 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
SpaceEdit: Learning a Unified Editing Space for Open-Domain Image Editing
Nov 30, 2021
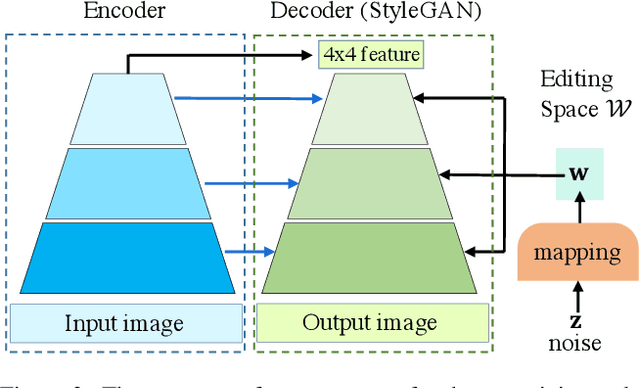
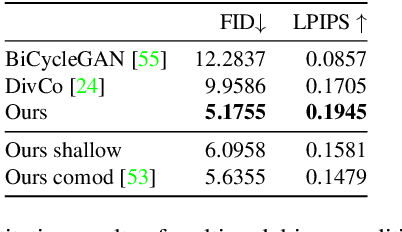


Recently, large pretrained models (e.g., BERT, StyleGAN, CLIP) have shown great knowledge transfer and generalization capability on various downstream tasks within their domains. Inspired by these efforts, in this paper we propose a unified model for open-domain image editing focusing on color and tone adjustment of open-domain images while keeping their original content and structure. Our model learns a unified editing space that is more semantic, intuitive, and easy to manipulate than the operation space (e.g., contrast, brightness, color curve) used in many existing photo editing softwares. Our model belongs to the image-to-image translation framework which consists of an image encoder and decoder, and is trained on pairs of before- and after-images to produce multimodal outputs. We show that by inverting image pairs into latent codes of the learned editing space, our model can be leveraged for various downstream editing tasks such as language-guided image editing, personalized editing, editing-style clustering, retrieval, etc. We extensively study the unique properties of the editing space in experiments and demonstrate superior performance on the aforementioned tasks.
Neural Point Light Fields
Dec 17, 2021


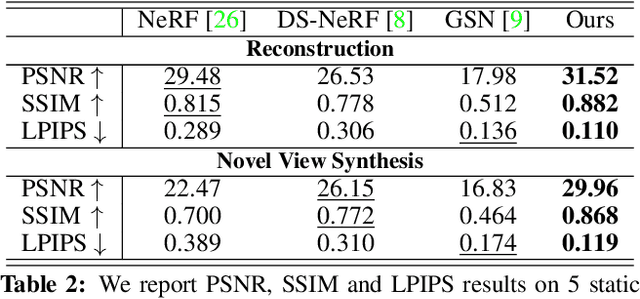
We introduce Neural Point Light Fields that represent scenes implicitly with a light field living on a sparse point cloud. Combining differentiable volume rendering with learned implicit density representations has made it possible to synthesize photo-realistic images for novel views of small scenes. As neural volumetric rendering methods require dense sampling of the underlying functional scene representation, at hundreds of samples along a ray cast through the volume, they are fundamentally limited to small scenes with the same objects projected to hundreds of training views. Promoting sparse point clouds to neural implicit light fields allows us to represent large scenes effectively with only a single implicit sampling operation per ray. These point light fields are as a function of the ray direction, and local point feature neighborhood, allowing us to interpolate the light field conditioned training images without dense object coverage and parallax. We assess the proposed method for novel view synthesis on large driving scenarios, where we synthesize realistic unseen views that existing implicit approaches fail to represent. We validate that Neural Point Light Fields make it possible to predict videos along unseen trajectories previously only feasible to generate by explicitly modeling the scene.
Camera View Adjustment Prediction for Improving Image Composition
Apr 15, 2021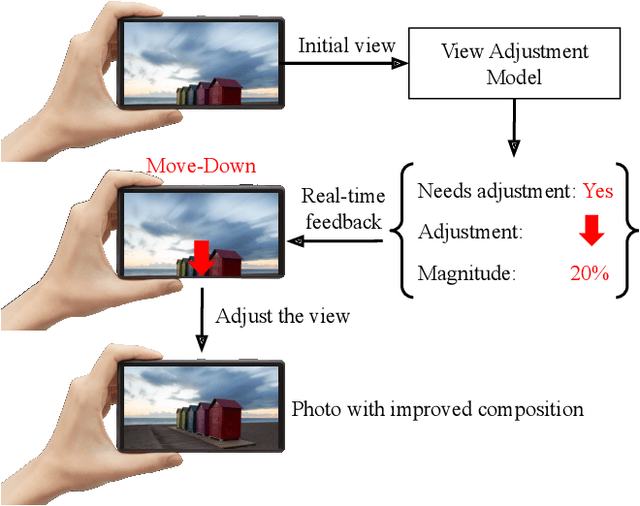
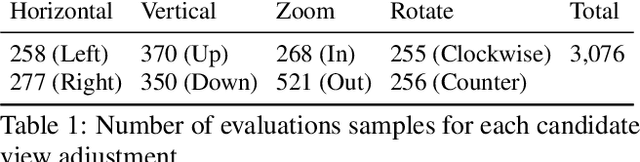


Image composition plays an important role in the quality of a photo. However, not every camera user possesses the knowledge and expertise required for capturing well-composed photos. While post-capture cropping can improve the composition sometimes, it does not work in many common scenarios in which the photographer needs to adjust the camera view to capture the best shot. To address this issue, we propose a deep learning-based approach that provides suggestions to the photographer on how to adjust the camera view before capturing. By optimizing the composition before a photo is captured, our system helps photographers to capture better photos. As there is no publicly-available dataset for this task, we create a view adjustment dataset by repurposing existing image cropping datasets. Furthermore, we propose a two-stage semi-supervised approach that utilizes both labeled and unlabeled images for training a view adjustment model. Experiment results show that the proposed semi-supervised approach outperforms the corresponding supervised alternatives, and our user study results show that the suggested view adjustment improves image composition 79% of the time.
Consistent Depth Prediction under Various Illuminations using Dilated Cross Attention
Dec 15, 2021

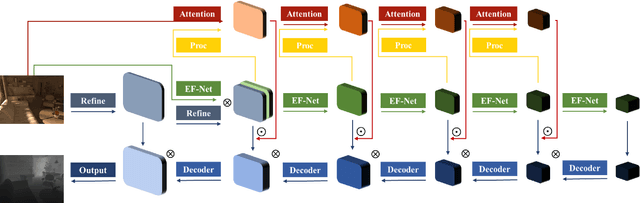
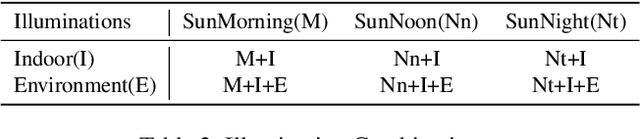
In this paper, we aim to solve the problem of consistent depth prediction in complex scenes under various illumination conditions. The existing indoor datasets based on RGB-D sensors or virtual rendering have two critical limitations - sparse depth maps (NYU Depth V2) and non-realistic illumination (SUN CG, SceneNet RGB-D). We propose to use internet 3D indoor scenes and manually tune their illuminations to render photo-realistic RGB photos and their corresponding depth and BRDF maps, obtaining a new indoor depth dataset called Vari dataset. We propose a simple convolutional block named DCA by applying depthwise separable dilated convolution on encoded features to process global information and reduce parameters. We perform cross attention on these dilated features to retain the consistency of depth prediction under different illuminations. Our method is evaluated by comparing it with current state-of-the-art methods on Vari dataset and a significant improvement is observed in our experiments. We also conduct the ablation study, finetune our model on NYU Depth V2 and also evaluate on real-world data to further validate the effectiveness of our DCA block. The code, pre-trained weights and Vari dataset are open-sourced.
Robust Egocentric Photo-realistic Facial Expression Transfer for Virtual Reality
Apr 10, 2021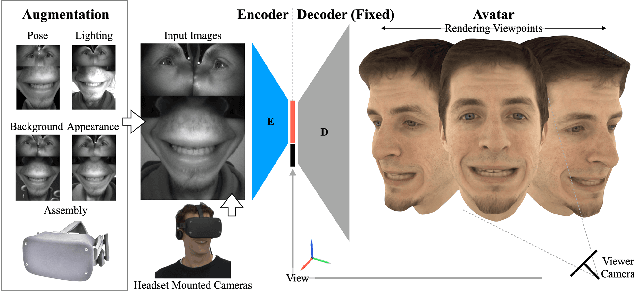
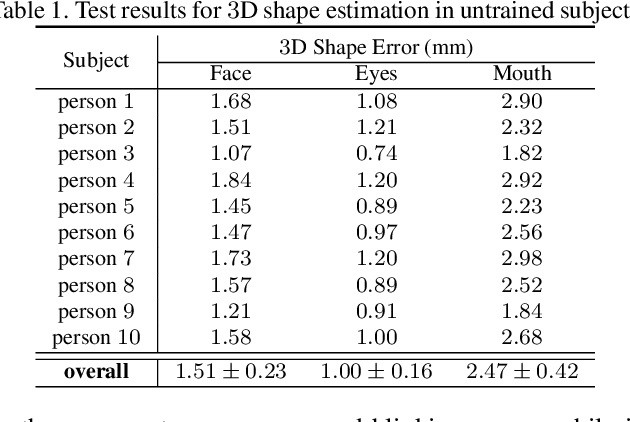

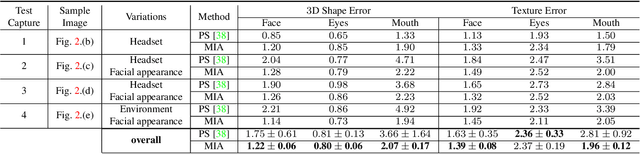
Social presence, the feeling of being there with a real person, will fuel the next generation of communication systems driven by digital humans in virtual reality (VR). The best 3D video-realistic VR avatars that minimize the uncanny effect rely on person-specific (PS) models. However, these PS models are time-consuming to build and are typically trained with limited data variability, which results in poor generalization and robustness. Major sources of variability that affects the accuracy of facial expression transfer algorithms include using different VR headsets (e.g., camera configuration, slop of the headset), facial appearance changes over time (e.g., beard, make-up), and environmental factors (e.g., lighting, backgrounds). This is a major drawback for the scalability of these models in VR. This paper makes progress in overcoming these limitations by proposing an end-to-end multi-identity architecture (MIA) trained with specialized augmentation strategies. MIA drives the shape component of the avatar from three cameras in the VR headset (two eyes, one mouth), in untrained subjects, using minimal personalized information (i.e., neutral 3D mesh shape). Similarly, if the PS texture decoder is available, MIA is able to drive the full avatar (shape+texture) robustly outperforming PS models in challenging scenarios. Our key contribution to improve robustness and generalization, is that our method implicitly decouples, in an unsupervised manner, the facial expression from nuisance factors (e.g., headset, environment, facial appearance). We demonstrate the superior performance and robustness of the proposed method versus state-of-the-art PS approaches in a variety of experiments.
Quality Metric Guided Portrait Line Drawing Generation from Unpaired Training Data
Feb 08, 2022
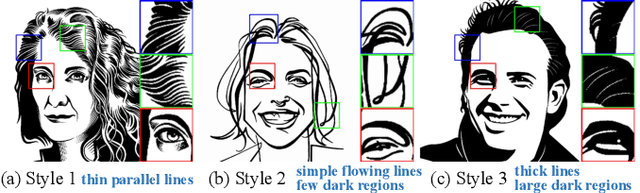
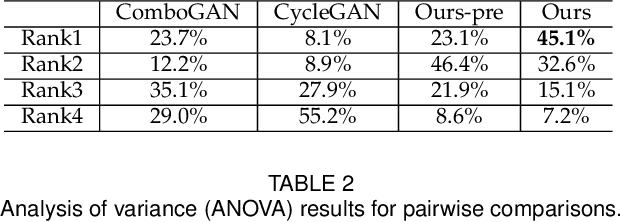

Face portrait line drawing is a unique style of art which is highly abstract and expressive. However, due to its high semantic constraints, many existing methods learn to generate portrait drawings using paired training data, which is costly and time-consuming to obtain. In this paper, we propose a novel method to automatically transform face photos to portrait drawings using unpaired training data with two new features; i.e., our method can (1) learn to generate high quality portrait drawings in multiple styles using a single network and (2) generate portrait drawings in a "new style" unseen in the training data. To achieve these benefits, we (1) propose a novel quality metric for portrait drawings which is learned from human perception, and (2) introduce a quality loss to guide the network toward generating better looking portrait drawings. We observe that existing unpaired translation methods such as CycleGAN tend to embed invisible reconstruction information indiscriminately in the whole drawings due to significant information imbalance between the photo and portrait drawing domains, which leads to important facial features missing. To address this problem, we propose a novel asymmetric cycle mapping that enforces the reconstruction information to be visible and only embedded in the selected facial regions. Along with localized discriminators for important facial regions, our method well preserves all important facial features in the generated drawings. Generator dissection further explains that our model learns to incorporate face semantic information during drawing generation. Extensive experiments including a user study show that our model outperforms state-of-the-art methods.
Unveiling Real-Life Effects of Online Photo Sharing
Dec 24, 2020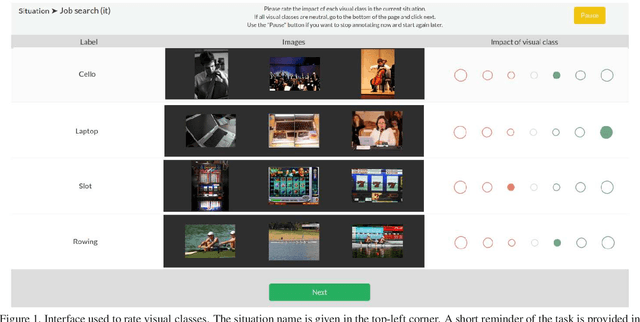

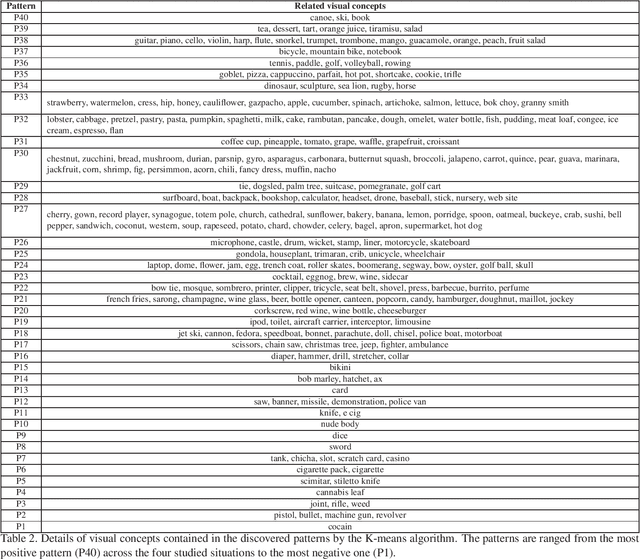
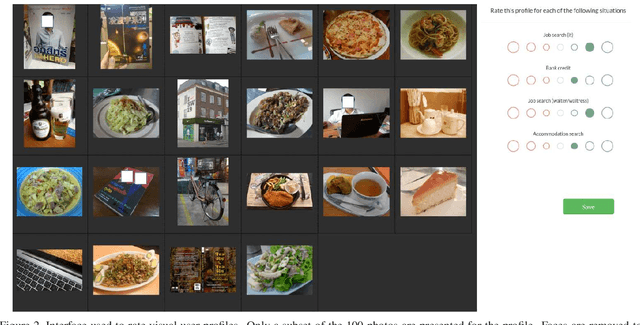
Social networks give free access to their services in exchange for the right to exploit their users' data. Data sharing is done in an initial context which is chosen by the users. However, data are used by social networks and third parties in different contexts which are often not transparent. We propose a new approach which unveils potential effects of data sharing in impactful real-life situations. Focus is put on visual content because of its strong influence in shaping online user profiles. The approach relies on three components: (1) a set of concepts with associated situation impact ratings obtained by crowdsourcing, (2) a corresponding set of object detectors used to analyze users' photos and (3) a ground truth dataset made of 500 visual user profiles which are manually rated for each situation. These components are combined in LERVUP, a method which learns to rate visual user profiles in each situation. LERVUP exploits a new image descriptor which aggregates concept ratings and object detections at user level. It also uses an attention mechanism to boost the detections of highly-rated concepts to prevent them from being overwhelmed by low-rated ones. Performance is evaluated per situation by measuring the correlation between the automatic ranking of profile ratings and a manual ground truth. Results indicate that LERVUP is effective since a strong correlation of the two rankings is obtained. This finding indicates that providing meaningful automatic situation-related feedback about the effects of data sharing is feasible.
InvGAN: Invertible GANs
Dec 10, 2021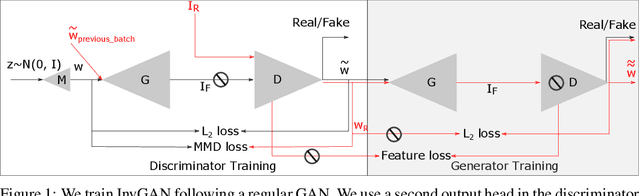
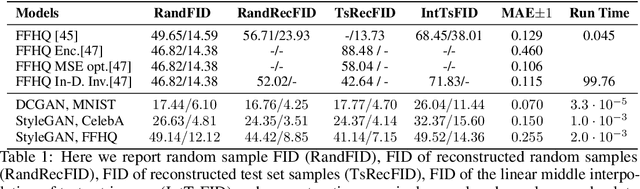


Generation of photo-realistic images, semantic editing and representation learning are a few of many potential applications of high resolution generative models. Recent progress in GANs have established them as an excellent choice for such tasks. However, since they do not provide an inference model, image editing or downstream tasks such as classification can not be done on real images using the GAN latent space. Despite numerous efforts to train an inference model or design an iterative method to invert a pre-trained generator, previous methods are dataset (e.g. human face images) and architecture (e.g. StyleGAN) specific. These methods are nontrivial to extend to novel datasets or architectures. We propose a general framework that is agnostic to architecture and datasets. Our key insight is that, by training the inference and the generative model together, we allow them to adapt to each other and to converge to a better quality model. Our \textbf{InvGAN}, short for Invertible GAN, successfully embeds real images to the latent space of a high quality generative model. This allows us to perform image inpainting, merging, interpolation and online data augmentation. We demonstrate this with extensive qualitative and quantitative experiments.
Transfer learning using deep neural networks for Ear Presentation Attack Detection: New Database for PAD
Dec 09, 2021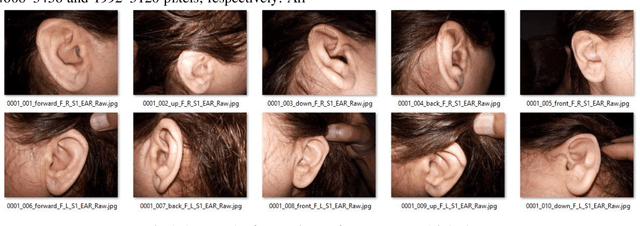
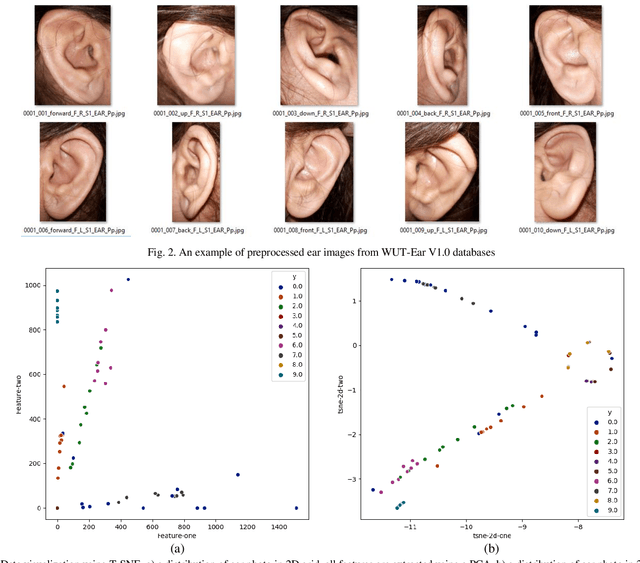
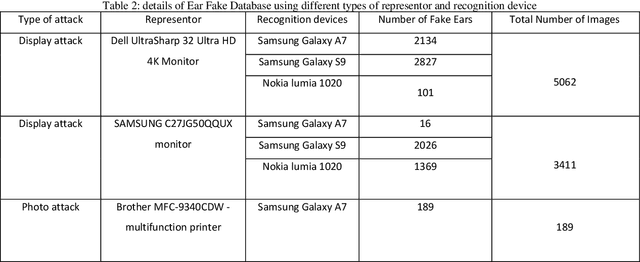
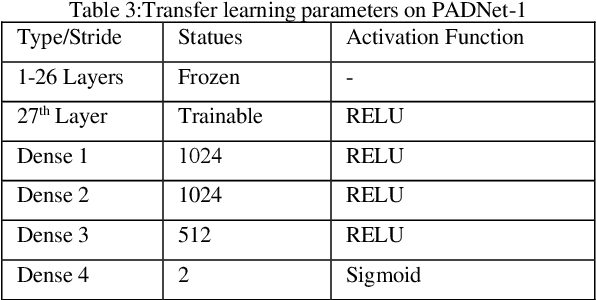
Ear recognition system has been widely studied whereas there are just a few ear presentation attack detection methods for ear recognition systems, consequently, there is no publicly available ear presentation attack detection (PAD) database. In this paper, we propose a PAD method using a pre-trained deep neural network and release a new dataset called Warsaw University of Technology Ear Dataset for Presentation Attack Detection (WUT-Ear V1.0). There is no ear database that is captured using mobile devices. Hence, we have captured more than 8500 genuine ear images from 134 subjects and more than 8500 fake ear images using. We made replay-attack and photo print attacks with 3 different mobile devices. Our approach achieves 99.83% and 0.08% for the half total error rate (HTER) and attack presentation classification error rate (APCER), respectively, on the replay-attack database. The captured data is analyzed and visualized statistically to find out its importance and make it a benchmark for further research. The experiments have been found out a secure PAD method for ear recognition system, publicly available ear image, and ear PAD dataset. The codes and evaluation results are publicly available at https://github.com/Jalilnkh/KartalOl-EAR-PAD.
toon2real: Translating Cartoon Images to Realistic Images
Feb 01, 2021
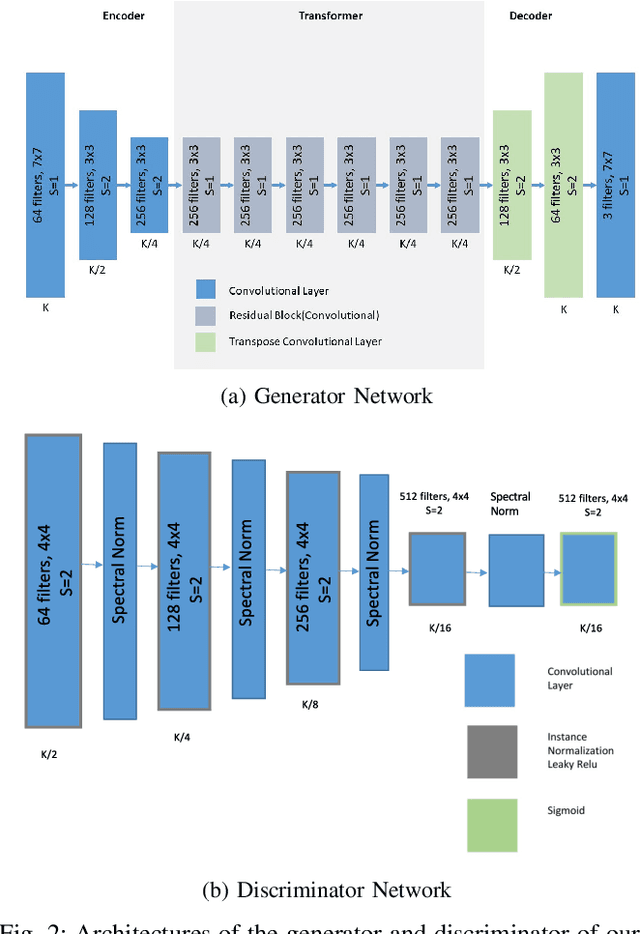

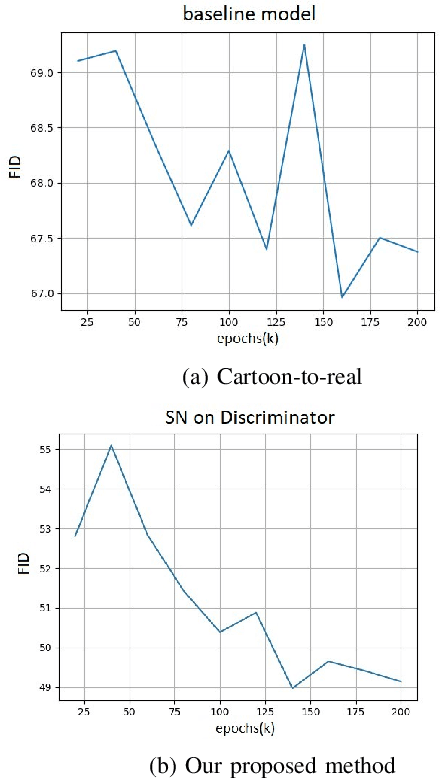
In terms of Image-to-image translation, Generative Adversarial Networks (GANs) has achieved great success even when it is used in the unsupervised dataset. In this work, we aim to translate cartoon images to photo-realistic images using GAN. We apply several state-of-the-art models to perform this task; however, they fail to perform good quality translations. We observe that the shallow difference between these two domains causes this issue. Based on this idea, we propose a method based on CycleGAN model for image translation from cartoon domain to photo-realistic domain. To make our model efficient, we implemented Spectral Normalization which added stability in our model. We demonstrate our experimental results and show that our proposed model has achieved the lowest Frechet Inception Distance score and better results compared to another state-of-the-art technique, UNIT.