 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
BLADERUNNER: Rapid Countermeasure for Synthetic (AI-Generated) StyleGAN Faces
Oct 14, 2022
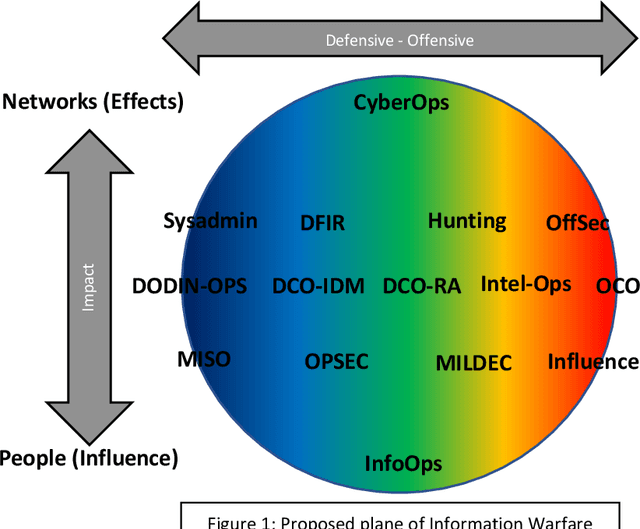
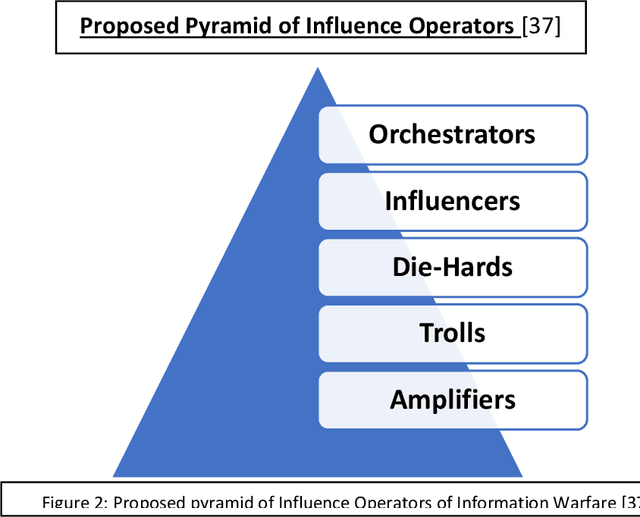


StyleGAN is the open-sourced TensorFlow implementation made by NVIDIA. It has revolutionized high quality facial image generation. However, this democratization of Artificial Intelligence / Machine Learning (AI/ML) algorithms has enabled hostile threat actors to establish cyber personas or sock-puppet accounts in social media platforms. These ultra-realistic synthetic faces. This report surveys the relevance of AI/ML with respect to Cyber & Information Operations. The proliferation of AI/ML algorithms has led to a rise in DeepFakes and inauthentic social media accounts. Threats are analyzed within the Strategic and Operational Environments. Existing methods of identifying synthetic faces exists, but they rely on human beings to visually scrutinize each photo for inconsistencies. However, through use of the DLIB 68-landmark pre-trained file, it is possible to analyze and detect synthetic faces by exploiting repetitive behaviors in StyleGAN images. Project Blade Runner encompasses two scripts necessary to counter StyleGAN images. Through PapersPlease acting as the analyzer, it is possible to derive indicators-of-attack (IOA) from scraped image samples. These IOAs can be fed back into Among_Us acting as the detector to identify synthetic faces from live operational samples. The opensource copy of Blade Runner may lack additional unit tests and some functionality, but the open-source copy is a redacted version, far leaner, better optimized, and a proof-of-concept for the information security community. The desired end-state will be to incrementally add automation to stay on-par with its closed-source predecessor.
Perception-Distortion Trade-off in the SR Space Spanned by Flow Models
Sep 18, 2022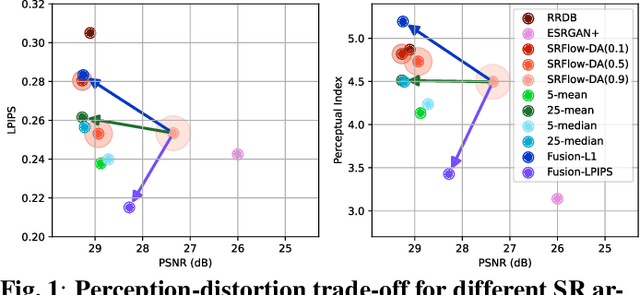
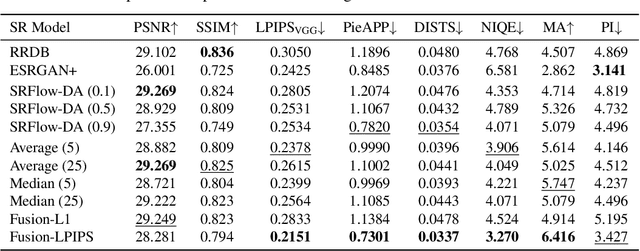


Flow-based generative super-resolution (SR) models learn to produce a diverse set of feasible SR solutions, called the SR space. Diversity of SR solutions increases with the temperature ($\tau$) of latent variables, which introduces random variations of texture among sample solutions, resulting in visual artifacts and low fidelity. In this paper, we present a simple but effective image ensembling/fusion approach to obtain a single SR image eliminating random artifacts and improving fidelity without significantly compromising perceptual quality. We achieve this by benefiting from a diverse set of feasible photo-realistic solutions in the SR space spanned by flow models. We propose different image ensembling and fusion strategies which offer multiple paths to move sample solutions in the SR space to more desired destinations in the perception-distortion plane in a controllable manner depending on the fidelity vs. perceptual quality requirements of the task at hand. Experimental results demonstrate that our image ensembling/fusion strategy achieves more promising perception-distortion trade-off compared to sample SR images produced by flow models and adversarially trained models in terms of both quantitative metrics and visual quality.
What does a platypus look like? Generating customized prompts for zero-shot image classification
Sep 07, 2022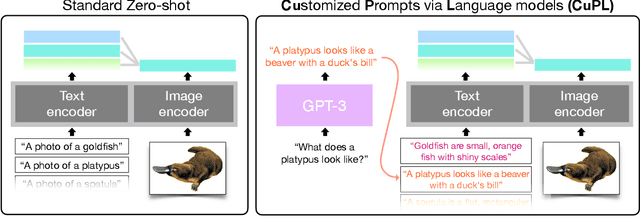
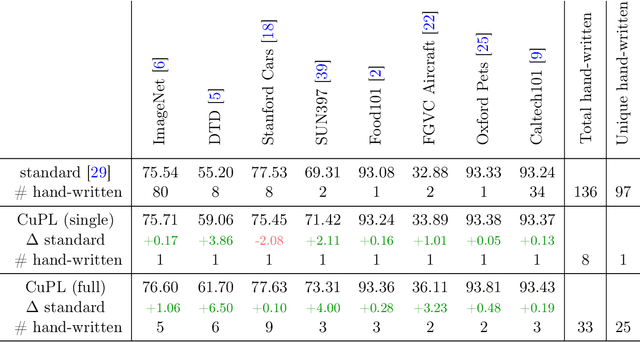
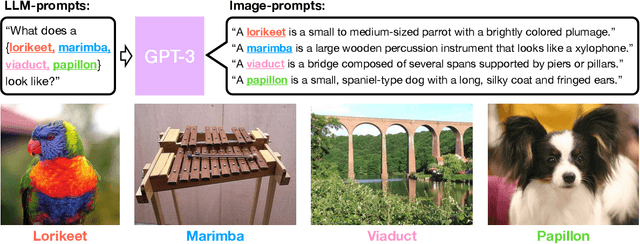
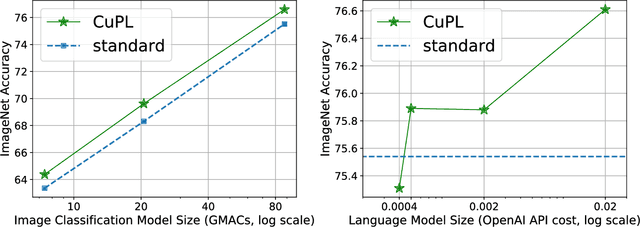
Open vocabulary models are a promising new paradigm for image classification. Unlike traditional classification models, open vocabulary models classify among any arbitrary set of categories specified with natural language during inference. This natural language, called "prompts", typically consists of a set of hand-written templates (e.g., "a photo of a {}") which are completed with each of the category names. This work introduces a simple method to generate higher accuracy prompts, without using explicit knowledge of the image domain and with far fewer hand-constructed sentences. To achieve this, we combine open vocabulary models with large language models (LLMs) to create Customized Prompts via Language models (CuPL, pronounced "couple"). In particular, we leverage the knowledge contained in LLMs in order to generate many descriptive sentences that are customized for each object category. We find that this straightforward and general approach improves accuracy on a range of zero-shot image classification benchmarks, including over one percentage point gain on ImageNet. Finally, this method requires no additional training and remains completely zero-shot. Code is available at https://github.com/sarahpratt/CuPL.
Neural Camera Models
Aug 27, 2022
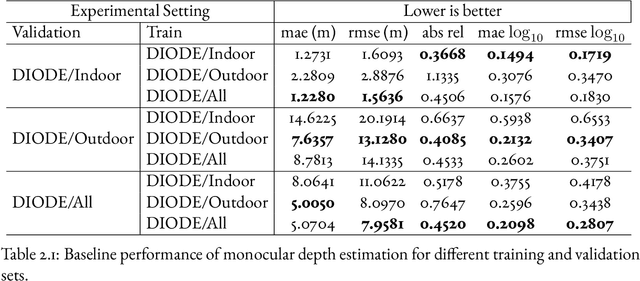
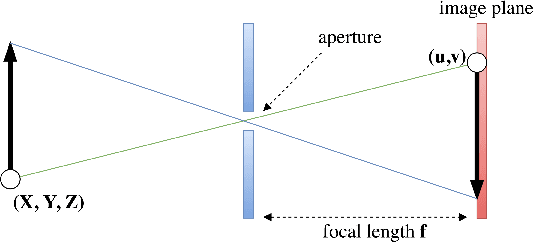

Modern computer vision has moved beyond the domain of internet photo collections and into the physical world, guiding camera-equipped robots and autonomous cars through unstructured environments. To enable these embodied agents to interact with real-world objects, cameras are increasingly being used as depth sensors, reconstructing the environment for a variety of downstream reasoning tasks. Machine-learning-aided depth perception, or depth estimation, predicts for each pixel in an image the distance to the imaged scene point. While impressive strides have been made in depth estimation, significant challenges remain: (1) ground truth depth labels are difficult and expensive to collect at scale, (2) camera information is typically assumed to be known, but is often unreliable and (3) restrictive camera assumptions are common, even though a great variety of camera types and lenses are used in practice. In this thesis, we focus on relaxing these assumptions, and describe contributions toward the ultimate goal of turning cameras into truly generic depth sensors.
NeRF-SOS: Any-View Self-supervised Object Segmentation on Complex Scenes
Oct 12, 2022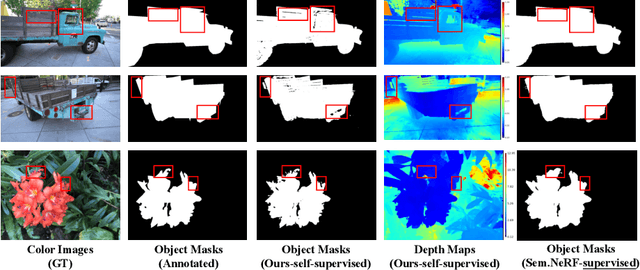
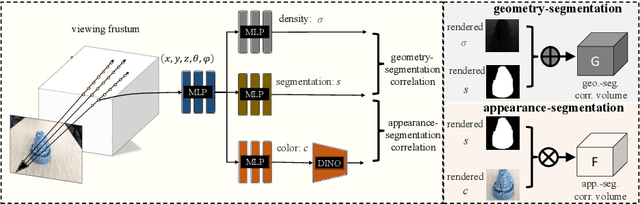
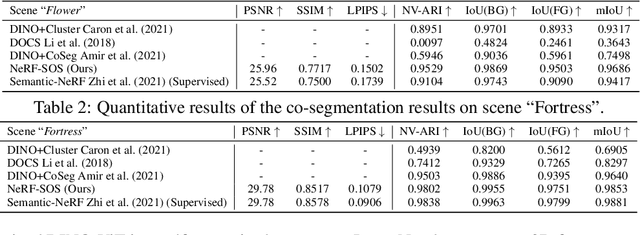

Neural volumetric representations have shown the potential that Multi-layer Perceptrons (MLPs) can be optimized with multi-view calibrated images to represent scene geometry and appearance, without explicit 3D supervision. Object segmentation can enrich many downstream applications based on the learned radiance field. However, introducing hand-crafted segmentation to define regions of interest in a complex real-world scene is non-trivial and expensive as it acquires per view annotation. This paper carries out the exploration of self-supervised learning for object segmentation using NeRF for complex real-world scenes. Our framework, called NeRF with Self-supervised Object Segmentation NeRF-SOS, couples object segmentation and neural radiance field to segment objects in any view within a scene. By proposing a novel collaborative contrastive loss in both appearance and geometry levels, NeRF-SOS encourages NeRF models to distill compact geometry-aware segmentation clusters from their density fields and the self-supervised pre-trained 2D visual features. The self-supervised object segmentation framework can be applied to various NeRF models that both lead to photo-realistic rendering results and convincing segmentation maps for both indoor and outdoor scenarios. Extensive results on the LLFF, Tank & Temple, and BlendedMVS datasets validate the effectiveness of NeRF-SOS. It consistently surpasses other 2D-based self-supervised baselines and predicts finer semantics masks than existing supervised counterparts. Please refer to the video on our project page for more details:https://zhiwenfan.github.io/NeRF-SOS.
Old Photo Restoration via Deep Latent Space Translation
Sep 14, 2020
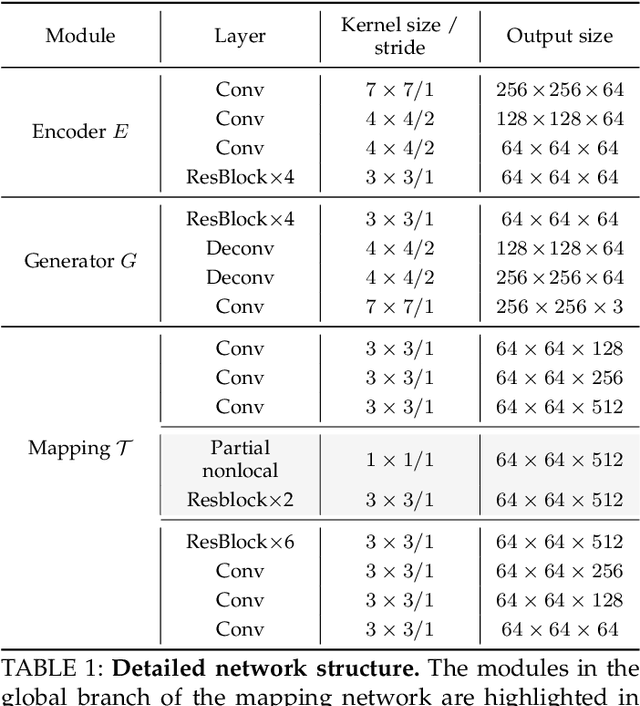
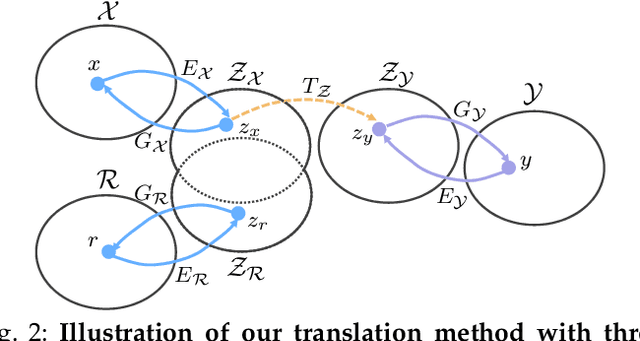
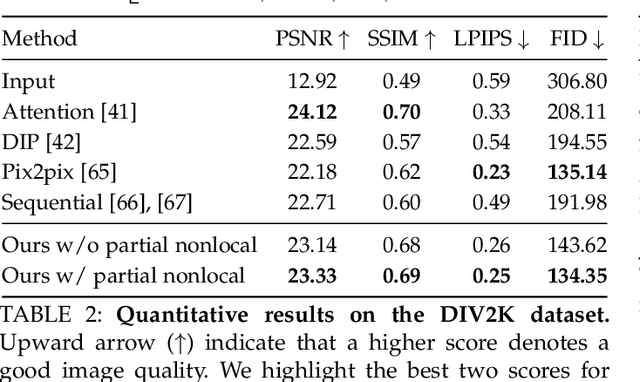
We propose to restore old photos that suffer from severe degradation through a deep learning approach. Unlike conventional restoration tasks that can be solved through supervised learning, the degradation in real photos is complex and the domain gap between synthetic images and real old photos makes the network fail to generalize. Therefore, we propose a novel triplet domain translation network by leveraging real photos along with massive synthetic image pairs. Specifically, we train two variational autoencoders (VAEs) to respectively transform old photos and clean photos into two latent spaces. And the translation between these two latent spaces is learned with synthetic paired data. This translation generalizes well to real photos because the domain gap is closed in the compact latent space. Besides, to address multiple degradations mixed in one old photo, we design a global branch with apartial nonlocal block targeting to the structured defects, such as scratches and dust spots, and a local branch targeting to the unstructured defects, such as noises and blurriness. Two branches are fused in the latent space, leading to improved capability to restore old photos from multiple defects. Furthermore, we apply another face refinement network to recover fine details of faces in the old photos, thus ultimately generating photos with enhanced perceptual quality. With comprehensive experiments, the proposed pipeline demonstrates superior performance over state-of-the-art methods as well as existing commercial tools in terms of visual quality for old photos restoration.
Fill in Fabrics: Body-Aware Self-Supervised Inpainting for Image-Based Virtual Try-On
Oct 03, 2022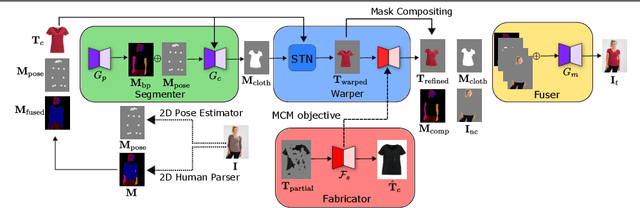
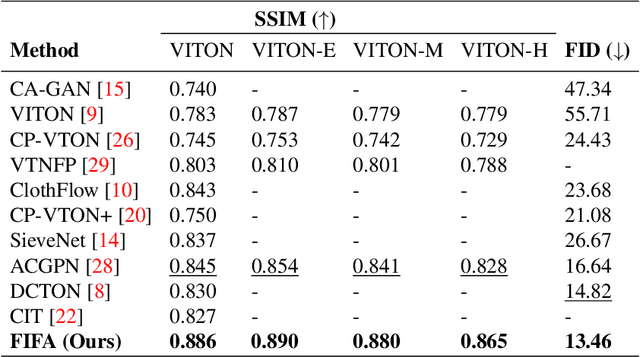


Previous virtual try-on methods usually focus on aligning a clothing item with a person, limiting their ability to exploit the complex pose, shape and skin color of the person, as well as the overall structure of the clothing, which is vital to photo-realistic virtual try-on. To address this potential weakness, we propose a fill in fabrics (FIFA) model, a self-supervised conditional generative adversarial network based framework comprised of a Fabricator and a unified virtual try-on pipeline with a Segmenter, Warper and Fuser. The Fabricator aims to reconstruct the clothing image when provided with a masked clothing as input, and learns the overall structure of the clothing by filling in fabrics. A virtual try-on pipeline is then trained by transferring the learned representations from the Fabricator to Warper in an effort to warp and refine the target clothing. We also propose to use a multi-scale structural constraint to enforce global context at multiple scales while warping the target clothing to better fit the pose and shape of the person. Extensive experiments demonstrate that our FIFA model achieves state-of-the-art results on the standard VITON dataset for virtual try-on of clothing items, and is shown to be effective at handling complex poses and retaining the texture and embroidery of the clothing.
A comprehensive survey on semantic facial attribute editing using generative adversarial networks
May 21, 2022
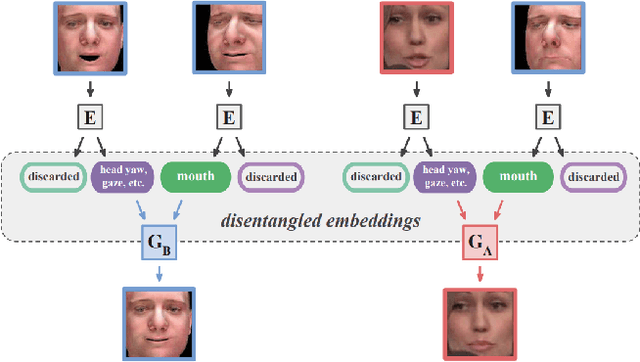
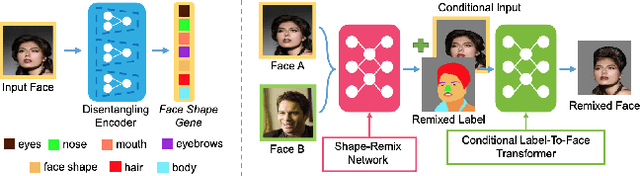
Generating random photo-realistic images has experienced tremendous growth during the past few years due to the advances of the deep convolutional neural networks and generative models. Among different domains, face photos have received a great deal of attention and a large number of face generation and manipulation models have been proposed. Semantic facial attribute editing is the process of varying the values of one or more attributes of a face image while the other attributes of the image are not affected. The requested modifications are provided as an attribute vector or in the form of driving face image and the whole process is performed by the corresponding models. In this paper, we survey the recent works and advances in semantic facial attribute editing. We cover all related aspects of these models including the related definitions and concepts, architectures, loss functions, datasets, evaluation metrics, and applications. Based on their architectures, the state-of-the-art models are categorized and studied as encoder-decoder, image-to-image, and photo-guided models. The challenges and restrictions of the current state-of-the-art methods are discussed as well.
Deep Sketch-Photo Face Recognition Assisted by Facial Attributes
Jul 31, 2018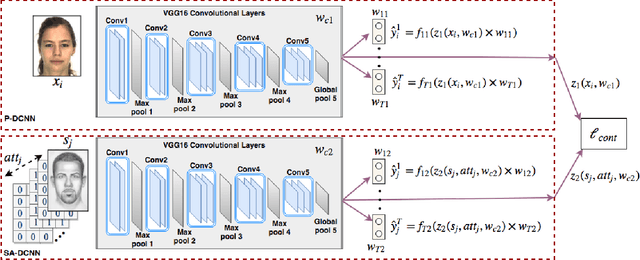

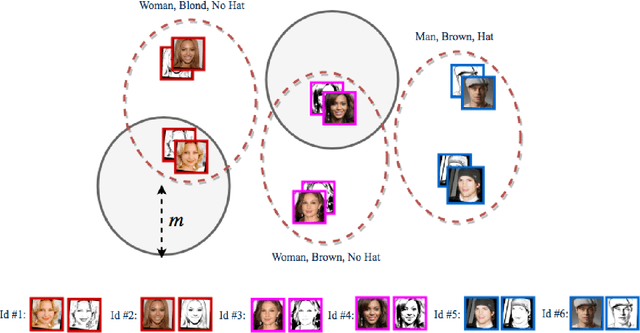
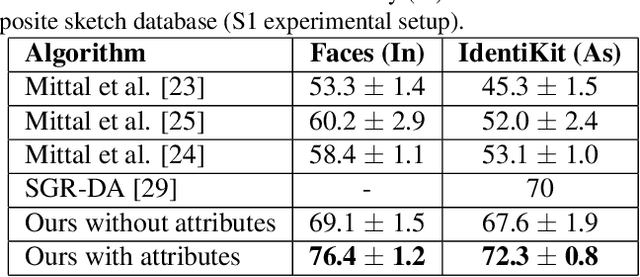
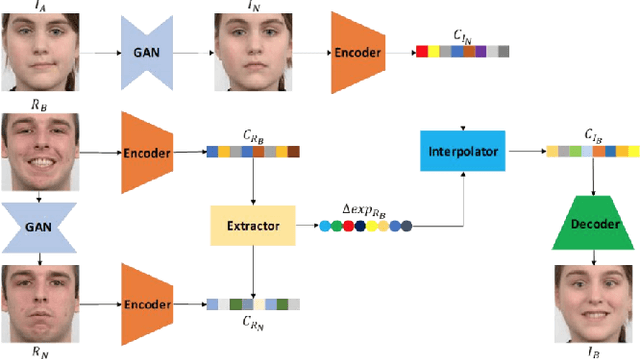
In this paper, we present a deep coupled framework to address the problem of matching sketch image against a gallery of mugshots. Face sketches have the essential in- formation about the spatial topology and geometric details of faces while missing some important facial attributes such as ethnicity, hair, eye, and skin color. We propose a cou- pled deep neural network architecture which utilizes facial attributes in order to improve the sketch-photo recognition performance. The proposed Attribute-Assisted Deep Con- volutional Neural Network (AADCNN) method exploits the facial attributes and leverages the loss functions from the facial attributes identification and face verification tasks in order to learn rich discriminative features in a common em- bedding subspace. The facial attribute identification task increases the inter-personal variations by pushing apart the embedded features extracted from individuals with differ- ent facial attributes, while the verification task reduces the intra-personal variations by pulling together all the fea- tures that are related to one person. The learned discrim- inative features can be well generalized to new identities not seen in the training data. The proposed architecture is able to make full use of the sketch and complementary fa- cial attribute information to train a deep model compared to the conventional sketch-photo recognition methods. Exten- sive experiments are performed on composite (E-PRIP) and semi-forensic (IIIT-D semi-forensic) datasets. The results show the superiority of our method compared to the state- of-the-art models in sketch-photo recognition algorithms
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
Aug 13, 2020
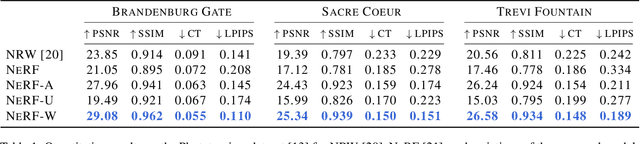

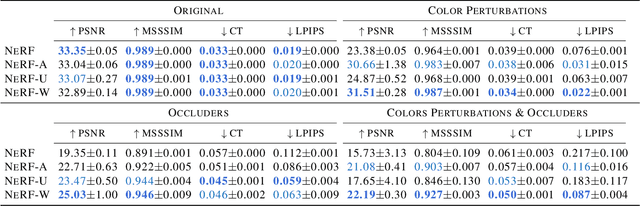
We present a learning-based method for synthesizing novel views of complex outdoor scenes using only unstructured collections of in-the-wild photographs. We build on neural radiance fields (NeRF), which uses the weights of a multilayer perceptron to implicitly model the volumetric density and color of a scene. While NeRF works well on images of static subjects captured under controlled settings, it is incapable of modeling many ubiquitous, real-world phenomena in uncontrolled images, such as variable illumination or transient occluders. In this work, we introduce a series of extensions to NeRF to address these issues, thereby allowing for accurate reconstructions from unstructured image collections taken from the internet. We apply our system, which we dub NeRF-W, to internet photo collections of famous landmarks, thereby producing photorealistic, spatially consistent scene representations despite unknown and confounding factors, resulting in significant improvement over the state of the art.