 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Towards Practicality of Sketch-Based Visual Understanding
Oct 27, 2022

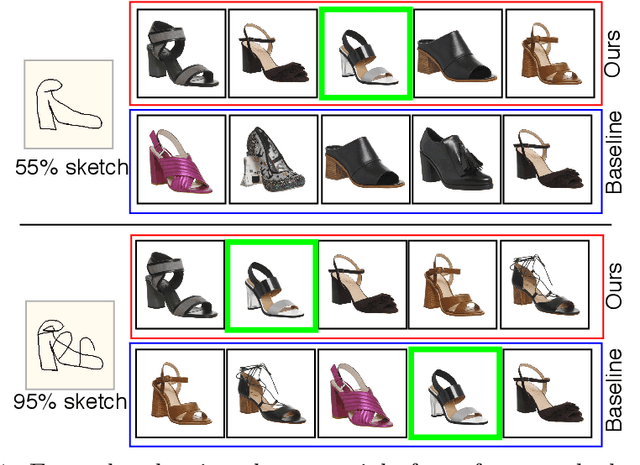
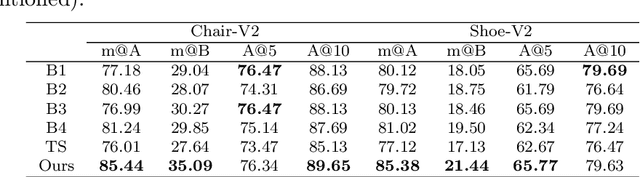
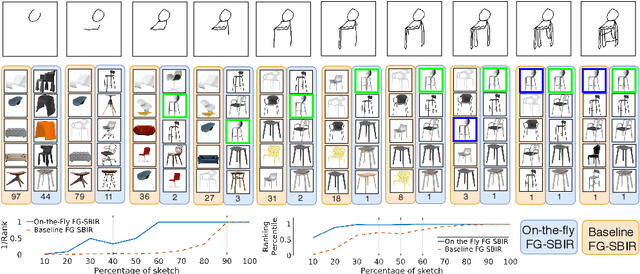
Sketches have been used to conceptualise and depict visual objects from pre-historic times. Sketch research has flourished in the past decade, particularly with the proliferation of touchscreen devices. Much of the utilisation of sketch has been anchored around the fact that it can be used to delineate visual concepts universally irrespective of age, race, language, or demography. The fine-grained interactive nature of sketches facilitates the application of sketches to various visual understanding tasks, like image retrieval, image-generation or editing, segmentation, 3D-shape modelling etc. However, sketches are highly abstract and subjective based on the perception of individuals. Although most agree that sketches provide fine-grained control to the user to depict a visual object, many consider sketching a tedious process due to their limited sketching skills compared to other query/support modalities like text/tags. Furthermore, collecting fine-grained sketch-photo association is a significant bottleneck to commercialising sketch applications. Therefore, this thesis aims to progress sketch-based visual understanding towards more practicality.
3D Scene Creation and Rendering via Rough Meshes: A Lighting Transfer Avenue
Nov 27, 2022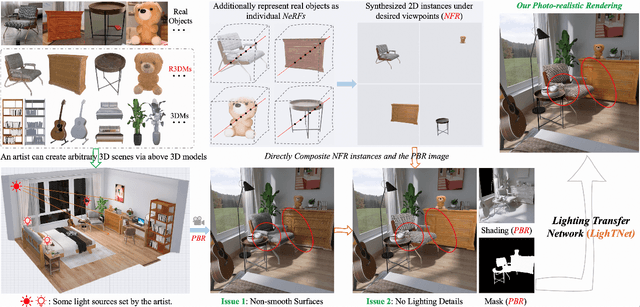
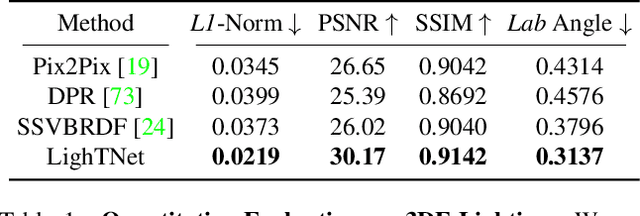

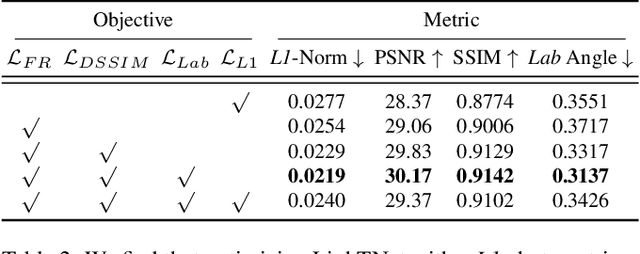
This paper studies how to flexibly integrate reconstructed 3D models into practical 3D modeling pipelines such as 3D scene creation and rendering. Due to the technical difficulty, one can only obtain rough 3D models (R3DMs) for most real objects using existing 3D reconstruction techniques. As a result, physically-based rendering (PBR) would render low-quality images or videos for scenes that are constructed by R3DMs. One promising solution would be representing real-world objects as Neural Fields such as NeRFs, which are able to generate photo-realistic renderings of an object under desired viewpoints. However, a drawback is that the synthesized views through Neural Fields Rendering (NFR) cannot reflect the simulated lighting details on R3DMs in PBR pipelines, especially when object interactions in the 3D scene creation cause local shadows. To solve this dilemma, we propose a lighting transfer network (LighTNet) to bridge NFR and PBR, such that they can benefit from each other. LighTNet reasons about a simplified image composition model, remedies the uneven surface issue caused by R3DMs, and is empowered by several perceptual-motivated constraints and a new Lab angle loss which enhances the contrast between lighting strength and colors. Comparisons demonstrate that LighTNet is superior in synthesizing impressive lighting, and is promising in pushing NFR further in practical 3D modeling workflows. Project page: https://3d-front-future.github.io/LighTNet .
Neural Sign Reenactor: Deep Photorealistic Sign Language Retargeting
Sep 03, 2022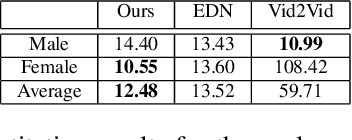
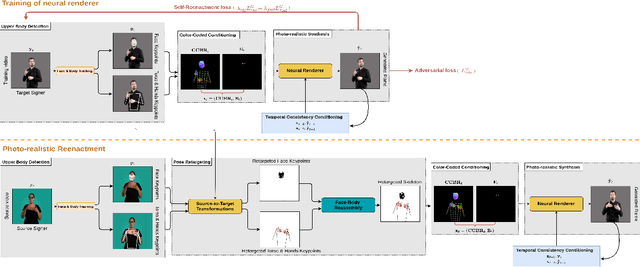

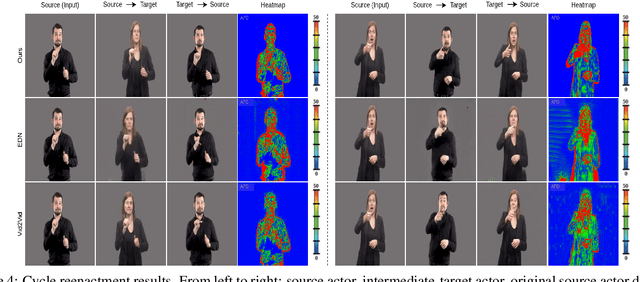
In this paper, we introduce a neural rendering pipeline for transferring the facial expressions, head pose and body movements of one person in a source video to another in a target video. We apply our method to the challenging case of Sign Language videos: given a source video of a sign language user, we can faithfully transfer the performed manual (e.g. handshape, palm orientation, movement, location) and non-manual (e.g. eye gaze, facial expressions, head movements) signs to a target video in a photo-realistic manner. To effectively capture the aforementioned cues, which are crucial for sign language communication, we build upon an effective combination of the most robust and reliable deep learning methods for body, hand and face tracking that have been introduced lately. Using a 3D-aware representation, the estimated motions of the body parts are combined and retargeted to the target signer. They are then given as conditional input to our Video Rendering Network, which generates temporally consistent and photo-realistic videos. We conduct detailed qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and its advantages over existing approaches. Our method yields promising results of unprecedented realism and can be used for Sign Language Anonymization. In addition, it can be readily applicable to reenactment of other types of full body activities (dancing, acting performance, exercising, etc.), as well as to the synthesis module of Sign Language Production systems.
A Novel Active Solution for Two-Dimensional Face Presentation Attack Detection
Dec 14, 2022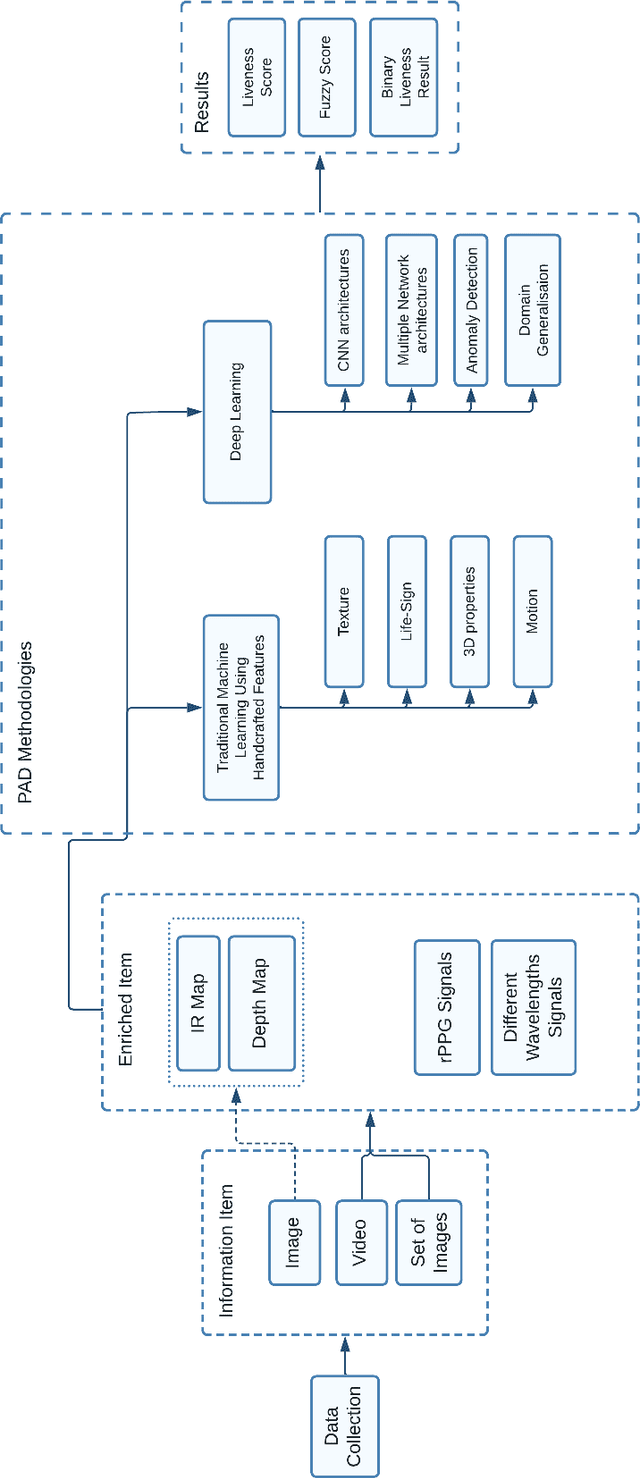

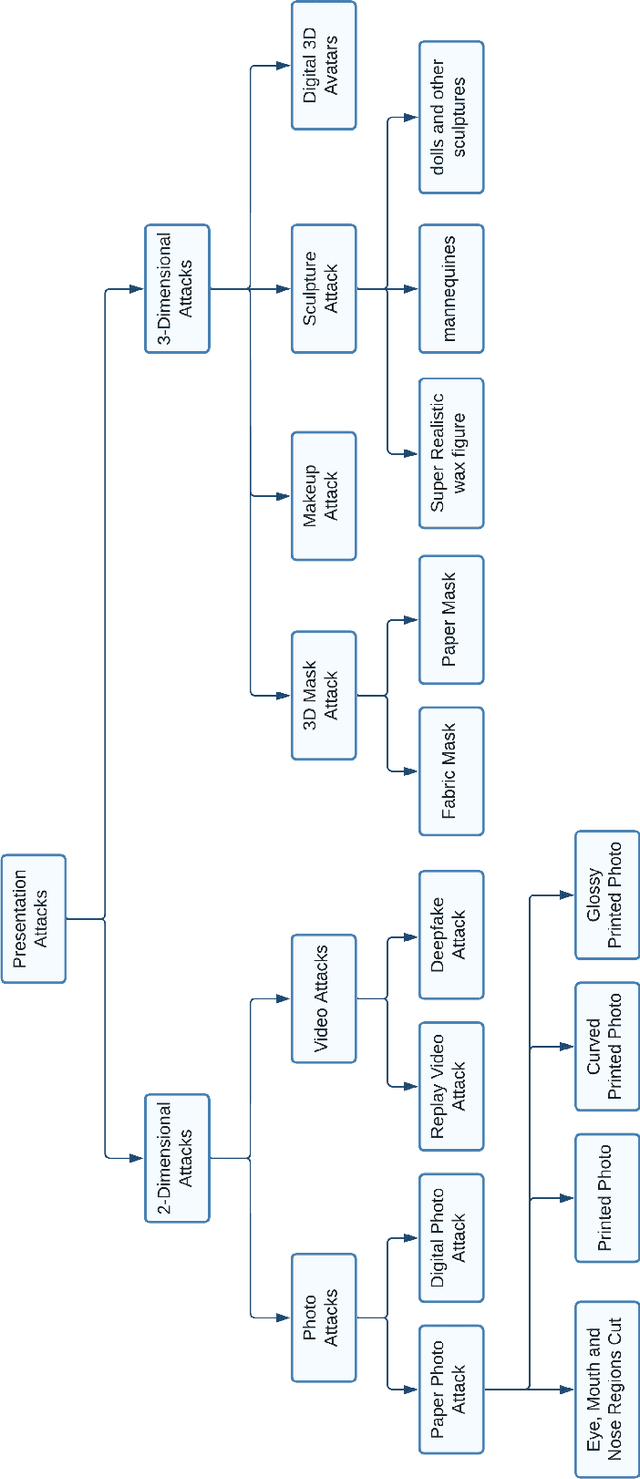
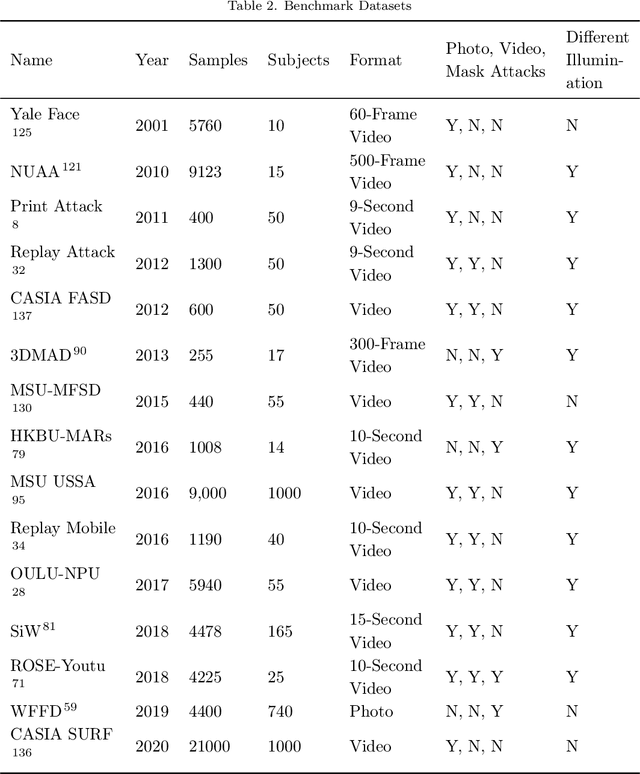
Identity authentication is the process of verifying one's identity. There are several identity authentication methods, among which biometric authentication is of utmost importance. Facial recognition is a sort of biometric authentication with various applications, such as unlocking mobile phones and accessing bank accounts. However, presentation attacks pose the greatest threat to facial recognition. A presentation attack is an attempt to present a non-live face, such as a photo, video, mask, and makeup, to the camera. Presentation attack detection is a countermeasure that attempts to identify between a genuine user and a presentation attack. Several industries, such as financial services, healthcare, and education, use biometric authentication services on various devices. This illustrates the significance of presentation attack detection as the verification step. In this paper, we study state-of-the-art to cover the challenges and solutions related to presentation attack detection in a single place. We identify and classify different presentation attack types and identify the state-of-the-art methods that could be used to detect each of them. We compare the state-of-the-art literature regarding attack types, evaluation metrics, accuracy, and datasets and discuss research and industry challenges of presentation attack detection. Most presentation attack detection approaches rely on extensive data training and quality, making them difficult to implement. We introduce an efficient active presentation attack detection approach that overcomes weaknesses in the existing literature. The proposed approach does not require training data, is CPU-light, can process low-quality images, has been tested with users of various ages and is shown to be user-friendly and highly robust to 2-dimensional presentation attacks.
High-Quality Facial Photo-Sketch Synthesis Using Multi-Adversarial Networks
Mar 03, 2018



Synthesizing face sketches from real photos and its inverse have many applications. However, photo/sketch synthesis remains a challenging problem due to the fact that photo and sketch have different characteristics. In this work, we consider this task as an image-to-image translation problem and explore the recently popular generative models (GANs) to generate high-quality realistic photos from sketches and sketches from photos. Recent GAN-based methods have shown promising results on image-to-image translation problems and photo-to-sketch synthesis in particular, however, they are known to have limited abilities in generating high-resolution realistic images. To this end, we propose a novel synthesis framework called Photo-Sketch Synthesis using Multi-Adversarial Networks, (PS2-MAN) that iteratively generates low resolution to high resolution images in an adversarial way. The hidden layers of the generator are supervised to first generate lower resolution images followed by implicit refinement in the network to generate higher resolution images. Furthermore, since photo-sketch synthesis is a coupled/paired translation problem, we leverage the pair information using CycleGAN framework. Both Image Quality Assessment (IQA) and Photo-Sketch Matching experiments are conducted to demonstrate the superior performance of our framework in comparison to existing state-of-the-art solutions. Code available at: https://github.com/lidan1/PhotoSketchMAN.
How Real is Real: Evaluating the Robustness of Real-World Super Resolution
Oct 22, 2022
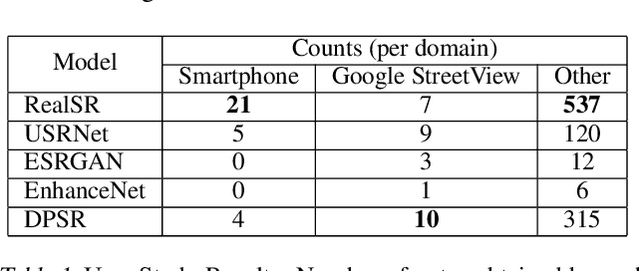

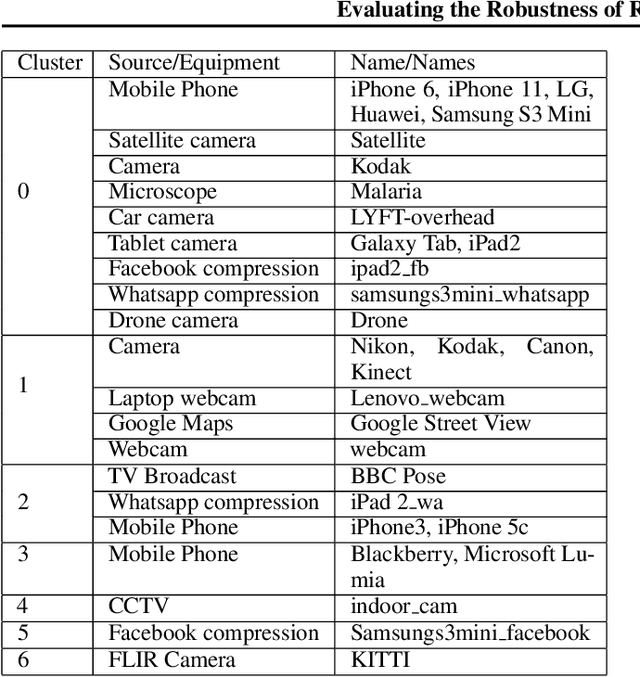
Image super-resolution (SR) is a field in computer vision that focuses on reconstructing high-resolution images from the respective low-resolution image. However, super-resolution is a well-known ill-posed problem as most methods rely on the downsampling method performed on the high-resolution image to form the low-resolution image to be known. Unfortunately, this is not something that is available in real-life super-resolution applications such as increasing the quality of a photo taken on a mobile phone. In this paper we will evaluate multiple state-of-the-art super-resolution methods and gauge their performance when presented with various types of real-life images and discuss the benefits and drawbacks of each method. We also introduce a novel dataset, WideRealSR, containing real images from a wide variety of sources. Finally, through careful experimentation and evaluation, we will present a potential solution to alleviate the generalization problem which is imminent in most state-of-the-art super-resolution models.
Photo-Realistic Blocksworld Dataset
Dec 05, 2018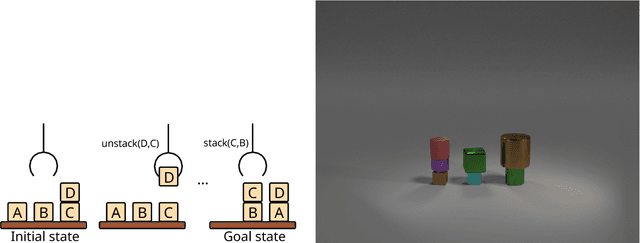

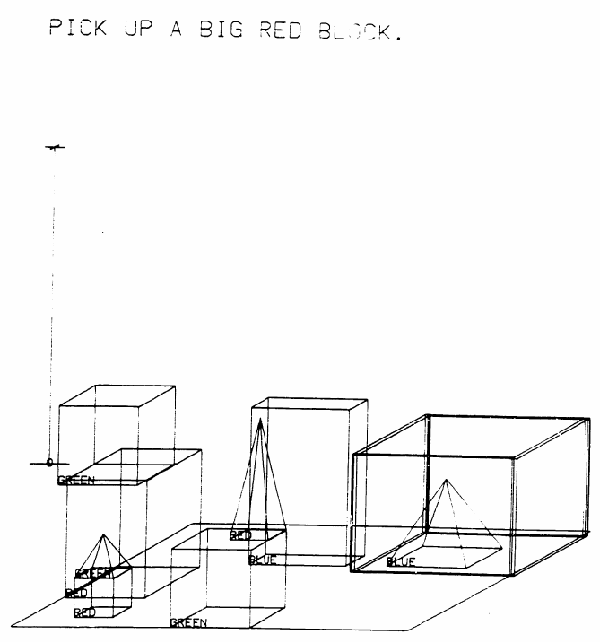

In this report, we introduce an artificial dataset generator for Photo-realistic Blocksworld domain. Blocksworld is one of the oldest high-level task planning domain that is well defined but contains sufficient complexity, e.g., the conflicting subgoals and the decomposability into subproblems. We aim to make this dataset a benchmark for Neural-Symbolic integrated systems and accelerate the research in this area. The key advantage of such systems is the ability to obtain a symbolic model from the real-world input and perform a fast, systematic, complete algorithm for symbolic reasoning, without any supervision and the reward signal from the environment.
SeaDroneSim: Simulation of Aerial Images for Detection of Objects Above Water
Oct 31, 2022



Unmanned Aerial Vehicles (UAVs) are known for their fast and versatile applicability. With UAVs' growth in availability and applications, they are now of vital importance in serving as technological support in search-and-rescue(SAR) operations in marine environments. High-resolution cameras and GPUs can be equipped on the UAVs to provide effective and efficient aid to emergency rescue operations. With modern computer vision algorithms, we can detect objects for aiming such rescue missions. However, these modern computer vision algorithms are dependent on numerous amounts of training data from UAVs, which is time-consuming and labor-intensive for maritime environments. To this end, we present a new benchmark suite, SeaDroneSim, that can be used to create photo-realistic aerial image datasets with the ground truth for segmentation masks of any given object. Utilizing only the synthetic data generated from SeaDroneSim, we obtain 71 mAP on real aerial images for detecting BlueROV as a feasibility study. This result from the new simulation suit also serves as a baseline for the detection of BlueROV.
Latent Video Diffusion Models for High-Fidelity Video Generation with Arbitrary Lengths
Nov 23, 2022

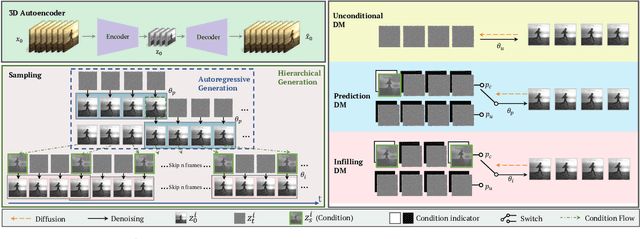
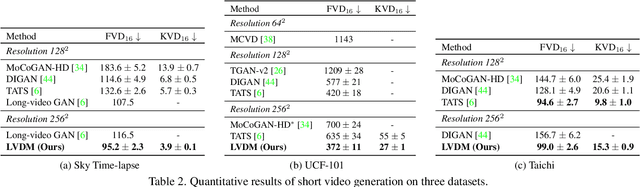
AI-generated content has attracted lots of attention recently, but photo-realistic video synthesis is still challenging. Although many attempts using GANs and autoregressive models have been made in this area, the visual quality and length of generated videos are far from satisfactory. Diffusion models (DMs) are another class of deep generative models and have recently achieved remarkable performance on various image synthesis tasks. However, training image diffusion models usually requires substantial computational resources to achieve a high performance, which makes expanding diffusion models to high-dimensional video synthesis tasks more computationally expensive. To ease this problem while leveraging its advantages, we introduce lightweight video diffusion models that synthesize high-fidelity and arbitrary-long videos from pure noise. Specifically, we propose to perform diffusion and denoising in a low-dimensional 3D latent space, which significantly outperforms previous methods on 3D pixel space when under a limited computational budget. In addition, though trained on tens of frames, our models can generate videos with arbitrary lengths, i.e., thousands of frames, in an autoregressive way. Finally, conditional latent perturbation is further introduced to reduce performance degradation during synthesizing long-duration videos. Extensive experiments on various datasets and generated lengths suggest that our framework is able to sample much more realistic and longer videos than previous approaches, including GAN-based, autoregressive-based, and diffusion-based methods.
Removing grid structure in angle-resolved photoemission spectra via deep learning method
Oct 20, 2022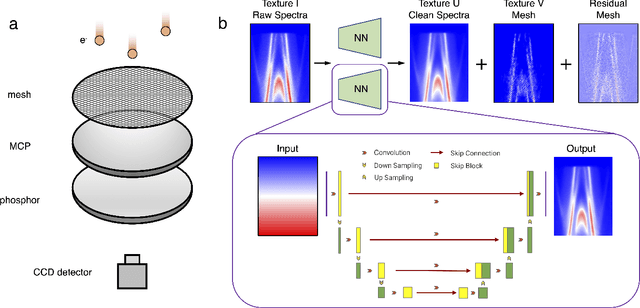
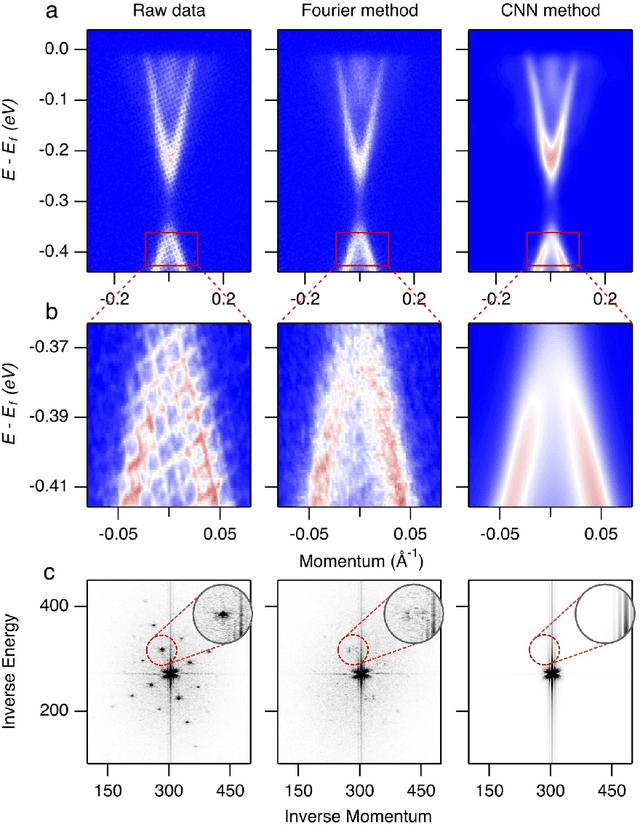
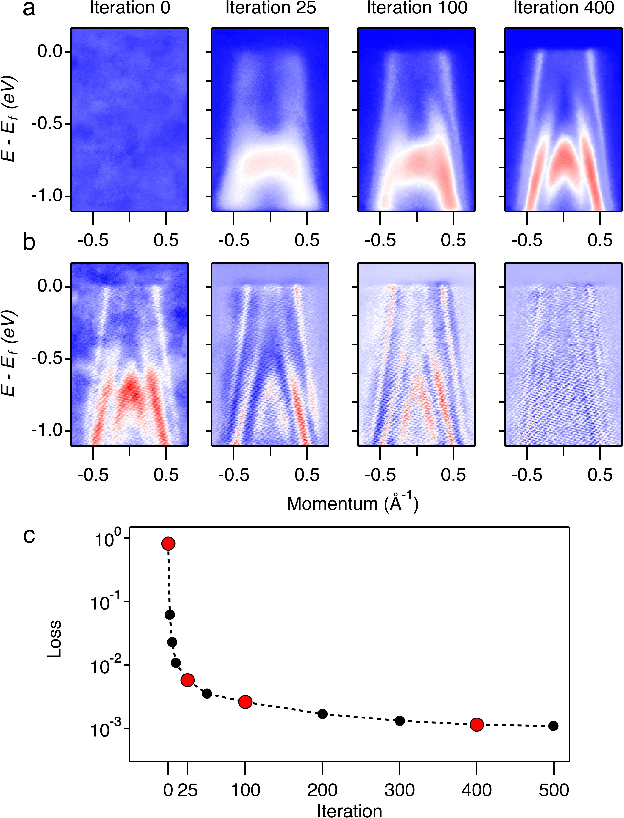
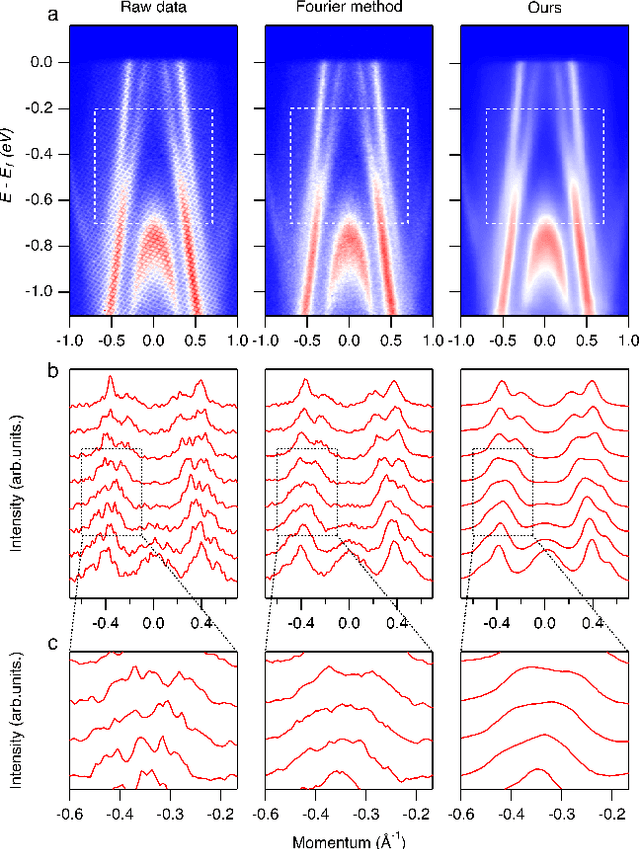
Spectroscopic data may often contain unwanted extrinsic signals. For example, in ARPES experiment, a wire mesh is typically placed in front of the CCD to block stray photo-electrons, but could cause a grid-like structure in the spectra during quick measurement mode. In the past, this structure was often removed using the mathematical Fourier filtering method by erasing the periodic structure. However, this method may lead to information loss and vacancies in the spectra because the grid structure is not strictly linearly superimposed. Here, we propose a deep learning method to effectively overcome this problem. Our method takes advantage of the self-correlation information within the spectra themselves and can greatly optimize the quality of the spectra while removing the grid structure and noise simultaneously. It has the potential to be extended to all spectroscopic measurements to eliminate other extrinsic signals and enhance the spectral quality based on the self-correlation of the spectra solely.