 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Differentially Private Imaging via Latent Space Manipulation
Mar 08, 2021
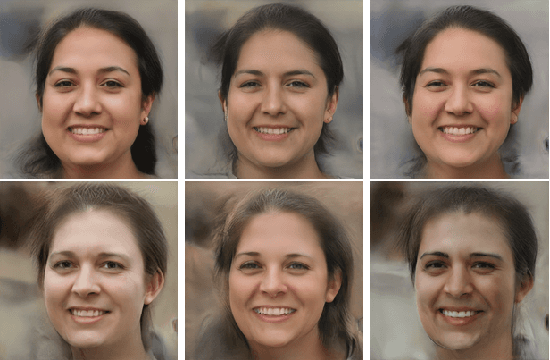

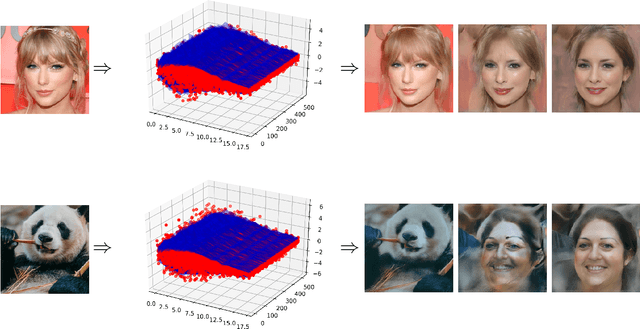
There is growing concern about image privacy due to the popularity of social media and photo devices, along with increasing use of face recognition systems. However, established image de-identification techniques are either too subject to re-identification, produce photos that are insufficiently realistic, or both. To tackle this, we present a novel approach for image obfuscation by manipulating latent spaces of an unconditionally trained generative model that is able to synthesize photo-realistic facial images of high resolution. This manipulation is done in a way that satisfies the formal privacy standard of local differential privacy. To our knowledge, this is the first approach to image privacy that satisfies $\varepsilon$-differential privacy \emph{for the person.}
A Contactless Fingerprint Recognition System
Aug 20, 2021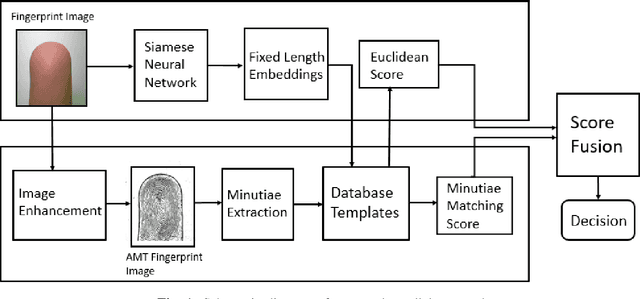
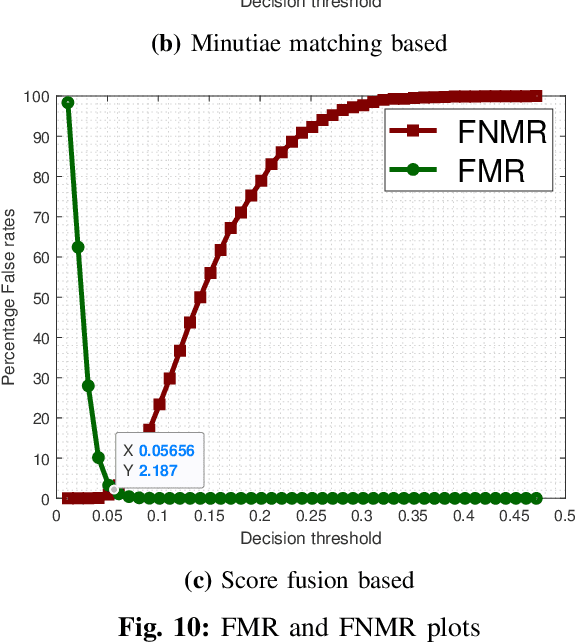
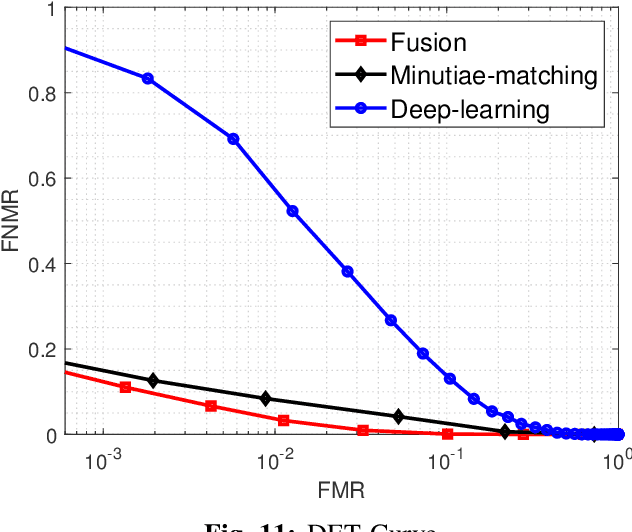
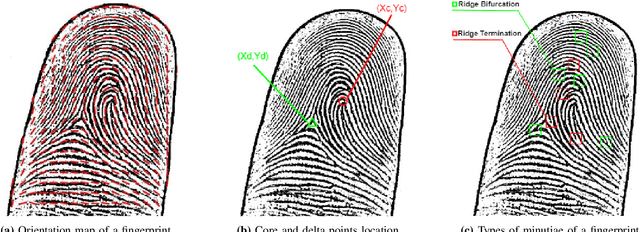
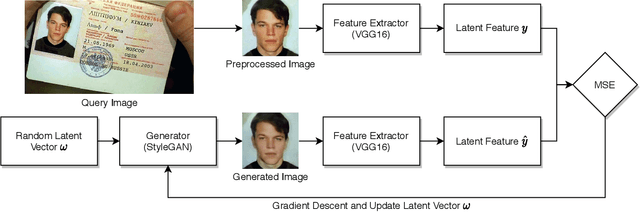
Fingerprints are one of the most widely explored biometric traits. Specifically, contact-based fingerprint recognition systems reign supreme due to their robustness, portability and the extensive research work done in the field. However, these systems suffer from issues such as hygiene, sensor degradation due to constant physical contact, and latent fingerprint threats. In this paper, we propose an approach for developing a contactless fingerprint recognition system that captures finger photo from a distance using an image sensor in a suitable environment. The captured finger photos are then processed further to obtain global and local (minutiae-based) features. Specifically, a Siamese convolutional neural network (CNN) is designed to extract global features from a given finger photo. The proposed system computes matching scores from CNN-based features and minutiae-based features. Finally, the two scores are fused to obtain the final matching score between the probe and reference fingerprint templates. Most importantly, the proposed system is developed using the Nvidia Jetson Nano development kit, which allows us to perform contactless fingerprint recognition in real-time with minimum latency and acceptable matching accuracy. The performance of the proposed system is evaluated on an in-house IITI contactless fingerprint dataset (IITI-CFD) containing 105train and 100 test subjects. The proposed system achieves an equal-error-rate of 2.19% on IITI-CFD.
Paper-based printed CPW-fed antenna for Wi-Fi applications
Jan 27, 2022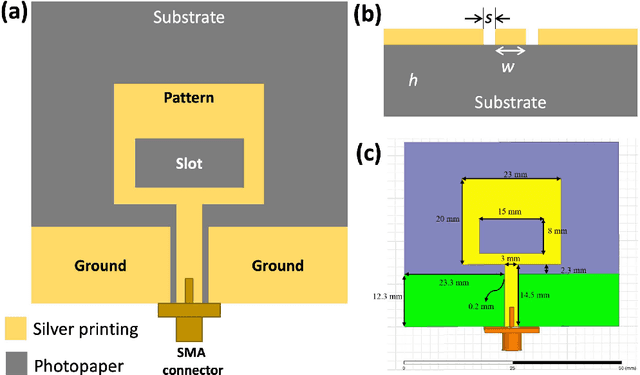

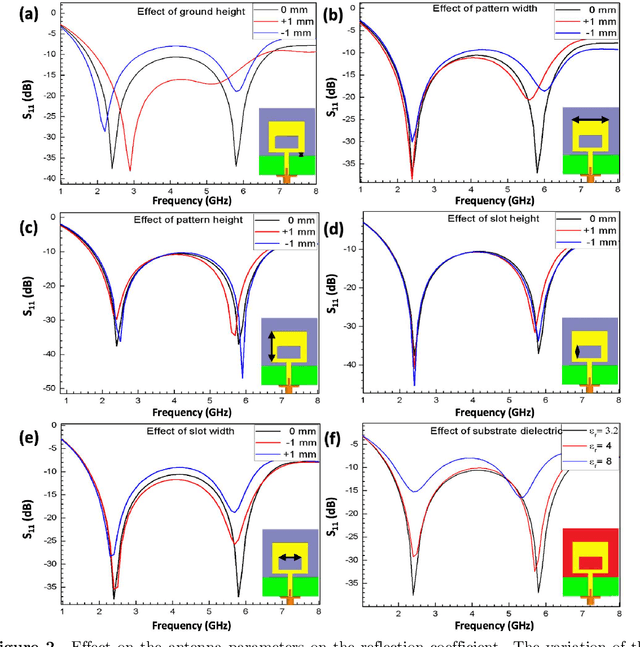
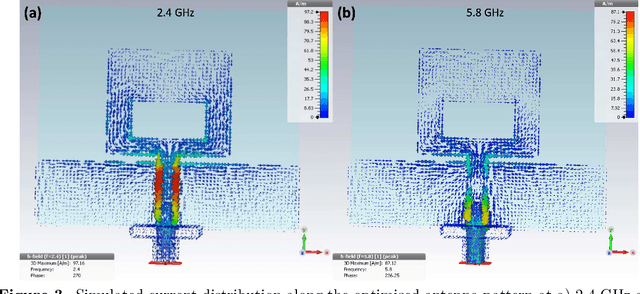
A paper-based co-planar waveguide (CPW) fed monopole antenna for Wi-Fi applications is proposed. The antenna is fabricated by printing a commercial silver nanoparticle (Ag NP) based ink on photo paper substrate. The antenna is designed as a single layer for the ease of fabrication, and it is designed to radiate at two frequencies, 2.4 and 5.8 GHz, which are suitable for Wi-Fi applications. The printed film exhibits good electrical conductivity, with a low sheet resistance of 114 m{\Omega}/sq comparable with commonly used conductive metal lines. The fabricated antenna demonstrates good radiative properties at both flat and bent conditions. This confirms the good flexible properties of the antenna making it compatible with mounting on curved surfaces. The performance of the fabricated antenna is also compared with a commercial rigid antenna by interfacing with a USB dongle. The printed antenna demonstrates better performance with respect to signal strength at specific distances when compared with the commercial antenna. This work demonstrates that rigid and long commercial antennas can be replaced with paper-based flexible and cheap antennas and incorporated with wearable technologies. Additionally, replacing Ag NPs with nanowires provides transparency without compromising on the electrical properties.
Brand Label Albedo Extraction of eCommerce Products using Generative Adversarial Network
Sep 07, 2021
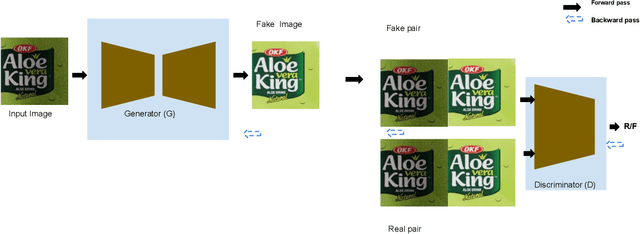


In this paper we present our solution to extract albedo of branded labels for e-commerce products. To this end, we generate a large-scale photo-realistic synthetic data set for albedo extraction followed by training a generative model to translate images with diverse lighting conditions to albedo. We performed an extensive evaluation to test the generalisation of our method to in-the-wild images. From the experimental results, we observe that our solution generalises well compared to the existing method both in the unseen rendered images as well as in the wild image.
Multi-Robot Collaborative Perception with Graph Neural Networks
Jan 05, 2022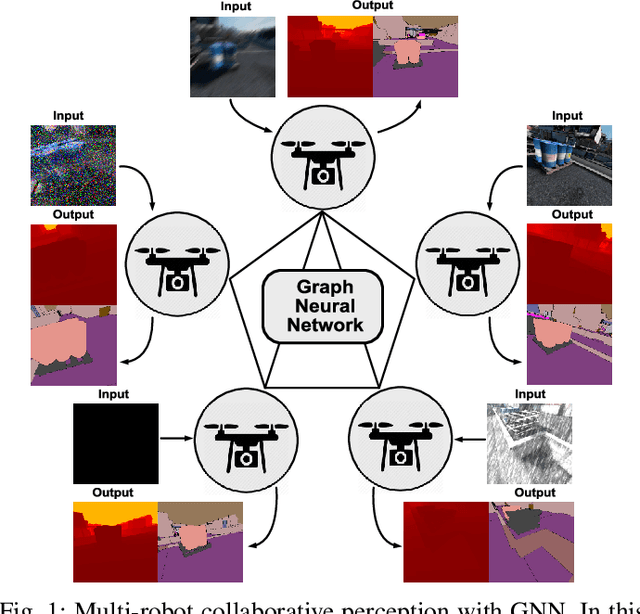

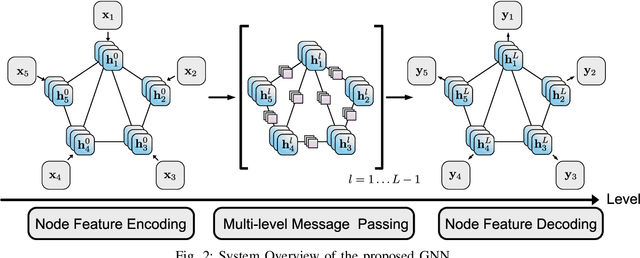
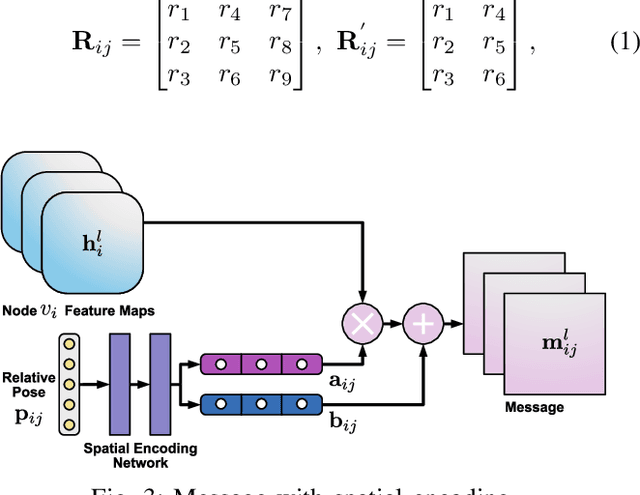
Multi-robot systems such as swarms of aerial robots are naturally suited to offer additional flexibility, resilience, and robustness in several tasks compared to a single robot by enabling cooperation among the agents. To enhance the autonomous robot decision-making process and situational awareness, multi-robot systems have to coordinate their perception capabilities to collect, share, and fuse environment information among the agents in an efficient and meaningful way such to accurately obtain context-appropriate information or gain resilience to sensor noise or failures. In this paper, we propose a general-purpose Graph Neural Network (GNN) with the main goal to increase, in multi-robot perception tasks, single robots' inference perception accuracy as well as resilience to sensor failures and disturbances. We show that the proposed framework can address multi-view visual perception problems such as monocular depth estimation and semantic segmentation. Several experiments both using photo-realistic and real data gathered from multiple aerial robots' viewpoints show the effectiveness of the proposed approach in challenging inference conditions including images corrupted by heavy noise and camera occlusions or failures.
Highly precise AMCW time-of-flight scanning sensor based on digital-parallel demodulation
Dec 16, 2021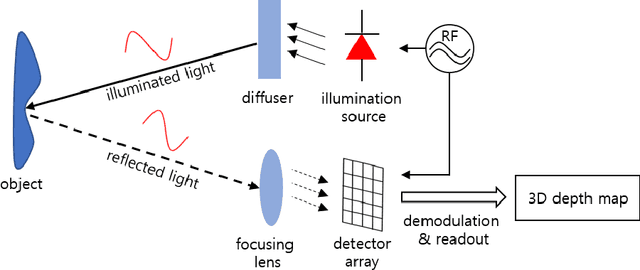
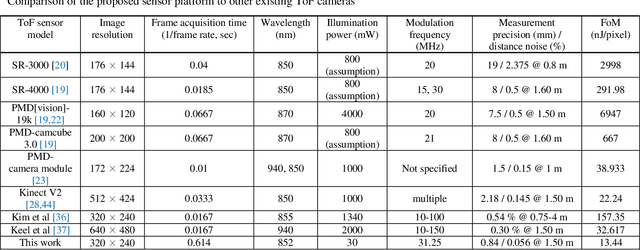
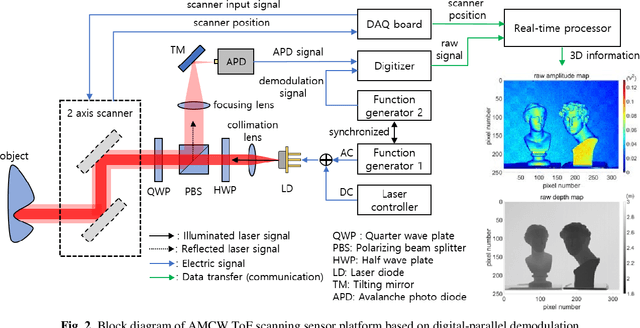
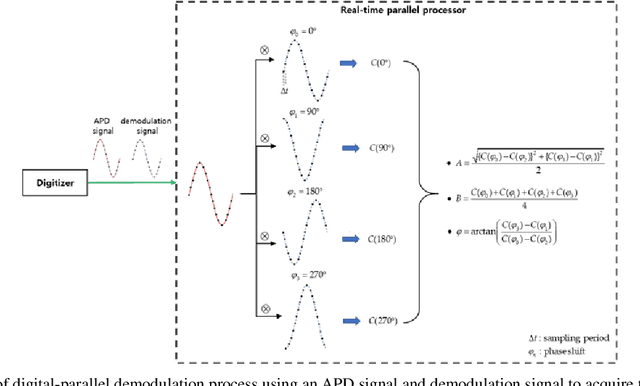
In this paper, a novel amplitude-modulated continuous wave (AMCW) time-of-flight (ToF) scanning sensor based on digital-parallel demodulation is proposed and demonstrated in the aspect of distance measurement precision. Since digital-parallel demodulation utilizes a high-amplitude demodulation signal with zero-offset, the proposed sensor platform can maintain extremely high demodulation contrast. Meanwhile, as all cross correlated samples are calculated in parallel and in extremely short integration time, the proposed sensor platform can utilize a 2D laser scanning structure with a single photo detector, maintaining a moderate frame rate. This optical structure can increase the received optical SNR and remove the crosstalk of image pixel array. Based on these measurement properties, the proposed AMCW ToF scanning sensor shows highly precise 3D depth measurement performance. In this study, this precise measurement performance is explained in detail. Additionally, the actual measurement performance of the proposed sensor platform is experimentally validated under various conditions.
I M Avatar: Implicit Morphable Head Avatars from Videos
Dec 15, 2021
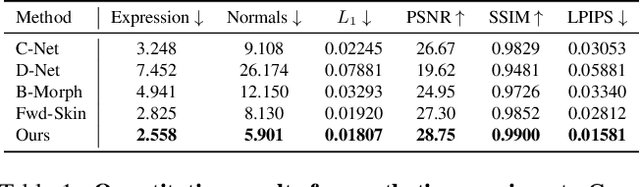
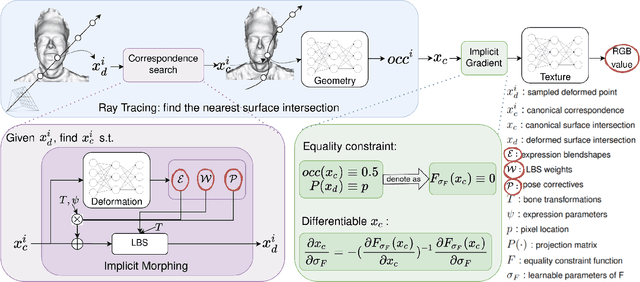
Traditional morphable face models provide fine-grained control over expression but cannot easily capture geometric and appearance details. Neural volumetric representations approach photo-realism but are hard to animate and do not generalize well to unseen expressions. To tackle this problem, we propose IMavatar (Implicit Morphable avatar), a novel method for learning implicit head avatars from monocular videos. Inspired by the fine-grained control mechanisms afforded by conventional 3DMMs, we represent the expression- and pose-related deformations via learned blendshapes and skinning fields. These attributes are pose-independent and can be used to morph the canonical geometry and texture fields given novel expression and pose parameters. We employ ray tracing and iterative root-finding to locate the canonical surface intersection for each pixel. A key contribution is our novel analytical gradient formulation that enables end-to-end training of IMavatars from videos. We show quantitatively and qualitatively that our method improves geometry and covers a more complete expression space compared to state-of-the-art methods.
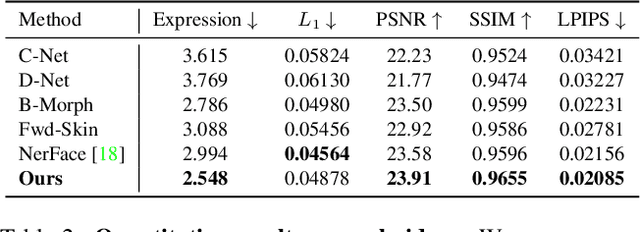
DFA-NeRF: Personalized Talking Head Generation via Disentangled Face Attributes Neural Rendering
Jan 03, 2022
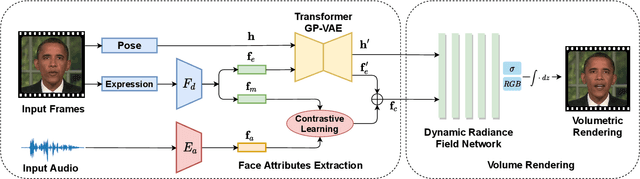
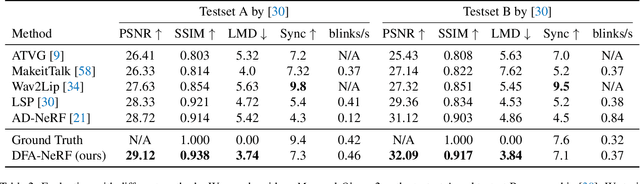
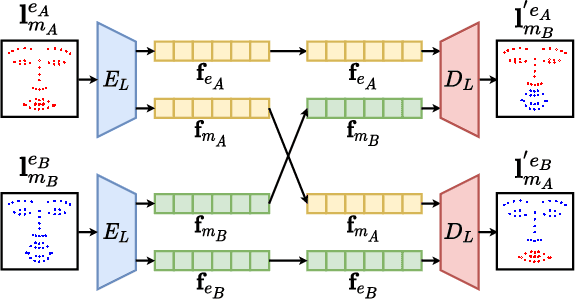
While recent advances in deep neural networks have made it possible to render high-quality images, generating photo-realistic and personalized talking head remains challenging. With given audio, the key to tackling this task is synchronizing lip movement and simultaneously generating personalized attributes like head movement and eye blink. In this work, we observe that the input audio is highly correlated to lip motion while less correlated to other personalized attributes (e.g., head movements). Inspired by this, we propose a novel framework based on neural radiance field to pursue high-fidelity and personalized talking head generation. Specifically, neural radiance field takes lip movements features and personalized attributes as two disentangled conditions, where lip movements are directly predicted from the audio inputs to achieve lip-synchronized generation. In the meanwhile, personalized attributes are sampled from a probabilistic model, where we design a Transformer-based variational autoencoder sampled from Gaussian Process to learn plausible and natural-looking head pose and eye blink. Experiments on several benchmarks demonstrate that our method achieves significantly better results than state-of-the-art methods.
Sim-to-Lab-to-Real: Safe Reinforcement Learning with Shielding and Generalization Guarantees
Jan 20, 2022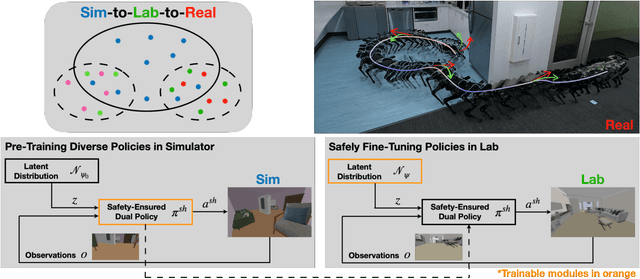

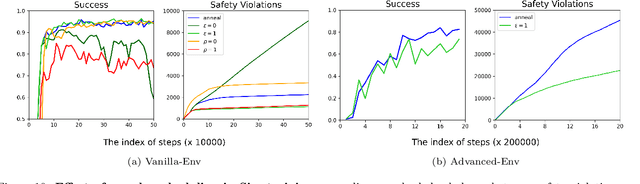
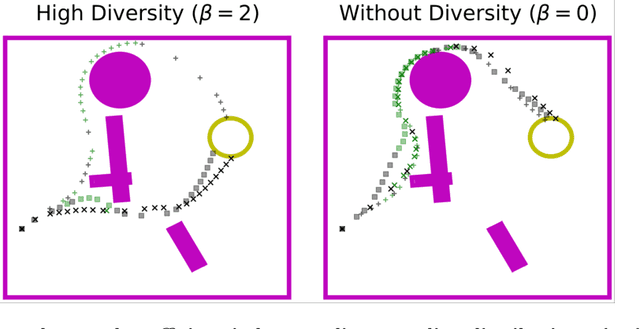
Safety is a critical component of autonomous systems and remains a challenge for learning-based policies to be utilized in the real world. In particular, policies learned using reinforcement learning often fail to generalize to novel environments due to unsafe behavior. In this paper, we propose Sim-to-Lab-to-Real to safely close the reality gap. To improve safety, we apply a dual policy setup where a performance policy is trained using the cumulative task reward and a backup (safety) policy is trained by solving the reach-avoid Bellman Equation based on Hamilton-Jacobi reachability analysis. In Sim-to-Lab transfer, we apply a supervisory control scheme to shield unsafe actions during exploration; in Lab-to-Real transfer, we leverage the Probably Approximately Correct (PAC)-Bayes framework to provide lower bounds on the expected performance and safety of policies in unseen environments. We empirically study the proposed framework for ego-vision navigation in two types of indoor environments including a photo-realistic one. We also demonstrate strong generalization performance through hardware experiments in real indoor spaces with a quadrupedal robot. See https://sites.google.com/princeton.edu/sim-to-lab-to-real for supplementary material.
HumanNeRF: Generalizable Neural Human Radiance Field from Sparse Inputs
Dec 15, 2021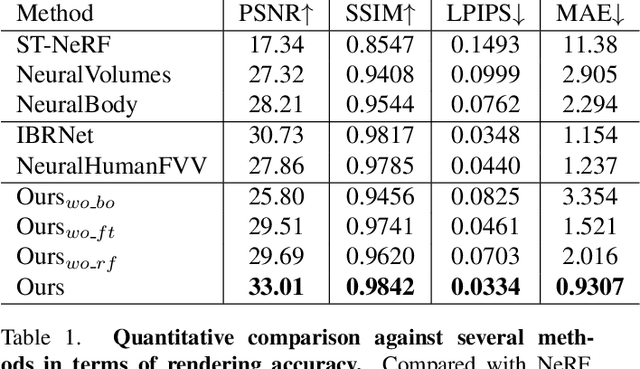
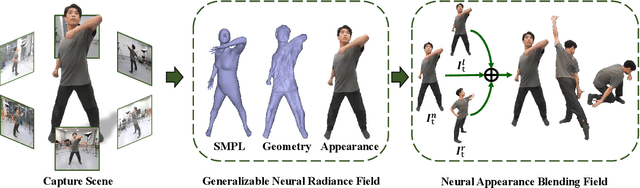
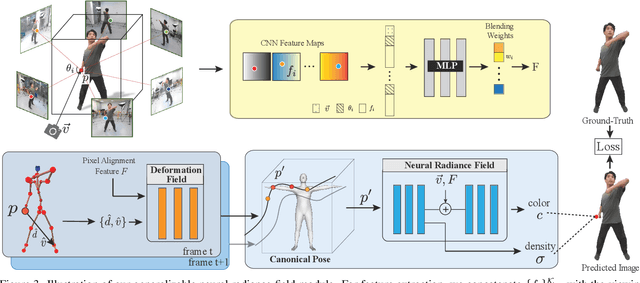
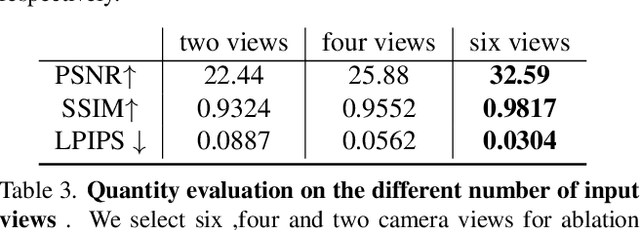
Recent neural human representations can produce high-quality multi-view rendering but require using dense multi-view inputs and costly training. They are hence largely limited to static models as training each frame is infeasible. We present HumanNeRF - a generalizable neural representation - for high-fidelity free-view synthesis of dynamic humans. Analogous to how IBRNet assists NeRF by avoiding per-scene training, HumanNeRF employs an aggregated pixel-alignment feature across multi-view inputs along with a pose embedded non-rigid deformation field for tackling dynamic motions. The raw HumanNeRF can already produce reasonable rendering on sparse video inputs of unseen subjects and camera settings. To further improve the rendering quality, we augment our solution with an appearance blending module for combining the benefits of both neural volumetric rendering and neural texture blending. Extensive experiments on various multi-view dynamic human datasets demonstrate the generalizability and effectiveness of our approach in synthesizing photo-realistic free-view humans under challenging motions and with very sparse camera view inputs.