 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Guided Facial Skin Color Correction
May 19, 2021
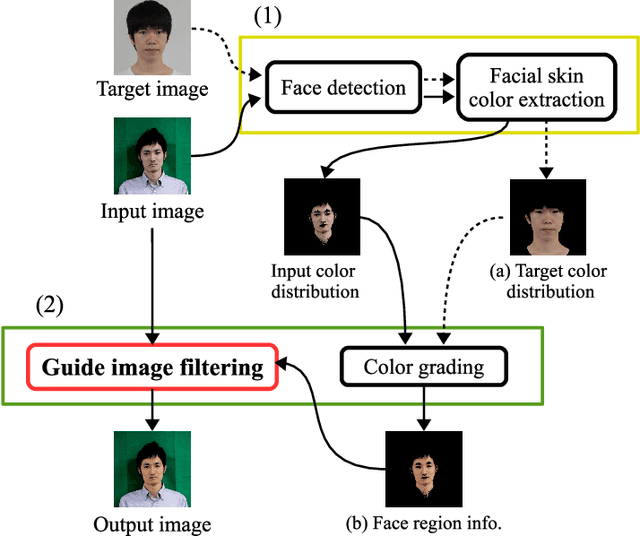

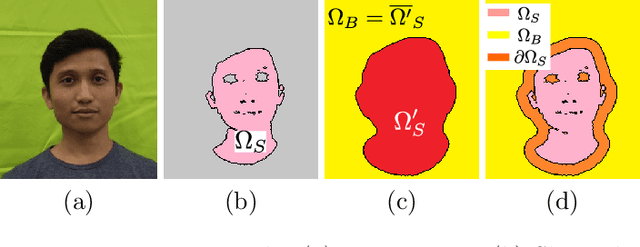

This paper proposes an automatic image correction method for portrait photographs, which promotes consistency of facial skin color by suppressing skin color changes due to background colors. In portrait photographs, skin color is often distorted due to the lighting environment (e.g., light reflected from a colored background wall and over-exposure by a camera strobe), and if the photo is artificially combined with another background color, this color change is emphasized, resulting in an unnatural synthesized result. In our framework, after roughly extracting the face region and rectifying the skin color distribution in a color space, we perform color and brightness correction around the face in the original image to achieve a proper color balance of the facial image, which is not affected by luminance and background colors. Unlike conventional algorithms for color correction, our final result is attained by a color correction process with a guide image. In particular, our guided image filtering for the color correction does not require a perfectly-aligned guide image required in the original guide image filtering method proposed by He et al. Experimental results show that our method generates more natural results than conventional methods on not only headshot photographs but also natural scene photographs. We also show automatic yearbook style photo generation as an another application.
CAISE: Conversational Agent for Image Search and Editing
Feb 24, 2022
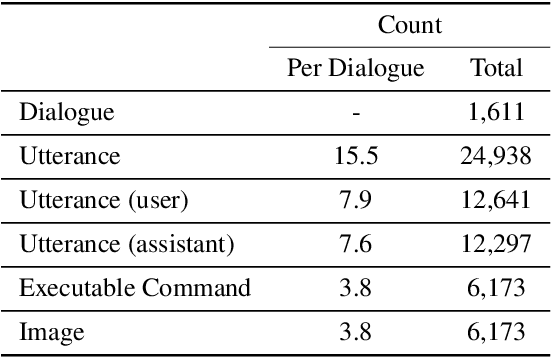

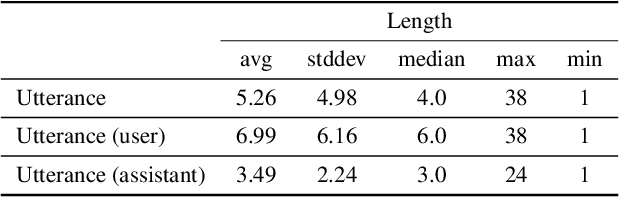
Demand for image editing has been increasing as users' desire for expression is also increasing. However, for most users, image editing tools are not easy to use since the tools require certain expertise in photo effects and have complex interfaces. Hence, users might need someone to help edit their images, but having a personal dedicated human assistant for every user is impossible to scale. For that reason, an automated assistant system for image editing is desirable. Additionally, users want more image sources for diverse image editing works, and integrating an image search functionality into the editing tool is a potential remedy for this demand. Thus, we propose a dataset of an automated Conversational Agent for Image Search and Editing (CAISE). To our knowledge, this is the first dataset that provides conversational image search and editing annotations, where the agent holds a grounded conversation with users and helps them to search and edit images according to their requests. To build such a system, we first collect image search and editing conversations between pairs of annotators. The assistant-annotators are equipped with a customized image search and editing tool to address the requests from the user-annotators. The functions that the assistant-annotators conduct with the tool are recorded as executable commands, allowing the trained system to be useful for real-world application execution. We also introduce a generator-extractor baseline model for this task, which can adaptively select the source of the next token (i.e., from the vocabulary or from textual/visual contexts) for the executable command. This serves as a strong starting point while still leaving a large human-machine performance gap for useful future work. Our code and dataset are publicly available at: https://github.com/hyounghk/CAISE
Bridging Unpaired Facial Photos And Sketches By Line-drawings
Feb 25, 2021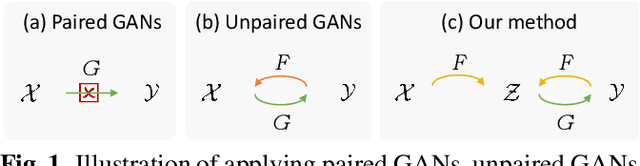
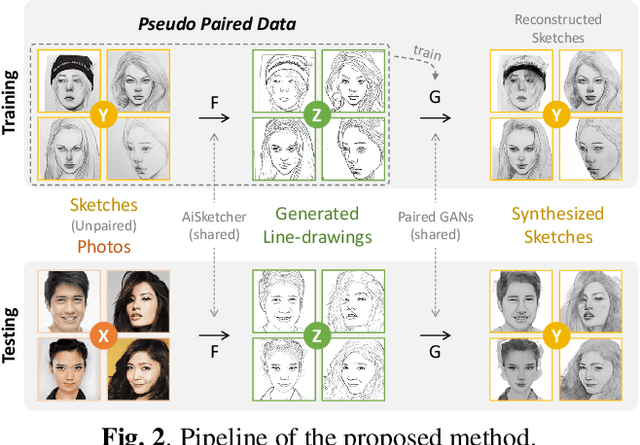
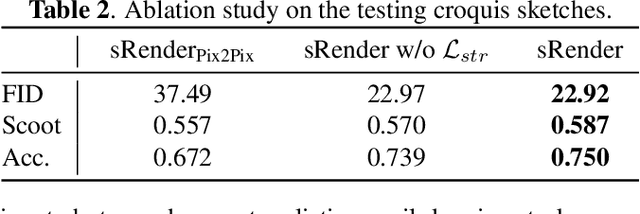
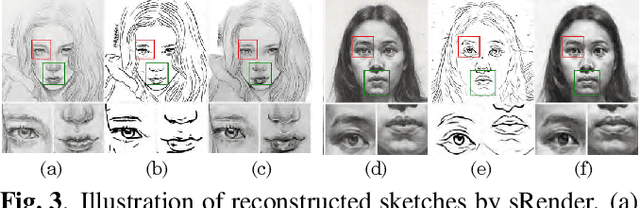
In this paper, we propose a novel method to learn face sketch synthesis models by using unpaired data. Our main idea is bridging the photo domain $\mathcal{X}$ and the sketch domain $Y$ by using the line-drawing domain $\mathcal{Z}$. Specially, we map both photos and sketches to line-drawings by using a neural style transfer method, i.e. $F: \mathcal{X}/\mathcal{Y} \mapsto \mathcal{Z}$. Consequently, we obtain \textit{pseudo paired data} $(\mathcal{Z}, \mathcal{Y})$, and can learn the mapping $G:\mathcal{Z} \mapsto \mathcal{Y}$ in a supervised learning manner. In the inference stage, given a facial photo, we can first transfer it to a line-drawing and then to a sketch by $G \circ F$. Additionally, we propose a novel stroke loss for generating different types of strokes. Our method, termed sRender, accords well with human artists' rendering process. Experimental results demonstrate that sRender can generate multi-style sketches, and significantly outperforms existing unpaired image-to-image translation methods.
NeurSF: Neural Shading Field for Image Harmonization
Dec 04, 2021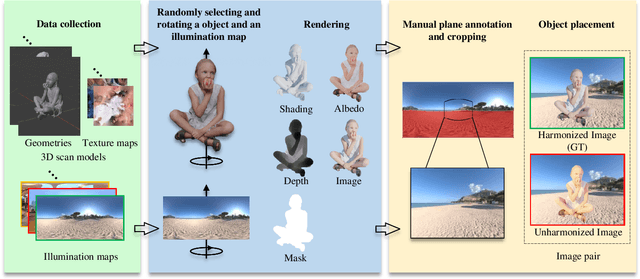

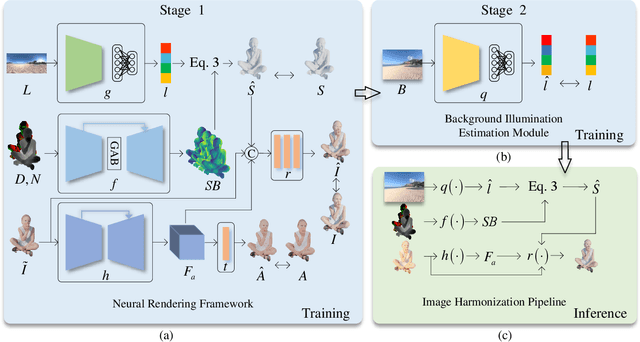
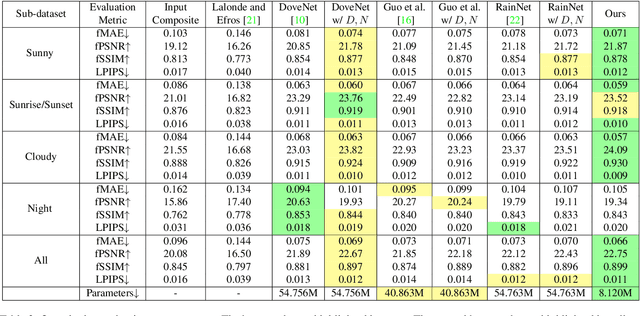
Image harmonization aims at adjusting the appearance of the foreground to make it more compatible with the background. Due to a lack of understanding of the background illumination direction, existing works are incapable of generating a realistic foreground shading. In this paper, we decompose the image harmonization into two sub-problems: 1) illumination estimation of background images and 2) rendering of foreground objects. Before solving these two sub-problems, we first learn a direction-aware illumination descriptor via a neural rendering framework, of which the key is a Shading Module that decomposes the shading field into multiple shading components given depth information. Then we design a Background Illumination Estimation Module to extract the direction-aware illumination descriptor from the background. Finally, the illumination descriptor is used in conjunction with the neural rendering framework to generate the harmonized foreground image containing a novel harmonized shading. Moreover, we construct a photo-realistic synthetic image harmonization dataset that contains numerous shading variations by image-based lighting. Extensive experiments on this dataset demonstrate the effectiveness of the proposed method. Our dataset and code will be made publicly available.
Neural Point Light Fields
Dec 02, 2021


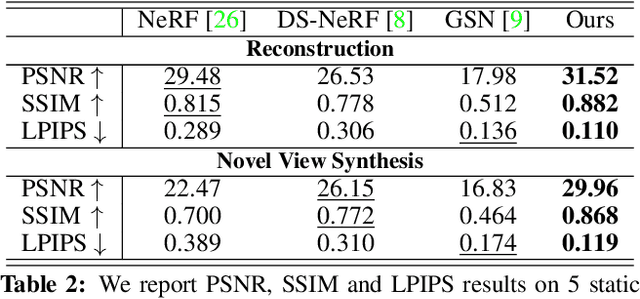
We introduce Neural Point Light Fields that represent scenes implicitly with a light field living on a sparse point cloud. Combining differentiable volume rendering with learned implicit density representations has made it possible to synthesize photo-realistic images for novel views of small scenes. As neural volumetric rendering methods require dense sampling of the underlying functional scene representation, at hundreds of samples along a ray cast through the volume, they are fundamentally limited to small scenes with the same objects projected to hundreds of training views. Promoting sparse point clouds to neural implicit light fields allows us to represent large scenes effectively with only a single implicit sampling operation per ray. These point light fields are as a function of the ray direction, and local point feature neighborhood, allowing us to interpolate the light field conditioned training images without dense object coverage and parallax. We assess the proposed method for novel view synthesis on large driving scenarios, where we synthesize realistic unseen views that existing implicit approaches fail to represent. We validate that Neural Point Light Fields make it possible to predict videos along unseen trajectories previously only feasible to generate by explicitly modeling the scene.
NeSF: Neural Shading Field for Image Harmonization
Dec 02, 2021Image harmonization aims at adjusting the appearance of the foreground to make it more compatible with the background. Due to a lack of understanding of the background illumination direction, existing works are incapable of generating a realistic foreground shading. In this paper, we decompose the image harmonization into two sub-problems: 1) illumination estimation of background images and 2) rendering of foreground objects. Before solving these two sub-problems, we first learn a direction-aware illumination descriptor via a neural rendering framework, of which the key is a Shading Module that decomposes the shading field into multiple shading components given depth information. Then we design a Background Illumination Estimation Module to extract the direction-aware illumination descriptor from the background. Finally, the illumination descriptor is used in conjunction with the neural rendering framework to generate the harmonized foreground image containing a novel harmonized shading. Moreover, we construct a photo-realistic synthetic image harmonization dataset that contains numerous shading variations by image-based lighting. Extensive experiments on this dataset demonstrate the effectiveness of the proposed method. Our dataset and code will be made publicly available.
Unconstrained Face Sketch Synthesis via Perception-Adaptive Network and A New Benchmark
Dec 02, 2021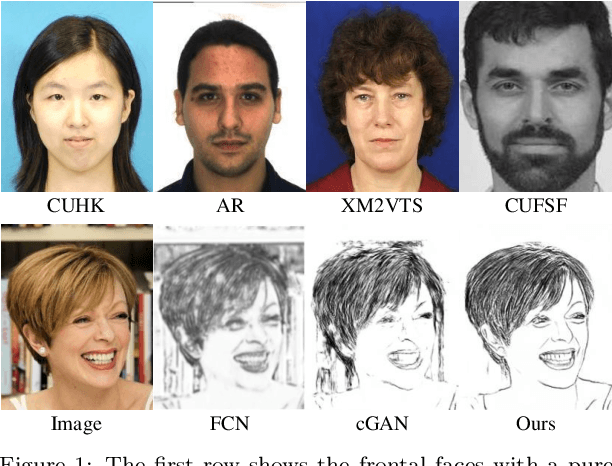
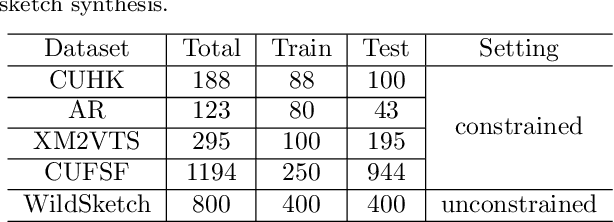

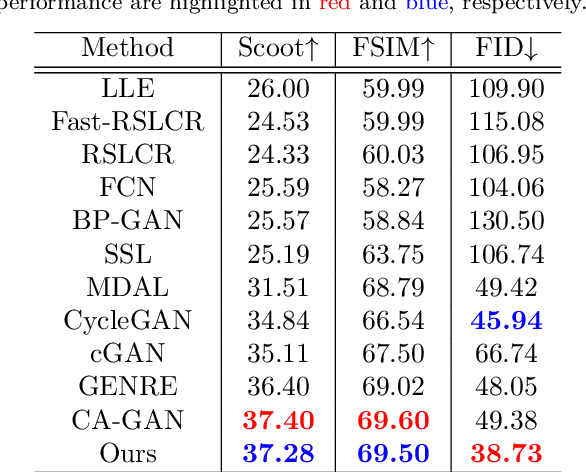
Face sketch generation has attracted much attention in the field of visual computing. However, existing methods either are limited to constrained conditions or heavily rely on various preprocessing steps to deal with in-the-wild cases. In this paper, we argue that accurately perceiving facial region and facial components is crucial for unconstrained sketch synthesis. To this end, we propose a novel Perception-Adaptive Network (PANet), which can generate high-quality face sketches under unconstrained conditions in an end-to-end scheme. Specifically, our PANet is composed of i) a Fully Convolutional Encoder for hierarchical feature extraction, ii) a Face-Adaptive Perceiving Decoder for extracting potential facial region and handling face variations, and iii) a Component-Adaptive Perceiving Module for facial component aware feature representation learning. To facilitate further researches of unconstrained face sketch synthesis, we introduce a new benchmark termed WildSketch, which contains 800 pairs of face photo-sketch with large variations in pose, expression, ethnic origin, background, and illumination. Extensive experiments demonstrate that the proposed method is capable of achieving state-of-the-art performance under both constrained and unconstrained conditions. Our source codes and the WildSketch benchmark are resealed on the project page http://lingboliu.com/unconstrained_face_sketch.html.
GIF: Generative Interpretable Faces
Aug 31, 2020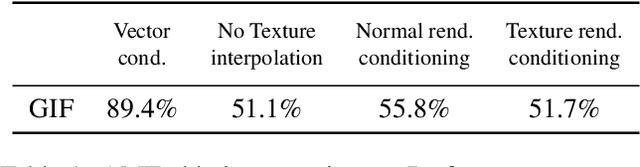
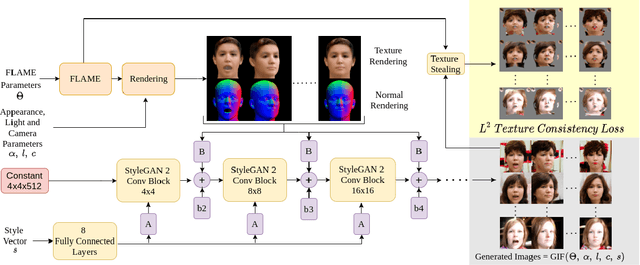
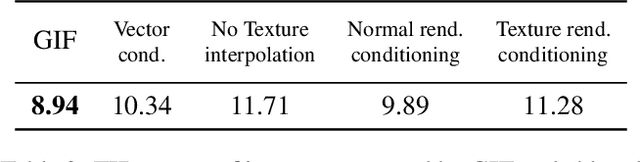

Photo-realistic visualization and animation of expressive human faces have been a long standing challenge. On one end of the spectrum, 3D face modeling methods provide parametric control but tend to generate unrealistic images, while on the other end, generative 2D models like GANs (Generative Adversarial Networks) output photo-realistic face images, but lack explicit control. Recent methods gain partial control, either by attempting to disentangle different factors in an unsupervised manner, or by adding control post hoc to a pre-trained model. Trained GANs without pre-defined control, however, may entangle factors that are hard to undo later. To guarantee some disentanglement that provides us with desired kinds of control, we train our generative model conditioned on pre-defined control parameters. Specifically, we condition StyleGAN2 on FLAME, a generative 3D face model. However, we found out that a naive conditioning on FLAME parameters yields rather unsatisfactory results. Instead we render out geometry and photo-metric details of the FLAME mesh and use these for conditioning instead. This gives us a generative 2D face model named GIF (Generative Interpretable Faces) that shares FLAME's parametric control. Given FLAME parameters for shape, pose, and expressions, parameters for appearance and lighting, and an additional style vector, GIF outputs photo-realistic face images. To evaluate how well GIF follows its conditioning and the impact of different design choices, we perform a perceptual study. The code and trained model are publicly available for research purposes at https://github.com/ParthaEth/GIF.
Cluster-guided Image Synthesis with Unconditional Models
Dec 24, 2021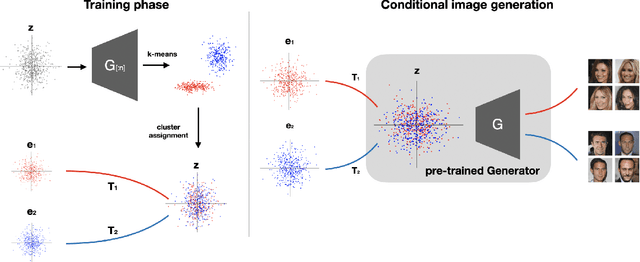
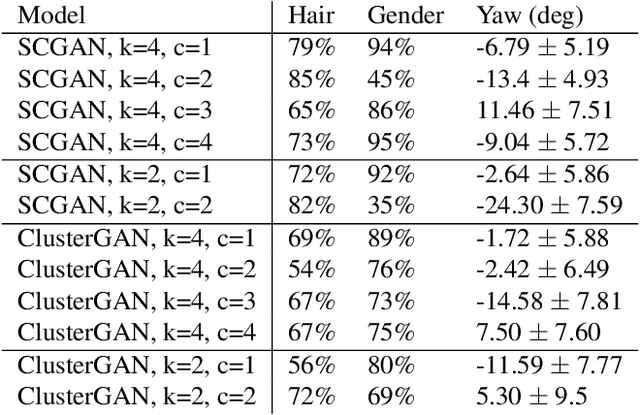

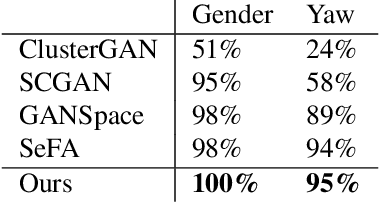
Generative Adversarial Networks (GANs) are the driving force behind the state-of-the-art in image generation. Despite their ability to synthesize high-resolution photo-realistic images, generating content with on-demand conditioning of different granularity remains a challenge. This challenge is usually tackled by annotating massive datasets with the attributes of interest, a laborious task that is not always a viable option. Therefore, it is vital to introduce control into the generation process of unsupervised generative models. In this work, we focus on controllable image generation by leveraging GANs that are well-trained in an unsupervised fashion. To this end, we discover that the representation space of intermediate layers of the generator forms a number of clusters that separate the data according to semantically meaningful attributes (e.g., hair color and pose). By conditioning on the cluster assignments, the proposed method is able to control the semantic class of the generated image. Our approach enables sampling from each cluster by Implicit Maximum Likelihood Estimation (IMLE). We showcase the efficacy of our approach on faces (CelebA-HQ and FFHQ), animals (Imagenet) and objects (LSUN) using different pre-trained generative models. The results highlight the ability of our approach to condition image generation on attributes like gender, pose and hair style on faces, as well as a variety of features on different object classes.