 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
TAVA: Template-free Animatable Volumetric Actors
Jun 21, 2022
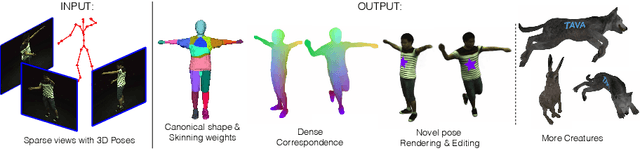

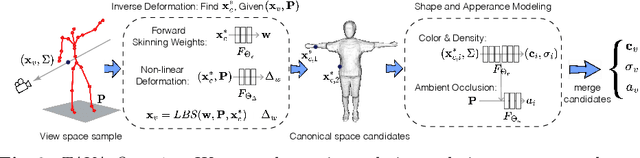
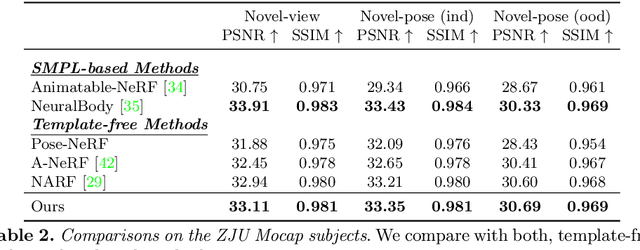
Coordinate-based volumetric representations have the potential to generate photo-realistic virtual avatars from images. However, virtual avatars also need to be controllable even to a novel pose that may not have been observed. Traditional techniques, such as LBS, provide such a function; yet it usually requires a hand-designed body template, 3D scan data, and limited appearance models. On the other hand, neural representation has been shown to be powerful in representing visual details, but are under explored on deforming dynamic articulated actors. In this paper, we propose TAVA, a method to create T emplate-free Animatable Volumetric Actors, based on neural representations. We rely solely on multi-view data and a tracked skeleton to create a volumetric model of an actor, which can be animated at the test time given novel pose. Since TAVA does not require a body template, it is applicable to humans as well as other creatures such as animals. Furthermore, TAVA is designed such that it can recover accurate dense correspondences, making it amenable to content-creation and editing tasks. Through extensive experiments, we demonstrate that the proposed method generalizes well to novel poses as well as unseen views and showcase basic editing capabilities.
Neural Photo Editing with Introspective Adversarial Networks
Feb 06, 2017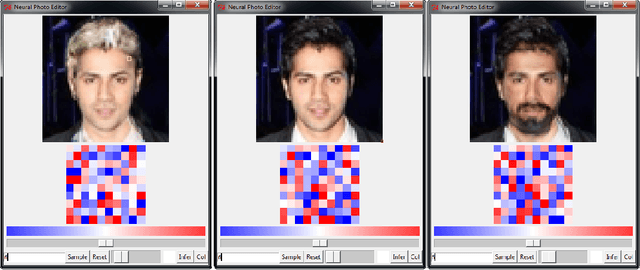
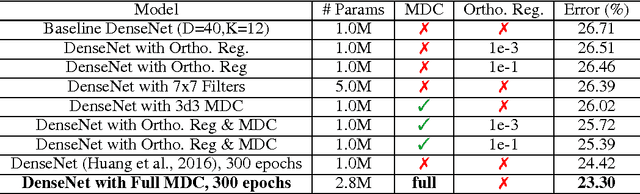

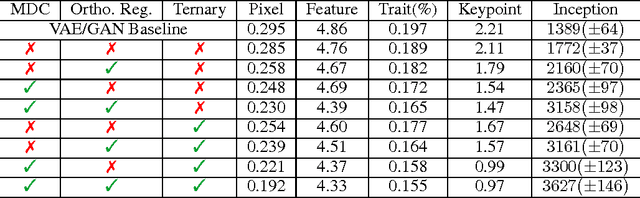
The increasingly photorealistic sample quality of generative image models suggests their feasibility in applications beyond image generation. We present the Neural Photo Editor, an interface that leverages the power of generative neural networks to make large, semantically coherent changes to existing images. To tackle the challenge of achieving accurate reconstructions without loss of feature quality, we introduce the Introspective Adversarial Network, a novel hybridization of the VAE and GAN. Our model efficiently captures long-range dependencies through use of a computational block based on weight-shared dilated convolutions, and improves generalization performance with Orthogonal Regularization, a novel weight regularization method. We validate our contributions on CelebA, SVHN, and CIFAR-100, and produce samples and reconstructions with high visual fidelity.
Unmanned Aerial Vehicle Instrumentation for Rapid Aerial Photo System
Apr 24, 2008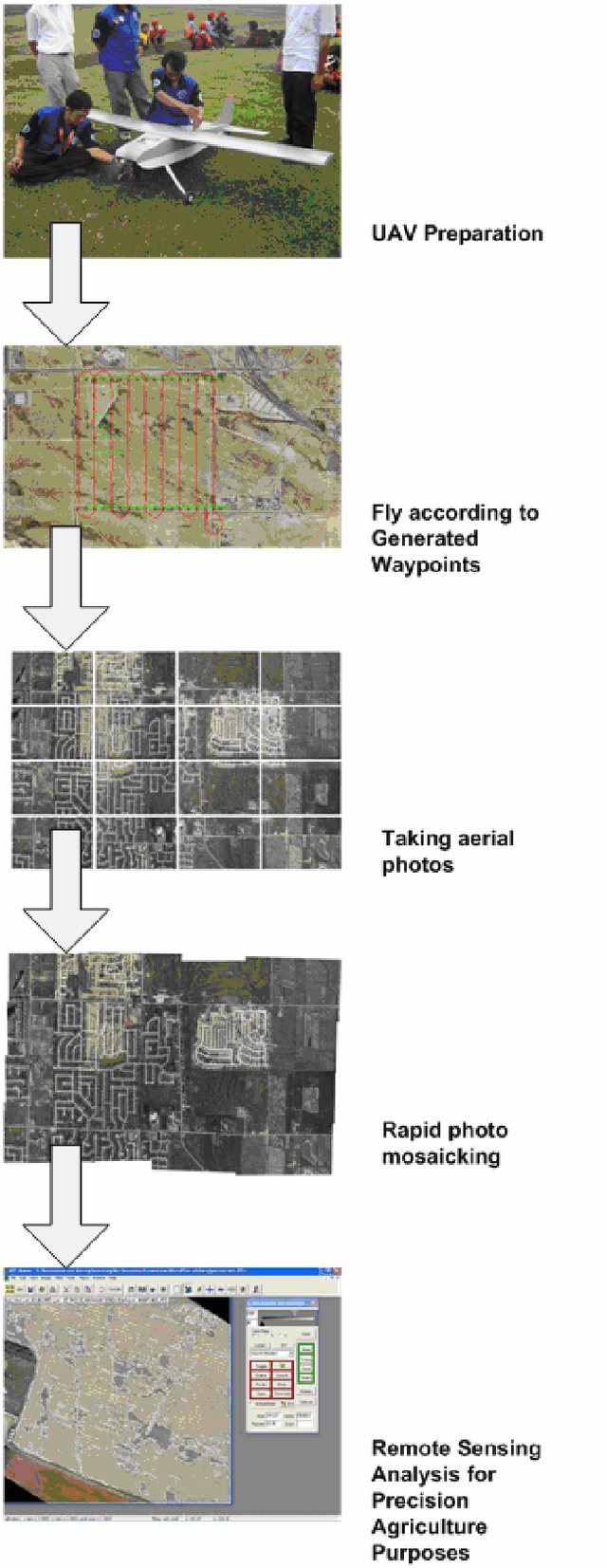


This research will proposed a new kind of relatively low cost autonomous UAV that will enable farmers to make just in time mosaics of aerial photo of their crop. These mosaics of aerial photo should be able to be produced with relatively low cost and within the 24 hours of acquisition constraint. The autonomous UAV will be equipped with payload management system specifically developed for rapid aerial mapping. As mentioned before turn around time is the key factor, so accuracy is not the main focus (not orthorectified aerial mapping). This system will also be equipped with special software to post process the aerial photos to produce the mosaic aerial photo map
* Uploaded by ICIUS2007 Conference Organizer on behalf of the author(s). 8 pages, 9 figures
SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image Enhancement
Jul 18, 2022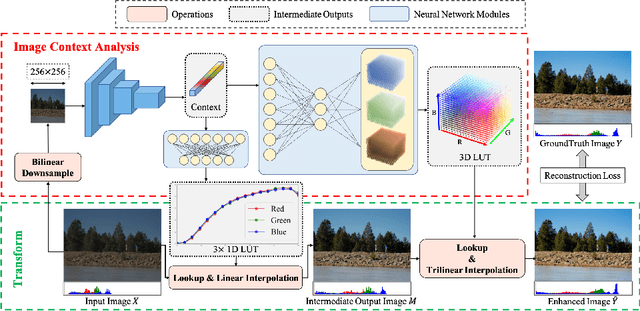
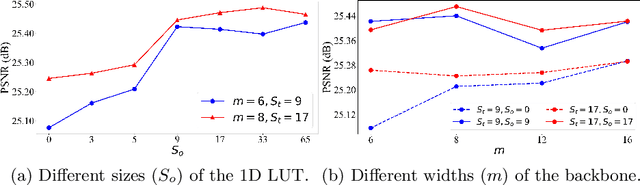
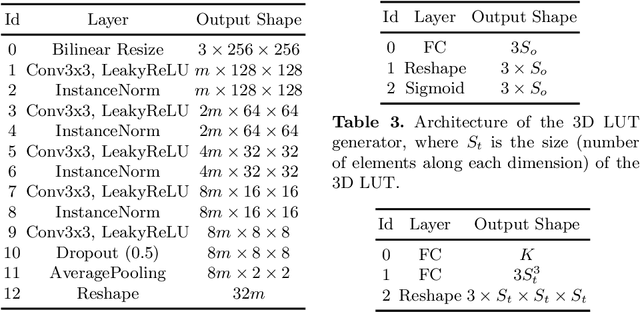
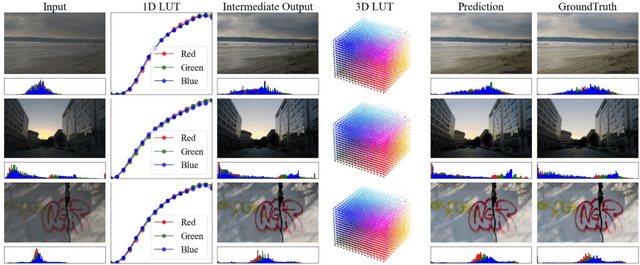
Image-adaptive lookup tables (LUTs) have achieved great success in real-time image enhancement tasks due to their high efficiency for modeling color transforms. However, they embed the complete transform, including the color component-independent and the component-correlated parts, into only a single type of LUTs, either 1D or 3D, in a coupled manner. This scheme raises a dilemma of improving model expressiveness or efficiency due to two factors. On the one hand, the 1D LUTs provide high computational efficiency but lack the critical capability of color components interaction. On the other, the 3D LUTs present enhanced component-correlated transform capability but suffer from heavy memory footprint, high training difficulty, and limited cell utilization. Inspired by the conventional divide-and-conquer practice in the image signal processor, we present SepLUT (separable image-adaptive lookup table) to tackle the above limitations. Specifically, we separate a single color transform into a cascade of component-independent and component-correlated sub-transforms instantiated as 1D and 3D LUTs, respectively. In this way, the capabilities of two sub-transforms can facilitate each other, where the 3D LUT complements the ability to mix up color components, and the 1D LUT redistributes the input colors to increase the cell utilization of the 3D LUT and thus enable the use of a more lightweight 3D LUT. Experiments demonstrate that the proposed method presents enhanced performance on photo retouching benchmark datasets than the current state-of-the-art and achieves real-time processing on both GPUs and CPUs.
Scene Aware Person Image Generation through Global Contextual Conditioning
Jun 06, 2022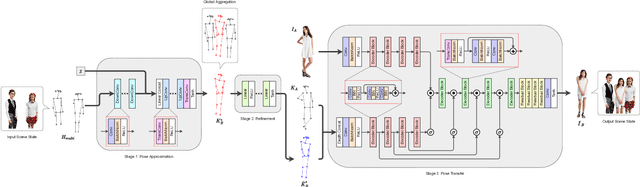
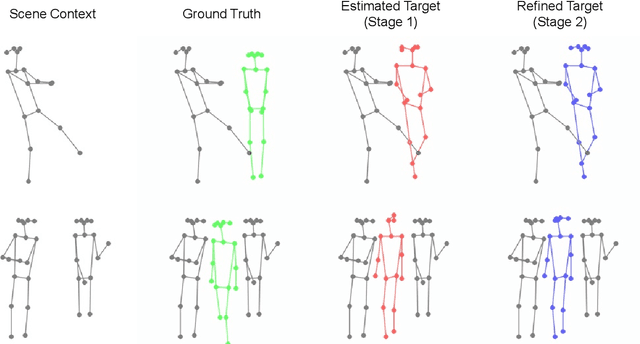


Person image generation is an intriguing yet challenging problem. However, this task becomes even more difficult under constrained situations. In this work, we propose a novel pipeline to generate and insert contextually relevant person images into an existing scene while preserving the global semantics. More specifically, we aim to insert a person such that the location, pose, and scale of the person being inserted blends in with the existing persons in the scene. Our method uses three individual networks in a sequential pipeline. At first, we predict the potential location and the skeletal structure of the new person by conditioning a Wasserstein Generative Adversarial Network (WGAN) on the existing human skeletons present in the scene. Next, the predicted skeleton is refined through a shallow linear network to achieve higher structural accuracy in the generated image. Finally, the target image is generated from the refined skeleton using another generative network conditioned on a given image of the target person. In our experiments, we achieve high-resolution photo-realistic generation results while preserving the general context of the scene. We conclude our paper with multiple qualitative and quantitative benchmarks on the results.
Multimodal Prediction and Personalization of Photo Edits with Deep Generative Models
Apr 17, 2017

Professional-grade software applications are powerful but complicated$-$expert users can achieve impressive results, but novices often struggle to complete even basic tasks. Photo editing is a prime example: after loading a photo, the user is confronted with an array of cryptic sliders like "clarity", "temp", and "highlights". An automatically generated suggestion could help, but there is no single "correct" edit for a given image$-$different experts may make very different aesthetic decisions when faced with the same image, and a single expert may make different choices depending on the intended use of the image (or on a whim). We therefore want a system that can propose multiple diverse, high-quality edits while also learning from and adapting to a user's aesthetic preferences. In this work, we develop a statistical model that meets these objectives. Our model builds on recent advances in neural network generative modeling and scalable inference, and uses hierarchical structure to learn editing patterns across many diverse users. Empirically, we find that our model outperforms other approaches on this challenging multimodal prediction task.
What makes domain generalization hard?
Jun 15, 2022
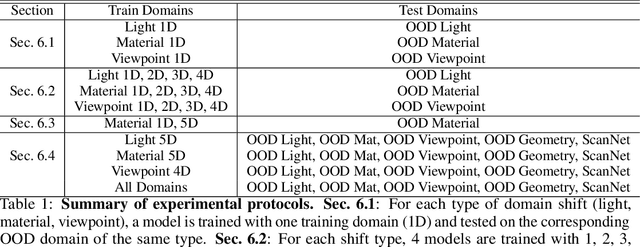
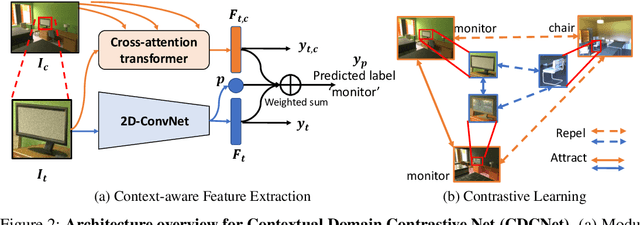
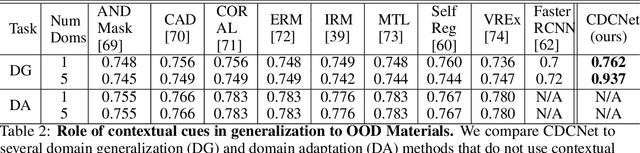
While several methodologies have been proposed for the daunting task of domain generalization, understanding what makes this task challenging has received little attention. Here we present SemanticDG (Semantic Domain Generalization): a benchmark with 15 photo-realistic domains with the same geometry, scene layout and camera parameters as the popular 3D ScanNet dataset, but with controlled domain shifts in lighting, materials, and viewpoints. Using this benchmark, we investigate the impact of each of these semantic shifts on generalization independently. Visual recognition models easily generalize to novel lighting, but struggle with distribution shifts in materials and viewpoints. Inspired by human vision, we hypothesize that scene context can serve as a bridge to help models generalize across material and viewpoint domain shifts and propose a context-aware vision transformer along with a contrastive loss over material and viewpoint changes to address these domain shifts. Our approach (dubbed as CDCNet) outperforms existing domain generalization methods by over an 18% margin. As a critical benchmark, we also conduct psychophysics experiments and find that humans generalize equally well across lighting, materials and viewpoints. The benchmark and computational model introduced here help understand the challenges associated with generalization across domains and provide initial steps towards extrapolation to semantic distribution shifts. We include all data and source code in the supplement.
Learning sRGB-to-Raw-RGB De-rendering with Content-Aware Metadata
Jun 03, 2022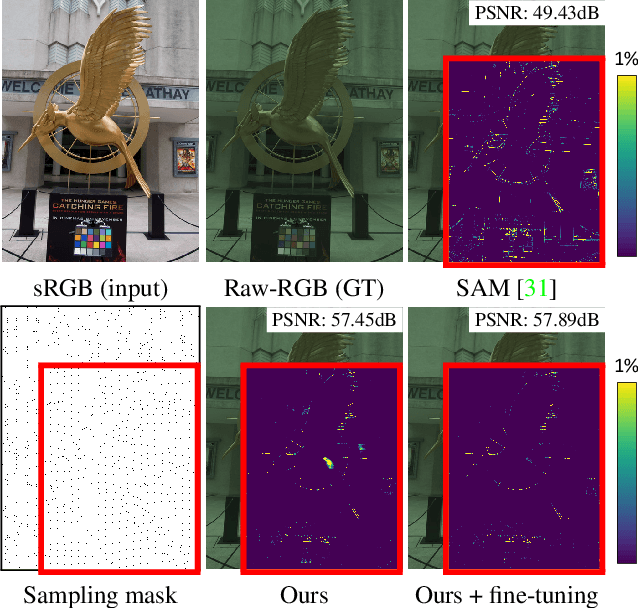

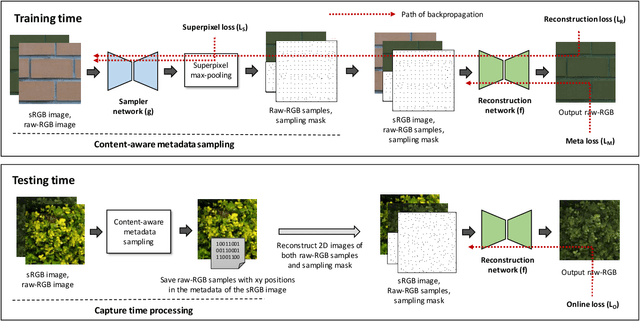
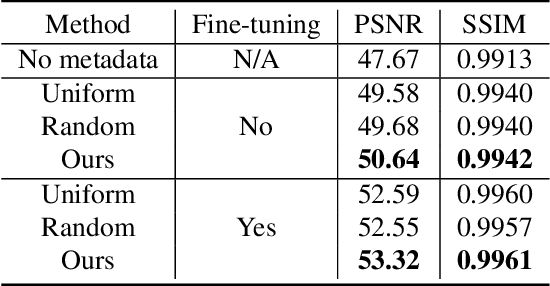
Most camera images are rendered and saved in the standard RGB (sRGB) format by the camera's hardware. Due to the in-camera photo-finishing routines, nonlinear sRGB images are undesirable for computer vision tasks that assume a direct relationship between pixel values and scene radiance. For such applications, linear raw-RGB sensor images are preferred. Saving images in their raw-RGB format is still uncommon due to the large storage requirement and lack of support by many imaging applications. Several "raw reconstruction" methods have been proposed that utilize specialized metadata sampled from the raw-RGB image at capture time and embedded in the sRGB image. This metadata is used to parameterize a mapping function to de-render the sRGB image back to its original raw-RGB format when needed. Existing raw reconstruction methods rely on simple sampling strategies and global mapping to perform the de-rendering. This paper shows how to improve the de-rendering results by jointly learning sampling and reconstruction. Our experiments show that our learned sampling can adapt to the image content to produce better raw reconstructions than existing methods. We also describe an online fine-tuning strategy for the reconstruction network to improve results further.
LatentKeypointGAN: Controlling Images via Latent Keypoints -- Extended Abstract
May 06, 2022
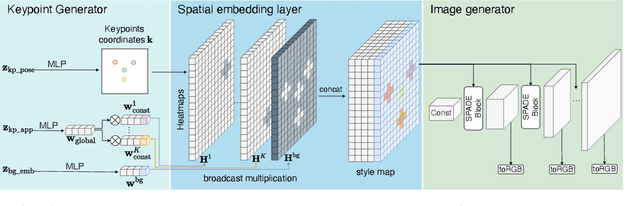
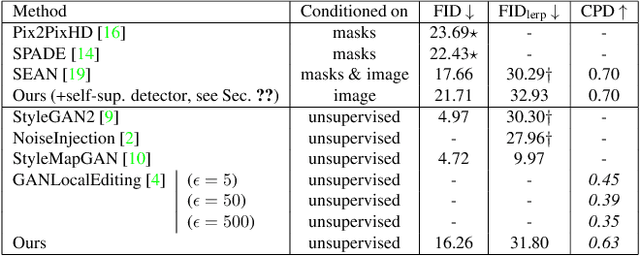
Generative adversarial networks (GANs) can now generate photo-realistic images. However, how to best control the image content remains an open challenge. We introduce LatentKeypointGAN, a two-stage GAN internally conditioned on a set of keypoints and associated appearance embeddings providing control of the position and style of the generated objects and their respective parts. A major difficulty that we address is disentangling the image into spatial and appearance factors with little domain knowledge and supervision signals. We demonstrate in a user study and quantitative experiments that LatentKeypointGAN provides an interpretable latent space that can be used to re-arrange the generated images by re-positioning and exchanging keypoint embeddings, such as generating portraits by combining the eyes, and mouth from different images. Notably, our method does not require labels as it is self-supervised and thereby applies to diverse application domains, such as editing portraits, indoor rooms, and full-body human poses.
Egocentric Human-Object Interaction Detection Exploiting Synthetic Data
Apr 14, 2022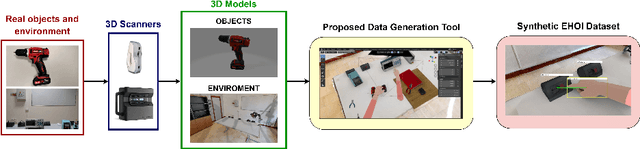



We consider the problem of detecting Egocentric HumanObject Interactions (EHOIs) in industrial contexts. Since collecting and labeling large amounts of real images is challenging, we propose a pipeline and a tool to generate photo-realistic synthetic First Person Vision (FPV) images automatically labeled for EHOI detection in a specific industrial scenario. To tackle the problem of EHOI detection, we propose a method that detects the hands, the objects in the scene, and determines which objects are currently involved in an interaction. We compare the performance of our method with a set of state-of-the-art baselines. Results show that using a synthetic dataset improves the performance of an EHOI detection system, especially when few real data are available. To encourage research on this topic, we publicly release the proposed dataset at the following url: https://iplab.dmi.unict.it/EHOI_SYNTH/.