 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Light Field Depth Estimation Based on Stitched-EPI
Mar 29, 2022
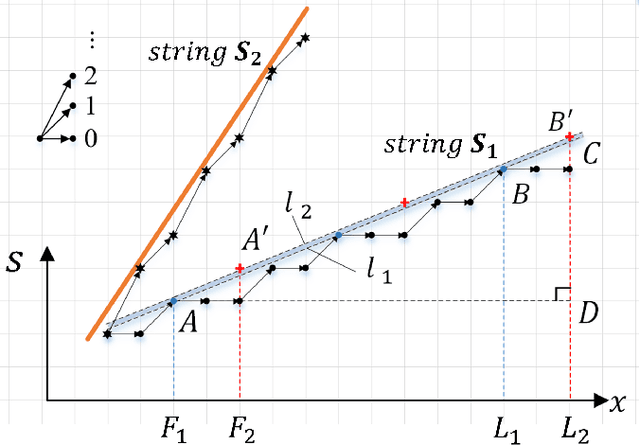
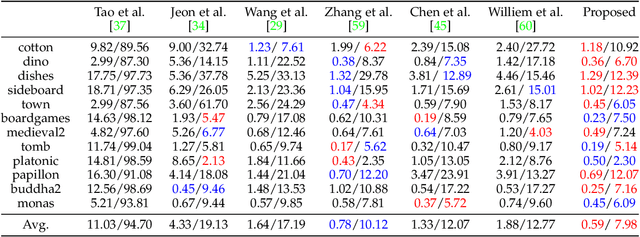
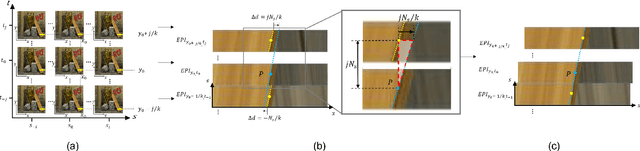
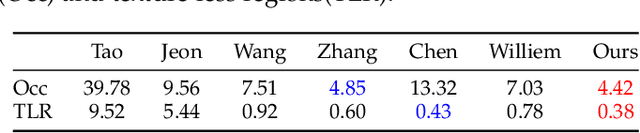
Depth estimation is one of the most essential problems for light field applications. In EPI-based methods, the slope computation usually suffers low accuracy due to the discretization error and low angular resolution. In addition, recent methods work well in most regions but often struggle with blurry edges over occluded regions and ambiguity over texture-less regions. To address these challenging issues, we first propose the stitched-EPI and half-stitched-EPI algorithms for non-occluded and occluded regions, respectively. The algorithms improve slope computation by shifting and concatenating lines in different EPIs but related to the same point in 3D scene, while the half-stitched-EPI only uses non-occluded part of lines. Combined with the joint photo-consistency cost proposed by us, the more accurate and robust depth map can be obtained in both occluded and non-occluded regions. Furthermore, to improve the depth estimation in texture-less regions, we propose a depth propagation strategy that determines their depth from the edge to interior, from accurate regions to coarse regions. Experimental and ablation results demonstrate that the proposed method achieves accurate and robust depth maps in all regions effectively.
Learning to estimate UAV created turbulence from scene structure observed by onboard cameras
Mar 28, 2022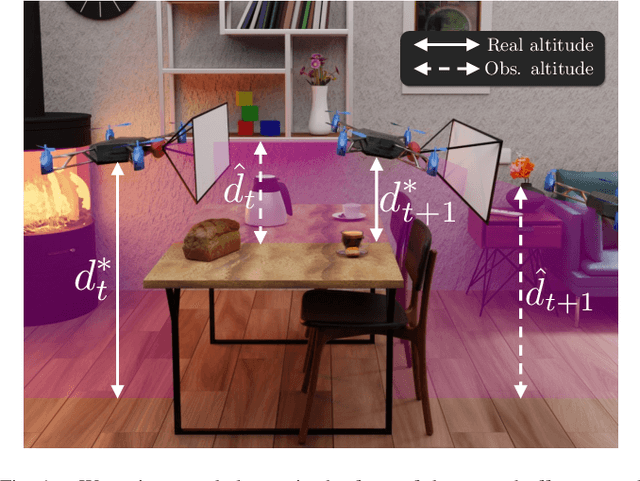
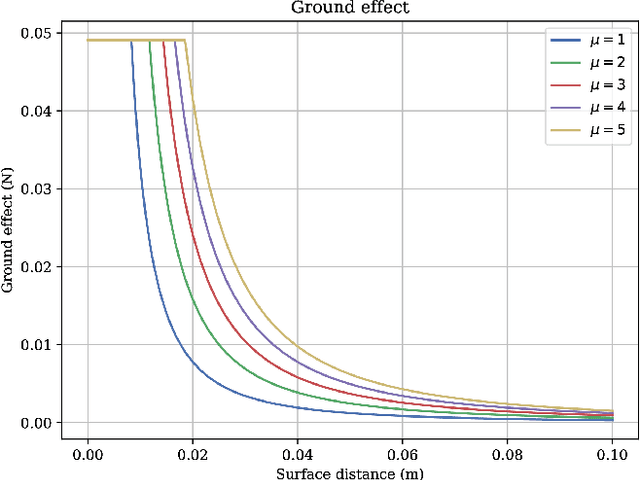

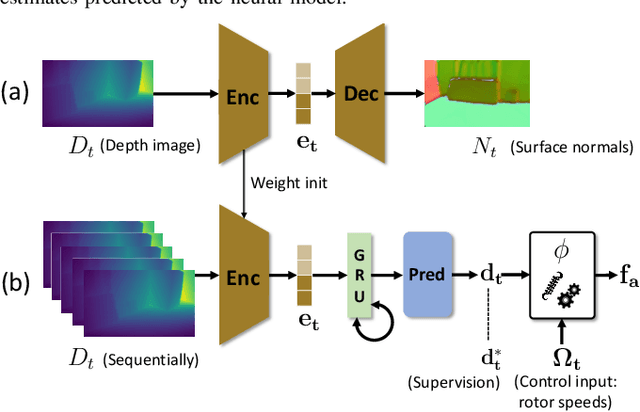
Controlling UAV flights precisely requires a realistic dynamic model and accurate state estimates from onboard sensors like UAV, GPS and visual observations. Obtaining a precise dynamic model is extremely difficult, as important aerodynamic effects are hard to model, in particular ground effect and other turbulences. While machine learning has been used in the past to estimate UAV created turbulence, this was restricted to flat grounds or diffuse in-flight air turbulences, both without taking into account obstacles. In this work we address the complex problem of estimating in-flight turbulences caused by obstacles, in particular the complex structures in cluttered environments. We learn a mapping from control input and images captured by onboard cameras to turbulence. In a large-scale setting, we train a model over a large number of different simulated photo-realistic environments loaded into the Habitat.AI simulator augmented with a dynamic UAV model and an analytic ground effect model. We transfer the model from simulation to a real environment and evaluate on real UAV flights from the EuRoC-MAV dataset, showing that the model is capable of good sim2real generalization performance. The dataset will be made publicly available upon acceptance.
Sketch3T: Test-Time Training for Zero-Shot SBIR
Mar 28, 2022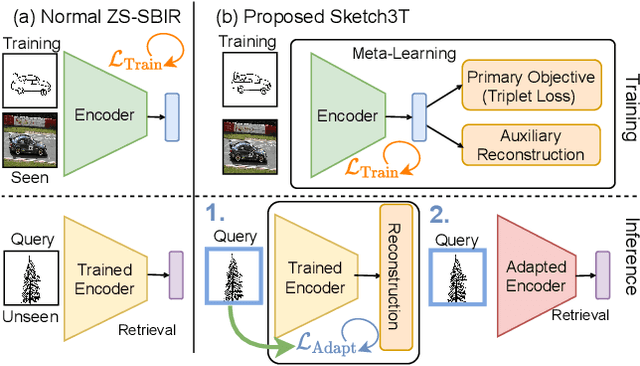
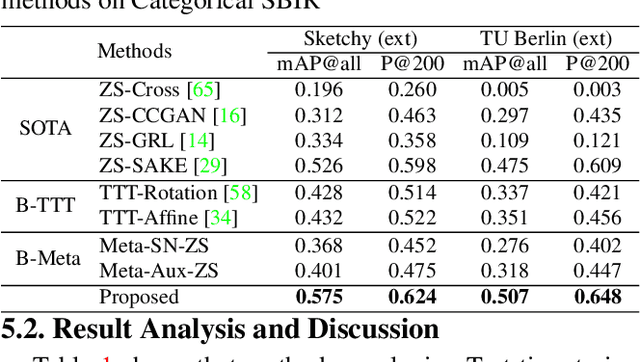
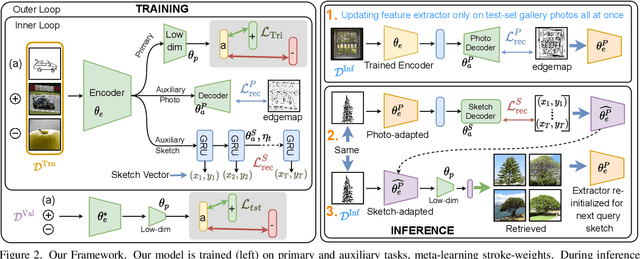
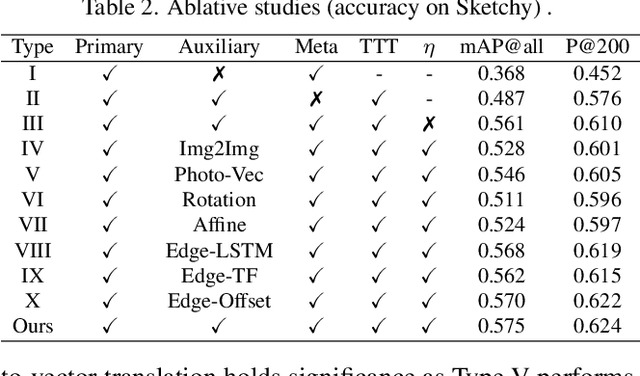
Zero-shot sketch-based image retrieval typically asks for a trained model to be applied as is to unseen categories. In this paper, we question to argue that this setup by definition is not compatible with the inherent abstract and subjective nature of sketches, i.e., the model might transfer well to new categories, but will not understand sketches existing in different test-time distribution as a result. We thus extend ZS-SBIR asking it to transfer to both categories and sketch distributions. Our key contribution is a test-time training paradigm that can adapt using just one sketch. Since there is no paired photo, we make use of a sketch raster-vector reconstruction module as a self-supervised auxiliary task. To maintain the fidelity of the trained cross-modal joint embedding during test-time update, we design a novel meta-learning based training paradigm to learn a separation between model updates incurred by this auxiliary task from those off the primary objective of discriminative learning. Extensive experiments show our model to outperform state of-the-arts, thanks to the proposed test-time adaption that not only transfers to new categories but also accommodates to new sketching styles.
Control-NeRF: Editable Feature Volumes for Scene Rendering and Manipulation
Apr 22, 2022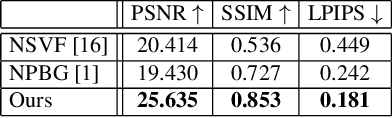
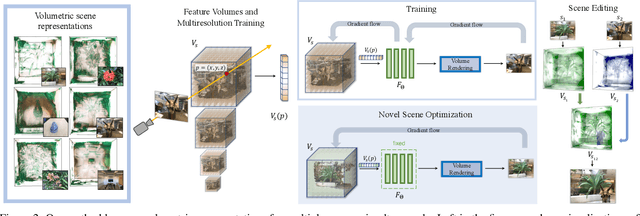
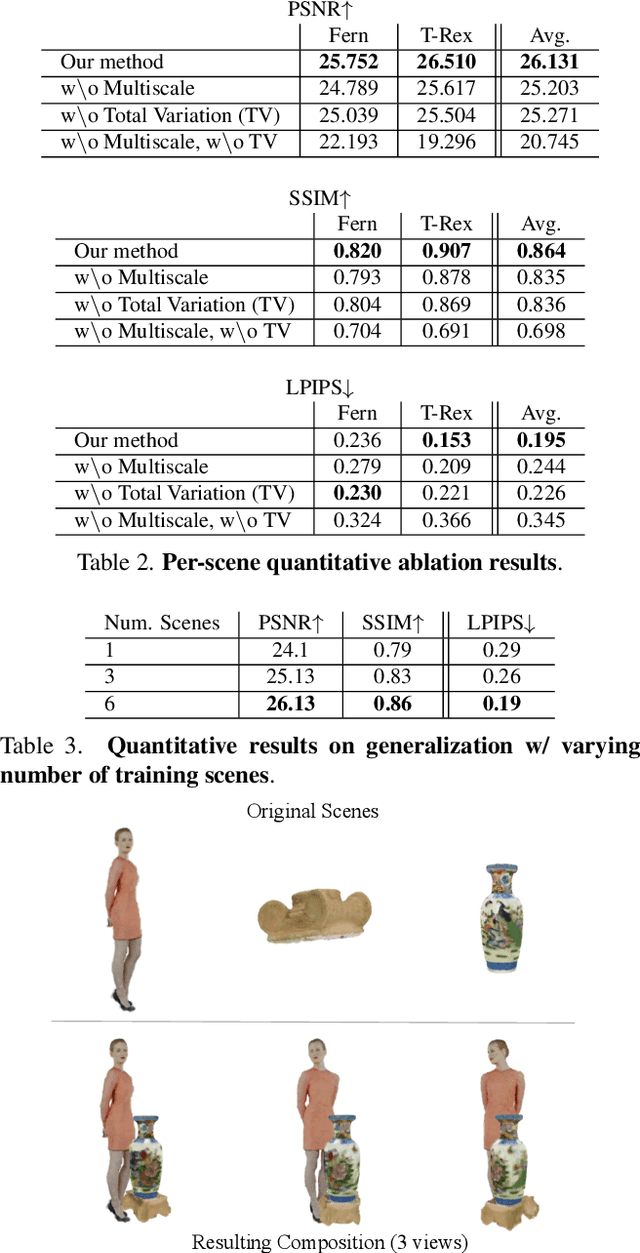

We present a novel method for performing flexible, 3D-aware image content manipulation while enabling high-quality novel view synthesis. While NeRF-based approaches are effective for novel view synthesis, such models memorize the radiance for every point in a scene within a neural network. Since these models are scene-specific and lack a 3D scene representation, classical editing such as shape manipulation, or combining scenes is not possible. Hence, editing and combining NeRF-based scenes has not been demonstrated. With the aim of obtaining interpretable and controllable scene representations, our model couples learnt scene-specific feature volumes with a scene agnostic neural rendering network. With this hybrid representation, we decouple neural rendering from scene-specific geometry and appearance. We can generalize to novel scenes by optimizing only the scene-specific 3D feature representation, while keeping the parameters of the rendering network fixed. The rendering function learnt during the initial training stage can thus be easily applied to new scenes, making our approach more flexible. More importantly, since the feature volumes are independent of the rendering model, we can manipulate and combine scenes by editing their corresponding feature volumes. The edited volume can then be plugged into the rendering model to synthesize high-quality novel views. We demonstrate various scene manipulations, including mixing scenes, deforming objects and inserting objects into scenes, while still producing photo-realistic results.
Structure-Aware Flow Generation for Human Body Reshaping
Mar 11, 2022
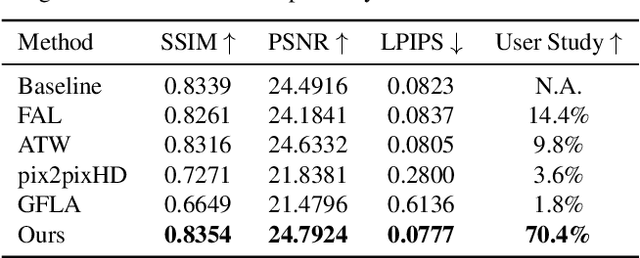
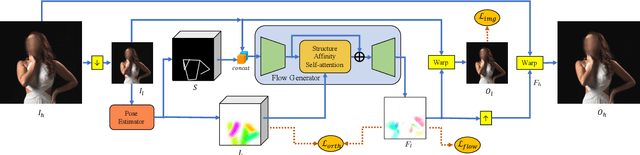
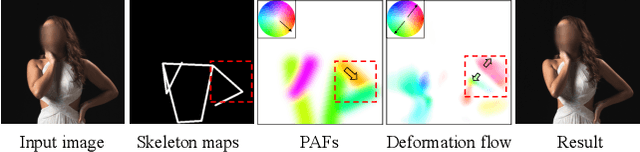
Body reshaping is an important procedure in portrait photo retouching. Due to the complicated structure and multifarious appearance of human bodies, existing methods either fall back on the 3D domain via body morphable model or resort to keypoint-based image deformation, leading to inefficiency and unsatisfied visual quality. In this paper, we address these limitations by formulating an end-to-end flow generation architecture under the guidance of body structural priors, including skeletons and Part Affinity Fields, and achieve unprecedentedly controllable performance under arbitrary poses and garments. A compositional attention mechanism is introduced for capturing both visual perceptual correlations and structural associations of the human body to reinforce the manipulation consistency among related parts. For a comprehensive evaluation, we construct the first large-scale body reshaping dataset, namely BR-5K, which contains 5,000 portrait photos as well as professionally retouched targets. Extensive experiments demonstrate that our approach significantly outperforms existing state-of-the-art methods in terms of visual performance, controllability, and efficiency. The dataset is available at our website: https://github.com/JianqiangRen/FlowBasedBodyReshaping.
Rethinking Visual Geo-localization for Large-Scale Applications
Apr 07, 2022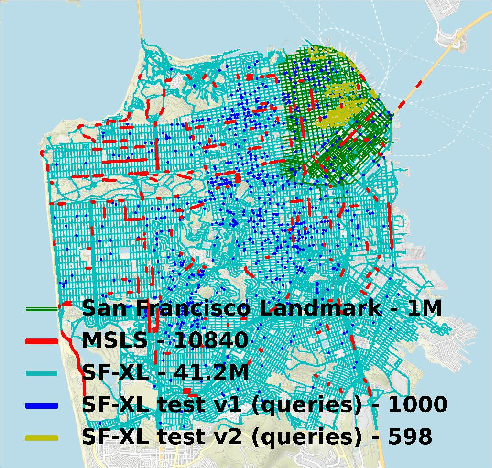
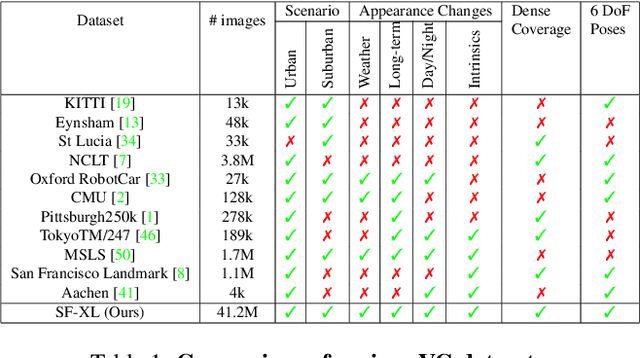
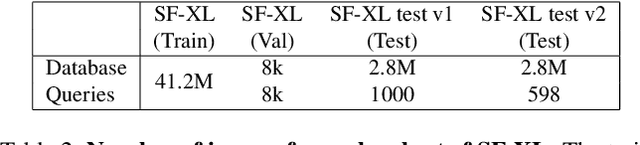

Visual Geo-localization (VG) is the task of estimating the position where a given photo was taken by comparing it with a large database of images of known locations. To investigate how existing techniques would perform on a real-world city-wide VG application, we build San Francisco eXtra Large, a new dataset covering a whole city and providing a wide range of challenging cases, with a size 30x bigger than the previous largest dataset for visual geo-localization. We find that current methods fail to scale to such large datasets, therefore we design a new highly scalable training technique, called CosPlace, which casts the training as a classification problem avoiding the expensive mining needed by the commonly used contrastive learning. We achieve state-of-the-art performance on a wide range of datasets and find that CosPlace is robust to heavy domain changes. Moreover, we show that, compared to the previous state-of-the-art, CosPlace requires roughly 80% less GPU memory at train time, and it achieves better results with 8x smaller descriptors, paving the way for city-wide real-world visual geo-localization. Dataset, code and trained models are available for research purposes at https://github.com/gmberton/CosPlace.
A SSIM Guided cGAN Architecture For Clinically Driven Generative Image Synthesis of Multiplexed Spatial Proteomics Channels
May 20, 2022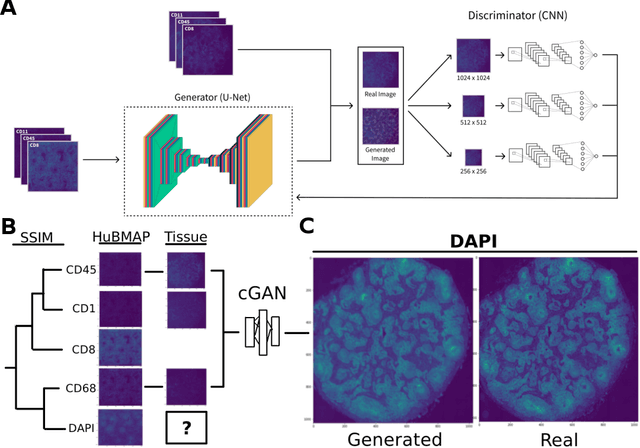


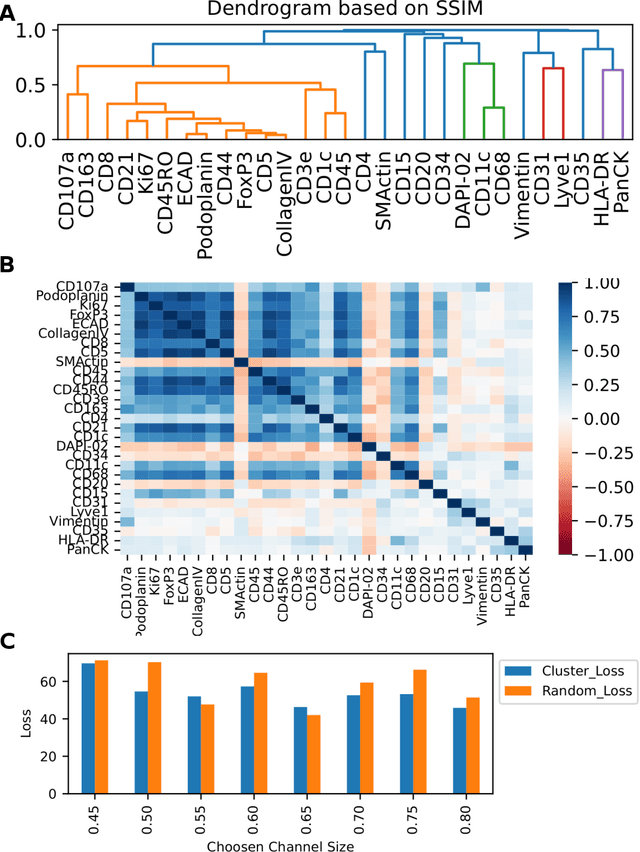
Here we present a structural similarity index measure (SSIM) guided conditional Generative Adversarial Network (cGAN) that generatively performs image-to-image (i2i) synthesis to generate photo-accurate protein channels in multiplexed spatial proteomics images. This approach can be utilized to accurately generate missing spatial proteomics channels that were not included during experimental data collection either at the bench or the clinic. Experimental spatial proteomic data from the Human BioMolecular Atlas Program (HuBMAP) was used to generate spatial representations of missing proteins through a U-Net based image synthesis pipeline. HuBMAP channels were hierarchically clustered by the (SSIM) as a heuristic to obtain the minimal set needed to recapitulate the underlying biology represented by the spatial landscape of proteins. We subsequently prove that our SSIM based architecture allows for scaling of generative image synthesis to slides with up to 100 channels, which is better than current state of the art algorithms which are limited to data with 11 channels. We validate these claims by generating a new experimental spatial proteomics data set from human lung adenocarcinoma tissue sections and show that a model trained on HuBMAP can accurately synthesize channels from our new data set. The ability to recapitulate experimental data from sparsely stained multiplexed histological slides containing spatial proteomic will have tremendous impact on medical diagnostics and drug development, and also raises important questions on the medical ethics of utilizing data produced by generative image synthesis in the clinical setting. The algorithm that we present in this paper will allow researchers and clinicians to save time and costs in proteomics based histological staining while also increasing the amount of data that they can generate through their experiments.
Beyond Separability: Analyzing the Linear Transferability of Contrastive Representations to Related Subpopulations
Apr 06, 2022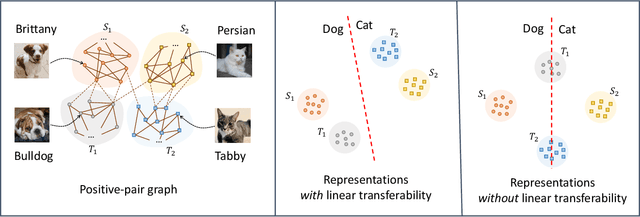

Contrastive learning is a highly effective method which uses unlabeled data to produce representations which are linearly separable for downstream classification tasks. Recent works have shown that contrastive representations are not only useful when data come from a single domain, but are also effective for transferring across domains. Concretely, when contrastive representations are trained on data from two domains (a source and target) and a linear classification head is trained to predict labels using only the labeled source data, the resulting classifier also exhibits good transfer to the target domain. In this work, we analyze this linear transferability phenomenon, building upon the framework proposed by HaoChen et al (2021) which relates contrastive learning to spectral clustering of a positive-pair graph on the data. We prove that contrastive representations capture relationships between subpopulations in the positive-pair graph: linear transferability can occur when data from the same class in different domains (e.g., photo dogs and cartoon dogs) are connected in the graph. Our analysis allows the source and target classes to have unbounded density ratios and be mapped to distant representations. Our proof is also built upon technical improvements over the main results of HaoChen et al (2021), which may be of independent interest.
Exposure: A White-Box Photo Post-Processing Framework
Feb 06, 2018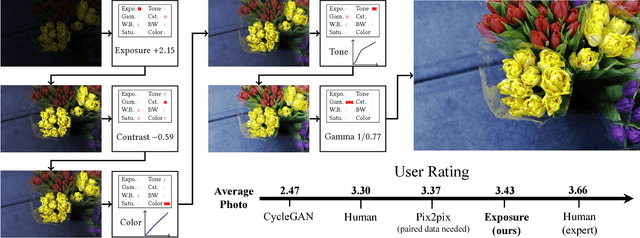


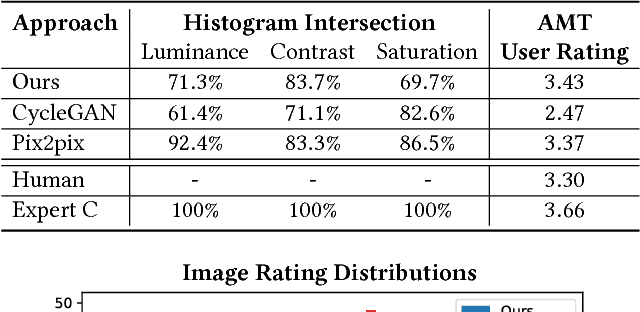
Retouching can significantly elevate the visual appeal of photos, but many casual photographers lack the expertise to do this well. To address this problem, previous works have proposed automatic retouching systems based on supervised learning from paired training images acquired before and after manual editing. As it is difficult for users to acquire paired images that reflect their retouching preferences, we present in this paper a deep learning approach that is instead trained on unpaired data, namely a set of photographs that exhibits a retouching style the user likes, which is much easier to collect. Our system is formulated using deep convolutional neural networks that learn to apply different retouching operations on an input image. Network training with respect to various types of edits is enabled by modeling these retouching operations in a unified manner as resolution-independent differentiable filters. To apply the filters in a proper sequence and with suitable parameters, we employ a deep reinforcement learning approach that learns to make decisions on what action to take next, given the current state of the image. In contrast to many deep learning systems, ours provides users with an understandable solution in the form of conventional retouching edits, rather than just a "black-box" result. Through quantitative comparisons and user studies, we show that this technique generates retouching results consistent with the provided photo set.