 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Face Photo Sketch Synthesis via Larger Patch and Multiresolution Spline
Sep 19, 2015
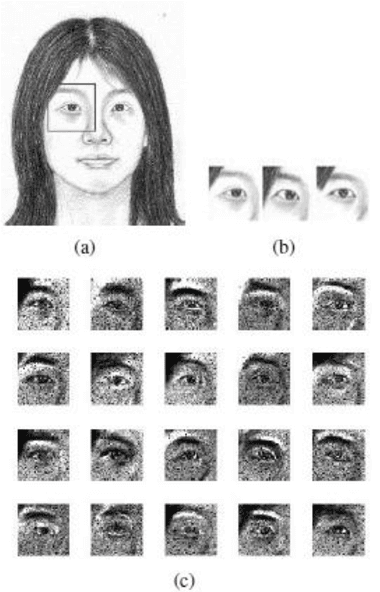
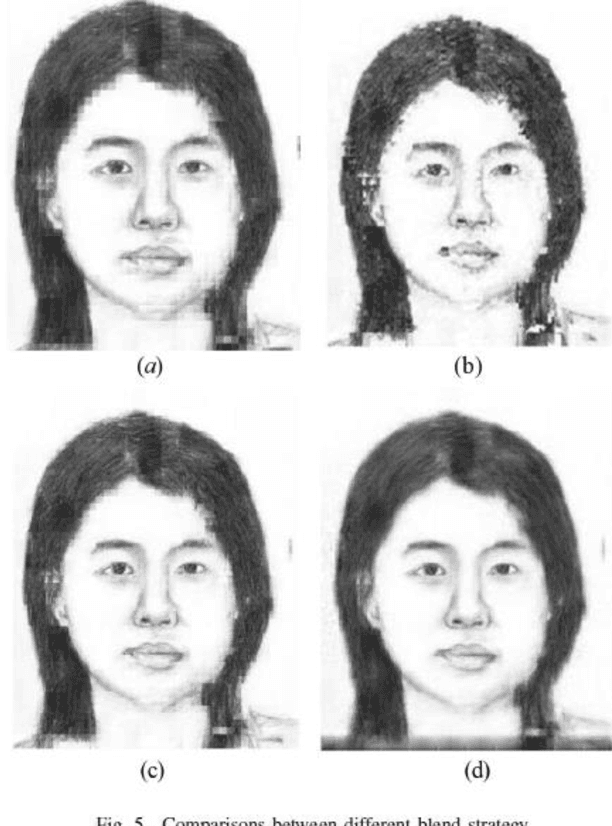
Face photo sketch synthesis has got some researchers' attention in recent years because of its potential applications in digital entertainment and law enforcement. Some patches based methods have been proposed to solve this problem. These methods usually focus more on how to get a sketch patch for a given photo patch than how to blend these generated patches. However, without appropriately blending method, some jagged parts and mottled points will appear in the entire face sketch. In order to get a smoother sketch, we propose a new method to reduce such jagged parts and mottled points. In our system, we resort to an existed method, which is Markov Random Fields (MRF), to train a crude face sketch firstly. Then this crude sketch face sketch will be divided into some larger patches again and retrained by Non-Negative Matrix Factorization (NMF). At last, we use Multiresolution Spline and a blend trick named full-coverage trick to blend these retrained patches. The experiment results show that compared with some previous method, we can get a smoother face sketch.
DANBO: Disentangled Articulated Neural Body Representations via Graph Neural Networks
May 03, 2022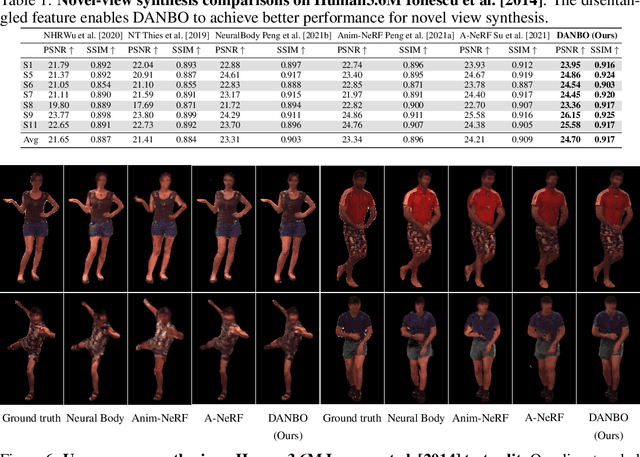
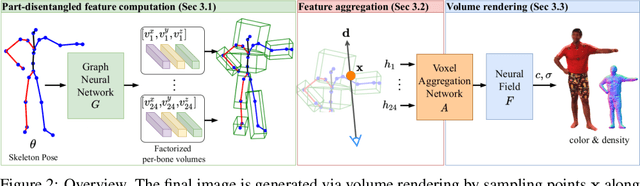
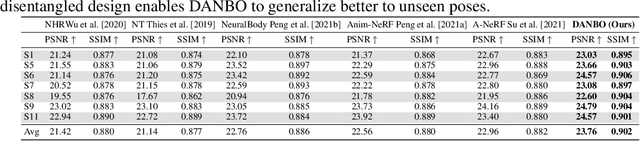
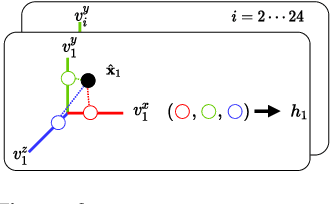
Deep learning greatly improved the realism of animatable human models by learning geometry and appearance from collections of 3D scans, template meshes, and multi-view imagery. High-resolution models enable photo-realistic avatars but at the cost of requiring studio settings not available to end users. Our goal is to create avatars directly from raw images without relying on expensive studio setups and surface tracking. While a few such approaches exist, those have limited generalization capabilities and are prone to learning spurious (chance) correlations between irrelevant body parts, resulting in implausible deformations and missing body parts on unseen poses. We introduce a three-stage method that induces two inductive biases to better disentangled pose-dependent deformation. First, we model correlations of body parts explicitly with a graph neural network. Second, to further reduce the effect of chance correlations, we introduce localized per-bone features that use a factorized volumetric representation and a new aggregation function. We demonstrate that our model produces realistic body shapes under challenging unseen poses and shows high-quality image synthesis. Our proposed representation strikes a better trade-off between model capacity, expressiveness, and robustness than competing methods. Project website: https://lemonatsu.github.io/danbo.
PCA-Based Knowledge Distillation Towards Lightweight and Content-Style Balanced Photorealistic Style Transfer Models
Mar 25, 2022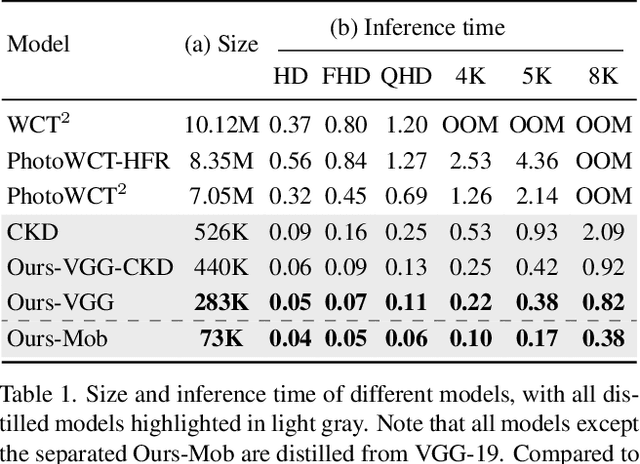
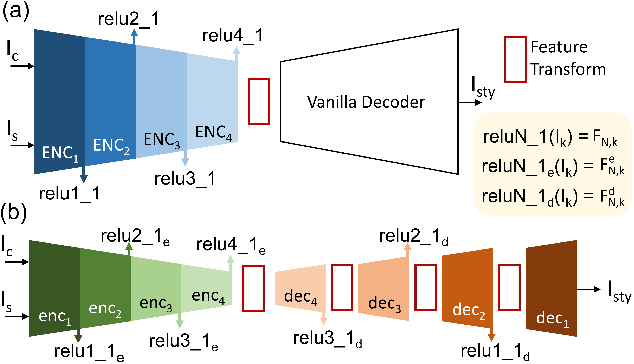
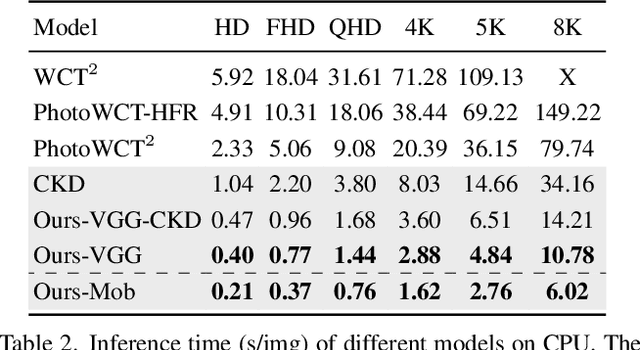
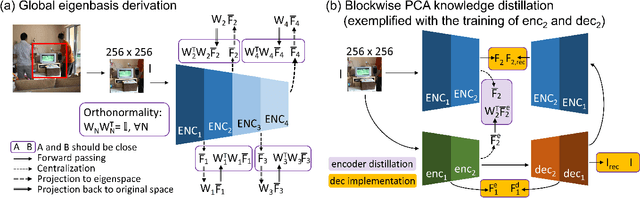
Photorealistic style transfer entails transferring the style of a reference image to another image so the result seems like a plausible photo. Our work is inspired by the observation that existing models are slow due to their large sizes. We introduce PCA-based knowledge distillation to distill lightweight models and show it is motivated by theory. To our knowledge, this is the first knowledge distillation method for photorealistic style transfer. Our experiments demonstrate its versatility for use with different backbone architectures, VGG and MobileNet, across six image resolutions. Compared to existing models, our top-performing model runs at speeds 5-20x faster using at most 1\% of the parameters. Additionally, our distilled models achieve a better balance between stylization strength and content preservation than existing models. To support reproducing our method and models, we share the code at \textit{https://github.com/chiutaiyin/PCA-Knowledge-Distillation}.
Semantic-Aware Latent Space Exploration for Face Image Restoration
Mar 06, 2022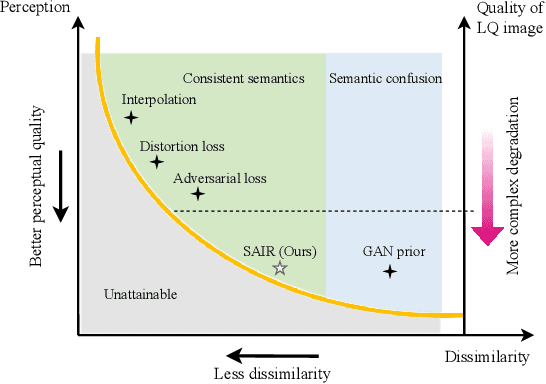
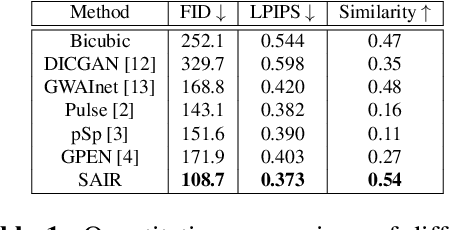
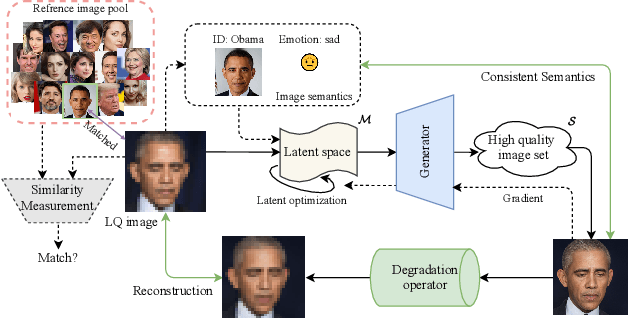
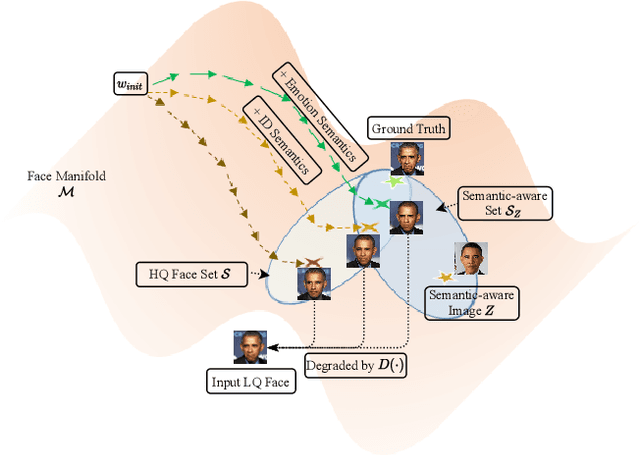
For image restoration, most existing deep learning based methods tend to overfit the training data leading to bad results when encountering unseen degradations out of the assumptions for training. To improve the robustness, generative adversarial network (GAN) prior based methods have been proposed, revealing a promising capability to restore photo-realistic and high-quality results. But these methods suffer from semantic confusion, especially on semantically significant images such as face images. In this paper, we propose a semantic-aware latent space exploration method for image restoration (SAIR). By explicitly modeling referenced semantics information, SAIR can consistently restore severely degraded images not only to high-resolution highly-realistic looks but also to correct semantics. Quantitative and qualitative experiments collectively demonstrate the effectiveness of the proposed SAIR. Our code can be found in https://github.com/Liamkuo/SAIR.
Text-to-Face Generation with StyleGAN2
May 25, 2022
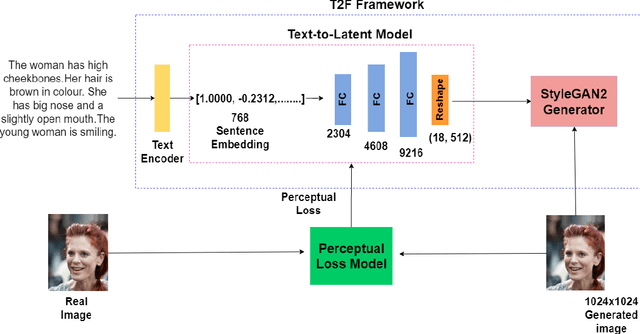
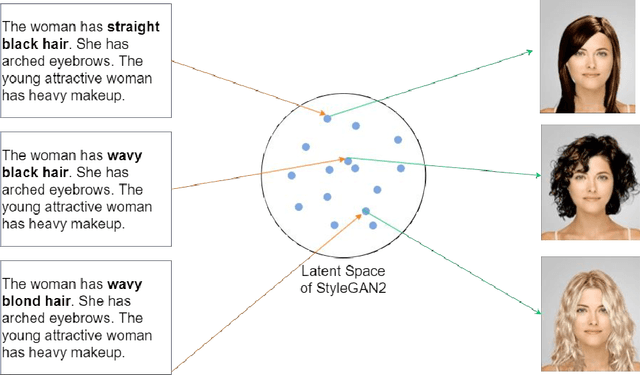
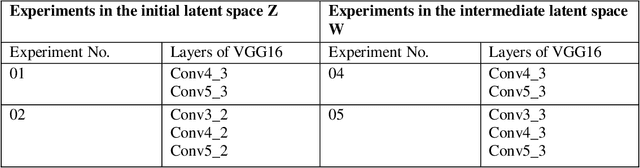
Synthesizing images from text descriptions has become an active research area with the advent of Generative Adversarial Networks. The main goal here is to generate photo-realistic images that are aligned with the input descriptions. Text-to-Face generation (T2F) is a sub-domain of Text-to-Image generation (T2I) that is more challenging due to the complexity and variation of facial attributes. It has a number of applications mainly in the domain of public safety. Even though several models are available for T2F, there is still the need to improve the image quality and the semantic alignment. In this research, we propose a novel framework, to generate facial images that are well-aligned with the input descriptions. Our framework utilizes the high-resolution face generator, StyleGAN2, and explores the possibility of using it in T2F. Here, we embed text in the input latent space of StyleGAN2 using BERT embeddings and oversee the generation of facial images using text descriptions. We trained our framework on attribute-based descriptions to generate images of 1024x1024 in resolution. The images generated exhibit a 57% similarity to the ground truth images, with a face semantic distance of 0.92, outperforming state-of-the-artwork. The generated images have a FID score of 118.097 and the experimental results show that our model generates promising images.
* 16 pages, 5 figures, for conference, https://aircconline.com/csit/papers/vol12/csit120805.pdf
Artemis: Articulated Neural Pets with Appearance and Motion synthesis
Feb 11, 2022
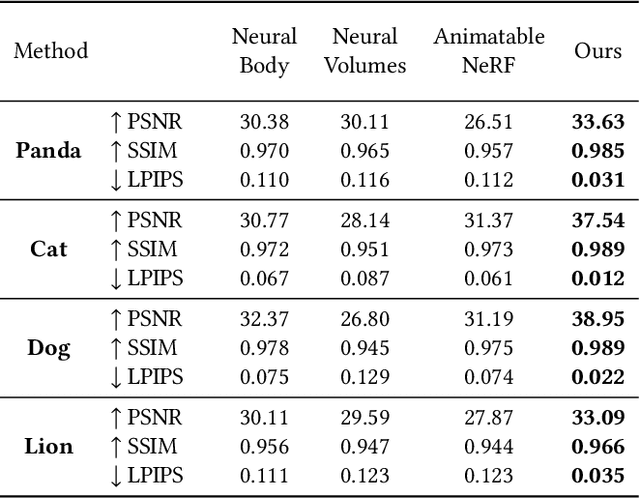
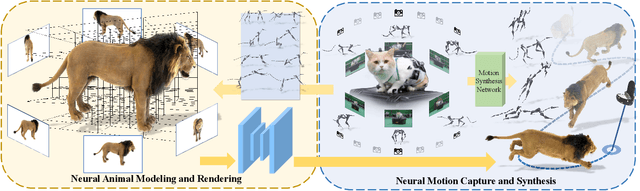
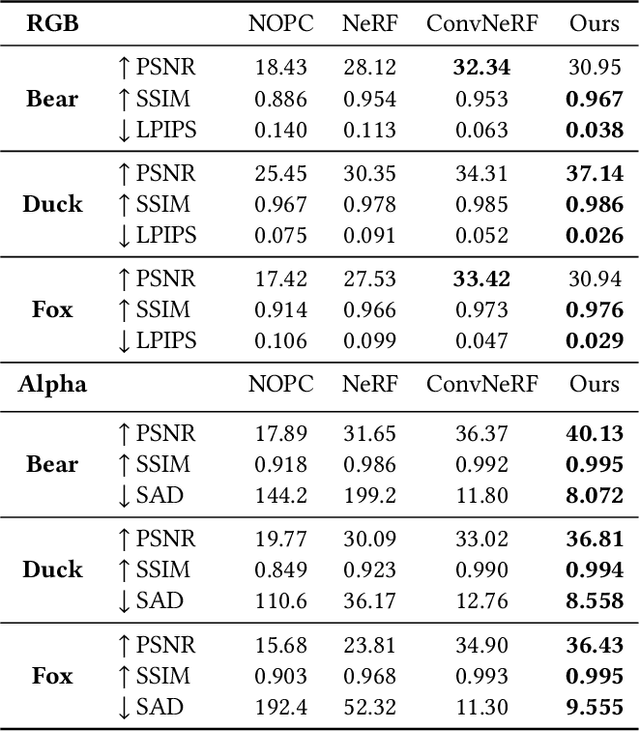
We human are entering into a virtual era, and surely want to bring animals to virtual world as well for companion. Yet, computer-generated (CGI) furry animals is limited by tedious off-line rendering, let alone interactive motion control. In this paper, we present ARTEMIS, a novel neural modeling and rendering pipeline for generating ARTiculated neural pets with appEarance and Motion synthesIS. Our ARTEMIS enables interactive motion control, real-time animation and photo-realistic rendering of furry animals. The core of ARTEMIS is a neural-generated (NGI) animal engine, which adopts an efficient octree based representation for animal animation and fur rendering. The animation then becomes equivalent to voxel level skeleton based deformation. We further use a fast octree indexing, an efficient volumetric rendering scheme to generate appearance and density features maps. Finally, we propose a novel shading network to generate high-fidelity details of appearance and opacity under novel poses. For the motion control module in ARTEMIS, we combine state-of-the-art animal motion capture approach with neural character control scheme. We introduce an effective optimization scheme to reconstruct skeletal motion of real animals captured by a multi-view RGB and Vicon camera array. We feed the captured motion into a neural character control scheme to generate abstract control signals with motion styles. We further integrate ARTEMIS into existing engines that support VR headsets, providing an unprecedented immersive experience where a user can intimately interact with a variety of virtual animals with vivid movements and photo-realistic appearance. Extensive experiments and showcases demonstrate the effectiveness of our ARTEMIS system to achieve highly realistic rendering of NGI animals in real-time, providing daily immersive and interactive experience with digital animals unseen before.
Domain-Aware Universal Style Transfer
Aug 17, 2021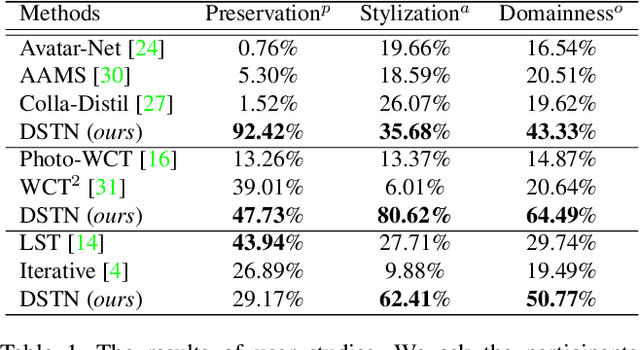
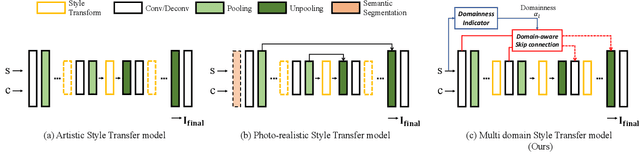
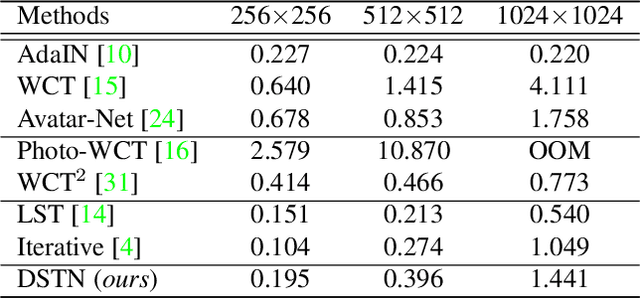
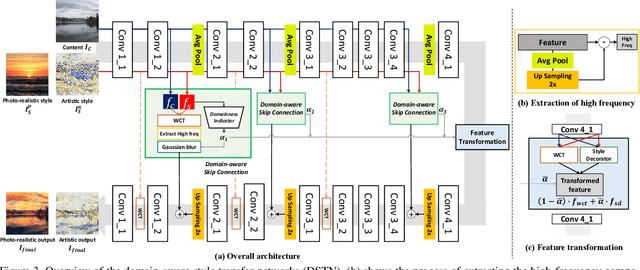
Style transfer aims to reproduce content images with the styles from reference images. Existing universal style transfer methods successfully deliver arbitrary styles to original images either in an artistic or a photo-realistic way. However, the range of 'arbitrary style' defined by existing works is bounded in the particular domain due to their structural limitation. Specifically, the degrees of content preservation and stylization are established according to a predefined target domain. As a result, both photo-realistic and artistic models have difficulty in performing the desired style transfer for the other domain. To overcome this limitation, we propose a unified architecture, Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. To this end, we design a novel domainness indicator that captures the domainness value from the texture and structural features of reference images. Moreover, we introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator. Our extensive experiments validate that our model produces better qualitative results and outperforms previous methods in terms of proxy metrics on both artistic and photo-realistic stylizations.
MoFaNeRF: Morphable Facial Neural Radiance Field
Dec 04, 2021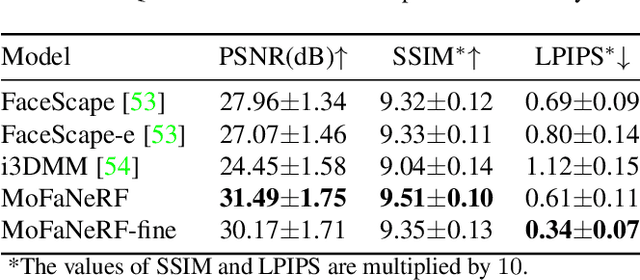
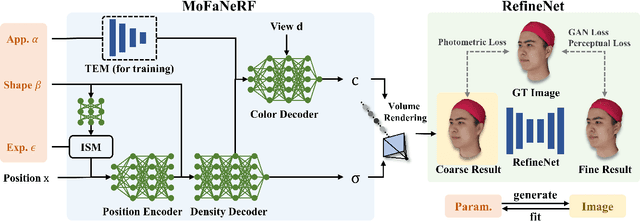
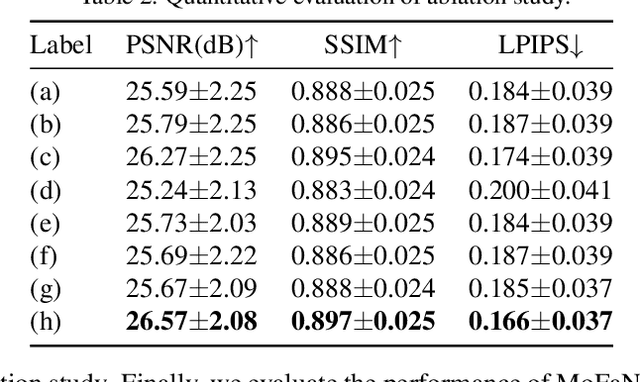

We propose a parametric model that maps free-view images into a vector space of coded facial shape, expression and appearance using a neural radiance field, namely Morphable Facial NeRF. Specifically, MoFaNeRF takes the coded facial shape, expression and appearance along with space coordinate and view direction as input to an MLP, and outputs the radiance of the space point for photo-realistic image synthesis. Compared with conventional 3D morphable models (3DMM), MoFaNeRF shows superiority in directly synthesizing photo-realistic facial details even for eyes, mouths, and beards. Also, continuous face morphing can be easily achieved by interpolating the input shape, expression and appearance codes. By introducing identity-specific modulation and texture encoder, our model synthesizes accurate photometric details and shows strong representation ability. Our model shows strong ability on multiple applications including image-based fitting, random generation, face rigging, face editing, and novel view synthesis. Experiments show that our method achieves higher representation ability than previous parametric models, and achieves competitive performance in several applications. To the best of our knowledge, our work is the first facial parametric model built upon a neural radiance field that can be used in fitting, generation and manipulation. Our code and model are released in https://github.com/zhuhao-nju/mofanerf.
LinesToFacePhoto: Face Photo Generation from Lines with Conditional Self-Attention Generative Adversarial Network
Oct 20, 2019
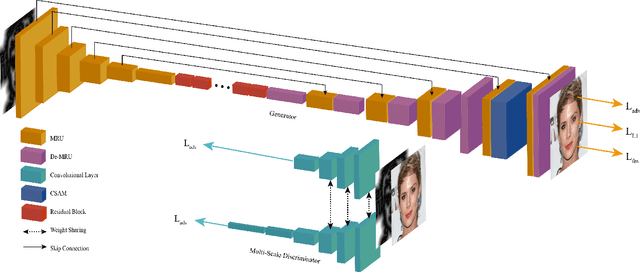
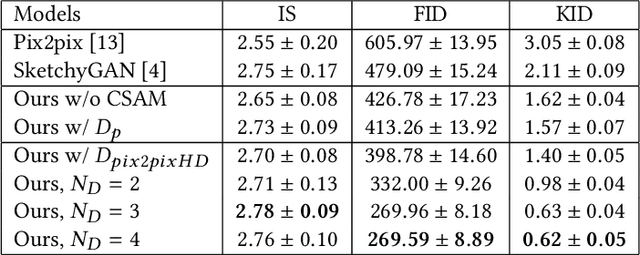

In this paper, we explore the task of generating photo-realistic face images from lines. Previous methods based on conditional generative adversarial networks (cGANs) have shown their power to generate visually plausible images when a conditional image and an output image share well-aligned structures. However, these models fail to synthesize face images with a whole set of well-defined structures, e.g. eyes, noses, mouths, etc., especially when the conditional line map lacks one or several parts. To address this problem, we propose a conditional self-attention generative adversarial network (CSAGAN). We introduce a conditional self-attention mechanism to cGANs to capture long-range dependencies between different regions in faces. We also build a multi-scale discriminator. The large-scale discriminator enforces the completeness of global structures and the small-scale discriminator encourages fine details, thereby enhancing the realism of generated face images. We evaluate the proposed model on the CelebA-HD dataset by two perceptual user studies and three quantitative metrics. The experiment results demonstrate that our method generates high-quality facial images while preserving facial structures. Our results outperform state-of-the-art methods both quantitatively and qualitatively.
Sim-to-Real 6D Object Pose Estimation via Iterative Self-training for Robotic Bin-picking
Apr 14, 2022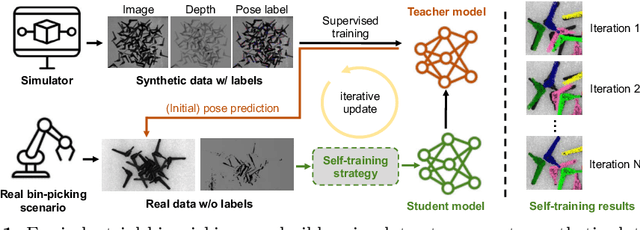
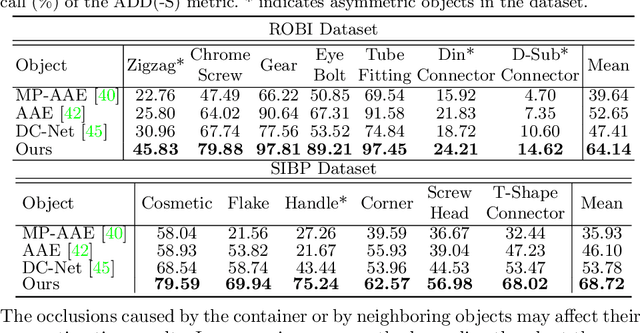
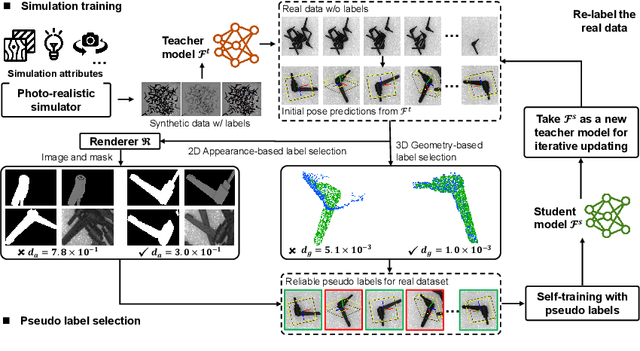
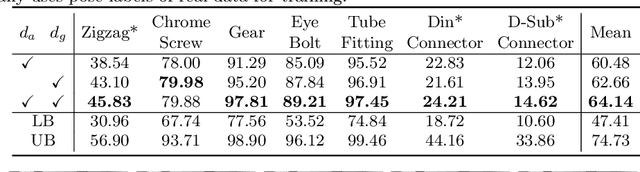
In this paper, we propose an iterative self-training framework for sim-to-real 6D object pose estimation to facilitate cost-effective robotic grasping. Given a bin-picking scenario, we establish a photo-realistic simulator to synthesize abundant virtual data, and use this to train an initial pose estimation network. This network then takes the role of a teacher model, which generates pose predictions for unlabeled real data. With these predictions, we further design a comprehensive adaptive selection scheme to distinguish reliable results, and leverage them as pseudo labels to update a student model for pose estimation on real data. To continuously improve the quality of pseudo labels, we iterate the above steps by taking the trained student model as a new teacher and re-label real data using the refined teacher model. We evaluate our method on a public benchmark and our newly-released dataset, achieving an ADD(-S) improvement of 11.49% and 22.62% respectively. Our method is also able to improve robotic bin-picking success by 19.54%, demonstrating the potential of iterative sim-to-real solutions for robotic applications.