 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Object Detection in Indian Food Platters using Transfer Learning with YOLOv4
May 10, 2022

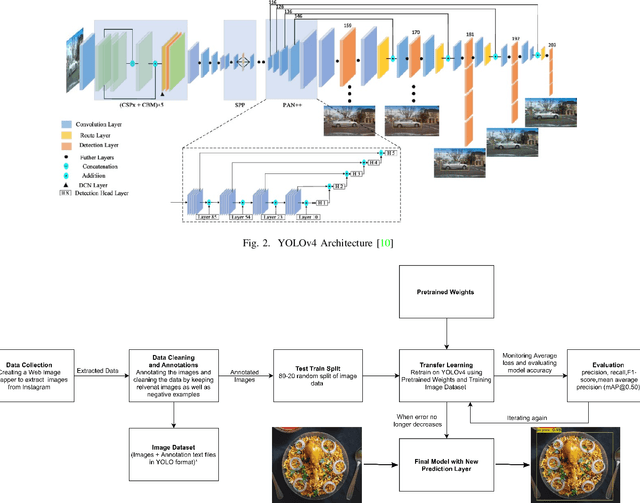

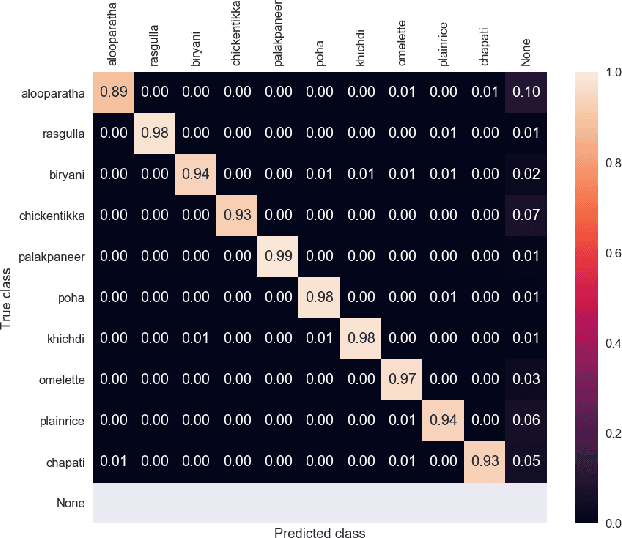
Object detection is a well-known problem in computer vision. Despite this, its usage and pervasiveness in the traditional Indian food dishes has been limited. Particularly, recognizing Indian food dishes present in a single photo is challenging due to three reasons: 1. Lack of annotated Indian food datasets 2. Non-distinct boundaries between the dishes 3. High intra-class variation. We solve these issues by providing a comprehensively labelled Indian food dataset- IndianFood10, which contains 10 food classes that appear frequently in a staple Indian meal and using transfer learning with YOLOv4 object detector model. Our model is able to achieve an overall mAP score of 91.8% and f1-score of 0.90 for our 10 class dataset. We also provide an extension of our 10 class dataset- IndianFood20, which contains 10 more traditional Indian food classes.
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
May 25, 2017
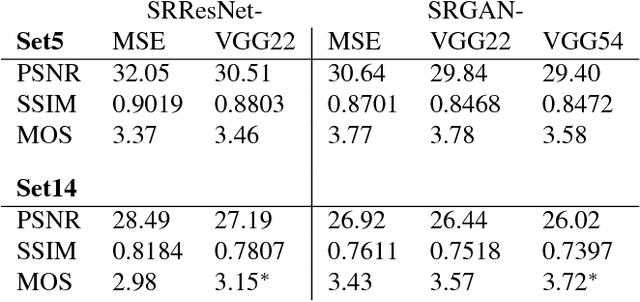

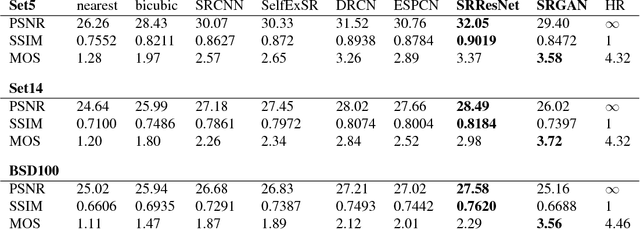
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.
Structured3D: A Large Photo-realistic Dataset for Structured 3D Modeling
Aug 01, 2019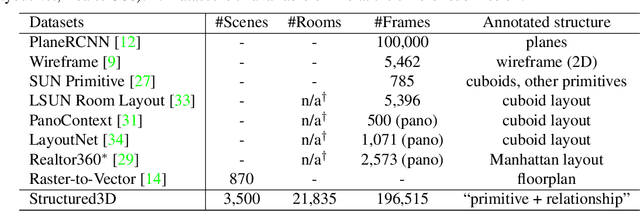

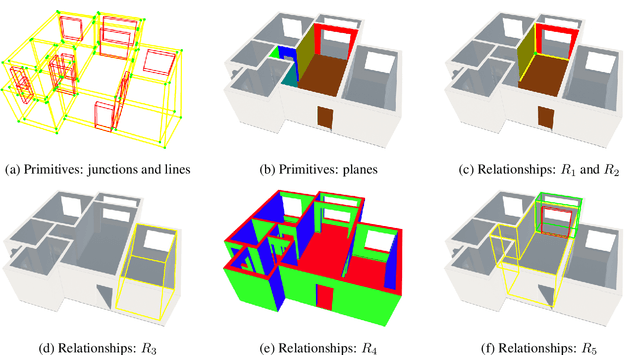
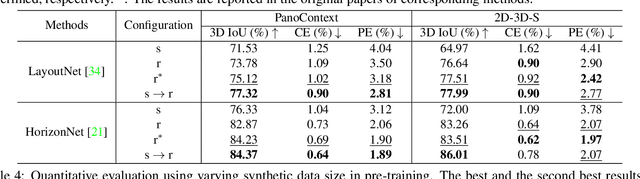
Recently, there has been growing interest in developing learning-based methods to detect and utilize salient semi-global or global structures, such as junctions, lines, planes, cuboids, smooth surfaces, and all types of symmetries, for 3D scene modeling and understanding. However, the ground truth annotations are often obtained via human labor, which is particularly challenging and inefficient for such tasks due to the large number of 3D structure instances (e.g., line segments) and other factors such as viewpoints and occlusions. In this paper, we present a new synthetic dataset, Structured3D, with the aim to providing large-scale photo-realistic images with rich 3D structure annotations for a wide spectrum of structured 3D modeling tasks. We take advantage of the availability of millions of professional interior designs and automatically extract 3D structures from them. We generate high-quality images with an industry-leading rendering engine. We use our synthetic dataset in combination with real images to train deep neural networks for room layout estimation and demonstrate improved performance on benchmark datasets.
Texture Generation Using Graph Generative Adversarial Network And Differentiable Rendering
Jun 17, 2022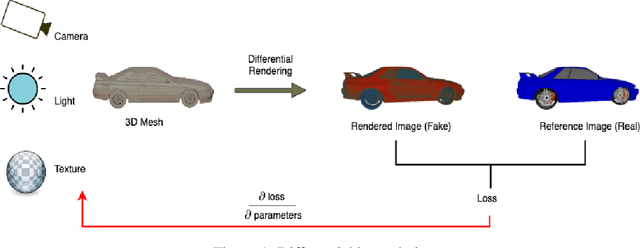
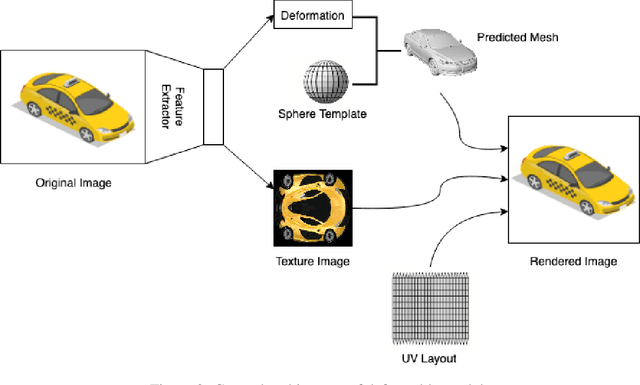
Novel texture synthesis for existing 3D mesh models is an important step towards photo realistic asset generation for existing simulators. But existing methods inherently work in the 2D image space which is the projection of the 3D space from a given camera perspective. These methods take camera angle, 3D model information, lighting information and generate photorealistic 2D image. To generate a photorealistic image from another perspective or lighting, we need to make a computationally expensive forward pass each time we change the parameters. Also, it is hard to generate such images for a simulator that can satisfy the temporal constraints the sequences of images should be similar but only need to change the viewpoint of lighting as desired. The solution can not be directly integrated with existing tools like Blender and Unreal Engine. Manual solution is expensive and time consuming. We thus present a new system called a graph generative adversarial network (GGAN) that can generate textures which can be directly integrated into a given 3D mesh models with tools like Blender and Unreal Engine and can be simulated from any perspective and lighting condition easily.
Roomsemble: Progressive web application for intuitive property search
Feb 15, 2022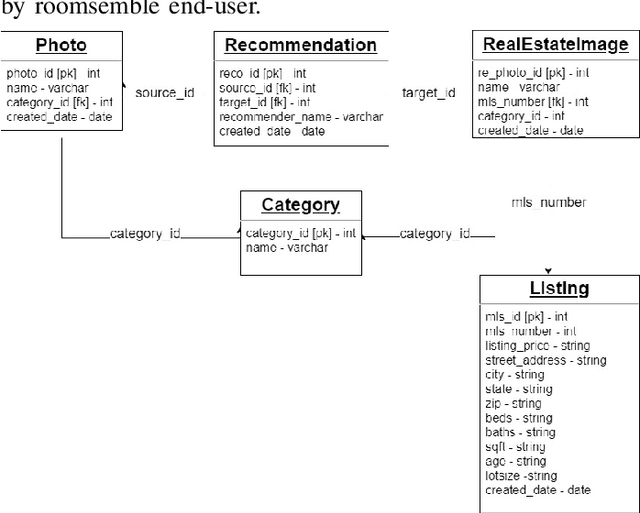

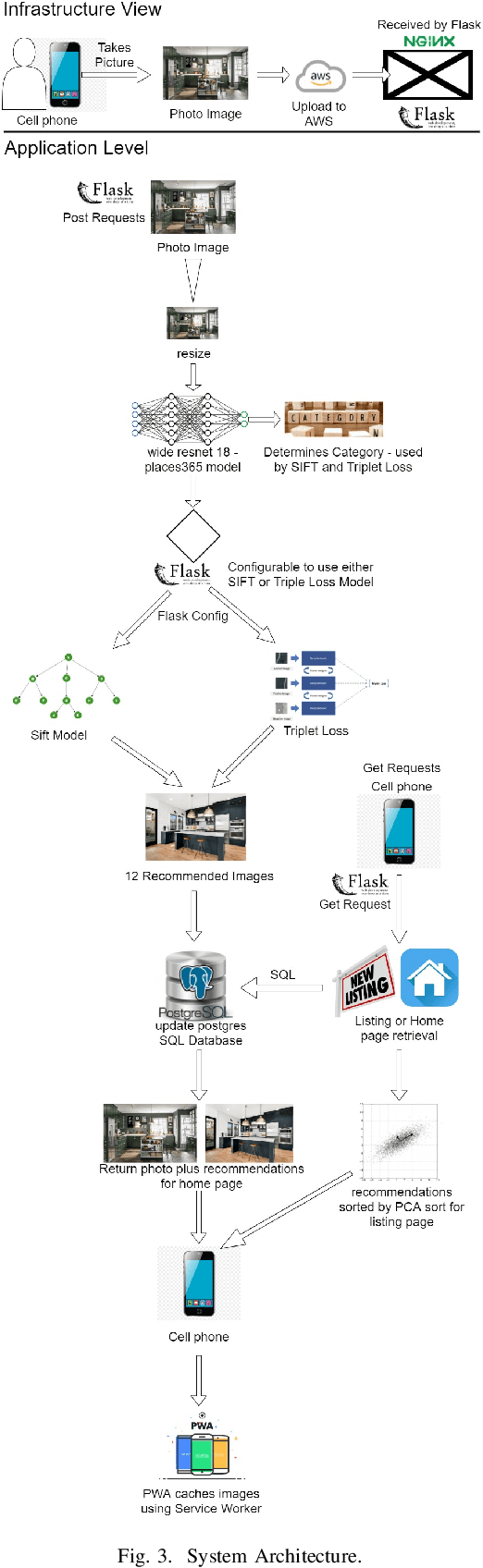
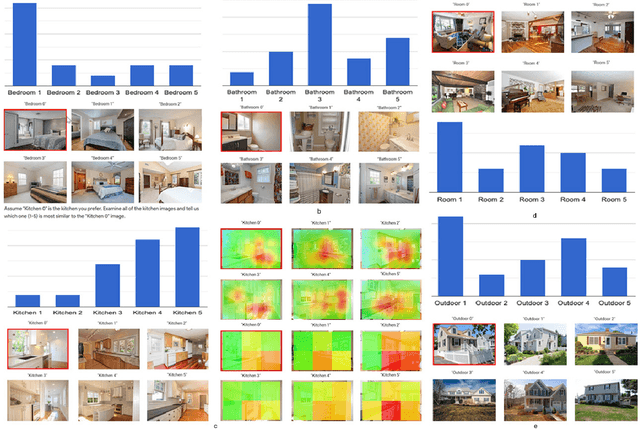
A successful real estate search process involves locating a property that meets a user's search criteria subject to an allocated budget and time constraints. Many studies have investigated modeling housing prices over time. However, little is known about how a user's tastes influence their real estate search and purchase decisions. It is unknown what house a user would choose taking into account an individual's personal tastes, behaviors, and constraints, and, therefore, creating an algorithm that finds the perfect match. In this paper, we investigate the first step in understanding a user's tastes by building a system to capture personal preferences. We concentrated our research on real estate photos, being inspired by house aesthetics, which often motivates prospective buyers into considering a property as a candidate for purchase. We designed a system that takes a user-provided photo representing that person's personal taste and recommends properties similar to the photo available on the market. The user can additionally filter the recommendations by budget and location when conducting a property search. The paper describes the application's overall layout including frontend design and backend processes for locating a desired property. The proposed model, which serves as the application's core, was tested with 25 users, and the study's findings, as well as some key conclusions, are detailed in this paper.
LatentKeypointGAN: Controlling Images via Latent Keypoints -- Extended Abstract
May 17, 2022
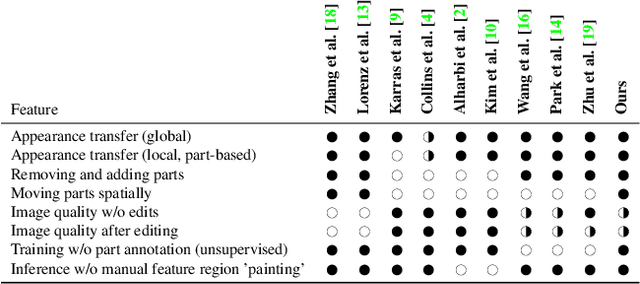
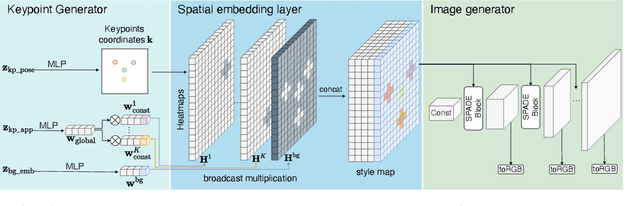
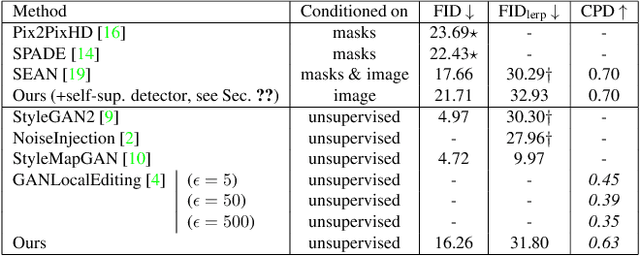
Generative adversarial networks (GANs) can now generate photo-realistic images. However, how to best control the image content remains an open challenge. We introduce LatentKeypointGAN, a two-stage GAN internally conditioned on a set of keypoints and associated appearance embeddings providing control of the position and style of the generated objects and their respective parts. A major difficulty that we address is disentangling the image into spatial and appearance factors with little domain knowledge and supervision signals. We demonstrate in a user study and quantitative experiments that LatentKeypointGAN provides an interpretable latent space that can be used to re-arrange the generated images by re-positioning and exchanging keypoint embeddings, such as generating portraits by combining the eyes, and mouth from different images. Notably, our method does not require labels as it is self-supervised and thereby applies to diverse application domains, such as editing portraits, indoor rooms, and full-body human poses.
Photo-realistic Monocular Gaze Redirection using Generative Adversarial Networks
Mar 29, 2019
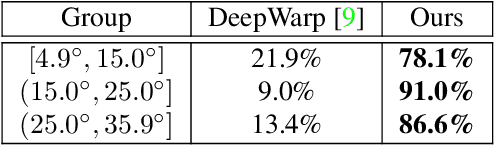
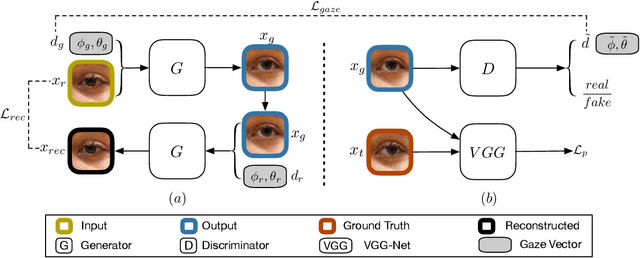
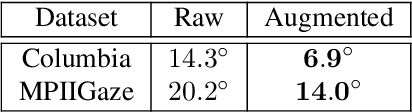
Gaze redirection is the task of changing the gaze to a desired direction for a given monocular eye patch image. Many applications such as videoconferencing, films and games, and generation of training data for gaze estimation require redirecting the gaze, without distorting the appearance of the area surrounding the eye and while producing photo-realistic images. Existing methods lack the ability to generate perceptually plausible images. In this work, we present a novel method to alleviate this problem by leveraging generative adversarial training to synthesize an eye image conditioned on a target gaze direction. Our method ensures perceptual similarity and consistency of synthesized images to the real images. Furthermore, a gaze estimation loss is used to control the gaze direction accurately. To attain high-quality images, we incorporate perceptual and cycle consistency losses into our architecture. In extensive evaluations we show that the proposed method outperforms state-of-the-art approaches in terms of both image quality and redirection precision. Finally, we show that generated images can bring significant improvement for the gaze estimation task if used to augment real training data.
Dynamic Selection of Perception Models for Robotic Control
Jul 13, 2022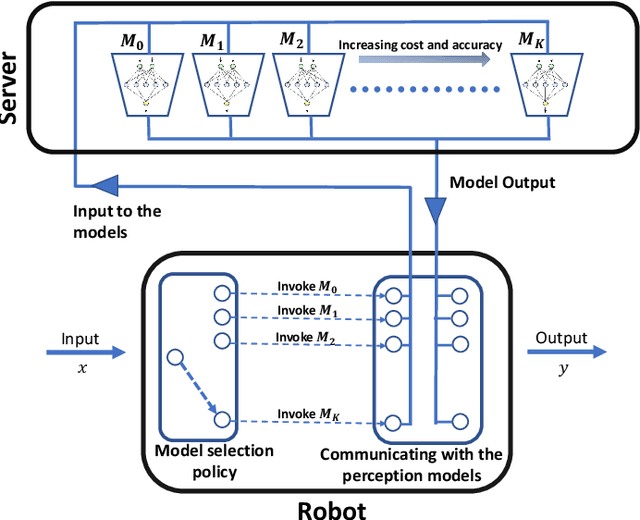

Robotic perception models, such as Deep Neural Networks (DNNs), are becoming more computationally intensive and there are several models being trained with accuracy and latency trade-offs. However, modern latency accuracy trade-offs largely report mean accuracy for single-step vision tasks, but there is little work showing which model to invoke for multi-step control tasks in robotics. The key challenge in a multi-step decision making is to make use of the right models at right times to accomplish the given task. That is, the accomplishment of the task with a minimum control cost and minimum perception time is a desideratum; this is known as the model selection problem. In this work, we precisely address this problem of invoking the correct sequence of perception models for multi-step control. In other words, we provide a provably optimal solution to the model selection problem by casting it as a multi-objective optimization problem balancing the control cost and perception time. The key insight obtained from our solution is how the variance of the perception models matters (not just the mean accuracy) for multi-step decision making, and to show how to use diverse perception models as a primitive for energy-efficient robotics. Further, we demonstrate our approach on a photo-realistic drone landing simulation using visual navigation in AirSim. Using our proposed policy, we achieved 38.04% lower control cost with 79.1% less perception time than other competing benchmarks.
Person Recognition in Personal Photo Collections
Oct 20, 2018



People nowadays share large parts of their personal lives through social media. Being able to automatically recognise people in personal photos may greatly enhance user convenience by easing photo album organisation. For human identification task, however, traditional focus of computer vision has been face recognition and pedestrian re-identification. Person recognition in social media photos sets new challenges for computer vision, including non-cooperative subjects (e.g. backward viewpoints, unusual poses) and great changes in appearance. To tackle this problem, we build a simple person recognition framework that leverages convnet features from multiple image regions (head, body, etc.). We propose new recognition scenarios that focus on the time and appearance gap between training and testing samples. We present an in-depth analysis of the importance of different features according to time and viewpoint generalisability. In the process, we verify that our simple approach achieves the state of the art result on the PIPA benchmark, arguably the largest social media based benchmark for person recognition to date with diverse poses, viewpoints, social groups, and events. Compared the conference version of the paper, this paper additionally presents (1) analysis of a face recogniser (DeepID2+), (2) new method naeil2 that combines the conference version method naeil and DeepID2+ to achieve state of the art results even compared to post-conference works, (3) discussion of related work since the conference version, (4) additional analysis including the head viewpoint-wise breakdown of performance, and (5) results on the open-world setup.
Improving Image-recognition Edge Caches with a Generative Adversarial Network
Feb 11, 2022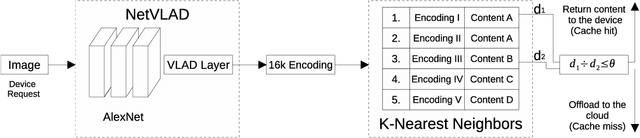
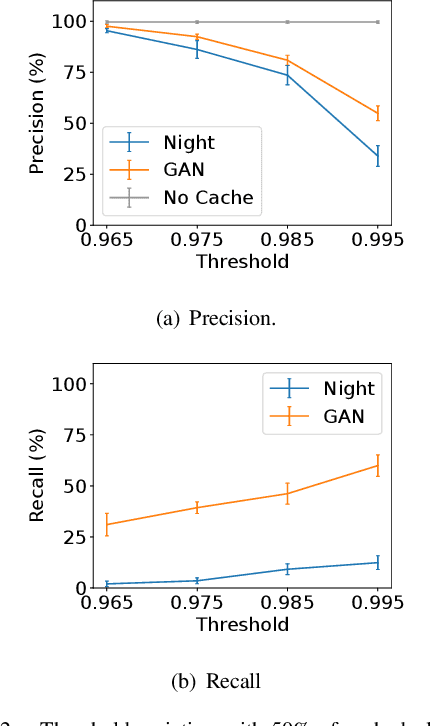
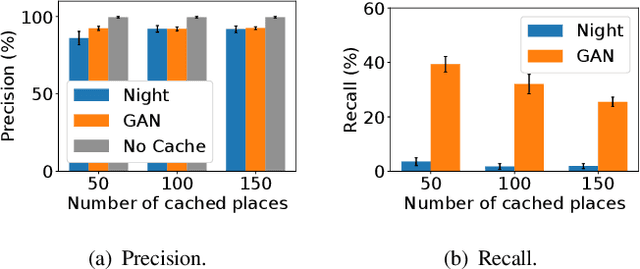
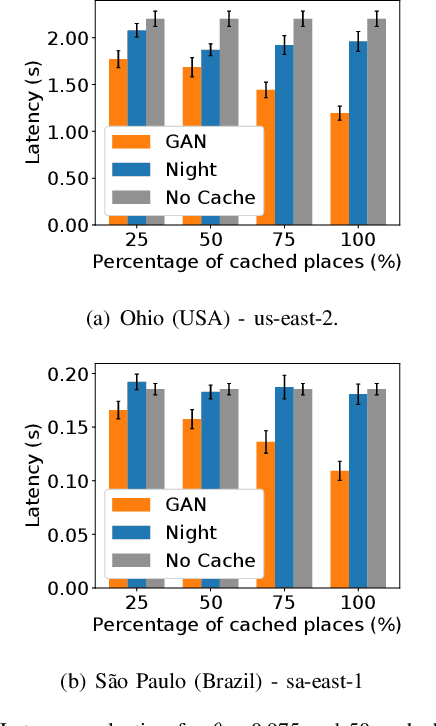
Image recognition is an essential task in several mobile applications. For instance, a smartphone can process a landmark photo to gather more information about its location. If the device does not have enough computational resources available, it offloads the processing task to a cloud infrastructure. Although this approach solves resource shortages, it introduces a communication delay. Image-recognition caches on the Internet's edge can mitigate this problem. These caches run on servers close to mobile devices and stores information about previously recognized images. If the server receives a request with a photo stored in its cache, it replies to the device, avoiding cloud offloading. The main challenge for this cache is to verify if the received image matches a stored one. Furthermore, for outdoor photos, it is difficult to compare them if one was taken in the daytime and the other at nighttime. In that case, the cache might wrongly infer that they refer to different places, offloading the processing to the cloud. This work shows that a well-known generative adversarial network, called ToDayGAN, can solve this problem by generating daytime images using nighttime ones. We can thus use this translation to populate a cache with synthetic photos that can help image matching. We show that our solution reduces cloud offloading and, therefore, the application's latency.