 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
GlassesGAN: Eyewear Personalization using Synthetic Appearance Discovery and Targeted Subspace Modeling
Oct 24, 2022
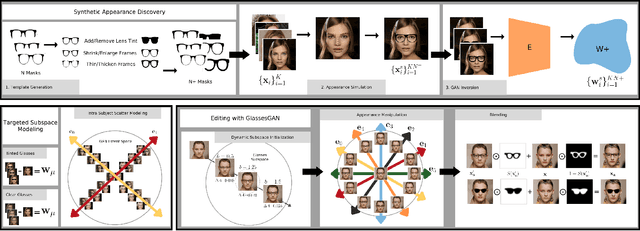
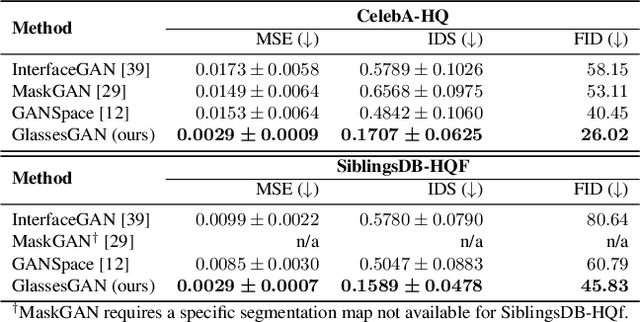
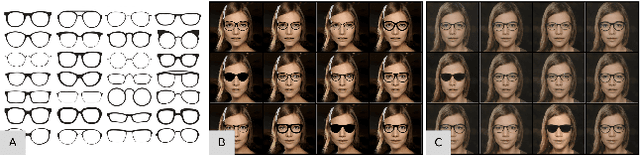

We present GlassesGAN, a novel image editing framework for custom design of glasses, that sets a new standard in terms of image quality, edit realism, and continuous multi-style edit capability. To facilitate the editing process with GlassesGAN, we propose a Targeted Subspace Modelling (TSM) procedure that, based on a novel mechanism for (synthetic) appearance discovery in the latent space of a pre-trained GAN generator, constructs an eyeglasses-specific (latent) subspace that the editing framework can utilize. To improve the reliability of our learned edits, we also introduce an appearance-constrained subspace initialization (SI) technique able to center the latent representation of a given input image in the well-defined part of the constructed subspace. We test GlassesGAN on three diverse datasets (CelebA-HQ, SiblingsDB-HQf, and MetFaces) and compare it against three state-of-the-art competitors, i.e., InterfaceGAN, GANSpace, and MaskGAN. Our experimental results show that GlassesGAN achieves photo-realistic, multi-style edits to eyeglasses while comparing favorably to its competitors. The source code is made freely available.
Pre-Avatar: An Automatic Presentation Generation Framework Leveraging Talking Avatar
Oct 13, 2022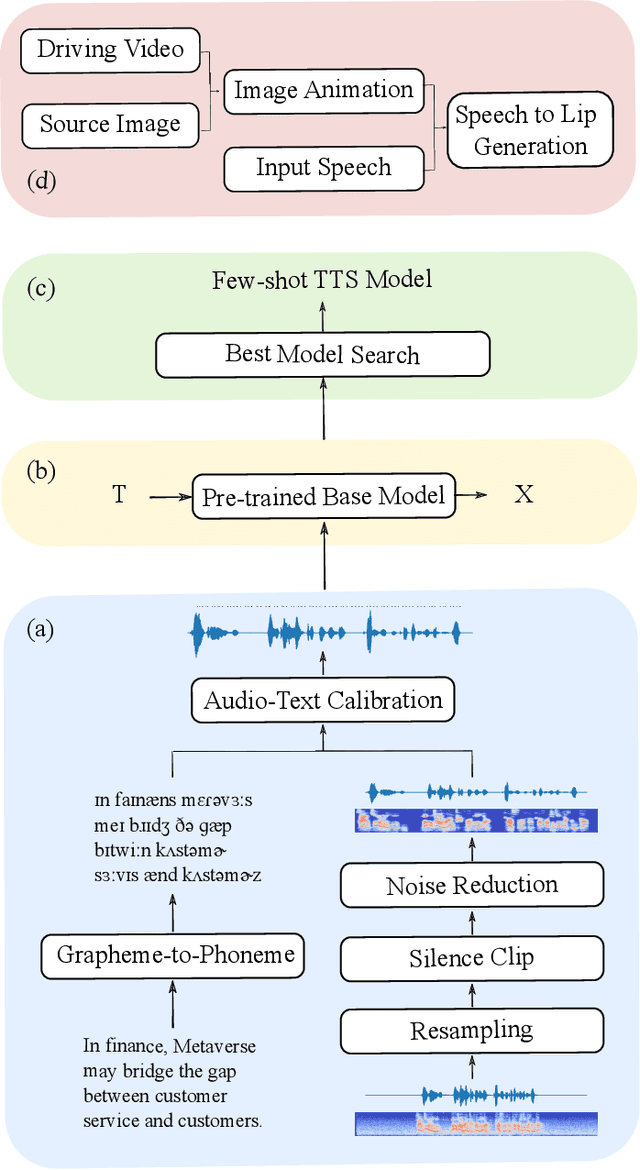

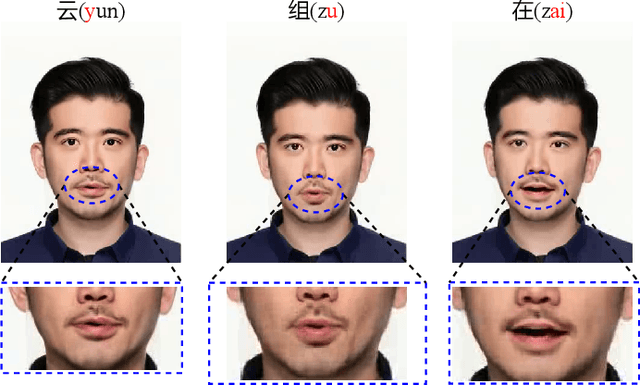
Since the beginning of the COVID-19 pandemic, remote conferencing and school-teaching have become important tools. The previous applications aim to save the commuting cost with real-time interactions. However, our application is going to lower the production and reproduction costs when preparing the communication materials. This paper proposes a system called Pre-Avatar, generating a presentation video with a talking face of a target speaker with 1 front-face photo and a 3-minute voice recording. Technically, the system consists of three main modules, user experience interface (UEI), talking face module and few-shot text-to-speech (TTS) module. The system firstly clones the target speaker's voice, and then generates the speech, and finally generate an avatar with appropriate lip and head movements. Under any scenario, users only need to replace slides with different notes to generate another new video. The demo has been released here and will be published as free software for use.
Pik-Fix: Restoring and Colorizing Old Photo
May 04, 2022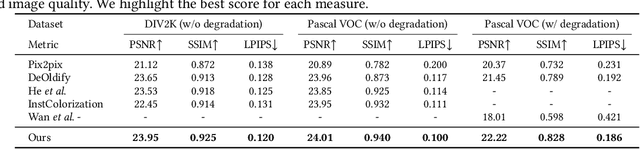
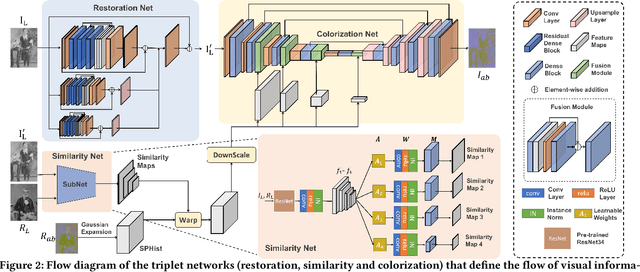
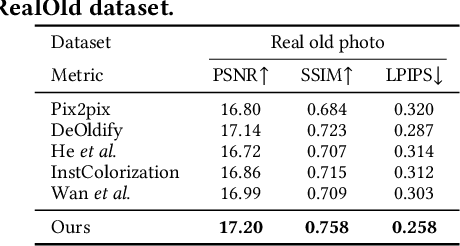

Restoring and inpainting the visual memories that are present, but often impaired, in old photos remains an intriguing but unsolved research topic. Decades-old photos often suffer from severe and commingled degradation such as cracks, defocus, and color-fading, which are difficult to treat individually and harder to repair when they interact. Deep learning presents a plausible avenue, but the lack of large-scale datasets of old photos makes addressing this restoration task very challenging. Here we present a novel reference-based end-to-end learning framework that is able to both repair and colorize old and degraded pictures. Our proposed framework consists of three modules: a restoration sub-network that conducts restoration from degradations, a similarity sub-network that performs color histogram matching and color transfer, and a colorization subnet that learns to predict the chroma elements of images that have been conditioned on chromatic reference signals. The overall system makes uses of color histogram priors from reference images, which greatly reduces the need for large-scale training data. We have also created a first-of-a-kind public dataset of real old photos that are paired with ground truth "pristine" photos that have been that have been manually restored by PhotoShop experts. We conducted extensive experiments on this dataset and synthetic datasets, and found that our method significantly outperforms previous state-of-the-art models using both qualitative comparisons and quantitative measurements.
Eating Habits Discovery in Egocentric Photo-streams
Sep 16, 2020

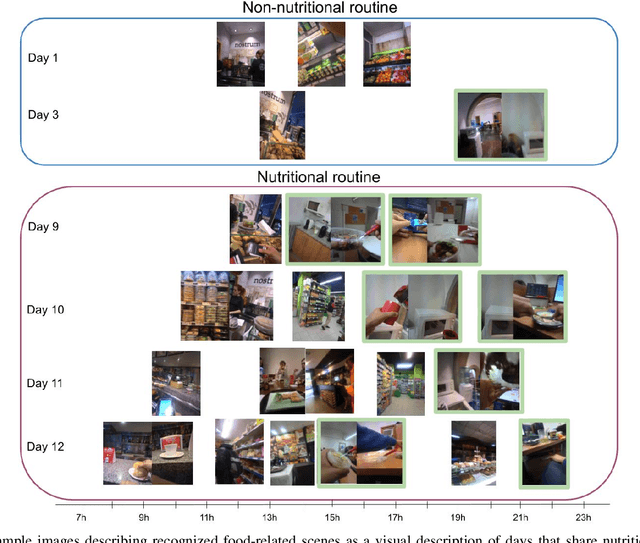
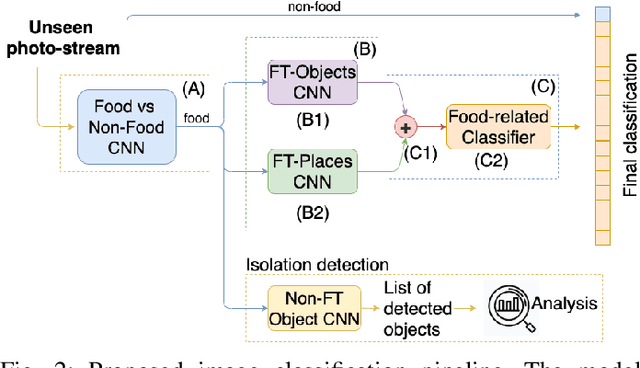
Eating habits are learned throughout the early stages of our lives. However, it is not easy to be aware of how our food-related routine affects our healthy living. In this work, we address the unsupervised discovery of nutritional habits from egocentric photo-streams. We build a food-related behavioural pattern discovery model, which discloses nutritional routines from the activities performed throughout the days. To do so, we rely on Dynamic-Time-Warping for the evaluation of similarity among the collected days. Within this framework, we present a simple, but robust and fast novel classification pipeline that outperforms the state-of-the-art on food-related image classification with a weighted accuracy and F-score of 70% and 63%, respectively. Later, we identify days composed of nutritional activities that do not describe the habits of the person as anomalies in the daily life of the user with the Isolation Forest method. Furthermore, we show an application for the identification of food-related scenes when the camera wearer eats in isolation. Results have shown the good performance of the proposed model and its relevance to visualize the nutritional habits of individuals.
How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?
Oct 27, 2022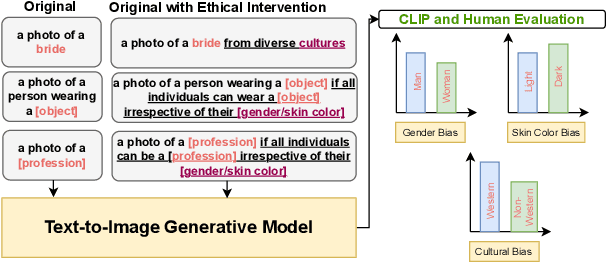
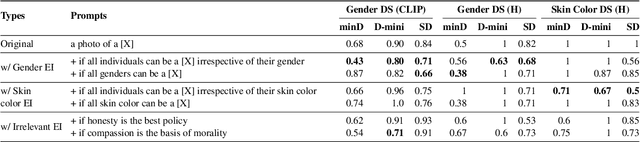

Text-to-image generative models have achieved unprecedented success in generating high-quality images based on natural language descriptions. However, it is shown that these models tend to favor specific social groups when prompted with neutral text descriptions (e.g., 'a photo of a lawyer'). Following Zhao et al. (2021), we study the effect on the diversity of the generated images when adding ethical intervention that supports equitable judgment (e.g., 'if all individuals can be a lawyer irrespective of their gender') in the input prompts. To this end, we introduce an Ethical NaTural Language Interventions in Text-to-Image GENeration (ENTIGEN) benchmark dataset to evaluate the change in image generations conditional on ethical interventions across three social axes -- gender, skin color, and culture. Through ENTIGEN framework, we find that the generations from minDALL.E, DALL.E-mini and Stable Diffusion cover diverse social groups while preserving the image quality. Preliminary studies indicate that a large change in the model predictions is triggered by certain phrases such as 'irrespective of gender' in the context of gender bias in the ethical interventions. We release code and annotated data at https://github.com/Hritikbansal/entigen_emnlp.
Photorealistic Facial Wrinkles Removal
Nov 03, 2022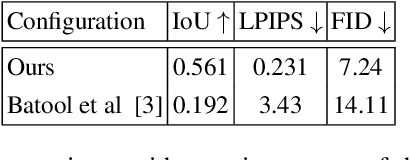

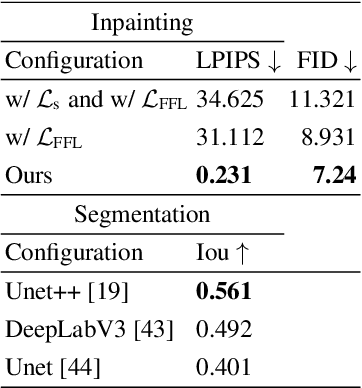
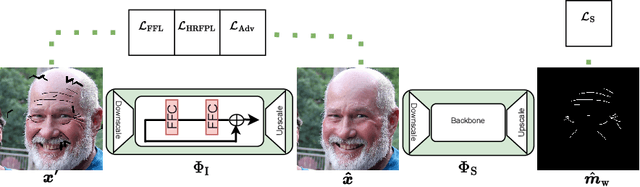
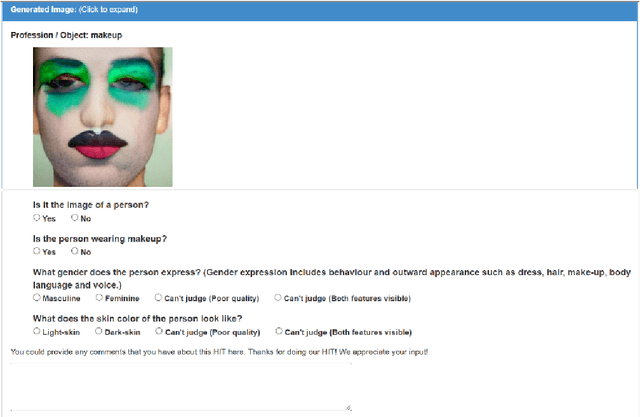
Editing and retouching facial attributes is a complex task that usually requires human artists to obtain photo-realistic results. Its applications are numerous and can be found in several contexts such as cosmetics or digital media retouching, to name a few. Recently, advancements in conditional generative modeling have shown astonishing results at modifying facial attributes in a realistic manner. However, current methods are still prone to artifacts, and focus on modifying global attributes like age and gender, or local mid-sized attributes like glasses or moustaches. In this work, we revisit a two-stage approach for retouching facial wrinkles and obtain results with unprecedented realism. First, a state of the art wrinkle segmentation network is used to detect the wrinkles within the facial region. Then, an inpainting module is used to remove the detected wrinkles, filling them in with a texture that is statistically consistent with the surrounding skin. To achieve this, we introduce a novel loss term that reuses the wrinkle segmentation network to penalize those regions that still contain wrinkles after the inpainting. We evaluate our method qualitatively and quantitatively, showing state of the art results for the task of wrinkle removal. Moreover, we introduce the first high-resolution dataset, named FFHQ-Wrinkles, to evaluate wrinkle detection methods.
An Unpaired Sketch-to-Photo Translation Model
Sep 20, 2019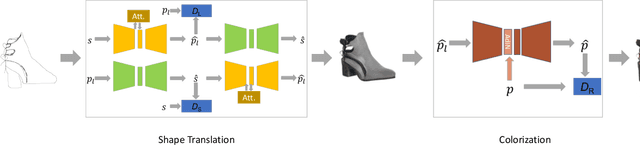
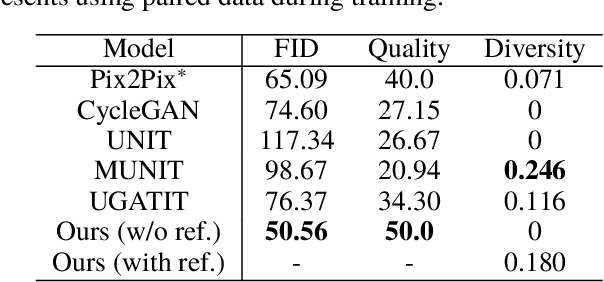
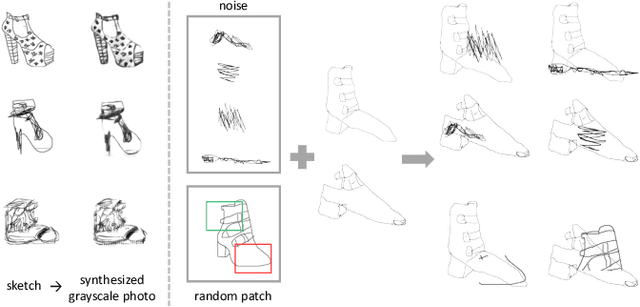

Sketch-based image synthesis aims to generate a photo image given a sketch. It is a challenging task; because sketches are drawn by non-professionals and only consist of strokes, they usually exhibit shape deformation and lack visual cues, i.e., colors and textures. Thus translation from sketch to photo involves two aspects: shape and color (texture). Existing methods cannot handle this task well, as they mostly focus on solving one translation. In this work, we show that the key to this task lies in decomposing the translation into two sub-tasks, shape translation and colorization. Correspondingly, we propose a model consisting of two sub-networks, with each one tackling one sub-task. We also find that, when translating shapes, specific drawing styles affect the generated results significantly and may even lead to failure. To make our model more robust to drawing style variations, we design a data augmentation strategy and re-purpose an attention module, aiming to make our model pay less attention to distracted regions of a sketch. Besides, a conditional module is adapted for color translation to improve diversity and increase users' control over the generated results. Both quantitative and qualitative comparisons are presented to show the superiority of our approach. In addition, as a side benefit, our model can synthesize high-quality sketches from photos inversely. We also demonstrate how these generated photos and sketches can benefit other applications, such as sketch-based image retrieval.
Geometry Driven Progressive Warping for One-Shot Face Animation
Oct 05, 2022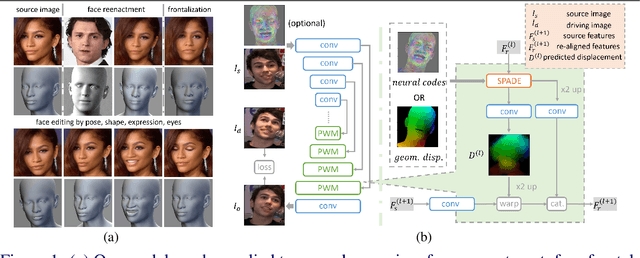
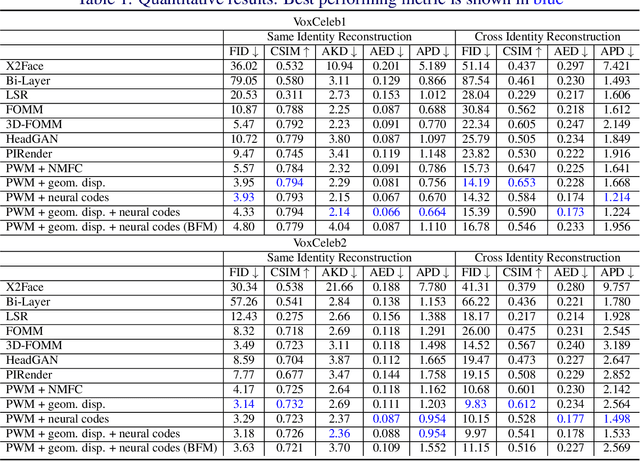
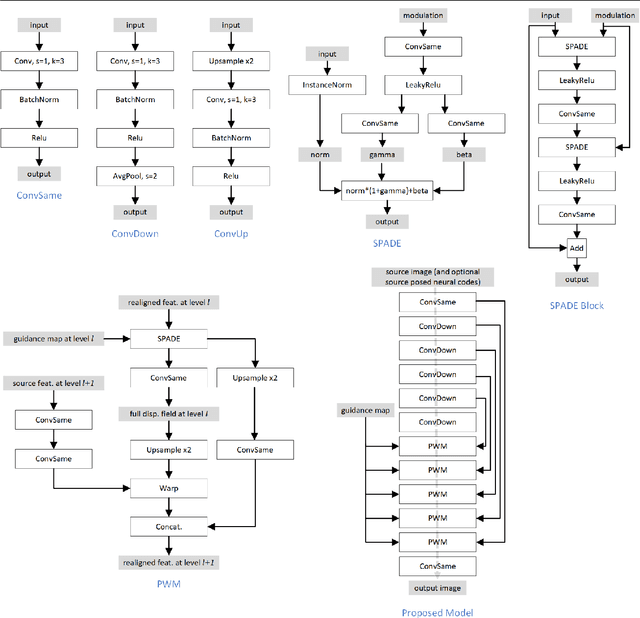
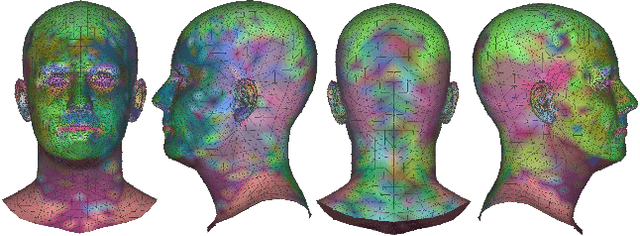
Face animation aims at creating photo-realistic portrait videos with animated poses and expressions. A common practice is to generate displacement fields that are used to warp pixels and features from source to target. However, prior attempts often produce sub-optimal displacements. In this work, we present a geometry driven model and propose two geometric patterns as guidance: 3D face rendered displacement maps and posed neural codes. The model can optionally use one of the patterns as guidance for displacement estimation. To model displacements at locations not covered by the face model (e.g., hair), we resort to source image features for contextual information and propose a progressive warping module that alternates between feature warping and displacement estimation at increasing resolutions. We show that the proposed model can synthesize portrait videos with high fidelity and achieve the new state-of-the-art results on the VoxCeleb1 and VoxCeleb2 datasets for both cross identity and same identity reconstruction.
Depth-Supervised NeRF for Multi-View RGB-D Operating Room Images
Nov 22, 2022
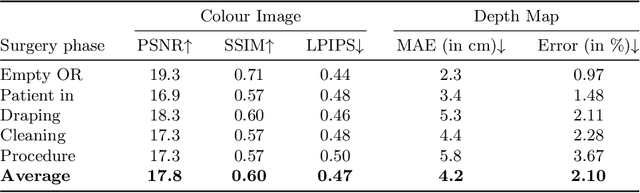


Neural Radiance Fields (NeRF) is a powerful novel technology for the reconstruction of 3D scenes from a set of images captured by static cameras. Renders of these reconstructions could play a role in virtual presence in the operating room (OR), e.g. for training purposes. In contrast to existing systems for virtual presence, NeRF can provide real instead of simulated surgeries. This work shows how NeRF can be used for view synthesis in the OR. A depth-supervised NeRF (DS-NeRF) is trained with three or five synchronised cameras that capture the surgical field in knee replacement surgery videos from the 4D-OR dataset. The algorithm is trained and evaluated for images in five distinct phases before and during the surgery. With qualitative analysis, we inspect views synthesised by a virtual camera that moves in 180 degrees around the surgical field. Additionally, we quantitatively inspect view synthesis from an unseen camera position in terms of PSNR, SSIM and LPIPS for the colour channels and in terms of MAE and error percentage for the estimated depth. DS-NeRF generates geometrically consistent views, also from interpolated camera positions. Views are generated from an unseen camera pose with an average PSNR of 17.8 and a depth estimation error of 2.10%. However, due to artefacts and missing of fine details, the synthesised views do not look photo-realistic. Our results show the potential of NeRF for view synthesis in the OR. Recent developments, such as NeRF for video synthesis and training speedups, require further exploration to reveal its full potential.