 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
CCPL: Contrastive Coherence Preserving Loss for Versatile Style Transfer
Jul 18, 2022
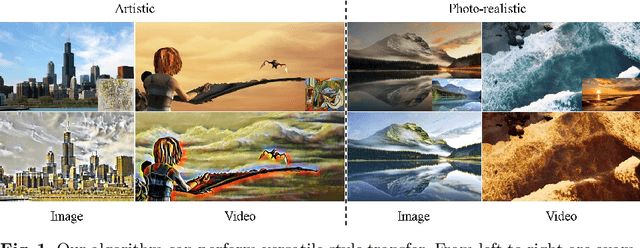
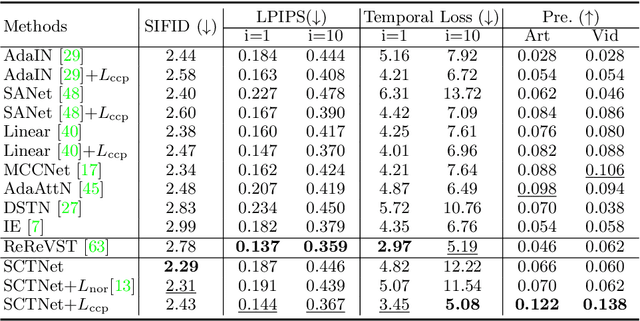
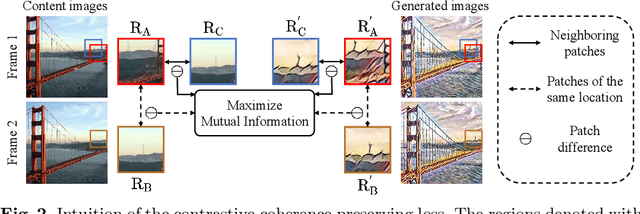

In this paper, we aim to devise a universally versatile style transfer method capable of performing artistic, photo-realistic, and video style transfer jointly, without seeing videos during training. Previous single-frame methods assume a strong constraint on the whole image to maintain temporal consistency, which could be violated in many cases. Instead, we make a mild and reasonable assumption that global inconsistency is dominated by local inconsistencies and devise a generic Contrastive Coherence Preserving Loss (CCPL) applied to local patches. CCPL can preserve the coherence of the content source during style transfer without degrading stylization. Moreover, it owns a neighbor-regulating mechanism, resulting in a vast reduction of local distortions and considerable visual quality improvement. Aside from its superior performance on versatile style transfer, it can be easily extended to other tasks, such as image-to-image translation. Besides, to better fuse content and style features, we propose Simple Covariance Transformation (SCT) to effectively align second-order statistics of the content feature with the style feature. Experiments demonstrate the effectiveness of the resulting model for versatile style transfer, when armed with CCPL.
Neural Radiance Transfer Fields for Relightable Novel-view Synthesis with Global Illumination
Jul 27, 2022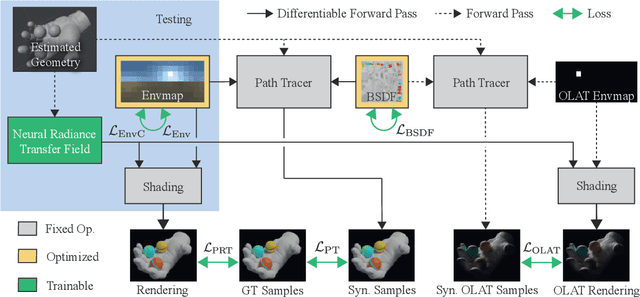
Given a set of images of a scene, the re-rendering of this scene from novel views and lighting conditions is an important and challenging problem in Computer Vision and Graphics. On the one hand, most existing works in Computer Vision usually impose many assumptions regarding the image formation process, e.g. direct illumination and predefined materials, to make scene parameter estimation tractable. On the other hand, mature Computer Graphics tools allow modeling of complex photo-realistic light transport given all the scene parameters. Combining these approaches, we propose a method for scene relighting under novel views by learning a neural precomputed radiance transfer function, which implicitly handles global illumination effects using novel environment maps. Our method can be solely supervised on a set of real images of the scene under a single unknown lighting condition. To disambiguate the task during training, we tightly integrate a differentiable path tracer in the training process and propose a combination of a synthesized OLAT and a real image loss. Results show that the recovered disentanglement of scene parameters improves significantly over the current state of the art and, thus, also our re-rendering results are more realistic and accurate.
Attribute-Centered Loss for Soft-Biometrics Guided Face Sketch-Photo Recognition
Apr 09, 2018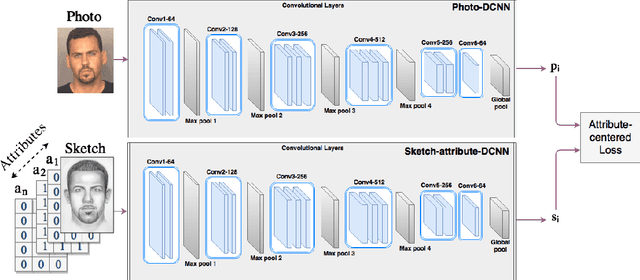

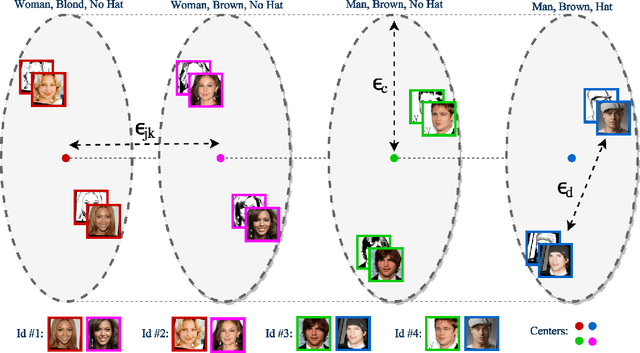

Face sketches are able to capture the spatial topology of a face while lacking some facial attributes such as race, skin, or hair color. Existing sketch-photo recognition approaches have mostly ignored the importance of facial attributes. In this paper, we propose a new loss function, called attribute-centered loss, to train a Deep Coupled Convolutional Neural Network (DCCNN) for the facial attribute guided sketch to photo matching. Specifically, an attribute-centered loss is proposed which learns several distinct centers, in a shared embedding space, for photos and sketches with different combinations of attributes. The DCCNN simultaneously is trained to map photos and pairs of testified attributes and corresponding forensic sketches around their associated centers, while preserving the spatial topology information. Importantly, the centers learn to keep a relative distance from each other, related to their number of contradictory attributes. Extensive experiments are performed on composite (E-PRIP) and semi-forensic (IIIT-D Semi-forensic) databases. The proposed method significantly outperforms the state-of-the-art.
USegScene: Unsupervised Learning of Depth, Optical Flow and Ego-Motion with Semantic Guidance and Coupled Networks
Jul 15, 2022
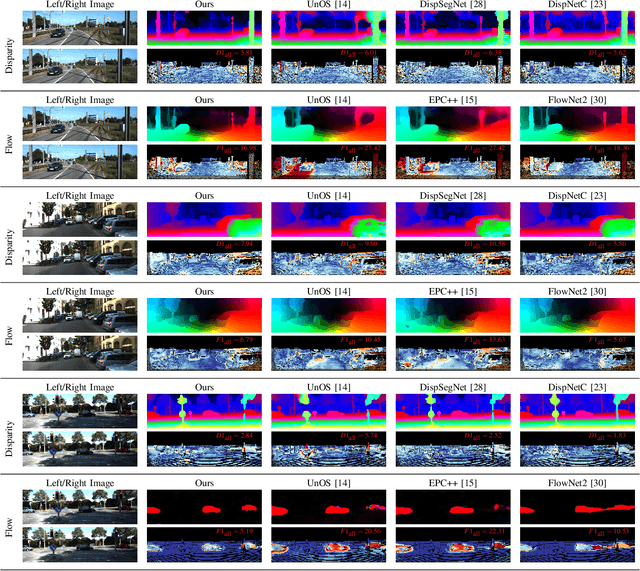
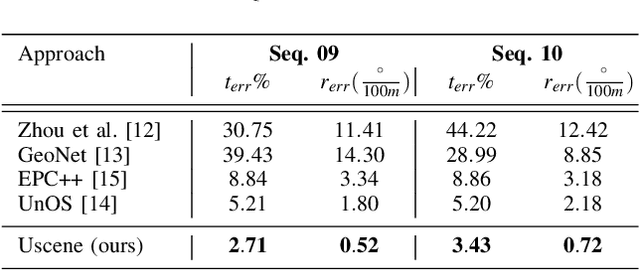
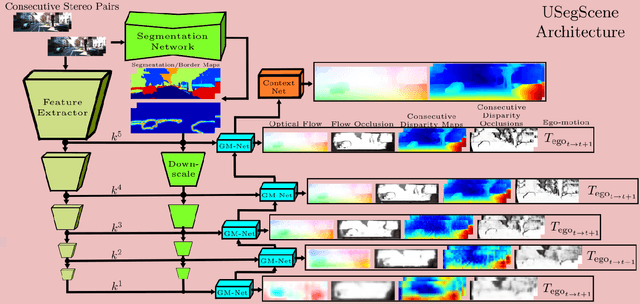
In this paper we propose USegScene, a framework for semantically guided unsupervised learning of depth, optical flow and ego-motion estimation for stereo camera images using convolutional neural networks. Our framework leverages semantic information for improved regularization of depth and optical flow maps, multimodal fusion and occlusion filling considering dynamic rigid object motions as independent SE(3) transformations. Furthermore, complementary to pure photo-metric matching, we propose matching of semantic features, pixel-wise classes and object instance borders between the consecutive images. In contrast to previous methods, we propose a network architecture that jointly predicts all outputs using shared encoders and allows passing information across the task-domains, e.g., the prediction of optical flow can benefit from the prediction of the depth. Furthermore, we explicitly learn the depth and optical flow occlusion maps inside the network, which are leveraged in order to improve the predictions in therespective regions. We present results on the popular KITTI dataset and show that our approach outperforms other methods by a large margin.
DRaCoN -- Differentiable Rasterization Conditioned Neural Radiance Fields for Articulated Avatars
Mar 29, 2022
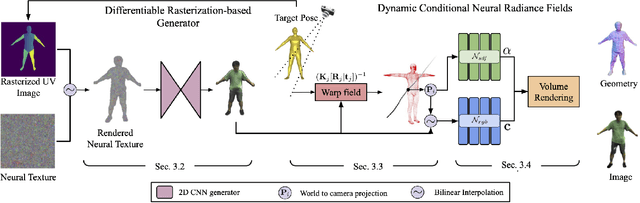
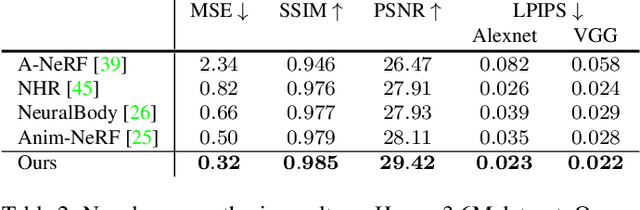
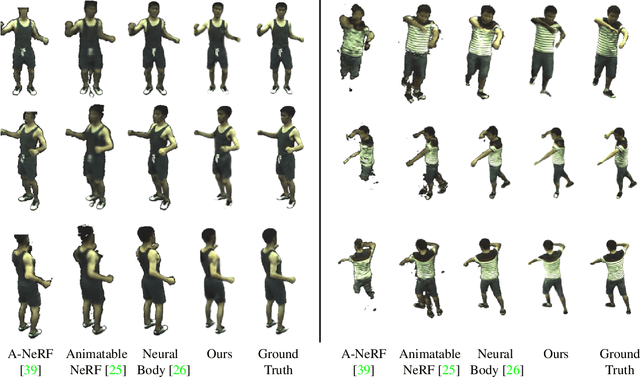
Acquisition and creation of digital human avatars is an important problem with applications to virtual telepresence, gaming, and human modeling. Most contemporary approaches for avatar generation can be viewed either as 3D-based methods, which use multi-view data to learn a 3D representation with appearance (such as a mesh, implicit surface, or volume), or 2D-based methods which learn photo-realistic renderings of avatars but lack accurate 3D representations. In this work, we present, DRaCoN, a framework for learning full-body volumetric avatars which exploits the advantages of both the 2D and 3D neural rendering techniques. It consists of a Differentiable Rasterization module, DiffRas, that synthesizes a low-resolution version of the target image along with additional latent features guided by a parametric body model. The output of DiffRas is then used as conditioning to our conditional neural 3D representation module (c-NeRF) which generates the final high-res image along with body geometry using volumetric rendering. While DiffRas helps in obtaining photo-realistic image quality, c-NeRF, which employs signed distance fields (SDF) for 3D representations, helps to obtain fine 3D geometric details. Experiments on the challenging ZJU-MoCap and Human3.6M datasets indicate that DRaCoN outperforms state-of-the-art methods both in terms of error metrics and visual quality.
Rethinking Super-Resolution as Text-Guided Details Generation
Jul 14, 2022

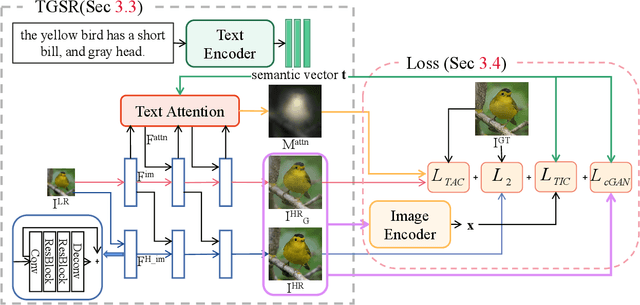
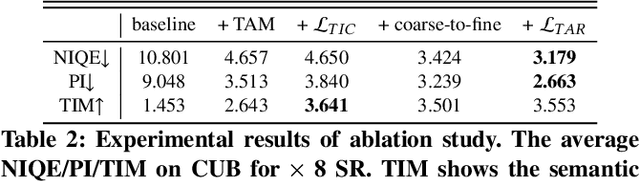
Deep neural networks have greatly promoted the performance of single image super-resolution (SISR). Conventional methods still resort to restoring the single high-resolution (HR) solution only based on the input of image modality. However, the image-level information is insufficient to predict adequate details and photo-realistic visual quality facing large upscaling factors (x8, x16). In this paper, we propose a new perspective that regards the SISR as a semantic image detail enhancement problem to generate semantically reasonable HR image that are faithful to the ground truth. To enhance the semantic accuracy and the visual quality of the reconstructed image, we explore the multi-modal fusion learning in SISR by proposing a Text-Guided Super-Resolution (TGSR) framework, which can effectively utilize the information from the text and image modalities. Different from existing methods, the proposed TGSR could generate HR image details that match the text descriptions through a coarse-to-fine process. Extensive experiments and ablation studies demonstrate the effect of the TGSR, which exploits the text reference to recover realistic images.
Let's Talk! Striking Up Conversations via Conversational Visual Question Generation
May 19, 2022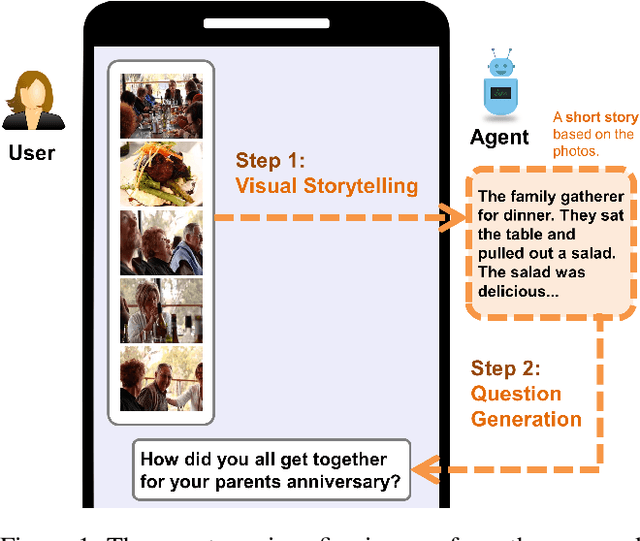

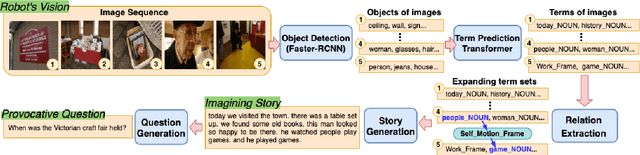

An engaging and provocative question can open up a great conversation. In this work, we explore a novel scenario: a conversation agent views a set of the user's photos (for example, from social media platforms) and asks an engaging question to initiate a conversation with the user. The existing vision-to-question models mostly generate tedious and obvious questions, which might not be ideals conversation starters. This paper introduces a two-phase framework that first generates a visual story for the photo set and then uses the story to produce an interesting question. The human evaluation shows that our framework generates more response-provoking questions for starting conversations than other vision-to-question baselines.
DoF-NeRF: Depth-of-Field Meets Neural Radiance Fields
Aug 01, 2022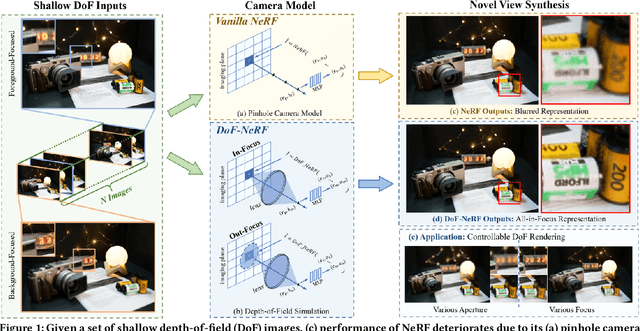
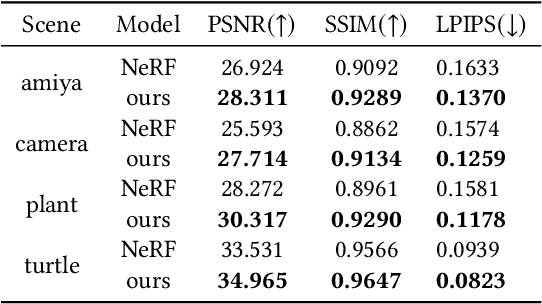
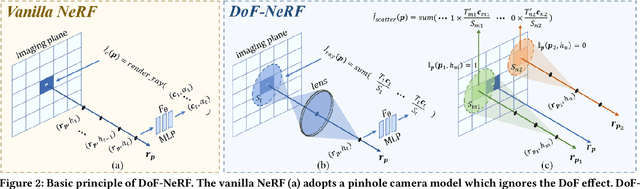
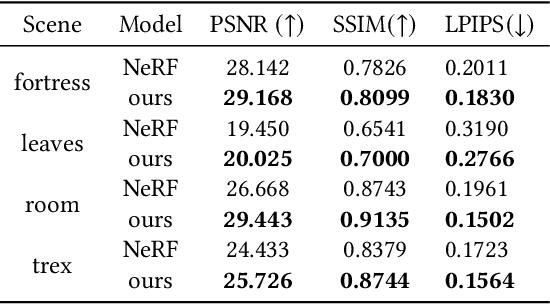
Neural Radiance Field (NeRF) and its variants have exhibited great success on representing 3D scenes and synthesizing photo-realistic novel views. However, they are generally based on the pinhole camera model and assume all-in-focus inputs. This limits their applicability as images captured from the real world often have finite depth-of-field (DoF). To mitigate this issue, we introduce DoF-NeRF, a novel neural rendering approach that can deal with shallow DoF inputs and can simulate DoF effect. In particular, it extends NeRF to simulate the aperture of lens following the principles of geometric optics. Such a physical guarantee allows DoF-NeRF to operate views with different focus configurations. Benefiting from explicit aperture modeling, DoF-NeRF also enables direct manipulation of DoF effect by adjusting virtual aperture and focus parameters. It is plug-and-play and can be inserted into NeRF-based frameworks. Experiments on synthetic and real-world datasets show that, DoF-NeRF not only performs comparably with NeRF in the all-in-focus setting, but also can synthesize all-in-focus novel views conditioned on shallow DoF inputs. An interesting application of DoF-NeRF to DoF rendering is also demonstrated. The source code will be made available at https://github.com/zijinwuzijin/DoF-NeRF.
Feature-based groupwise registration of historical aerial images to present-day ortho-photo maps
Nov 22, 2018
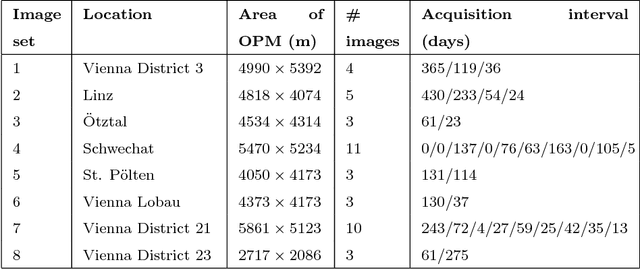
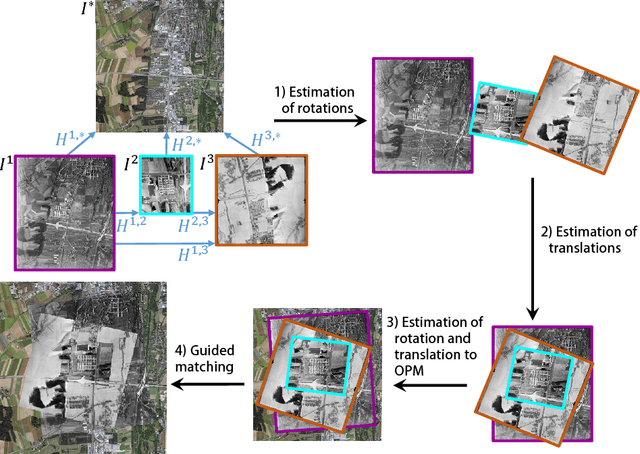
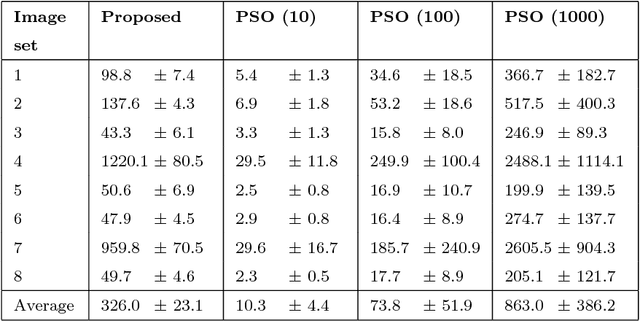
In this paper, we address the registration of historical WWII images to present-day ortho-photo maps for the purpose of geolocalization. Due to the challenging nature of this problem, we propose to register the images jointly as a group rather than in a step-by-step manner. To this end, we exploit Hough Voting spaces as pairwise registration estimators and show how they can be integrated into a probabilistic groupwise registration framework that can be efficiently optimized. The feature-based nature of our registration framework allows to register images with a-priori unknown translational and rotational relations, and is also able to handle scale changes of up to 30% in our test data due to a final geometrically guided matching step. The superiority of the proposed method over existing pairwise and groupwise registration methods is demonstrated on eight highly challenging sets of historical images with corresponding ortho-photo maps.
BokehMe: When Neural Rendering Meets Classical Rendering
Jun 25, 2022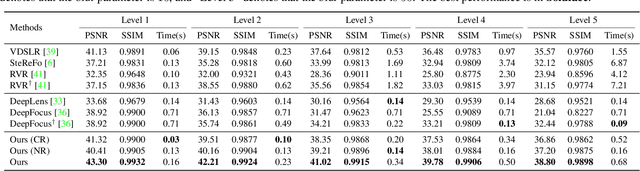
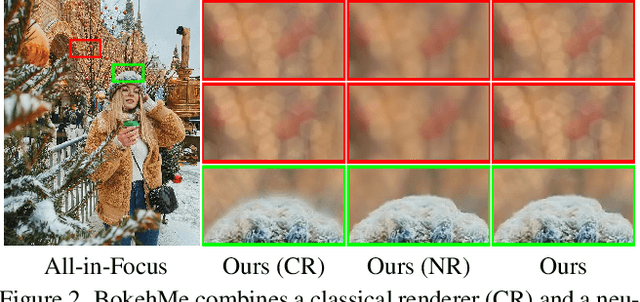
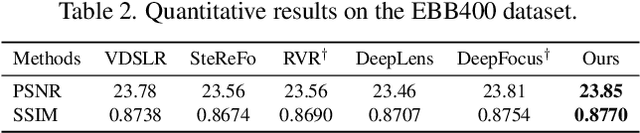
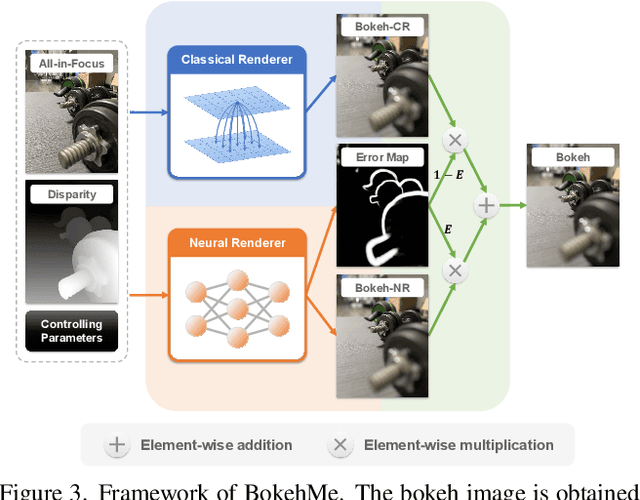
We propose BokehMe, a hybrid bokeh rendering framework that marries a neural renderer with a classical physically motivated renderer. Given a single image and a potentially imperfect disparity map, BokehMe generates high-resolution photo-realistic bokeh effects with adjustable blur size, focal plane, and aperture shape. To this end, we analyze the errors from the classical scattering-based method and derive a formulation to calculate an error map. Based on this formulation, we implement the classical renderer by a scattering-based method and propose a two-stage neural renderer to fix the erroneous areas from the classical renderer. The neural renderer employs a dynamic multi-scale scheme to efficiently handle arbitrary blur sizes, and it is trained to handle imperfect disparity input. Experiments show that our method compares favorably against previous methods on both synthetic image data and real image data with predicted disparity. A user study is further conducted to validate the advantage of our method.