 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
PDRF: Progressively Deblurring Radiance Field for Fast and Robust Scene Reconstruction from Blurry Images
Aug 17, 2022
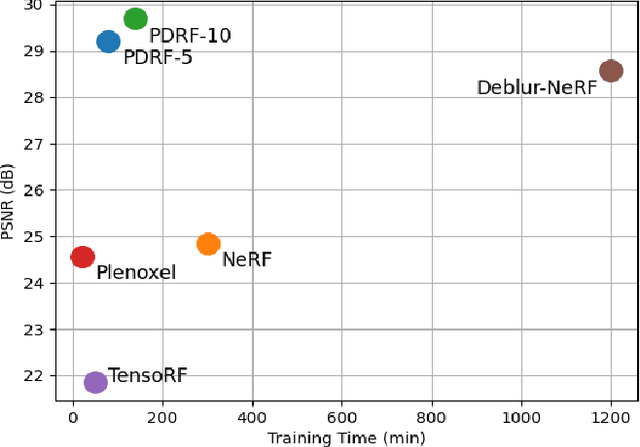
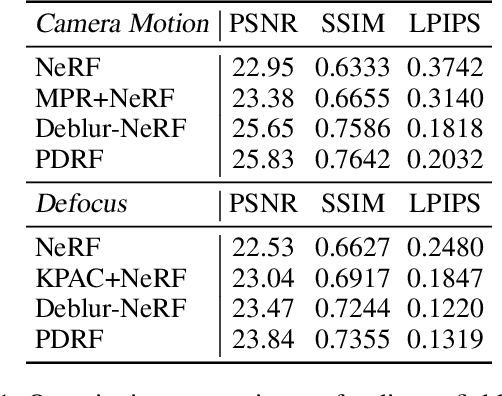

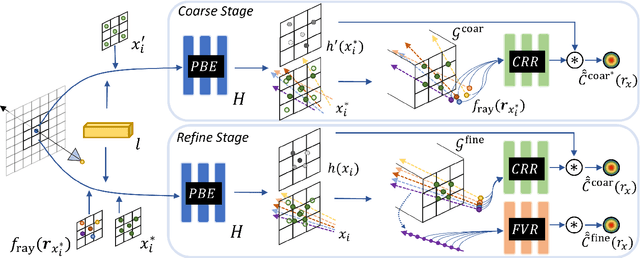
We present Progressively Deblurring Radiance Field (PDRF), a novel approach to efficiently reconstruct high quality radiance fields from blurry images. While current State-of-The-Art (SoTA) scene reconstruction methods achieve photo-realistic rendering results from clean source views, their performances suffer when the source views are affected by blur, which is commonly observed for images in the wild. Previous deblurring methods either do not account for 3D geometry, or are computationally intense. To addresses these issues, PDRF, a progressively deblurring scheme in radiance field modeling, accurately models blur by incorporating 3D scene context. PDRF further uses an efficient importance sampling scheme, which results in fast scene optimization. Specifically, PDRF proposes a Coarse Ray Renderer to quickly estimate voxel density and feature; a Fine Voxel Renderer is then used to achieve high quality ray tracing. We perform extensive experiments and show that PDRF is 15X faster than previous SoTA while achieving better performance on both synthetic and real scenes.
Learning Dual Memory Dictionaries for Blind Face Restoration
Oct 15, 2022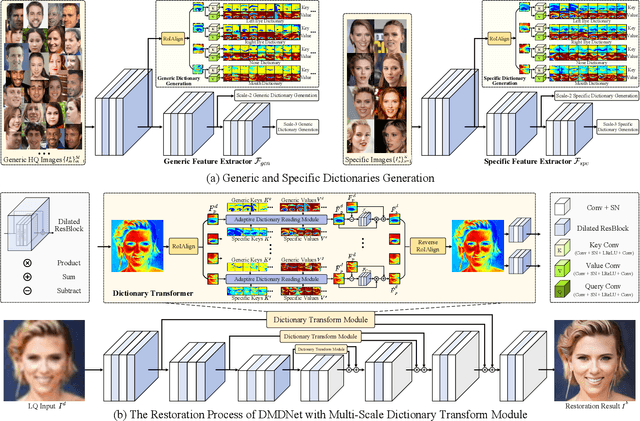
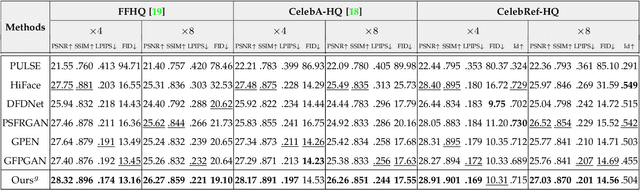
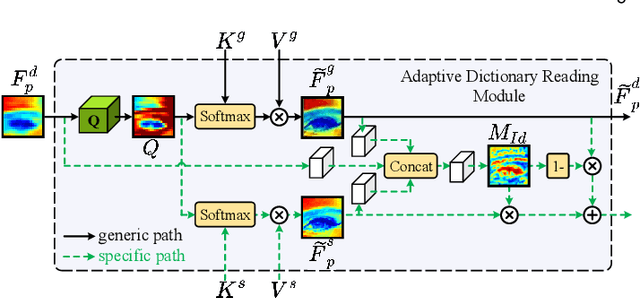
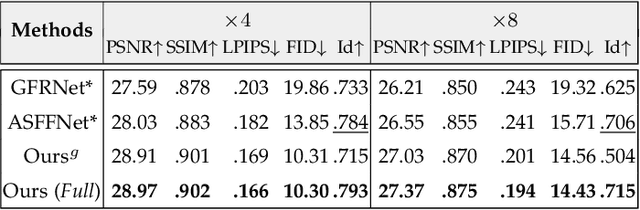
To improve the performance of blind face restoration, recent works mainly treat the two aspects, i.e., generic and specific restoration, separately. In particular, generic restoration attempts to restore the results through general facial structure prior, while on the one hand, cannot generalize to real-world degraded observations due to the limited capability of direct CNNs' mappings in learning blind restoration, and on the other hand, fails to exploit the identity-specific details. On the contrary, specific restoration aims to incorporate the identity features from the reference of the same identity, in which the requirement of proper reference severely limits the application scenarios. Generally, it is a challenging and intractable task to improve the photo-realistic performance of blind restoration and adaptively handle the generic and specific restoration scenarios with a single unified model. Instead of implicitly learning the mapping from a low-quality image to its high-quality counterpart, this paper suggests a DMDNet by explicitly memorizing the generic and specific features through dual dictionaries. First, the generic dictionary learns the general facial priors from high-quality images of any identity, while the specific dictionary stores the identity-belonging features for each person individually. Second, to handle the degraded input with or without specific reference, dictionary transform module is suggested to read the relevant details from the dual dictionaries which are subsequently fused into the input features. Finally, multi-scale dictionaries are leveraged to benefit the coarse-to-fine restoration. Moreover, a new high-quality dataset, termed CelebRef-HQ, is constructed to promote the exploration of specific face restoration in the high-resolution space.
Neural Implicit Representations for Physical Parameter Inference from a Single Video
Apr 29, 2022
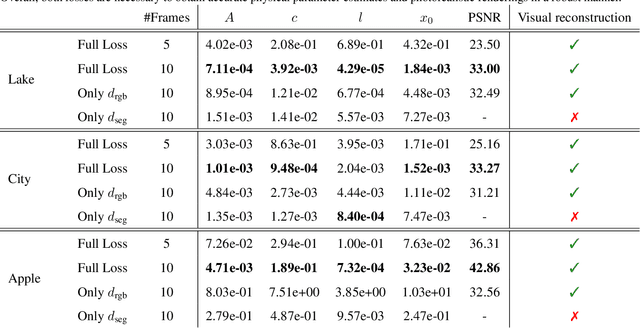
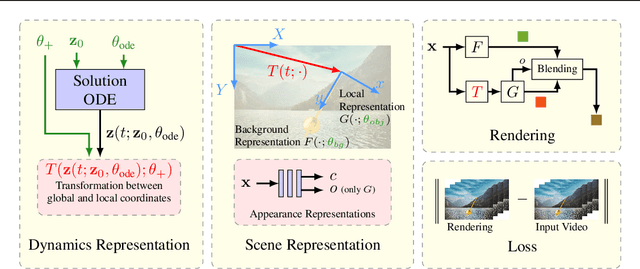

Neural networks have recently been used to analyze diverse physical systems and to identify the underlying dynamics. While existing methods achieve impressive results, they are limited by their strong demand for training data and their weak generalization abilities to out-of-distribution data. To overcome these limitations, in this work we propose to combine neural implicit representations for appearance modeling with neural ordinary differential equations (ODEs) for modelling physical phenomena to obtain a dynamic scene representation that can be identified directly from visual observations. Our proposed model combines several unique advantages: (i) Contrary to existing approaches that require large training datasets, we are able to identify physical parameters from only a single video. (ii) The use of neural implicit representations enables the processing of high-resolution videos and the synthesis of photo-realistic images. (iii) The embedded neural ODE has a known parametric form that allows for the identification of interpretable physical parameters, and (iv) long-term prediction in state space. (v) Furthermore, the photo-realistic rendering of novel scenes with modified physical parameters becomes possible.
Improved Wavelets for Image Compression from Unitary Circuits
Mar 04, 2022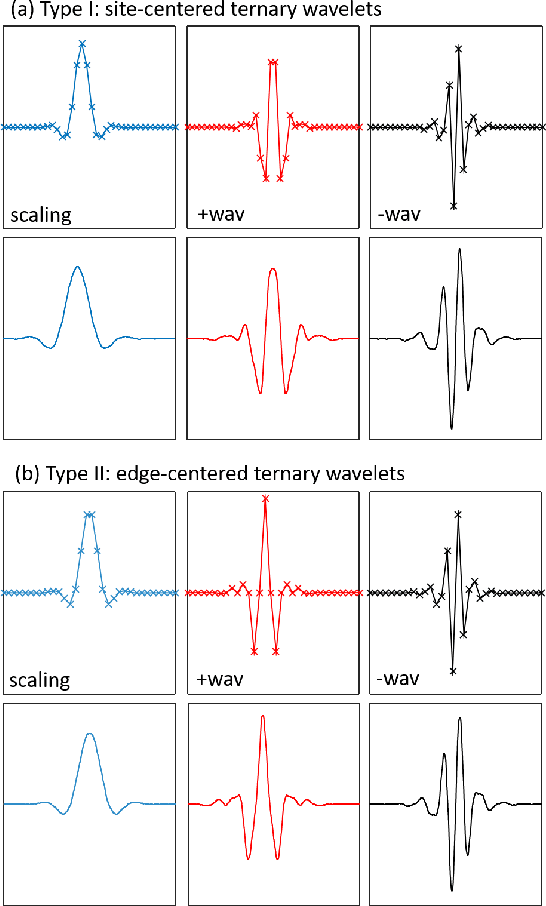
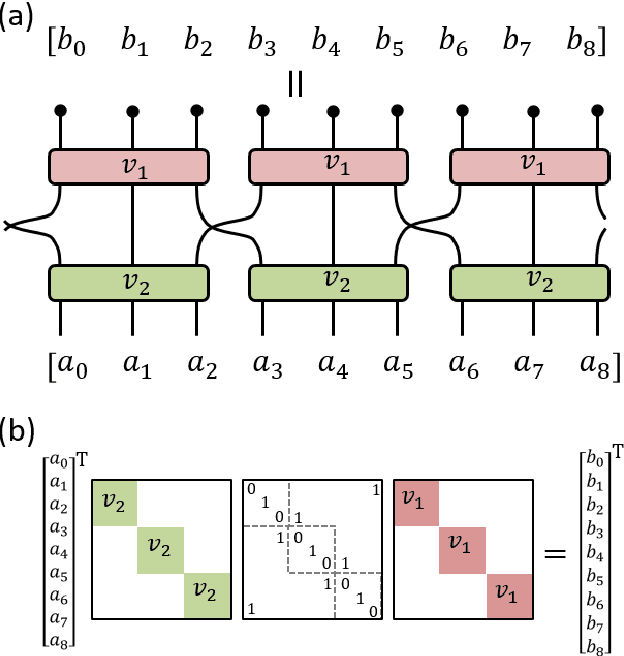
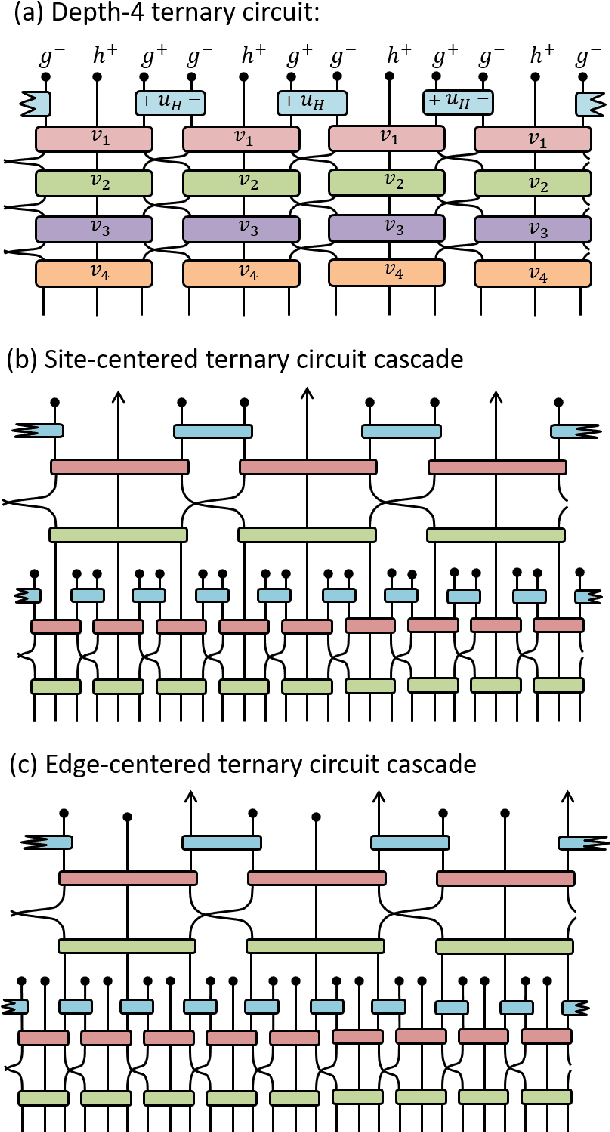
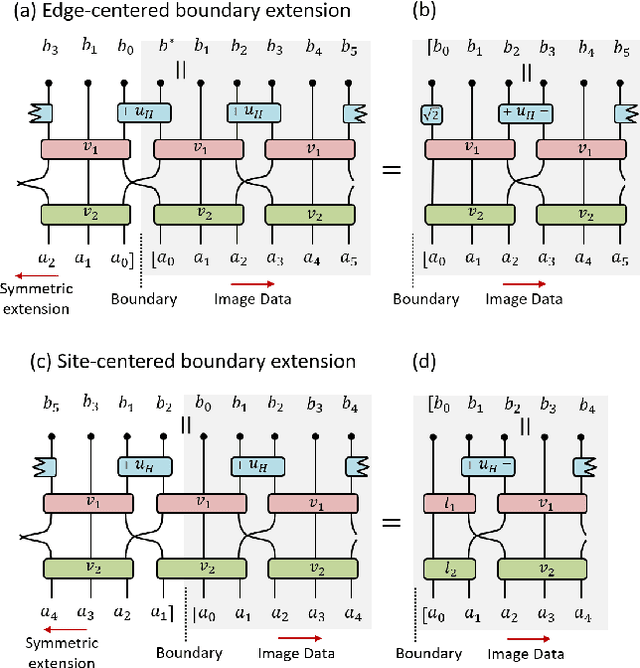
We benchmark the efficacy of several novel orthogonal, symmetric, dilation-3 wavelets, derived from a unitary circuit based construction, towards image compression. The performance of these wavelets is compared across several photo databases against the CDF-9/7 wavelets in terms of the minimum number of non-zero wavelet coefficients needed to obtain a specified image quality, as measured by the multi-scale structural similarity index (MS-SSIM). The new wavelets are found to consistently offer better compression efficiency than the CDF-9/7 wavelets across a broad range of image resolutions and quality requirements, averaging 7-8% improved compression efficiency on high-resolution photo images when high-quality (MS-SSIM = 0.99) is required.
DTA: Physical Camouflage Attacks using Differentiable Transformation Network
Mar 18, 2022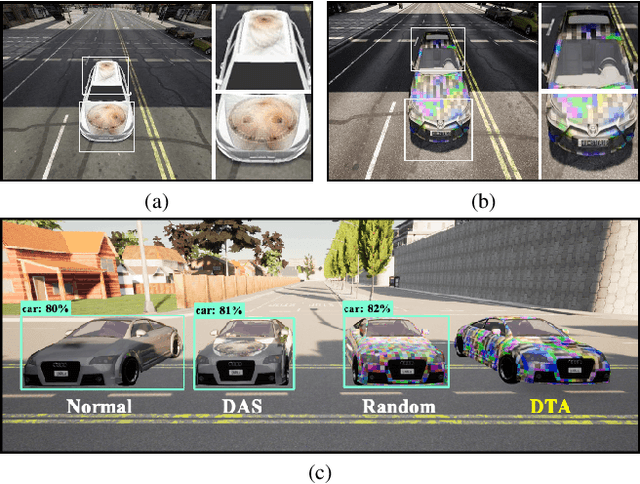
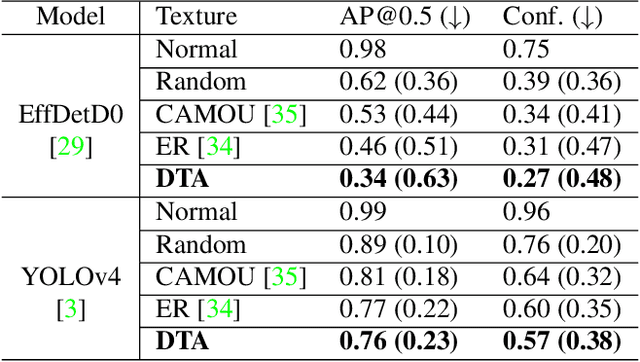
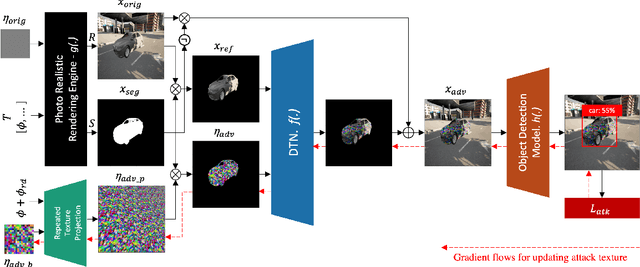
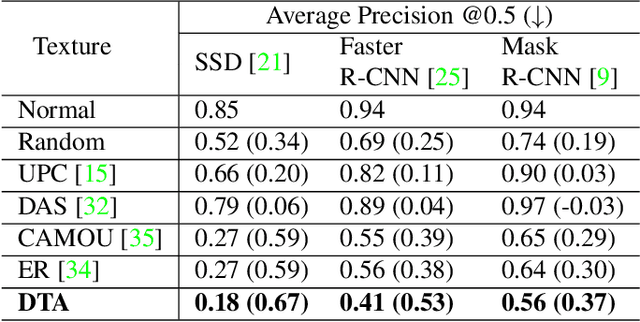
To perform adversarial attacks in the physical world, many studies have proposed adversarial camouflage, a method to hide a target object by applying camouflage patterns on 3D object surfaces. For obtaining optimal physical adversarial camouflage, previous studies have utilized the so-called neural renderer, as it supports differentiability. However, existing neural renderers cannot fully represent various real-world transformations due to a lack of control of scene parameters compared to the legacy photo-realistic renderers. In this paper, we propose the Differentiable Transformation Attack (DTA), a framework for generating a robust physical adversarial pattern on a target object to camouflage it against object detection models with a wide range of transformations. It utilizes our novel Differentiable Transformation Network (DTN), which learns the expected transformation of a rendered object when the texture is changed while preserving the original properties of the target object. Using our attack framework, an adversary can gain both the advantages of the legacy photo-realistic renderers including various physical-world transformations and the benefit of white-box access by offering differentiability. Our experiments show that our camouflaged 3D vehicles can successfully evade state-of-the-art object detection models in the photo-realistic environment (i.e., CARLA on Unreal Engine). Furthermore, our demonstration on a scaled Tesla Model 3 proves the applicability and transferability of our method to the real world.
Improving 3D-aware Image Synthesis with A Geometry-aware Discriminator
Sep 30, 2022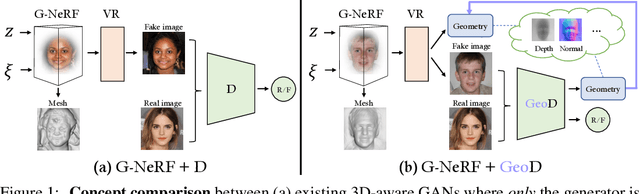
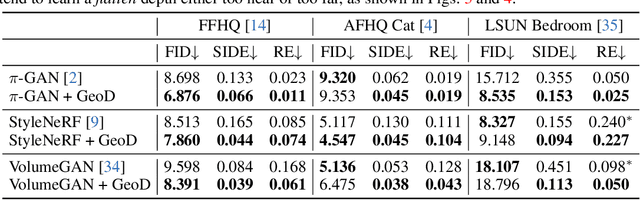

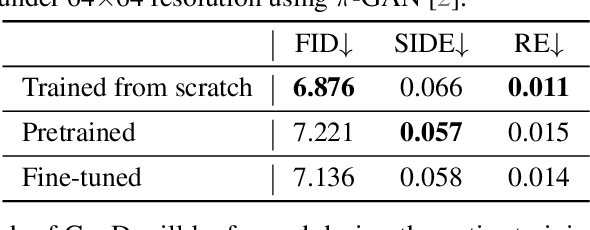
3D-aware image synthesis aims at learning a generative model that can render photo-realistic 2D images while capturing decent underlying 3D shapes. A popular solution is to adopt the generative adversarial network (GAN) and replace the generator with a 3D renderer, where volume rendering with neural radiance field (NeRF) is commonly used. Despite the advancement of synthesis quality, existing methods fail to obtain moderate 3D shapes. We argue that, considering the two-player game in the formulation of GANs, only making the generator 3D-aware is not enough. In other words, displacing the generative mechanism only offers the capability, but not the guarantee, of producing 3D-aware images, because the supervision of the generator primarily comes from the discriminator. To address this issue, we propose GeoD through learning a geometry-aware discriminator to improve 3D-aware GANs. Concretely, besides differentiating real and fake samples from the 2D image space, the discriminator is additionally asked to derive the geometry information from the inputs, which is then applied as the guidance of the generator. Such a simple yet effective design facilitates learning substantially more accurate 3D shapes. Extensive experiments on various generator architectures and training datasets verify the superiority of GeoD over state-of-the-art alternatives. Moreover, our approach is registered as a general framework such that a more capable discriminator (i.e., with a third task of novel view synthesis beyond domain classification and geometry extraction) can further assist the generator with a better multi-view consistency.
NeRF-SOS: Any-View Self-supervised Object Segmentation from Complex Real-World Scenes
Sep 22, 2022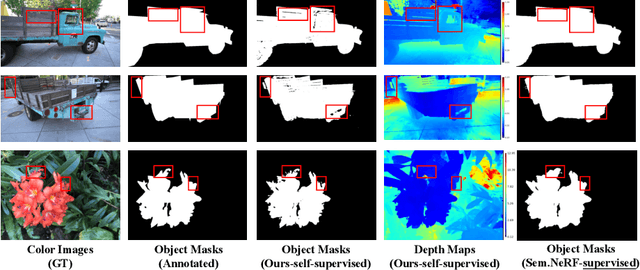
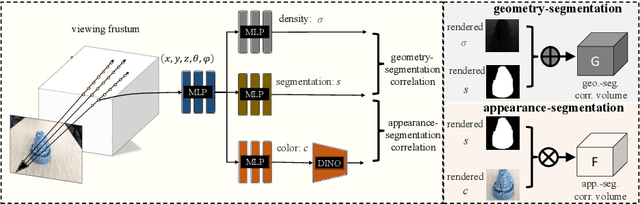
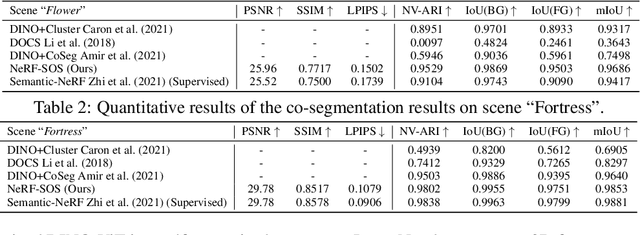

Neural volumetric representations have shown the potential that Multi-layer Perceptrons (MLPs) can be optimized with multi-view calibrated images to represent scene geometry and appearance, without explicit 3D supervision. Object segmentation can enrich many downstream applications based on the learned radiance field. However, introducing hand-crafted segmentation to define regions of interest in a complex real-world scene is non-trivial and expensive as it acquires per view annotation. This paper carries out the exploration of self-supervised learning for object segmentation using NeRF for complex real-world scenes. Our framework, called NeRF with Self-supervised Object Segmentation NeRF-SOS, couples object segmentation and neural radiance field to segment objects in any view within a scene. By proposing a novel collaborative contrastive loss in both appearance and geometry levels, NeRF-SOS encourages NeRF models to distill compact geometry-aware segmentation clusters from their density fields and the self-supervised pre-trained 2D visual features. The self-supervised object segmentation framework can be applied to various NeRF models that both lead to photo-realistic rendering results and convincing segmentation maps for both indoor and outdoor scenarios. Extensive results on the LLFF, Tank & Temple, and BlendedMVS datasets validate the effectiveness of NeRF-SOS. It consistently surpasses other 2D-based self-supervised baselines and predicts finer semantics masks than existing supervised counterparts. Code is available at: https://github.com/VITA-Group/NeRF-SOS.
UAV-CROWD: Violent and non-violent crowd activity simulator from the perspective of UAV
Aug 13, 2022
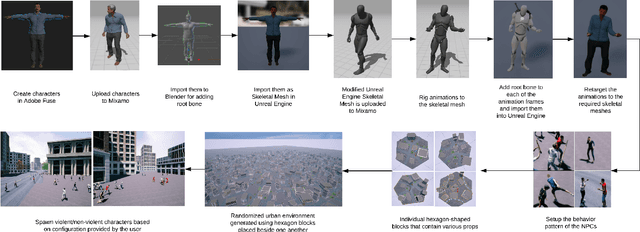
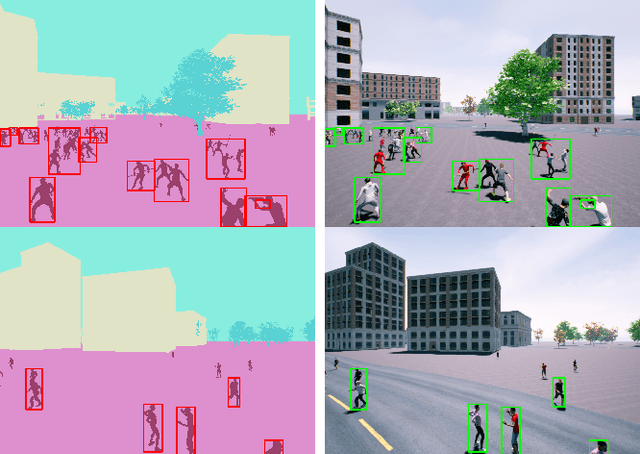
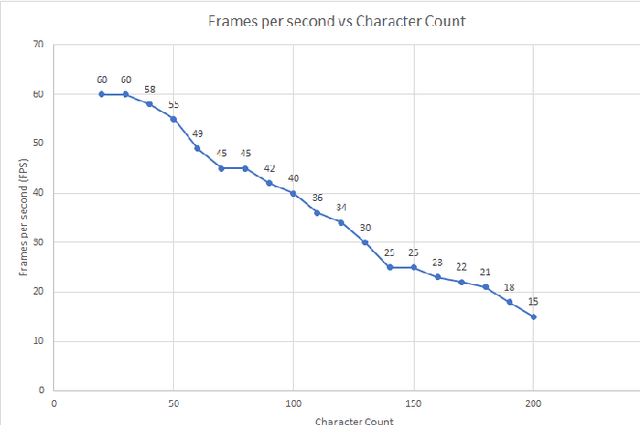
Unmanned Aerial Vehicle (UAV) has gained significant traction in the recent years, particularly the context of surveillance. However, video datasets that capture violent and non-violent human activity from aerial point-of-view is scarce. To address this issue, we propose a novel, baseline simulator which is capable of generating sequences of photo-realistic synthetic images of crowds engaging in various activities that can be categorized as violent or non-violent. The crowd groups are annotated with bounding boxes that are automatically computed using semantic segmentation. Our simulator is capable of generating large, randomized urban environments and is able to maintain an average of 25 frames per second on a mid-range computer with 150 concurrent crowd agents interacting with each other. We also show that when synthetic data from the proposed simulator is augmented with real world data, binary video classification accuracy is improved by 5% on average across two different models.
A Portable Multiscopic Camera for Novel View and Time Synthesis in Dynamic Scenes
Aug 30, 2022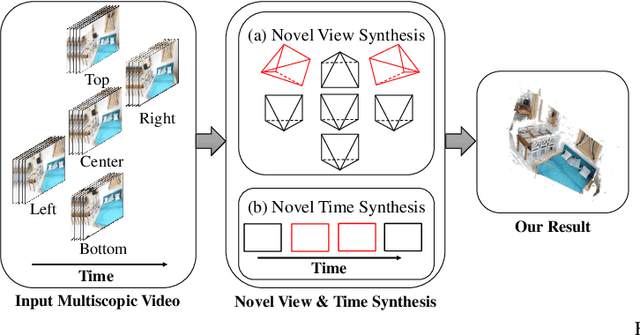
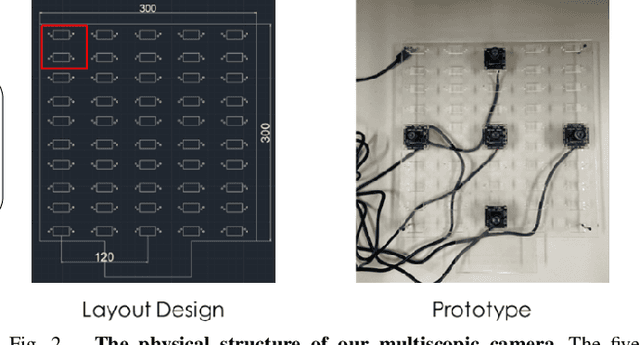
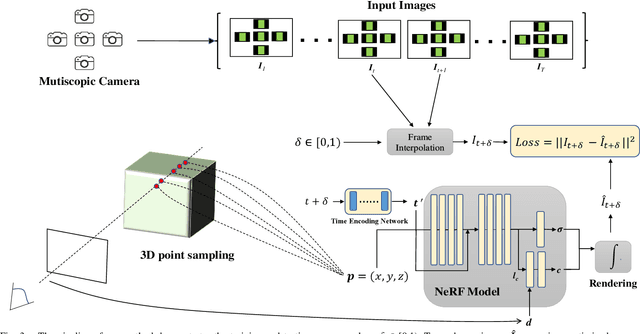

We present a portable multiscopic camera system with a dedicated model for novel view and time synthesis in dynamic scenes. Our goal is to render high-quality images for a dynamic scene from any viewpoint at any time using our portable multiscopic camera. To achieve such novel view and time synthesis, we develop a physical multiscopic camera equipped with five cameras to train a neural radiance field (NeRF) in both time and spatial domains for dynamic scenes. Our model maps a 6D coordinate (3D spatial position, 1D temporal coordinate, and 2D viewing direction) to view-dependent and time-varying emitted radiance and volume density. Volume rendering is applied to render a photo-realistic image at a specified camera pose and time. To improve the robustness of our physical camera, we propose a camera parameter optimization module and a temporal frame interpolation module to promote information propagation across time. We conduct experiments on both real-world and synthetic datasets to evaluate our system, and the results show that our approach outperforms alternative solutions qualitatively and quantitatively. Our code and dataset are available at https://yuenfuilau.github.io.
NeRF-SOS: Any-View Self-supervised Object Segmentation on Complex Scenes
Sep 23, 2022Neural volumetric representations have shown the potential that Multi-layer Perceptrons (MLPs) can be optimized with multi-view calibrated images to represent scene geometry and appearance, without explicit 3D supervision. Object segmentation can enrich many downstream applications based on the learned radiance field. However, introducing hand-crafted segmentation to define regions of interest in a complex real-world scene is non-trivial and expensive as it acquires per view annotation. This paper carries out the exploration of self-supervised learning for object segmentation using NeRF for complex real-world scenes. Our framework, called NeRF with Self-supervised Object Segmentation NeRF-SOS, couples object segmentation and neural radiance field to segment objects in any view within a scene. By proposing a novel collaborative contrastive loss in both appearance and geometry levels, NeRF-SOS encourages NeRF models to distill compact geometry-aware segmentation clusters from their density fields and the self-supervised pre-trained 2D visual features. The self-supervised object segmentation framework can be applied to various NeRF models that both lead to photo-realistic rendering results and convincing segmentation maps for both indoor and outdoor scenarios. Extensive results on the LLFF, Tank & Temple, and BlendedMVS datasets validate the effectiveness of NeRF-SOS. It consistently surpasses other 2D-based self-supervised baselines and predicts finer semantics masks than existing supervised counterparts. Please refer to the video on our project page for more details:https://zhiwenfan.github.io/NeRF-SOS.