 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Exposure: A White-Box Photo Post-Processing Framework
Feb 06, 2018
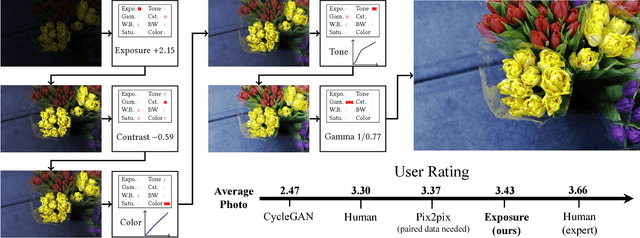


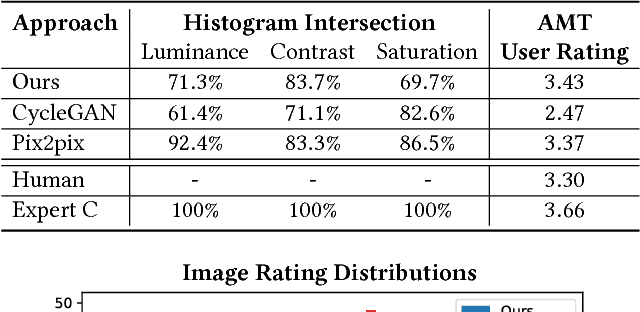
Retouching can significantly elevate the visual appeal of photos, but many casual photographers lack the expertise to do this well. To address this problem, previous works have proposed automatic retouching systems based on supervised learning from paired training images acquired before and after manual editing. As it is difficult for users to acquire paired images that reflect their retouching preferences, we present in this paper a deep learning approach that is instead trained on unpaired data, namely a set of photographs that exhibits a retouching style the user likes, which is much easier to collect. Our system is formulated using deep convolutional neural networks that learn to apply different retouching operations on an input image. Network training with respect to various types of edits is enabled by modeling these retouching operations in a unified manner as resolution-independent differentiable filters. To apply the filters in a proper sequence and with suitable parameters, we employ a deep reinforcement learning approach that learns to make decisions on what action to take next, given the current state of the image. In contrast to many deep learning systems, ours provides users with an understandable solution in the form of conventional retouching edits, rather than just a "black-box" result. Through quantitative comparisons and user studies, we show that this technique generates retouching results consistent with the provided photo set.
Animatable Neural Radiance Fields from Monocular RGB-D
Apr 04, 2022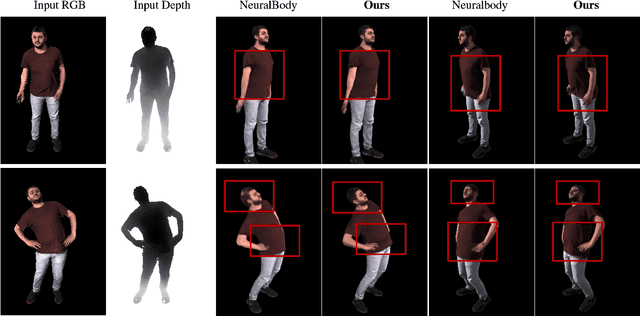
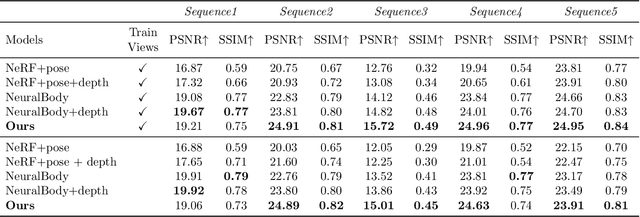
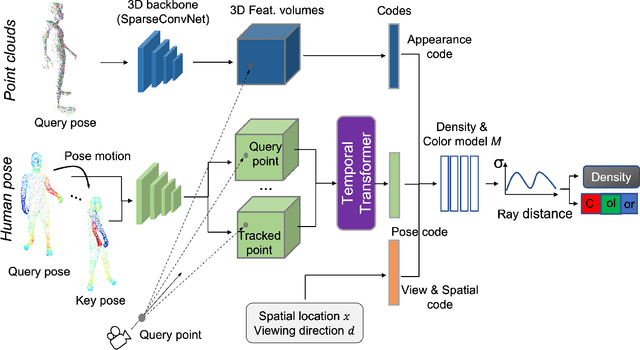

This paper aims at representing animatable photo-realistic humans under novel views and poses. Recent work has shown significant progress with dynamic scenes by exploring shared canonical neural radiance fields. However learning a user-controlled model for novel poses remains a challenging task. To tackle this problem, we introduce a novel method to integrate observations across frames and encode the appearance at each individual frame by utilizing the human pose that models the body shape and point clouds which cover partial part of the human as the input. Specifically, our method simultaneously learns a shared set of latent codes anchored to the human pose among frames, and learns an appearance-dependent code anchored to incomplete point clouds generated by monocular RGB-D at each frame. A human pose-based code models the shape of the performer whereas a point cloud based code predicts details and reasons about missing structures at the unseen poses. To further recover non-visible regions in query frames, we utilize a temporal transformer to integrate features of points in query frames and tracked body points from automatically-selected key frames. Experiments on various sequences of humans in motion show that our method significantly outperforms existing works under unseen poses and novel views given monocular RGB-D videos as input.
DrawingInStyles: Portrait Image Generation and Editing with Spatially Conditioned StyleGAN
Mar 05, 2022

The research topic of sketch-to-portrait generation has witnessed a boost of progress with deep learning techniques. The recently proposed StyleGAN architectures achieve state-of-the-art generation ability but the original StyleGAN is not friendly for sketch-based creation due to its unconditional generation nature. To address this issue, we propose a direct conditioning strategy to better preserve the spatial information under the StyleGAN framework. Specifically, we introduce Spatially Conditioned StyleGAN (SC-StyleGAN for short), which explicitly injects spatial constraints to the original StyleGAN generation process. We explore two input modalities, sketches and semantic maps, which together allow users to express desired generation results more precisely and easily. Based on SC-StyleGAN, we present DrawingInStyles, a novel drawing interface for non-professional users to easily produce high-quality, photo-realistic face images with precise control, either from scratch or editing existing ones. Qualitative and quantitative evaluations show the superior generation ability of our method to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.
Changing the Image Memorability: From Basic Photo Editing to GANs
Nov 15, 2018

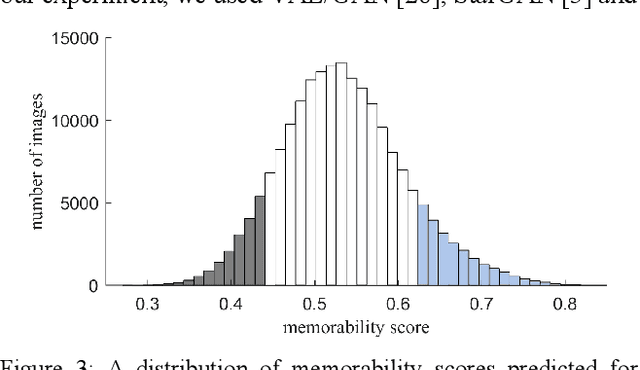
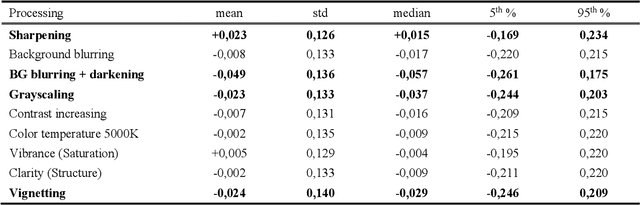
Memorability is considered to be an important characteristic of visual content, whereas for advertisement and educational purposes it is the most important one. Despite numerous studies on understanding and predicting image memorability, there are almost no achievements in memorability modification. In this work, we study two possible approaches to image modification which likely may influence memorability. The visual features which influence memorability directly stay unknown till now, hence it is impossible to control it manually. As a solution, we let GAN learn it deeply using labeled data, and then use it for conditional generation of new images. By analogy with algorithms which edit facial attributes, we consider memorability as yet another attribute and operate with it in the same way. Obtained data is also interesting for analysis, simply because there are no real-world examples of successful change of image memorability while preserving its other attributes. We believe this may give many new answers to the question "what makes an image memorable?" Apart from that we also study the influence of conventional photo-editing tools (Photoshop, Instagram, etc.) used daily by a wide audience on memorability. In this case, we start from real practical methods and study it using statistics and recent advances in memorability prediction. Photographers, designers, and advertisers will benefit from the results of this study directly.
ALAP-AE: As-Lite-as-Possible Auto-Encoder
Mar 19, 2022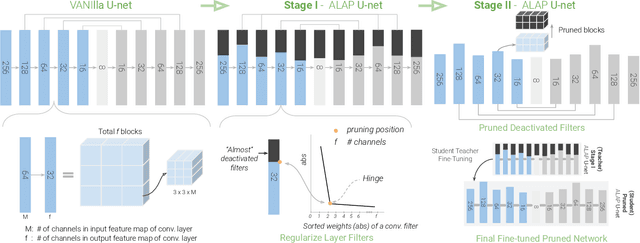
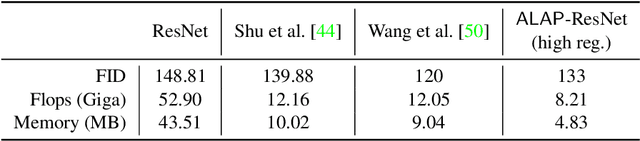
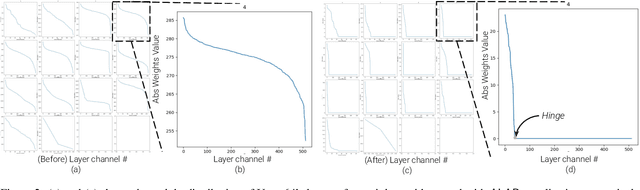
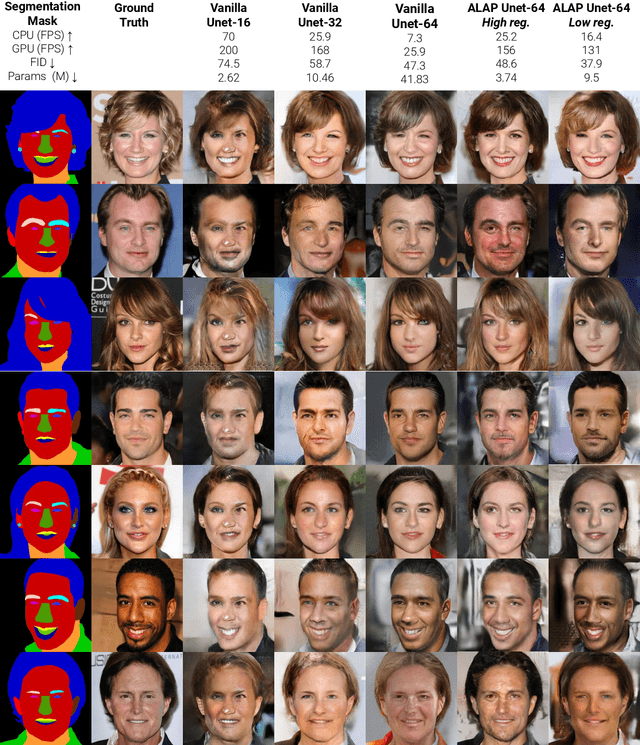
We present a novel algorithm to reduce tensor compute required by a conditional image generation autoencoder and make it as-lite-as-possible, without sacrificing quality of photo-realistic image generation. Our method is device agnostic, and can optimize an autoencoder for a given CPU-only, GPU compute device(s) in about normal time it takes to train an autoencoder on a generic workstation. We achieve this via a two-stage novel strategy where, first, we condense the channel weights, such that, as few as possible channels are used. Then, we prune the nearly zeroed out weight activations, and fine-tune this lite autoencoder. To maintain image quality, fine-tuning is done via student-teacher training, where we reuse the condensed autoencoder as the teacher. We show performance gains for various conditional image generation tasks: segmentation mask to face images, face images to cartoonization, and finally CycleGAN-based model on horse to zebra dataset over multiple compute devices. We perform various ablation studies to justify the claims and design choices, and achieve real-time versions of various autoencoders on CPU-only devices while maintaining image quality, thus enabling at-scale deployment of such autoencoders.
Restricted Black-box Adversarial Attack Against DeepFake Face Swapping
Apr 26, 2022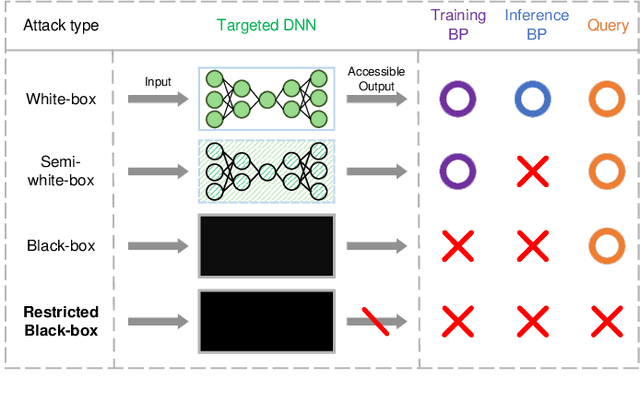
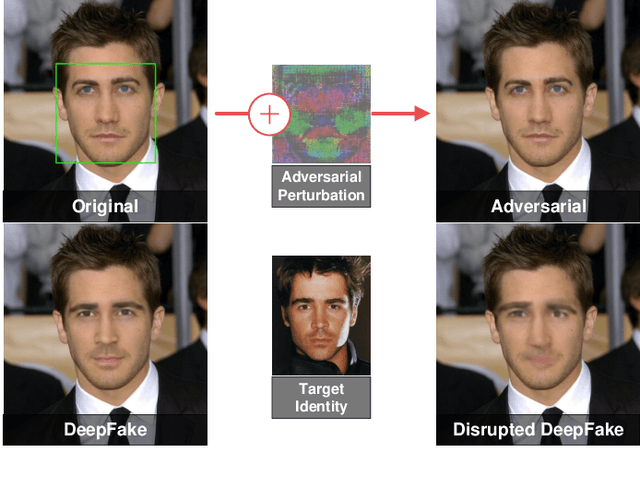
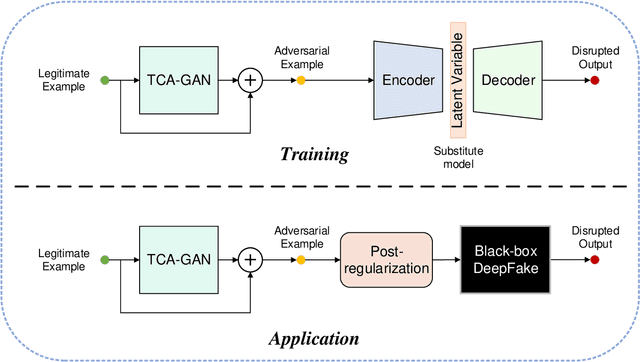
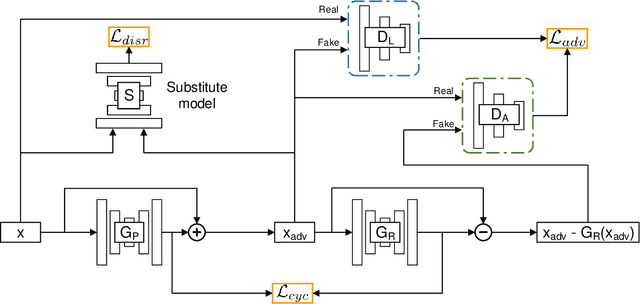
DeepFake face swapping presents a significant threat to online security and social media, which can replace the source face in an arbitrary photo/video with the target face of an entirely different person. In order to prevent this fraud, some researchers have begun to study the adversarial methods against DeepFake or face manipulation. However, existing works focus on the white-box setting or the black-box setting driven by abundant queries, which severely limits the practical application of these methods. To tackle this problem, we introduce a practical adversarial attack that does not require any queries to the facial image forgery model. Our method is built on a substitute model persuing for face reconstruction and then transfers adversarial examples from the substitute model directly to inaccessible black-box DeepFake models. Specially, we propose the Transferable Cycle Adversary Generative Adversarial Network (TCA-GAN) to construct the adversarial perturbation for disrupting unknown DeepFake systems. We also present a novel post-regularization module for enhancing the transferability of generated adversarial examples. To comprehensively measure the effectiveness of our approaches, we construct a challenging benchmark of DeepFake adversarial attacks for future development. Extensive experiments impressively show that the proposed adversarial attack method makes the visual quality of DeepFake face images plummet so that they are easier to be detected by humans and algorithms. Moreover, we demonstrate that the proposed algorithm can be generalized to offer face image protection against various face translation methods.
LiP-Flow: Learning Inference-time Priors for Codec Avatars via Normalizing Flows in Latent Space
Mar 15, 2022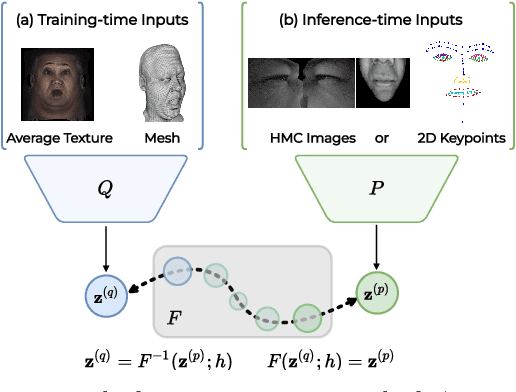
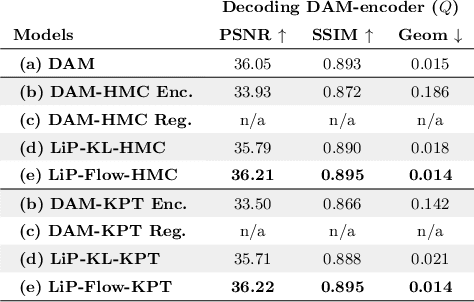

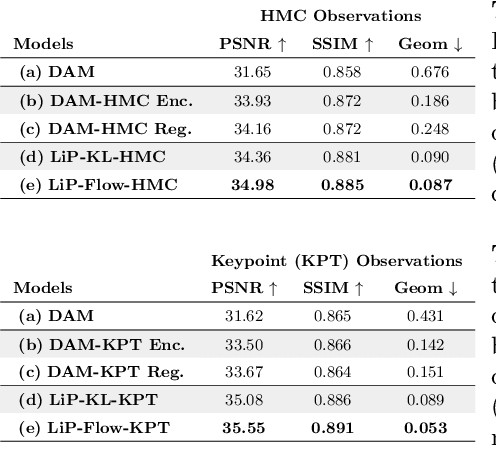
Neural face avatars that are trained from multi-view data captured in camera domes can produce photo-realistic 3D reconstructions. However, at inference time, they must be driven by limited inputs such as partial views recorded by headset-mounted cameras or a front-facing camera, and sparse facial landmarks. To mitigate this asymmetry, we introduce a prior model that is conditioned on the runtime inputs and tie this prior space to the 3D face model via a normalizing flow in the latent space. Our proposed model, LiP-Flow, consists of two encoders that learn representations from the rich training-time and impoverished inference-time observations. A normalizing flow bridges the two representation spaces and transforms latent samples from one domain to another, allowing us to define a latent likelihood objective. We trained our model end-to-end to maximize the similarity of both representation spaces and the reconstruction quality, making the 3D face model aware of the limited driving signals. We conduct extensive evaluations where the latent codes are optimized to reconstruct 3D avatars from partial or sparse observations. We show that our approach leads to an expressive and effective prior, capturing facial dynamics and subtle expressions better.
Embodied vision for learning object representations
May 12, 2022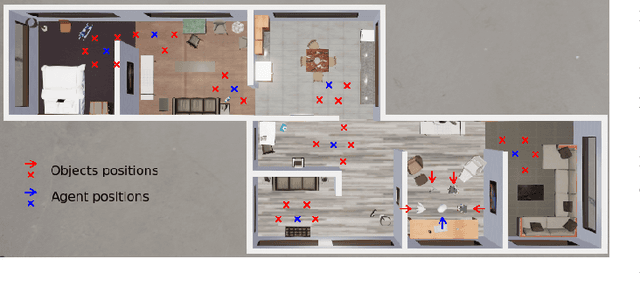


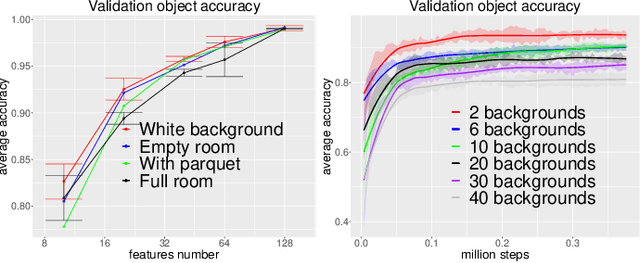
Recent time-contrastive learning approaches manage to learn invariant object representations without supervision. This is achieved by mapping successive views of an object onto close-by internal representations. When considering this learning approach as a model of the development of human object recognition, it is important to consider what visual input a toddler would typically observe while interacting with objects. First, human vision is highly foveated, with high resolution only available in the central region of the field of view. Second, objects may be seen against a blurry background due to infants' limited depth of field. Third, during object manipulation a toddler mostly observes close objects filling a large part of the field of view due to their rather short arms. Here, we study how these effects impact the quality of visual representations learnt through time-contrastive learning. To this end, we let a visually embodied agent "play" with objects in different locations of a near photo-realistic flat. During each play session the agent views an object in multiple orientations before turning its body to view another object. The resulting sequence of views feeds a time-contrastive learning algorithm. Our results show that visual statistics mimicking those of a toddler improve object recognition accuracy in both familiar and novel environments. We argue that this effect is caused by the reduction of features extracted in the background, a neural network bias for large features in the image and a greater similarity between novel and familiar background regions. We conclude that the embodied nature of visual learning may be crucial for understanding the development of human object perception.
Doodle It Yourself: Class Incremental Learning by Drawing a Few Sketches
Mar 28, 2022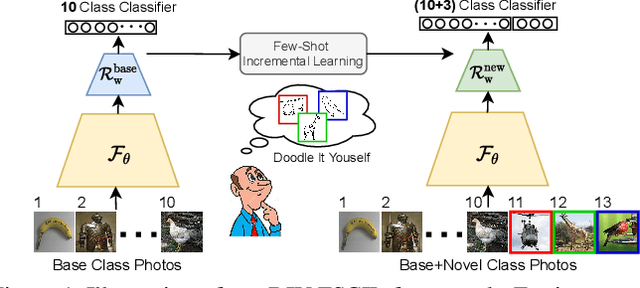
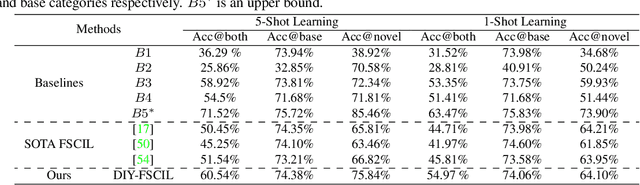
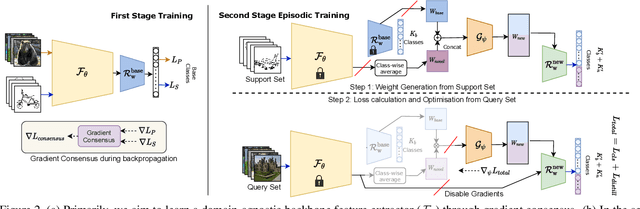

The human visual system is remarkable in learning new visual concepts from just a few examples. This is precisely the goal behind few-shot class incremental learning (FSCIL), where the emphasis is additionally placed on ensuring the model does not suffer from "forgetting". In this paper, we push the boundary further for FSCIL by addressing two key questions that bottleneck its ubiquitous application (i) can the model learn from diverse modalities other than just photo (as humans do), and (ii) what if photos are not readily accessible (due to ethical and privacy constraints). Our key innovation lies in advocating the use of sketches as a new modality for class support. The product is a "Doodle It Yourself" (DIY) FSCIL framework where the users can freely sketch a few examples of a novel class for the model to learn to recognize photos of that class. For that, we present a framework that infuses (i) gradient consensus for domain invariant learning, (ii) knowledge distillation for preserving old class information, and (iii) graph attention networks for message passing between old and novel classes. We experimentally show that sketches are better class support than text in the context of FSCIL, echoing findings elsewhere in the sketching literature.
The self-learning AI controller for adaptive power beaming with fiber-array laser transmitter system
Apr 08, 2022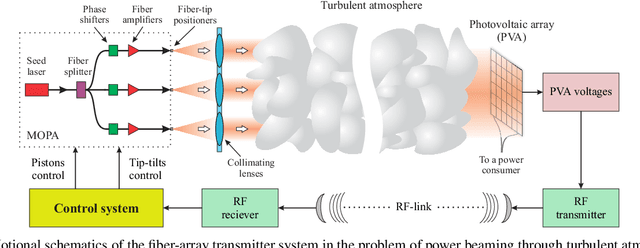
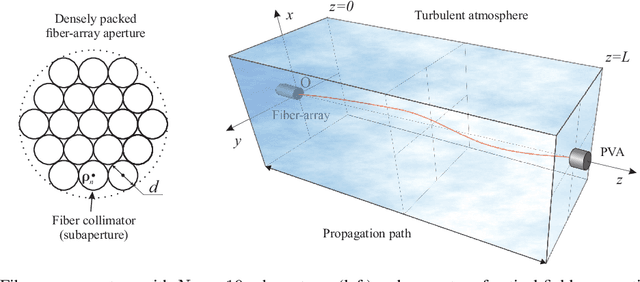
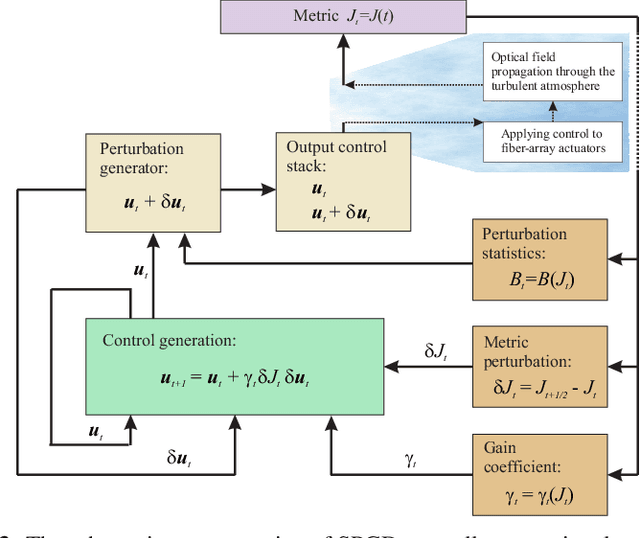
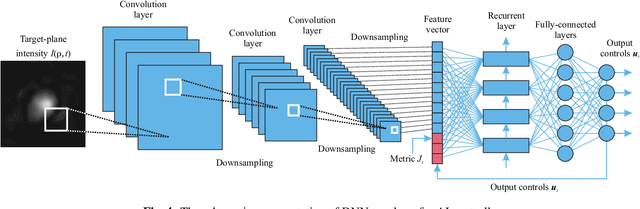
In this study we consider adaptive power beaming with fiber-array laser transmitter system in presence of atmospheric turbulence. For optimization of power transition through the atmosphere fiber-array is traditionally controlled by stochastic parallel gradient descent (SPGD) algorithm where control feedback is provided via radio frequency link by an optical-to-electrical power conversion sensor, attached to a cooperative target. The SPGD algorithm continuously and randomly perturbs voltages applied to fiber-array phase shifters and fiber tip positioners in order to maximize sensor signal, i.e. uses, so-called, "blind" optimization principle. In opposite to this approach a perspective artificially intelligent (AI) control systems for synthesis of optimal control can utilize various pupil- or target-plane data available for the analysis including wavefront sensor data, photo-voltaic array (PVA) data, other optical or atmospheric parameters, and potentially can eliminate well-known drawbacks of SPGD-based controllers. In this study an optimal control is synthesized by a deep neural network (DNN) using target-plane PVA sensor data as its input. A DNN training is occurred online in sync with control system operation and is performed by applying of small perturbations to DNN's outputs. This approach does not require initial DNN's pre-training as well as guarantees optimization of system performance in time. All theoretical results are verified by numerical experiments.