 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Generating Photo-Realistic Training Data to Improve Face Recognition Accuracy
Oct 31, 2018
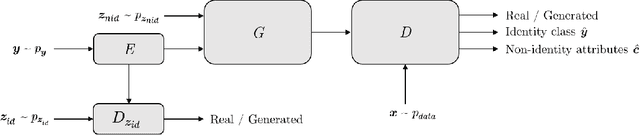


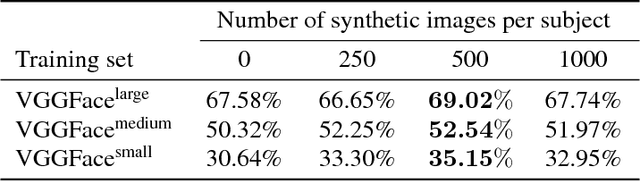
In this paper we investigate the feasibility of using synthetic data to augment face datasets. In particular, we propose a novel generative adversarial network (GAN) that can disentangle identity-related attributes from non-identity-related attributes. This is done by training an embedding network that maps discrete identity labels to an identity latent space that follows a simple prior distribution, and training a GAN conditioned on samples from that distribution. Our proposed GAN allows us to augment face datasets by generating both synthetic images of subjects in the training set and synthetic images of new subjects not in the training set. By using recent advances in GAN training, we show that the synthetic images generated by our model are photo-realistic, and that training with augmented datasets can indeed increase the accuracy of face recognition models as compared with models trained with real images alone.
ShoeRinsics: Shoeprint Prediction for Forensics with Intrinsic Decomposition
May 04, 2022


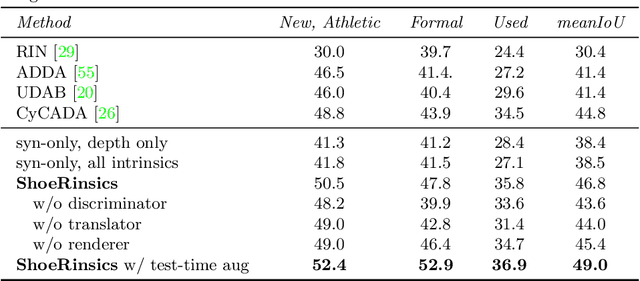
Shoe tread impressions are one of the most common types of evidence left at crime scenes. However, the utility of such evidence is limited by the lack of databases of footwear impression patterns that cover the huge and growing number of distinct shoe models. We propose to address this gap by leveraging shoe tread photographs collected by online retailers. The core challenge is to predict the impression pattern from the shoe photograph since ground-truth impressions or 3D shapes of tread patterns are not available. We develop a model that performs intrinsic image decomposition (predicting depth, normal, albedo, and lighting) from a single tread photo. Our approach, which we term ShoeRinsics, combines domain adaptation and re-rendering losses in order to leverage a mix of fully supervised synthetic data and unsupervised retail image data. To validate model performance, we also collected a set of paired shoe-sole images and corresponding prints, and define a benchmarking protocol to quantify the accuracy of predicted impressions. On this benchmark, ShoeRinsics outperforms existing methods for depth prediction and synthetic-to-real domain adaptation.
Jointly Harnessing Prior Structures and Temporal Consistency for Sign Language Video Generation
Jul 08, 2022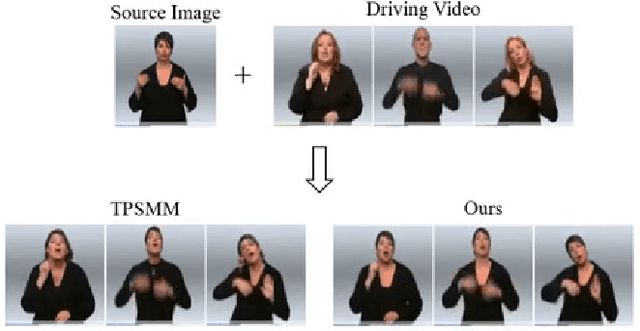
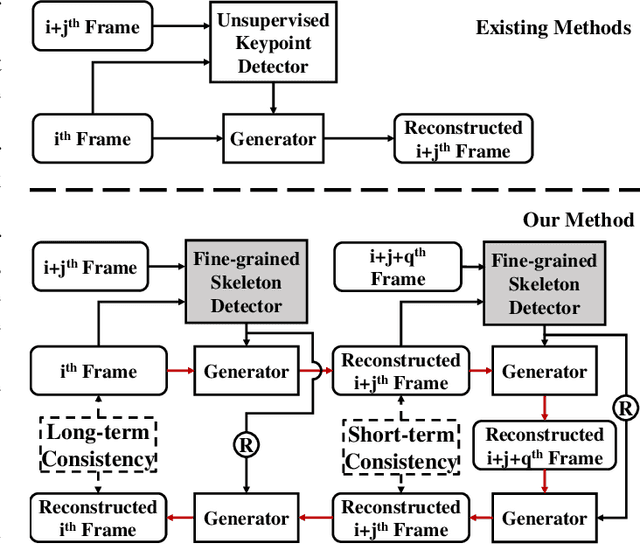
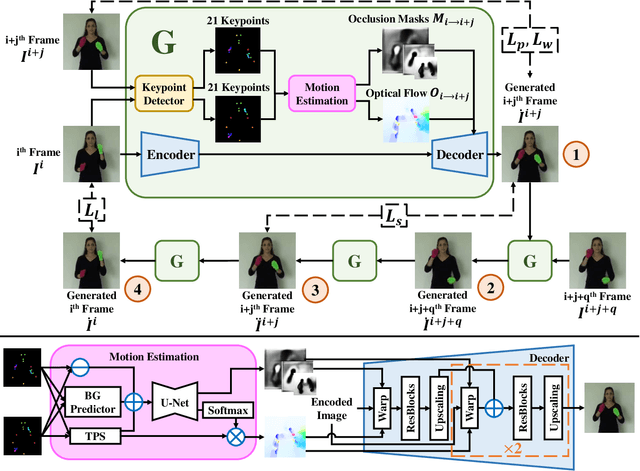

Sign language is the window for people differently-abled to express their feelings as well as emotions. However, it remains challenging for people to learn sign language in a short time. To address this real-world challenge, in this work, we study the motion transfer system, which can transfer the user photo to the sign language video of specific words. In particular, the appearance content of the output video comes from the provided user image, while the motion of the video is extracted from the specified tutorial video. We observe two primary limitations in adopting the state-of-the-art motion transfer methods to sign language generation:(1) Existing motion transfer works ignore the prior geometrical knowledge of the human body. (2) The previous image animation methods only take image pairs as input in the training stage, which could not fully exploit the temporal information within videos. In an attempt to address the above-mentioned limitations, we propose Structure-aware Temporal Consistency Network (STCNet) to jointly optimize the prior structure of human with the temporal consistency for sign language video generation. There are two main contributions in this paper. (1) We harness a fine-grained skeleton detector to provide prior knowledge of the body keypoints. In this way, we ensure the keypoint movement in a valid range and make the model become more explainable and robust. (2) We introduce two cycle-consistency losses, i.e., short-term cycle loss and long-term cycle loss, which are conducted to assure the continuity of the generated video. We optimize the two losses and keypoint detector network in an end-to-end manner.
TileGen: Tileable, Controllable Material Generation and Capture
Jun 20, 2022



Recent methods (e.g. MaterialGAN) have used unconditional GANs to generate per-pixel material maps, or as a prior to reconstruct materials from input photographs. These models can generate varied random material appearance, but do not have any mechanism to constrain the generated material to a specific category or to control the coarse structure of the generated material, such as the exact brick layout on a brick wall. Furthermore, materials reconstructed from a single input photo commonly have artifacts and are generally not tileable, which limits their use in practical content creation pipelines. We propose TileGen, a generative model for SVBRDFs that is specific to a material category, always tileable, and optionally conditional on a provided input structure pattern. TileGen is a variant of StyleGAN whose architecture is modified to always produce tileable (periodic) material maps. In addition to the standard "style" latent code, TileGen can optionally take a condition image, giving a user direct control over the dominant spatial (and optionally color) features of the material. For example, in brick materials, the user can specify a brick layout and the brick color, or in leather materials, the locations of wrinkles and folds. Our inverse rendering approach can find a material perceptually matching a single target photograph by optimization. This reconstruction can also be conditional on a user-provided pattern. The resulting materials are tileable, can be larger than the target image, and are editable by varying the condition.
CARLA-GeAR: a Dataset Generator for a Systematic Evaluation of Adversarial Robustness of Vision Models
Jun 09, 2022
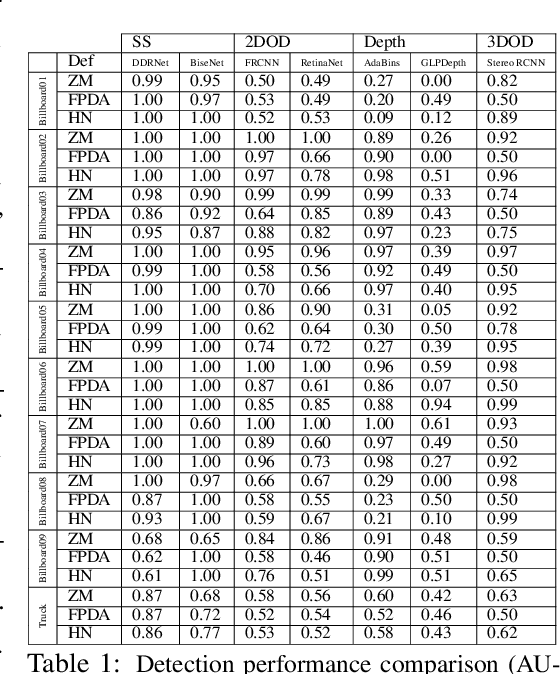
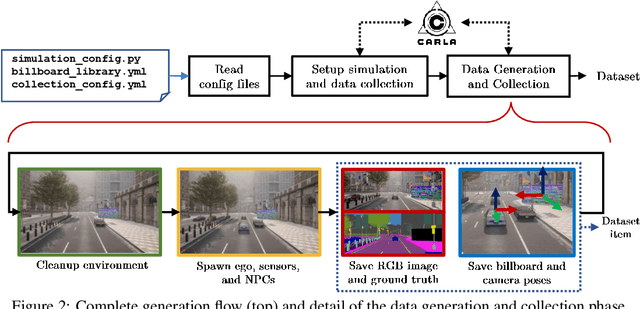
Adversarial examples represent a serious threat for deep neural networks in several application domains and a huge amount of work has been produced to investigate them and mitigate their effects. Nevertheless, no much work has been devoted to the generation of datasets specifically designed to evaluate the adversarial robustness of neural models. This paper presents CARLA-GeAR, a tool for the automatic generation of photo-realistic synthetic datasets that can be used for a systematic evaluation of the adversarial robustness of neural models against physical adversarial patches, as well as for comparing the performance of different adversarial defense/detection methods. The tool is built on the CARLA simulator, using its Python API, and allows the generation of datasets for several vision tasks in the context of autonomous driving. The adversarial patches included in the generated datasets are attached to billboards or the back of a truck and are crafted by using state-of-the-art white-box attack strategies to maximize the prediction error of the model under test. Finally, the paper presents an experimental study to evaluate the performance of some defense methods against such attacks, showing how the datasets generated with CARLA-GeAR might be used in future work as a benchmark for adversarial defense in the real world. All the code and datasets used in this paper are available at http://carlagear.retis.santannapisa.it.
Comparision and analysis of photo image forgery detection techniques
Jan 10, 2013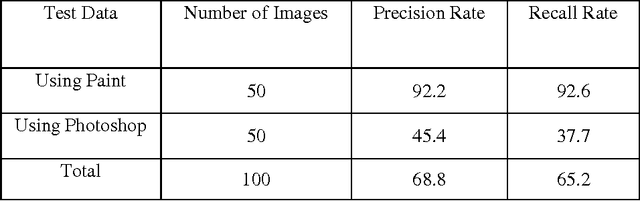


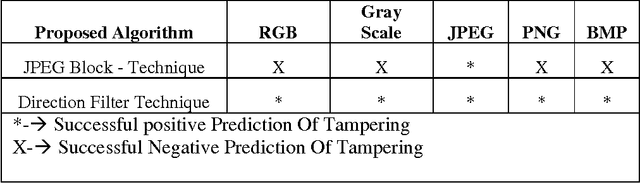
Digital Photo images are everywhere, on the covers of magazines, in newspapers, in courtrooms, and all over the Internet. We are exposed to them throughout the day and most of the time. Ease with which images can be manipulated; we need to be aware that seeing does not always imply believing. We propose methodologies to identify such unbelievable photo images and succeeded to identify forged region by given only the forged image. Formats are additive tag for every file system and contents are relatively expressed with extension based on most popular digital camera uses JPEG and Other image formats like png, bmp etc. We have designed algorithm running behind with the concept of abnormal anomalies and identify the forgery regions.
OptGAN: Optimizing and Interpreting the Latent Space of the Conditional Text-to-Image GANs
Feb 25, 2022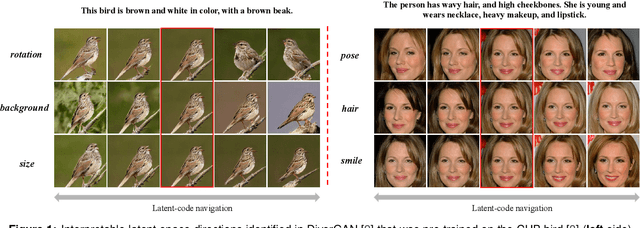

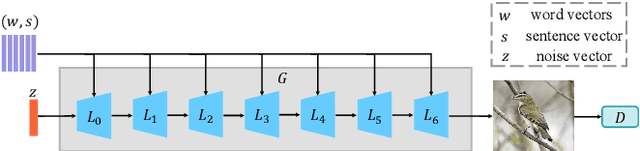
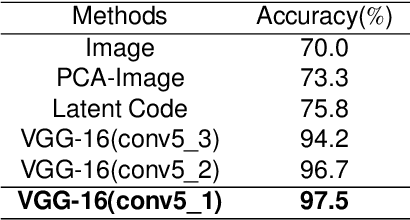
Text-to-image generation intends to automatically produce a photo-realistic image, conditioned on a textual description. It can be potentially employed in the field of art creation, data augmentation, photo-editing, etc. Although many efforts have been dedicated to this task, it remains particularly challenging to generate believable, natural scenes. To facilitate the real-world applications of text-to-image synthesis, we focus on studying the following three issues: 1) How to ensure that generated samples are believable, realistic or natural? 2) How to exploit the latent space of the generator to edit a synthesized image? 3) How to improve the explainability of a text-to-image generation framework? In this work, we constructed two novel data sets (i.e., the Good & Bad bird and face data sets) consisting of successful as well as unsuccessful generated samples, according to strict criteria. To effectively and efficiently acquire high-quality images by increasing the probability of generating Good latent codes, we use a dedicated Good/Bad classifier for generated images. It is based on a pre-trained front end and fine-tuned on the basis of the proposed Good & Bad data set. After that, we present a novel algorithm which identifies semantically-understandable directions in the latent space of a conditional text-to-image GAN architecture by performing independent component analysis on the pre-trained weight values of the generator. Furthermore, we develop a background-flattening loss (BFL), to improve the background appearance in the edited image. Subsequently, we introduce linear interpolation analysis between pairs of keywords. This is extended into a similar triangular `linguistic' interpolation in order to take a deep look into what a text-to-image synthesis model has learned within the linguistic embeddings. Our data set is available at https://zenodo.org/record/6283798#.YhkN_ujMI2w.
NeuVV: Neural Volumetric Videos with Immersive Rendering and Editing
Feb 12, 2022
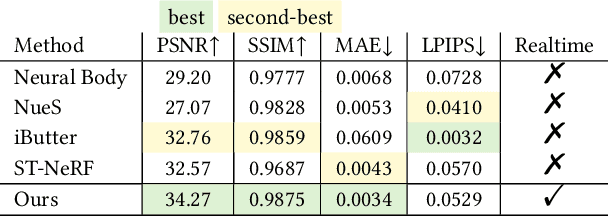
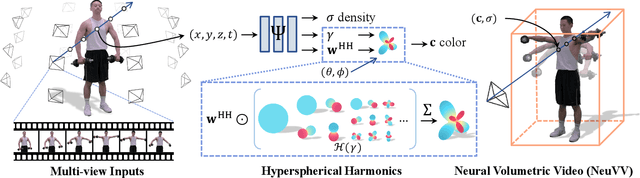
Some of the most exciting experiences that Metaverse promises to offer, for instance, live interactions with virtual characters in virtual environments, require real-time photo-realistic rendering. 3D reconstruction approaches to rendering, active or passive, still require extensive cleanup work to fix the meshes or point clouds. In this paper, we present a neural volumography technique called neural volumetric video or NeuVV to support immersive, interactive, and spatial-temporal rendering of volumetric video contents with photo-realism and in real-time. The core of NeuVV is to efficiently encode a dynamic neural radiance field (NeRF) into renderable and editable primitives. We introduce two types of factorization schemes: a hyper-spherical harmonics (HH) decomposition for modeling smooth color variations over space and time and a learnable basis representation for modeling abrupt density and color changes caused by motion. NeuVV factorization can be integrated into a Video Octree (VOctree) analogous to PlenOctree to significantly accelerate training while reducing memory overhead. Real-time NeuVV rendering further enables a class of immersive content editing tools. Specifically, NeuVV treats each VOctree as a primitive and implements volume-based depth ordering and alpha blending to realize spatial-temporal compositions for content re-purposing. For example, we demonstrate positioning varied manifestations of the same performance at different 3D locations with different timing, adjusting color/texture of the performer's clothing, casting spotlight shadows and synthesizing distance falloff lighting, etc, all at an interactive speed. We further develop a hybrid neural-rasterization rendering framework to support consumer-level VR headsets so that the aforementioned volumetric video viewing and editing, for the first time, can be conducted immersively in virtual 3D space.
CNN-based Real-time Dense Face Reconstruction with Inverse-rendered Photo-realistic Face Images
May 15, 2018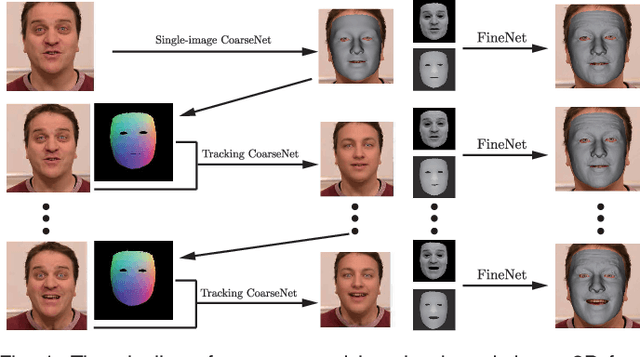
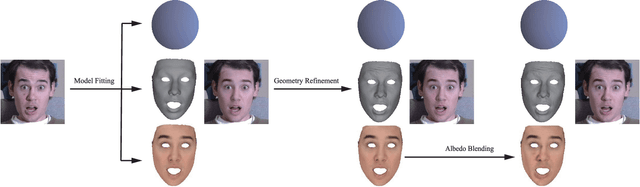

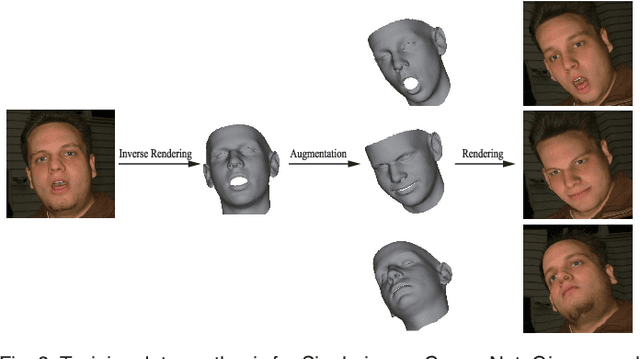
With the powerfulness of convolution neural networks (CNN), CNN based face reconstruction has recently shown promising performance in reconstructing detailed face shape from 2D face images. The success of CNN-based methods relies on a large number of labeled data. The state-of-the-art synthesizes such data using a coarse morphable face model, which however has difficulty to generate detailed photo-realistic images of faces (with wrinkles). This paper presents a novel face data generation method. Specifically, we render a large number of photo-realistic face images with different attributes based on inverse rendering. Furthermore, we construct a fine-detailed face image dataset by transferring different scales of details from one image to another. We also construct a large number of video-type adjacent frame pairs by simulating the distribution of real video data. With these nicely constructed datasets, we propose a coarse-to-fine learning framework consisting of three convolutional networks. The networks are trained for real-time detailed 3D face reconstruction from monocular video as well as from a single image. Extensive experimental results demonstrate that our framework can produce high-quality reconstruction but with much less computation time compared to the state-of-the-art. Moreover, our method is robust to pose, expression and lighting due to the diversity of data.
Face Photo Sketch Synthesis via Larger Patch and Multiresolution Spline
Sep 19, 2015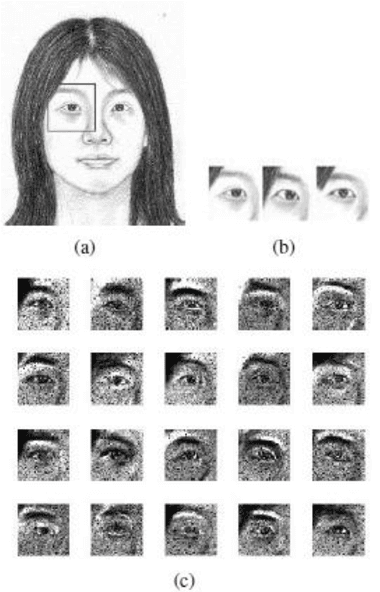
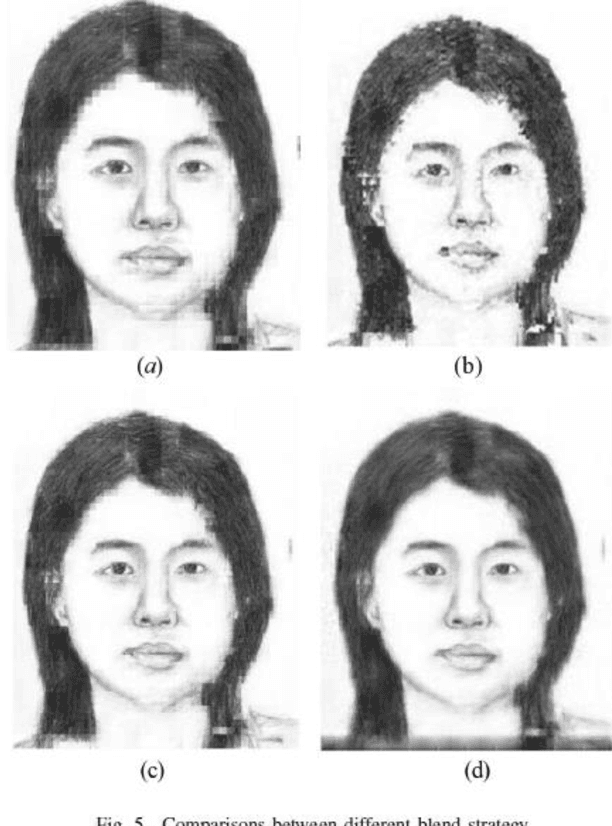
Face photo sketch synthesis has got some researchers' attention in recent years because of its potential applications in digital entertainment and law enforcement. Some patches based methods have been proposed to solve this problem. These methods usually focus more on how to get a sketch patch for a given photo patch than how to blend these generated patches. However, without appropriately blending method, some jagged parts and mottled points will appear in the entire face sketch. In order to get a smoother sketch, we propose a new method to reduce such jagged parts and mottled points. In our system, we resort to an existed method, which is Markov Random Fields (MRF), to train a crude face sketch firstly. Then this crude sketch face sketch will be divided into some larger patches again and retrained by Non-Negative Matrix Factorization (NMF). At last, we use Multiresolution Spline and a blend trick named full-coverage trick to blend these retrained patches. The experiment results show that compared with some previous method, we can get a smoother face sketch.