 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Controllable Image Enhancement
Jun 16, 2022
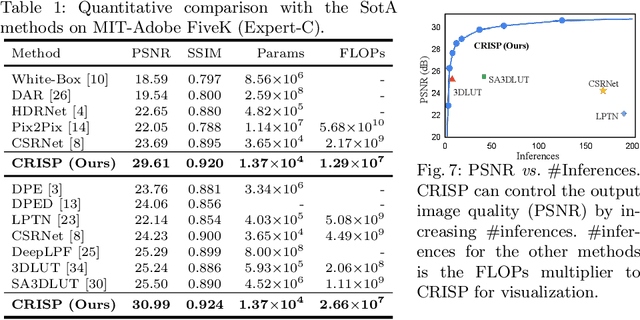
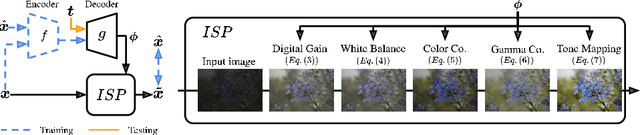

Editing flat-looking images into stunning photographs requires skill and time. Automated image enhancement algorithms have attracted increased interest by generating high-quality images without user interaction. However, the quality assessment of a photograph is subjective. Even in tone and color adjustments, a single photograph of auto-enhancement is challenging to fit user preferences which are subtle and even changeable. To address this problem, we present a semiautomatic image enhancement algorithm that can generate high-quality images with multiple styles by controlling a few parameters. We first disentangle photo retouching skills from high-quality images and build an efficient enhancement system for each skill. Specifically, an encoder-decoder framework encodes the retouching skills into latent codes and decodes them into the parameters of image signal processing (ISP) functions. The ISP functions are computationally efficient and consist of only 19 parameters. Despite our approach requiring multiple inferences to obtain the desired result, experimental results present that the proposed method achieves state-of-the-art performances on the benchmark dataset for image quality and model efficiency.
Recognition of Multiple Food Items in a Single Photo for Use in a Buffet-Style Restaurant
Mar 03, 2019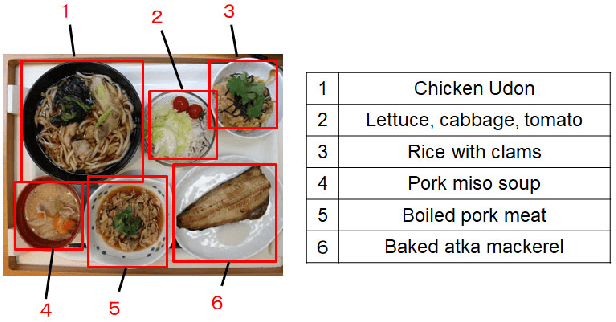
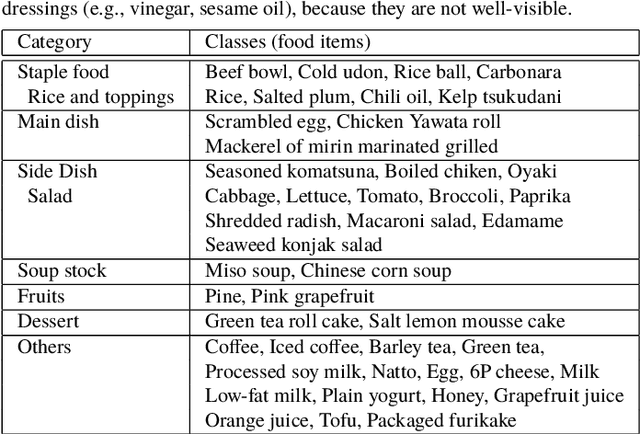
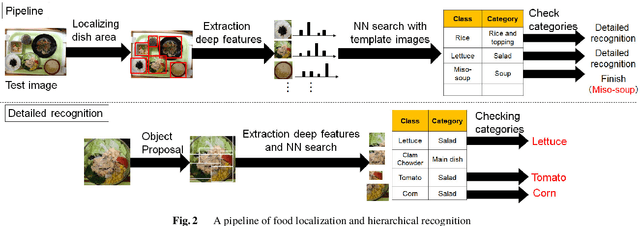
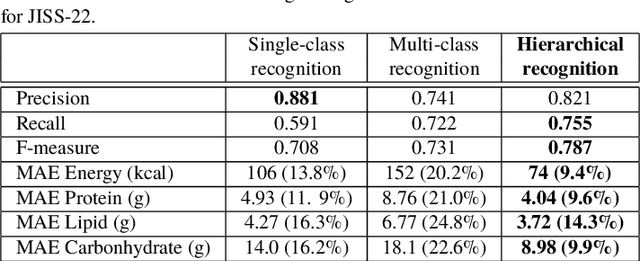
We investigate image recognition of multiple food items in a single photo, focusing on a buffet restaurant application, where menu changes at every meal, and only a few images per class are available. After detecting food areas, we perform hierarchical recognition. We evaluate our results, comparing to two baseline methods.
* 5 pages, 7 figures
Neural 3D Reconstruction in the Wild
May 25, 2022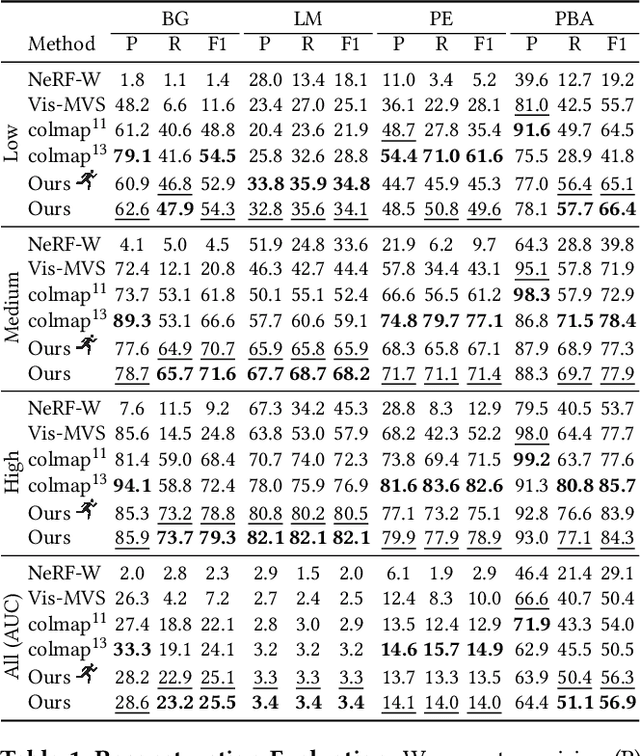
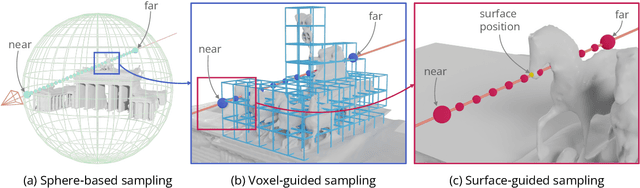
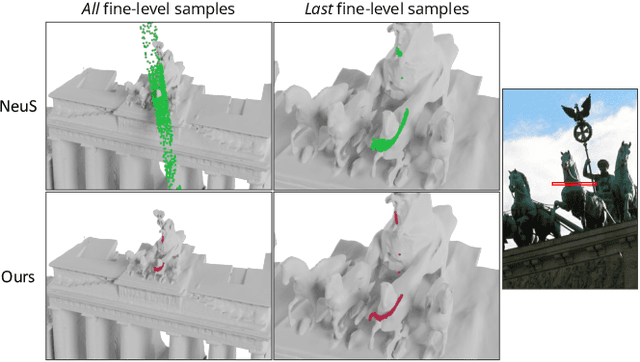

We are witnessing an explosion of neural implicit representations in computer vision and graphics. Their applicability has recently expanded beyond tasks such as shape generation and image-based rendering to the fundamental problem of image-based 3D reconstruction. However, existing methods typically assume constrained 3D environments with constant illumination captured by a small set of roughly uniformly distributed cameras. We introduce a new method that enables efficient and accurate surface reconstruction from Internet photo collections in the presence of varying illumination. To achieve this, we propose a hybrid voxel- and surface-guided sampling technique that allows for more efficient ray sampling around surfaces and leads to significant improvements in reconstruction quality. Further, we present a new benchmark and protocol for evaluating reconstruction performance on such in-the-wild scenes. We perform extensive experiments, demonstrating that our approach surpasses both classical and neural reconstruction methods on a wide variety of metrics.
Optimizing Video Prediction via Video Frame Interpolation
Jun 27, 2022
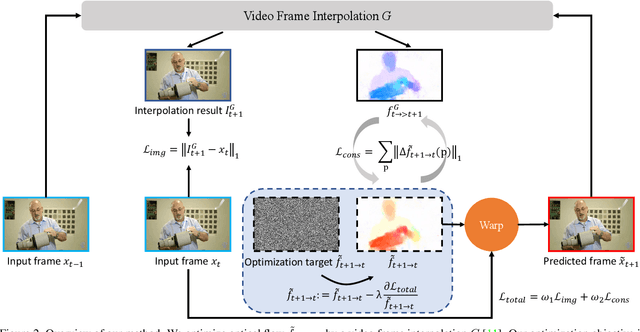
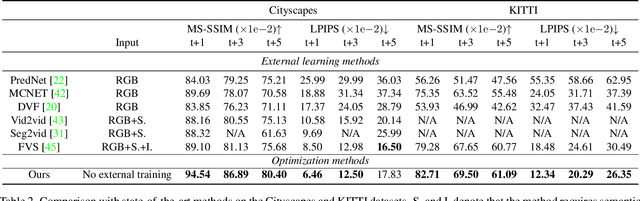

Video prediction is an extrapolation task that predicts future frames given past frames, and video frame interpolation is an interpolation task that estimates intermediate frames between two frames. We have witnessed the tremendous advancement of video frame interpolation, but the general video prediction in the wild is still an open question. Inspired by the photo-realistic results of video frame interpolation, we present a new optimization framework for video prediction via video frame interpolation, in which we solve an extrapolation problem based on an interpolation model. Our video prediction framework is based on optimization with a pretrained differentiable video frame interpolation module without the need for a training dataset, and thus there is no domain gap issue between training and test data. Also, our approach does not need any additional information such as semantic or instance maps, which makes our framework applicable to any video. Extensive experiments on the Cityscapes, KITTI, DAVIS, Middlebury, and Vimeo90K datasets show that our video prediction results are robust in general scenarios, and our approach outperforms other video prediction methods that require a large amount of training data or extra semantic information.
Flow Synthesis Based Visual Servoing Frameworks for Monocular Obstacle Avoidance Amidst High-Rises
Jul 07, 2022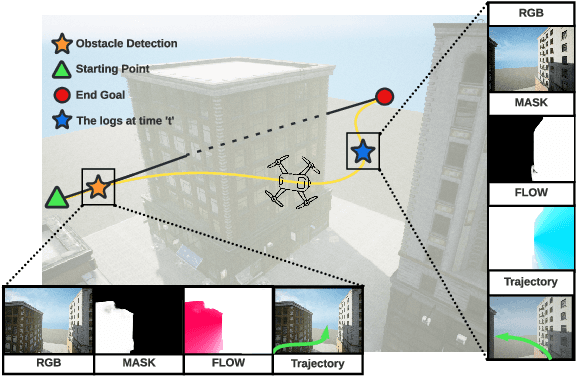
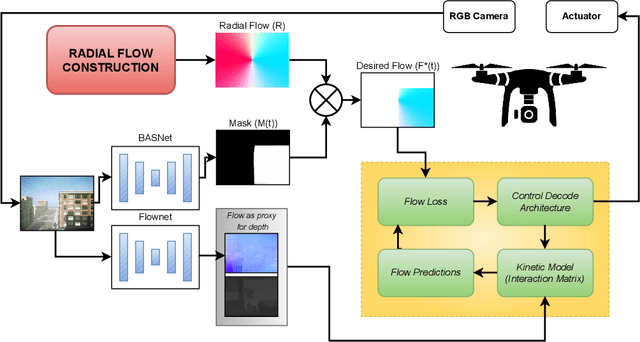

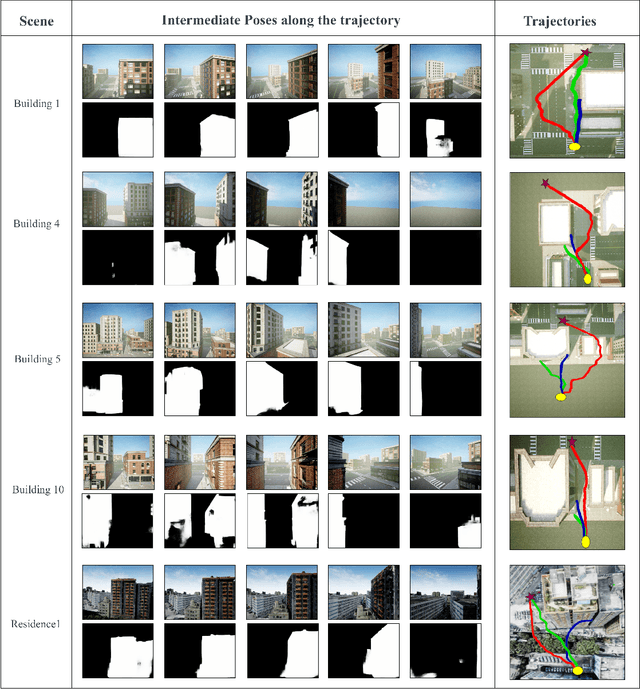
We propose a novel flow synthesis based visual servoing framework enabling long-range obstacle avoidance for Micro Air Vehicles (MAV) flying amongst tall skyscrapers. Recent deep learning based frameworks use optical flow to do high-precision visual servoing. In this paper, we explore the question: can we design a surrogate flow for these high-precision visual-servoing methods, which leads to obstacle avoidance? We revisit the concept of saliency for identifying high-rise structures in/close to the line of attack amongst other competing skyscrapers and buildings as a collision obstacle. A synthesised flow is used to displace the salient object segmentation mask. This flow is so computed that the visual servoing controller maneuvers the MAV safely around the obstacle. In this approach, we use a multi-step Cross-Entropy Method (CEM) based servo control to achieve flow convergence, resulting in obstacle avoidance. We use this novel pipeline to successfully and persistently maneuver high-rises and reach the goal in simulated and photo-realistic real-world scenes. We conduct extensive experimentation and compare our approach with optical flow and short-range depth-based obstacle avoidance methods to demonstrate the proposed framework's merit. Additional Visualisation can be found at https://sites.google.com/view/monocular-obstacle/home
Content Authentication for Neural Imaging Pipelines: End-to-end Optimization of Photo Provenance in Complex Distribution Channels
Dec 04, 2018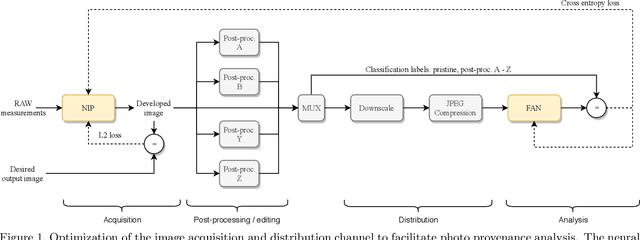
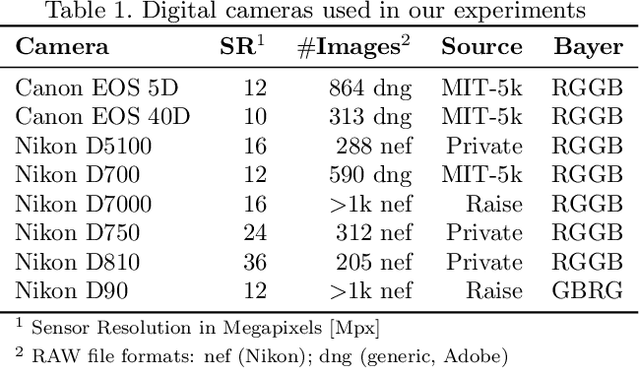

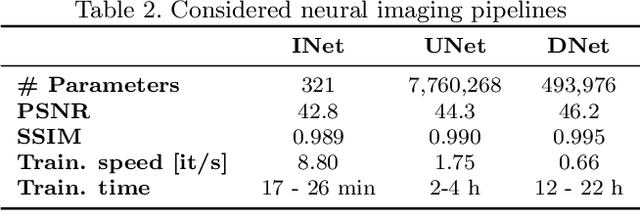
Forensic analysis of digital photo provenance relies on intrinsic traces left in the photograph at the time of its acquisition. Such analysis becomes unreliable after heavy post-processing, such as down-sampling and re-compression applied upon distribution in the Web. This paper explores end-to-end optimization of the entire image acquisition and distribution workflow to facilitate reliable forensic analysis at the end of the distribution channel. We demonstrate that neural imaging pipelines can be trained to replace the internals of digital cameras, and jointly optimized for high-fidelity photo development and reliable provenance analysis. In our experiments, the proposed approach increased image manipulation detection accuracy from 55% to nearly 98%. The findings encourage further research towards building more reliable imaging pipelines with explicit provenance-guaranteeing properties.
RigNeRF: Fully Controllable Neural 3D Portraits
Jun 13, 2022
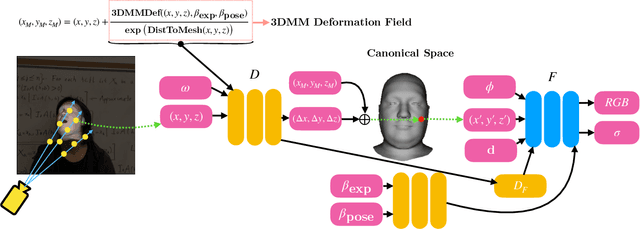

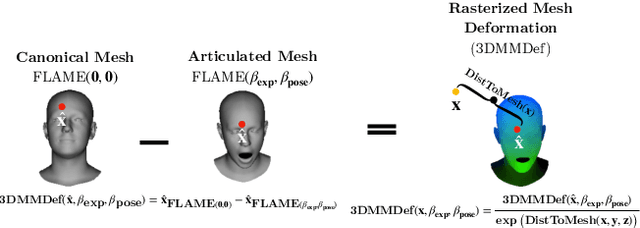
Volumetric neural rendering methods, such as neural radiance fields (NeRFs), have enabled photo-realistic novel view synthesis. However, in their standard form, NeRFs do not support the editing of objects, such as a human head, within a scene. In this work, we propose RigNeRF, a system that goes beyond just novel view synthesis and enables full control of head pose and facial expressions learned from a single portrait video. We model changes in head pose and facial expressions using a deformation field that is guided by a 3D morphable face model (3DMM). The 3DMM effectively acts as a prior for RigNeRF that learns to predict only residuals to the 3DMM deformations and allows us to render novel (rigid) poses and (non-rigid) expressions that were not present in the input sequence. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls. The project page can be found here: http://shahrukhathar.github.io/2022/06/06/RigNeRF.html
ARMANI: Part-level Garment-Text Alignment for Unified Cross-Modal Fashion Design
Aug 11, 2022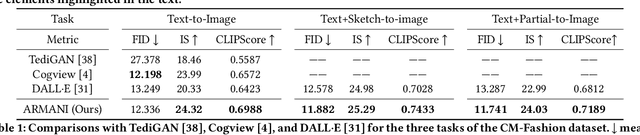

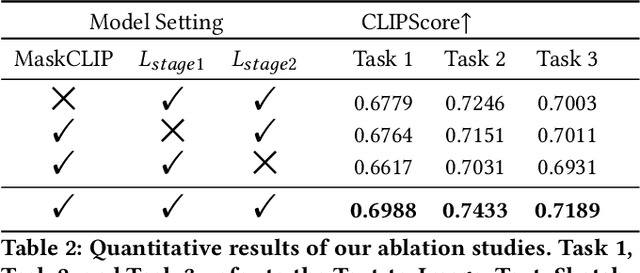
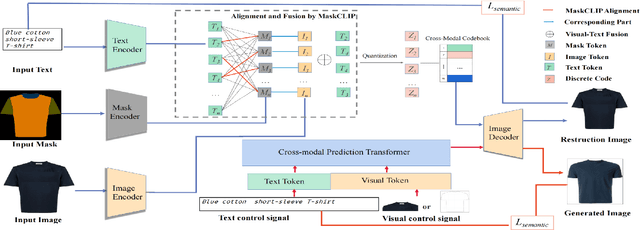
Cross-modal fashion image synthesis has emerged as one of the most promising directions in the generation domain due to the vast untapped potential of incorporating multiple modalities and the wide range of fashion image applications. To facilitate accurate generation, cross-modal synthesis methods typically rely on Contrastive Language-Image Pre-training (CLIP) to align textual and garment information. In this work, we argue that simply aligning texture and garment information is not sufficient to capture the semantics of the visual information and therefore propose MaskCLIP. MaskCLIP decomposes the garments into semantic parts, ensuring fine-grained and semantically accurate alignment between the visual and text information. Building on MaskCLIP, we propose ARMANI, a unified cross-modal fashion designer with part-level garment-text alignment. ARMANI discretizes an image into uniform tokens based on a learned cross-modal codebook in its first stage and uses a Transformer to model the distribution of image tokens for a real image given the tokens of the control signals in its second stage. Contrary to prior approaches that also rely on two-stage paradigms, ARMANI introduces textual tokens into the codebook, making it possible for the model to utilize fine-grain semantic information to generate more realistic images. Further, by introducing a cross-modal Transformer, ARMANI is versatile and can accomplish image synthesis from various control signals, such as pure text, sketch images, and partial images. Extensive experiments conducted on our newly collected cross-modal fashion dataset demonstrate that ARMANI generates photo-realistic images in diverse synthesis tasks and outperforms existing state-of-the-art cross-modal image synthesis approaches.Our code is available at https://github.com/Harvey594/ARMANI.
A Novel Face-Anti Spoofing Neural Network Model For Face Recognition And Detection
May 14, 2022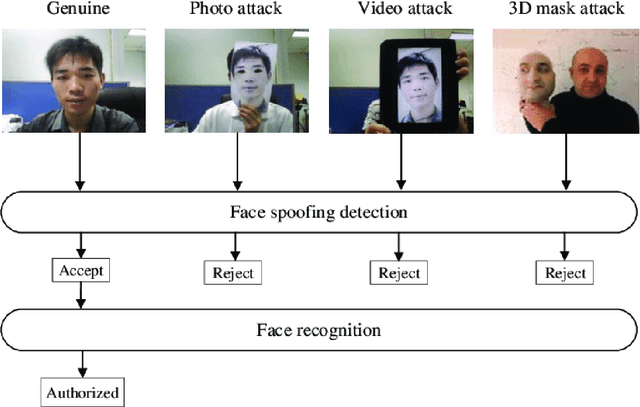
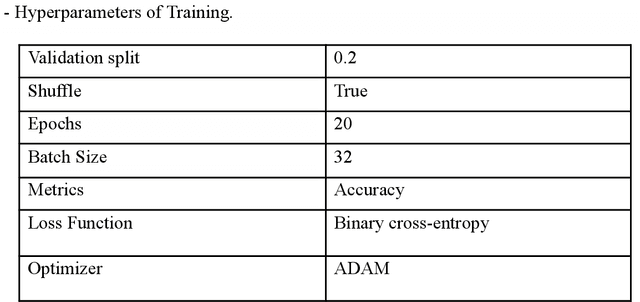


Face Recognition (FR) systems are being used in a variety of applications, including road crossings, banking, and mobile banking. The widespread use of FR systems has raised concerns about the safety of face biometrics against spoofing attacks, which use the use of a photo or video of a legitimate user's face to gain illegal access to the resources or activities. Despite the development of several FAS or liveness detection methods (which determine whether a face is live or spoofed at the time of acquisition), the problem remains unsolved due to the difficulty of identifying discrimination and operationally reasonably priced spoof characteristics but also approaches. Additionally, certain facial portions are frequently repeated or correlate to image clutter, resulting in poor performance overall. This research proposes a face-anti-spoofing neural network model that outperforms existing models and has an efficiency of 0.89 percent.
Google Scanned Objects: A High-Quality Dataset of 3D Scanned Household Items
Apr 25, 2022
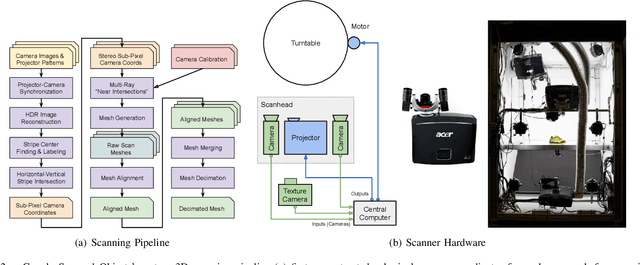

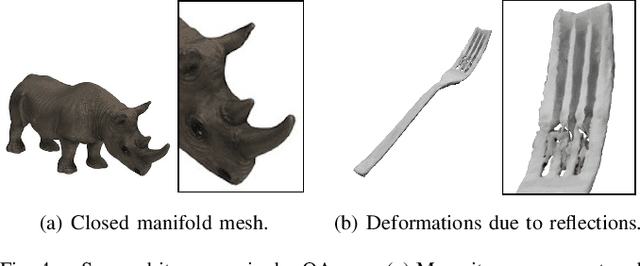
Interactive 3D simulations have enabled breakthroughs in robotics and computer vision, but simulating the broad diversity of environments needed for deep learning requires large corpora of photo-realistic 3D object models. To address this need, we present Google Scanned Objects, an open-source collection of over one thousand 3D-scanned household items released under a Creative Commons license; these models are preprocessed for use in Ignition Gazebo and the Bullet simulation platforms, but are easily adaptable to other simulators. We describe our object scanning and curation pipeline, then provide statistics about the contents of the dataset and its usage. We hope that the diversity, quality, and flexibility of Google Scanned Objects will lead to advances in interactive simulation, synthetic perception, and robotic learning.