domain with minimal loss or alteration of the content representations. Major progress has been made since I2I was proposed with the invention of a variety of revolutionary generative models. Among them, GAN-based models perform exceptionally well as they are mostly tailor-made for specific domains or tasks. However, few works proposed a tailor-made method for the artistic domain. In this project, I propose the Semantic-aware Mask CycleGAN (SMCycleGAN) architecture which can translate artistic portraits to photo-realistic visualizations. This model can generate realistic human portraits by feeding the discriminators semantically masked fake samples, thus enforcing them to make discriminative decisions with partial information so that the generators can be optimized to synthesize more realistic human portraits instead of increasing the similarity of other irrelevant components, such as the background. Experiments have shown that the SMCycleGAN generate images with significantly increased realism and minimal loss of content representations.
A Framework for Fast Prototyping of Photo-realistic Environments with Multiple Pedestrians
Apr 14, 2023
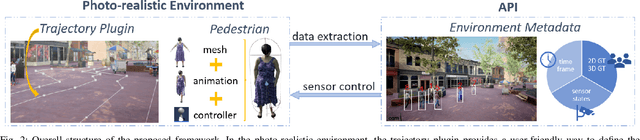
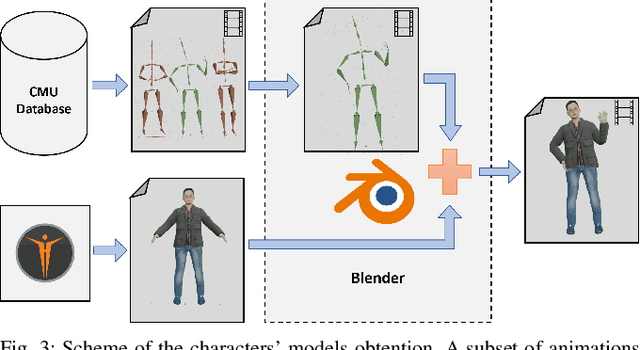
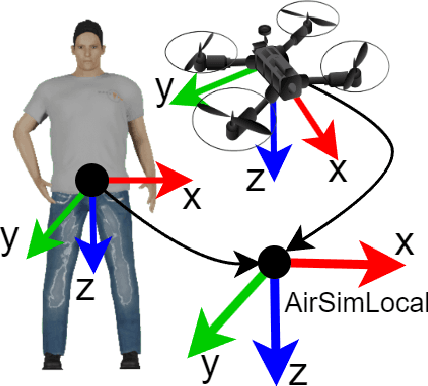
Robotic applications involving people often require advanced perception systems to better understand complex real-world scenarios. To address this challenge, photo-realistic and physics simulators are gaining popularity as a means of generating accurate data labeling and designing scenarios for evaluating generalization capabilities, e.g., lighting changes, camera movements or different weather conditions. We develop a photo-realistic framework built on Unreal Engine and AirSim to generate easily scenarios with pedestrians and mobile robots. The framework is capable to generate random and customized trajectories for each person and provides up to 50 ready-to-use people models along with an API for their metadata retrieval. We demonstrate the usefulness of the proposed framework with a use case of multi-target tracking, a popular problem in real pedestrian scenarios. The notable feature variability in the obtained perception data is presented and evaluated.
GETAvatar: Generative Textured Meshes for Animatable Human Avatars
Oct 04, 2023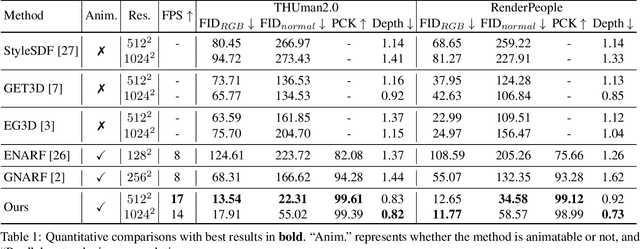
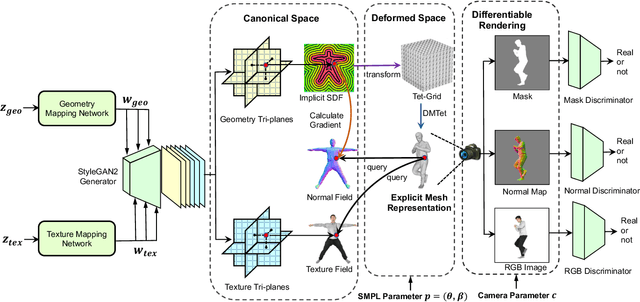

We study the problem of 3D-aware full-body human generation, aiming at creating animatable human avatars with high-quality textures and geometries. Generally, two challenges remain in this field: i) existing methods struggle to generate geometries with rich realistic details such as the wrinkles of garments; ii) they typically utilize volumetric radiance fields and neural renderers in the synthesis process, making high-resolution rendering non-trivial. To overcome these problems, we propose GETAvatar, a Generative model that directly generates Explicit Textured 3D meshes for animatable human Avatar, with photo-realistic appearance and fine geometric details. Specifically, we first design an articulated 3D human representation with explicit surface modeling, and enrich the generated humans with realistic surface details by learning from the 2D normal maps of 3D scan data. Second, with the explicit mesh representation, we can use a rasterization-based renderer to perform surface rendering, allowing us to achieve high-resolution image generation efficiently. Extensive experiments demonstrate that GETAvatar achieves state-of-the-art performance on 3D-aware human generation both in appearance and geometry quality. Notably, GETAvatar can generate images at 512x512 resolution with 17FPS and 1024x1024 resolution with 14FPS, improving upon previous methods by 2x. Our code and models will be available.
Automatic Animation of Hair Blowing in Still Portrait Photos
Sep 25, 2023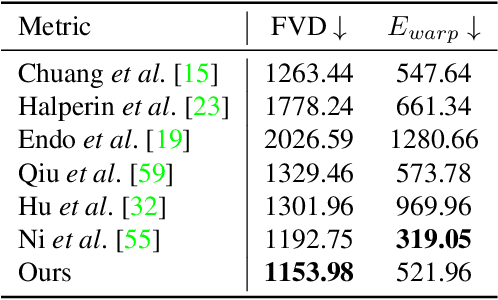
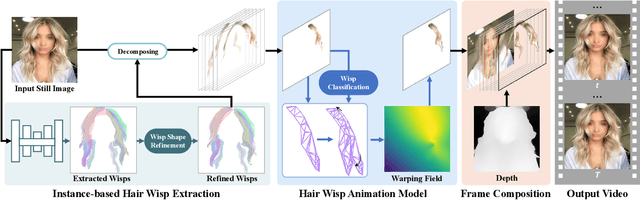

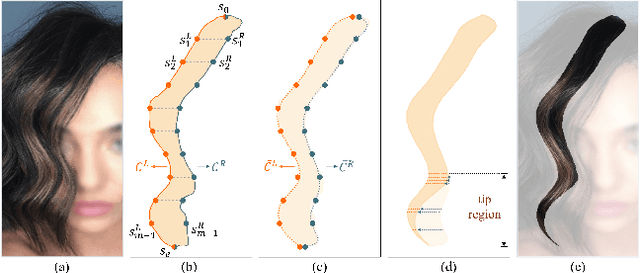
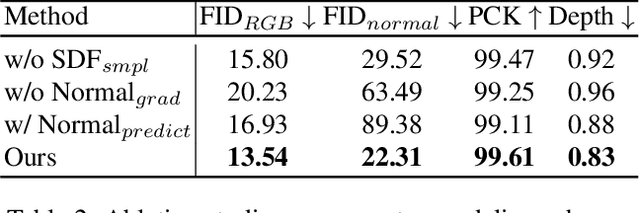
We propose a novel approach to animate human hair in a still portrait photo. Existing work has largely studied the animation of fluid elements such as water and fire. However, hair animation for a real image remains underexplored, which is a challenging problem, due to the high complexity of hair structure and dynamics. Considering the complexity of hair structure, we innovatively treat hair wisp extraction as an instance segmentation problem, where a hair wisp is referred to as an instance. With advanced instance segmentation networks, our method extracts meaningful and natural hair wisps. Furthermore, we propose a wisp-aware animation module that animates hair wisps with pleasing motions without noticeable artifacts. The extensive experiments show the superiority of our method. Our method provides the most pleasing and compelling viewing experience in the qualitative experiments and outperforms state-of-the-art still-image animation methods by a large margin in the quantitative evaluation. Project url: \url{https://nevergiveu.github.io/AutomaticHairBlowing/}
Drag View: Generalizable Novel View Synthesis with Unposed Imagery
Oct 05, 2023

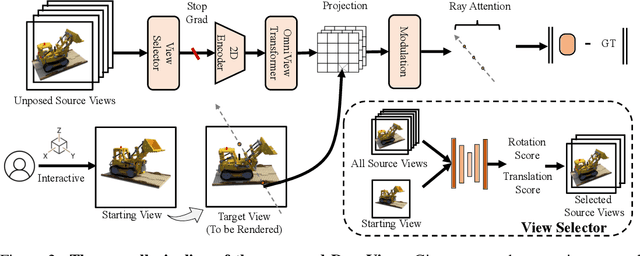
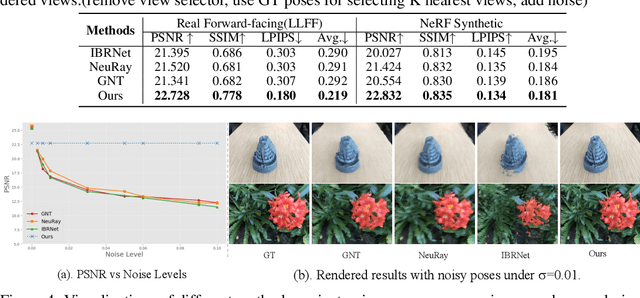
We introduce DragView, a novel and interactive framework for generating novel views of unseen scenes. DragView initializes the new view from a single source image, and the rendering is supported by a sparse set of unposed multi-view images, all seamlessly executed within a single feed-forward pass. Our approach begins with users dragging a source view through a local relative coordinate system. Pixel-aligned features are obtained by projecting the sampled 3D points along the target ray onto the source view. We then incorporate a view-dependent modulation layer to effectively handle occlusion during the projection. Additionally, we broaden the epipolar attention mechanism to encompass all source pixels, facilitating the aggregation of initialized coordinate-aligned point features from other unposed views. Finally, we employ another transformer to decode ray features into final pixel intensities. Crucially, our framework does not rely on either 2D prior models or the explicit estimation of camera poses. During testing, DragView showcases the capability to generalize to new scenes unseen during training, also utilizing only unposed support images, enabling the generation of photo-realistic new views characterized by flexible camera trajectories. In our experiments, we conduct a comprehensive comparison of the performance of DragView with recent scene representation networks operating under pose-free conditions, as well as with generalizable NeRFs subject to noisy test camera poses. DragView consistently demonstrates its superior performance in view synthesis quality, while also being more user-friendly. Project page: https://zhiwenfan.github.io/DragView/.
OceanChat: Piloting Autonomous Underwater Vehicles in Natural Language
Sep 27, 2023
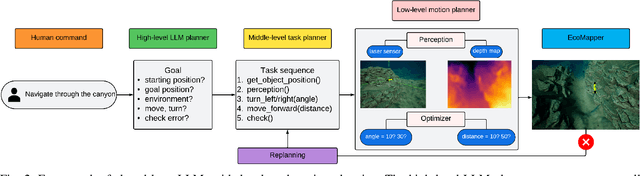


In the trending research of fusing Large Language Models (LLMs) and robotics, we aim to pave the way for innovative development of AI systems that can enable Autonomous Underwater Vehicles (AUVs) to seamlessly interact with humans in an intuitive manner. We propose OceanChat, a system that leverages a closed-loop LLM-guided task and motion planning framework to tackle AUV missions in the wild. LLMs translate an abstract human command into a high-level goal, while a task planner further grounds the goal into a task sequence with logical constraints. To assist the AUV with understanding the task sequence, we utilize a motion planner to incorporate real-time Lagrangian data streams received by the AUV, thus mapping the task sequence into an executable motion plan. Considering the highly dynamic and partially known nature of the underwater environment, an event-triggered replanning scheme is developed to enhance the system's robustness towards uncertainty. We also build a simulation platform HoloEco that generates photo-realistic simulation for a wide range of AUV applications. Experimental evaluation verifies that the proposed system can achieve improved performance in terms of both success rate and computation time. Project website: \url{https://sites.google.com/view/oceanchat}