 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
NeuralHumanFVV: Real-Time Neural Volumetric Human Performance Rendering using RGB Cameras
Mar 13, 2021


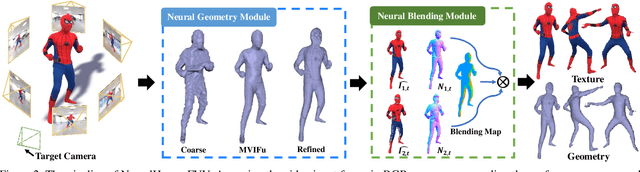
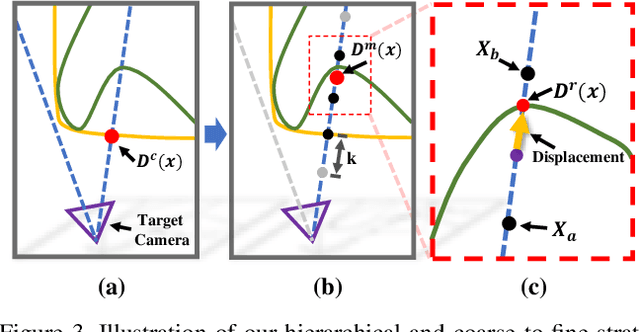
4D reconstruction and rendering of human activities is critical for immersive VR/AR experience.Recent advances still fail to recover fine geometry and texture results with the level of detail present in the input images from sparse multi-view RGB cameras. In this paper, we propose NeuralHumanFVV, a real-time neural human performance capture and rendering system to generate both high-quality geometry and photo-realistic texture of human activities in arbitrary novel views. We propose a neural geometry generation scheme with a hierarchical sampling strategy for real-time implicit geometry inference, as well as a novel neural blending scheme to generate high resolution (e.g., 1k) and photo-realistic texture results in the novel views. Furthermore, we adopt neural normal blending to enhance geometry details and formulate our neural geometry and texture rendering into a multi-task learning framework. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality geometry and photo-realistic free view-point reconstruction for challenging human performances.
Semi-Supervised Super-Resolution
Apr 19, 2022
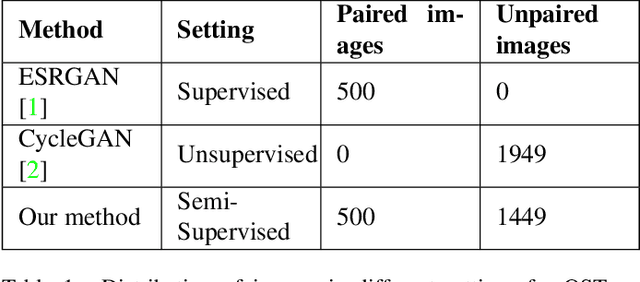
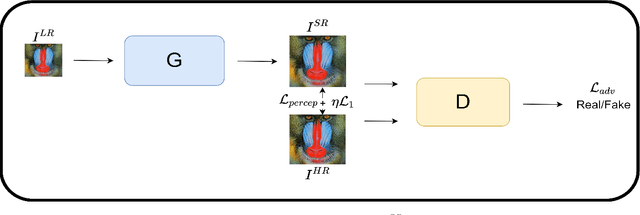
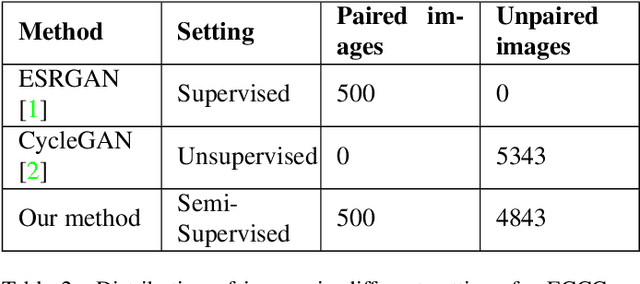
Super-Resolution is the technique to improve the quality of a low-resolution photo by boosting its plausible resolution. The computer vision community has extensively explored the area of Super-Resolution. However, previous Super-Resolution methods require vast amounts of data for training which becomes problematic in domains where very few low-resolution, high-resolution pairs might be available. One such area is statistical downscaling, where super-resolution is increasingly being used to obtain high-resolution climate information from low-resolution data. Acquiring high-resolution climate data is extremely expensive and challenging. To reduce the cost of generating high-resolution climate information, Super-Resolution algorithms should be able to train with a limited number of low-resolution, high-resolution pairs. This paper tries to solve the aforementioned problem by introducing a semi-supervised way to perform super-resolution that can generate sharp, high-resolution images with as few as 500 paired examples. The proposed semi-supervised technique can be used as a plug-and-play module with any supervised GAN-based Super-Resolution method to enhance its performance. We quantitatively and qualitatively analyze the performance of the proposed model and compare it with completely supervised methods as well as other unsupervised techniques. Comprehensive evaluations show the superiority of our method over other methods on different metrics. We also offer the applicability of our approach in statistical downscaling to obtain high-resolution climate images.
Visual-based Safe Landing for UAVs in Populated Areas: Real-time Validation in Virtual Environments
Mar 25, 2022

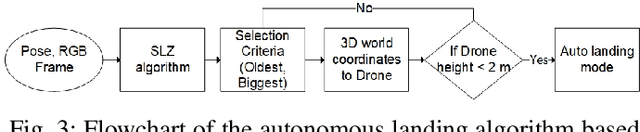

Safe autonomous landing for Unmanned Aerial Vehicles (UAVs) in populated areas is a crucial aspect for successful urban deployment, particularly in emergency landing situations. Nonetheless, validating autonomous landing in real scenarios is a challenging task involving a high risk of injuring people. In this work, we propose a framework for real-time safe and thorough evaluation of vision-based autonomous landing in populated scenarios, using photo-realistic virtual environments. We propose to use the Unreal graphics engine coupled with the AirSim plugin for drone's simulation, and evaluate autonomous landing strategies based on visual detection of Safe Landing Zones (SLZ) in populated scenarios. Then, we study two different criteria for selecting the "best" SLZ, and evaluate them during autonomous landing of a virtual drone in different scenarios and conditions, under different distributions of people in urban scenes, including moving people. We evaluate different metrics to quantify the performance of the landing strategies, establishing a baseline for comparison with future works in this challenging task, and analyze them through an important number of randomized iterations. The study suggests that the use of the autonomous landing algorithms considerably helps to prevent accidents involving humans, which may allow to unleash the full potential of drones in urban environments near to people.
Exploring to establish an appropriate model for image aesthetic assessment via CNN-based RSRL: An empirical study
Jun 28, 2021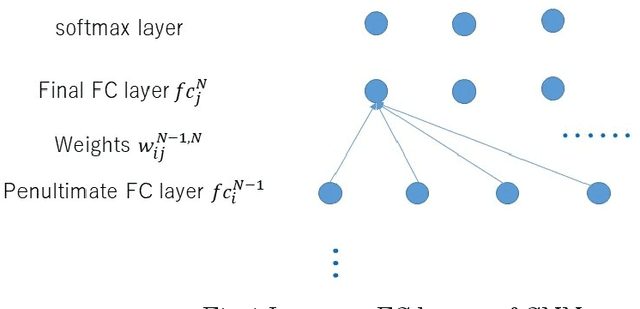

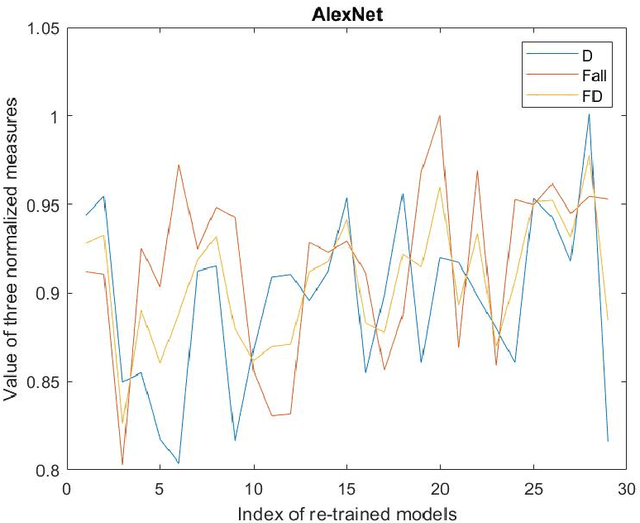
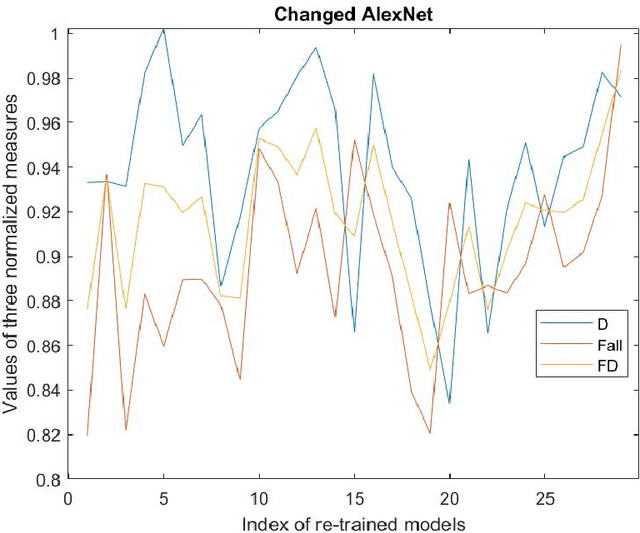
To establish an appropriate model for photo aesthetic assessment, in this paper, a D-measure which reflects the disentanglement degree of the final layer FC nodes of CNN is introduced. By combining F-measure with D-measure to obtain a FD measure, an algorithm of determining the optimal model from the multiple photo score prediction models generated by CNN-based repetitively self-revised learning(RSRL) is proposed. Furthermore, the first fixation perspective(FFP) and the assessment interest region(AIR) of the models are defined and calculated. The experimental results show that the FD measure is effective for establishing the appropriate model from the multiple score prediction models with different CNN structures. Moreover, the FD-determined optimal models with the comparatively high FD always have the FFP an AIR which are close to the human's aesthetic perception when enjoying photos.
Recognizing and Curating Photo Albums via Event-Specific Image Importance
Jul 19, 2017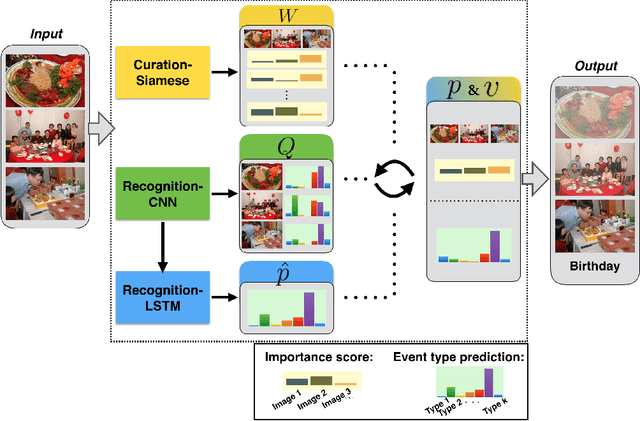
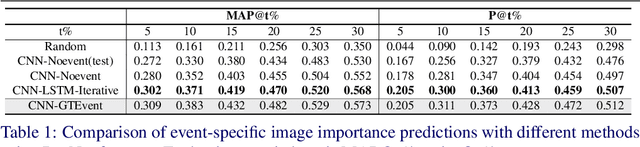
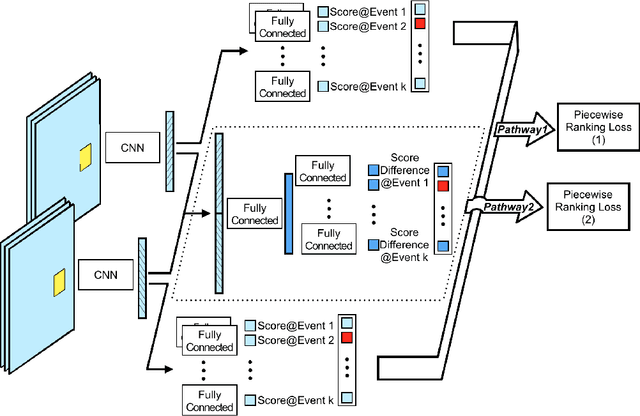
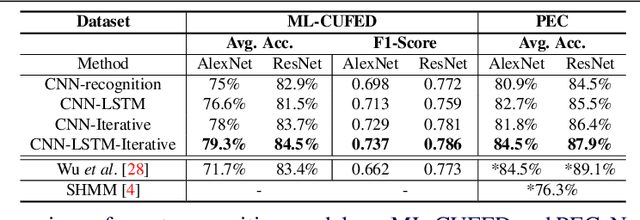
Automatic organization of personal photos is a problem with many real world ap- plications, and can be divided into two main tasks: recognizing the event type of the photo collection, and selecting interesting images from the collection. In this paper, we attempt to simultaneously solve both tasks: album-wise event recognition and image- wise importance prediction. We collected an album dataset with both event type labels and image importance labels, refined from an existing CUFED dataset. We propose a hybrid system consisting of three parts: A siamese network-based event-specific image importance prediction, a Convolutional Neural Network (CNN) that recognizes the event type, and a Long Short-Term Memory (LSTM)-based sequence level event recognizer. We propose an iterative updating procedure for event type and image importance score prediction. We experimentally verified that image importance score prediction and event type recognition can each help the performance of the other.
FlexIT: Towards Flexible Semantic Image Translation
Mar 09, 2022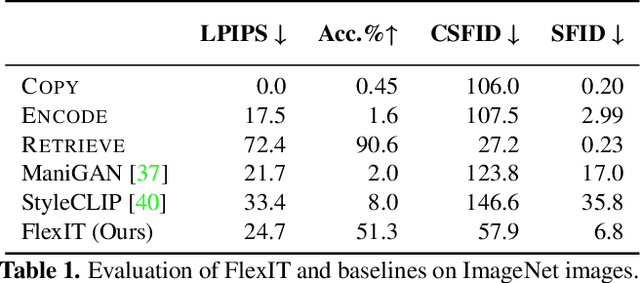
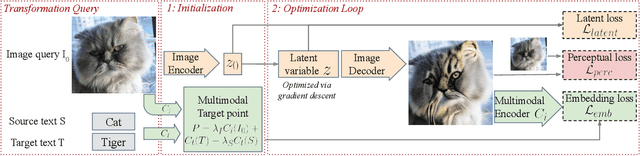

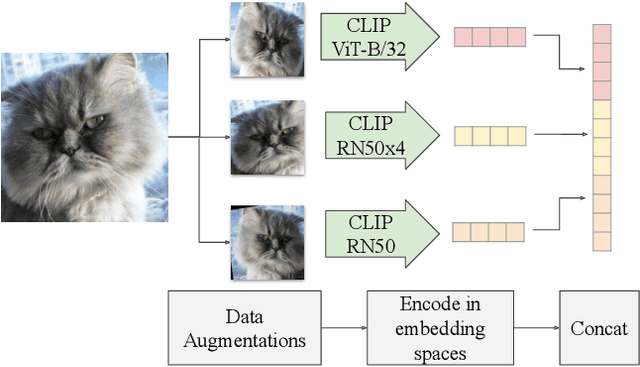
Deep generative models, like GANs, have considerably improved the state of the art in image synthesis, and are able to generate near photo-realistic images in structured domains such as human faces. Based on this success, recent work on image editing proceeds by projecting images to the GAN latent space and manipulating the latent vector. However, these approaches are limited in that only images from a narrow domain can be transformed, and with only a limited number of editing operations. We propose FlexIT, a novel method which can take any input image and a user-defined text instruction for editing. Our method achieves flexible and natural editing, pushing the limits of semantic image translation. First, FlexIT combines the input image and text into a single target point in the CLIP multimodal embedding space. Via the latent space of an auto-encoder, we iteratively transform the input image toward the target point, ensuring coherence and quality with a variety of novel regularization terms. We propose an evaluation protocol for semantic image translation, and thoroughly evaluate our method on ImageNet. Code will be made publicly available.
High-fidelity Face Tracking for AR/VR via Deep Lighting Adaptation
Mar 29, 2021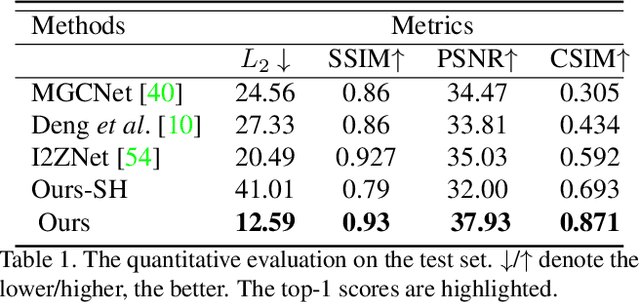
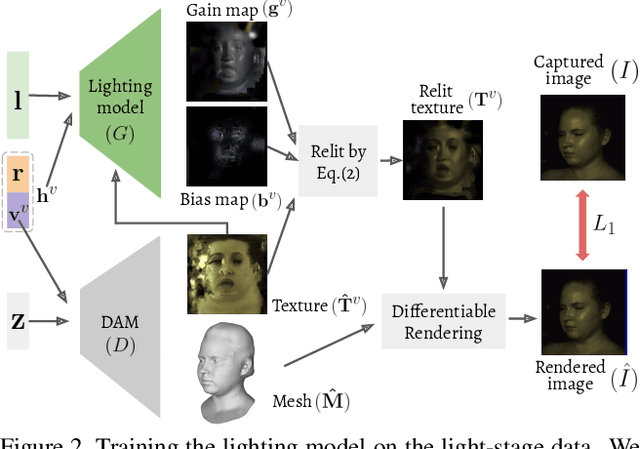
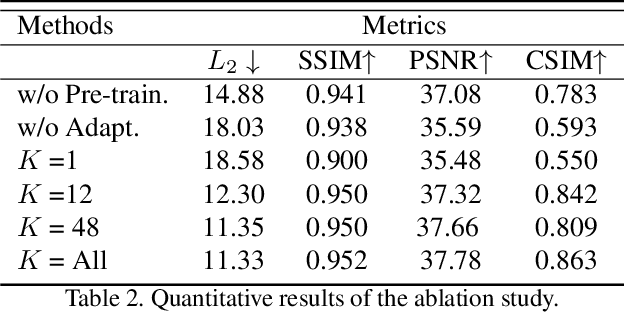

3D video avatars can empower virtual communications by providing compression, privacy, entertainment, and a sense of presence in AR/VR. Best 3D photo-realistic AR/VR avatars driven by video, that can minimize uncanny effects, rely on person-specific models. However, existing person-specific photo-realistic 3D models are not robust to lighting, hence their results typically miss subtle facial behaviors and cause artifacts in the avatar. This is a major drawback for the scalability of these models in communication systems (e.g., Messenger, Skype, FaceTime) and AR/VR. This paper addresses previous limitations by learning a deep learning lighting model, that in combination with a high-quality 3D face tracking algorithm, provides a method for subtle and robust facial motion transfer from a regular video to a 3D photo-realistic avatar. Extensive experimental validation and comparisons to other state-of-the-art methods demonstrate the effectiveness of the proposed framework in real-world scenarios with variability in pose, expression, and illumination. Please visit https://www.youtube.com/watch?v=dtz1LgZR8cc for more results. Our project page can be found at https://www.cs.rochester.edu/u/lchen63.
Markedness in Visual Semantic AI
May 23, 2022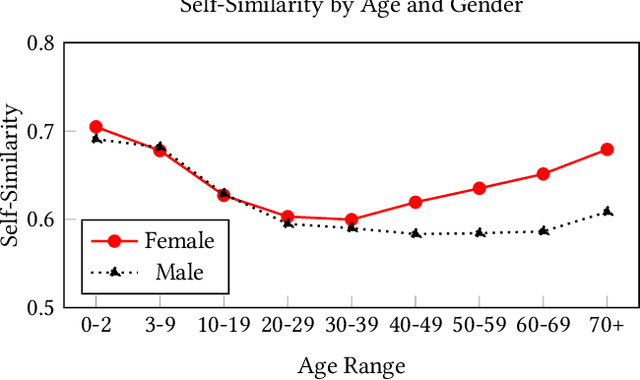
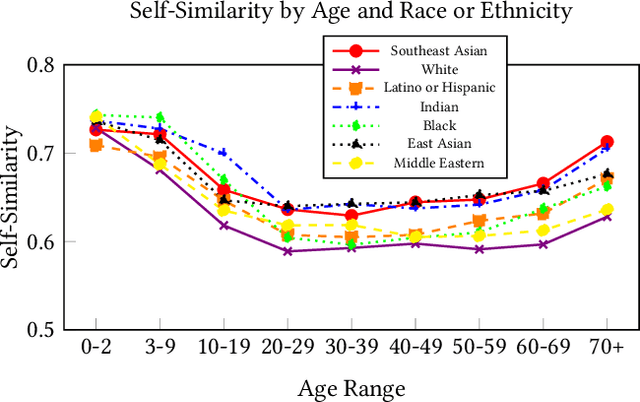

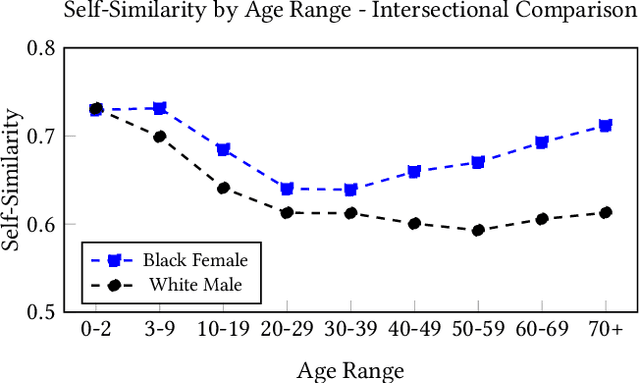
We evaluate the state-of-the-art multimodal "visual semantic" model CLIP ("Contrastive Language Image Pretraining") for biases related to the marking of age, gender, and race or ethnicity. Given the option to label an image as "a photo of a person" or to select a label denoting race or ethnicity, CLIP chooses the "person" label 47.9% of the time for White individuals, compared with 5.0% or less for individuals who are Black, East Asian, Southeast Asian, Indian, or Latino or Hispanic. The model is more likely to rank the unmarked "person" label higher than labels denoting gender for Male individuals (26.7% of the time) vs. Female individuals (15.2% of the time). Age affects whether an individual is marked by the model: Female individuals under the age of 20 are more likely than Male individuals to be marked with a gender label, but less likely to be marked with an age label, while Female individuals over the age of 40 are more likely to be marked based on age than Male individuals. We also examine the self-similarity (mean pairwise cosine similarity) for each social group, where higher self-similarity denotes greater attention directed by CLIP to the shared characteristics (age, race, or gender) of the social group. As age increases, the self-similarity of representations of Female individuals increases at a higher rate than for Male individuals, with the disparity most pronounced at the "more than 70" age range. All ten of the most self-similar social groups are individuals under the age of 10 or over the age of 70, and six of the ten are Female individuals. Existing biases of self-similarity and markedness between Male and Female gender groups are further exacerbated when the groups compared are individuals who are White and Male and individuals who are Black and Female. Results indicate that CLIP reflects the biases of the language and society which produced its training data.
Learning-by-Novel-View-Synthesis for Full-Face Appearance-based 3D Gaze Estimation
Jan 23, 2022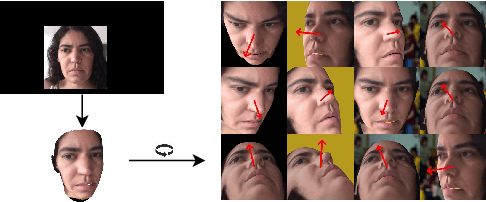
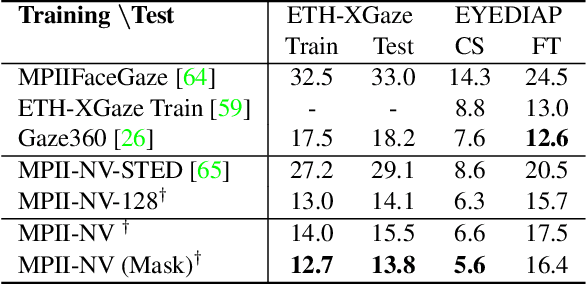

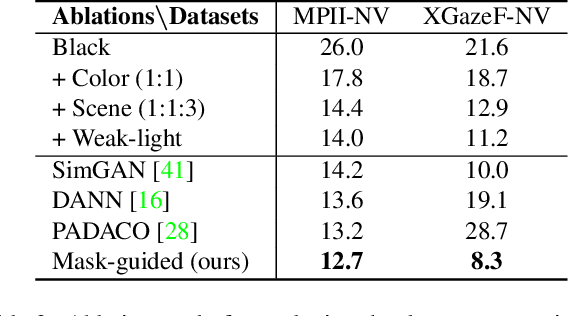
Despite recent advances in appearance-based gaze estimation techniques, the need for training data that covers the target head pose and gaze distribution remains a crucial challenge for practical deployment. This work examines a novel approach for synthesizing gaze estimation training data based on monocular 3D face reconstruction. Unlike prior works using multi-view reconstruction, photo-realistic CG models, or generative neural networks, our approach can manipulate and extend the head pose range of existing training data without any additional requirements. We introduce a projective matching procedure to align the reconstructed 3D facial mesh to the camera coordinate system and synthesize face images with accurate gaze labels. We also propose a mask-guided gaze estimation model and data augmentation strategies to further improve the estimation accuracy by taking advantage of the synthetic training data. Experiments using multiple public datasets show that our approach can significantly improve the estimation performance on challenging cross-dataset settings with non-overlapping gaze distributions.
Exploring to establish an appropriate model for mage aesthetic assessment via CNN-based RSRL: An empirical study
Jun 07, 2021To establish an appropriate model for photo aesthetic assessment, in this paper, a D-measure which reflects the disentanglement degree of the final layer FC nodes of CNN is introduced. By combining F-measure with D-measure to obtain a FD measure, an algorithm of determining the optimal model from the multiple photo score prediction models generated by CNN-based repetitively self-revised learning(RSRL) is proposed. Furthermore, the first fixation perspective(FFP) and the assessment interest region(AIR) of the models are defined and calculated. The experimental results show that the FD measure is effective for establishing the appropriate model from the multiple score prediction models with different CNN structures. Moreover, the FD-determined optimal models with the comparatively high FD always have the FFP an AIR which are close to the human's aesthetic perception when enjoying photos.