 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
DynIBaR: Neural Dynamic Image-Based Rendering
Nov 20, 2022
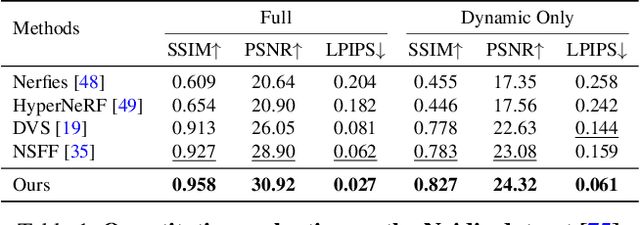
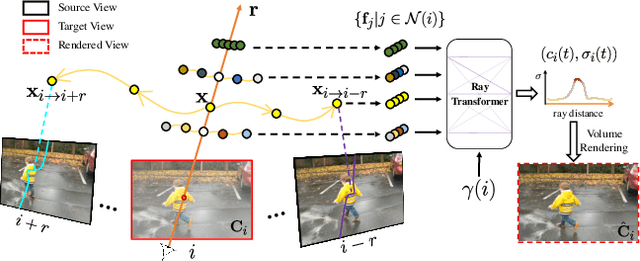
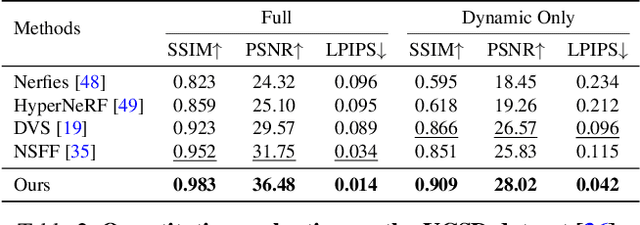
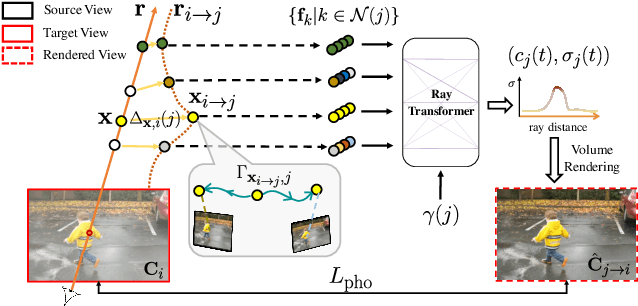
We address the problem of synthesizing novel views from a monocular video depicting a complex dynamic scene. State-of-the-art methods based on temporally varying Neural Radiance Fields (aka dynamic NeRFs) have shown impressive results on this task. However, for long videos with complex object motions and uncontrolled camera trajectories, these methods can produce blurry or inaccurate renderings, hampering their use in real-world applications. Instead of encoding the entire dynamic scene within the weights of an MLP, we present a new approach that addresses these limitations by adopting a volumetric image-based rendering framework that synthesizes new viewpoints by aggregating features from nearby views in a scene-motion-aware manner. Our system retains the advantages of prior methods in its ability to model complex scenes and view-dependent effects, but also enables synthesizing photo-realistic novel views from long videos featuring complex scene dynamics with unconstrained camera trajectories. We demonstrate significant improvements over state-of-the-art methods on dynamic scene datasets, and also apply our approach to in-the-wild videos with challenging camera and object motion, where prior methods fail to produce high-quality renderings. Our project webpage is at dynibar.github.io.
3D Scene Creation and Rendering via Rough Meshes: A Lighting Transfer Avenue
Dec 04, 2022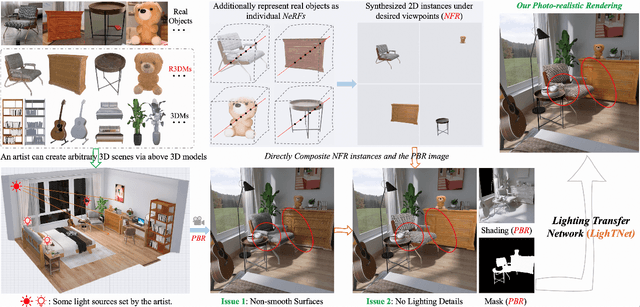
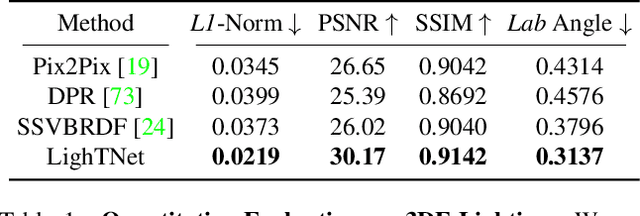

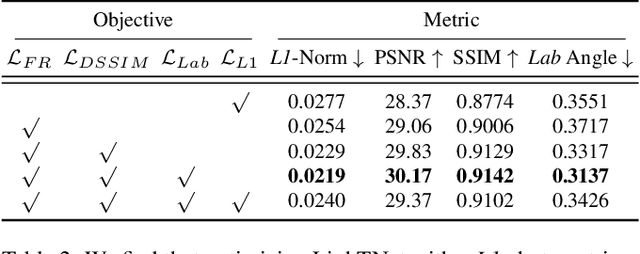
This paper studies how to flexibly integrate reconstructed 3D models into practical 3D modeling pipelines such as 3D scene creation and rendering. Due to the technical difficulty, one can only obtain rough 3D models (R3DMs) for most real objects using existing 3D reconstruction techniques. As a result, physically-based rendering (PBR) would render low-quality images or videos for scenes that are constructed by R3DMs. One promising solution would be representing real-world objects as Neural Fields such as NeRFs, which are able to generate photo-realistic renderings of an object under desired viewpoints. However, a drawback is that the synthesized views through Neural Fields Rendering (NFR) cannot reflect the simulated lighting details on R3DMs in PBR pipelines, especially when object interactions in the 3D scene creation cause local shadows. To solve this dilemma, we propose a lighting transfer network (LighTNet) to bridge NFR and PBR, such that they can benefit from each other. LighTNet reasons about a simplified image composition model, remedies the uneven surface issue caused by R3DMs, and is empowered by several perceptual-motivated constraints and a new Lab angle loss which enhances the contrast between lighting strength and colors. Comparisons demonstrate that LighTNet is superior in synthesizing impressive lighting, and is promising in pushing NFR further in practical 3D modeling workflows. Project page: https://3d-front-future.github.io/LighTNet .
Human Performance Modeling and Rendering via Neural Animated Mesh
Sep 18, 2022

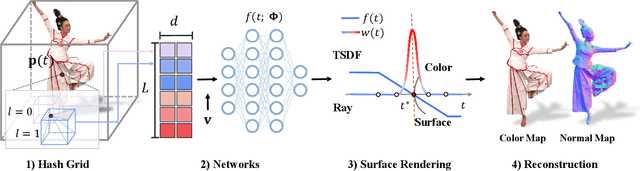
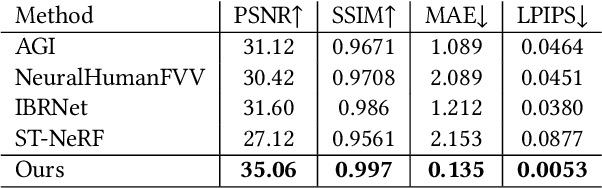
We have recently seen tremendous progress in the neural advances for photo-real human modeling and rendering. However, it's still challenging to integrate them into an existing mesh-based pipeline for downstream applications. In this paper, we present a comprehensive neural approach for high-quality reconstruction, compression, and rendering of human performances from dense multi-view videos. Our core intuition is to bridge the traditional animated mesh workflow with a new class of highly efficient neural techniques. We first introduce a neural surface reconstructor for high-quality surface generation in minutes. It marries the implicit volumetric rendering of the truncated signed distance field (TSDF) with multi-resolution hash encoding. We further propose a hybrid neural tracker to generate animated meshes, which combines explicit non-rigid tracking with implicit dynamic deformation in a self-supervised framework. The former provides the coarse warping back into the canonical space, while the latter implicit one further predicts the displacements using the 4D hash encoding as in our reconstructor. Then, we discuss the rendering schemes using the obtained animated meshes, ranging from dynamic texturing to lumigraph rendering under various bandwidth settings. To strike an intricate balance between quality and bandwidth, we propose a hierarchical solution by first rendering 6 virtual views covering the performer and then conducting occlusion-aware neural texture blending. We demonstrate the efficacy of our approach in a variety of mesh-based applications and photo-realistic free-view experiences on various platforms, i.e., inserting virtual human performances into real environments through mobile AR or immersively watching talent shows with VR headsets.
Expanding Small-Scale Datasets with Guided Imagination
Nov 25, 2022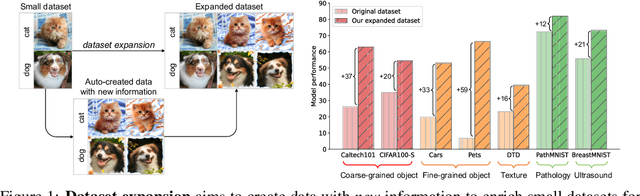
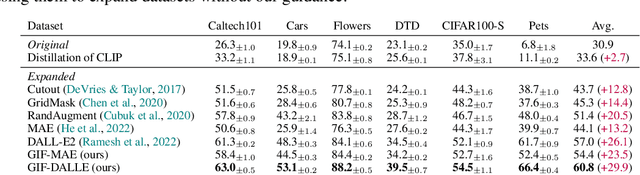
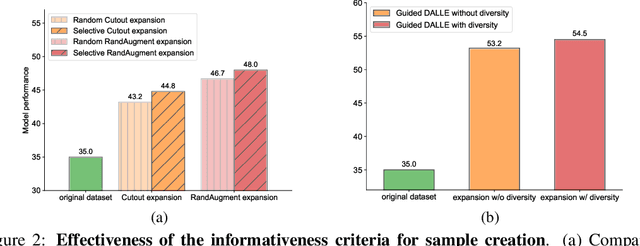

The power of Deep Neural Networks (DNNs) depends heavily on the training data quantity, quality and diversity. However, in many real scenarios, it is costly and time-consuming to collect and annotate large-scale data. This has severely hindered the application of DNNs. To address this challenge, we explore a new task of dataset expansion, which seeks to automatically create new labeled samples to expand a small dataset. To this end, we present a Guided Imagination Framework (GIF) that leverages the recently developed big generative models (e.g., DALL-E2) and reconstruction models (e.g., MAE) to "imagine" and create informative new data from seed data to expand small datasets. Specifically, GIF conducts imagination by optimizing the latent features of seed data in a semantically meaningful space, which are fed into the generative models to generate photo-realistic images with new contents. For guiding the imagination towards creating samples useful for model training, we exploit the zero-shot recognition ability of CLIP and introduce three criteria to encourage informative sample generation, i.e., prediction consistency, entropy maximization and diversity promotion. With these essential criteria as guidance, GIF works well for expanding datasets in different domains, leading to 29.9% accuracy gain on average over six natural image datasets, and 12.3% accuracy gain on average over three medical image datasets.
MAOMaps: A Photo-Realistic Benchmark For vSLAM and Map Merging Quality Assessment
May 31, 2021
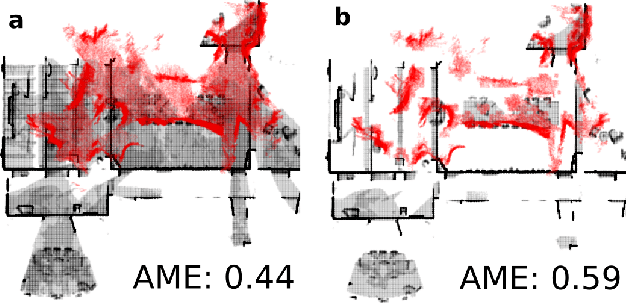
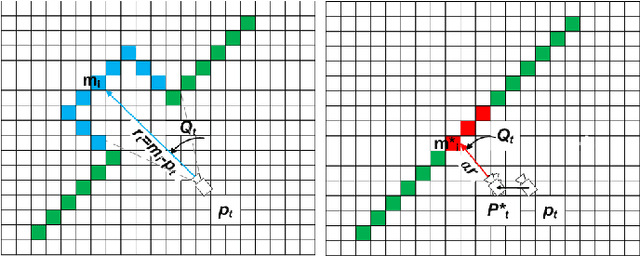
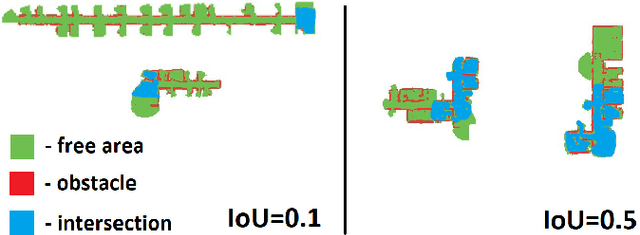
Running numerous experiments in simulation is a necessary step before deploying a control system on a real robot. In this paper we introduce a novel benchmark that is aimed at quantitatively evaluating the quality of vision-based simultaneous localization and mapping (vSLAM) and map merging algorithms. The benchmark consists of both a dataset and a set of tools for automatic evaluation. The dataset is photo-realistic and provides both the localization and the map ground truth data. This makes it possible to evaluate not only the localization part of the SLAM pipeline but the mapping part as well. To compare the vSLAM-built maps and the ground-truth ones we introduce a novel way to find correspondences between them that takes the SLAM context into account (as opposed to other approaches like nearest neighbors). The benchmark is ROS-compatable and is open-sourced to the community. The data and the code are available at: \texttt{github.com/CnnDepth/MAOMaps}.
Re-Imagen: Retrieval-Augmented Text-to-Image Generator
Oct 01, 2022

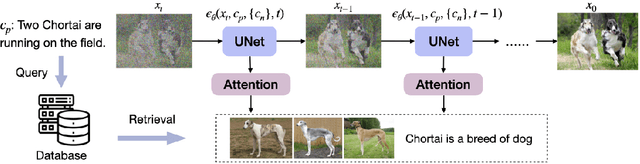
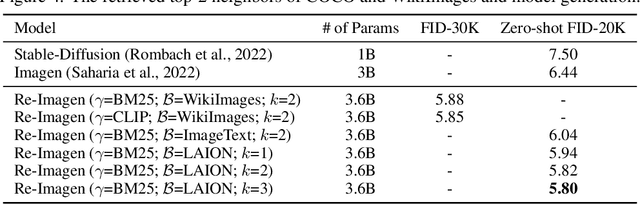
Research on text-to-image generation has witnessed significant progress in generating diverse and photo-realistic images, driven by diffusion and auto-regressive models trained on large-scale image-text data. Though state-of-the-art models can generate high-quality images of common entities, they often have difficulty generating images of uncommon entities, such as `Chortai (dog)' or `Picarones (food)'. To tackle this issue, we present the Retrieval-Augmented Text-to-Image Generator (Re-Imagen), a generative model that uses retrieved information to produce high-fidelity and faithful images, even for rare or unseen entities. Given a text prompt, Re-Imagen accesses an external multi-modal knowledge base to retrieve relevant (image, text) pairs, and uses them as references to generate the image. With this retrieval step, Re-Imagen is augmented with the knowledge of high-level semantics and low-level visual details of the mentioned entities, and thus improves its accuracy in generating the entities' visual appearances. We train Re-Imagen on a constructed dataset containing (image, text, retrieval) triples to teach the model to ground on both text prompt and retrieval. Furthermore, we develop a new sampling strategy to interleave the classifier-free guidance for text and retrieval condition to balance the text and retrieval alignment. Re-Imagen achieves new SoTA FID results on two image generation benchmarks, such as COCO (ie, FID = 5.25) and WikiImage (ie, FID = 5.82) without fine-tuning. To further evaluate the capabilities of the model, we introduce EntityDrawBench, a new benchmark that evaluates image generation for diverse entities, from frequent to rare, across multiple visual domains. Human evaluation on EntityDrawBench shows that Re-Imagen performs on par with the best prior models in photo-realism, but with significantly better faithfulness, especially on less frequent entities.
Is synthetic data from generative models ready for image recognition?
Oct 14, 2022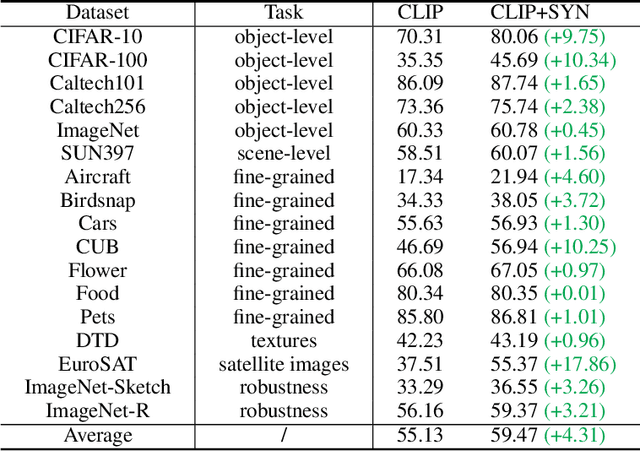
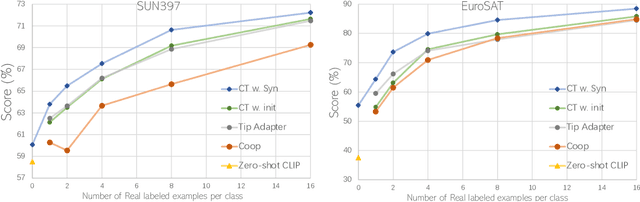
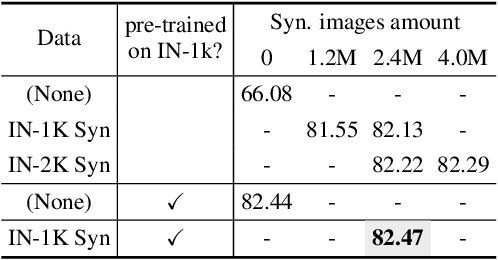

Recent text-to-image generation models have shown promising results in generating high-fidelity photo-realistic images. Though the results are astonishing to human eyes, how applicable these generated images are for recognition tasks remains under-explored. In this work, we extensively study whether and how synthetic images generated from state-of-the-art text-to-image generation models can be used for image recognition tasks, and focus on two perspectives: synthetic data for improving classification models in data-scarce settings (i.e. zero-shot and few-shot), and synthetic data for large-scale model pre-training for transfer learning. We showcase the powerfulness and shortcomings of synthetic data from existing generative models, and propose strategies for better applying synthetic data for recognition tasks. Code: https://github.com/CVMI-Lab/SyntheticData.
Learned Smartphone ISP on Mobile GPUs with Deep Learning, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022
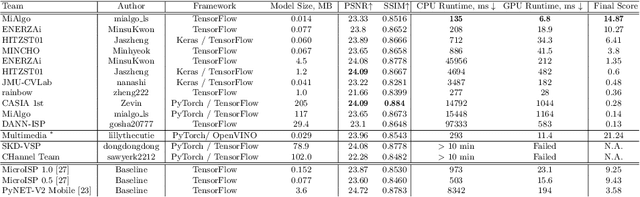
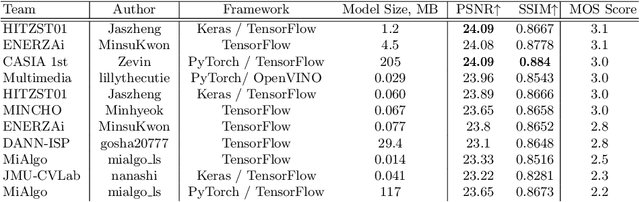
The role of mobile cameras increased dramatically over the past few years, leading to more and more research in automatic image quality enhancement and RAW photo processing. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based image signal processing (ISP) pipeline replacing the standard mobile ISPs that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The runtime of the resulting models was evaluated on the Snapdragon's 8 Gen 1 GPU that provides excellent acceleration results for the majority of common deep learning ops. The proposed solutions are compatible with all recent mobile GPUs, being able to process Full HD photos in less than 20-50 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Photo style transfer with consistency losses
May 09, 2020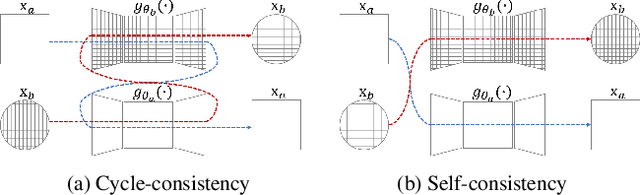


We address the problem of style transfer between two photos and propose a new way to preserve photorealism. Using the single pair of photos available as input, we train a pair of deep convolution networks (convnets), each of which transfers the style of one photo to the other. To enforce photorealism, we introduce a content preserving mechanism by combining a cycle-consistency loss with a self-consistency loss. Experimental results show that this method does not suffer from typical artifacts observed in methods working in the same settings. We then further analyze some properties of these trained convnets. First, we notice that they can be used to stylize other unseen images with same known style. Second, we show that retraining only a small subset of the network parameters can be sufficient to adapt these convnets to new styles.