 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
FaceMap: Towards Unsupervised Face Clustering via Map Equation
Mar 21, 2022
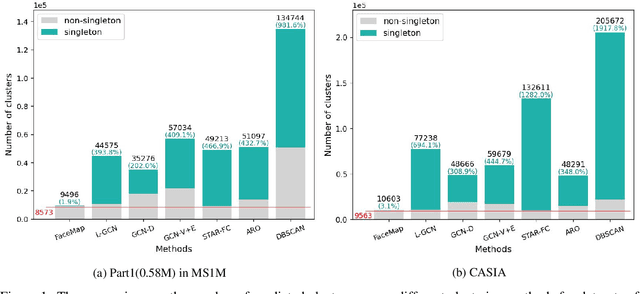
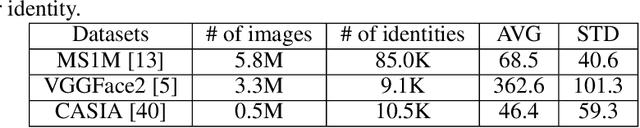
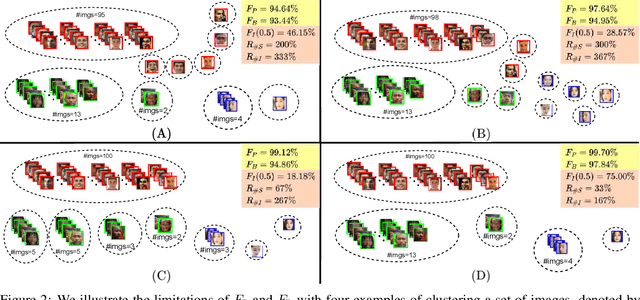

Face clustering is an essential task in computer vision due to the explosion of related applications such as augmented reality or photo album management. The main challenge of this task lies in the imperfectness of similarities among image feature representations. Given an existing feature extraction model, it is still an unresolved problem that how can the inherent characteristics of similarities of unlabelled images be leveraged to improve the clustering performance. Motivated by answering the question, we develop an effective unsupervised method, named as FaceMap, by formulating face clustering as a process of non-overlapping community detection, and minimizing the entropy of information flows on a network of images. The entropy is denoted by the map equation and its minimum represents the least description of paths among images in expectation. Inspired by observations on the ranked transition probabilities in the affinity graph constructed from facial images, we develop an outlier detection strategy to adaptively adjust transition probabilities among images. Experiments with ablation studies demonstrate that FaceMap significantly outperforms existing methods and achieves new state-of-the-arts on three popular large-scale datasets for face clustering, e.g., an absolute improvement of more than $10\%$ and $4\%$ comparing with prior unsupervised and supervised methods respectively in terms of average of Pairwise F-score. Our code is publicly available on github.
Kubric: A scalable dataset generator
Mar 07, 2022

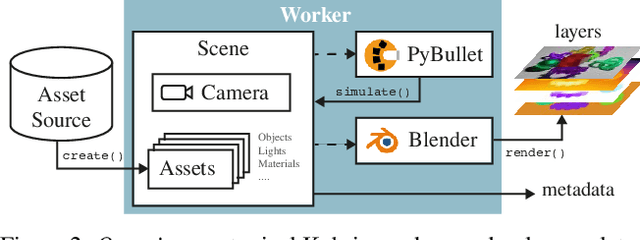
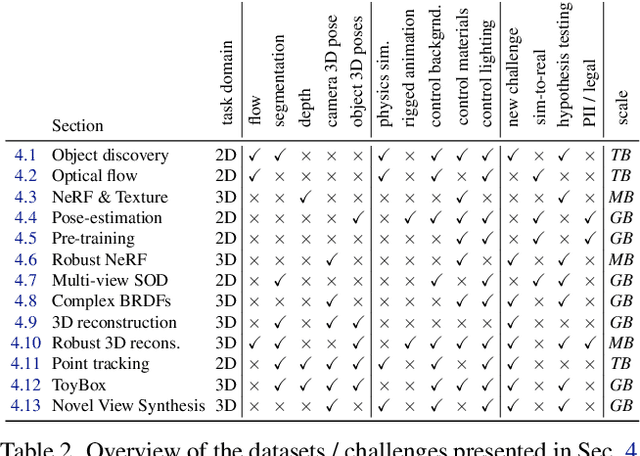
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Discovering Objects that Can Move
Mar 18, 2022
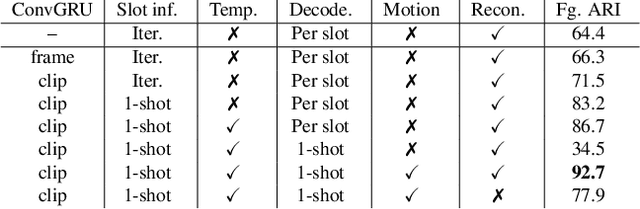
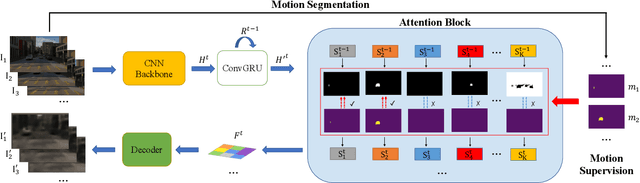
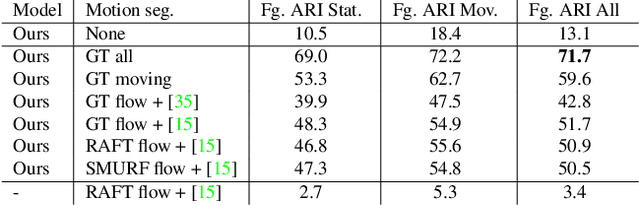
This paper studies the problem of object discovery -- separating objects from the background without manual labels. Existing approaches utilize appearance cues, such as color, texture, and location, to group pixels into object-like regions. However, by relying on appearance alone, these methods fail to separate objects from the background in cluttered scenes. This is a fundamental limitation since the definition of an object is inherently ambiguous and context-dependent. To resolve this ambiguity, we choose to focus on dynamic objects -- entities that can move independently in the world. We then scale the recent auto-encoder based frameworks for unsupervised object discovery from toy synthetic images to complex real-world scenes. To this end, we simplify their architecture, and augment the resulting model with a weak learning signal from general motion segmentation algorithms. Our experiments demonstrate that, despite only capturing a small subset of the objects that move, this signal is enough to generalize to segment both moving and static instances of dynamic objects. We show that our model scales to a newly collected, photo-realistic synthetic dataset with street driving scenarios. Additionally, we leverage ground truth segmentation and flow annotations in this dataset for thorough ablation and evaluation. Finally, our experiments on the real-world KITTI benchmark demonstrate that the proposed approach outperforms both heuristic- and learning-based methods by capitalizing on motion cues.
Distinguishing Natural and Computer-Generated Images using Multi-Colorspace fused EfficientNet
Oct 18, 2021
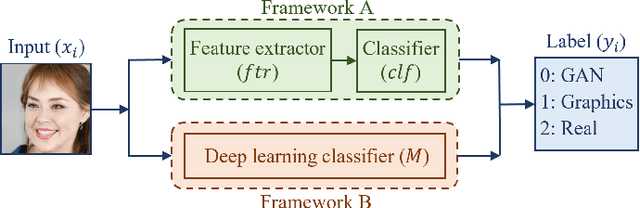
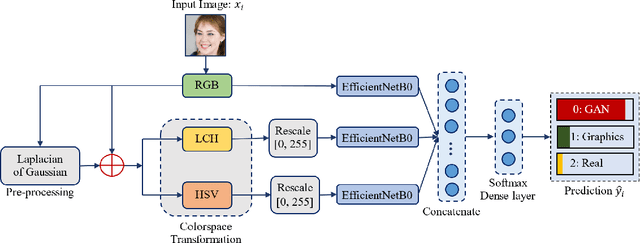
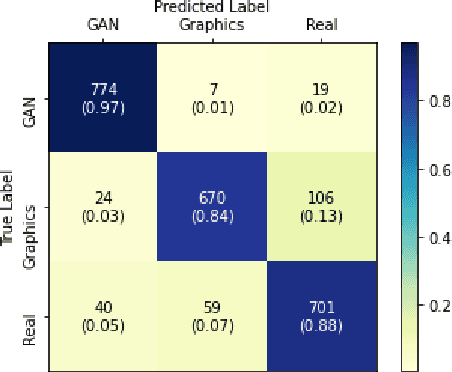
The problem of distinguishing natural images from photo-realistic computer-generated ones either addresses natural images versus computer graphics or natural images versus GAN images, at a time. But in a real-world image forensic scenario, it is highly essential to consider all categories of image generation, since in most cases image generation is unknown. We, for the first time, to our best knowledge, approach the problem of distinguishing natural images from photo-realistic computer-generated images as a three-class classification task classifying natural, computer graphics, and GAN images. For the task, we propose a Multi-Colorspace fused EfficientNet model by parallelly fusing three EfficientNet networks that follow transfer learning methodology where each network operates in different colorspaces, RGB, LCH, and HSV, chosen after analyzing the efficacy of various colorspace transformations in this image forensics problem. Our model outperforms the baselines in terms of accuracy, robustness towards post-processing, and generalizability towards other datasets. We conduct psychophysics experiments to understand how accurately humans can distinguish natural, computer graphics, and GAN images where we could observe that humans find difficulty in classifying these images, particularly the computer-generated images, indicating the necessity of computational algorithms for the task. We also analyze the behavior of our model through visual explanations to understand salient regions that contribute to the model's decision making and compare with manual explanations provided by human participants in the form of region markings, where we could observe similarities in both the explanations indicating the powerful nature of our model to take the decisions meaningfully.
Visual communication of object concepts at different levels of abstraction
Jun 05, 2021

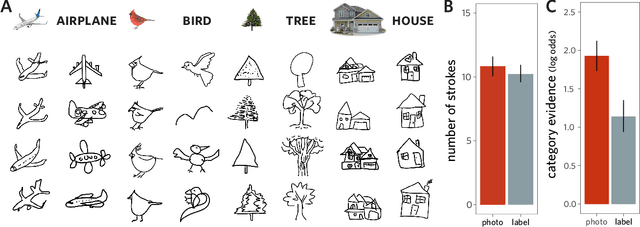
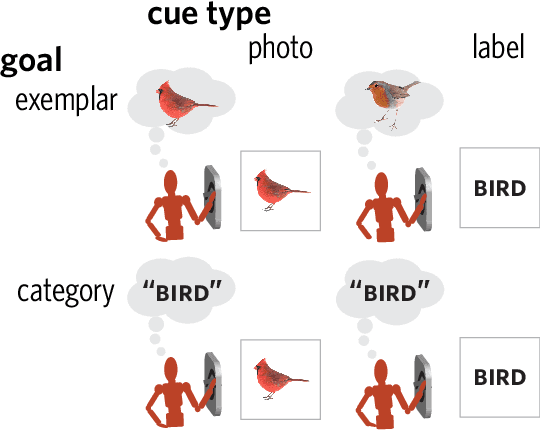
People can produce drawings of specific entities (e.g., Garfield), as well as general categories (e.g., "cat"). What explains this ability to produce such varied drawings of even highly familiar object concepts? We hypothesized that drawing objects at different levels of abstraction depends on both sensory information and representational goals, such that drawings intended to portray a recently seen object preserve more detail than those intended to represent a category. Participants drew objects cued either with a photo or a category label. For each cue type, half the participants aimed to draw a specific exemplar; the other half aimed to draw the category. We found that label-cued category drawings were the most recognizable at the basic level, whereas photo-cued exemplar drawings were the least recognizable. Together, these findings highlight the importance of task context for explaining how people use drawings to communicate visual concepts in different ways.
DronePose: The identification, segmentation, and orientation detection of drones via neural networks
Dec 10, 2021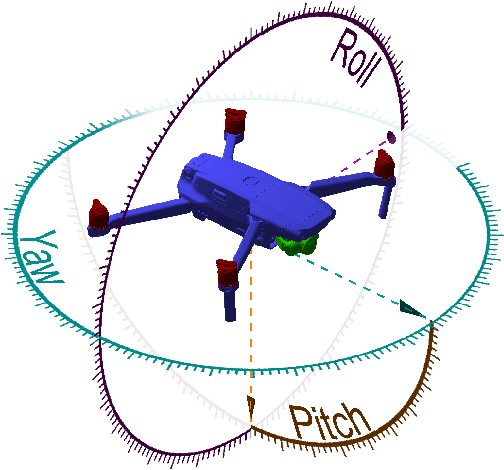
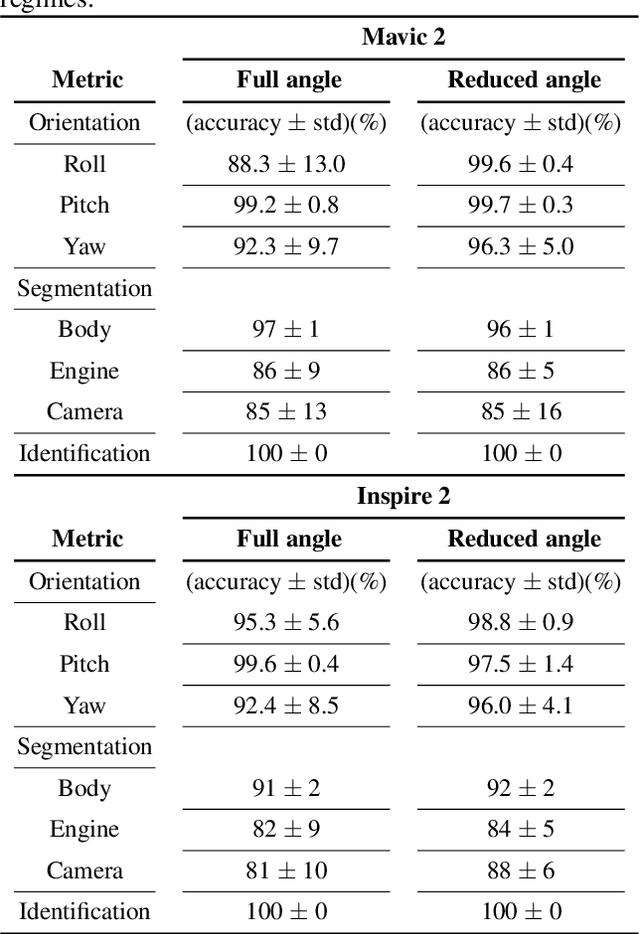
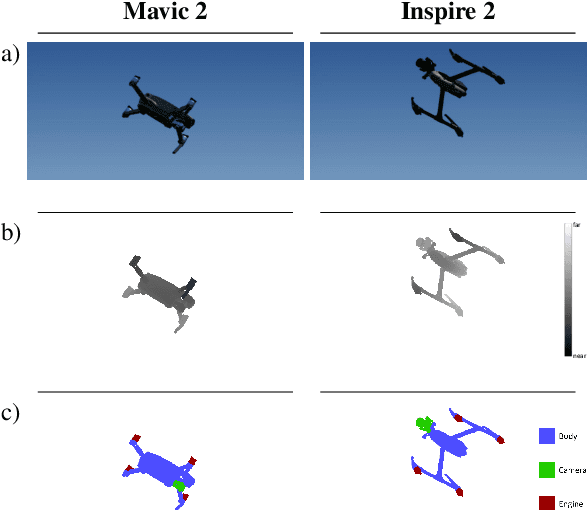

The growing ubiquity of drones has raised concerns over the ability of traditional air-space monitoring technologies to accurately characterise such vehicles. Here, we present a CNN using a decision tree and ensemble structure to fully characterise drones in flight. Our system determines the drone type, orientation (in terms of pitch, roll, and yaw), and performs segmentation to classify different body parts (engines, body, and camera). We also provide a computer model for the rapid generation of large quantities of accurately labelled photo-realistic training data and demonstrate that this data is of sufficient fidelity to allow the system to accurately characterise real drones in flight. Our network will provide a valuable tool in the image processing chain where it may build upon existing drone detection technologies to provide complete drone characterisation over wide areas.
A-Lamp: Adaptive Layout-Aware Multi-Patch Deep Convolutional Neural Network for Photo Aesthetic Assessment
Apr 02, 2017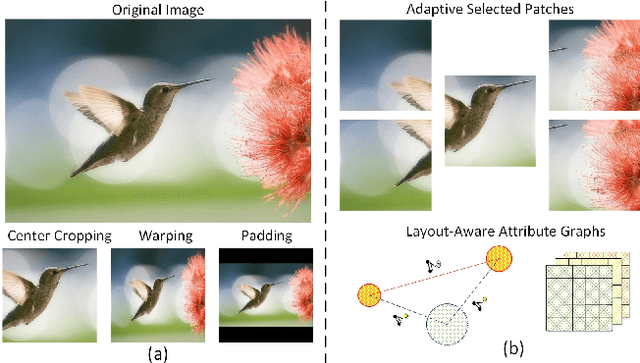
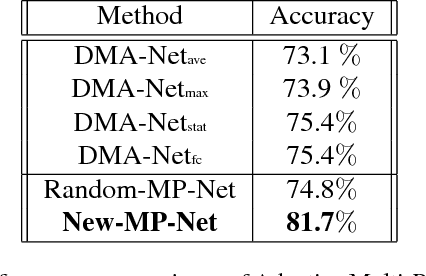
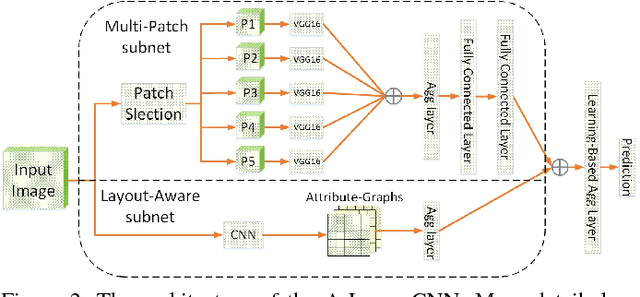
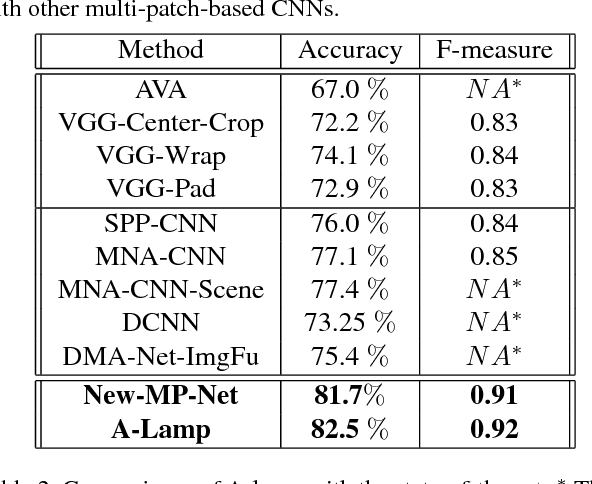
Deep convolutional neural networks (CNN) have recently been shown to generate promising results for aesthetics assessment. However, the performance of these deep CNN methods is often compromised by the constraint that the neural network only takes the fixed-size input. To accommodate this requirement, input images need to be transformed via cropping, warping, or padding, which often alter image composition, reduce image resolution, or cause image distortion. Thus the aesthetics of the original images is impaired because of potential loss of fine grained details and holistic image layout. However, such fine grained details and holistic image layout is critical for evaluating an image's aesthetics. In this paper, we present an Adaptive Layout-Aware Multi-Patch Convolutional Neural Network (A-Lamp CNN) architecture for photo aesthetic assessment. This novel scheme is able to accept arbitrary sized images, and learn from both fined grained details and holistic image layout simultaneously. To enable training on these hybrid inputs, we extend the method by developing a dedicated double-subnet neural network structure, i.e. a Multi-Patch subnet and a Layout-Aware subnet. We further construct an aggregation layer to effectively combine the hybrid features from these two subnets. Extensive experiments on the large-scale aesthetics assessment benchmark (AVA) demonstrate significant performance improvement over the state-of-the-art in photo aesthetic assessment.
A Multidisciplinary Approach to Optimal Communication and Flight Operation of High Altitude Long Endurance Platform
Mar 01, 2022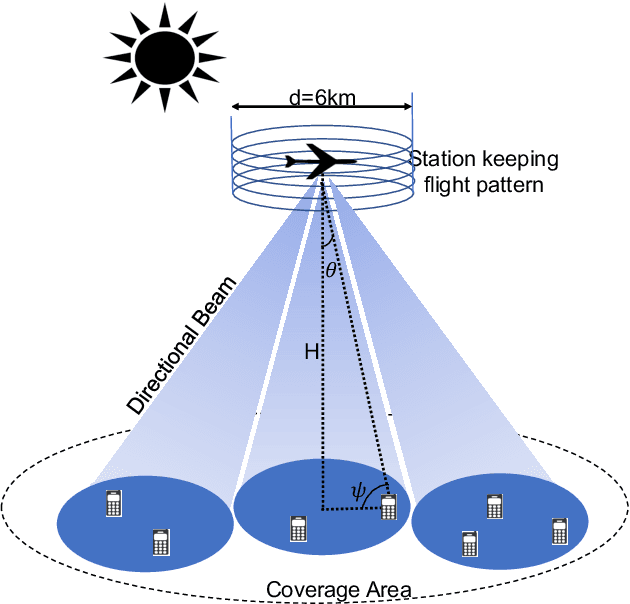
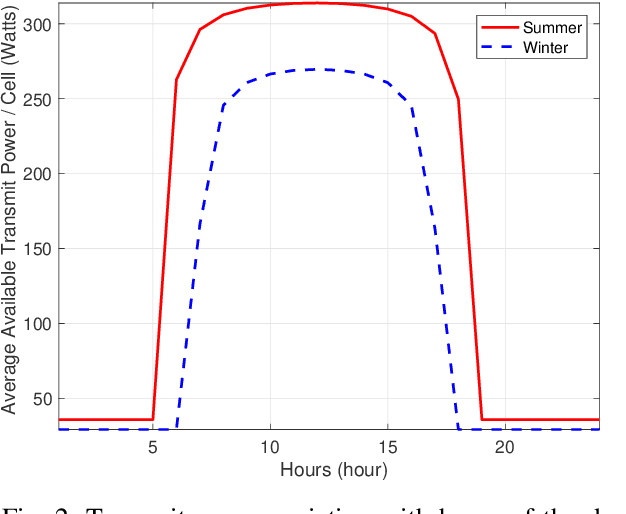
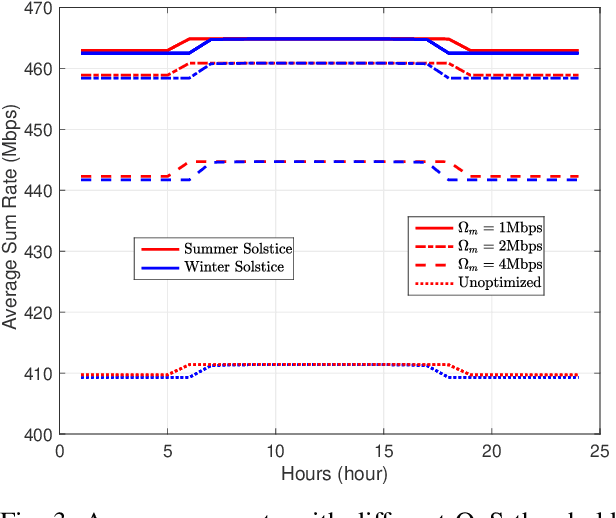
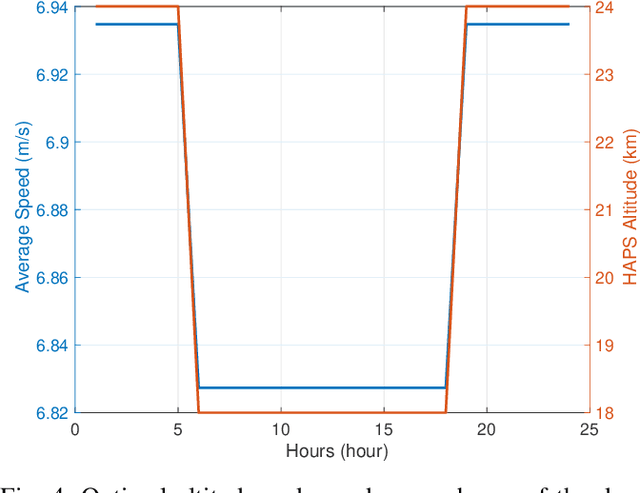
Aerial communication platforms especially stratospheric high altitude pseudo-satellite (HAPS) has the potential to provide/catalyze advanced mobile wireless communication services with its ubiquitous connectivity and ultra-wide coverage radius. Recently, HAPS has gained immense popularity - achieved primarily through self-sufficient energy systems - to render long endurance characteristics. The photo voltaic cells mounted on the aircraft harvest solar energy during the day, which is partially used for communication and station keeping, whereas, the excess is stored in the rechargeable batteries for the night time operation. We carried out an adroit power budgeting to ascertain if the available solar power can simultaneously and efficiently self-sustain the requisite propulsion and communication power expense. We propose an energy optimum trajectory for station-keeping flight and non-orthogonal multiple access (NOMA) for users in multicells served by the directional beams from HAPS communication system. We design optimal power allocation for downlink (DL) NOMA users along with the ideal position and speed of flight with the aim to maximize sum data rate during the day and minimize power expenditure during the night while ensuring quality of service. Our findings reveal the significance of joint design of communication and aerodynamics parameters for optimum energy utilization and resource allocation.
Point Label Aware Superpixels for Multi-species Segmentation of Underwater Imagery
Feb 27, 2022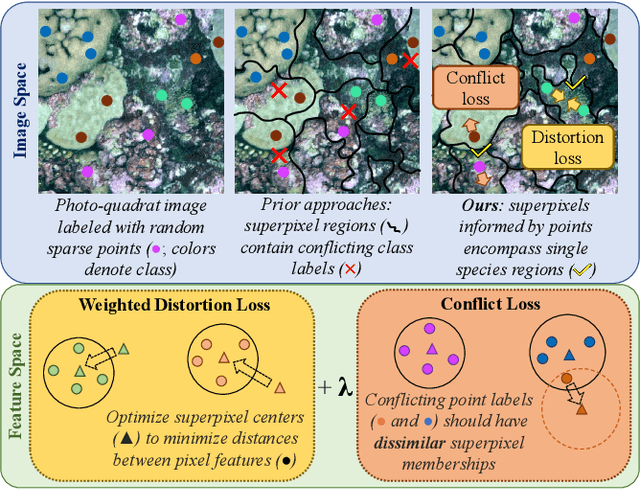
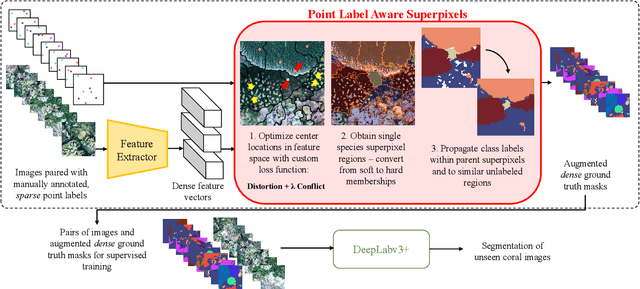
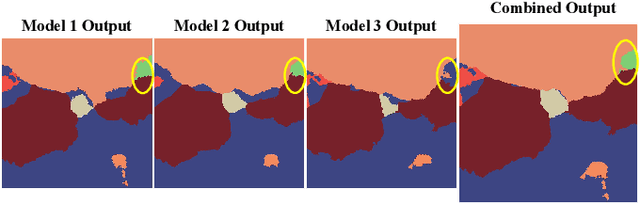
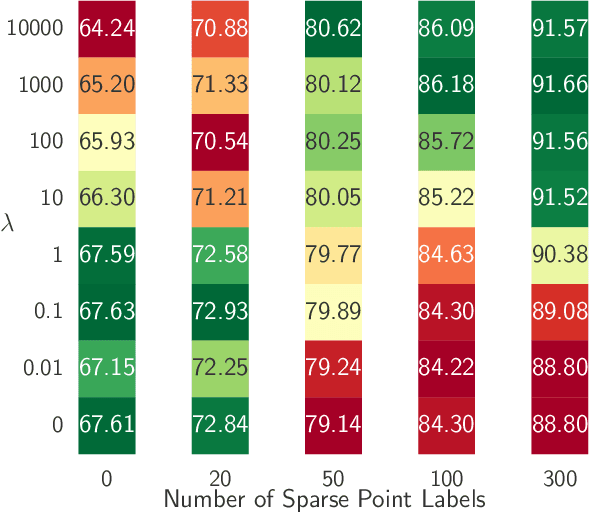
Monitoring coral reefs using underwater vehicles increases the range of marine surveys and availability of historical ecological data by collecting significant quantities of images. Analysis of this imagery can be automated using a model trained to perform semantic segmentation, however it is too costly and time-consuming to densely label images for training supervised models. In this letter, we leverage photo-quadrat imagery labeled by ecologists with sparse point labels. We propose a point label aware method for propagating labels within superpixel regions to obtain augmented ground truth for training a semantic segmentation model. Our point label aware superpixel method utilizes the sparse point labels, and clusters pixels using learned features to accurately generate single-species segments in cluttered, complex coral images. Our method outperforms prior methods on the UCSD Mosaics dataset by 3.62% for pixel accuracy and 8.35% for mean IoU for the label propagation task. Furthermore, our approach reduces computation time reported by previous approaches by 76%. We train a DeepLabv3+ architecture and outperform state-of-the-art for semantic segmentation by 2.91% for pixel accuracy and 9.65% for mean IoU on the UCSD Mosaics dataset and by 4.19% for pixel accuracy and 14.32% mean IoU for the Eilat dataset.
Advances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...