 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Removing grid structure in angle-resolved photoemission spectra via deep learning method
Oct 20, 2022
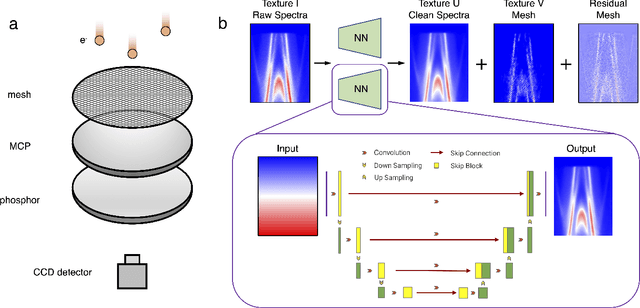
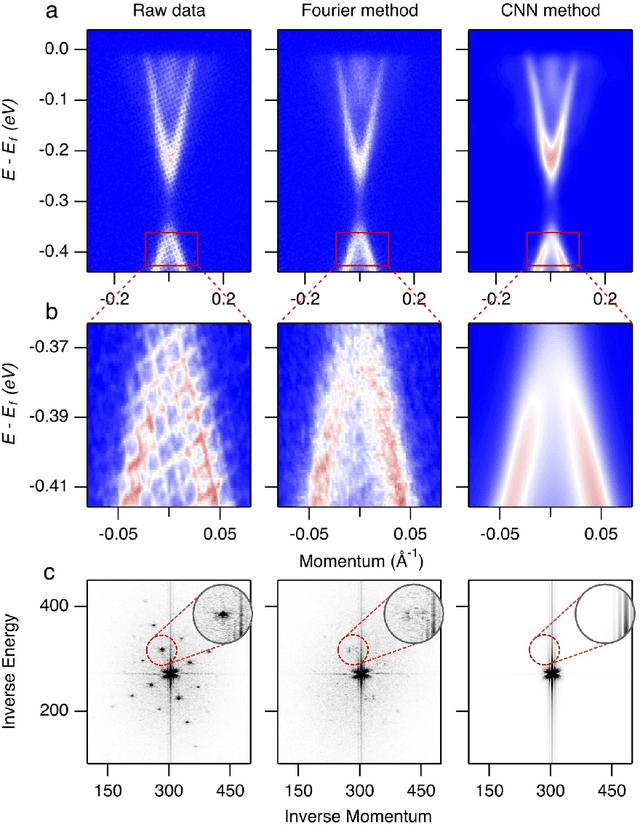
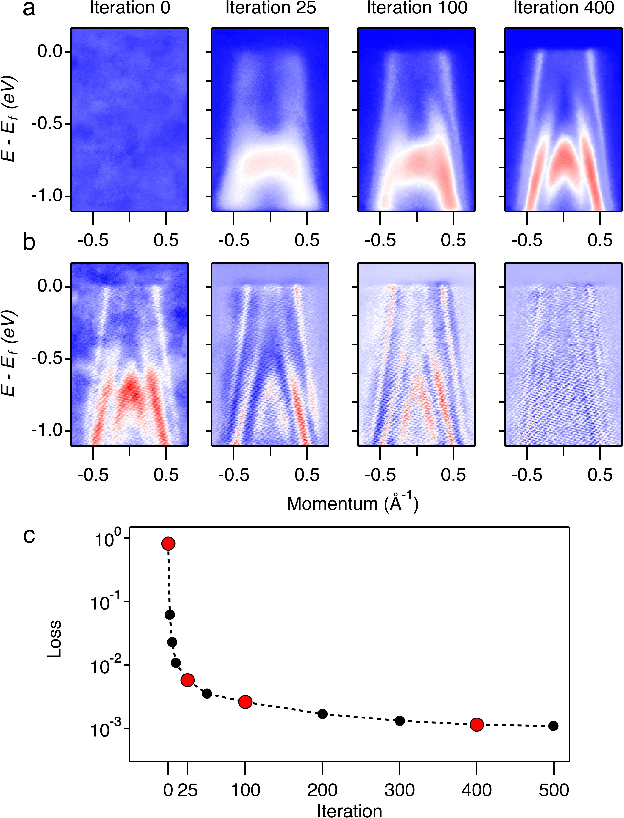
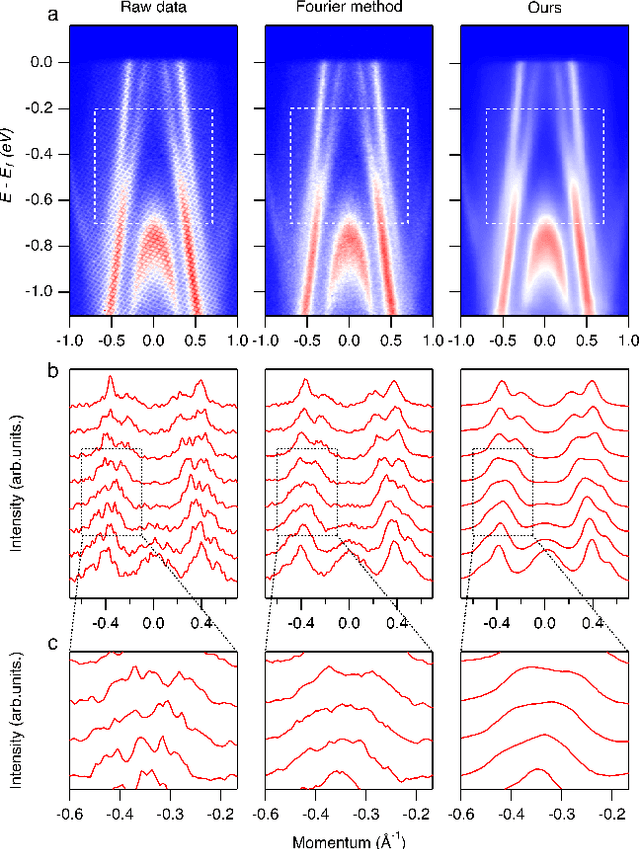
Spectroscopic data may often contain unwanted extrinsic signals. For example, in ARPES experiment, a wire mesh is typically placed in front of the CCD to block stray photo-electrons, but could cause a grid-like structure in the spectra during quick measurement mode. In the past, this structure was often removed using the mathematical Fourier filtering method by erasing the periodic structure. However, this method may lead to information loss and vacancies in the spectra because the grid structure is not strictly linearly superimposed. Here, we propose a deep learning method to effectively overcome this problem. Our method takes advantage of the self-correlation information within the spectra themselves and can greatly optimize the quality of the spectra while removing the grid structure and noise simultaneously. It has the potential to be extended to all spectroscopic measurements to eliminate other extrinsic signals and enhance the spectral quality based on the self-correlation of the spectra solely.
Cross-Modal Fusion Distillation for Fine-Grained Sketch-Based Image Retrieval
Oct 19, 2022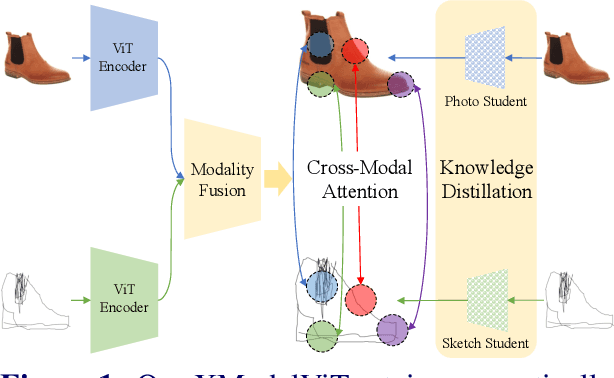
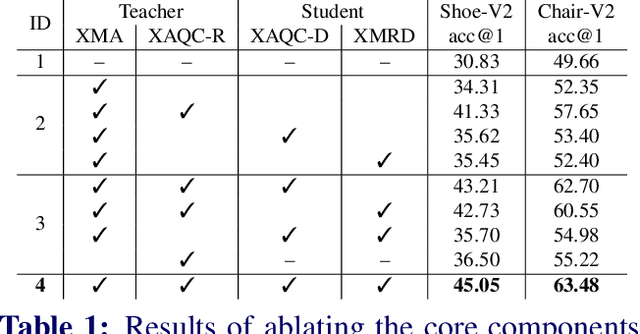

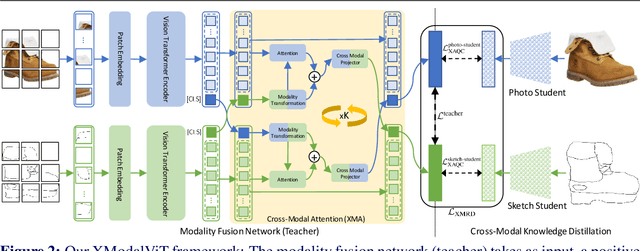
Representation learning for sketch-based image retrieval has mostly been tackled by learning embeddings that discard modality-specific information. As instances from different modalities can often provide complementary information describing the underlying concept, we propose a cross-attention framework for Vision Transformers (XModalViT) that fuses modality-specific information instead of discarding them. Our framework first maps paired datapoints from the individual photo and sketch modalities to fused representations that unify information from both modalities. We then decouple the input space of the aforementioned modality fusion network into independent encoders of the individual modalities via contrastive and relational cross-modal knowledge distillation. Such encoders can then be applied to downstream tasks like cross-modal retrieval. We demonstrate the expressive capacity of the learned representations by performing a wide range of experiments and achieving state-of-the-art results on three fine-grained sketch-based image retrieval benchmarks: Shoe-V2, Chair-V2 and Sketchy. Implementation is available at https://github.com/abhrac/xmodal-vit.
Dual Pyramid Generative Adversarial Networks for Semantic Image Synthesis
Oct 08, 2022



The goal of semantic image synthesis is to generate photo-realistic images from semantic label maps. It is highly relevant for tasks like content generation and image editing. Current state-of-the-art approaches, however, still struggle to generate realistic objects in images at various scales. In particular, small objects tend to fade away and large objects are often generated as collages of patches. In order to address this issue, we propose a Dual Pyramid Generative Adversarial Network (DP-GAN) that learns the conditioning of spatially-adaptive normalization blocks at all scales jointly, such that scale information is bi-directionally used, and it unifies supervision at different scales. Our qualitative and quantitative results show that the proposed approach generates images where small and large objects look more realistic compared to images generated by state-of-the-art methods.
S$^3$-NeRF: Neural Reflectance Field from Shading and Shadow under a Single Viewpoint
Oct 17, 2022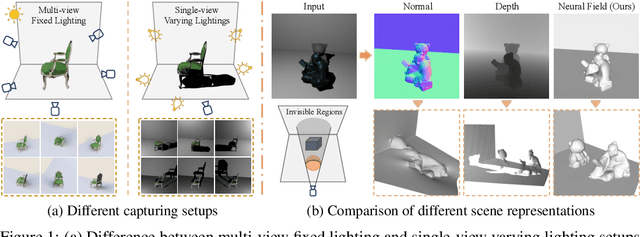
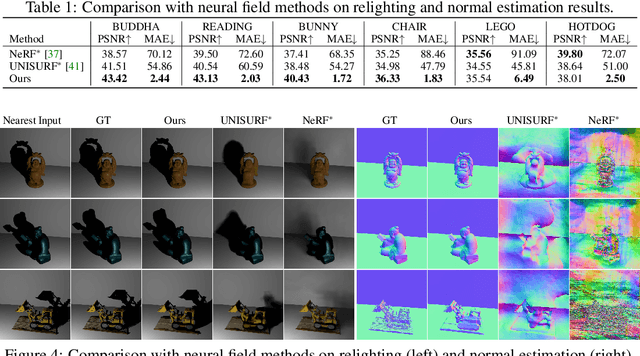
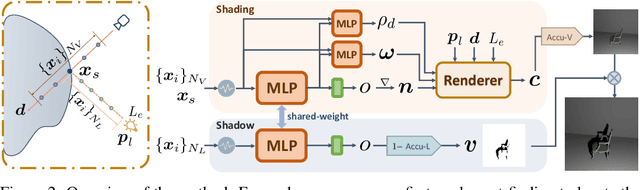
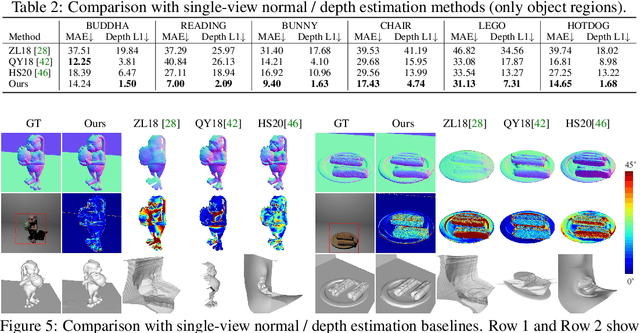
In this paper, we address the "dual problem" of multi-view scene reconstruction in which we utilize single-view images captured under different point lights to learn a neural scene representation. Different from existing single-view methods which can only recover a 2.5D scene representation (i.e., a normal / depth map for the visible surface), our method learns a neural reflectance field to represent the 3D geometry and BRDFs of a scene. Instead of relying on multi-view photo-consistency, our method exploits two information-rich monocular cues, namely shading and shadow, to infer scene geometry. Experiments on multiple challenging datasets show that our method is capable of recovering 3D geometry, including both visible and invisible parts, of a scene from single-view images. Thanks to the neural reflectance field representation, our method is robust to depth discontinuities. It supports applications like novel-view synthesis and relighting. Our code and model can be found at https://ywq.github.io/s3nerf.
Social Style Characterization from Egocentric Photo-streams
Sep 18, 2017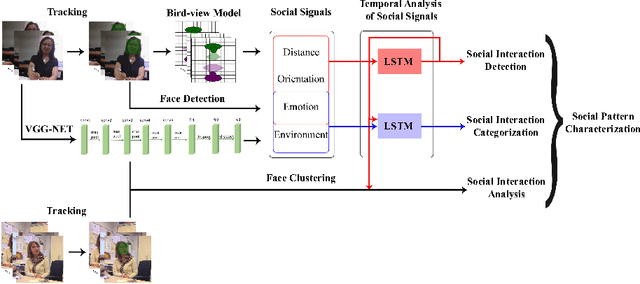
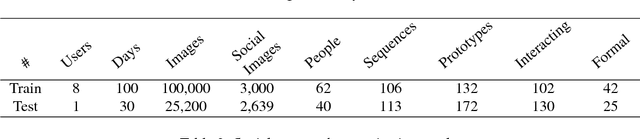

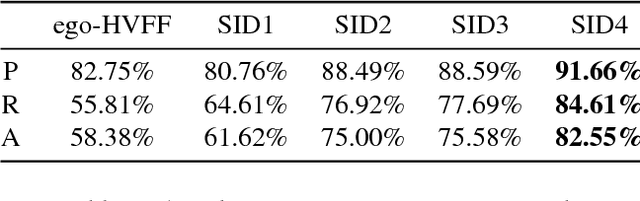
This paper proposes a system for automatic social pattern characterization using a wearable photo-camera. The proposed pipeline consists of three major steps. First, detection of people with whom the camera wearer interacts and, second, categorization of the detected social interactions into formal and informal. These two steps act at event-level where each potential social event is modeled as a multi-dimensional time-series, whose dimensions correspond to a set of relevant features for each task, and a LSTM network is employed for time-series classification. In the last step, recurrences of the same person across the whole set of social interactions are clustered to achieve a comprehensive understanding of the diversity and frequency of the social relations of the user. Experiments over a dataset acquired by a user wearing a photo-camera during a month show promising results on the task of social pattern characterization from egocentric photo-streams.
Perspective (In)consistency of Paint by Text
Jun 27, 2022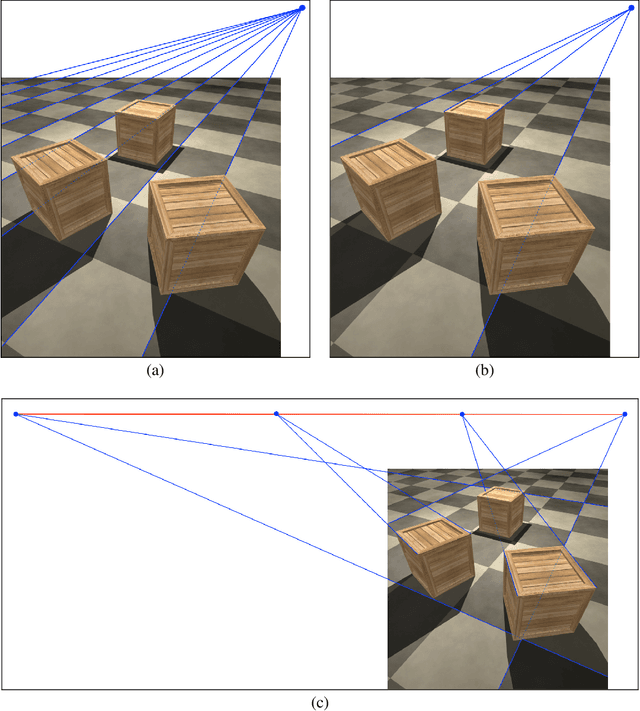

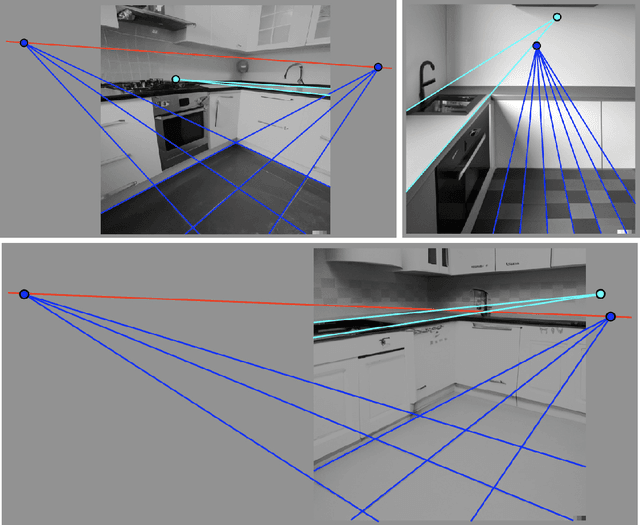

Type "a sea otter with a pearl earring by Johannes Vermeer" or "a photo of a teddy bear on a skateboard in Times Square" into OpenAI's DALL-E-2 paint-by-text synthesis engine and you will not be disappointed by the delightful and eerily pertinent results. The ability to synthesize highly realistic images -- with seemingly no limitation other than our imagination -- is sure to yield many exciting and creative applications. These images are also likely to pose new challenges to the photo-forensic community. Motivated by the fact that paint by text is not based on explicit geometric modeling, and the human visual system's often obliviousness to even glaring geometric inconsistencies, we provide an initial exploration of the perspective consistency of DALL-E-2 synthesized images to determine if geometric-based forensic analyses will prove fruitful in detecting this new breed of synthetic media.
3D-TOGO: Towards Text-Guided Cross-Category 3D Object Generation
Dec 02, 2022
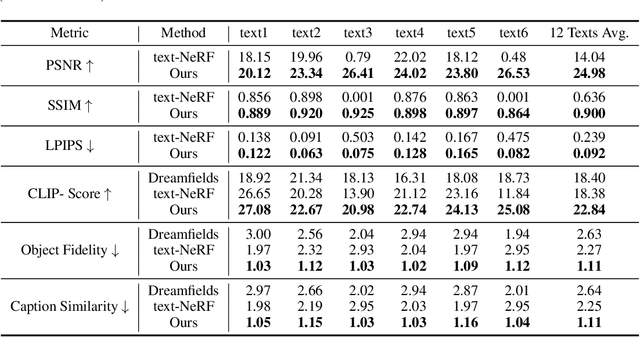
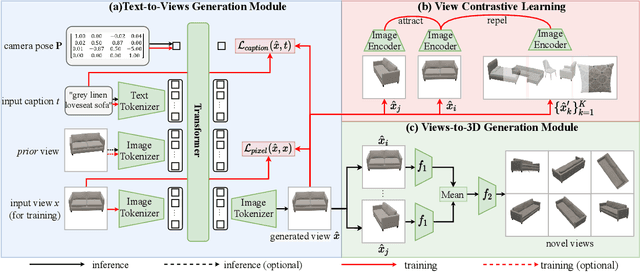
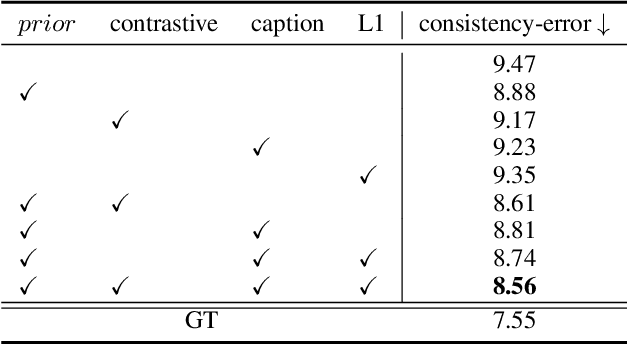
Text-guided 3D object generation aims to generate 3D objects described by user-defined captions, which paves a flexible way to visualize what we imagined. Although some works have been devoted to solving this challenging task, these works either utilize some explicit 3D representations (e.g., mesh), which lack texture and require post-processing for rendering photo-realistic views; or require individual time-consuming optimization for every single case. Here, we make the first attempt to achieve generic text-guided cross-category 3D object generation via a new 3D-TOGO model, which integrates a text-to-views generation module and a views-to-3D generation module. The text-to-views generation module is designed to generate different views of the target 3D object given an input caption. prior-guidance, caption-guidance and view contrastive learning are proposed for achieving better view-consistency and caption similarity. Meanwhile, a pixelNeRF model is adopted for the views-to-3D generation module to obtain the implicit 3D neural representation from the previously-generated views. Our 3D-TOGO model generates 3D objects in the form of the neural radiance field with good texture and requires no time-cost optimization for every single caption. Besides, 3D-TOGO can control the category, color and shape of generated 3D objects with the input caption. Extensive experiments on the largest 3D object dataset (i.e., ABO) are conducted to verify that 3D-TOGO can better generate high-quality 3D objects according to the input captions across 98 different categories, in terms of PSNR, SSIM, LPIPS and CLIP-score, compared with text-NeRF and Dreamfields.
Towards Hard-pose Virtual Try-on via 3D-aware Global Correspondence Learning
Nov 25, 2022
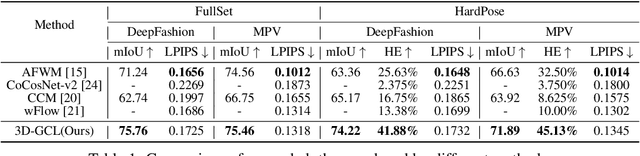
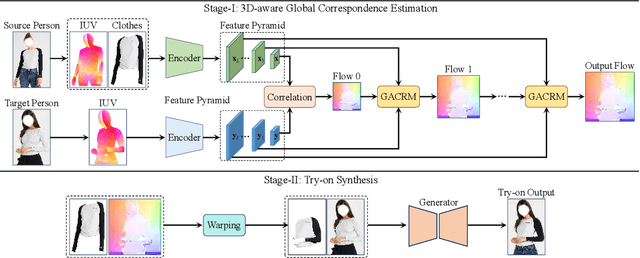
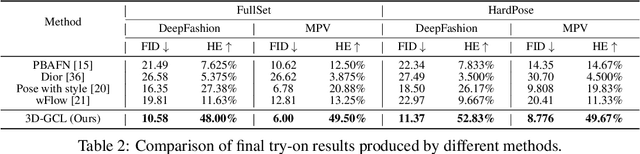
In this paper, we target image-based person-to-person virtual try-on in the presence of diverse poses and large viewpoint variations. Existing methods are restricted in this setting as they estimate garment warping flows mainly based on 2D poses and appearance, which omits the geometric prior of the 3D human body shape. Moreover, current garment warping methods are confined to localized regions, which makes them ineffective in capturing long-range dependencies and results in inferior flows with artifacts. To tackle these issues, we present 3D-aware global correspondences, which are reliable flows that jointly encode global semantic correlations, local deformations, and geometric priors of 3D human bodies. Particularly, given an image pair depicting the source and target person, (a) we first obtain their pose-aware and high-level representations via two encoders, and introduce a coarse-to-fine decoder with multiple refinement modules to predict the pixel-wise global correspondence. (b) 3D parametric human models inferred from images are incorporated as priors to regularize the correspondence refinement process so that our flows can be 3D-aware and better handle variations of pose and viewpoint. (c) Finally, an adversarial generator takes the garment warped by the 3D-aware flow, and the image of the target person as inputs, to synthesize the photo-realistic try-on result. Extensive experiments on public benchmarks and our HardPose test set demonstrate the superiority of our method against the SOTA try-on approaches.
Do Time Constraints Re-Prioritize Attention to Shapes During Visual Photo Inspection?
Apr 14, 2021
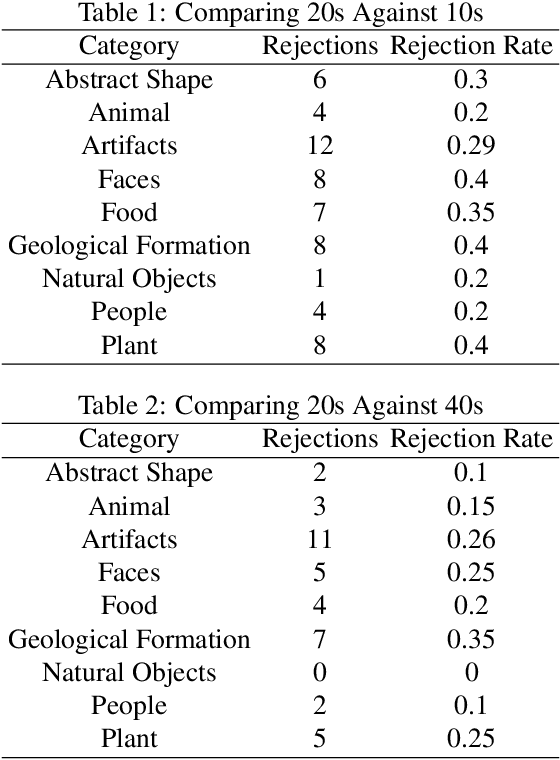


People's visual experiences of the world are easy to carve up and examine along natural language boundaries, e.g., by category labels, attribute labels, etc. However, it is more difficult to elicit detailed visuospatial information about what a person attends to, e.g., the specific shape of a tree. Paying attention to the shapes of things not only feeds into well defined tasks like visual category learning, but it is also what enables us to differentiate similarly named objects and to take on creative visual pursuits, like poetically describing the shape of a thing, or finding shapes in the clouds or stars. We use a new data collection method that elicits people's prioritized attention to shapes during visual photo inspection by asking them to trace important parts of the image under varying time constraints. Using data collected via crowdsourcing over a set of 187 photographs, we examine changes in patterns of visual attention across individuals, across image types, and across time constraints.
Learning to Aggregate and Personalize 3D Face from In-the-Wild Photo Collection
Jun 15, 2021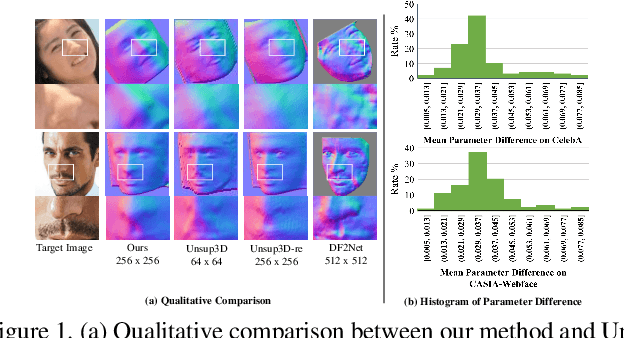
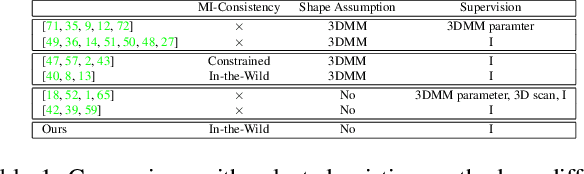
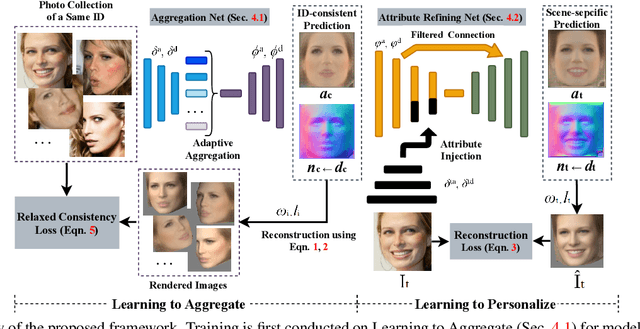
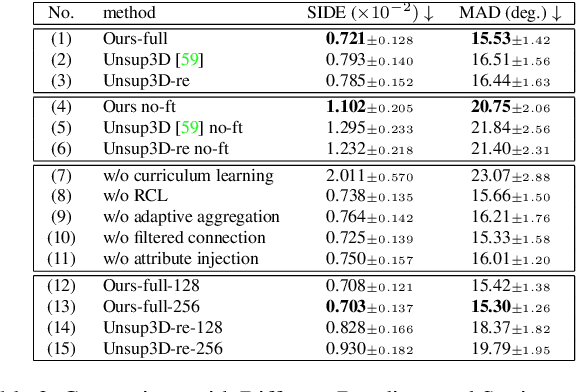
Non-parametric face modeling aims to reconstruct 3D face only from images without shape assumptions. While plausible facial details are predicted, the models tend to over-depend on local color appearance and suffer from ambiguous noise. To address such problem, this paper presents a novel Learning to Aggregate and Personalize (LAP) framework for unsupervised robust 3D face modeling. Instead of using controlled environment, the proposed method implicitly disentangles ID-consistent and scene-specific face from unconstrained photo set. Specifically, to learn ID-consistent face, LAP adaptively aggregates intrinsic face factors of an identity based on a novel curriculum learning approach with relaxed consistency loss. To adapt the face for a personalized scene, we propose a novel attribute-refining network to modify ID-consistent face with target attribute and details. Based on the proposed method, we make unsupervised 3D face modeling benefit from meaningful image facial structure and possibly higher resolutions. Extensive experiments on benchmarks show LAP recovers superior or competitive face shape and texture, compared with state-of-the-art (SOTA) methods with or without prior and supervision.