 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Skyline variations allow estimating distance to trees on landscape photos using semantic segmentation
Jan 14, 2022
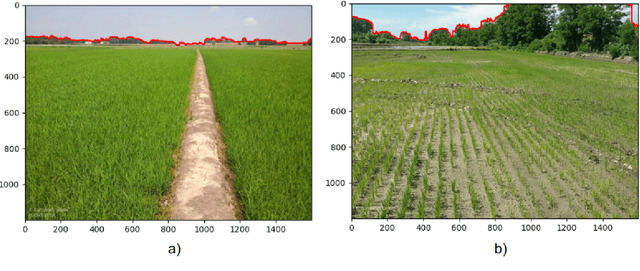
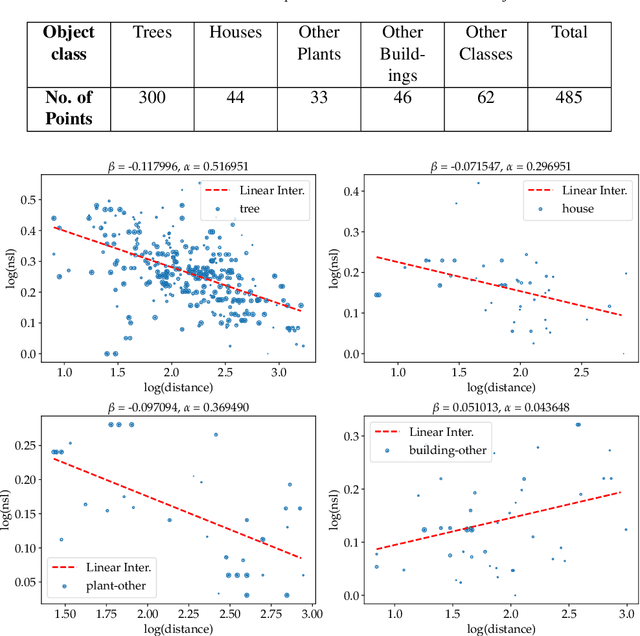
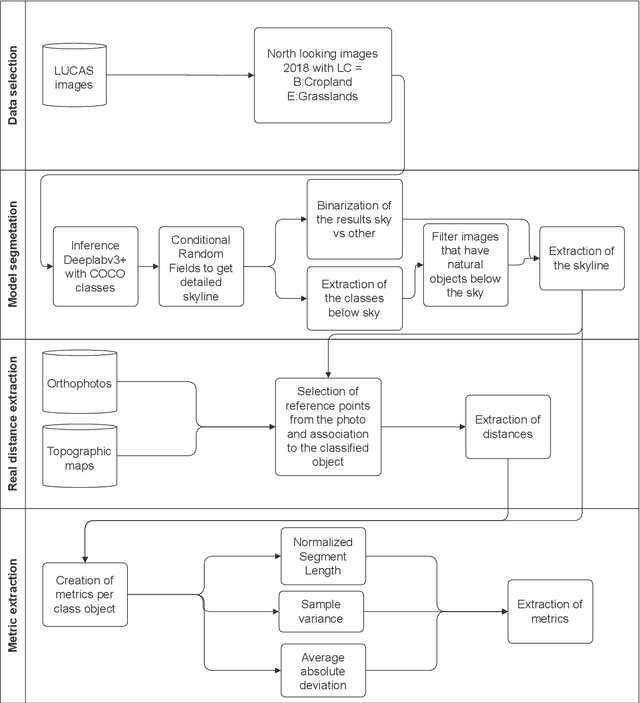

Approximate distance estimation can be used to determine fundamental landscape properties including complexity and openness. We show that variations in the skyline of landscape photos can be used to estimate distances to trees on the horizon. A methodology based on the variations of the skyline has been developed and used to investigate potential relationships with the distance to skyline objects. The skyline signal, defined by the skyline height expressed in pixels, was extracted for several Land Use/Cover Area frame Survey (LUCAS) landscape photos. Photos were semantically segmented with DeepLabV3+ trained with the Common Objects in Context (COCO) dataset. This provided pixel-level classification of the objects forming the skyline. A Conditional Random Fields (CRF) algorithm was also applied to increase the details of the skyline signal. Three metrics, able to capture the skyline signal variations, were then considered for the analysis. These metrics shows a functional relationship with distance for the class of trees, whose contours have a fractal nature. In particular, regression analysis was performed against 475 ortho-photo based distance measurements, and, in the best case, a R2 score equal to 0.47 was achieved. This is an encouraging result which shows the potential of skyline variation metrics for inferring distance related information.
Mining the manifolds of deep generative models for multiple data-consistent solutions of ill-posed tomographic imaging problems
Feb 10, 2022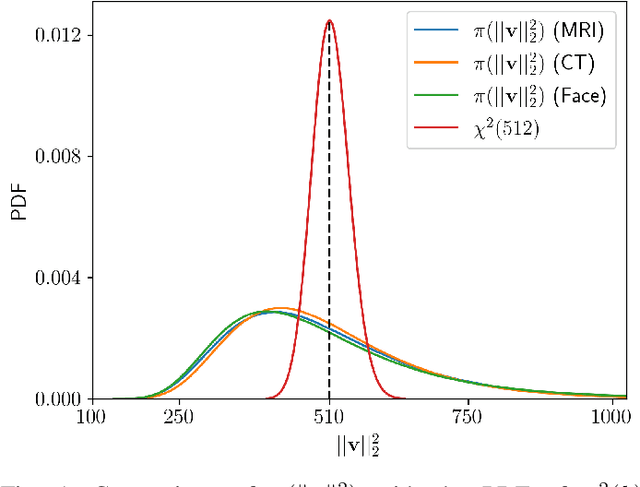
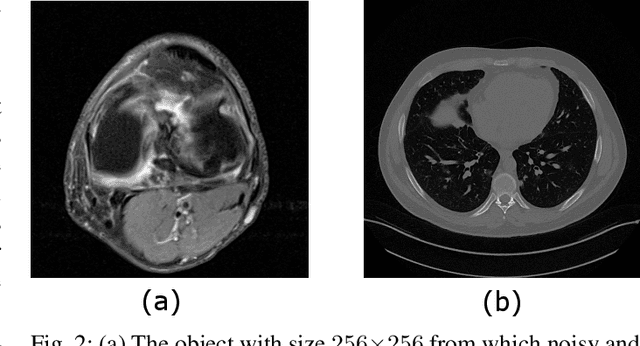
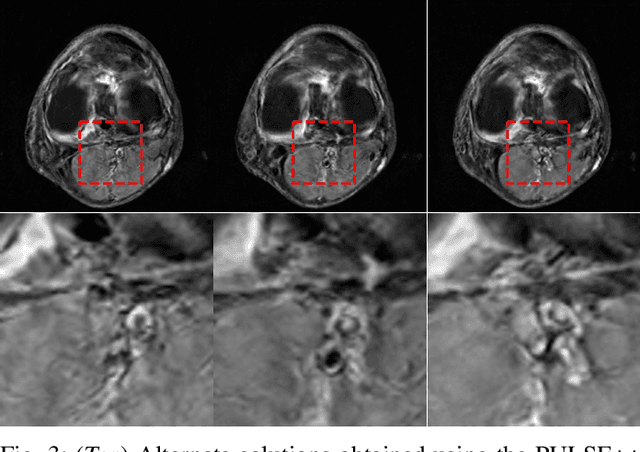
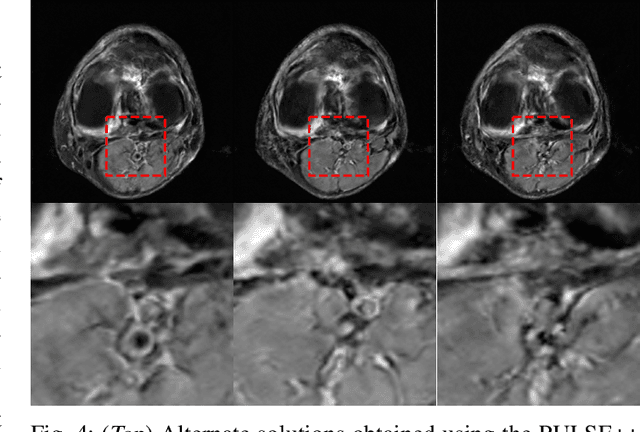
Tomographic imaging is in general an ill-posed inverse problem. Typically, a single regularized image estimate of the sought-after object is obtained from tomographic measurements. However, there may be multiple objects that are all consistent with the same measurement data. The ability to generate such alternate solutions is important because it may enable new assessments of imaging systems. In principle, this can be achieved by means of posterior sampling methods. In recent years, deep neural networks have been employed for posterior sampling with promising results. However, such methods are not yet for use with large-scale tomographic imaging applications. On the other hand, empirical sampling methods may be computationally feasible for large-scale imaging systems and enable uncertainty quantification for practical applications. Empirical sampling involves solving a regularized inverse problem within a stochastic optimization framework in order to obtain alternate data-consistent solutions. In this work, we propose a new empirical sampling method that computes multiple solutions of a tomographic inverse problem that are consistent with the same acquired measurement data. The method operates by repeatedly solving an optimization problem in the latent space of a style-based generative adversarial network (StyleGAN), and was inspired by the Photo Upsampling via Latent Space Exploration (PULSE) method that was developed for super-resolution tasks. The proposed method is demonstrated and analyzed via numerical studies that involve two stylized tomographic imaging modalities. These studies establish the ability of the method to perform efficient empirical sampling and uncertainty quantification.
Good Artists Copy, Great Artists Steal: Model Extraction Attacks Against Image Translation Generative Adversarial Networks
Apr 26, 2021
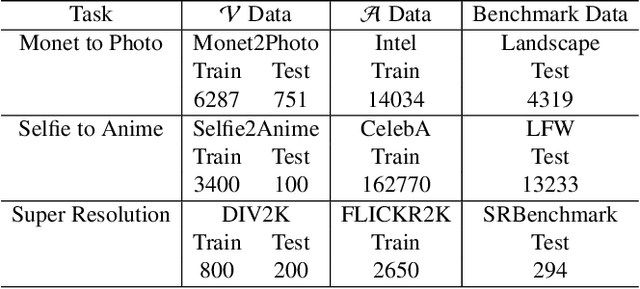

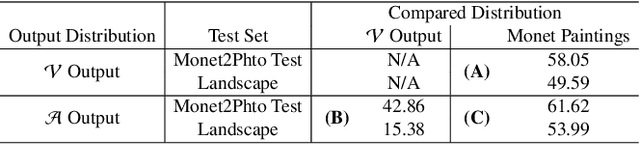
Machine learning models are typically made available to potential client users via inference APIs. Model extraction attacks occur when a malicious client uses information gleaned from queries to the inference API of a victim model $F_V$ to build a surrogate model $F_A$ that has comparable functionality. Recent research has shown successful model extraction attacks against image classification, and NLP models. In this paper, we show the first model extraction attack against real-world generative adversarial network (GAN) image translation models. We present a framework for conducting model extraction attacks against image translation models, and show that the adversary can successfully extract functional surrogate models. The adversary is not required to know $F_V$'s architecture or any other information about it beyond its intended image translation task, and queries $F_V$'s inference interface using data drawn from the same domain as the training data for $F_V$. We evaluate the effectiveness of our attacks using three different instances of two popular categories of image translation: (1) Selfie-to-Anime and (2) Monet-to-Photo (image style transfer), and (3) Super-Resolution (super resolution). Using standard performance metrics for GANs, we show that our attacks are effective in each of the three cases -- the differences between $F_V$ and $F_A$, compared to the target are in the following ranges: Selfie-to-Anime: FID $13.36-68.66$, Monet-to-Photo: FID $3.57-4.40$, and Super-Resolution: SSIM: $0.06-0.08$ and PSNR: $1.43-4.46$. Furthermore, we conducted a large scale (125 participants) user study on Selfie-to-Anime and Monet-to-Photo to show that human perception of the images produced by the victim and surrogate models can be considered equivalent, within an equivalence bound of Cohen's $d=0.3$.
Photo Filter Recommendation by Category-Aware Aesthetic Learning
Mar 27, 2017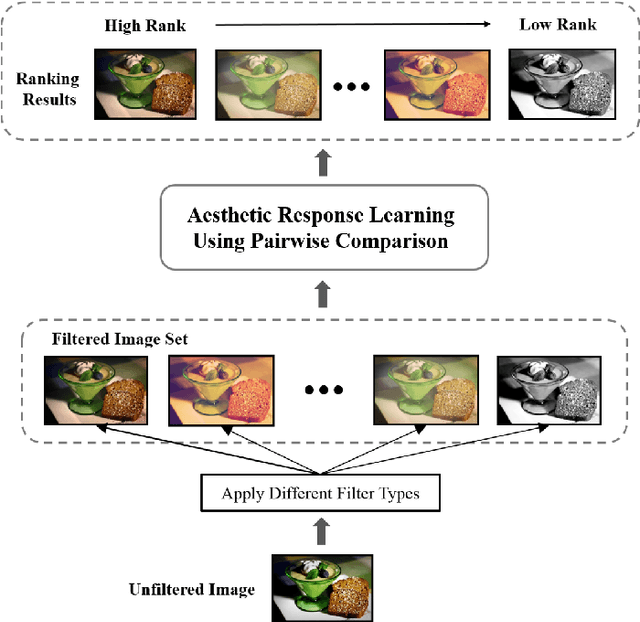
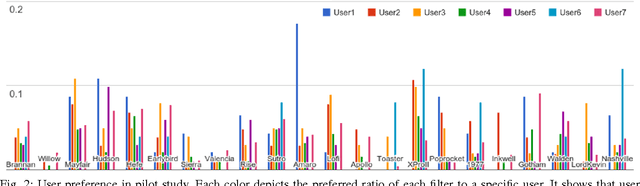

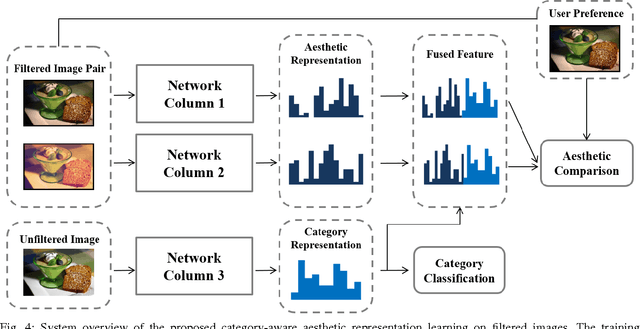
Nowadays, social media has become a popular platform for the public to share photos. To make photos more visually appealing, users usually apply filters on their photos without domain knowledge. However, due to the growing number of filter types, it becomes a major issue for users to choose the best filter type. For this purpose, filter recommendation for photo aesthetics takes an important role in image quality ranking problems. In these years, several works have declared that Convolutional Neural Networks (CNNs) outperform traditional methods in image aesthetic categorization, which classifies images into high or low quality. Most of them do not consider the effect on filtered images; hence, we propose a novel image aesthetic learning for filter recommendation. Instead of binarizing image quality, we adjust the state-of-the-art CNN architectures and design a pairwise loss function to learn the embedded aesthetic responses in hidden layers for filtered images. Based on our pilot study, we observe image categories (e.g., portrait, landscape, food) will affect user preference on filter selection. We further integrate category classification into our proposed aesthetic-oriented models. To the best of our knowledge, there is no public dataset for aesthetic judgment with filtered images. We create a new dataset called Filter Aesthetic Comparison Dataset (FACD). It contains 28,160 filtered images based on the AVA dataset and 42,240 reliable image pairs with aesthetic annotations using Amazon Mechanical Turk. It is the first dataset containing filtered images and user preference labels. We conduct experiments on the collected FACD for filter recommendation, and the results show that our proposed category-aware aesthetic learning outperforms aesthetic classification methods (e.g., 12% relative improvement).
How useful is photo-realistic rendering for visual learning?
Sep 08, 2016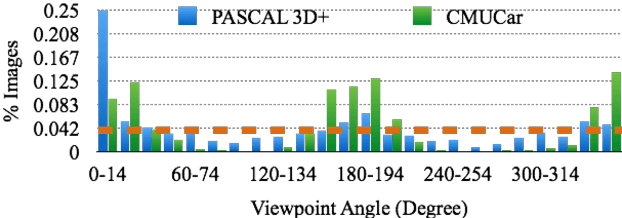
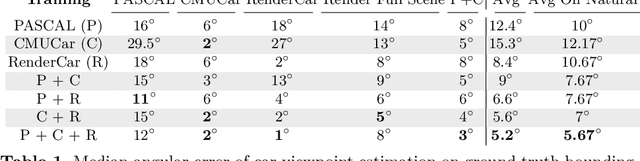


Data seems cheap to get, and in many ways it is, but the process of creating a high quality labeled dataset from a mass of data is time-consuming and expensive. With the advent of rich 3D repositories, photo-realistic rendering systems offer the opportunity to provide nearly limitless data. Yet, their primary value for visual learning may be the quality of the data they can provide rather than the quantity. Rendering engines offer the promise of perfect labels in addition to the data: what the precise camera pose is; what the precise lighting location, temperature, and distribution is; what the geometry of the object is. In this work we focus on semi-automating dataset creation through use of synthetic data and apply this method to an important task -- object viewpoint estimation. Using state-of-the-art rendering software we generate a large labeled dataset of cars rendered densely in viewpoint space. We investigate the effect of rendering parameters on estimation performance and show realism is important. We show that generalizing from synthetic data is not harder than the domain adaptation required between two real-image datasets and that combining synthetic images with a small amount of real data improves estimation accuracy.
MirrorNeRF: One-shot Neural Portrait RadianceField from Multi-mirror Catadioptric Imaging
Apr 06, 2021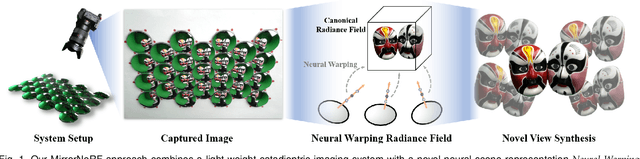

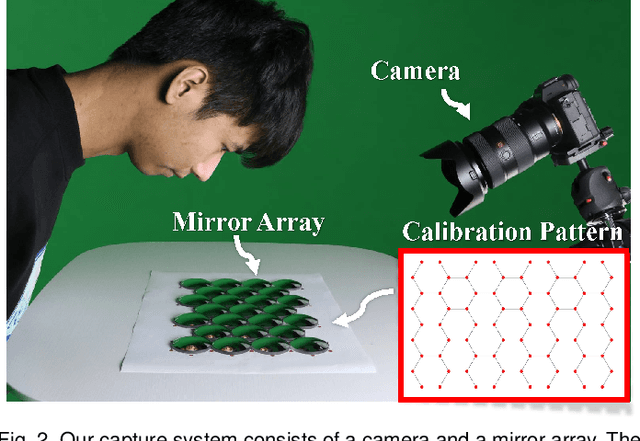
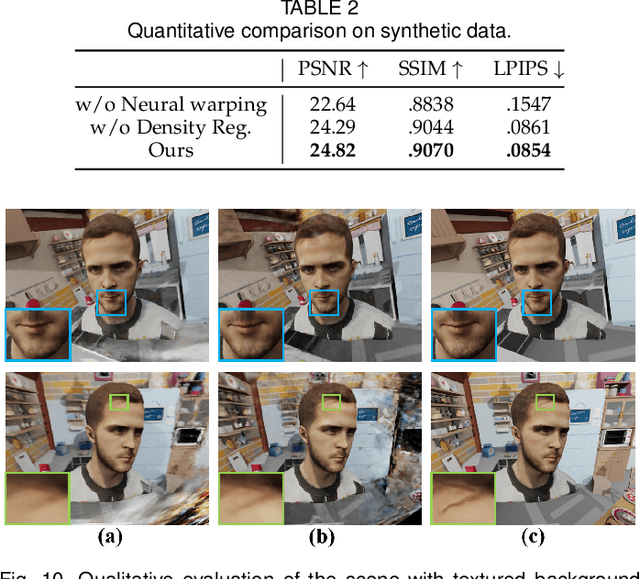
Photo-realistic neural reconstruction and rendering of the human portrait are critical for numerous VR/AR applications. Still, existing solutions inherently rely on multi-view capture settings, and the one-shot solution to get rid of the tedious multi-view synchronization and calibration remains extremely challenging. In this paper, we propose MirrorNeRF - a one-shot neural portrait free-viewpoint rendering approach using a catadioptric imaging system with multiple sphere mirrors and a single high-resolution digital camera, which is the first to combine neural radiance field with catadioptric imaging so as to enable one-shot photo-realistic human portrait reconstruction and rendering, in a low-cost and casual capture setting. More specifically, we propose a light-weight catadioptric system design with a sphere mirror array to enable diverse ray sampling in the continuous 3D space as well as an effective online calibration for the camera and the mirror array. Our catadioptric imaging system can be easily deployed with a low budget and the casual capture ability for convenient daily usages. We introduce a novel neural warping radiance field representation to learn a continuous displacement field that implicitly compensates for the misalignment due to our flexible system setting. We further propose a density regularization scheme to leverage the inherent geometry information from the catadioptric data in a self-supervision manner, which not only improves the training efficiency but also provides more effective density supervision for higher rendering quality. Extensive experiments demonstrate the effectiveness and robustness of our scheme to achieve one-shot photo-realistic and high-quality appearance free-viewpoint rendering for human portrait scenes.
Projective Urban Texturing
Jan 25, 2022
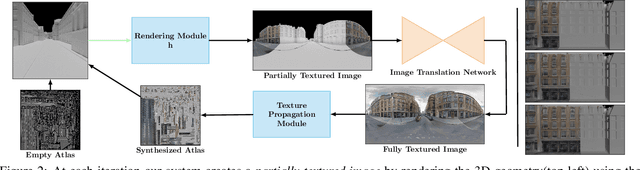
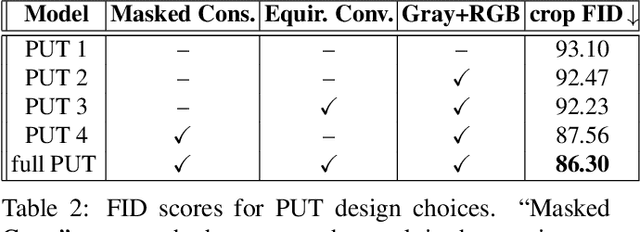

This paper proposes a method for automatic generation of textures for 3D city meshes in immersive urban environments. Many recent pipelines capture or synthesize large quantities of city geometry using scanners or procedural modeling pipelines. Such geometry is intricate and realistic, however the generation of photo-realistic textures for such large scenes remains a problem. We propose to generate textures for input target 3D meshes driven by the textural style present in readily available datasets of panoramic photos capturing urban environments. Re-targeting such 2D datasets to 3D geometry is challenging because the underlying shape, size, and layout of the urban structures in the photos do not correspond to the ones in the target meshes. Photos also often have objects (e.g., trees, vehicles) that may not even be present in the target geometry.To address these issues we present a method, called Projective Urban Texturing (PUT), which re-targets textural style from real-world panoramic images to unseen urban meshes. PUT relies on contrastive and adversarial training of a neural architecture designed for unpaired image-to-texture translation. The generated textures are stored in a texture atlas applied to the target 3D mesh geometry. To promote texture consistency, PUT employs an iterative procedure in which texture synthesis is conditioned on previously generated, adjacent textures. We demonstrate both quantitative and qualitative evaluation of the generated textures.
An implementation of ROS Autonomous Navigation on Parallax Eddie platform
Aug 28, 2021


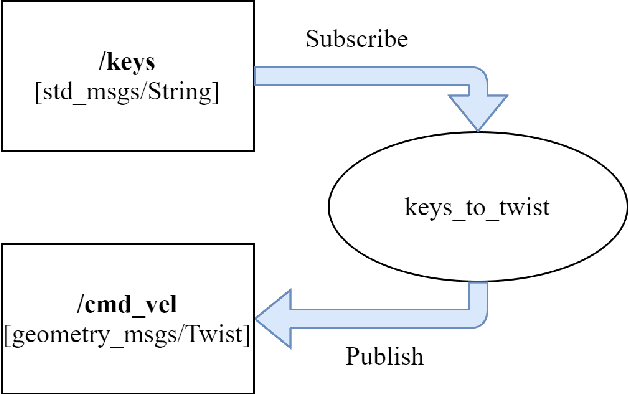
This paper presents an implementation of autonomous navigation functionality based on Robot Operating System (ROS) on a wheeled differential drive mobile platform called Eddie robot. ROS is a framework that contains many reusable software stacks as well as visualization and debugging tools that provides an ideal environment for any robotic project development. The main contribution of this paper is the description of the customized hardware and software system setup of Eddie robot to work with an autonomous navigation system in ROS called Navigation Stack and to implement one application use case for autonomous navigation. For this paper, photo taking is chosen to demonstrate a use case of the mobile robot.
Development of Automatic Tree Counting Software from UAV Based Aerial Images With Machine Learning
Jan 07, 2022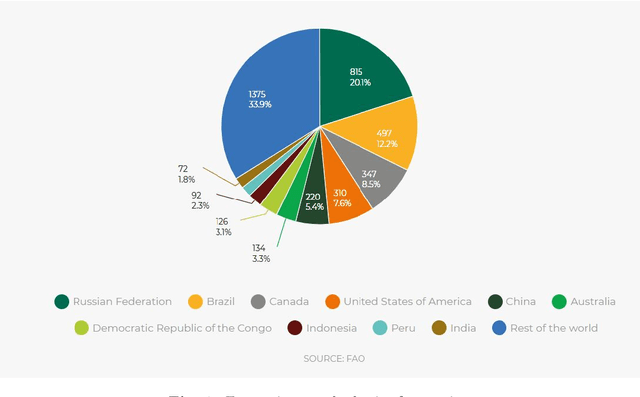

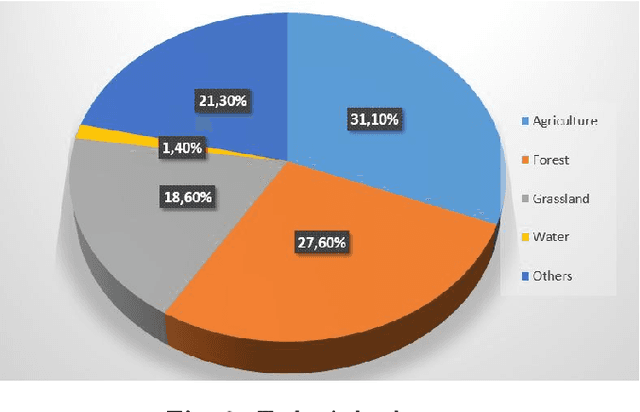
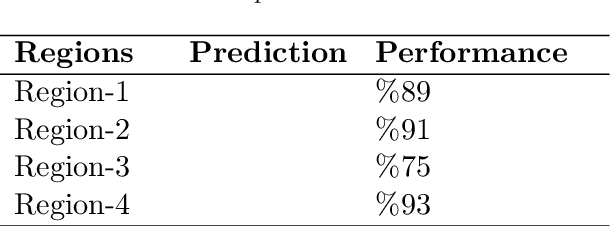
Unmanned aerial vehicles (UAV) are used successfully in many application areas such as military, security, monitoring, emergency aid, tourism, agriculture, and forestry. This study aims to automatically count trees in designated areas on the Siirt University campus from high-resolution images obtained by UAV. Images obtained at 30 meters height with 20% overlap were stitched offline at the ground station using Adobe Photoshop's photo merge tool. The resulting image was denoised and smoothed by applying the 3x3 median and mean filter, respectively. After generating the orthophoto map of the aerial images captured by the UAV in certain regions, the bounding boxes of different objects on these maps were labeled in the modalities of HSV (Hue Saturation Value), RGB (Red Green Blue) and Gray. Training, validation, and test datasets were generated and then have been evaluated for classification success rates related to tree detection using various machine learning algorithms. In the last step, a ground truth model was established by obtaining the actual tree numbers, and then the prediction performance was calculated by comparing the reference ground truth data with the proposed model. It is considered that significant success has been achieved for tree count with an average accuracy rate of 87% obtained using the MLP classifier in predetermined regions.
Hallucinated Neural Radiance Fields in the Wild
Dec 01, 2021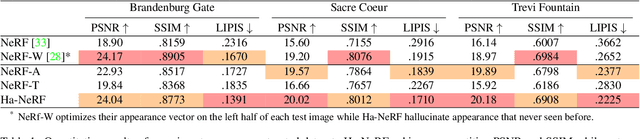
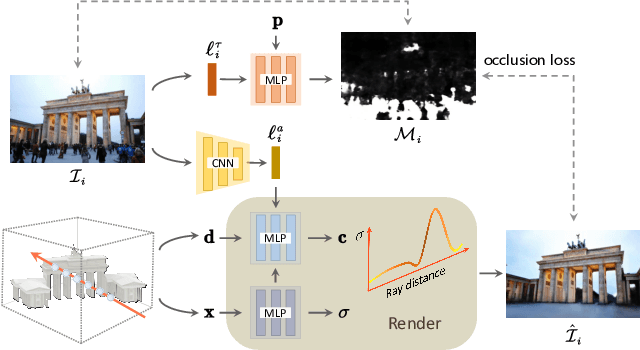
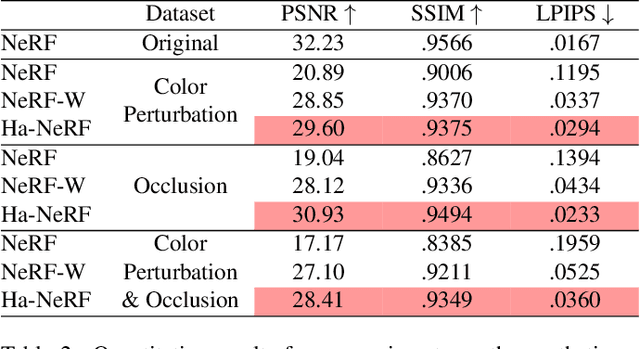
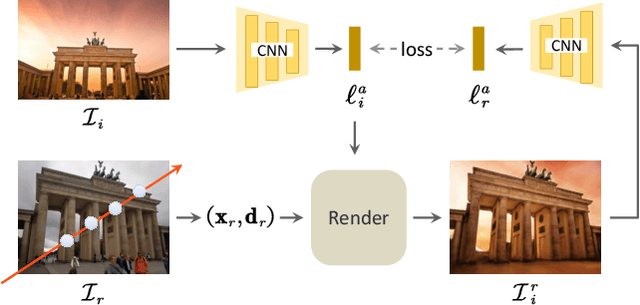
Neural Radiance Fields (NeRF) has recently gained popularity for its impressive novel view synthesis ability. This paper studies the problem of hallucinated NeRF: i.e. recovering a realistic NeRF at a different time of day from a group of tourism images. Existing solutions adopt NeRF with a controllable appearance embedding to render novel views under various conditions, but cannot render view-consistent images with an unseen appearance. To solve this problem, we present an end-to-end framework for constructing a hallucinated NeRF, dubbed as Ha-NeRF. Specifically, we propose an appearance hallucination module to handle time-varying appearances and transfer them to novel views. Considering the complex occlusions of tourism images, an anti-occlusion module is introduced to decompose the static subjects for visibility accurately. Experimental results on synthetic data and real tourism photo collections demonstrate that our method can not only hallucinate the desired appearances, but also render occlusion-free images from different views. The project and supplementary materials are available at https://rover-xingyu.github.io/Ha-NeRF/.