 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Parameters for > 300 million Gaia stars: Bayesian inference vs. machine learning
Feb 14, 2023
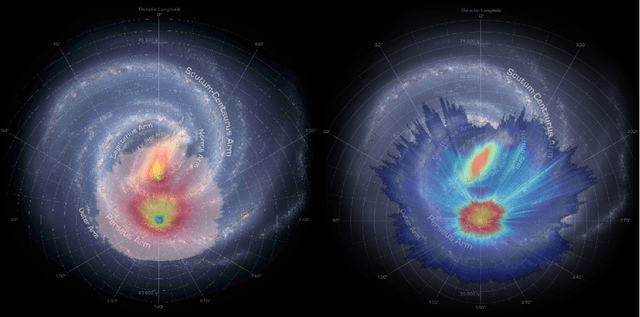
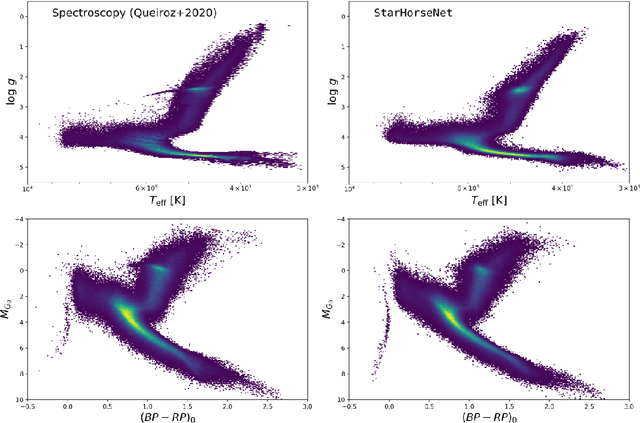
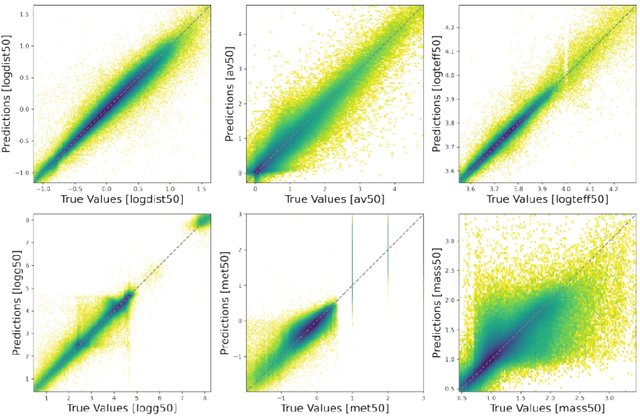
The Gaia Data Release 3 (DR3), published in June 2022, delivers a diverse set of astrometric, photometric, and spectroscopic measurements for more than a billion stars. The wealth and complexity of the data makes traditional approaches for estimating stellar parameters for the full Gaia dataset almost prohibitive. We have explored different supervised learning methods for extracting basic stellar parameters as well as distances and line-of-sight extinctions, given spectro-photo-astrometric data (including also the new Gaia XP spectra). For training we use an enhanced high-quality dataset compiled from Gaia DR3 and ground-based spectroscopic survey data covering the whole sky and all Galactic components. We show that even with a simple neural-network architecture or tree-based algorithm (and in the absence of Gaia XP spectra), we succeed in predicting competitive results (compared to Bayesian isochrone fitting) down to faint magnitudes. We will present a new Gaia DR3 stellar-parameter catalogue obtained using the currently best-performing machine-learning algorithm for tabular data, XGBoost, in the near future.
CoordFill: Efficient High-Resolution Image Inpainting via Parameterized Coordinate Querying
Mar 15, 2023
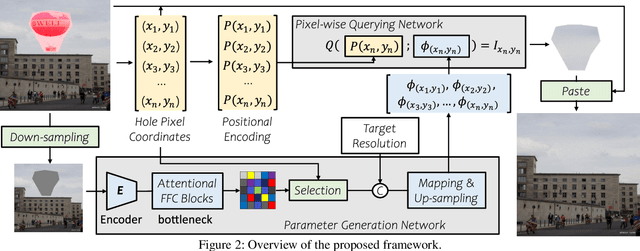
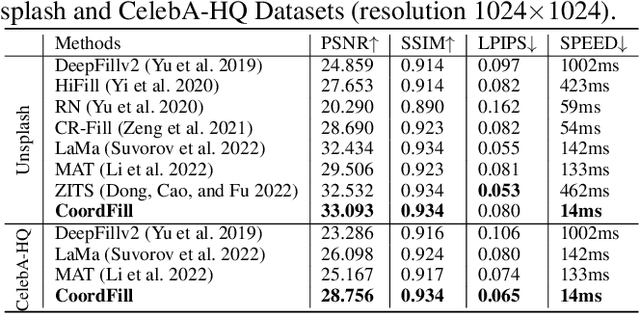
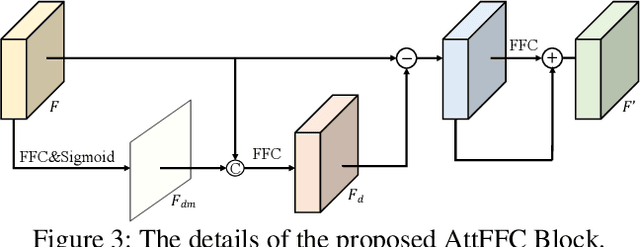
Image inpainting aims to fill the missing hole of the input. It is hard to solve this task efficiently when facing high-resolution images due to two reasons: (1) Large reception field needs to be handled for high-resolution image inpainting. (2) The general encoder and decoder network synthesizes many background pixels synchronously due to the form of the image matrix. In this paper, we try to break the above limitations for the first time thanks to the recent development of continuous implicit representation. In detail, we down-sample and encode the degraded image to produce the spatial-adaptive parameters for each spatial patch via an attentional Fast Fourier Convolution(FFC)-based parameter generation network. Then, we take these parameters as the weights and biases of a series of multi-layer perceptron(MLP), where the input is the encoded continuous coordinates and the output is the synthesized color value. Thanks to the proposed structure, we only encode the high-resolution image in a relatively low resolution for larger reception field capturing. Then, the continuous position encoding will be helpful to synthesize the photo-realistic high-frequency textures by re-sampling the coordinate in a higher resolution. Also, our framework enables us to query the coordinates of missing pixels only in parallel, yielding a more efficient solution than the previous methods. Experiments show that the proposed method achieves real-time performance on the 2048$\times$2048 images using a single GTX 2080 Ti GPU and can handle 4096$\times$4096 images, with much better performance than existing state-of-the-art methods visually and numerically. The code is available at: https://github.com/NiFangBaAGe/CoordFill.
DeepTeeth: A Teeth-photo Based Human Authentication System for Mobile and Hand-held Devices
Jul 28, 2021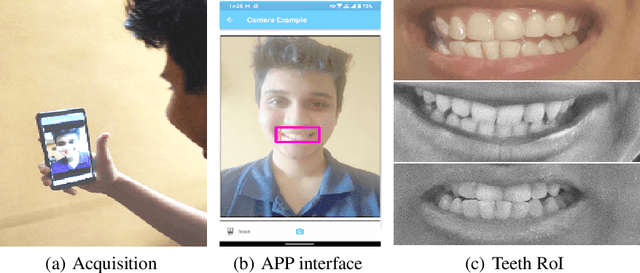
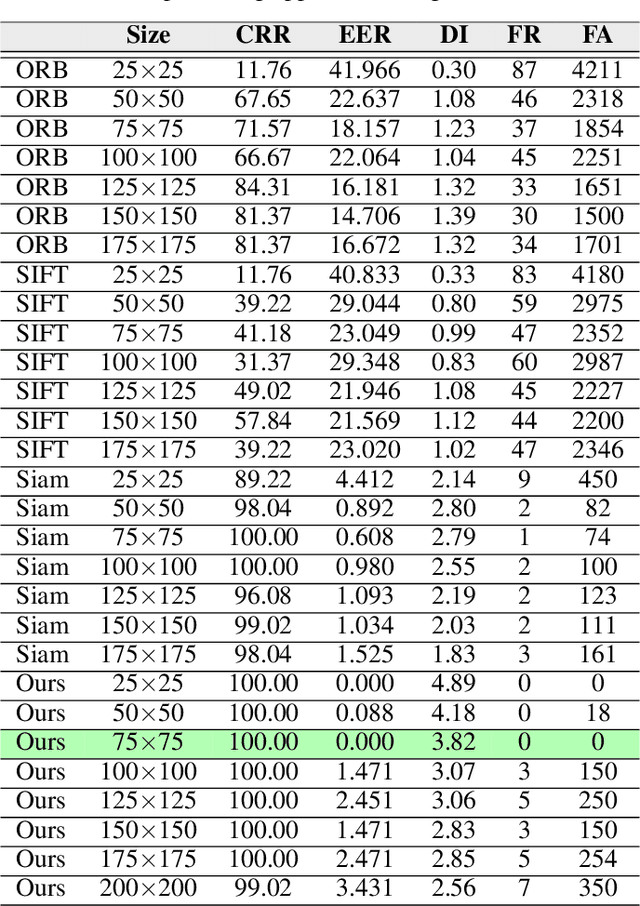

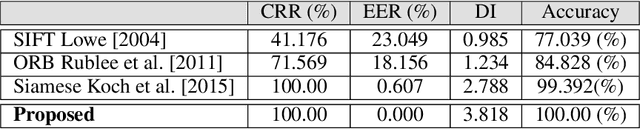
This paper proposes teeth-photo, a new biometric modality for human authentication on mobile and hand held devices. Biometrics samples are acquired using the camera mounted on mobile device with the help of a mobile application having specific markers to register the teeth area. Region of interest (RoI) is then extracted using the markers and the obtained sample is enhanced using contrast limited adaptive histogram equalization (CLAHE) for better visual clarity. We propose a deep learning architecture and novel regularization scheme to obtain highly discriminative embedding for small size RoI. Proposed custom loss function was able to achieve perfect classification for the tiny RoI of $75\times 75$ size. The model is end-to-end and few-shot and therefore is very efficient in terms of time and energy requirements. The system can be used in many ways including device unlocking and secure authentication. To the best of our understanding, this is the first work on teeth-photo based authentication for mobile device. Experiments have been conducted on an in-house teeth-photo database collected using our application. The database is made publicly available. Results have shown that the proposed system has perfect accuracy.
Learning Generalized Zero-Shot Learners for Open-Domain Image Geolocalization
Feb 01, 2023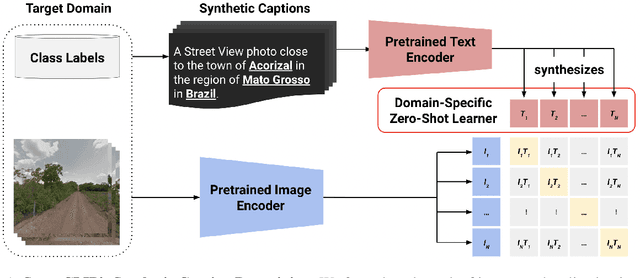
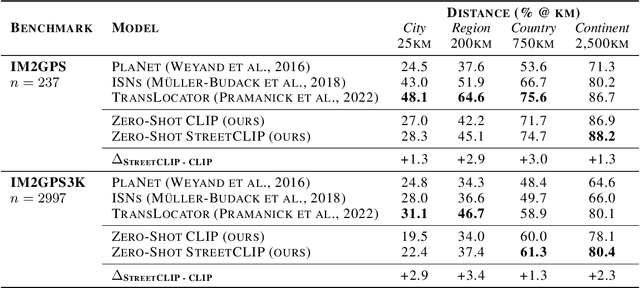
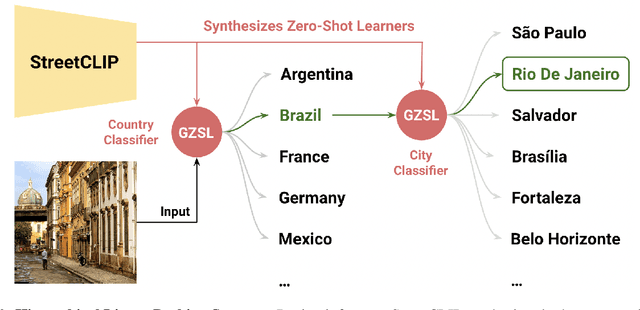

Image geolocalization is the challenging task of predicting the geographic coordinates of origin for a given photo. It is an unsolved problem relying on the ability to combine visual clues with general knowledge about the world to make accurate predictions across geographies. We present $\href{https://huggingface.co/geolocal/StreetCLIP}{\text{StreetCLIP}}$, a robust, publicly available foundation model not only achieving state-of-the-art performance on multiple open-domain image geolocalization benchmarks but also doing so in a zero-shot setting, outperforming supervised models trained on more than 4 million images. Our method introduces a meta-learning approach for generalized zero-shot learning by pretraining CLIP from synthetic captions, grounding CLIP in a domain of choice. We show that our method effectively transfers CLIP's generalized zero-shot capabilities to the domain of image geolocalization, improving in-domain generalized zero-shot performance without finetuning StreetCLIP on a fixed set of classes.
ManVatar : Fast 3D Head Avatar Reconstruction Using Motion-Aware Neural Voxels
Nov 23, 2022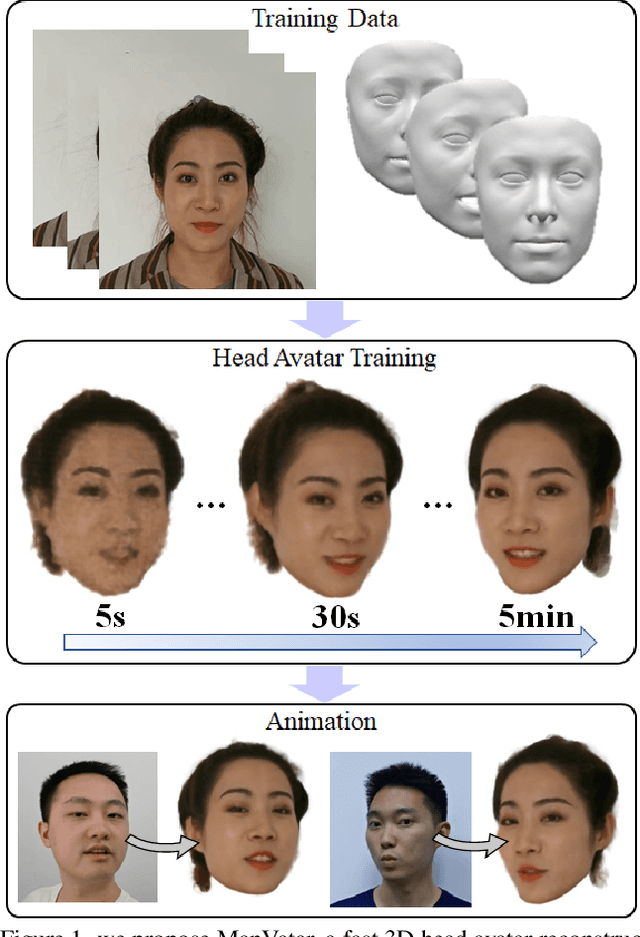
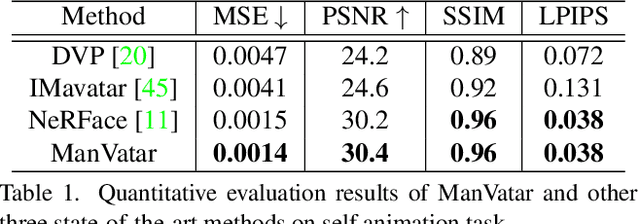
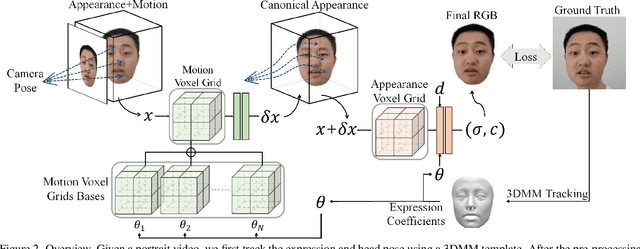
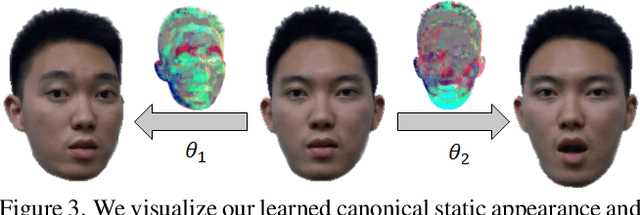
With NeRF widely used for facial reenactment, recent methods can recover photo-realistic 3D head avatar from just a monocular video. Unfortunately, the training process of the NeRF-based methods is quite time-consuming, as MLP used in the NeRF-based methods is inefficient and requires too many iterations to converge. To overcome this problem, we propose ManVatar, a fast 3D head avatar reconstruction method using Motion-Aware Neural Voxels. ManVatar is the first to decouple expression motion from canonical appearance for head avatar, and model the expression motion by neural voxels. In particular, the motion-aware neural voxels is generated from the weighted concatenation of multiple 4D tensors. The 4D tensors semantically correspond one-to-one with 3DMM expression bases and share the same weights as 3DMM expression coefficients. Benefiting from our novel representation, the proposed ManVatar can recover photo-realistic head avatars in just 5 minutes (implemented with pure PyTorch), which is significantly faster than the state-of-the-art facial reenactment methods.
DDColor: Towards Photo-Realistic and Semantic-Aware Image Colorization via Dual Decoders
Dec 23, 2022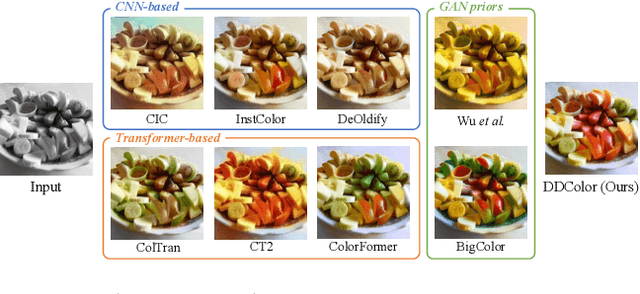
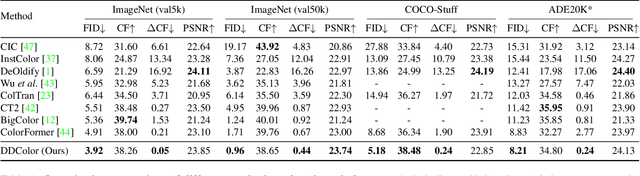
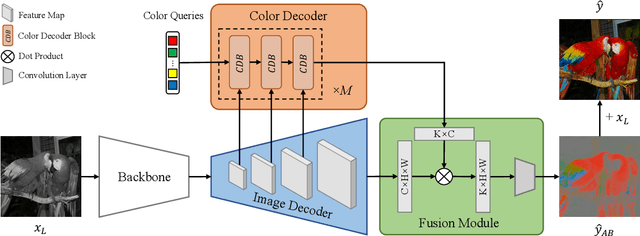

Automatic image colorization is a particularly challenging problem. Due to the high illness of the problem and multi-modal uncertainty, directly training a deep neural network usually leads to incorrect semantic colors and low color richness. Existing transformer-based methods can deliver better results but highly depend on hand-crafted dataset-level empirical distribution priors. In this work, we propose DDColor, a new end-to-end method with dual decoders, for image colorization. More specifically, we design a multi-scale image decoder and a transformer-based color decoder. The former manages to restore the spatial resolution of the image, while the latter establishes the correlation between semantic representations and color queries via cross-attention. The two decoders incorporate to learn semantic-aware color embedding by leveraging the multi-scale visual features. With the help of these two decoders, our method succeeds in producing semantically consistent and visually plausible colorization results without any additional priors. In addition, a simple but effective colorfulness loss is introduced to further improve the color richness of generated results. Our extensive experiments demonstrate that the proposed DDColor achieves significantly superior performance to existing state-of-the-art works both quantitatively and qualitatively. Codes will be made publicly available at https://github.com/piddnad/DDColor.
Feature Likelihood Score: Evaluating Generalization of Generative Models Using Samples
Feb 09, 2023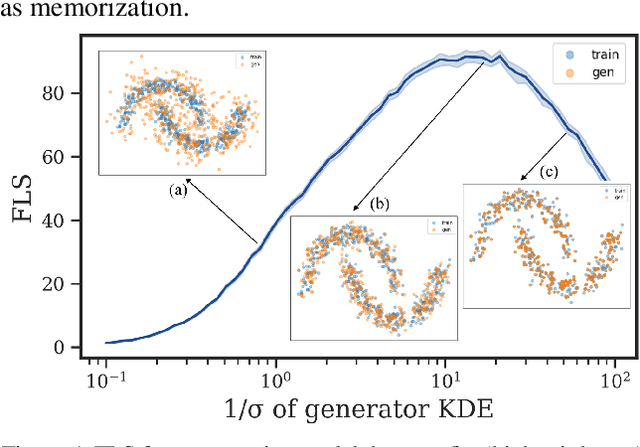
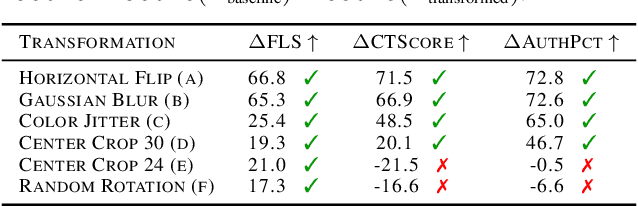
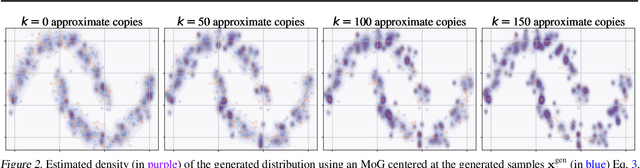
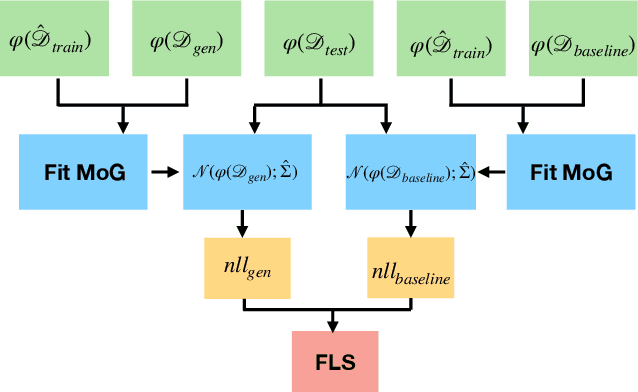
Deep generative models have demonstrated the ability to generate complex, high-dimensional, and photo-realistic data. However, a unified framework for evaluating different generative modeling families remains a challenge. Indeed, likelihood-based metrics do not apply in many cases while pure sample-based metrics such as FID fail to capture known failure modes such as overfitting on training data. In this work, we introduce the Feature Likelihood Score (FLS), a parametric sample-based score that uses density estimation to quantitatively measure the quality/diversity of generated samples while taking into account overfitting. We empirically demonstrate the ability of FLS to identify specific overfitting problem cases, even when previously proposed metrics fail. We further perform an extensive experimental evaluation on various image datasets and model classes. Our results indicate that FLS matches intuitions of previous metrics, such as FID, while providing a more holistic evaluation of generative models that highlights models whose generalization abilities are under or overappreciated. Code for computing FLS is provided at https://github.com/marcojira/fls
Protecting Geolocation Privacy of Photo Collections
Dec 04, 2019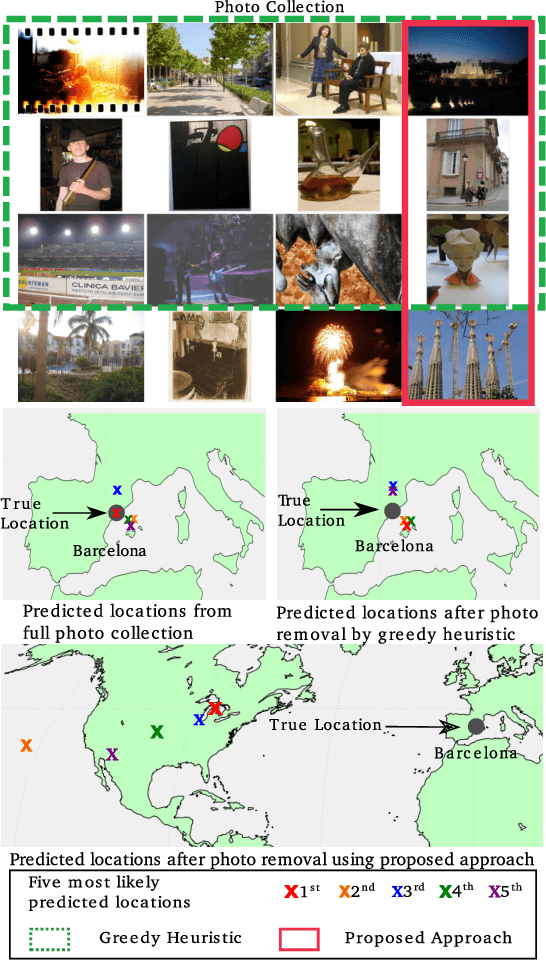
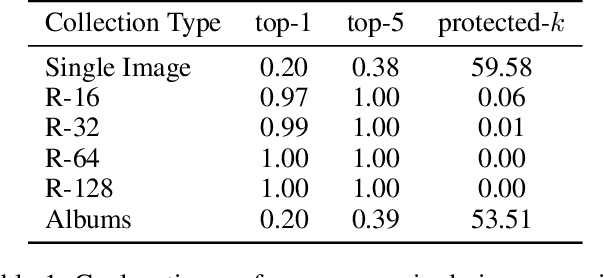
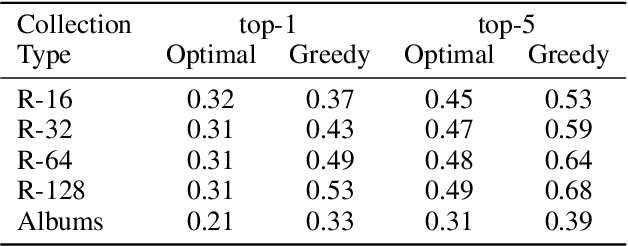
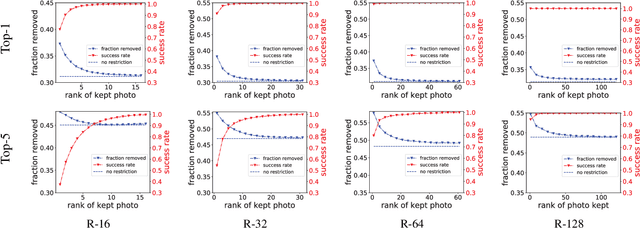
People increasingly share personal information, including their photos and photo collections, on social media. This information, however, can compromise individual privacy, particularly as social media platforms use it to infer detailed models of user behavior, including tracking their location. We consider the specific issue of location privacy as potentially revealed by posting photo collections, which facilitate accurate geolocation with the help of deep learning methods even in the absence of geotags. One means to limit associated inadvertent geolocation privacy disclosure is by carefully pruning select photos from photo collections before these are posted publicly. We study this problem formally as a combinatorial optimization problem in the context of geolocation prediction facilitated by deep learning. We first demonstrate the complexity both by showing that a natural greedy algorithm can be arbitrarily bad and by proving that the problem is NP-Hard. We then exhibit an important tractable special case, as well as a more general approach based on mixed-integer linear programming. Through extensive experiments on real photo collections, we demonstrate that our approaches are indeed highly effective at preserving geolocation privacy.
GeneFace: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis
Jan 31, 2023
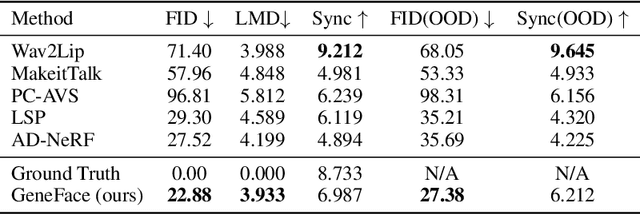
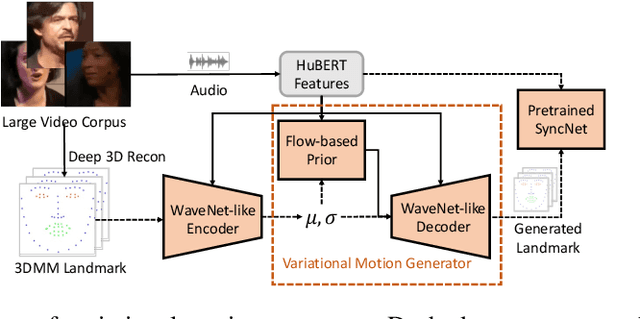

Generating photo-realistic video portrait with arbitrary speech audio is a crucial problem in film-making and virtual reality. Recently, several works explore the usage of neural radiance field in this task to improve 3D realness and image fidelity. However, the generalizability of previous NeRF-based methods to out-of-domain audio is limited by the small scale of training data. In this work, we propose GeneFace, a generalized and high-fidelity NeRF-based talking face generation method, which can generate natural results corresponding to various out-of-domain audio. Specifically, we learn a variaitional motion generator on a large lip-reading corpus, and introduce a domain adaptative post-net to calibrate the result. Moreover, we learn a NeRF-based renderer conditioned on the predicted facial motion. A head-aware torso-NeRF is proposed to eliminate the head-torso separation problem. Extensive experiments show that our method achieves more generalized and high-fidelity talking face generation compared to previous methods.
Dynamic Neural Portraits
Nov 25, 2022
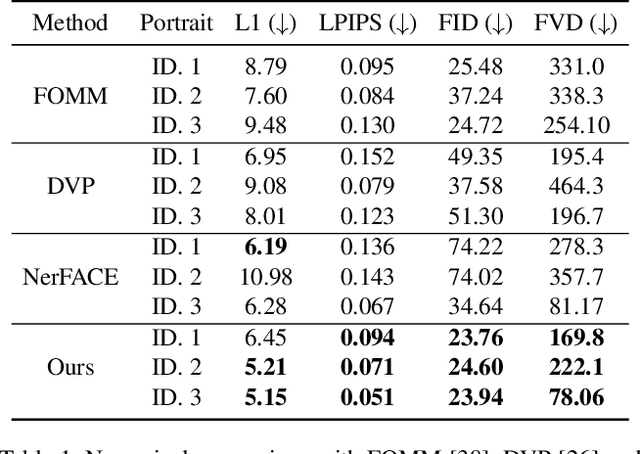
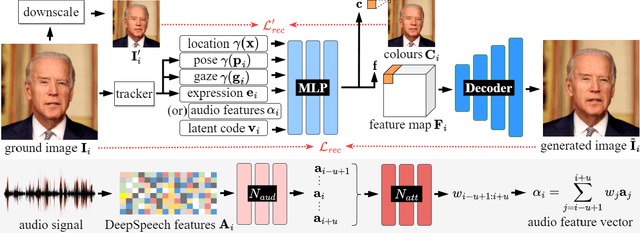
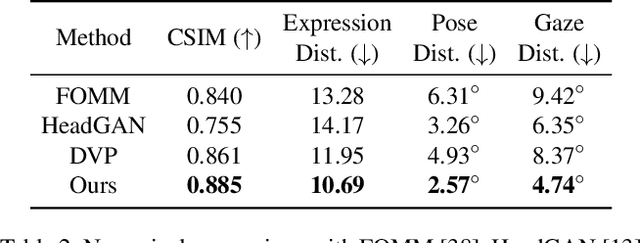
We present Dynamic Neural Portraits, a novel approach to the problem of full-head reenactment. Our method generates photo-realistic video portraits by explicitly controlling head pose, facial expressions and eye gaze. Our proposed architecture is different from existing methods that rely on GAN-based image-to-image translation networks for transforming renderings of 3D faces into photo-realistic images. Instead, we build our system upon a 2D coordinate-based MLP with controllable dynamics. Our intuition to adopt a 2D-based representation, as opposed to recent 3D NeRF-like systems, stems from the fact that video portraits are captured by monocular stationary cameras, therefore, only a single viewpoint of the scene is available. Primarily, we condition our generative model on expression blendshapes, nonetheless, we show that our system can be successfully driven by audio features as well. Our experiments demonstrate that the proposed method is 270 times faster than recent NeRF-based reenactment methods, with our networks achieving speeds of 24 fps for resolutions up to 1024 x 1024, while outperforming prior works in terms of visual quality.