 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Multimodal Feature Extraction for Memes Sentiment Classification
Jul 07, 2022
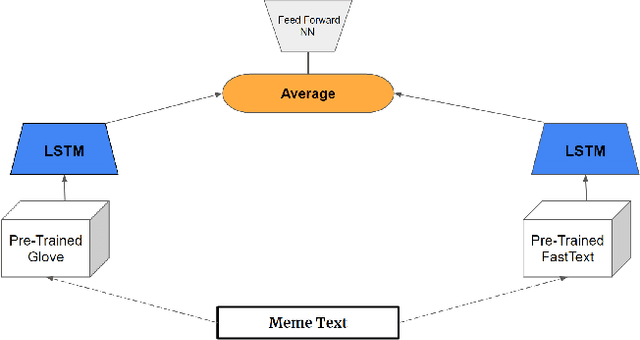
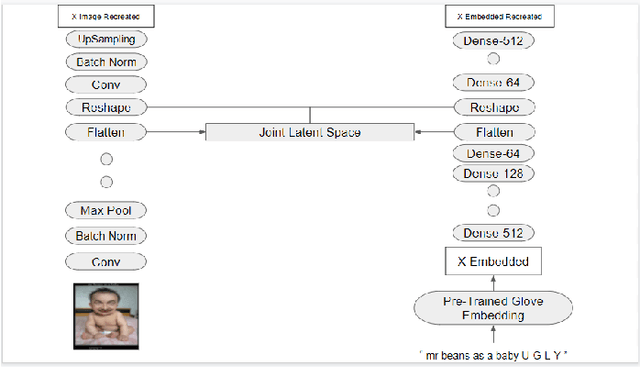
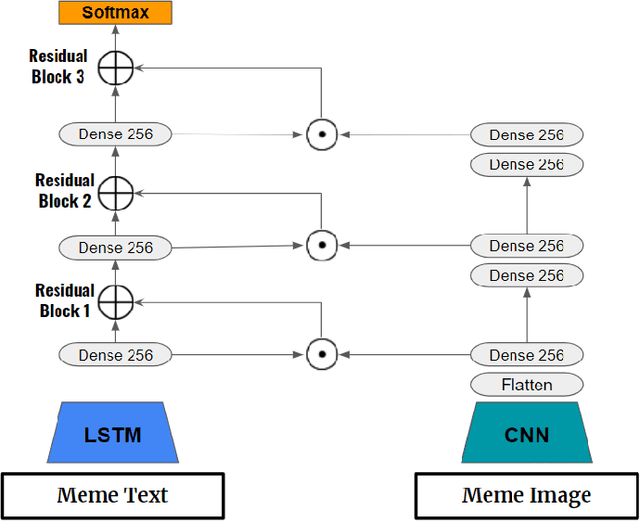
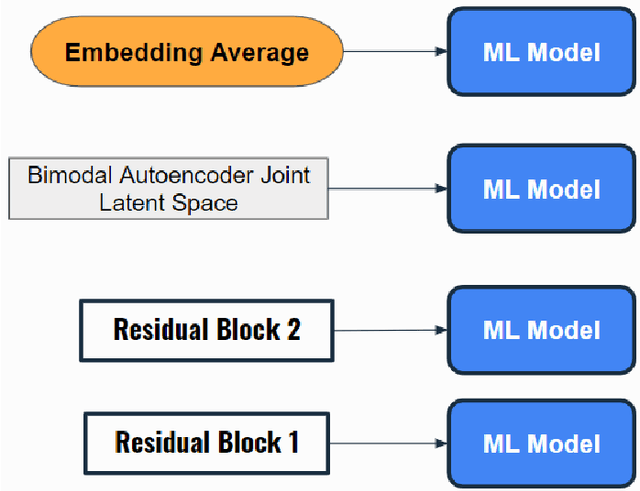
In this study, we propose feature extraction for multimodal meme classification using Deep Learning approaches. A meme is usually a photo or video with text shared by the young generation on social media platforms that expresses a culturally relevant idea. Since they are an efficient way to express emotions and feelings, a good classifier that can classify the sentiment behind the meme is important. To make the learning process more efficient, reduce the likelihood of overfitting, and improve the generalizability of the model, one needs a good approach for joint feature extraction from all modalities. In this work, we proposed to use different multimodal neural network approaches for multimodal feature extraction and use the extracted features to train a classifier to identify the sentiment in a meme.
Free-HeadGAN: Neural Talking Head Synthesis with Explicit Gaze Control
Aug 03, 2022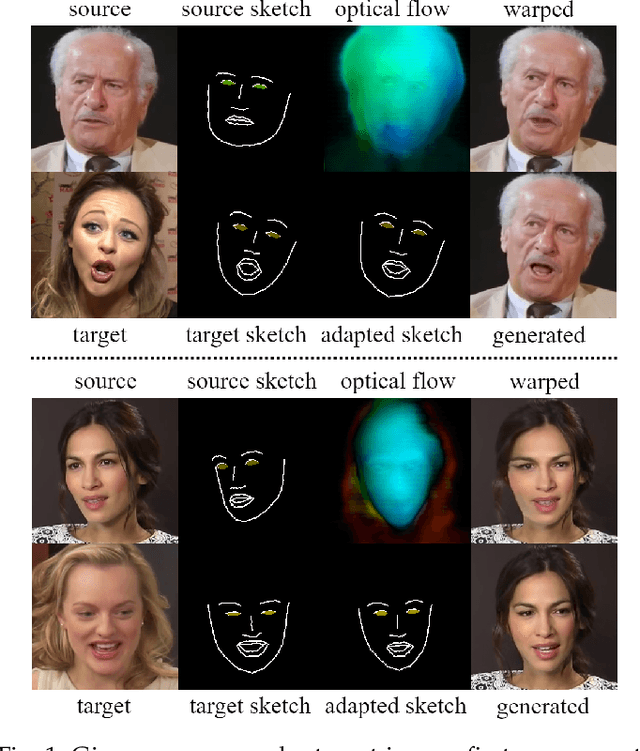
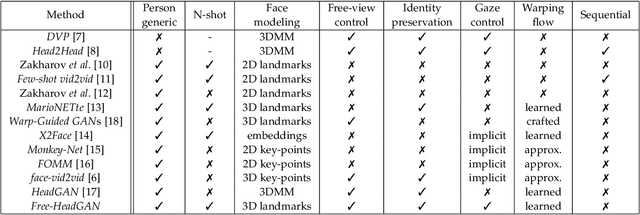
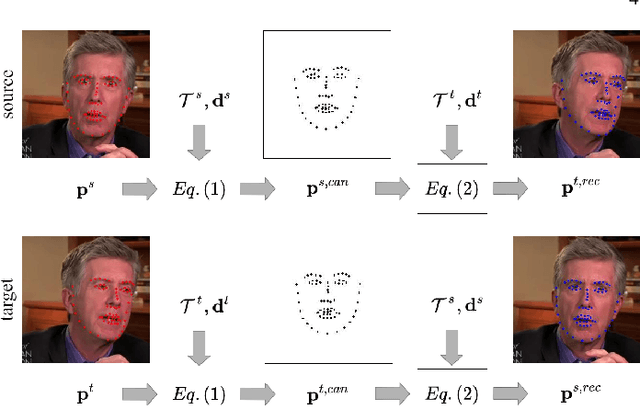
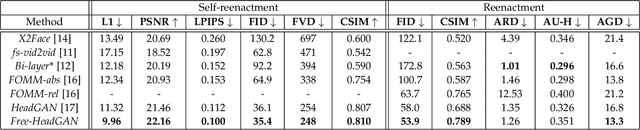
We present Free-HeadGAN, a person-generic neural talking head synthesis system. We show that modeling faces with sparse 3D facial landmarks are sufficient for achieving state-of-the-art generative performance, without relying on strong statistical priors of the face, such as 3D Morphable Models. Apart from 3D pose and facial expressions, our method is capable of fully transferring the eye gaze, from a driving actor to a source identity. Our complete pipeline consists of three components: a canonical 3D key-point estimator that regresses 3D pose and expression-related deformations, a gaze estimation network and a generator that is built upon the architecture of HeadGAN. We further experiment with an extension of our generator to accommodate few-shot learning using an attention mechanism, in case more than one source images are available. Compared to the latest models for reenactment and motion transfer, our system achieves higher photo-realism combined with superior identity preservation, while offering explicit gaze control.
Photo Aesthetics Ranking Network with Attributes and Content Adaptation
Jul 27, 2016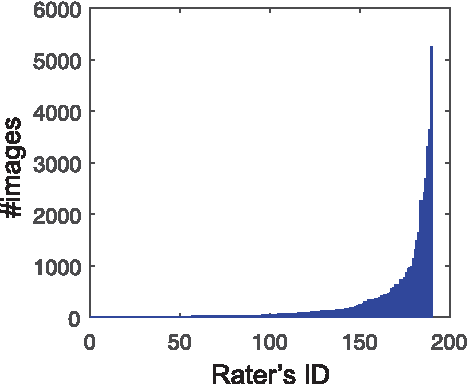

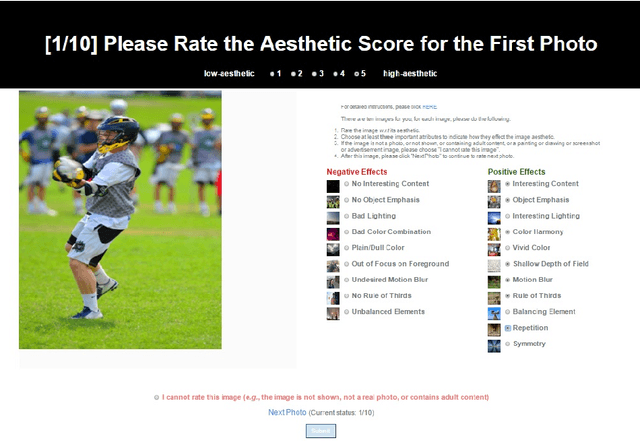
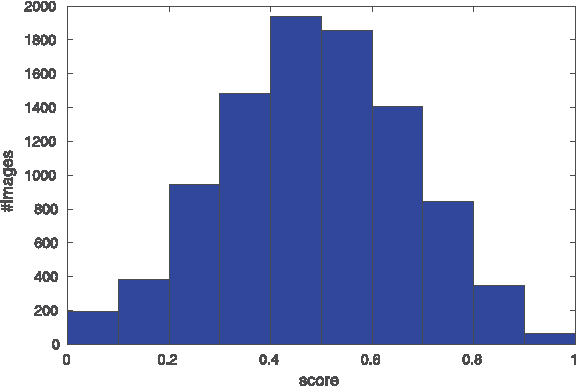
Real-world applications could benefit from the ability to automatically generate a fine-grained ranking of photo aesthetics. However, previous methods for image aesthetics analysis have primarily focused on the coarse, binary categorization of images into high- or low-aesthetic categories. In this work, we propose to learn a deep convolutional neural network to rank photo aesthetics in which the relative ranking of photo aesthetics are directly modeled in the loss function. Our model incorporates joint learning of meaningful photographic attributes and image content information which can help regularize the complicated photo aesthetics rating problem. To train and analyze this model, we have assembled a new aesthetics and attributes database (AADB) which contains aesthetic scores and meaningful attributes assigned to each image by multiple human raters. Anonymized rater identities are recorded across images allowing us to exploit intra-rater consistency using a novel sampling strategy when computing the ranking loss of training image pairs. We show the proposed sampling strategy is very effective and robust in face of subjective judgement of image aesthetics by individuals with different aesthetic tastes. Experiments demonstrate that our unified model can generate aesthetic rankings that are more consistent with human ratings. To further validate our model, we show that by simply thresholding the estimated aesthetic scores, we are able to achieve state-or-the-art classification performance on the existing AVA dataset benchmark.
Multi-granularity Association Learning Framework for on-the-fly Fine-Grained Sketch-based Image Retrieval
Jan 13, 2022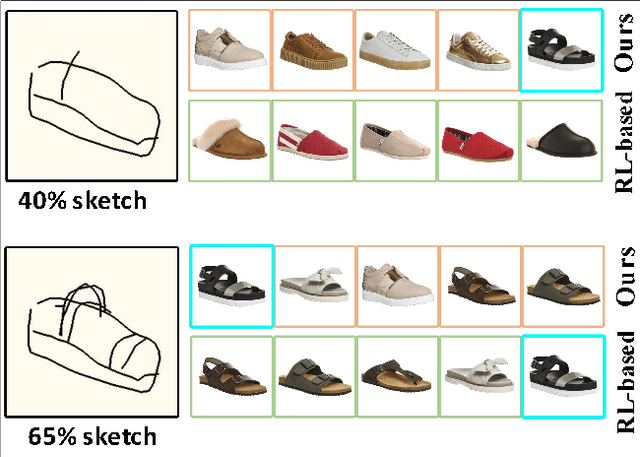
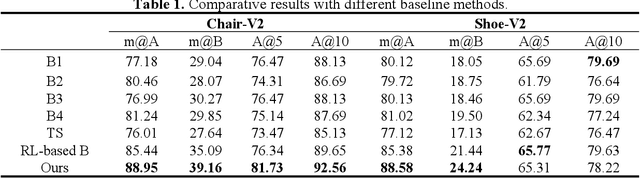
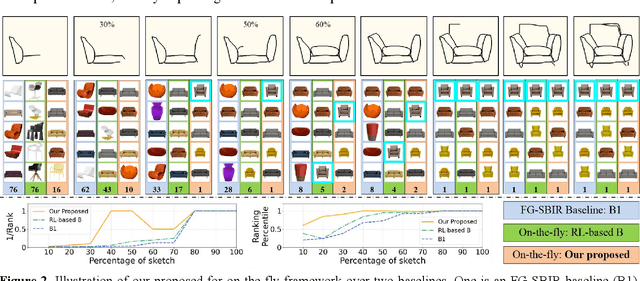
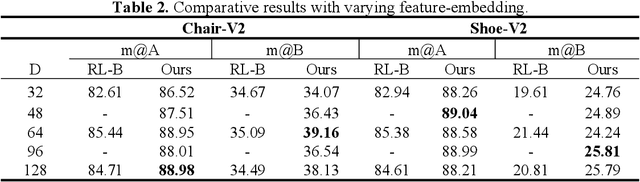
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo in a given query sketch. However, its widespread applicability is limited by the fact that it is difficult to draw a complete sketch for most people, and the drawing process often takes time. In this study, we aim to retrieve the target photo with the least number of strokes possible (incomplete sketch), named on-the-fly FG-SBIR (Bhunia et al. 2020), which starts retrieving at each stroke as soon as the drawing begins. We consider that there is a significant correlation among these incomplete sketches in the sketch drawing episode of each photo. To learn more efficient joint embedding space shared between the photo and its incomplete sketches, we propose a multi-granularity association learning framework that further optimizes the embedding space of all incomplete sketches. Specifically, based on the integrity of the sketch, we can divide a complete sketch episode into several stages, each of which corresponds to a simple linear mapping layer. Moreover, our framework guides the vector space representation of the current sketch to approximate that of its later sketches to realize the retrieval performance of the sketch with fewer strokes to approach that of the sketch with more strokes. In the experiments, we proposed more realistic challenges, and our method achieved superior early retrieval efficiency over the state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
NeuralHOFusion: Neural Volumetric Rendering under Human-object Interactions
Mar 28, 2022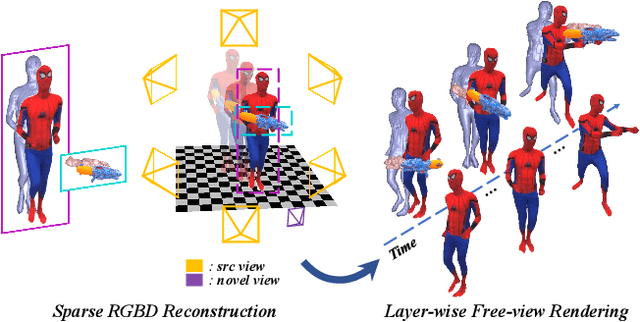
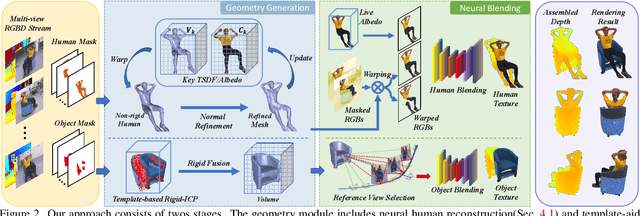
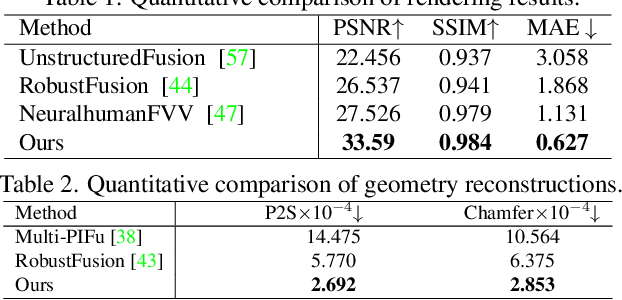
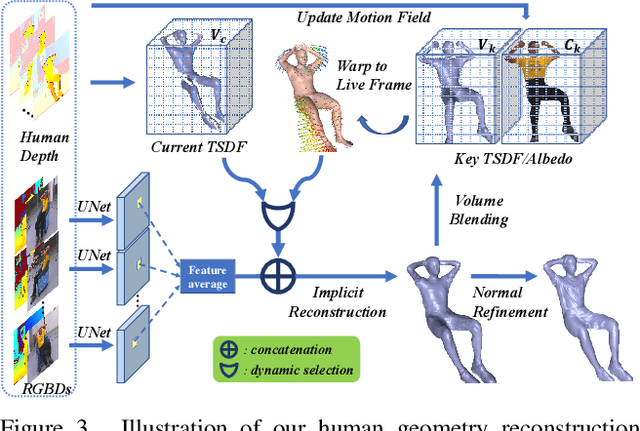
4D modeling of human-object interactions is critical for numerous applications. However, efficient volumetric capture and rendering of complex interaction scenarios, especially from sparse inputs, remain challenging. In this paper, we propose NeuralHOFusion, a neural approach for volumetric human-object capture and rendering using sparse consumer RGBD sensors. It marries traditional non-rigid fusion with recent neural implicit modeling and blending advances, where the captured humans and objects are layerwise disentangled. For geometry modeling, we propose a neural implicit inference scheme with non-rigid key-volume fusion, as well as a template-aid robust object tracking pipeline. Our scheme enables detailed and complete geometry generation under complex interactions and occlusions. Moreover, we introduce a layer-wise human-object texture rendering scheme, which combines volumetric and image-based rendering in both spatial and temporal domains to obtain photo-realistic results. Extensive experiments demonstrate the effectiveness and efficiency of our approach in synthesizing photo-realistic free-view results under complex human-object interactions.
3D-FM GAN: Towards 3D-Controllable Face Manipulation
Aug 24, 2022
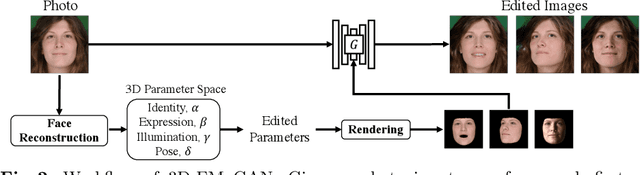

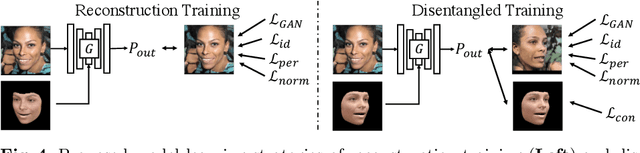
3D-controllable portrait synthesis has significantly advanced, thanks to breakthroughs in generative adversarial networks (GANs). However, it is still challenging to manipulate existing face images with precise 3D control. While concatenating GAN inversion and a 3D-aware, noise-to-image GAN is a straight-forward solution, it is inefficient and may lead to noticeable drop in editing quality. To fill this gap, we propose 3D-FM GAN, a novel conditional GAN framework designed specifically for 3D-controllable face manipulation, and does not require any tuning after the end-to-end learning phase. By carefully encoding both the input face image and a physically-based rendering of 3D edits into a StyleGAN's latent spaces, our image generator provides high-quality, identity-preserved, 3D-controllable face manipulation. To effectively learn such novel framework, we develop two essential training strategies and a novel multiplicative co-modulation architecture that improves significantly upon naive schemes. With extensive evaluations, we show that our method outperforms the prior arts on various tasks, with better editability, stronger identity preservation, and higher photo-realism. In addition, we demonstrate a better generalizability of our design on large pose editing and out-of-domain images.
Significance of Skeleton-based Features in Virtual Try-On
Sep 01, 2022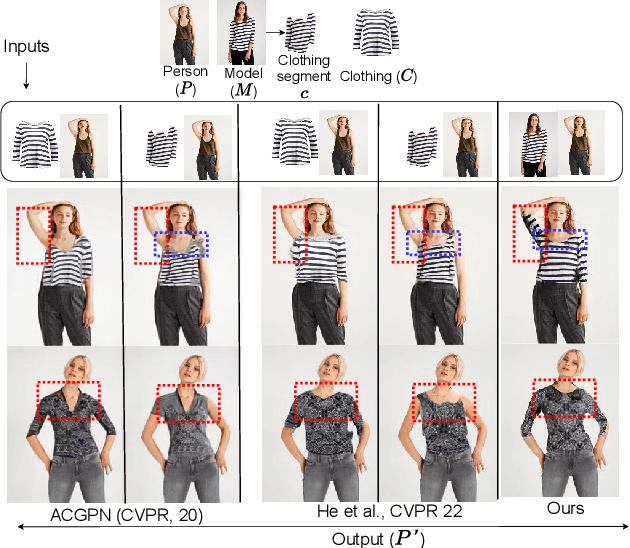


The idea of \textit{Virtual Try-ON} (VTON) benefits e-retailing by giving an user the convenience of trying a clothing at the comfort of their home. In general, most of the existing VTON methods produce inconsistent results when a person posing with his arms folded i.e., bent or crossed, wants to try an outfit. The problem becomes severe in the case of long-sleeved outfits. As then, for crossed arm postures, overlap among different clothing parts might happen. The existing approaches, especially the warping-based methods employing \textit{Thin Plate Spline (TPS)} transform can not tackle such cases. To this end, we attempt a solution approach where the clothing from the source person is segmented into semantically meaningful parts and each part is warped independently to the shape of the person. To address the bending issue, we employ hand-crafted geometric features consistent with human body geometry for warping the source outfit. In addition, we propose two learning-based modules: a synthesizer network and a mask prediction network. All these together attempt to produce a photo-realistic, pose-robust VTON solution without requiring any paired training data. Comparison with some of the benchmark methods clearly establishes the effectiveness of the approach.
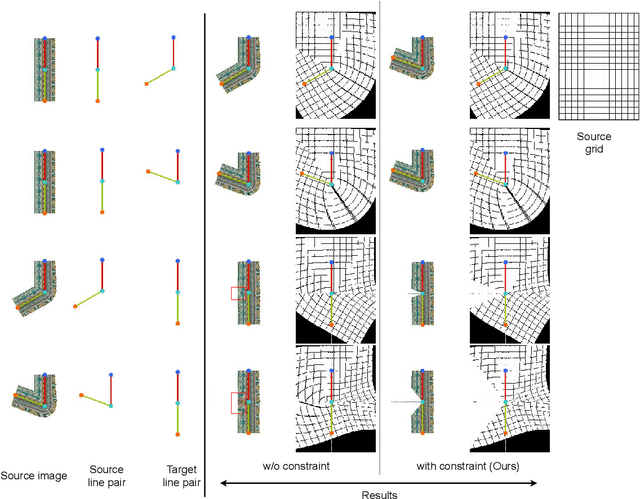
Sim4CV: A Photo-Realistic Simulator for Computer Vision Applications
Mar 24, 2018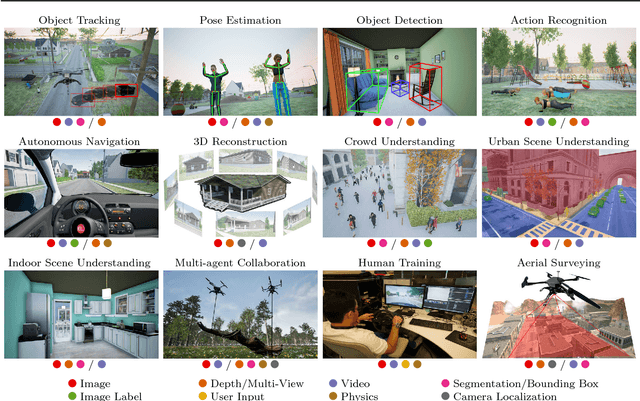

We present a photo-realistic training and evaluation simulator (Sim4CV) with extensive applications across various fields of computer vision. Built on top of the Unreal Engine, the simulator integrates full featured physics based cars, unmanned aerial vehicles (UAVs), and animated human actors in diverse urban and suburban 3D environments. We demonstrate the versatility of the simulator with two case studies: autonomous UAV-based tracking of moving objects and autonomous driving using supervised learning. The simulator fully integrates both several state-of-the-art tracking algorithms with a benchmark evaluation tool and a deep neural network (DNN) architecture for training vehicles to drive autonomously. It generates synthetic photo-realistic datasets with automatic ground truth annotations to easily extend existing real-world datasets and provides extensive synthetic data variety through its ability to reconfigure synthetic worlds on the fly using an automatic world generation tool. The supplementary video can be viewed a https://youtu.be/SqAxzsQ7qUU
Aesthetic Language Guidance Generation of Images Using Attribute Comparison
Aug 09, 2022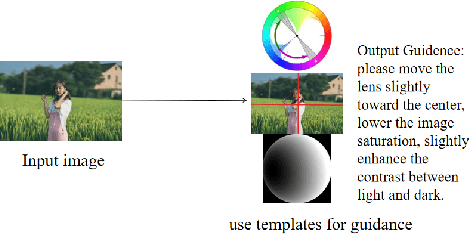

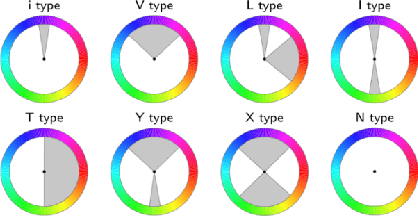
With the vigorous development of mobile photography technology, major mobile phone manufacturers are scrambling to improve the shooting ability of equipments and the photo beautification algorithm of software. However, the improvement of intelligent equipments and algorithms cannot replace human subjective photography technology. In this paper, we propose the aesthetic language guidance of image (ALG). We divide ALG into ALG-T and ALG-I according to whether the guiding rules are based on photography templates or guidance images. Whether it is ALG-T or ALG-I, we guide photography from three attributes of color, lighting and composition of the images. The differences of the three attributes between the input images and the photography templates or the guidance images are described in natural language, which is aesthetic natural language guidance (ALG). Also, because of the differences in lighting and composition between landscape images and portrait images, we divide the input images into landscape images and portrait images. Both ALG-T and ALG-I conduct aesthetic language guidance respectively for the two types of input images (landscape images and portrait images).
A Survey on Leveraging Pre-trained Generative Adversarial Networks for Image Editing and Restoration
Jul 21, 2022

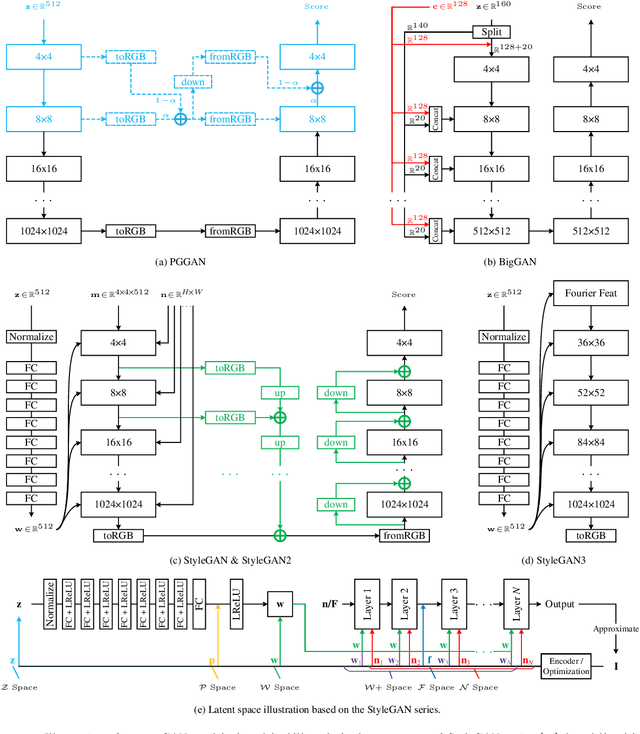

Generative adversarial networks (GANs) have drawn enormous attention due to the simple yet effective training mechanism and superior image generation quality. With the ability to generate photo-realistic high-resolution (e.g., $1024\times1024$) images, recent GAN models have greatly narrowed the gaps between the generated images and the real ones. Therefore, many recent works show emerging interest to take advantage of pre-trained GAN models by exploiting the well-disentangled latent space and the learned GAN priors. In this paper, we briefly review recent progress on leveraging pre-trained large-scale GAN models from three aspects, i.e., 1) the training of large-scale generative adversarial networks, 2) exploring and understanding the pre-trained GAN models, and 3) leveraging these models for subsequent tasks like image restoration and editing. More information about relevant methods and repositories can be found at https://github.com/csmliu/pretrained-GANs.