 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
STEPS: Joint Self-supervised Nighttime Image Enhancement and Depth Estimation
Feb 02, 2023
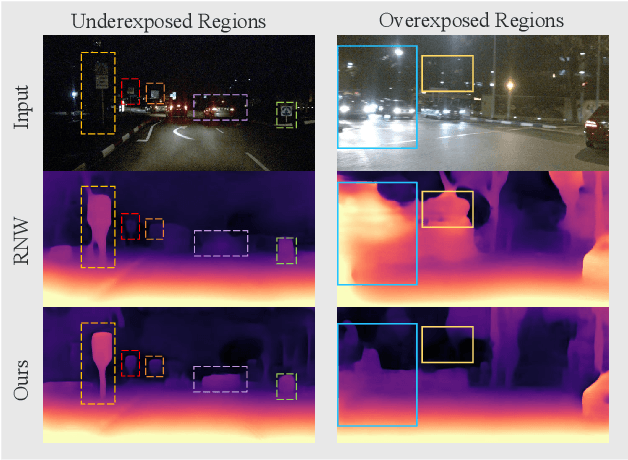
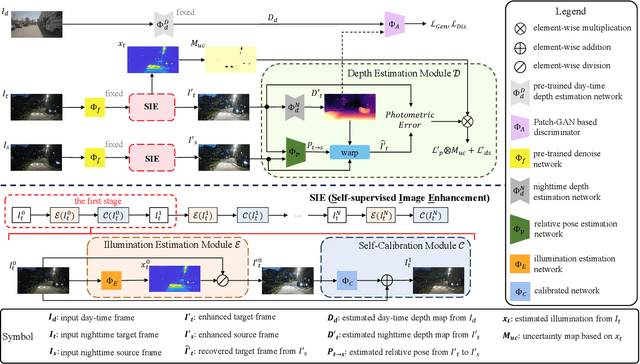

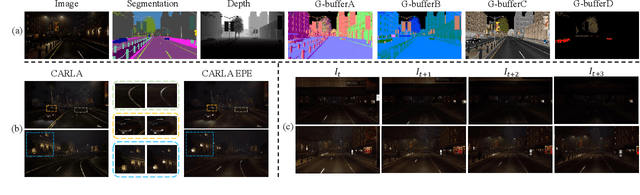
Self-supervised depth estimation draws a lot of attention recently as it can promote the 3D sensing capabilities of self-driving vehicles. However, it intrinsically relies upon the photometric consistency assumption, which hardly holds during nighttime. Although various supervised nighttime image enhancement methods have been proposed, their generalization performance in challenging driving scenarios is not satisfactory. To this end, we propose the first method that jointly learns a nighttime image enhancer and a depth estimator, without using ground truth for either task. Our method tightly entangles two self-supervised tasks using a newly proposed uncertain pixel masking strategy. This strategy originates from the observation that nighttime images not only suffer from underexposed regions but also from overexposed regions. By fitting a bridge-shaped curve to the illumination map distribution, both regions are suppressed and two tasks are bridged naturally. We benchmark the method on two established datasets: nuScenes and RobotCar and demonstrate state-of-the-art performance on both of them. Detailed ablations also reveal the mechanism of our proposal. Last but not least, to mitigate the problem of sparse ground truth of existing datasets, we provide a new photo-realistically enhanced nighttime dataset based upon CARLA. It brings meaningful new challenges to the community. Codes, data, and models are available at https://github.com/ucaszyp/STEPS.
Unsupervised Light Field Depth Estimation via Multi-view Feature Matching with Occlusion Prediction
Jan 20, 2023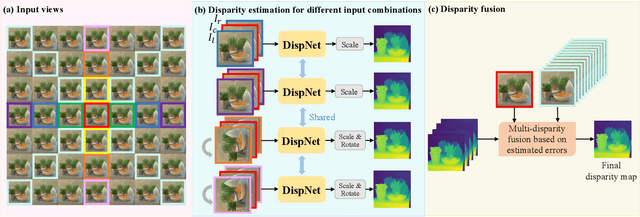
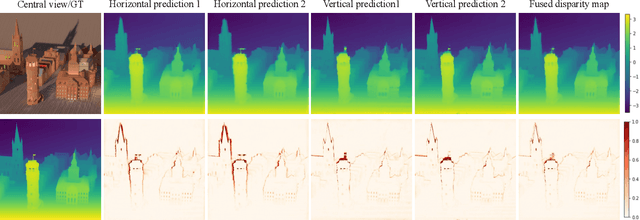
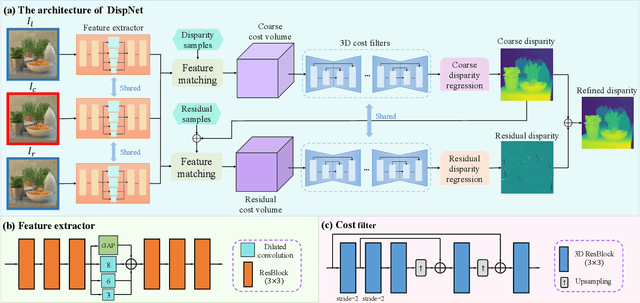
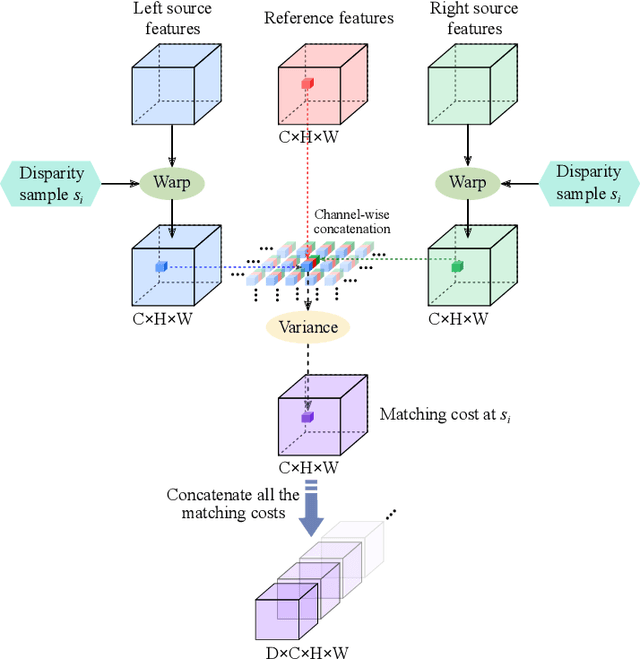
Depth estimation from light field (LF) images is a fundamental step for some applications. Recently, learning-based methods have achieved higher accuracy and efficiency than the traditional methods. However, it is costly to obtain sufficient depth labels for supervised training. In this paper, we propose an unsupervised framework to estimate depth from LF images. First, we design a disparity estimation network (DispNet) with a coarse-to-fine structure to predict disparity maps from different view combinations by performing multi-view feature matching to learn the correspondences more effectively. As occlusions may cause the violation of photo-consistency, we design an occlusion prediction network (OccNet) to predict the occlusion maps, which are used as the element-wise weights of photometric loss to solve the occlusion issue and assist the disparity learning. With the disparity maps estimated by multiple input combinations, we propose a disparity fusion strategy based on the estimated errors with effective occlusion handling to obtain the final disparity map. Experimental results demonstrate that our method achieves superior performance on both the dense and sparse LF images, and also has better generalization ability to the real-world LF images.
GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis
Jan 30, 2023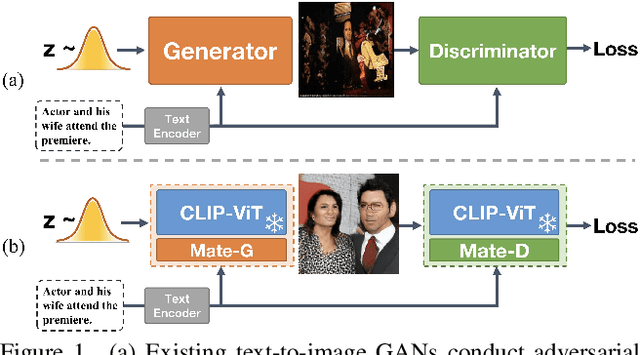
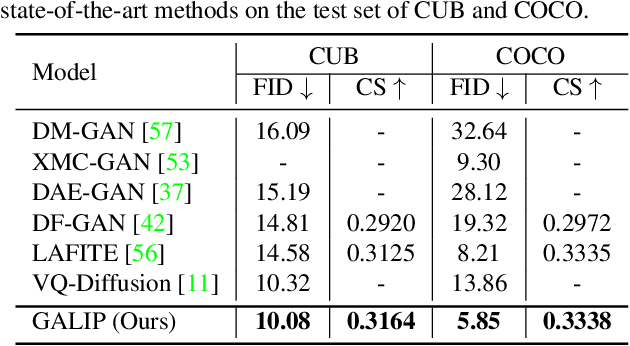
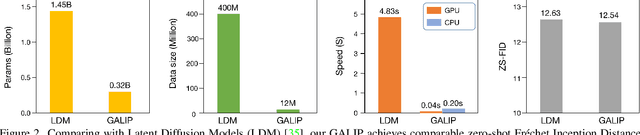
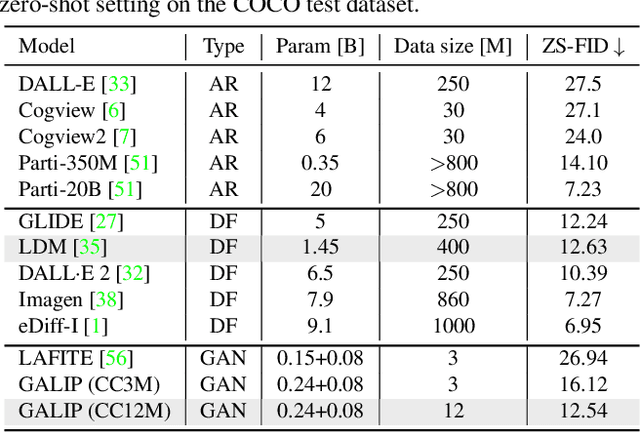
Synthesizing high-fidelity complex images from text is challenging. Based on large pretraining, the autoregressive and diffusion models can synthesize photo-realistic images. Although these large models have shown notable progress, there remain three flaws. 1) These models require tremendous training data and parameters to achieve good performance. 2) The multi-step generation design slows the image synthesis process heavily. 3) The synthesized visual features are difficult to control and require delicately designed prompts. To enable high-quality, efficient, fast, and controllable text-to-image synthesis, we propose Generative Adversarial CLIPs, namely GALIP. GALIP leverages the powerful pretrained CLIP model both in the discriminator and generator. Specifically, we propose a CLIP-based discriminator. The complex scene understanding ability of CLIP enables the discriminator to accurately assess the image quality. Furthermore, we propose a CLIP-empowered generator that induces the visual concepts from CLIP through bridge features and prompts. The CLIP-integrated generator and discriminator boost training efficiency, and as a result, our model only requires about 3% training data and 6% learnable parameters, achieving comparable results to large pretrained autoregressive and diffusion models. Moreover, our model achieves 120 times faster synthesis speed and inherits the smooth latent space from GAN. The extensive experimental results demonstrate the excellent performance of our GALIP. Code is available at https://github.com/tobran/GALIP.
Application of the YOLOv5 Model for the Detection of Microobjects in the Marine Environment
Nov 28, 2022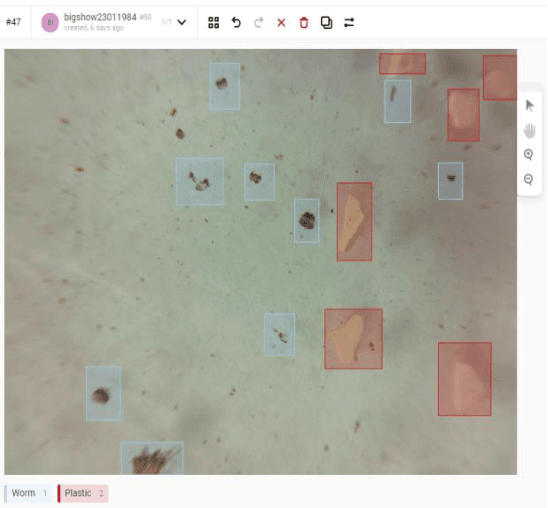

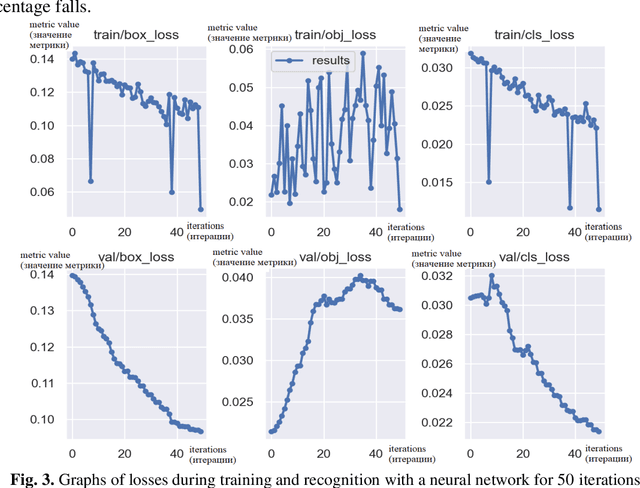
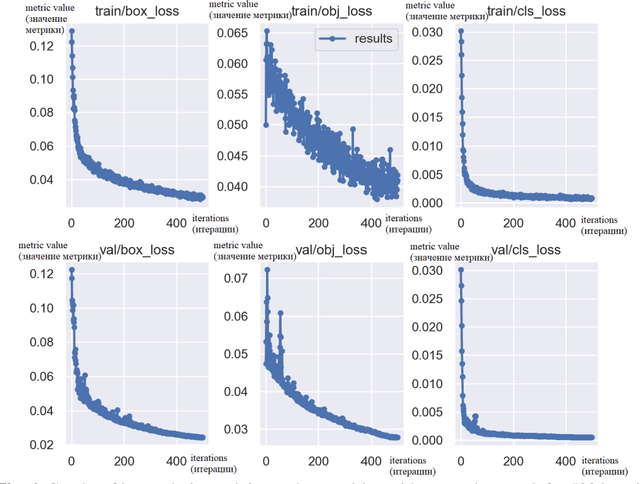
The efficiency of using the YOLOV5 machine learning model for solving the problem of automatic de-tection and recognition of micro-objects in the marine environment is studied. Samples of microplankton and microplastics were prepared, according to which a database of classified images was collected for training an image recognition neural network. The results of experiments using a trained network to find micro-objects in photo and video images in real time are presented. Experimental studies have shown high efficiency, comparable to manual recognition, of the proposed model in solving problems of detect-ing micro-objects in the marine environment.
An Optical XNOR-Bitcount Based Accelerator for Efficient Inference of Binary Neural Networks
Feb 03, 2023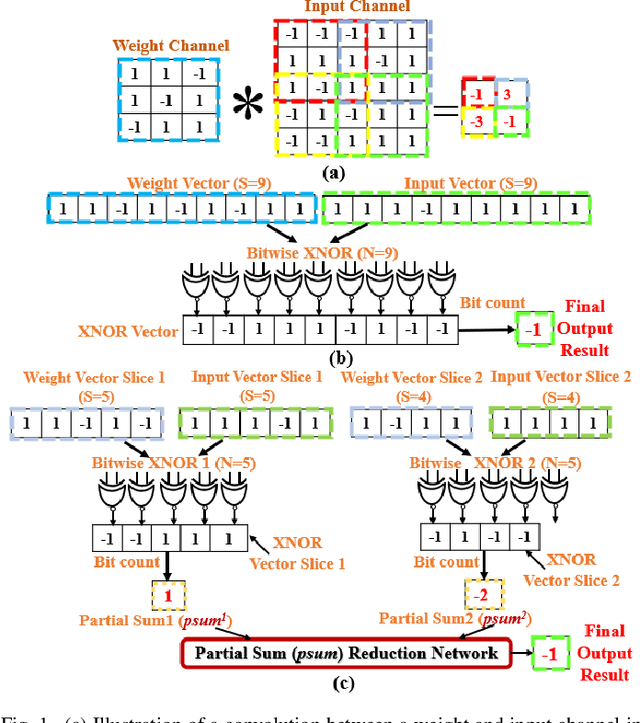
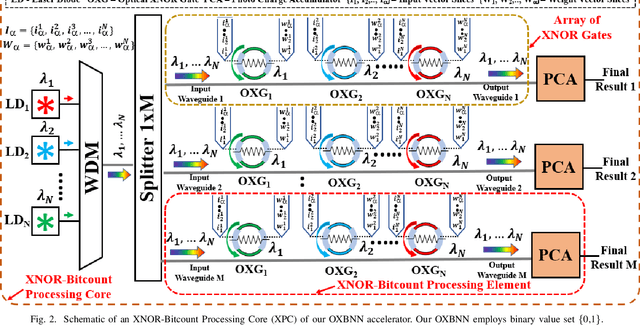
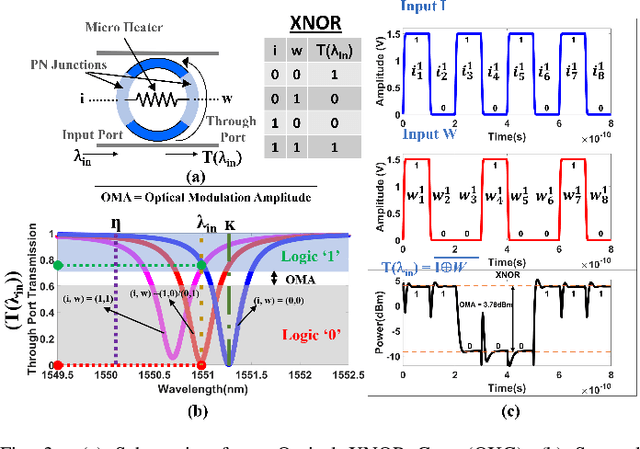
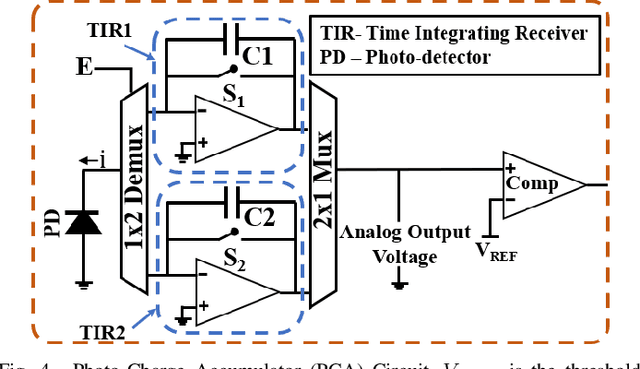
Binary Neural Networks (BNNs) are increasingly preferred over full-precision Convolutional Neural Networks(CNNs) to reduce the memory and computational requirements of inference processing with minimal accuracy drop. BNNs convert CNN model parameters to 1-bit precision, allowing inference of BNNs to be processed with simple XNOR and bitcount operations. This makes BNNs amenable to hardware acceleration. Several photonic integrated circuits (PICs) based BNN accelerators have been proposed. Although these accelerators provide remarkably higher throughput and energy efficiency than their electronic counterparts, the utilized XNOR and bitcount circuits in these accelerators need to be further enhanced to improve their area, energy efficiency, and throughput. This paper aims to fulfill this need. For that, we invent a single-MRR-based optical XNOR gate (OXG). Moreover, we present a novel design of bitcount circuit which we refer to as Photo-Charge Accumulator (PCA). We employ multiple OXGs in a cascaded manner using dense wavelength division multiplexing (DWDM) and connect them to the PCA, to forge a novel Optical XNOR-Bitcount based Binary Neural Network Accelerator (OXBNN). Our evaluation for the inference of four modern BNNs indicates that OXBNN provides improvements of up to 62x and 7.6x in frames-per-second (FPS) and FPS/W (energy efficiency), respectively, on geometric mean over two PIC-based BNN accelerators from prior work. We developed a transaction-level, event-driven python-based simulator for evaluation of accelerators (https://github.com/uky-UCAT/B_ONN_SIM).
Internal Diverse Image Completion
Dec 18, 2022
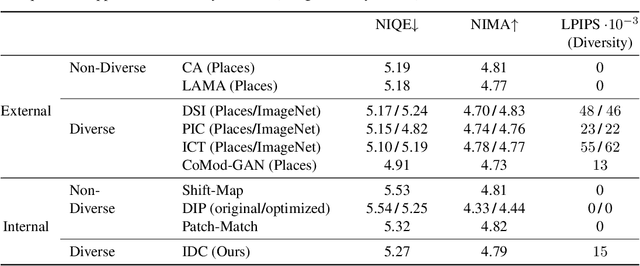
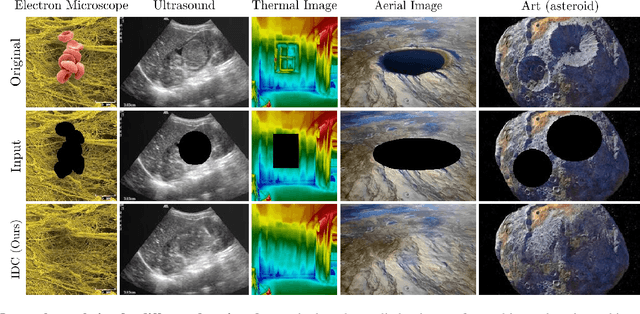
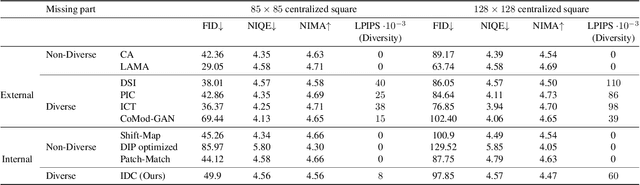
Image completion is widely used in photo restoration and editing applications, e.g. for object removal. Recently, there has been a surge of research on generating diverse completions for missing regions. However, existing methods require large training sets from a specific domain of interest, and often fail on general-content images. In this paper, we propose a diverse completion method that does not require a training set and can thus treat arbitrary images from any domain. Our internal diverse completion (IDC) approach draws inspiration from recent single-image generative models that are trained on multiple scales of a single image, adapting them to the extreme setting in which only a small portion of the image is available for training. We illustrate the strength of IDC on several datasets, using both user studies and quantitative comparisons.
Photo Wake-Up: 3D Character Animation from a Single Photo
Dec 05, 2018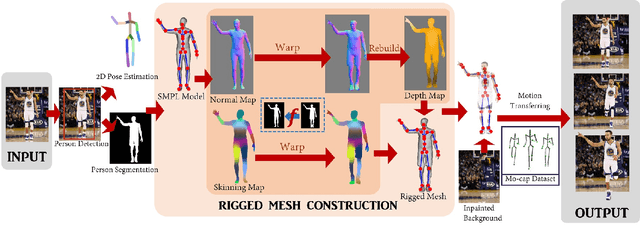
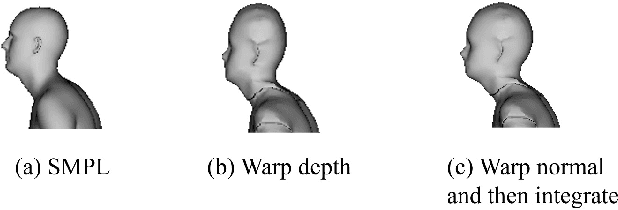
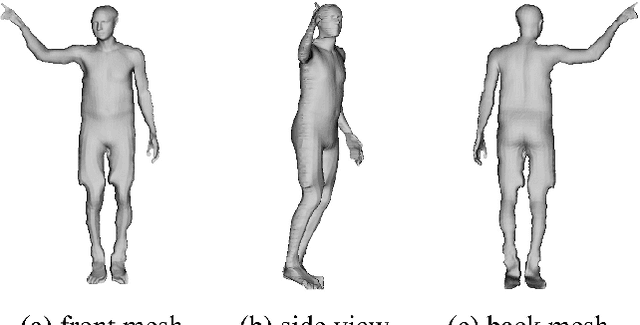
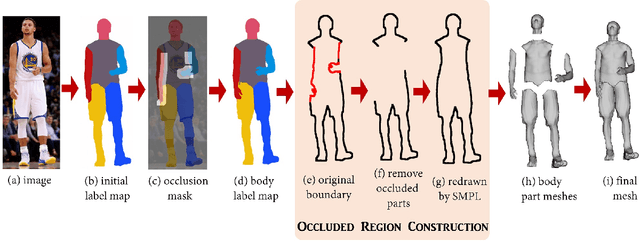
We present a method and application for animating a human subject from a single photo. E.g., the character can walk out, run, sit, or jump in 3D. The key contributions of this paper are: 1) an application of viewing and animating humans in single photos in 3D, 2) a novel 2D warping method to deform a posable template body model to fit the person's complex silhouette to create an animatable mesh, and 3) a method for handling partial self occlusions. We compare to state-of-the-art related methods and evaluate results with human studies. Further, we present an interactive interface that allows re-posing the person in 3D, and an augmented reality setup where the animated 3D person can emerge from the photo into the real world. We demonstrate the method on photos, posters, and art.
3D Photo Stylization: Learning to Generate Stylized Novel Views from a Single Image
Dec 04, 2021
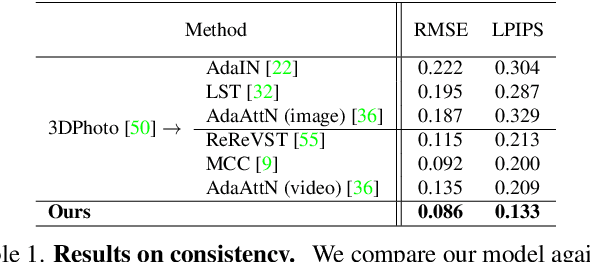

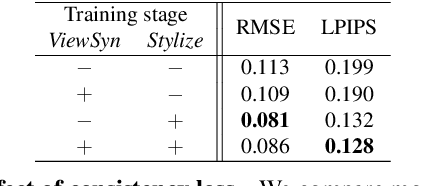
Visual content creation has spurred a soaring interest given its applications in mobile photography and AR / VR. Style transfer and single-image 3D photography as two representative tasks have so far evolved independently. In this paper, we make a connection between the two, and address the challenging task of 3D photo stylization - generating stylized novel views from a single image given an arbitrary style. Our key intuition is that style transfer and view synthesis have to be jointly modeled for this task. To this end, we propose a deep model that learns geometry-aware content features for stylization from a point cloud representation of the scene, resulting in high-quality stylized images that are consistent across views. Further, we introduce a novel training protocol to enable the learning using only 2D images. We demonstrate the superiority of our method via extensive qualitative and quantitative studies, and showcase key applications of our method in light of the growing demand for 3D content creation from 2D image assets.
A LiDAR-Inertial-Visual SLAM System with Loop Detection
Jan 13, 2023
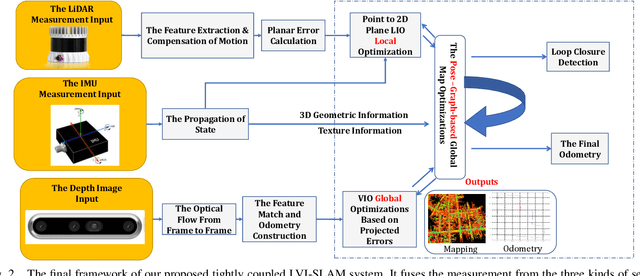
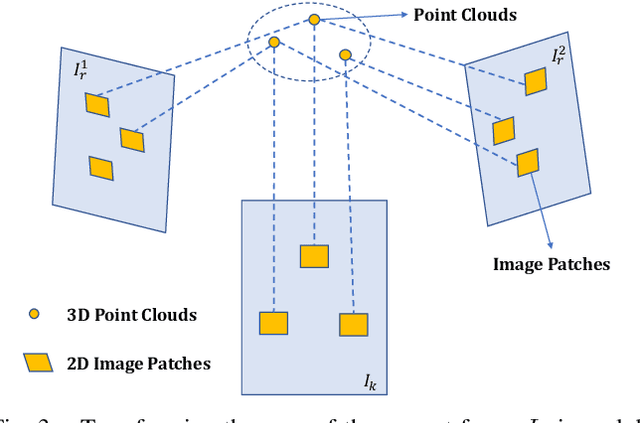
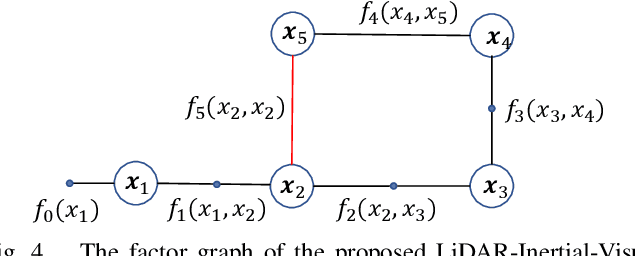
We have proposed, to the best of our knowledge, the first-of-its-kind LiDAR-Inertial-Visual-Fused simultaneous localization and mapping (SLAM) system with a strong place recognition capacity. Our proposed SLAM system is consist of visual-inertial odometry (VIO) and LiDAR inertial odometry (LIO) subsystems. We propose the LIO subsystem utilizing the measurement from the LiDAR and the inertial sensors to build the local odometry map, and propose the VIO subsystem which takes in the visual information to construct the 2D-3D associated map. Then, we propose an iterative Kalman Filter-based optimization function to optimize the local project-based 2D-to-3D photo-metric error between the projected image pixels and the local 3D points to make the robust 2D-3D alignment. Finally, we have also proposed the back-end pose graph global optimization and the elaborately designed loop closure detection network to improve the accuracy of the whole SLAM system. Extensive experiments deployed on the UGV in complicated real-world circumstances demonstrate that our proposed LiDAR-Visual-Inertial localization system outperforms the current state-of-the-art in terms of accuracy, efficiency, and robustness.
LostNet: A smart way for lost and find
Jan 05, 2023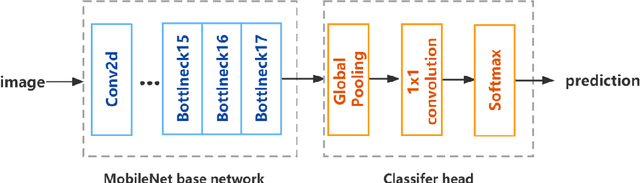
Due to the enormous population growth of cities in recent years, objects are frequently lost and unclaimed on public transportation, in restaurants, or any other public areas. While services like Find My iPhone can easily identify lost electronic devices, more valuable objects cannot be tracked in an intelligent manner, making it impossible for administrators to reclaim a large number of lost and found items in a timely manner. We present a method that significantly reduces the complexity of searching by comparing previous images of lost and recovered things provided by the owner with photos taken when registered lost and found items are received. In this research, we will primarily design a photo matching network by combining the fine-tuning method of MobileNetv2 with CBAM Attention and using the Internet framework to develop an online lost and found image identification system. Our implementation gets a testing accuracy of 96.8% using only 665.12M GLFOPs and 3.5M training parameters. It can recognize practice images and can be run on a regular laptop.