 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Batch-based Activity Recognition from Egocentric Photo-Streams Revisited
May 09, 2018

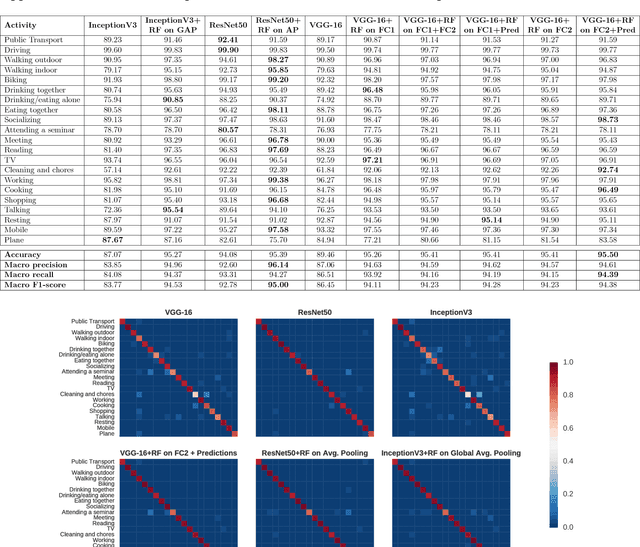
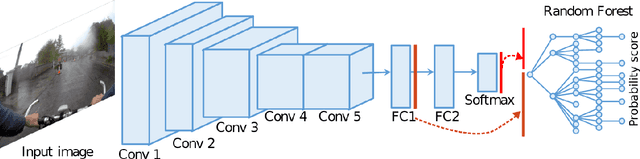
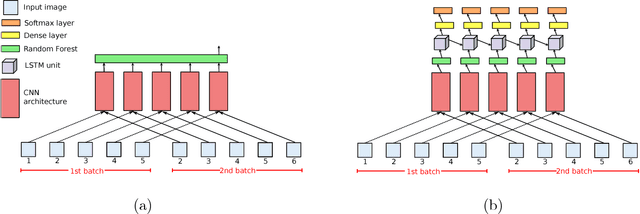
Wearable cameras can gather large a\-mounts of image data that provide rich visual information about the daily activities of the wearer. Motivated by the large number of health applications that could be enabled by the automatic recognition of daily activities, such as lifestyle characterization for habit improvement, context-aware personal assistance and tele-rehabilitation services, we propose a system to classify 21 daily activities from photo-streams acquired by a wearable photo-camera. Our approach combines the advantages of a Late Fusion Ensemble strategy relying on convolutional neural networks at image level with the ability of recurrent neural networks to account for the temporal evolution of high level features in photo-streams without relying on event boundaries. The proposed batch-based approach achieved an overall accuracy of 89.85\%, outperforming state of the art end-to-end methodologies. These results were achieved on a dataset consists of 44,902 egocentric pictures from three persons captured during 26 days in average.
Vision-based Perimeter Defense via Multiview Pose Estimation
Sep 25, 2022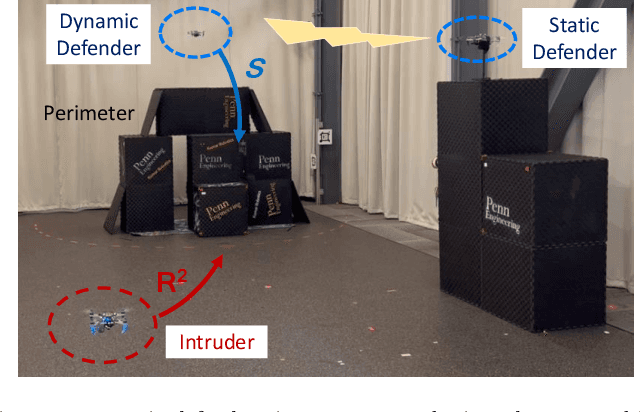
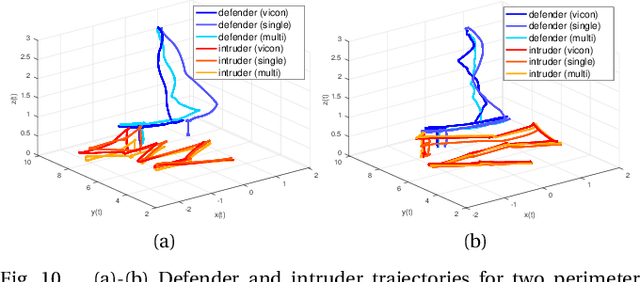
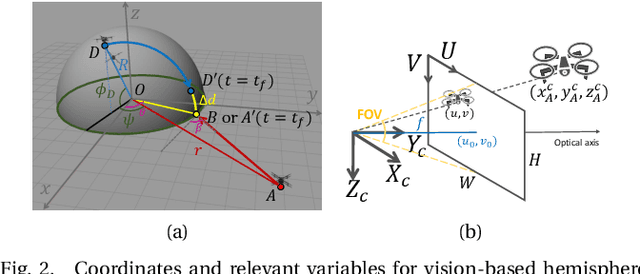
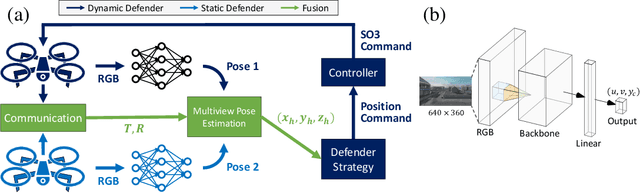
Previous studies in the perimeter defense game have largely focused on the fully observable setting where the true player states are known to all players. However, this is unrealistic for practical implementation since defenders may have to perceive the intruders and estimate their states. In this work, we study the perimeter defense game in a photo-realistic simulator and the real world, requiring defenders to estimate intruder states from vision. We train a deep machine learning-based system for intruder pose detection with domain randomization that aggregates multiple views to reduce state estimation errors and adapt the defensive strategy to account for this. We newly introduce performance metrics to evaluate the vision-based perimeter defense. Through extensive experiments, we show that our approach improves state estimation, and eventually, perimeter defense performance in both 1-defender-vs-1-intruder games, and 2-defenders-vs-1-intruder games.
Evolution of a Web-Scale Near Duplicate Image Detection System
Sep 18, 2022
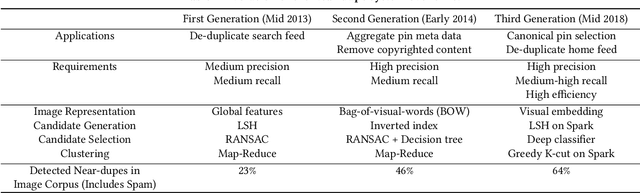


Detecting near duplicate images is fundamental to the content ecosystem of photo sharing web applications. However, such a task is challenging when involving a web-scale image corpus containing billions of images. In this paper, we present an efficient system for detecting near duplicate images across 8 billion images. Our system consists of three stages: candidate generation, candidate selection, and clustering. We also demonstrate that this system can be used to greatly improve the quality of recommendations and search results across a number of real-world applications. In addition, we include the evolution of the system over the course of six years, bringing out experiences and lessons on how new systems are designed to accommodate organic content growth as well as the latest technology. Finally, we are releasing a human-labeled dataset of ~53,000 pairs of images introduced in this paper.
Towards Photo-Realistic Virtual Try-On by Adaptively Generating$\leftrightarrow$Preserving Image Content
Mar 12, 2020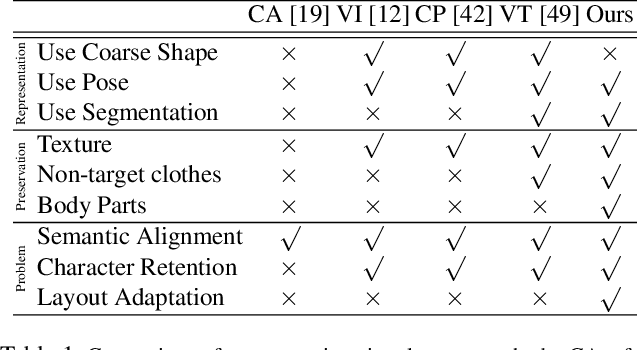
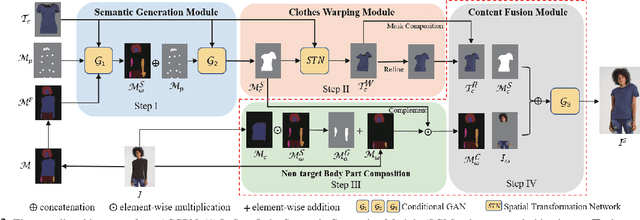
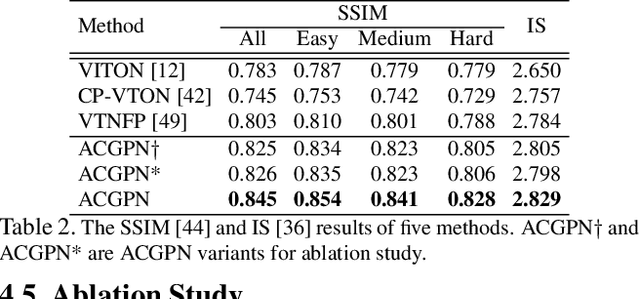

Image visual try-on aims at transferring a target clothing image onto a reference person, and has become a hot topic in recent years. Prior arts usually focus on preserving the character of a clothing image (e.g. texture, logo, embroidery) when warping it to arbitrary human pose. However, it remains a big challenge to generate photo-realistic try-on images when large occlusions and human poses are presented in the reference person. To address this issue, we propose a novel visual try-on network, namely Adaptive Content Generating and Preserving Network (ACGPN). In particular, ACGPN first predicts semantic layout of the reference image that will be changed after try-on (e.g. long sleeve shirt$\rightarrow$arm, arm$\rightarrow$jacket), and then determines whether its image content needs to be generated or preserved according to the predicted semantic layout, leading to photo-realistic try-on and rich clothing details. ACGPN generally involves three major modules. First, a semantic layout generation module utilizes semantic segmentation of the reference image to progressively predict the desired semantic layout after try-on. Second, a clothes warping module warps clothing images according to the generated semantic layout, where a second-order difference constraint is introduced to stabilize the warping process during training. Third, an inpainting module for content fusion integrates all information (e.g. reference image, semantic layout, warped clothes) to adaptively produce each semantic part of human body. In comparison to the state-of-the-art methods, ACGPN can generate photo-realistic images with much better perceptual quality and richer fine-details.
Vision-Language Matching for Text-to-Image Synthesis via Generative Adversarial Networks
Aug 20, 2022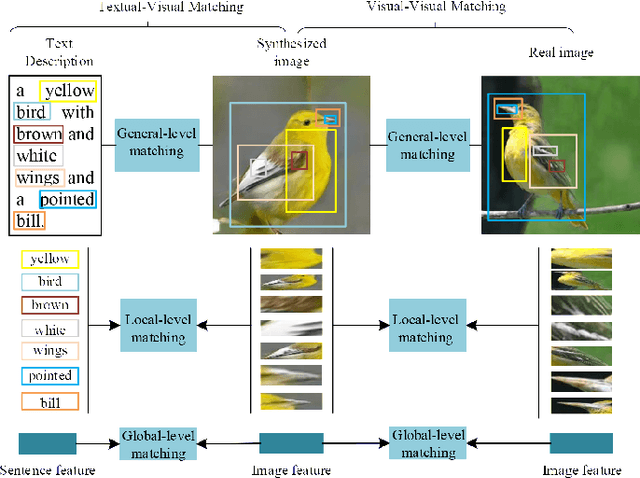
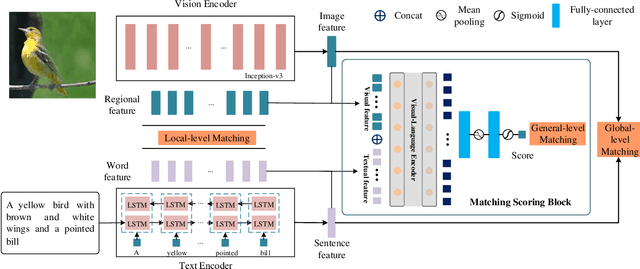
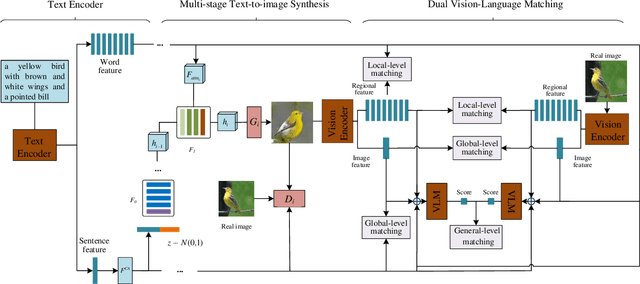

Text-to-image synthesis aims to generate a photo-realistic and semantic consistent image from a specific text description. The images synthesized by off-the-shelf models usually contain limited components compared with the corresponding image and text description, which decreases the image quality and the textual-visual consistency. To address this issue, we propose a novel Vision-Language Matching strategy for text-to-image synthesis, named VLMGAN*, which introduces a dual vision-language matching mechanism to strengthen the image quality and semantic consistency. The dual vision-language matching mechanism considers textual-visual matching between the generated image and the corresponding text description, and visual-visual consistent constraints between the synthesized image and the real image. Given a specific text description, VLMGAN* firstly encodes it into textual features and then feeds them to a dual vision-language matching-based generative model to synthesize a photo-realistic and textual semantic consistent image. Besides, the popular evaluation metrics for text-to-image synthesis are borrowed from simple image generation, which mainly evaluates the reality and diversity of the synthesized images. Therefore, we introduce a metric named Vision-Language Matching Score (VLMS) to evaluate the performance of text-to-image synthesis which can consider both the image quality and the semantic consistency between synthesized image and the description. The proposed dual multi-level vision-language matching strategy can be applied to other text-to-image synthesis methods. We implement this strategy on two popular baselines, which are marked with ${\text{VLMGAN}_{+\text{AttnGAN}}}$ and ${\text{VLMGAN}_{+\text{DFGAN}}}$. The experimental results on two widely-used datasets show that the model achieves significant improvements over other state-of-the-art methods.
Towards Efficient Neural Scene Graphs by Learning Consistency Fields
Oct 09, 2022
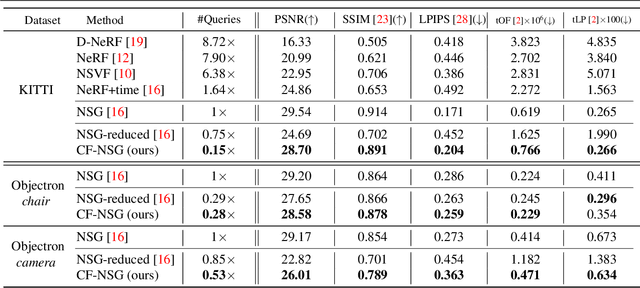
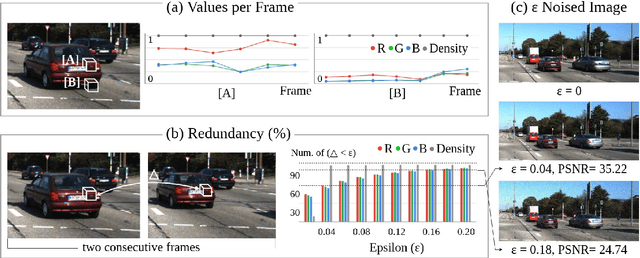

Neural Radiance Fields (NeRF) achieves photo-realistic image rendering from novel views, and the Neural Scene Graphs (NSG) \cite{ost2021neural} extends it to dynamic scenes (video) with multiple objects. Nevertheless, computationally heavy ray marching for every image frame becomes a huge burden. In this paper, taking advantage of significant redundancy across adjacent frames in videos, we propose a feature-reusing framework. From the first try of naively reusing the NSG features, however, we learn that it is crucial to disentangle object-intrinsic properties consistent across frames from transient ones. Our proposed method, \textit{Consistency-Field-based NSG (CF-NSG)}, reformulates neural radiance fields to additionally consider \textit{consistency fields}. With disentangled representations, CF-NSG takes full advantage of the feature-reusing scheme and performs an extended degree of scene manipulation in a more controllable manner. We empirically verify that CF-NSG greatly improves the inference efficiency by using 85\% less queries than NSG without notable degradation in rendering quality. Code will be available at: https://github.com/ldynx/CF-NSG
Face Deblurring using Dual Camera Fusion on Mobile Phones
Jul 23, 2022
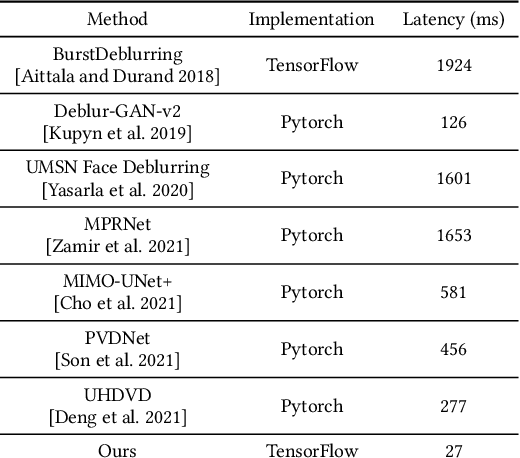

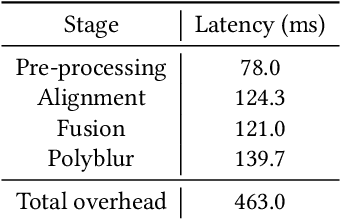
Motion blur of fast-moving subjects is a longstanding problem in photography and very common on mobile phones due to limited light collection efficiency, particularly in low-light conditions. While we have witnessed great progress in image deblurring in recent years, most methods require significant computational power and have limitations in processing high-resolution photos with severe local motions. To this end, we develop a novel face deblurring system based on the dual camera fusion technique for mobile phones. The system detects subject motion to dynamically enable a reference camera, e.g., ultrawide angle camera commonly available on recent premium phones, and captures an auxiliary photo with faster shutter settings. While the main shot is low noise but blurry, the reference shot is sharp but noisy. We learn ML models to align and fuse these two shots and output a clear photo without motion blur. Our algorithm runs efficiently on Google Pixel 6, which takes 463 ms overhead per shot. Our experiments demonstrate the advantage and robustness of our system against alternative single-image, multi-frame, face-specific, and video deblurring algorithms as well as commercial products. To the best of our knowledge, our work is the first mobile solution for face motion deblurring that works reliably and robustly over thousands of images in diverse motion and lighting conditions.
GarmentGAN: Photo-realistic Adversarial Fashion Transfer
Mar 04, 2020
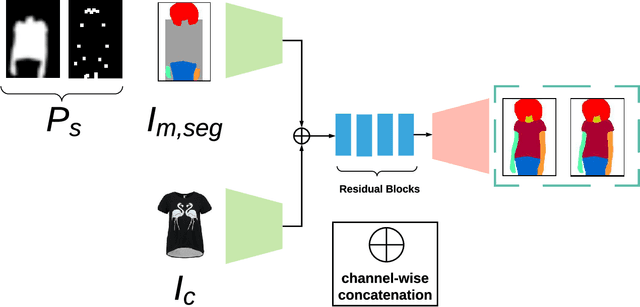
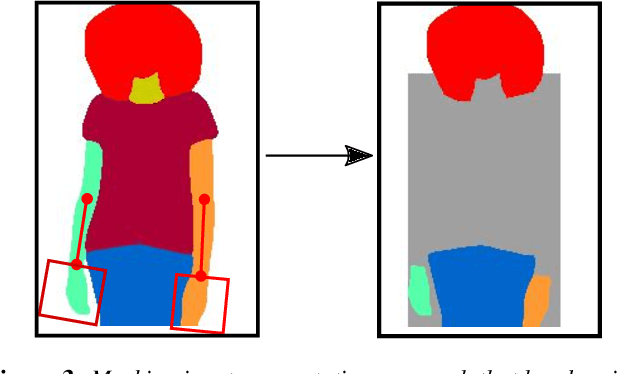
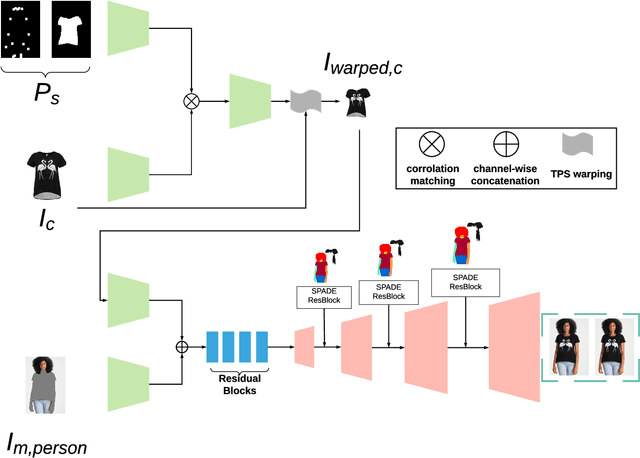
The garment transfer problem comprises two tasks: learning to separate a person's body (pose, shape, color) from their clothing (garment type, shape, style) and then generating new images of the wearer dressed in arbitrary garments. We present GarmentGAN, a new algorithm that performs image-based garment transfer through generative adversarial methods. The GarmentGAN framework allows users to virtually try-on items before purchase and generalizes to various apparel types. GarmentGAN requires as input only two images, namely, a picture of the target fashion item and an image containing the customer. The output is a synthetic image wherein the customer is wearing the target apparel. In order to make the generated image look photo-realistic, we employ the use of novel generative adversarial techniques. GarmentGAN improves on existing methods in the realism of generated imagery and solves various problems related to self-occlusions. Our proposed model incorporates additional information during training, utilizing both segmentation maps and body key-point information. We show qualitative and quantitative comparisons to several other networks to demonstrate the effectiveness of this technique.
CU-Net: Efficient Point Cloud Color Upsampling Network
Sep 12, 2022



Point cloud upsampling is necessary for Augmented Reality, Virtual Reality, and telepresence scenarios. Although the geometry upsampling is well studied to densify point cloud coordinates, the upsampling of colors has been largely overlooked. In this paper, we propose CU-Net, the first deep-learning point cloud color upsampling model. Leveraging a feature extractor based on sparse convolution and a color prediction module based on neural implicit function, CU-Net achieves linear time and space complexity. Therefore, CU-Net is theoretically guaranteed to be more efficient than most existing methods with quadratic complexity. Experimental results demonstrate that CU-Net can colorize a photo-realistic point cloud with nearly a million points in real time, while having better visual quality than baselines. Besides, CU-Net can adapt to an arbitrary upsampling ratio and unseen objects. Our source code will be released to the public soon.
Assuring safety of vision-based swarm formation control
Oct 03, 2022
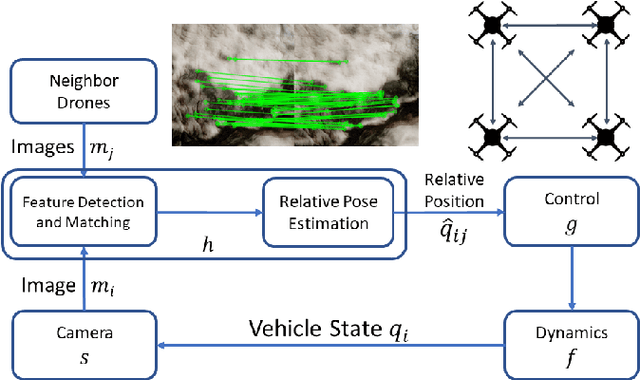

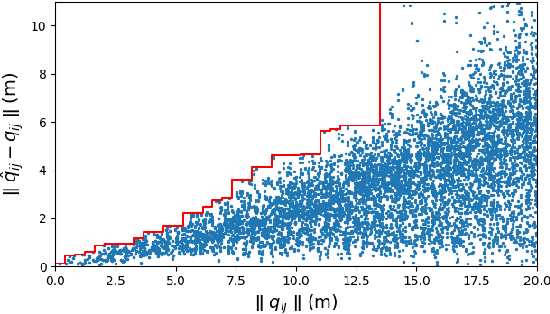
Vision-based formation control systems recently have attracted attentions from both the research community and the industry for its applicability in GPS-denied environments. The safety assurance for such systems is challenging due to the lack of formal specifications for computer vision systems and the complex impact of imprecise estimations on distributed control. We propose a technique for safety assurance of vision-based formation control. Our technique combines (1) the construction of a piecewise approximation of the worst-case error of perception and (2) a classical Lyapunov-based safety analysis of the consensus control algorithm. The analysis provides the ultimate bound on the relative distance between drones. This ultimate bound can then be used to guarantee safe separation of all drones. We implement an instance of the vision-based control system on top of the photo-realistic AirSim simulator. We construct the piecewise approximation for varying perception error under different environments and weather conditions, and we are able to validate the safe separation provided by our analysis across the different weather conditions with AirSim simulation.