 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
State of the Art on Neural Rendering
Apr 08, 2020
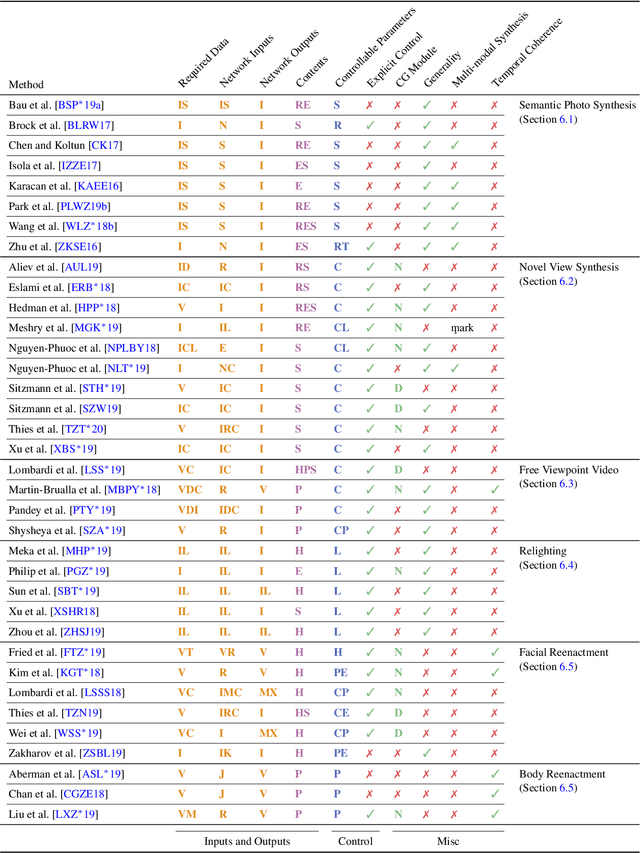



Efficient rendering of photo-realistic virtual worlds is a long standing effort of computer graphics. Modern graphics techniques have succeeded in synthesizing photo-realistic images from hand-crafted scene representations. However, the automatic generation of shape, materials, lighting, and other aspects of scenes remains a challenging problem that, if solved, would make photo-realistic computer graphics more widely accessible. Concurrently, progress in computer vision and machine learning have given rise to a new approach to image synthesis and editing, namely deep generative models. Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. With a plethora of applications in computer graphics and vision, neural rendering is poised to become a new area in the graphics community, yet no survey of this emerging field exists. This state-of-the-art report summarizes the recent trends and applications of neural rendering. We focus on approaches that combine classic computer graphics techniques with deep generative models to obtain controllable and photo-realistic outputs. Starting with an overview of the underlying computer graphics and machine learning concepts, we discuss critical aspects of neural rendering approaches. This state-of-the-art report is focused on the many important use cases for the described algorithms such as novel view synthesis, semantic photo manipulation, facial and body reenactment, relighting, free-viewpoint video, and the creation of photo-realistic avatars for virtual and augmented reality telepresence. Finally, we conclude with a discussion of the social implications of such technology and investigate open research problems.
Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis Learning
Nov 20, 2021
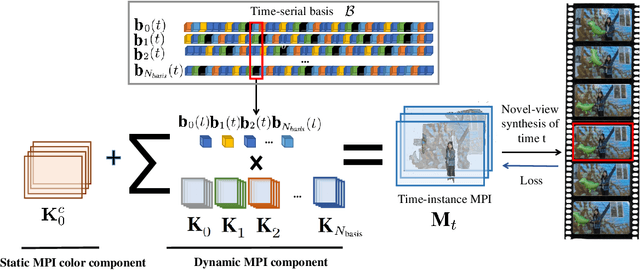

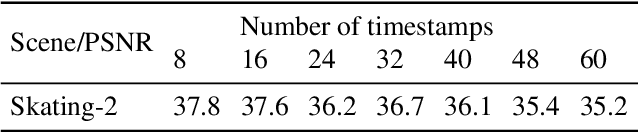
Novel view synthesis of static scenes has achieved remarkable advancements in producing photo-realistic results. However, key challenges remain for immersive rendering for dynamic contents. For example, one of the seminal image-based rendering frameworks, the multi-plane image (MPI) produces high novel-view synthesis quality for static scenes but faces difficulty in modeling dynamic parts. In addition, modeling dynamic variations through MPI may require huge storage space and long inference time, which hinders its application in real-time scenarios. In this paper, we propose a novel Temporal-MPI representation which is able to encode the rich 3D and dynamic variation information throughout the entire video as compact temporal basis. Novel-views at arbitrary time-instance will be able to be rendered real-time with high visual quality due to the highly compact and expressive latent basis and the coefficients jointly learned. We show that given comparable memory consumption, our proposed Temporal-MPI framework is able to generate a time-instance MPI with only 0.002 seconds, which is up to 3000 times faster, with 3dB higher average view-synthesis PSNR as compared with other state-of-the-art dynamic scene modelling frameworks.
Bridging Unpaired Facial Photos And Sketches By Line-drawings
Feb 01, 2021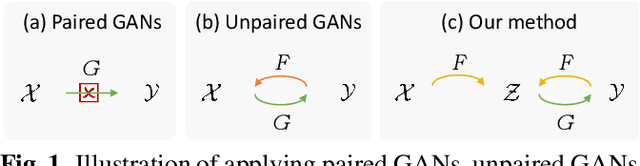
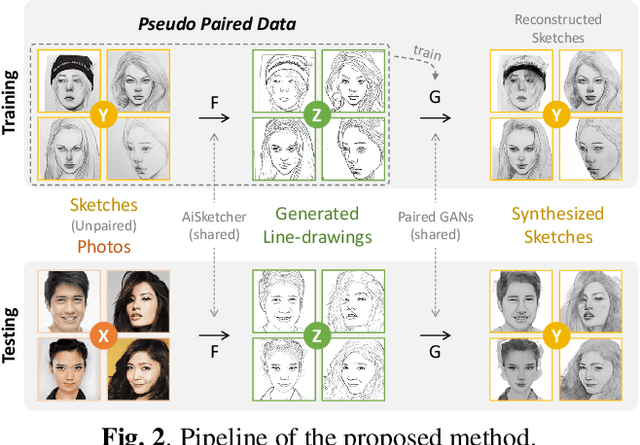
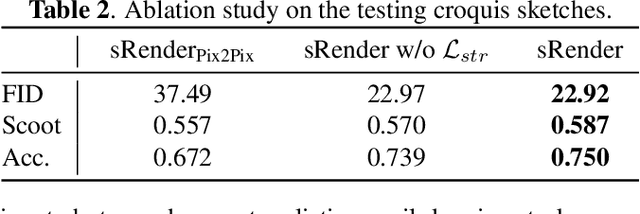
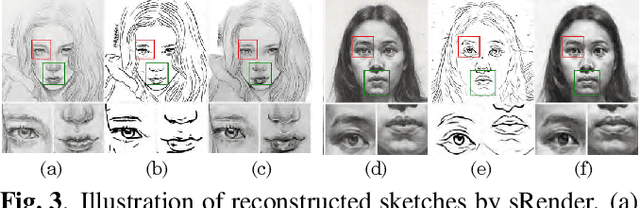
In this paper, we propose a novel method to learn face sketch synthesis models by using unpaired data. Our main idea is bridging the photo domain $\mathcal{X}$ and the sketch domain $Y$ by using the line-drawing domain $\mathcal{Z}$. Specially, we map both photos and sketches to line-drawings by using a neural style transfer method, i.e. $F: \mathcal{X}/\mathcal{Y} \mapsto \mathcal{Z}$. Consequently, we obtain \textit{pseudo paired data} $(\mathcal{Z}, \mathcal{Y})$, and can learn the mapping $G:\mathcal{Z} \mapsto \mathcal{Y}$ in a supervised learning manner. In the inference stage, given a facial photo, we can first transfer it to a line-drawing and then to a sketch by $G \circ F$. Additionally, we propose a novel stroke loss for generating different types of strokes. Our method, termed sRender, accords well with human artists' rendering process. Experimental results demonstrate that sRender can generate multi-style sketches, and significantly outperforms existing unpaired image-to-image translation methods.
Learning Flow-based Feature Warping for Face Frontalization with Illumination Inconsistent Supervision
Sep 09, 2020
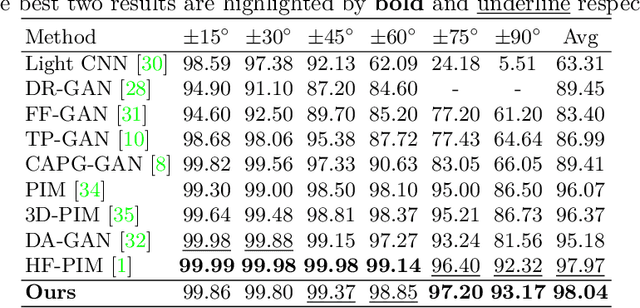
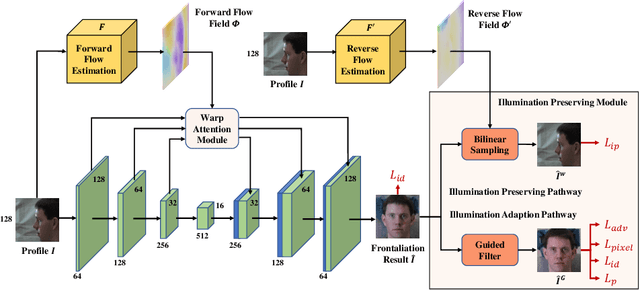

Despite recent advances in deep learning-based face frontalization methods, photo-realistic and illumination preserving frontal face synthesis is still challenging due to large pose and illumination discrepancy during training. We propose a novel Flow-based Feature Warping Model (FFWM) which can learn to synthesize photo-realistic and illumination preserving frontal images with illumination inconsistent supervision. Specifically, an Illumination Preserving Module (IPM) is proposed to learn illumination preserving image synthesis from illumination inconsistent image pairs. IPM includes two pathways which collaborate to ensure the synthesized frontal images are illumination preserving and with fine details. Moreover, a Warp Attention Module (WAM) is introduced to reduce the pose discrepancy in the feature level, and hence to synthesize frontal images more effectively and preserve more details of profile images. The attention mechanism in WAM helps reduce the artifacts caused by the displacements between the profile and the frontal images. Quantitative and qualitative experimental results show that our FFWM can synthesize photo-realistic and illumination preserving frontal images and performs favorably against the state-of-the-art results.
Low dosage 3D volume fluorescence microscopy imaging using compressive sensing
Jan 03, 2022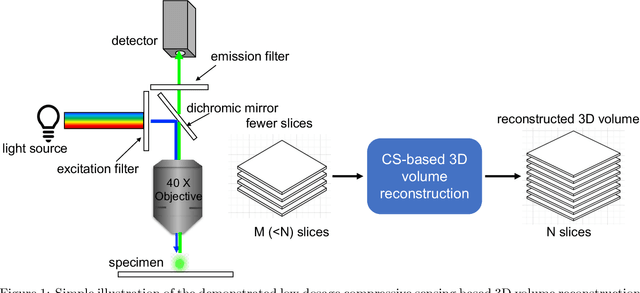
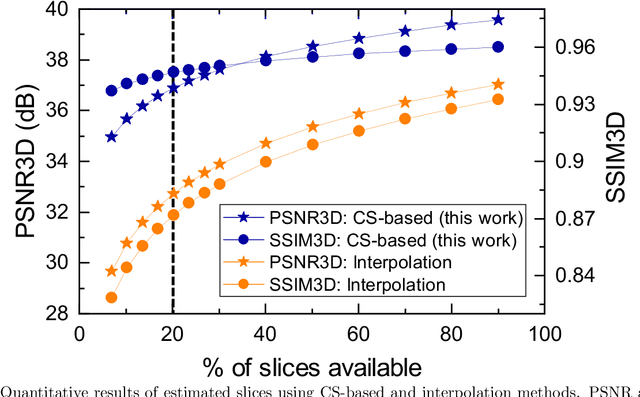

Fluorescence microscopy has been a significant tool to observe long-term imaging of embryos (in vivo) growth over time. However, cumulative exposure is phototoxic to such sensitive live samples. While techniques like light-sheet fluorescence microscopy (LSFM) allow for reduced exposure, it is not well suited for deep imaging models. Other computational techniques are computationally expensive and often lack restoration quality. To address this challenge, one can use various low-dosage imaging techniques that are developed to achieve the 3D volume reconstruction using a few slices in the axial direction (z-axis); however, they often lack restoration quality. Also, acquiring dense images (with small steps) in the axial direction is computationally expensive. To address this challenge, we present a compressive sensing (CS) based approach to fully reconstruct 3D volumes with the same signal-to-noise ratio (SNR) with less than half of the excitation dosage. We present the theory and experimentally validate the approach. To demonstrate our technique, we capture a 3D volume of the RFP labeled neurons in the zebrafish embryo spinal cord (30um thickness) with the axial sampling of 0.1um using a confocal microscope. From the results, we observe the CS-based approach achieves accurate 3D volume reconstruction from less than 20% of the entire stack optical sections. The developed CS-based methodology in this work can be easily applied to other deep imaging modalities such as two-photon and light-sheet microscopy, where reducing sample photo-toxicity is a critical challenge.
Learning Actions for Drift-Free Navigation in Highly Dynamic Scenes
Oct 28, 2021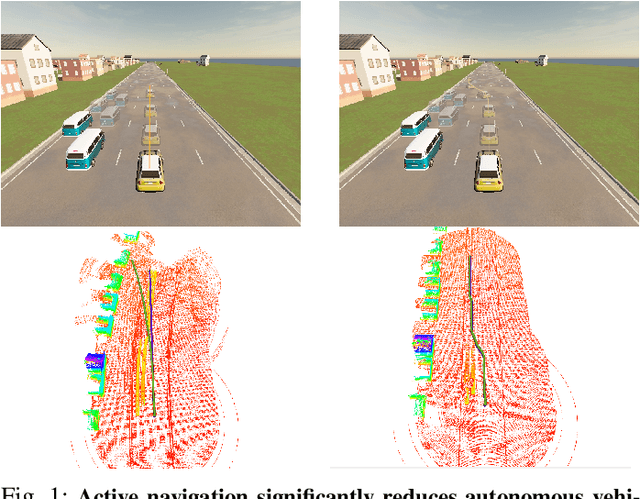
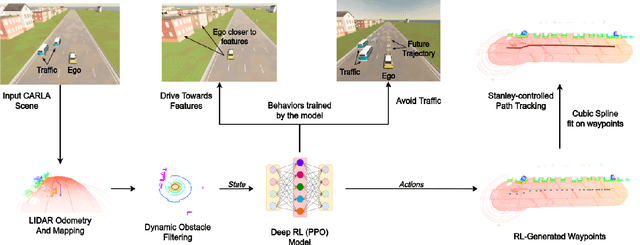
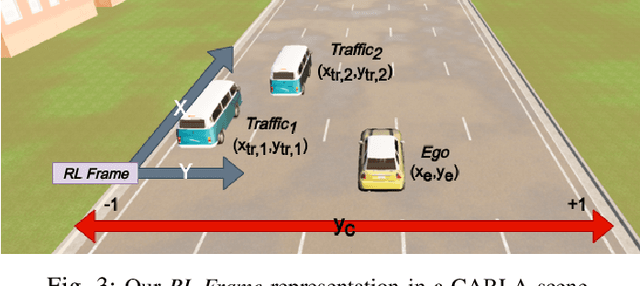
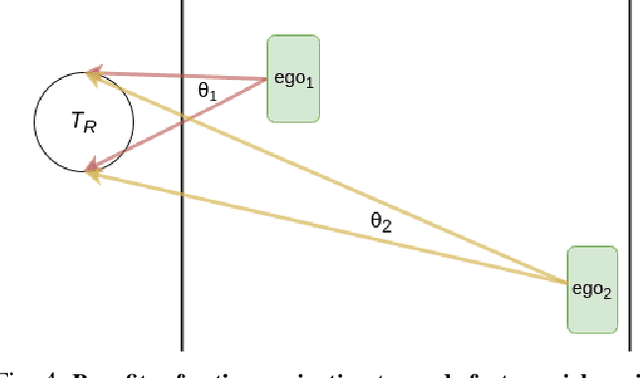
We embark on a hitherto unreported problem of an autonomous robot (self-driving car) navigating in dynamic scenes in a manner that reduces its localization error and eventual cumulative drift or Absolute Trajectory Error, which is pronounced in such dynamic scenes. With the hugely popular Velodyne-16 3D LIDAR as the main sensing modality, and the accurate LIDAR-based Localization and Mapping algorithm, LOAM, as the state estimation framework, we show that in the absence of a navigation policy, drift rapidly accumulates in the presence of moving objects. To overcome this, we learn actions that lead to drift-minimized navigation through a suitable set of reward and penalty functions. We use Proximal Policy Optimization, a class of Deep Reinforcement Learning methods, to learn the actions that result in drift-minimized trajectories. We show by extensive comparisons on a variety of synthetic, yet photo-realistic scenes made available through the CARLA Simulator the superior performance of the proposed framework vis-a-vis methods that do not adopt such policies.
Seuillage par hystérésis pour le test de photo-consistance des voxels dans le cadre de la reconstruction 3D
Sep 17, 2018
Voxel coloring is a popular method of reconstructing a three-dimensional surface model from a set of calibrated 2D images. However, the reconstruction quality is largely dependent on a thresholding procedure allowing the authors to decide, for each voxel, whether it is photo-consistent or not. Even so, this method is widely used because of its simplicity and low computational cost. We have returned to this method in order to propose an improvement in the thresholding step which will be fully automated. Indeed, the geometrical information is implicitly integrated using an hysteresis thresholding which takes into account the spatial coherence of color voxels. Moreover, the ambiguity of choosing the thresholds is extremely minimized by defining a fuzzy degree of membership of each voxel into the class of consistent voxels. Also, there is no need for preset thresholds since the hysteresis ones are defined automatically and adaptively depending on the number of images that the voxel isprojected onto. Preliminary results are very promising and demonstrate that the proposed method performs automatically precise and smooth volumetric scene reconstruction.
Sim2Real Docs: Domain Randomization for Documents in Natural Scenes using Ray-traced Rendering
Dec 16, 2021

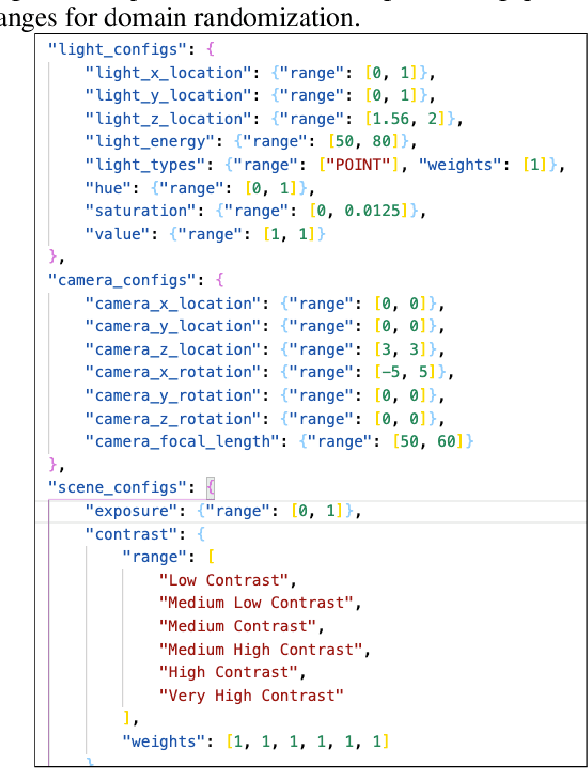
In the past, computer vision systems for digitized documents could rely on systematically captured, high-quality scans. Today, transactions involving digital documents are more likely to start as mobile phone photo uploads taken by non-professionals. As such, computer vision for document automation must now account for documents captured in natural scene contexts. An additional challenge is that task objectives for document processing can be highly use-case specific, which makes publicly-available datasets limited in their utility, while manual data labeling is also costly and poorly translates between use cases. To address these issues we created Sim2Real Docs - a framework for synthesizing datasets and performing domain randomization of documents in natural scenes. Sim2Real Docs enables programmatic 3D rendering of documents using Blender, an open source tool for 3D modeling and ray-traced rendering. By using rendering that simulates physical interactions of light, geometry, camera, and background, we synthesize datasets of documents in a natural scene context. Each render is paired with use-case specific ground truth data specifying latent characteristics of interest, producing unlimited fit-for-task training data. The role of machine learning models is then to solve the inverse problem posed by the rendering pipeline. Such models can be further iterated upon with real-world data by either fine tuning or making adjustments to domain randomization parameters.
A Generative Adversarial Approach with Residual Learning for Dust and Scratches Artifacts Removal
Sep 22, 2020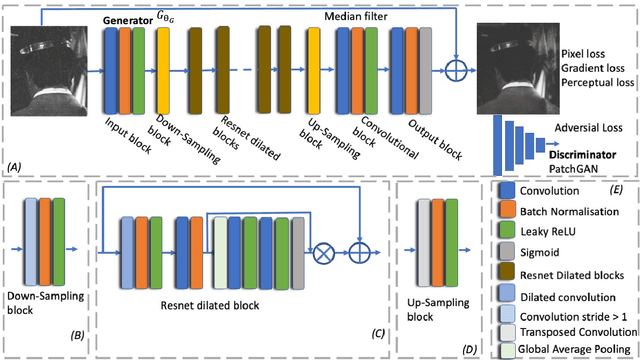
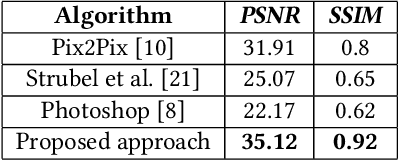


Retouching can significantly elevate the visual appeal of photos, but many casual photographers lack the expertise to operate in a professional manner. One particularly challenging task for old photo retouching remains the removal of dust and scratches artifacts. Traditionally, this task has been completed manually with special image enhancement software and represents a tedious task that requires special know-how of photo editing applications. However, recent research utilizing Generative Adversarial Networks (GANs) has been proven to obtain good results in various automated image enhancement tasks compared to traditional methods. This motivated us to explore the use of GANs in the context of film photo editing. In this paper, we present a GAN based method that is able to remove dust and scratches errors from film scans. Specifically, residual learning is utilized to speed up the training process, as well as boost the denoising performance. An extensive evaluation of our model on a community provided dataset shows that it generalizes remarkably well, not being dependent on any particular type of image. Finally, we significantly outperform the state-of-the-art methods and software applications, providing superior results.
Adaptive Multi-layer Contrastive Graph Neural Networks
Sep 29, 2021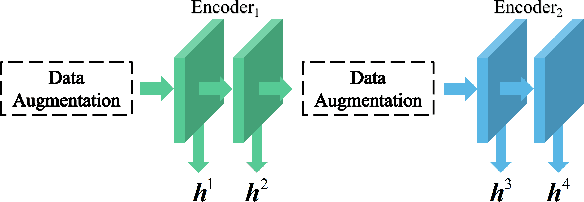
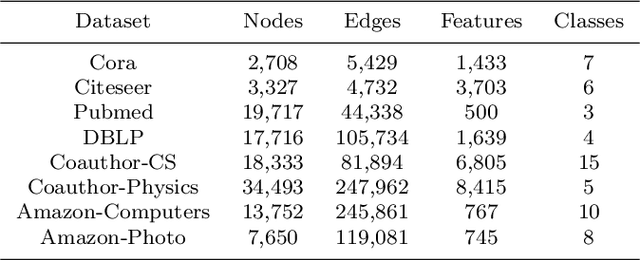
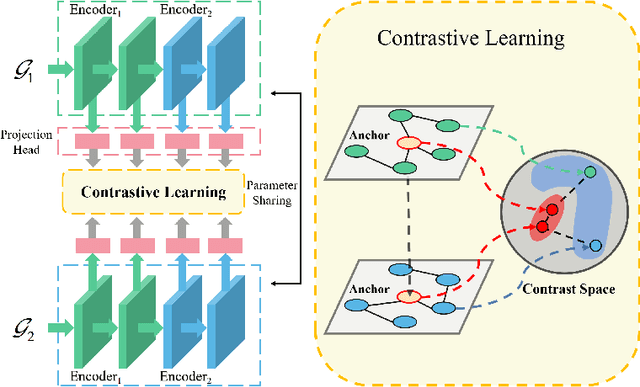
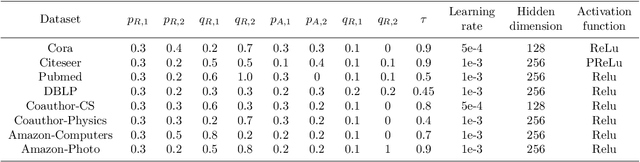
We present Adaptive Multi-layer Contrastive Graph Neural Networks (AMC-GNN), a self-supervised learning framework for Graph Neural Network, which learns feature representations of sample data without data labels. AMC-GNN generates two graph views by data augmentation and compares different layers' output embeddings of Graph Neural Network encoders to obtain feature representations, which could be used for downstream tasks. AMC-GNN could learn the importance weights of embeddings in different layers adaptively through the attention mechanism, and an auxiliary encoder is introduced to train graph contrastive encoders better. The accuracy is improved by maximizing the representation's consistency of positive pairs in the early layers and the final embedding space. Our experiments show that the results can be consistently improved by using the AMC-GNN framework, across four established graph benchmarks: Cora, Citeseer, Pubmed, DBLP citation network datasets, as well as four newly proposed datasets: Co-author-CS, Co-author-Physics, Amazon-Computers, Amazon-Photo.