 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Instance Shadow Detection with A Single-Stage Detector
Jul 11, 2022




This paper formulates a new problem, instance shadow detection, which aims to detect shadow instance and the associated object instance that cast each shadow in the input image. To approach this task, we first compile a new dataset with the masks for shadow instances, object instances, and shadow-object associations. We then design an evaluation metric for quantitative evaluation of the performance of instance shadow detection. Further, we design a single-stage detector to perform instance shadow detection in an end-to-end manner, where the bidirectional relation learning module and the deformable maskIoU head are proposed in the detector to directly learn the relation between shadow instances and object instances and to improve the accuracy of the predicted masks. Finally, we quantitatively and qualitatively evaluate our method on the benchmark dataset of instance shadow detection and show the applicability of our method on light direction estimation and photo editing.
Face Anti-Spoofing from the Perspective of Data Sampling
Aug 28, 2022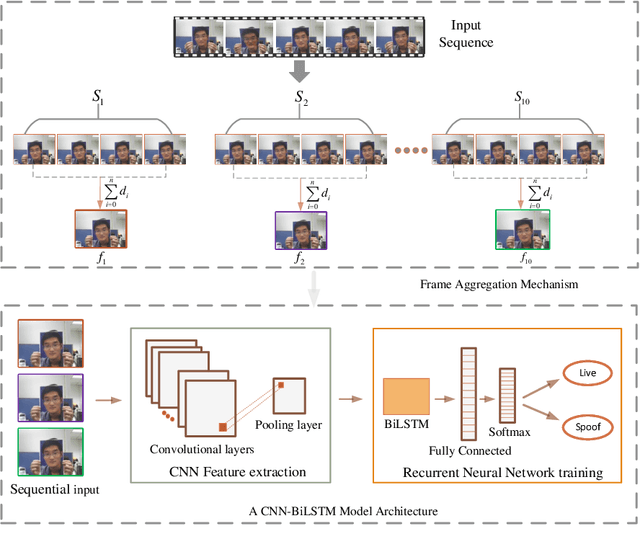

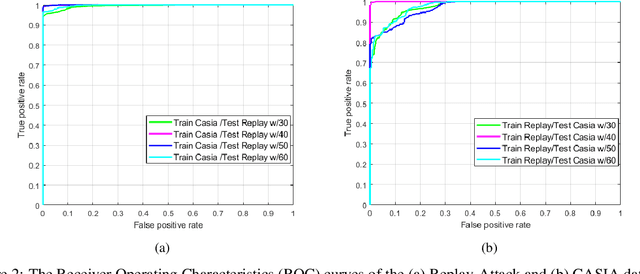
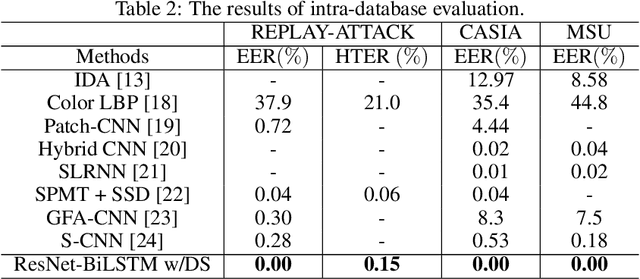
Without deploying face anti-spoofing countermeasures, face recognition systems can be spoofed by presenting a printed photo, a video, or a silicon mask of a genuine user. Thus, face presentation attack detection (PAD) plays a vital role in providing secure facial access to digital devices. Most existing video-based PAD countermeasures lack the ability to cope with long-range temporal variations in videos. Moreover, the key-frame sampling prior to the feature extraction step has not been widely studied in the face anti-spoofing domain. To mitigate these issues, this paper provides a data sampling approach by proposing a video processing scheme that models the long-range temporal variations based on Gaussian Weighting Function. Specifically, the proposed scheme encodes the consecutive t frames of video sequences into a single RGB image based on a Gaussian-weighted summation of the t frames. Using simply the data sampling scheme alone, we demonstrate that state-of-the-art performance can be achieved without any bells and whistles in both intra-database and inter-database testing scenarios for the three public benchmark datasets; namely, Replay-Attack, MSU-MFSD, and CASIA-FASD. In particular, the proposed scheme provides a much lower error (from 15.2% to 6.7% on CASIA-FASD and 5.9% to 4.9% on Replay-Attack) compared to baselines in cross-database scenarios.
Unsupervised Coherent Video Cartoonization with Perceptual Motion Consistency
Apr 02, 2022
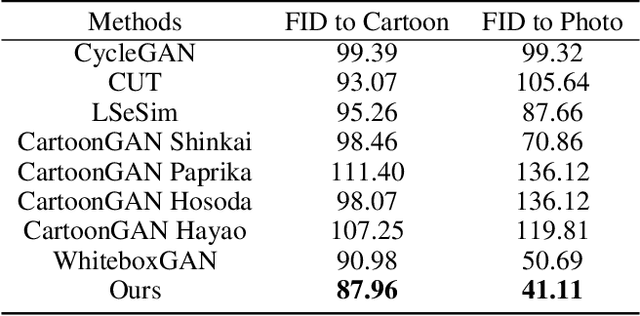

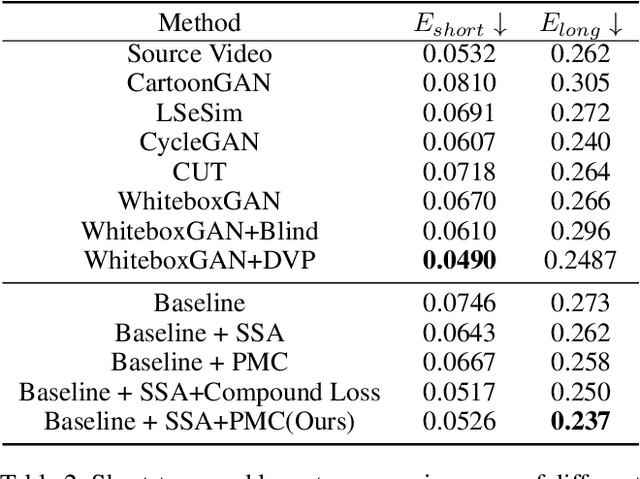
In recent years, creative content generations like style transfer and neural photo editing have attracted more and more attention. Among these, cartoonization of real-world scenes has promising applications in entertainment and industry. Different from image translations focusing on improving the style effect of generated images, video cartoonization has additional requirements on the temporal consistency. In this paper, we propose a spatially-adaptive semantic alignment framework with perceptual motion consistency for coherent video cartoonization in an unsupervised manner. The semantic alignment module is designed to restore deformation of semantic structure caused by spatial information lost in the encoder-decoder architecture. Furthermore, we devise the spatio-temporal correlative map as a style-independent, global-aware regularization on the perceptual motion consistency. Deriving from similarity measurement of high-level features in photo and cartoon frames, it captures global semantic information beyond raw pixel-value in optical flow. Besides, the similarity measurement disentangles temporal relationships from domain-specific style properties, which helps regularize the temporal consistency without hurting style effects of cartoon images. Qualitative and quantitative experiments demonstrate our method is able to generate highly stylistic and temporal consistent cartoon videos.
End-to-End Photo-Sketch Generation via Fully Convolutional Representation Learning
Apr 11, 2015
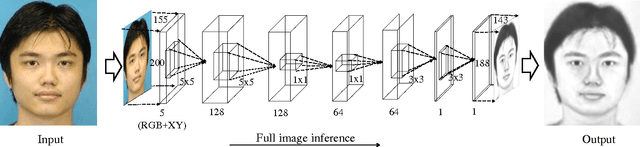

Sketch-based face recognition is an interesting task in vision and multimedia research, yet it is quite challenging due to the great difference between face photos and sketches. In this paper, we propose a novel approach for photo-sketch generation, aiming to automatically transform face photos into detail-preserving personal sketches. Unlike the traditional models synthesizing sketches based on a dictionary of exemplars, we develop a fully convolutional network to learn the end-to-end photo-sketch mapping. Our approach takes whole face photos as inputs and directly generates the corresponding sketch images with efficient inference and learning, in which the architecture are stacked by only convolutional kernels of very small sizes. To well capture the person identity during the photo-sketch transformation, we define our optimization objective in the form of joint generative-discriminative minimization. In particular, a discriminative regularization term is incorporated into the photo-sketch generation, enhancing the discriminability of the generated person sketches against other individuals. Extensive experiments on several standard benchmarks suggest that our approach outperforms other state-of-the-art methods in both photo-sketch generation and face sketch verification.
Significance of Skeleton-based Features in Virtual Try-On
Aug 17, 2022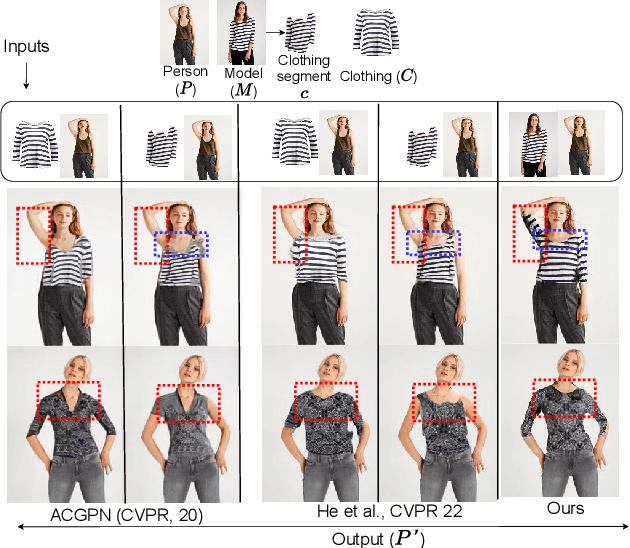
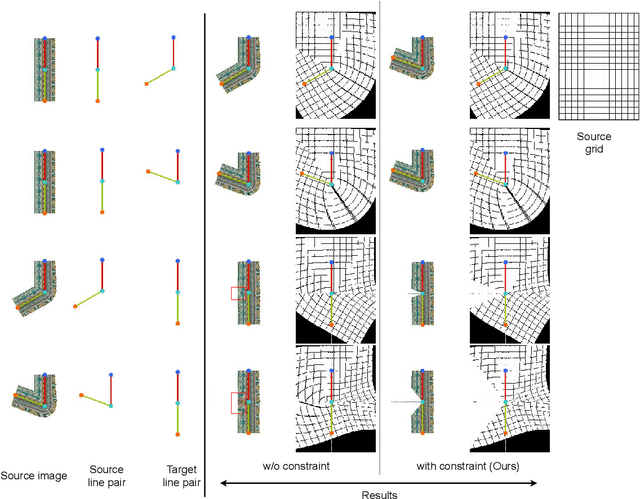


The idea of \textit{Virtual Try-ON} (VTON) benefits e-retailing by giving an user the convenience of trying a clothing at the comfort of their home. In general, most of the existing VTON methods produce inconsistent results when a person posing with his arms folded i.e., bent or crossed, wants to try an outfit. The problem becomes severe in the case of long-sleeved outfits. As then, for crossed arm postures, overlap among different clothing parts might happen. The existing approaches, especially the warping-based methods employing \textit{Thin Plate Spline (TPS)} transform can not tackle such cases. To this end, we attempt a solution approach where the clothing from the source person is segmented into semantically meaningful parts and each part is warped independently to the shape of the person. To address the bending issue, we employ hand-crafted geometric features consistent with human body geometry for warping the source outfit. In addition, we propose two learning-based modules: a synthesizer network and a mask prediction network. All these together attempt to produce a photo-realistic, pose-robust VTON solution without requiring any paired training data. Comparison with some of the benchmark methods clearly establishes the effectiveness of the approach.
CariGANs: Unpaired Photo-to-Caricature Translation
Nov 02, 2018
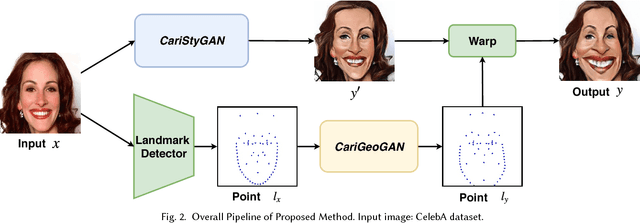
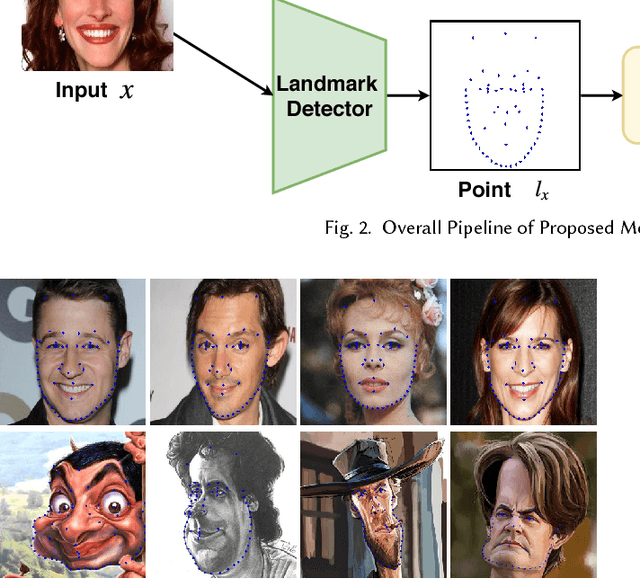
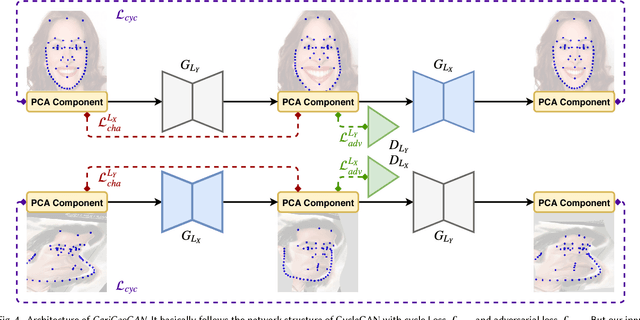
Facial caricature is an art form of drawing faces in an exaggerated way to convey humor or sarcasm. In this paper, we propose the first Generative Adversarial Network (GAN) for unpaired photo-to-caricature translation, which we call "CariGANs". It explicitly models geometric exaggeration and appearance stylization using two components: CariGeoGAN, which only models the geometry-to-geometry transformation from face photos to caricatures, and CariStyGAN, which transfers the style appearance from caricatures to face photos without any geometry deformation. In this way, a difficult cross-domain translation problem is decoupled into two easier tasks. The perceptual study shows that caricatures generated by our CariGANs are closer to the hand-drawn ones, and at the same time better persevere the identity, compared to state-of-the-art methods. Moreover, our CariGANs allow users to control the shape exaggeration degree and change the color/texture style by tuning the parameters or giving an example caricature.
* To appear at SIGGRAPH Asia 2018
NeuralFusion: Neural Volumetric Rendering under Human-object Interactions
Feb 28, 2022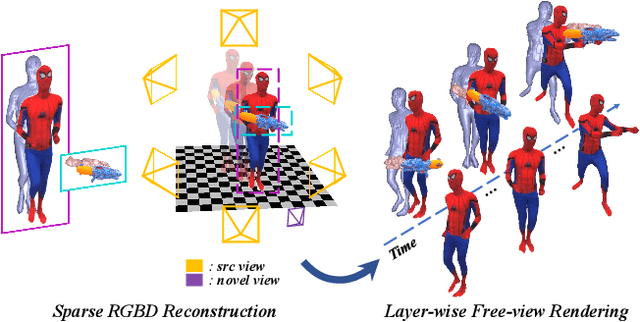
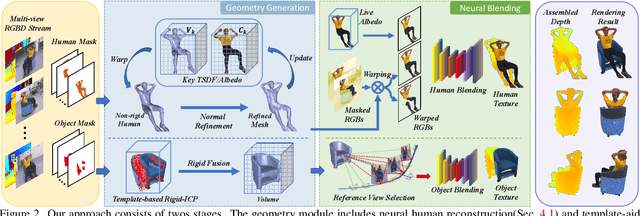
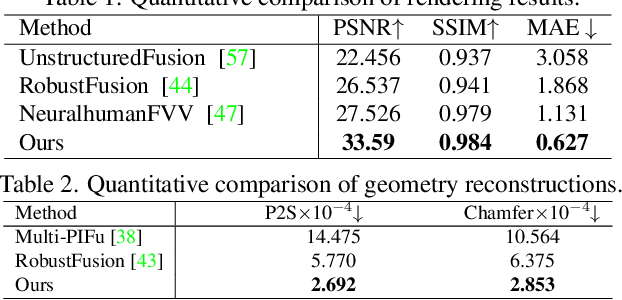
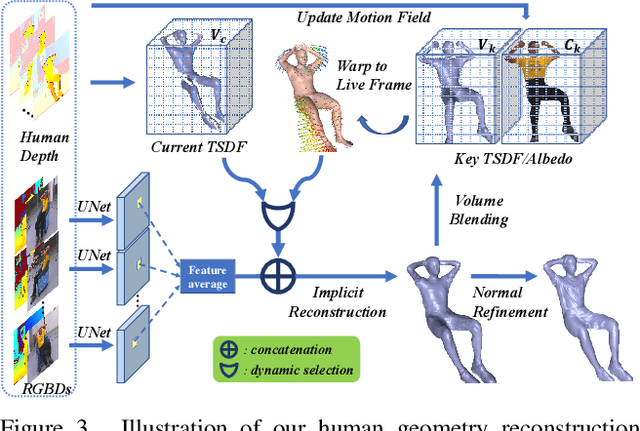
4D modeling of human-object interactions is critical for numerous applications. However, efficient volumetric capture and rendering of complex interaction scenarios, especially from sparse inputs, remain challenging. In this paper, we propose NeuralFusion, a neural approach for volumetric human-object capture and rendering using sparse consumer RGBD sensors. It marries traditional non-rigid fusion with recent neural implicit modeling and blending advances, where the captured humans and objects are layerwise disentangled. For geometry modeling, we propose a neural implicit inference scheme with non-rigid key-volume fusion, as well as a template-aid robust object tracking pipeline. Our scheme enables detailed and complete geometry generation under complex interactions and occlusions. Moreover, we introduce a layer-wise human-object texture rendering scheme, which combines volumetric and image-based rendering in both spatial and temporal domains to obtain photo-realistic results. Extensive experiments demonstrate the effectiveness and efficiency of our approach in synthesizing photo-realistic free-view results under complex human-object interactions.
Heart rate estimation in intense exercise videos
Aug 04, 2022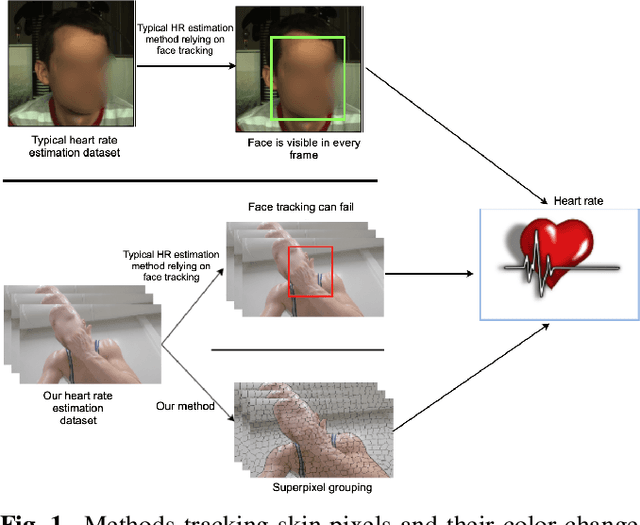

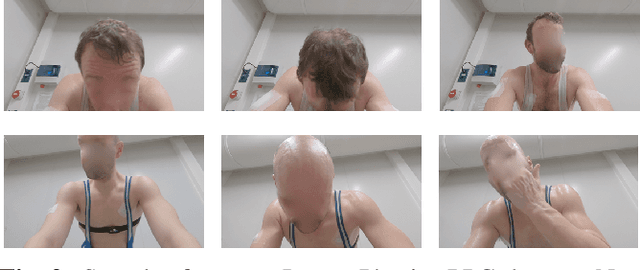
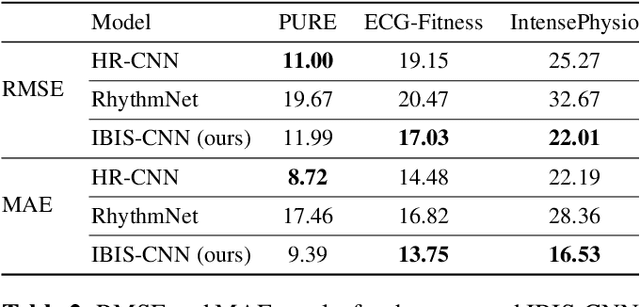
Estimating heart rate from video allows non-contact health monitoring with applications in patient care, human interaction, and sports. Existing work can robustly measure heart rate under some degree of motion by face tracking. However, this is not always possible in unconstrained settings, as the face might be occluded or even outside the camera. Here, we present IntensePhysio: a challenging video heart rate estimation dataset with realistic face occlusions, severe subject motion, and ample heart rate variation. To ensure heart rate variation in a realistic setting we record each subject for around 1-2 hours. The subject is exercising (at a moderate to high intensity) on a cycling ergometer with an attached video camera and is given no instructions regarding positioning or movement. We have 11 subjects, and approximately 20 total hours of video. We show that the existing remote photo-plethysmography methods have difficulty in estimating heart rate in this setting. In addition, we present IBIS-CNN, a new baseline using spatio-temporal superpixels, which improves on existing models by eliminating the need for a visible face/face tracking. We will make the code and data publically available soon.
Automatic Calibration of a Six-Degrees-of-Freedom Pose Estimation System
Aug 23, 2022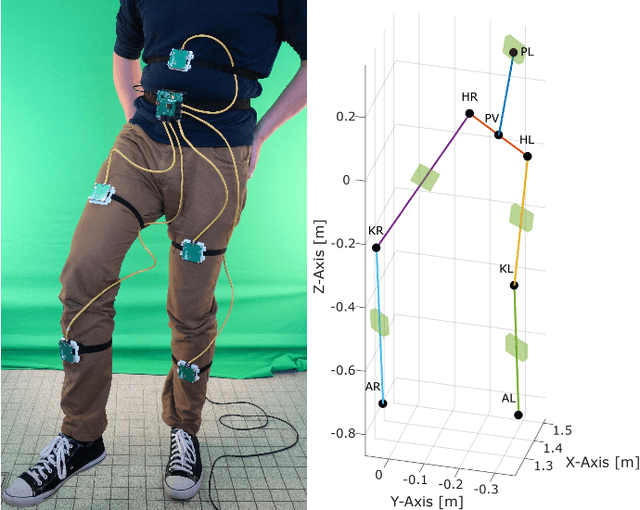
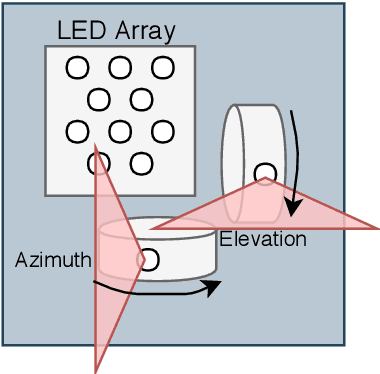
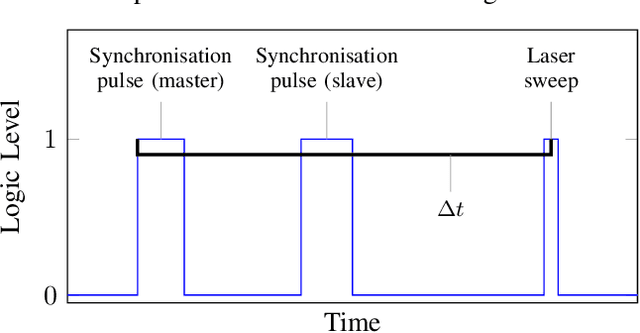

Systems for estimating the six-degrees-of-freedom human body pose have been improving for over two decades. Technologies such as motion capture cameras, advanced gaming peripherals and more recently both deep learning techniques and virtual reality systems have shown impressive results. However, most systems that provide high accuracy and high precision are expensive and not easy to operate. Recently, research has been carried out to estimate the human body pose using the HTC Vive virtual reality system. This system shows accurate results while keeping the cost under a 1000 USD. This system uses an optical approach. Two transmitter devices emit infrared pulses and laser planes are tracked by use of photo diodes on receiver hardware. A system using these transmitter devices combined with low-cost custom-made receiver hardware was developed previously but requires manual measurement of the position and orientation of the transmitter devices. These manual measurements can be time consuming, prone to error and not possible in particular setups. We propose an algorithm to automatically calibrate the poses of the transmitter devices in any chosen environment with custom receiver/calibration hardware. Results show that the calibration works in a variety of setups while being more accurate than what manual measurements would allow. Furthermore, the calibration movement and speed has no noticeable influence on the precision of the results.
Automatic Photo Adjustment Using Deep Neural Networks
May 16, 2015
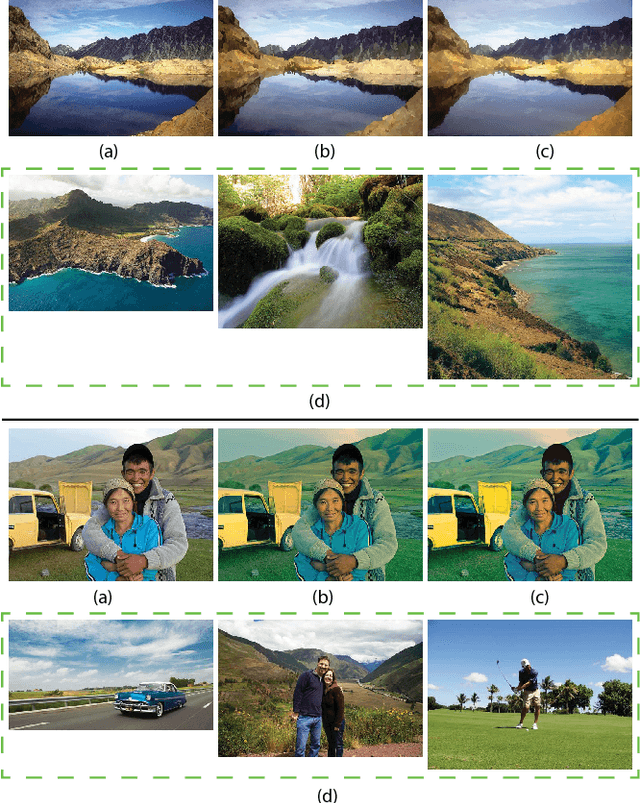

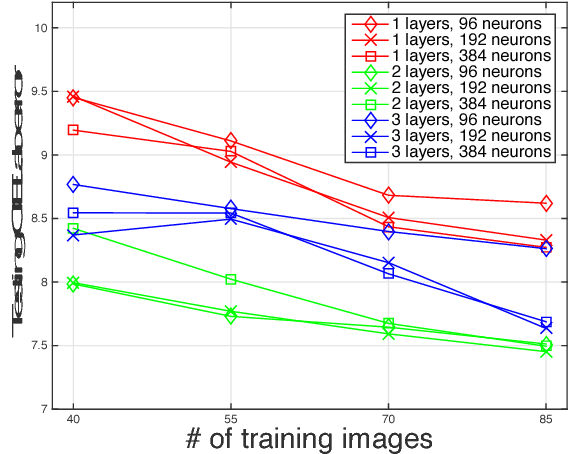
Photo retouching enables photographers to invoke dramatic visual impressions by artistically enhancing their photos through stylistic color and tone adjustments. However, it is also a time-consuming and challenging task that requires advanced skills beyond the abilities of casual photographers. Using an automated algorithm is an appealing alternative to manual work but such an algorithm faces many hurdles. Many photographic styles rely on subtle adjustments that depend on the image content and even its semantics. Further, these adjustments are often spatially varying. Because of these characteristics, existing automatic algorithms are still limited and cover only a subset of these challenges. Recently, deep machine learning has shown unique abilities to address hard problems that resisted machine algorithms for long. This motivated us to explore the use of deep learning in the context of photo editing. In this paper, we explain how to formulate the automatic photo adjustment problem in a way suitable for this approach. We also introduce an image descriptor that accounts for the local semantics of an image. Our experiments demonstrate that our deep learning formulation applied using these descriptors successfully capture sophisticated photographic styles. In particular and unlike previous techniques, it can model local adjustments that depend on the image semantics. We show on several examples that this yields results that are qualitatively and quantitatively better than previous work.