 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
DronePose: The identification, segmentation, and orientation detection of drones via neural networks
Dec 10, 2021
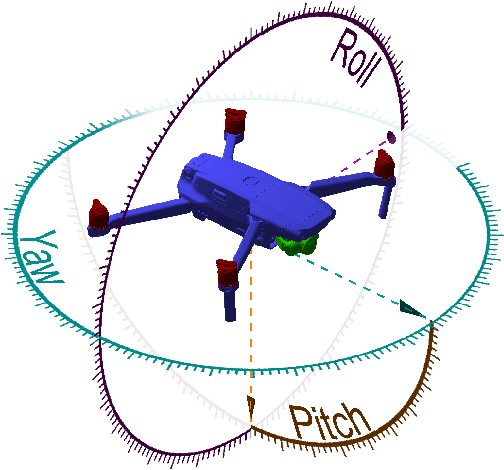
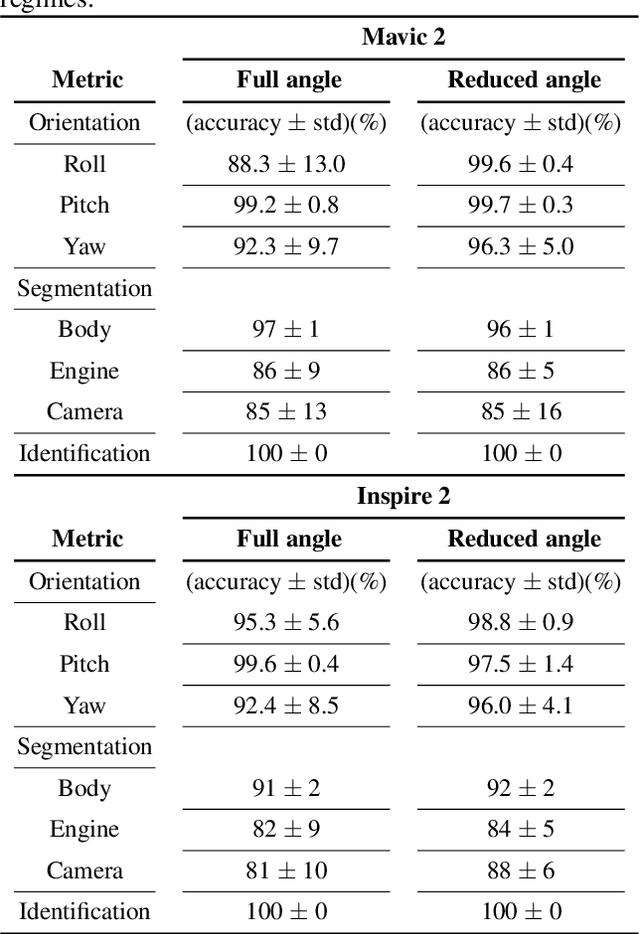
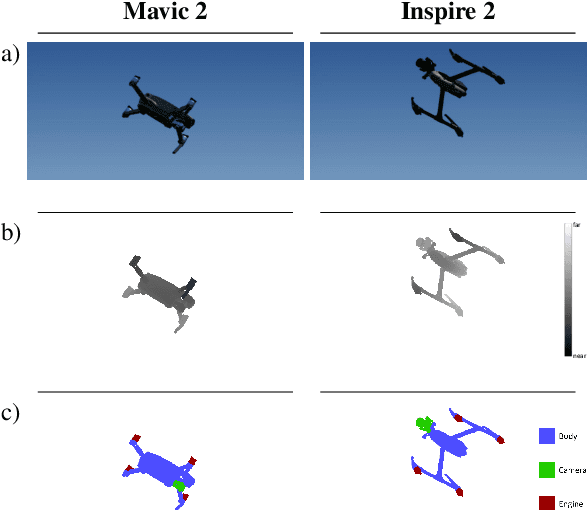

The growing ubiquity of drones has raised concerns over the ability of traditional air-space monitoring technologies to accurately characterise such vehicles. Here, we present a CNN using a decision tree and ensemble structure to fully characterise drones in flight. Our system determines the drone type, orientation (in terms of pitch, roll, and yaw), and performs segmentation to classify different body parts (engines, body, and camera). We also provide a computer model for the rapid generation of large quantities of accurately labelled photo-realistic training data and demonstrate that this data is of sufficient fidelity to allow the system to accurately characterise real drones in flight. Our network will provide a valuable tool in the image processing chain where it may build upon existing drone detection technologies to provide complete drone characterisation over wide areas.
A Multidisciplinary Approach to Optimal Communication and Flight Operation of High Altitude Long Endurance Platform
Mar 01, 2022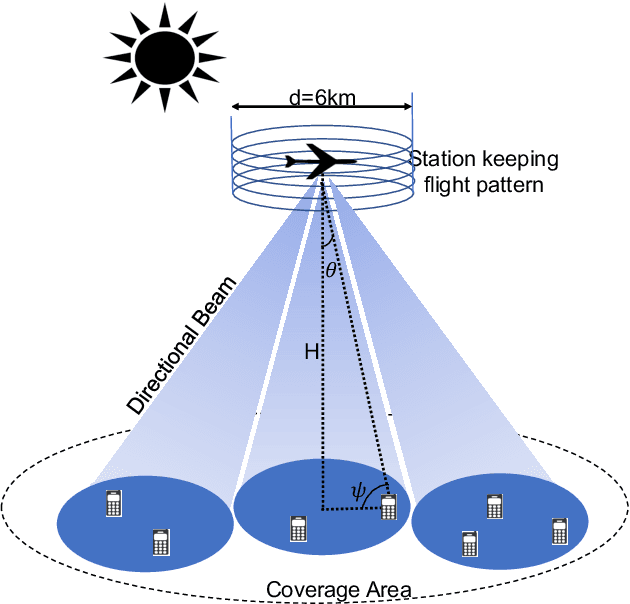
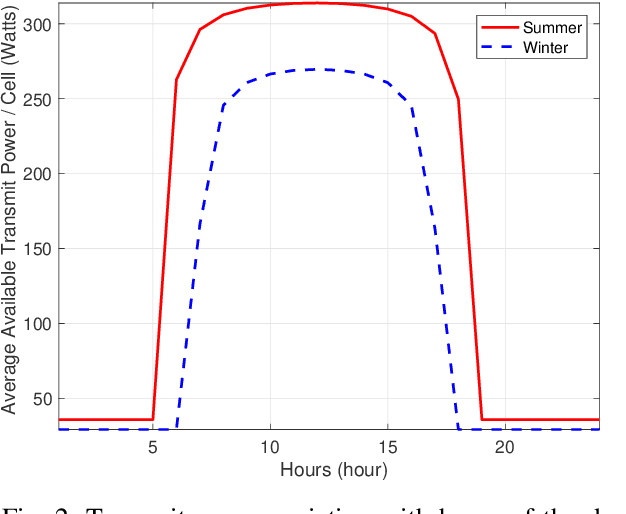
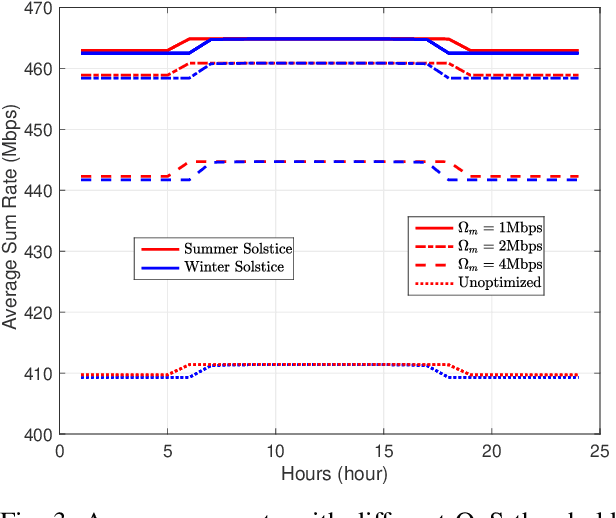
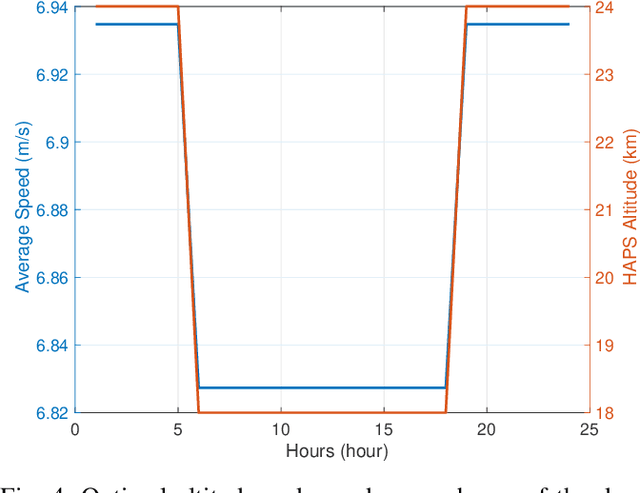
Aerial communication platforms especially stratospheric high altitude pseudo-satellite (HAPS) has the potential to provide/catalyze advanced mobile wireless communication services with its ubiquitous connectivity and ultra-wide coverage radius. Recently, HAPS has gained immense popularity - achieved primarily through self-sufficient energy systems - to render long endurance characteristics. The photo voltaic cells mounted on the aircraft harvest solar energy during the day, which is partially used for communication and station keeping, whereas, the excess is stored in the rechargeable batteries for the night time operation. We carried out an adroit power budgeting to ascertain if the available solar power can simultaneously and efficiently self-sustain the requisite propulsion and communication power expense. We propose an energy optimum trajectory for station-keeping flight and non-orthogonal multiple access (NOMA) for users in multicells served by the directional beams from HAPS communication system. We design optimal power allocation for downlink (DL) NOMA users along with the ideal position and speed of flight with the aim to maximize sum data rate during the day and minimize power expenditure during the night while ensuring quality of service. Our findings reveal the significance of joint design of communication and aerodynamics parameters for optimum energy utilization and resource allocation.
Advances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...
Point Label Aware Superpixels for Multi-species Segmentation of Underwater Imagery
Feb 27, 2022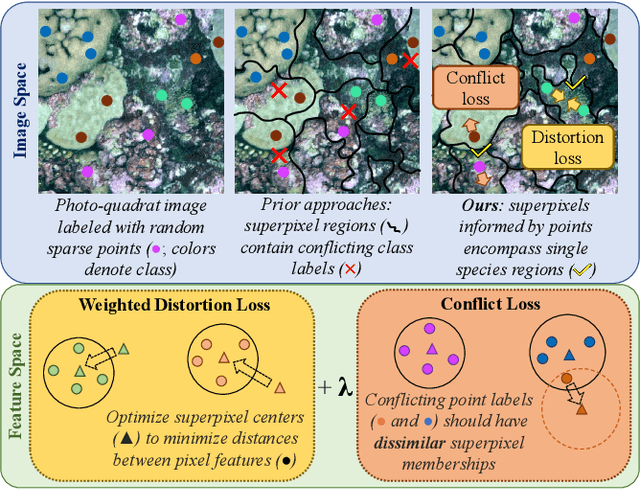
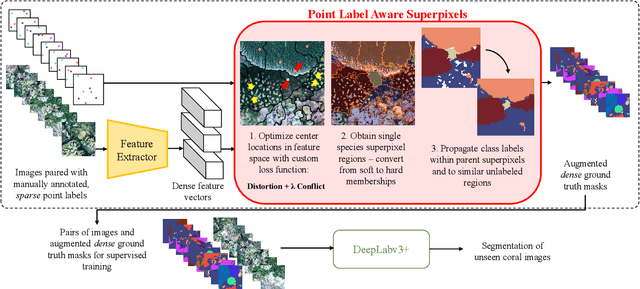
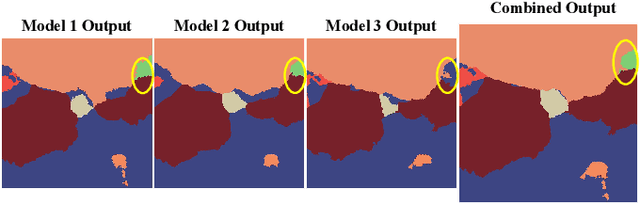
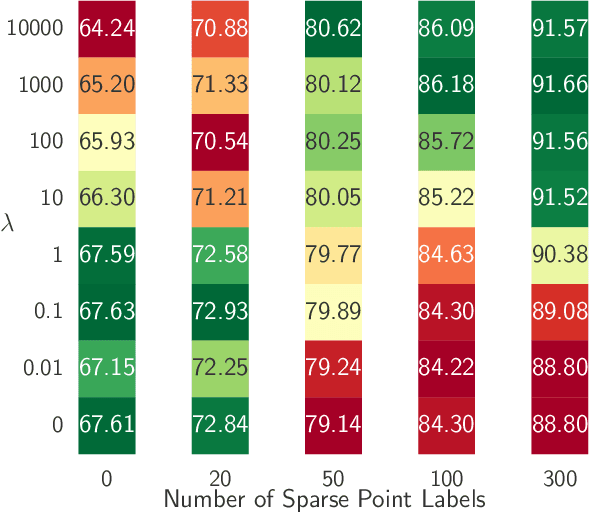
Monitoring coral reefs using underwater vehicles increases the range of marine surveys and availability of historical ecological data by collecting significant quantities of images. Analysis of this imagery can be automated using a model trained to perform semantic segmentation, however it is too costly and time-consuming to densely label images for training supervised models. In this letter, we leverage photo-quadrat imagery labeled by ecologists with sparse point labels. We propose a point label aware method for propagating labels within superpixel regions to obtain augmented ground truth for training a semantic segmentation model. Our point label aware superpixel method utilizes the sparse point labels, and clusters pixels using learned features to accurately generate single-species segments in cluttered, complex coral images. Our method outperforms prior methods on the UCSD Mosaics dataset by 3.62% for pixel accuracy and 8.35% for mean IoU for the label propagation task. Furthermore, our approach reduces computation time reported by previous approaches by 76%. We train a DeepLabv3+ architecture and outperform state-of-the-art for semantic segmentation by 2.91% for pixel accuracy and 9.65% for mean IoU on the UCSD Mosaics dataset and by 4.19% for pixel accuracy and 14.32% mean IoU for the Eilat dataset.
CRD-CGAN: Category-Consistent and Relativistic Constraints for Diverse Text-to-Image Generation
Jul 28, 2021
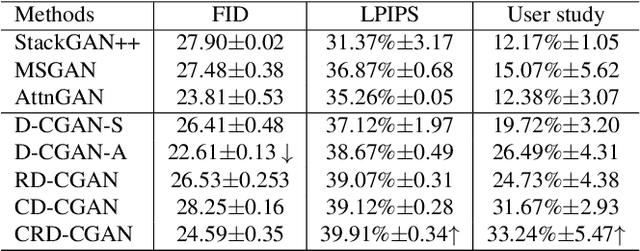

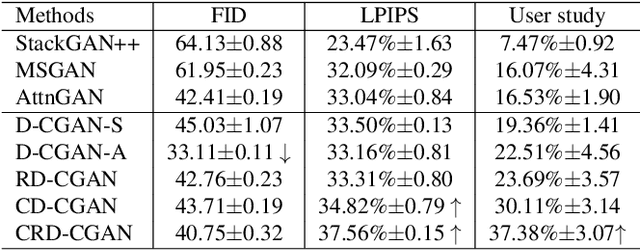
Generating photo-realistic images from a text description is a challenging problem in computer vision. Previous works have shown promising performance to generate synthetic images conditional on text by Generative Adversarial Networks (GANs). In this paper, we focus on the category-consistent and relativistic diverse constraints to optimize the diversity of synthetic images. Based on those constraints, a category-consistent and relativistic diverse conditional GAN (CRD-CGAN) is proposed to synthesize $K$ photo-realistic images simultaneously. We use the attention loss and diversity loss to improve the sensitivity of the GAN to word attention and noises. Then, we employ the relativistic conditional loss to estimate the probability of relatively real or fake for synthetic images, which can improve the performance of basic conditional loss. Finally, we introduce a category-consistent loss to alleviate the over-category issues between K synthetic images. We evaluate our approach using the Birds-200-2011, Oxford-102 flower and MSCOCO 2014 datasets, and the extensive experiments demonstrate superiority of the proposed method in comparison with state-of-the-art methods in terms of photorealistic and diversity of the generated synthetic images.
Simultaneous Human-robot Matching and Routing for Multi-robot Tour Guiding under Time Uncertainty
Jan 25, 2022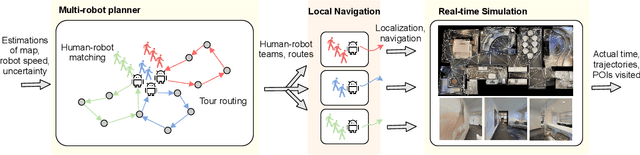

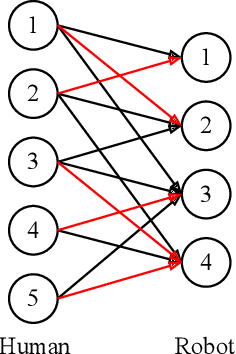
This work presents a framework for multi-robot tour guidance in a partially known environment with uncertainty, such as a museum. In the proposed centralized multi-robot planner, a simultaneous matching and routing problem (SMRP) is formulated to match the humans with robot guides according to their selected places of interest (POIs) and generate the routes and schedules for the robots according to uncertain spatial and time estimation. A large neighborhood search algorithm is developed to efficiently find sub-optimal low-cost solutions for the SMRP. The scalability and optimality of the multi-robot planner are evaluated computationally under different numbers of humans, robots, and POIs. The largest case tested involves 50 robots, 250 humans, and 50 POIs. Then, a photo-realistic multi-robot simulation platform was developed based on Habitat-AI to verify the tour guiding performance in an uncertain indoor environment. Results demonstrate that the proposed centralized tour planner is scalable, makes a smooth trade-off in the plans under different environmental constraints, and can lead to robust performance with inaccurate uncertainty estimations (within a certain margin).
FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning
Aug 18, 2021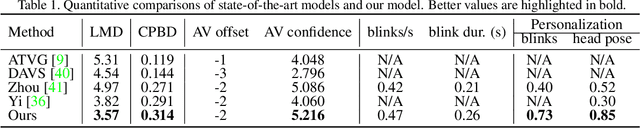
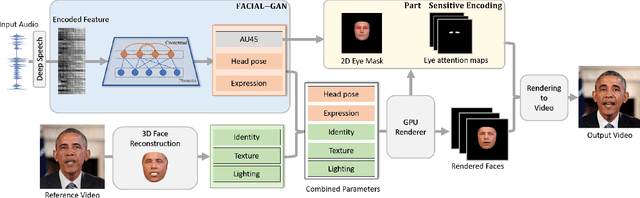
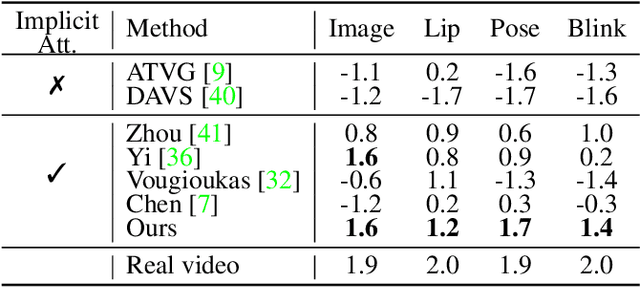
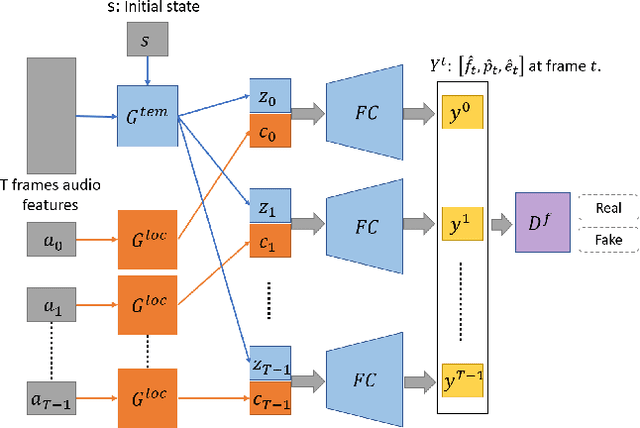
In this paper, we propose a talking face generation method that takes an audio signal as input and a short target video clip as reference, and synthesizes a photo-realistic video of the target face with natural lip motions, head poses, and eye blinks that are in-sync with the input audio signal. We note that the synthetic face attributes include not only explicit ones such as lip motions that have high correlations with speech, but also implicit ones such as head poses and eye blinks that have only weak correlation with the input audio. To model such complicated relationships among different face attributes with input audio, we propose a FACe Implicit Attribute Learning Generative Adversarial Network (FACIAL-GAN), which integrates the phonetics-aware, context-aware, and identity-aware information to synthesize the 3D face animation with realistic motions of lips, head poses, and eye blinks. Then, our Rendering-to-Video network takes the rendered face images and the attention map of eye blinks as input to generate the photo-realistic output video frames. Experimental results and user studies show our method can generate realistic talking face videos with not only synchronized lip motions, but also natural head movements and eye blinks, with better qualities than the results of state-of-the-art methods.
Sim-to-Lab-to-Real: Safe Reinforcement Learning with Shielding and Generalization Guarantees
Feb 10, 2022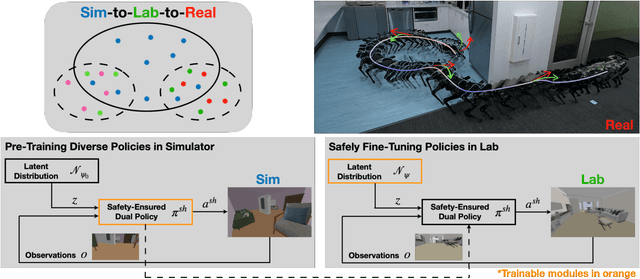

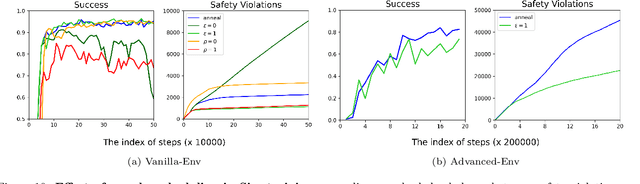
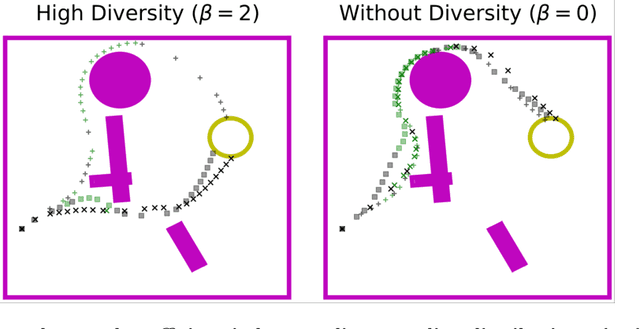
Safety is a critical component of autonomous systems and remains a challenge for learning-based policies to be utilized in the real world. In particular, policies learned using reinforcement learning often fail to generalize to novel environments due to unsafe behavior. In this paper, we propose Sim-to-Lab-to-Real to safely close the reality gap. To improve safety, we apply a dual policy setup where a performance policy is trained using the cumulative task reward and a backup (safety) policy is trained by solving the reach-avoid Bellman Equation based on Hamilton-Jacobi reachability analysis. In Sim-to-Lab transfer, we apply a supervisory control scheme to shield unsafe actions during exploration; in Lab-to-Real transfer, we leverage the Probably Approximately Correct (PAC)-Bayes framework to provide lower bounds on the expected performance and safety of policies in unseen environments. We empirically study the proposed framework for ego-vision navigation in two types of indoor environments including a photo-realistic one. We also demonstrate strong generalization performance through hardware experiments in real indoor spaces with a quadrupedal robot. See https://sites.google.com/princeton.edu/sim-to-lab-to-real for supplementary material.
Multi-Robot Collaborative Perception with Graph Neural Networks
Jan 23, 2022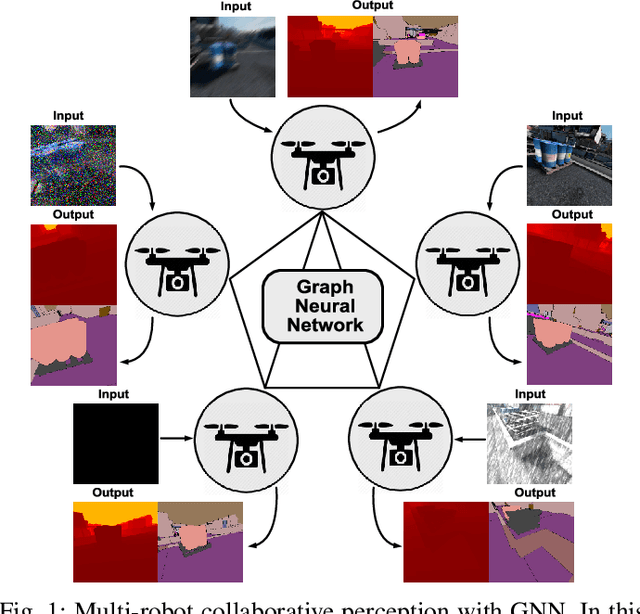

Multi-robot systems such as swarms of aerial robots are naturally suited to offer additional flexibility, resilience, and robustness in several tasks compared to a single robot by enabling cooperation among the agents. To enhance the autonomous robot decision-making process and situational awareness, multi-robot systems have to coordinate their perception capabilities to collect, share, and fuse environment information among the agents in an efficient and meaningful way such to accurately obtain context-appropriate information or gain resilience to sensor noise or failures. In this paper, we propose a general-purpose Graph Neural Network (GNN) with the main goal to increase, in multi-robot perception tasks, single robots' inference perception accuracy as well as resilience to sensor failures and disturbances. We show that the proposed framework can address multi-view visual perception problems such as monocular depth estimation and semantic segmentation. Several experiments both using photo-realistic and real data gathered from multiple aerial robots' viewpoints show the effectiveness of the proposed approach in challenging inference conditions including images corrupted by heavy noise and camera occlusions or failures.
UV Volumes for Real-time Rendering of Editable Free-view Human Performance
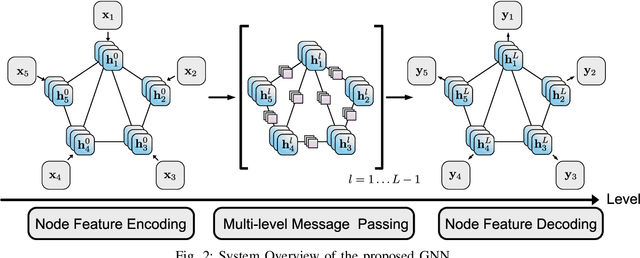
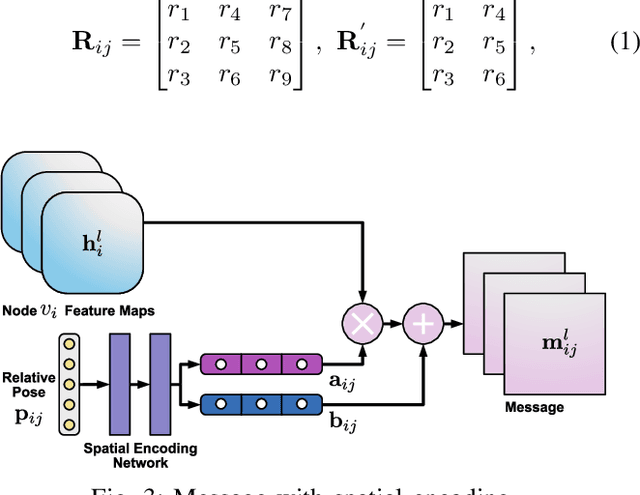
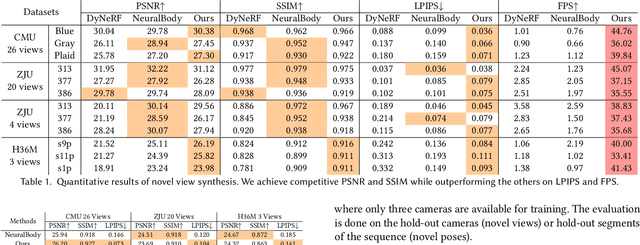
Mar 27, 2022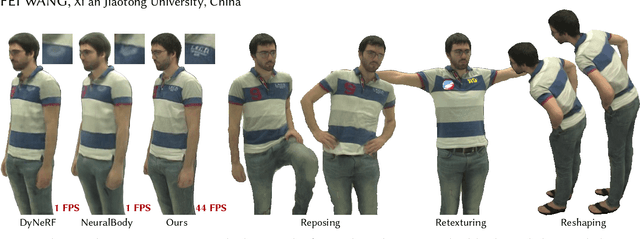
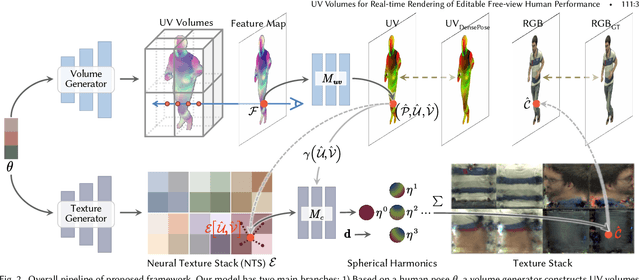

Neural volume rendering has been proven to be a promising method for efficient and photo-realistic rendering of a human performer in free-view, a critical task in many immersive VR/AR applications. However, existing approaches are severely limited by their high computational cost in the rendering process. To solve this problem, we propose the UV Volumes, an approach that can render an editable free-view video of a human performer in real-time. It is achieved by removing the high-frequency (i.e., non-smooth) human textures from the 3D volume and encoding them into a 2D neural texture stack (NTS). The smooth UV volume allows us to employ a much smaller and shallower structure for 3D CNN and MLP, to obtain the density and texture coordinates without losing image details. Meanwhile, the NTS only needs to be queried once for each pixel in the UV image to retrieve its RGB value. For editability, the 3D CNN and MLP decoder can easily fit the function that maps the input structured-and-posed latent codes to the relatively smooth densities and texture coordinates. It gives our model a better generalization ability to handle novel poses and shapes. Furthermore, the use of NST enables new applications, e.g., retexturing. Extensive experiments on CMU Panoptic, ZJU Mocap, and H36M datasets show that our model can render 900 * 500 images in 40 fps on average with comparable photorealism to state-of-the-art methods. The project and supplementary materials are available at https://fanegg.github.io/UV-Volumes.