 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
ClimateGAN: Raising Climate Change Awareness by Generating Images of Floods
Oct 06, 2021

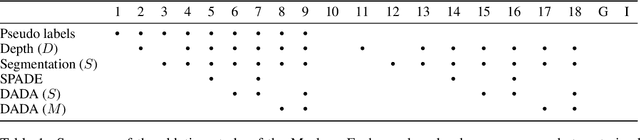
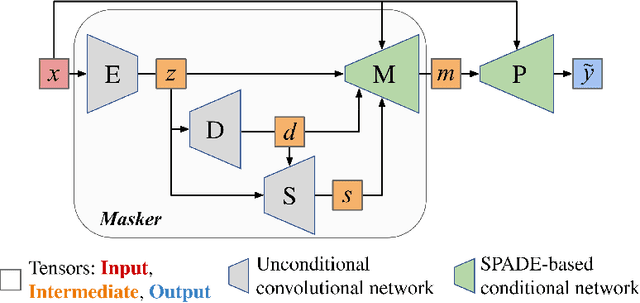

Climate change is a major threat to humanity, and the actions required to prevent its catastrophic consequences include changes in both policy-making and individual behaviour. However, taking action requires understanding the effects of climate change, even though they may seem abstract and distant. Projecting the potential consequences of extreme climate events such as flooding in familiar places can help make the abstract impacts of climate change more concrete and encourage action. As part of a larger initiative to build a website that projects extreme climate events onto user-chosen photos, we present our solution to simulate photo-realistic floods on authentic images. To address this complex task in the absence of suitable training data, we propose ClimateGAN, a model that leverages both simulated and real data for unsupervised domain adaptation and conditional image generation. In this paper, we describe the details of our framework, thoroughly evaluate components of our architecture and demonstrate that our model is capable of robustly generating photo-realistic flooding.
LinesToFacePhoto: Face Photo Generation from Lines with Conditional Self-Attention Generative Adversarial Network
Oct 20, 2019
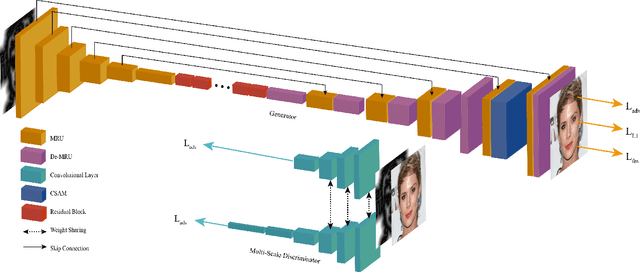
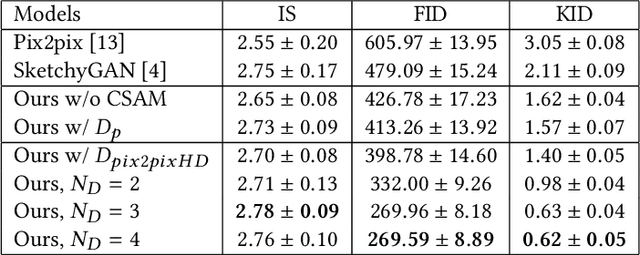

In this paper, we explore the task of generating photo-realistic face images from lines. Previous methods based on conditional generative adversarial networks (cGANs) have shown their power to generate visually plausible images when a conditional image and an output image share well-aligned structures. However, these models fail to synthesize face images with a whole set of well-defined structures, e.g. eyes, noses, mouths, etc., especially when the conditional line map lacks one or several parts. To address this problem, we propose a conditional self-attention generative adversarial network (CSAGAN). We introduce a conditional self-attention mechanism to cGANs to capture long-range dependencies between different regions in faces. We also build a multi-scale discriminator. The large-scale discriminator enforces the completeness of global structures and the small-scale discriminator encourages fine details, thereby enhancing the realism of generated face images. We evaluate the proposed model on the CelebA-HD dataset by two perceptual user studies and three quantitative metrics. The experiment results demonstrate that our method generates high-quality facial images while preserving facial structures. Our results outperform state-of-the-art methods both quantitatively and qualitatively.
PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
Mar 08, 2020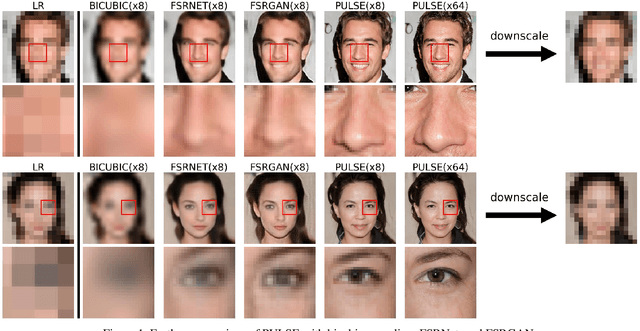
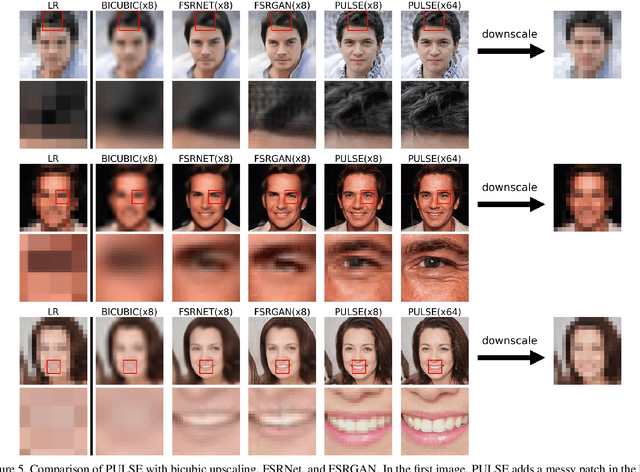


The primary aim of single-image super-resolution is to construct a high-resolution (HR) image from a corresponding low-resolution (LR) input. In previous approaches, which have generally been supervised, the training objective typically measures a pixel-wise average distance between the super-resolved (SR) and HR images. Optimizing such metrics often leads to blurring, especially in high variance (detailed) regions. We propose an alternative formulation of the super-resolution problem based on creating realistic SR images that downscale correctly. We present a novel super-resolution algorithm addressing this problem, PULSE (Photo Upsampling via Latent Space Exploration), which generates high-resolution, realistic images at resolutions previously unseen in the literature. It accomplishes this in an entirely self-supervised fashion and is not confined to a specific degradation operator used during training, unlike previous methods (which require training on databases of LR-HR image pairs for supervised learning). Instead of starting with the LR image and slowly adding detail, PULSE traverses the high-resolution natural image manifold, searching for images that downscale to the original LR image. This is formalized through the "downscaling loss," which guides exploration through the latent space of a generative model. By leveraging properties of high-dimensional Gaussians, we restrict the search space to guarantee that our outputs are realistic. PULSE thereby generates super-resolved images that both are realistic and downscale correctly. We show extensive experimental results demonstrating the efficacy of our approach in the domain of face super-resolution (also known as face hallucination). Our method outperforms state-of-the-art methods in perceptual quality at higher resolutions and scale factors than previously possible.
Do Different Deep Metric Learning Losses Lead to Similar Learned Features?
May 05, 2022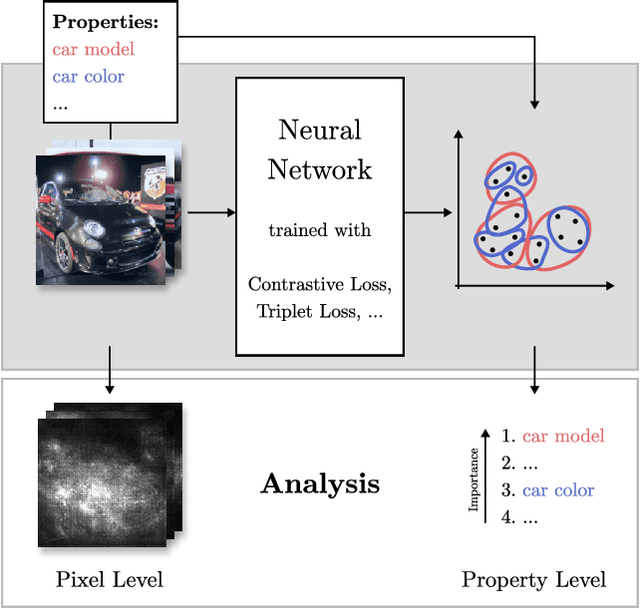
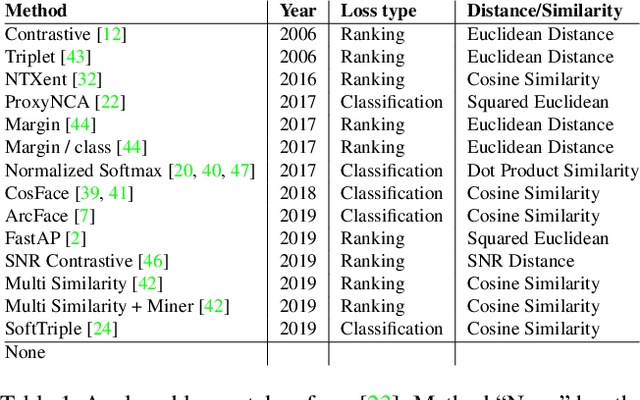
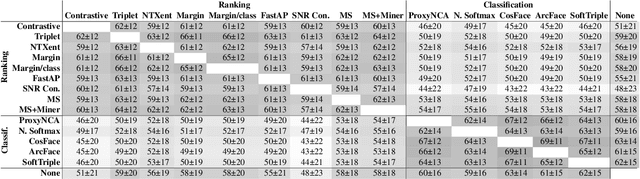

Recent studies have shown that many deep metric learning loss functions perform very similarly under the same experimental conditions. One potential reason for this unexpected result is that all losses let the network focus on similar image regions or properties. In this paper, we investigate this by conducting a two-step analysis to extract and compare the learned visual features of the same model architecture trained with different loss functions: First, we compare the learned features on the pixel level by correlating saliency maps of the same input images. Second, we compare the clustering of embeddings for several image properties, e.g. object color or illumination. To provide independent control over these properties, photo-realistic 3D car renders similar to images in the Cars196 dataset are generated. In our analysis, we compare 14 pretrained models from a recent study and find that, even though all models perform similarly, different loss functions can guide the model to learn different features. We especially find differences between classification and ranking based losses. Our analysis also shows that some seemingly irrelevant properties can have significant influence on the resulting embedding. We encourage researchers from the deep metric learning community to use our methods to get insights into the features learned by their proposed methods.
ProbNVS: Fast Novel View Synthesis with Learned Probability-Guided Sampling
Apr 07, 2022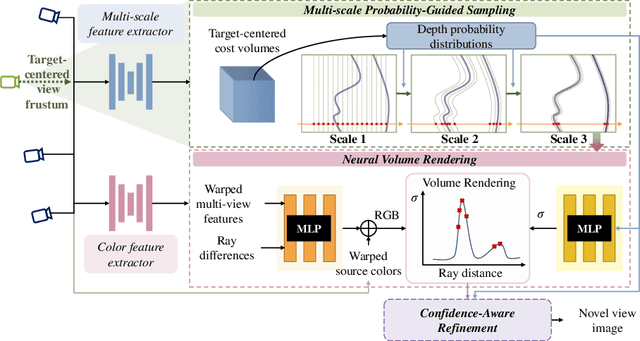
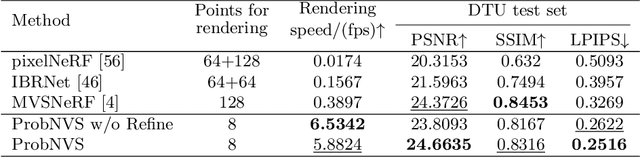
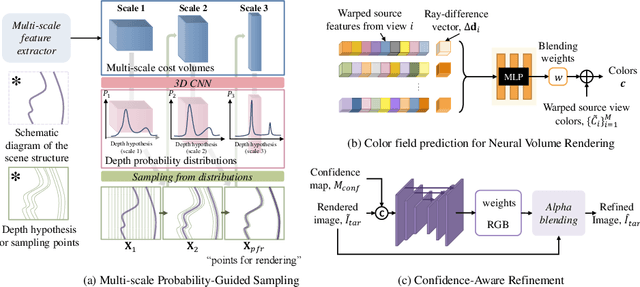
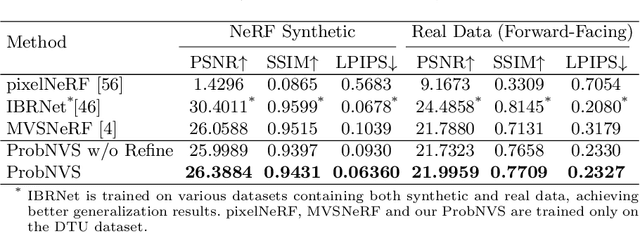
Existing state-of-the-art novel view synthesis methods rely on either fairly accurate 3D geometry estimation or sampling of the entire space for neural volumetric rendering, which limit the overall efficiency. In order to improve the rendering efficiency by reducing sampling points without sacrificing rendering quality, we propose to build a novel view synthesis framework based on learned MVS priors that enables general, fast and photo-realistic view synthesis simultaneously. Specifically, fewer but important points are sampled under the guidance of depth probability distributions extracted from the learned MVS architecture. Based on the learned probability-guided sampling, a neural volume rendering module is elaborately devised to fully aggregate source view information as well as the learned scene structures to synthesize photorealistic target view images. Finally, the rendering results in uncertain, occluded and unreferenced regions can be further improved by incorporating a confidence-aware refinement module. Experiments show that our method achieves 15 to 40 times faster rendering compared to state-of-the-art baselines, with strong generalization capacity and comparable high-quality novel view synthesis performance.
NeRFusion: Fusing Radiance Fields for Large-Scale Scene Reconstruction
Mar 21, 2022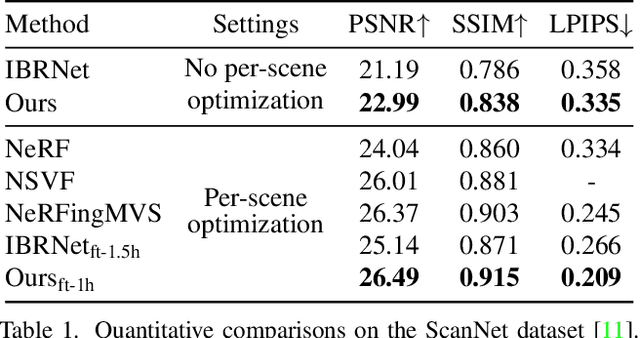
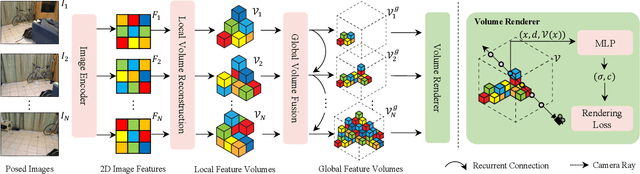
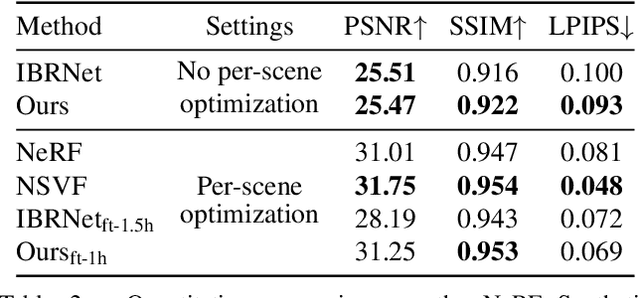
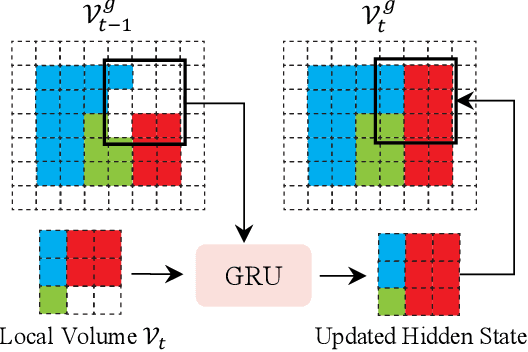
While NeRF has shown great success for neural reconstruction and rendering, its limited MLP capacity and long per-scene optimization times make it challenging to model large-scale indoor scenes. In contrast, classical 3D reconstruction methods can handle large-scale scenes but do not produce realistic renderings. We propose NeRFusion, a method that combines the advantages of NeRF and TSDF-based fusion techniques to achieve efficient large-scale reconstruction and photo-realistic rendering. We process the input image sequence to predict per-frame local radiance fields via direct network inference. These are then fused using a novel recurrent neural network that incrementally reconstructs a global, sparse scene representation in real-time at 22 fps. This global volume can be further fine-tuned to boost rendering quality. We demonstrate that NeRFusion achieves state-of-the-art quality on both large-scale indoor and small-scale object scenes, with substantially faster reconstruction than NeRF and other recent methods.
StyleCariGAN: Caricature Generation via StyleGAN Feature Map Modulation
Jul 09, 2021
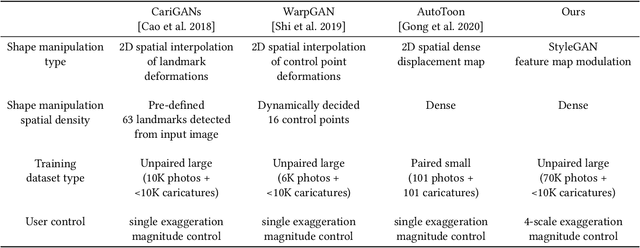


We present a caricature generation framework based on shape and style manipulation using StyleGAN. Our framework, dubbed StyleCariGAN, automatically creates a realistic and detailed caricature from an input photo with optional controls on shape exaggeration degree and color stylization type. The key component of our method is shape exaggeration blocks that are used for modulating coarse layer feature maps of StyleGAN to produce desirable caricature shape exaggerations. We first build a layer-mixed StyleGAN for photo-to-caricature style conversion by swapping fine layers of the StyleGAN for photos to the corresponding layers of the StyleGAN trained to generate caricatures. Given an input photo, the layer-mixed model produces detailed color stylization for a caricature but without shape exaggerations. We then append shape exaggeration blocks to the coarse layers of the layer-mixed model and train the blocks to create shape exaggerations while preserving the characteristic appearances of the input. Experimental results show that our StyleCariGAN generates realistic and detailed caricatures compared to the current state-of-the-art methods. We demonstrate StyleCariGAN also supports other StyleGAN-based image manipulations, such as facial expression control.
* Accepted to SIGGRAPH 2021. For supplementary material, see http://cg.postech.ac.kr/papers/2021_StyleCariGAN_supp.zip
Storytelling of Photo Stream with Bidirectional Multi-thread Recurrent Neural Network
Jun 02, 2016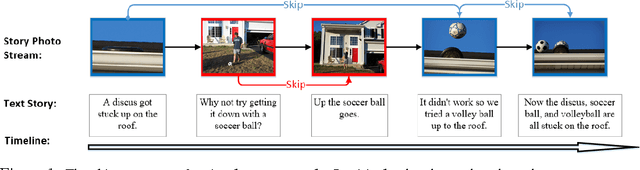
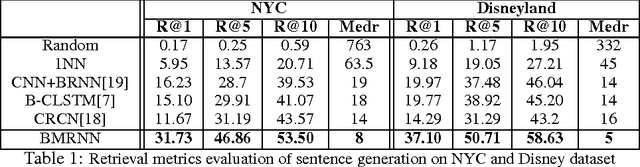
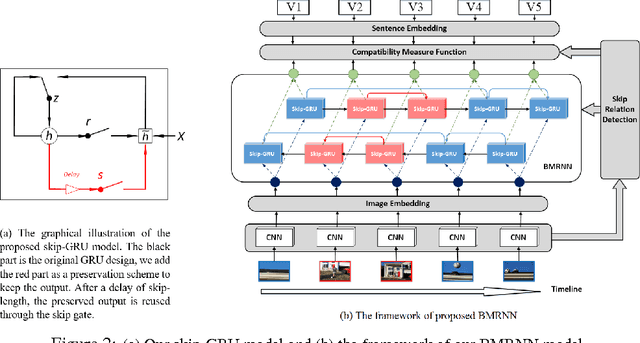
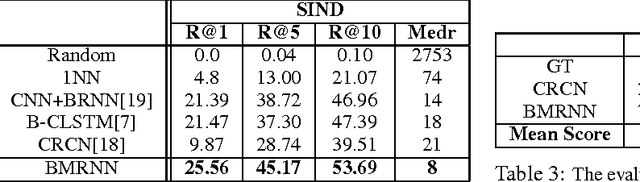
Visual storytelling aims to generate human-level narrative language (i.e., a natural paragraph with multiple sentences) from a photo streams. A typical photo story consists of a global timeline with multi-thread local storylines, where each storyline occurs in one different scene. Such complex structure leads to large content gaps at scene transitions between consecutive photos. Most existing image/video captioning methods can only achieve limited performance, because the units in traditional recurrent neural networks (RNN) tend to "forget" the previous state when the visual sequence is inconsistent. In this paper, we propose a novel visual storytelling approach with Bidirectional Multi-thread Recurrent Neural Network (BMRNN). First, based on the mined local storylines, a skip gated recurrent unit (sGRU) with delay control is proposed to maintain longer range visual information. Second, by using sGRU as basic units, the BMRNN is trained to align the local storylines into the global sequential timeline. Third, a new training scheme with a storyline-constrained objective function is proposed by jointly considering both global and local matches. Experiments on three standard storytelling datasets show that the BMRNN model outperforms the state-of-the-art methods.
Hyperspectral 3D Mapping of Underwater Environments
Oct 13, 2021

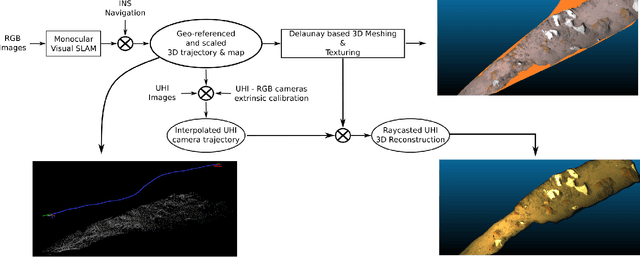

Hyperspectral imaging has been increasingly used for underwater survey applications over the past years. As many hyperspectral cameras work as push-broom scanners, their use is usually limited to the creation of photo-mosaics based on a flat surface approximation and by interpolating the camera pose from dead-reckoning navigation. Yet, because of drift in the navigation and the mostly wrong flat surface assumption, the quality of the obtained photo-mosaics is often too low to support adequate analysis.In this paper we present an initial method for creating hyperspectral 3D reconstructions of underwater environments. By fusing the data gathered by a classical RGB camera, an inertial navigation system and a hyperspectral push-broom camera, we show that the proposed method creates highly accurate 3D reconstructions with hyperspectral textures. We propose to combine techniques from simultaneous localization and mapping, structure-from-motion and 3D reconstruction and advantageously use them to create 3D models with hyperspectral texture, allowing us to overcome the flat surface assumption and the classical limitation of dead-reckoning navigation.
* ICCV'21 - Computer Vision in the Ocean Workshop
iButter: Neural Interactive Bullet Time Generator for Human Free-viewpoint Rendering
Aug 12, 2021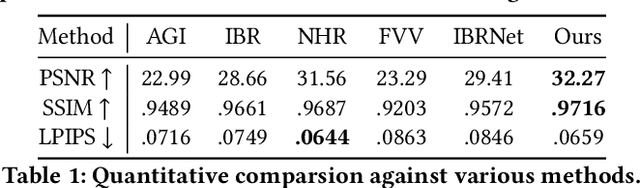
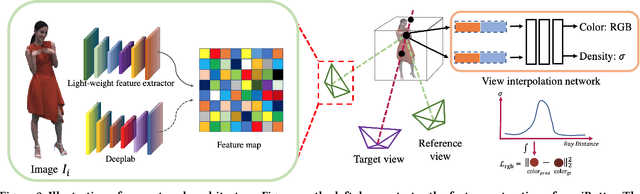
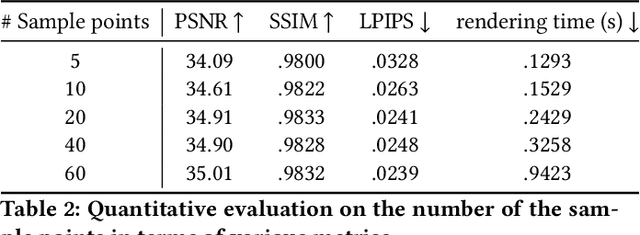
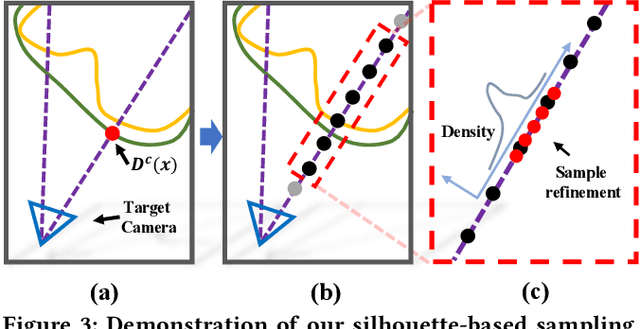
Generating ``bullet-time'' effects of human free-viewpoint videos is critical for immersive visual effects and VR/AR experience. Recent neural advances still lack the controllable and interactive bullet-time design ability for human free-viewpoint rendering, especially under the real-time, dynamic and general setting for our trajectory-aware task. To fill this gap, in this paper we propose a neural interactive bullet-time generator (iButter) for photo-realistic human free-viewpoint rendering from dense RGB streams, which enables flexible and interactive design for human bullet-time visual effects. Our iButter approach consists of a real-time preview and design stage as well as a trajectory-aware refinement stage. During preview, we propose an interactive bullet-time design approach by extending the NeRF rendering to a real-time and dynamic setting and getting rid of the tedious per-scene training. To this end, our bullet-time design stage utilizes a hybrid training set, light-weight network design and an efficient silhouette-based sampling strategy. During refinement, we introduce an efficient trajectory-aware scheme within 20 minutes, which jointly encodes the spatial, temporal consistency and semantic cues along the designed trajectory, achieving photo-realistic bullet-time viewing experience of human activities. Extensive experiments demonstrate the effectiveness of our approach for convenient interactive bullet-time design and photo-realistic human free-viewpoint video generation.