 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Blind Super-Resolution for Remote Sensing Images via Conditional Stochastic Normalizing Flows
Oct 14, 2022

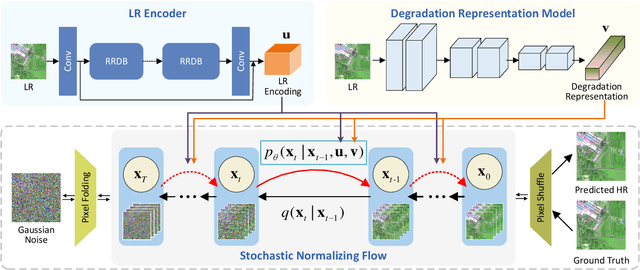
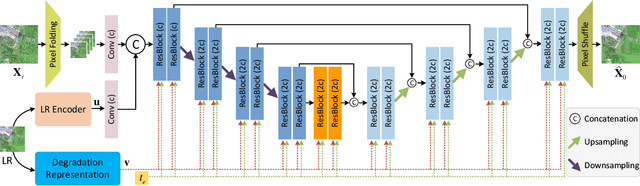
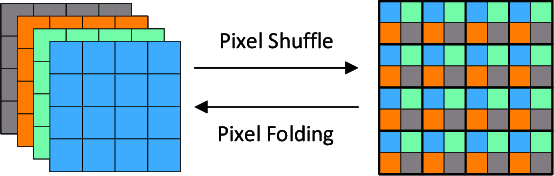
Remote sensing images (RSIs) in real scenes may be disturbed by multiple factors such as optical blur, undersampling, and additional noise, resulting in complex and diverse degradation models. At present, the mainstream SR algorithms only consider a single and fixed degradation (such as bicubic interpolation) and cannot flexibly handle complex degradations in real scenes. Therefore, designing a super-resolution (SR) model that can cope with various degradations is gradually attracting the attention of researchers. Some studies first estimate the degradation kernels and then perform degradation-adaptive SR but face the problems of estimation error amplification and insufficient high-frequency details in the results. Although blind SR algorithms based on generative adversarial networks (GAN) have greatly improved visual quality, they still suffer from pseudo-texture, mode collapse, and poor training stability. In this article, we propose a novel blind SR framework based on the stochastic normalizing flow (BlindSRSNF) to address the above problems. BlindSRSNF learns the conditional probability distribution over the high-resolution image space given a low-resolution (LR) image by explicitly optimizing the variational bound on the likelihood. BlindSRSNF is easy to train and can generate photo-realistic SR results that outperform GAN-based models. Besides, we introduce a degradation representation strategy based on contrastive learning to avoid the error amplification problem caused by the explicit degradation estimation. Comprehensive experiments show that the proposed algorithm can obtain SR results with excellent visual perception quality on both simulated LR and real-world RSIs.
BLADERUNNER: Rapid Countermeasure for Synthetic (AI-Generated) StyleGAN Faces
Oct 14, 2022
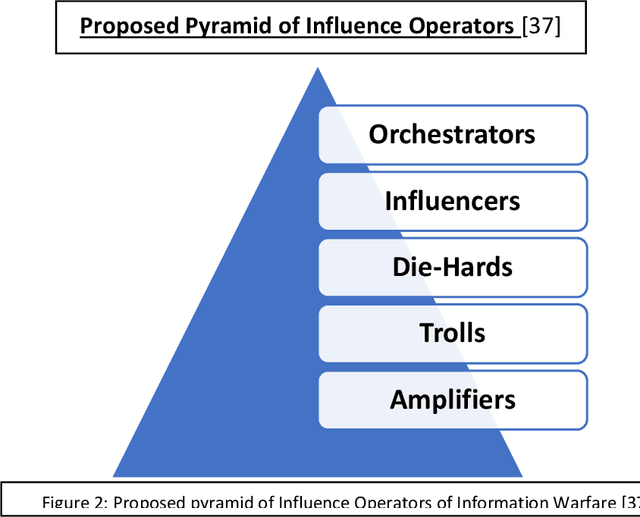


StyleGAN is the open-sourced TensorFlow implementation made by NVIDIA. It has revolutionized high quality facial image generation. However, this democratization of Artificial Intelligence / Machine Learning (AI/ML) algorithms has enabled hostile threat actors to establish cyber personas or sock-puppet accounts in social media platforms. These ultra-realistic synthetic faces. This report surveys the relevance of AI/ML with respect to Cyber & Information Operations. The proliferation of AI/ML algorithms has led to a rise in DeepFakes and inauthentic social media accounts. Threats are analyzed within the Strategic and Operational Environments. Existing methods of identifying synthetic faces exists, but they rely on human beings to visually scrutinize each photo for inconsistencies. However, through use of the DLIB 68-landmark pre-trained file, it is possible to analyze and detect synthetic faces by exploiting repetitive behaviors in StyleGAN images. Project Blade Runner encompasses two scripts necessary to counter StyleGAN images. Through PapersPlease acting as the analyzer, it is possible to derive indicators-of-attack (IOA) from scraped image samples. These IOAs can be fed back into Among_Us acting as the detector to identify synthetic faces from live operational samples. The opensource copy of Blade Runner may lack additional unit tests and some functionality, but the open-source copy is a redacted version, far leaner, better optimized, and a proof-of-concept for the information security community. The desired end-state will be to incrementally add automation to stay on-par with its closed-source predecessor.
Predicting and Attending to Damaging Collisions for Placing Everyday Objects in Photo-Realistic Simulations
Feb 12, 2021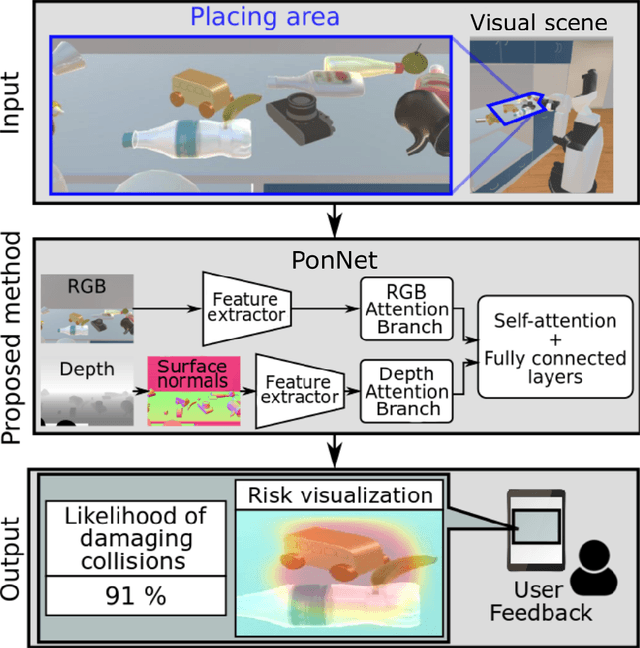


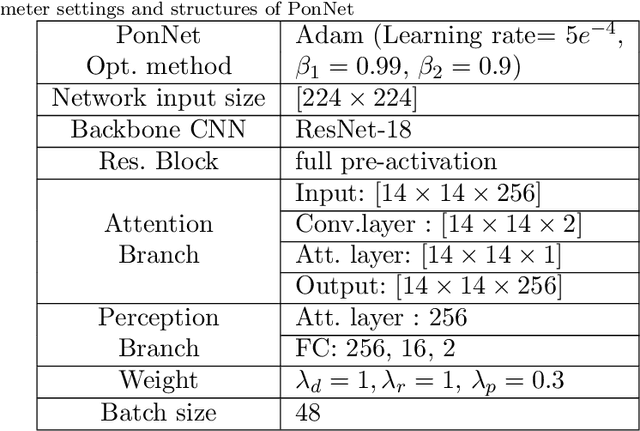
Placing objects is a fundamental task for domestic service robots (DSRs). Thus, inferring the collision-risk before a placing motion is crucial for achieving the requested task. This problem is particularly challenging because it is necessary to predict what happens if an object is placed in a cluttered designated area. We show that a rule-based approach that uses plane detection, to detect free areas, performs poorly. To address this, we develop PonNet, which has multimodal attention branches and a self-attention mechanism to predict damaging collisions, based on RGBD images. Our method can visualize the risk of damaging collisions, which is convenient because it enables the user to understand the risk. For this purpose, we build and publish an original dataset that contains 12,000 photo-realistic images of specific placing areas, with daily life objects, in home environments. The experimental results show that our approach improves accuracy compared with the baseline methods.
Perception-Distortion Trade-off in the SR Space Spanned by Flow Models
Sep 18, 2022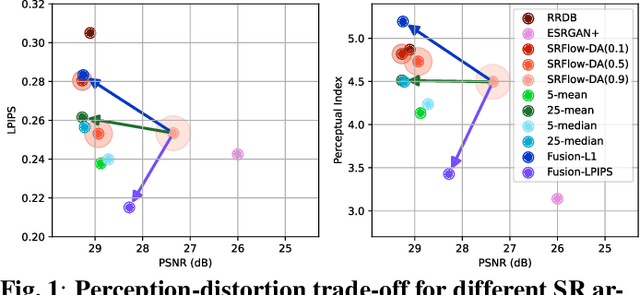
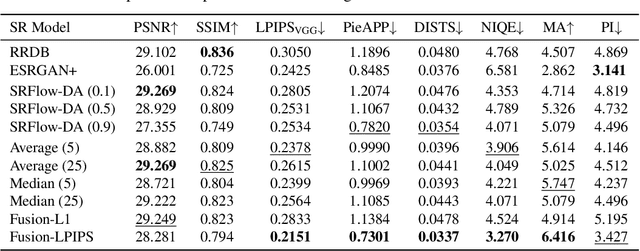


Flow-based generative super-resolution (SR) models learn to produce a diverse set of feasible SR solutions, called the SR space. Diversity of SR solutions increases with the temperature ($\tau$) of latent variables, which introduces random variations of texture among sample solutions, resulting in visual artifacts and low fidelity. In this paper, we present a simple but effective image ensembling/fusion approach to obtain a single SR image eliminating random artifacts and improving fidelity without significantly compromising perceptual quality. We achieve this by benefiting from a diverse set of feasible photo-realistic solutions in the SR space spanned by flow models. We propose different image ensembling and fusion strategies which offer multiple paths to move sample solutions in the SR space to more desired destinations in the perception-distortion plane in a controllable manner depending on the fidelity vs. perceptual quality requirements of the task at hand. Experimental results demonstrate that our image ensembling/fusion strategy achieves more promising perception-distortion trade-off compared to sample SR images produced by flow models and adversarially trained models in terms of both quantitative metrics and visual quality.
What does a platypus look like? Generating customized prompts for zero-shot image classification
Sep 07, 2022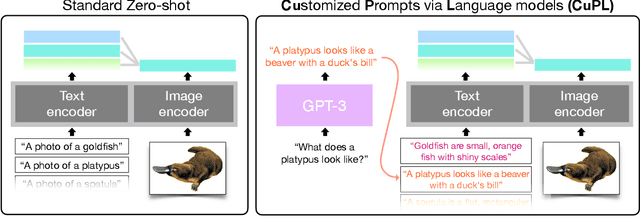
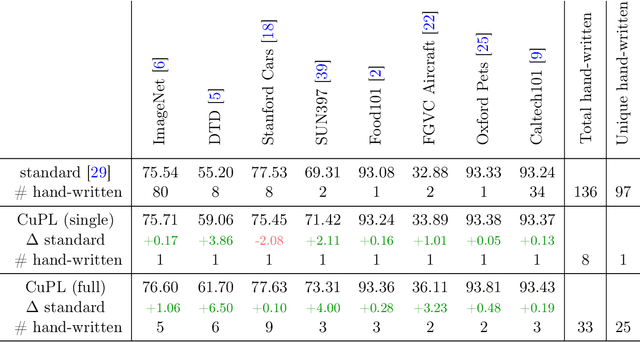
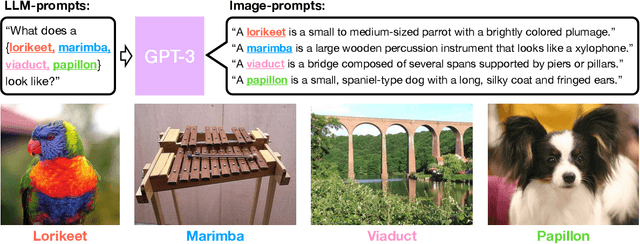
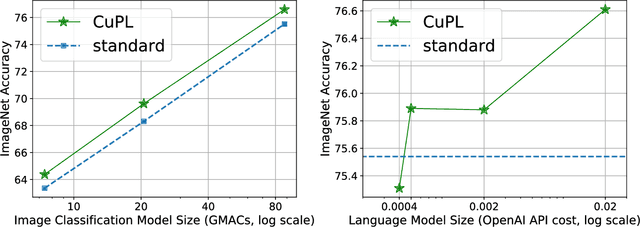
Open vocabulary models are a promising new paradigm for image classification. Unlike traditional classification models, open vocabulary models classify among any arbitrary set of categories specified with natural language during inference. This natural language, called "prompts", typically consists of a set of hand-written templates (e.g., "a photo of a {}") which are completed with each of the category names. This work introduces a simple method to generate higher accuracy prompts, without using explicit knowledge of the image domain and with far fewer hand-constructed sentences. To achieve this, we combine open vocabulary models with large language models (LLMs) to create Customized Prompts via Language models (CuPL, pronounced "couple"). In particular, we leverage the knowledge contained in LLMs in order to generate many descriptive sentences that are customized for each object category. We find that this straightforward and general approach improves accuracy on a range of zero-shot image classification benchmarks, including over one percentage point gain on ImageNet. Finally, this method requires no additional training and remains completely zero-shot. Code is available at https://github.com/sarahpratt/CuPL.
WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
Mar 03, 2018
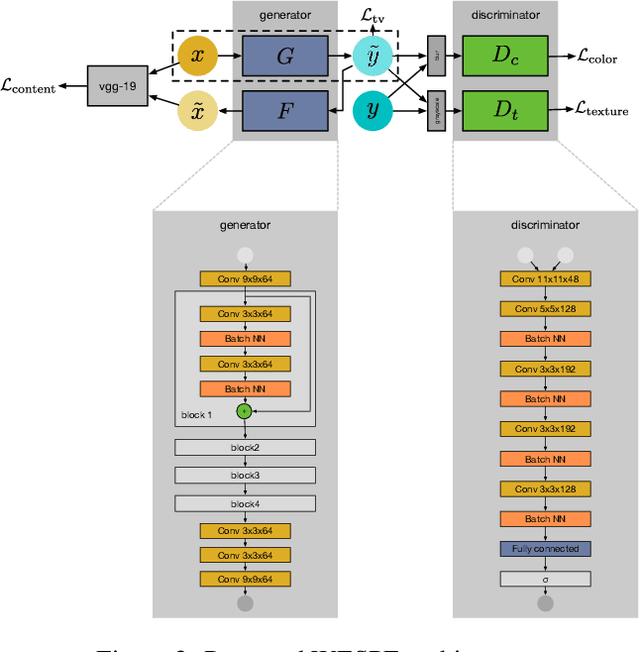


Low-end and compact mobile cameras demonstrate limited photo quality mainly due to space, hardware and budget constraints. In this work, we propose a deep learning solution that translates photos taken by cameras with limited capabilities into DSLR-quality photos automatically. We tackle this problem by introducing a weakly supervised photo enhancer (WESPE) - a novel image-to-image Generative Adversarial Network-based architecture. The proposed model is trained by under weak supervision: unlike previous works, there is no need for strong supervision in the form of a large annotated dataset of aligned original/enhanced photo pairs. The sole requirement is two distinct datasets: one from the source camera, and one composed of arbitrary high-quality images that can be generally crawled from the Internet - the visual content they exhibit may be unrelated. Hence, our solution is repeatable for any camera: collecting the data and training can be achieved in a couple of hours. In this work, we emphasize on extensive evaluation of obtained results. Besides standard objective metrics and subjective user study, we train a virtual rater in the form of a separate CNN that mimics human raters on Flickr data and use this network to get reference scores for both original and enhanced photos. Our experiments on the DPED, KITTI and Cityscapes datasets as well as pictures from several generations of smartphones demonstrate that WESPE produces comparable or improved qualitative results with state-of-the-art strongly supervised methods.
Automated Deep Photo Style Transfer
Jan 12, 2019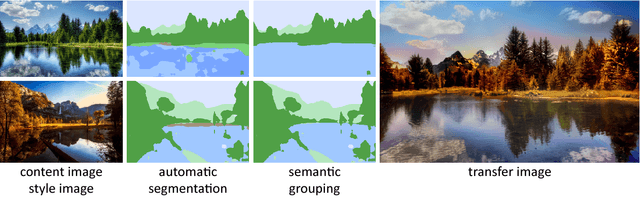

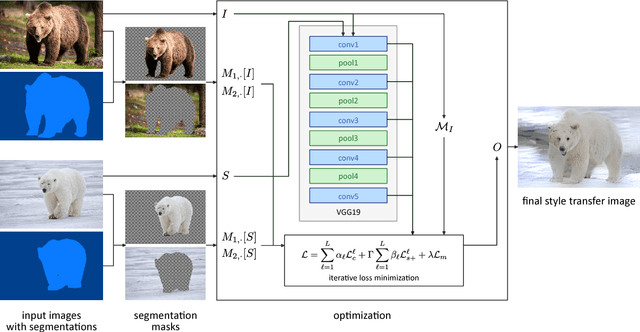

Photorealism is a complex concept that cannot easily be formulated mathematically. Deep Photo Style Transfer is an attempt to transfer the style of a reference image to a content image while preserving its photorealism. This is achieved by introducing a constraint that prevents distortions in the content image and by applying the style transfer independently for semantically different parts of the images. In addition, an automated segmentation process is presented that consists of a neural network based segmentation method followed by a semantic grouping step. To further improve the results a measure for image aesthetics is used and elaborated. If the content and the style image are sufficiently similar, the result images look very realistic. With the automation of the image segmentation the pipeline becomes completely independent from any user interaction, which allows for new applications.
NeRF-SOS: Any-View Self-supervised Object Segmentation on Complex Scenes
Oct 12, 2022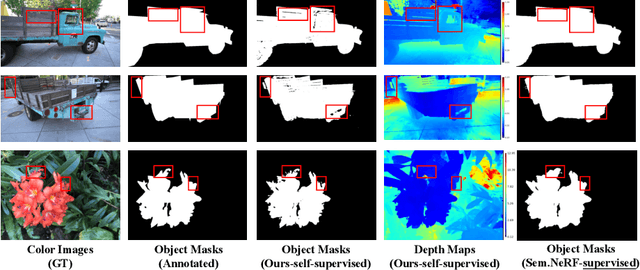
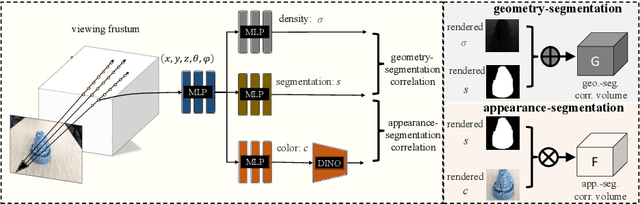
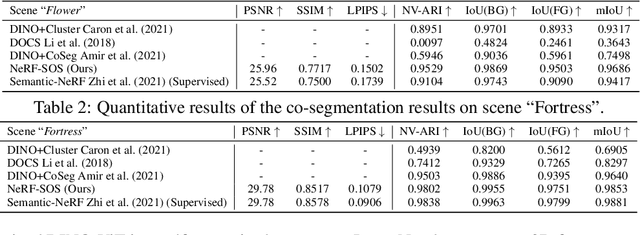

Neural volumetric representations have shown the potential that Multi-layer Perceptrons (MLPs) can be optimized with multi-view calibrated images to represent scene geometry and appearance, without explicit 3D supervision. Object segmentation can enrich many downstream applications based on the learned radiance field. However, introducing hand-crafted segmentation to define regions of interest in a complex real-world scene is non-trivial and expensive as it acquires per view annotation. This paper carries out the exploration of self-supervised learning for object segmentation using NeRF for complex real-world scenes. Our framework, called NeRF with Self-supervised Object Segmentation NeRF-SOS, couples object segmentation and neural radiance field to segment objects in any view within a scene. By proposing a novel collaborative contrastive loss in both appearance and geometry levels, NeRF-SOS encourages NeRF models to distill compact geometry-aware segmentation clusters from their density fields and the self-supervised pre-trained 2D visual features. The self-supervised object segmentation framework can be applied to various NeRF models that both lead to photo-realistic rendering results and convincing segmentation maps for both indoor and outdoor scenarios. Extensive results on the LLFF, Tank & Temple, and BlendedMVS datasets validate the effectiveness of NeRF-SOS. It consistently surpasses other 2D-based self-supervised baselines and predicts finer semantics masks than existing supervised counterparts. Please refer to the video on our project page for more details:https://zhiwenfan.github.io/NeRF-SOS.
Neural Camera Models
Aug 27, 2022
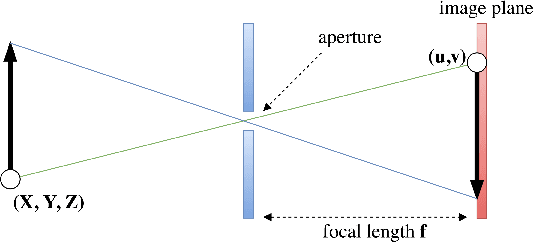

Modern computer vision has moved beyond the domain of internet photo collections and into the physical world, guiding camera-equipped robots and autonomous cars through unstructured environments. To enable these embodied agents to interact with real-world objects, cameras are increasingly being used as depth sensors, reconstructing the environment for a variety of downstream reasoning tasks. Machine-learning-aided depth perception, or depth estimation, predicts for each pixel in an image the distance to the imaged scene point. While impressive strides have been made in depth estimation, significant challenges remain: (1) ground truth depth labels are difficult and expensive to collect at scale, (2) camera information is typically assumed to be known, but is often unreliable and (3) restrictive camera assumptions are common, even though a great variety of camera types and lenses are used in practice. In this thesis, we focus on relaxing these assumptions, and describe contributions toward the ultimate goal of turning cameras into truly generic depth sensors.
CAPTAIN: Comprehensive Composition Assistance for Photo Taking
Nov 10, 2018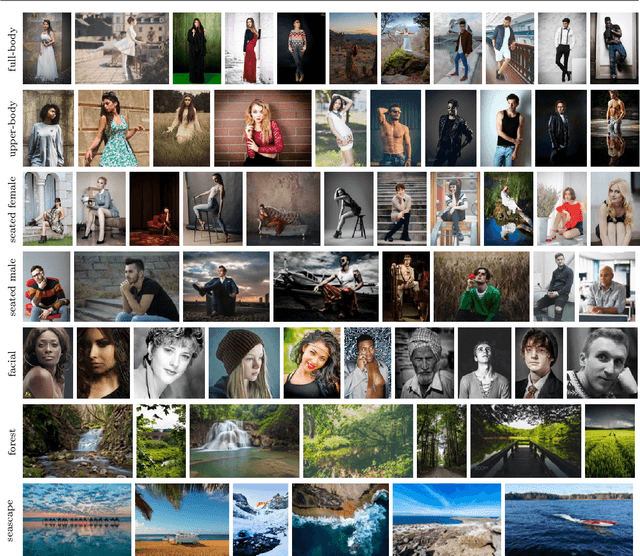
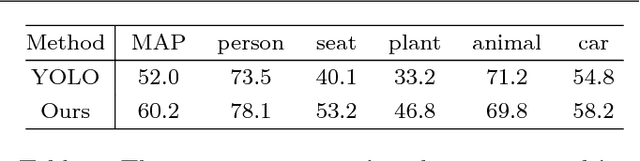
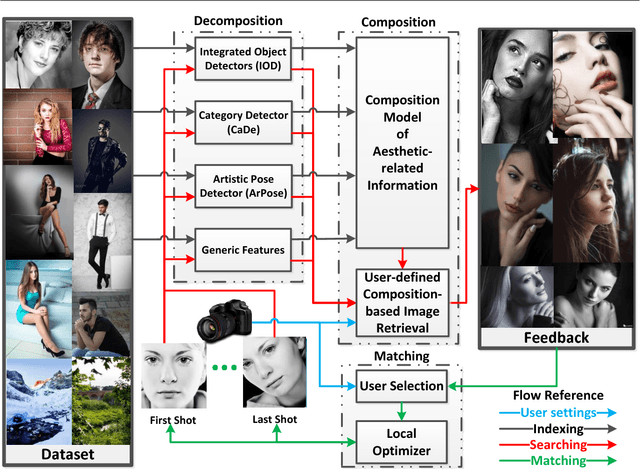

Many people are interested in taking astonishing photos and sharing with others. Emerging hightech hardware and software facilitate ubiquitousness and functionality of digital photography. Because composition matters in photography, researchers have leveraged some common composition techniques to assess the aesthetic quality of photos computationally. However, composition techniques developed by professionals are far more diverse than well-documented techniques can cover. We leverage the vast underexplored innovations in photography for computational composition assistance. We propose a comprehensive framework, named CAPTAIN (Composition Assistance for Photo Taking), containing integrated deep-learned semantic detectors, sub-genre categorization, artistic pose clustering, personalized aesthetics-based image retrieval, and style set matching. The framework is backed by a large dataset crawled from a photo-sharing Website with mostly photography enthusiasts and professionals. The work proposes a sequence of steps that have not been explored in the past by researchers. The work addresses personal preferences for composition through presenting a ranked-list of photographs to the user based on user-specified weights in the similarity measure. The matching algorithm recognizes the best shot among a sequence of shots with respect to the user's preferred style set. We have conducted a number of experiments on the newly proposed components and reported findings. A user study demonstrates that the work is useful to those taking photos.