 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
BaLi-RF: Bandlimited Radiance Fields for Dynamic Scene Modeling
Feb 27, 2023
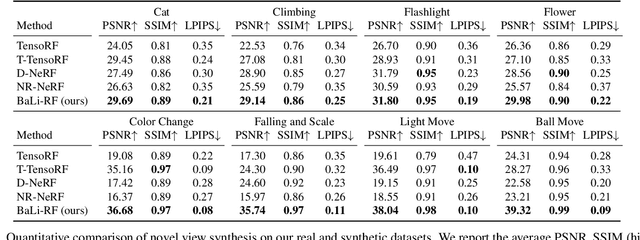
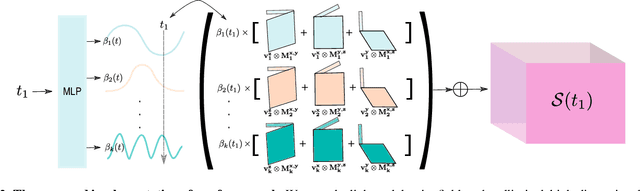

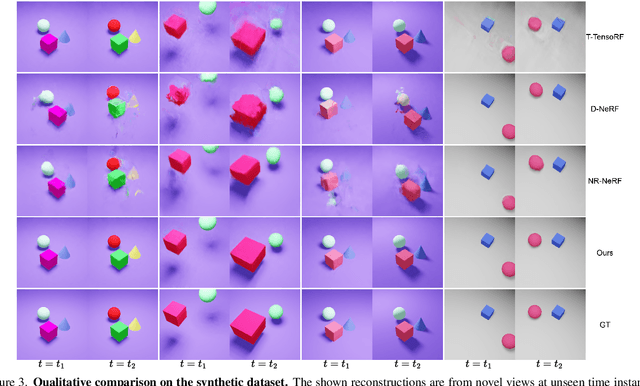
Reasoning the 3D structure of a non-rigid dynamic scene from a single moving camera is an under-constrained problem. Inspired by the remarkable progress of neural radiance fields (NeRFs) in photo-realistic novel view synthesis of static scenes, extensions have been proposed for dynamic settings. These methods heavily rely on neural priors in order to regularize the problem. In this work, we take a step back and reinvestigate how current implementations may entail deleterious effects, including limited expressiveness, entanglement of light and density fields, and sub-optimal motion localization. As a remedy, we advocate for a bridge between classic non-rigid-structure-from-motion (\nrsfm) and NeRF, enabling the well-studied priors of the former to constrain the latter. To this end, we propose a framework that factorizes time and space by formulating a scene as a composition of bandlimited, high-dimensional signals. We demonstrate compelling results across complex dynamic scenes that involve changes in lighting, texture and long-range dynamics.
Data-Free Sketch-Based Image Retrieval
Mar 14, 2023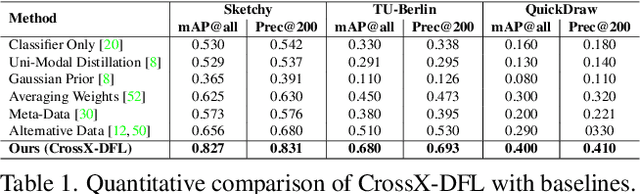

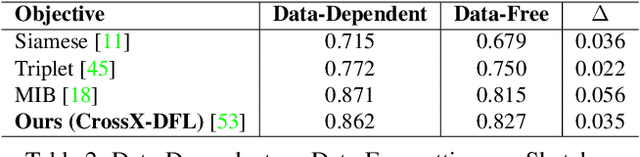
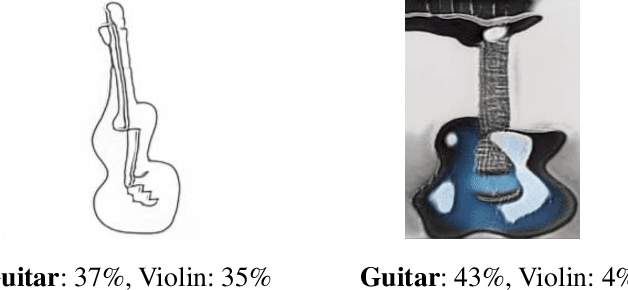
Rising concerns about privacy and anonymity preservation of deep learning models have facilitated research in data-free learning (DFL). For the first time, we identify that for data-scarce tasks like Sketch-Based Image Retrieval (SBIR), where the difficulty in acquiring paired photos and hand-drawn sketches limits data-dependent cross-modal learning algorithms, DFL can prove to be a much more practical paradigm. We thus propose Data-Free (DF)-SBIR, where, unlike existing DFL problems, pre-trained, single-modality classification models have to be leveraged to learn a cross-modal metric-space for retrieval without access to any training data. The widespread availability of pre-trained classification models, along with the difficulty in acquiring paired photo-sketch datasets for SBIR justify the practicality of this setting. We present a methodology for DF-SBIR, which can leverage knowledge from models independently trained to perform classification on photos and sketches. We evaluate our model on the Sketchy, TU-Berlin, and QuickDraw benchmarks, designing a variety of baselines based on state-of-the-art DFL literature, and observe that our method surpasses all of them by significant margins. Our method also achieves mAPs competitive with data-dependent approaches, all the while requiring no training data. Implementation is available at \url{https://github.com/abhrac/data-free-sbir}.
Robust Fusion for Bayesian Semantic Mapping
Mar 14, 2023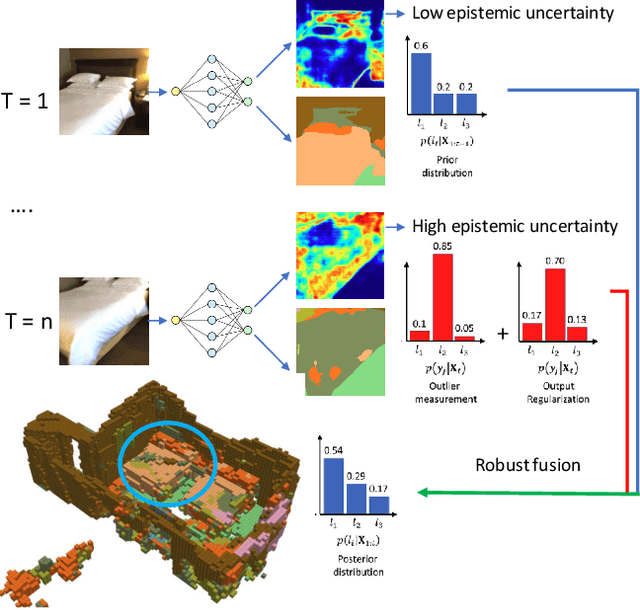
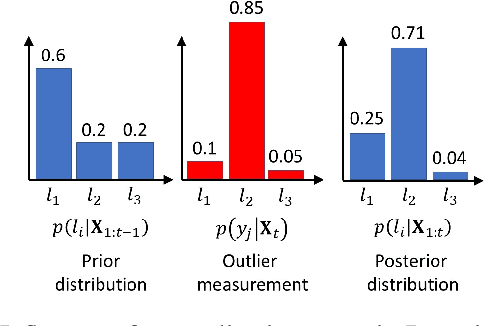
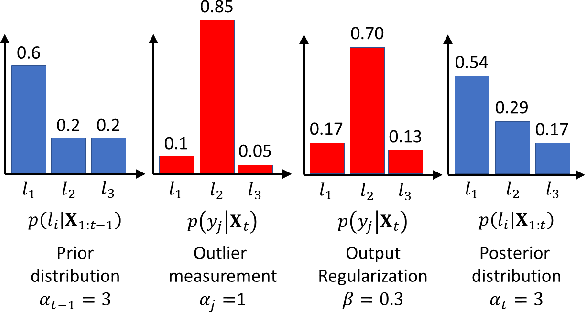

The integration of semantic information in a map allows robots to understand better their environment and make high-level decisions. In the last few years, neural networks have shown enormous progress in their perception capabilities. However, when fusing multiple observations from a neural network in a semantic map, its inherent overconfidence with unknown data gives too much weight to the outliers and decreases the robustness of the resulting map. In this work, we propose a novel robust fusion method to combine multiple Bayesian semantic predictions. Our method uses the uncertainty estimation provided by a Bayesian neural network to calibrate the way in which the measurements are fused. This is done by regularizing the observations to mitigate the problem of overconfident outlier predictions and using the epistemic uncertainty to weigh their influence in the fusion, resulting in a different formulation of the probability distributions. We validate our robust fusion strategy by performing experiments on photo-realistic simulated environments and real scenes. In both cases, we use a network trained on different data to expose the model to varying data distributions. The results show that considering the model's uncertainty and regularizing the probability distribution of the observations distribution results in a better semantic segmentation performance and more robustness to outliers, compared with other methods.
Multiresolution Textual Inversion
Nov 30, 2022



We extend Textual Inversion to learn pseudo-words that represent a concept at different resolutions. This allows us to generate images that use the concept with different levels of detail and also to manipulate different resolutions using language. Once learned, the user can generate images at different levels of agreement to the original concept; "A photo of $S^*(0)$" produces the exact object while the prompt "A photo of $S^*(0.8)$" only matches the rough outlines and colors. Our framework allows us to generate images that use different resolutions of an image (e.g. details, textures, styles) as separate pseudo-words that can be composed in various ways. We open-soure our code in the following URL: https://github.com/giannisdaras/multires_textual_inversion
Raising The Limit Of Image Rescaling Using Auxiliary Encoding
Mar 12, 2023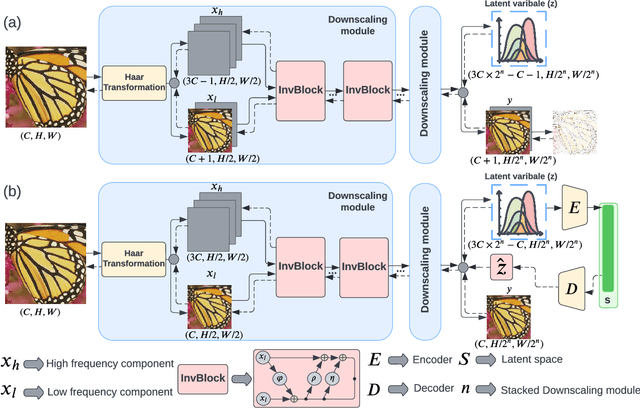
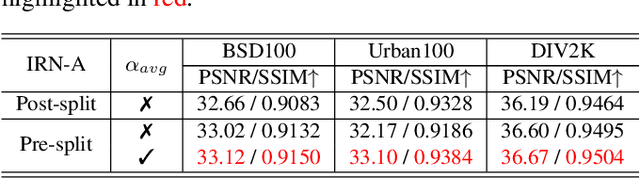
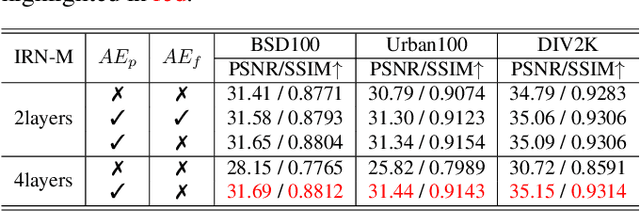

Normalizing flow models using invertible neural networks (INN) have been widely investigated for successful generative image super-resolution (SR) by learning the transformation between the normal distribution of latent variable $z$ and the conditional distribution of high-resolution (HR) images gave a low-resolution (LR) input. Recently, image rescaling models like IRN utilize the bidirectional nature of INN to push the performance limit of image upscaling by optimizing the downscaling and upscaling steps jointly. While the random sampling of latent variable $z$ is useful in generating diverse photo-realistic images, it is not desirable for image rescaling when accurate restoration of the HR image is more important. Hence, in places of random sampling of $z$, we propose auxiliary encoding modules to further push the limit of image rescaling performance. Two options to store the encoded latent variables in downscaled LR images, both readily supported in existing image file format, are proposed. One is saved as the alpha-channel, the other is saved as meta-data in the image header, and the corresponding modules are denoted as suffixes -A and -M respectively. Optimal network architectural changes are investigated for both options to demonstrate their effectiveness in raising the rescaling performance limit on different baseline models including IRN and DLV-IRN.
CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not
Mar 28, 2023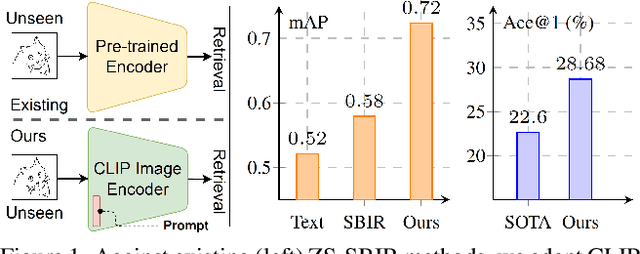
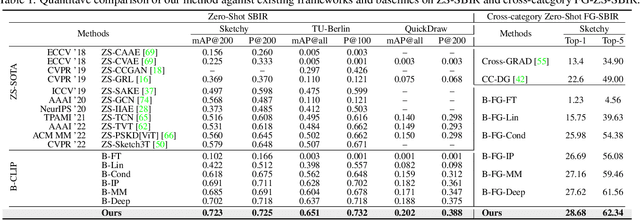

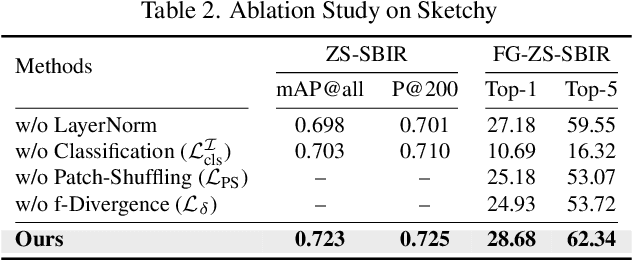
In this paper, we leverage CLIP for zero-shot sketch based image retrieval (ZS-SBIR). We are largely inspired by recent advances on foundation models and the unparalleled generalisation ability they seem to offer, but for the first time tailor it to benefit the sketch community. We put forward novel designs on how best to achieve this synergy, for both the category setting and the fine-grained setting ("all"). At the very core of our solution is a prompt learning setup. First we show just via factoring in sketch-specific prompts, we already have a category-level ZS-SBIR system that overshoots all prior arts, by a large margin (24.8%) - a great testimony on studying the CLIP and ZS-SBIR synergy. Moving onto the fine-grained setup is however trickier, and requires a deeper dive into this synergy. For that, we come up with two specific designs to tackle the fine-grained matching nature of the problem: (i) an additional regularisation loss to ensure the relative separation between sketches and photos is uniform across categories, which is not the case for the gold standard standalone triplet loss, and (ii) a clever patch shuffling technique to help establishing instance-level structural correspondences between sketch-photo pairs. With these designs, we again observe significant performance gains in the region of 26.9% over previous state-of-the-art. The take-home message, if any, is the proposed CLIP and prompt learning paradigm carries great promise in tackling other sketch-related tasks (not limited to ZS-SBIR) where data scarcity remains a great challenge. Project page: https://aneeshan95.github.io/Sketch_LVM/
Human-Imperceptible Identification with Learnable Lensless Imaging
Feb 04, 2023



Lensless imaging protects visual privacy by capturing heavily blurred images that are imperceptible for humans to recognize the subject but contain enough information for machines to infer information. Unfortunately, protecting visual privacy comes with a reduction in recognition accuracy and vice versa. We propose a learnable lensless imaging framework that protects visual privacy while maintaining recognition accuracy. To make captured images imperceptible to humans, we designed several loss functions based on total variation, invertibility, and the restricted isometry property. We studied the effect of privacy protection with blurriness on the identification of personal identity via a quantitative method based on a subjective evaluation. Moreover, we validate our simulation by implementing a hardware realization of lensless imaging with photo-lithographically printed masks.
Spawrious: A Benchmark for Fine Control of Spurious Correlation Biases
Mar 09, 2023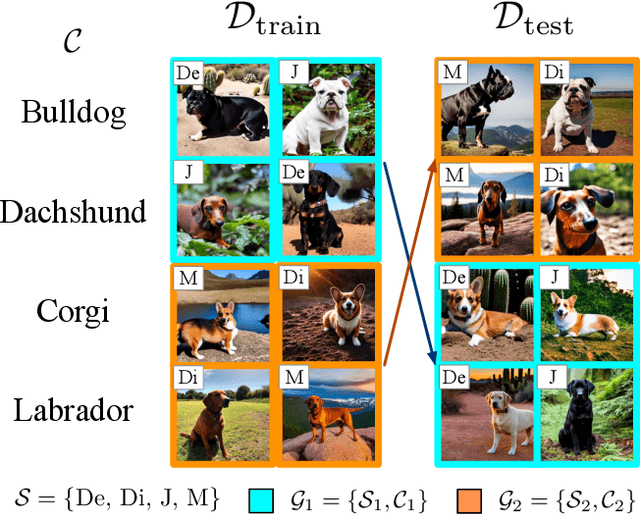
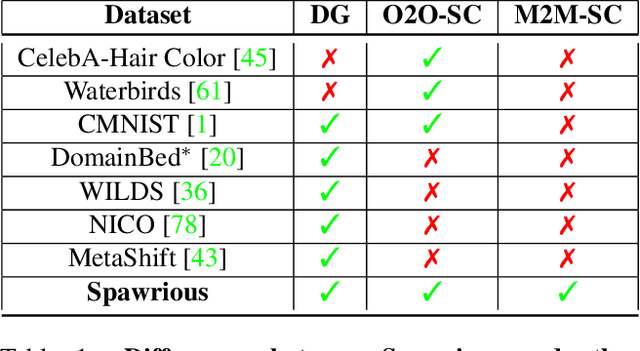

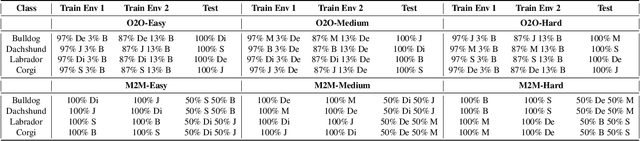
The problem of spurious correlations (SCs) arises when a classifier relies on non-predictive features that happen to be correlated with the labels in the training data. For example, a classifier may misclassify dog breeds based on the background of dog images. This happens when the backgrounds are correlated with other breeds in the training data, leading to misclassifications during test time. Previous SC benchmark datasets suffer from varying issues, e.g., over-saturation or only containing one-to-one (O2O) SCs, but no many-to-many (M2M) SCs arising between groups of spurious attributes and classes. In this paper, we present Spawrious-{O2O, M2M}-{Easy, Medium, Hard}, an image classification benchmark suite containing spurious correlations among different dog breeds and background locations. To create this dataset, we employ a text-to-image model to generate photo-realistic images, and an image captioning model to filter out unsuitable ones. The resulting dataset is of high quality, containing approximately 152,000 images. Our experimental results demonstrate that state-of-the-art group robustness methods struggle with Spawrious, most notably on the Hard-splits with $<60\%$ accuracy. By examining model misclassifications, we detect reliances on spurious backgrounds, demonstrating that our dataset provides a significant challenge to drive future research.
Spring: A High-Resolution High-Detail Dataset and Benchmark for Scene Flow, Optical Flow and Stereo
Mar 03, 2023
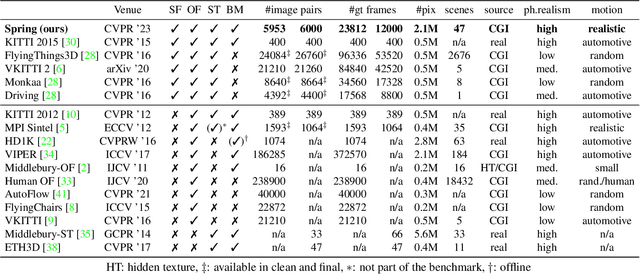

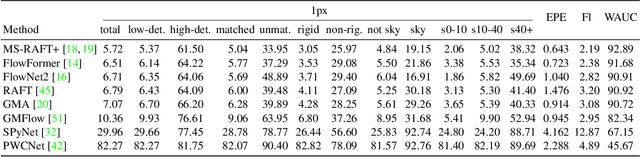
While recent methods for motion and stereo estimation recover an unprecedented amount of details, such highly detailed structures are neither adequately reflected in the data of existing benchmarks nor their evaluation methodology. Hence, we introduce Spring $-$ a large, high-resolution, high-detail, computer-generated benchmark for scene flow, optical flow, and stereo. Based on rendered scenes from the open-source Blender movie "Spring", it provides photo-realistic HD datasets with state-of-the-art visual effects and ground truth training data. Furthermore, we provide a website to upload, analyze and compare results. Using a novel evaluation methodology based on a super-resolved UHD ground truth, our Spring benchmark can assess the quality of fine structures and provides further detailed performance statistics on different image regions. Regarding the number of ground truth frames, Spring is 60$\times$ larger than the only scene flow benchmark, KITTI 2015, and 15$\times$ larger than the well-established MPI Sintel optical flow benchmark. Initial results for recent methods on our benchmark show that estimating fine details is indeed challenging, as their accuracy leaves significant room for improvement. The Spring benchmark and the corresponding datasets are available at http://spring-benchmark.org.
DINet: Deformation Inpainting Network for Realistic Face Visually Dubbing on High Resolution Video
Mar 07, 2023
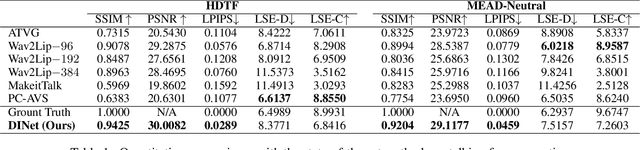
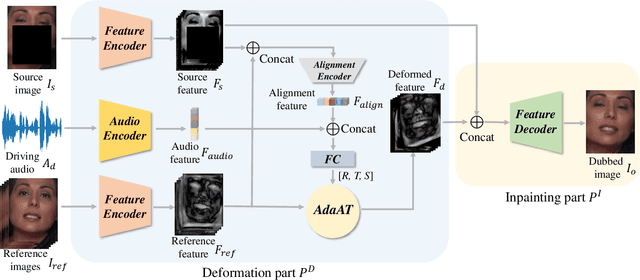
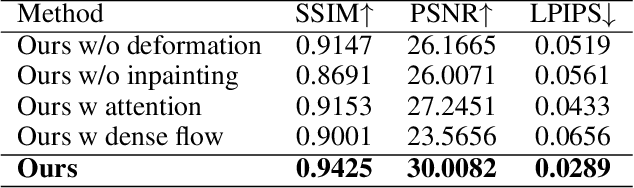
For few-shot learning, it is still a critical challenge to realize photo-realistic face visually dubbing on high-resolution videos. Previous works fail to generate high-fidelity dubbing results. To address the above problem, this paper proposes a Deformation Inpainting Network (DINet) for high-resolution face visually dubbing. Different from previous works relying on multiple up-sample layers to directly generate pixels from latent embeddings, DINet performs spatial deformation on feature maps of reference images to better preserve high-frequency textural details. Specifically, DINet consists of one deformation part and one inpainting part. In the first part, five reference facial images adaptively perform spatial deformation to create deformed feature maps encoding mouth shapes at each frame, in order to align with the input driving audio and also the head poses of the input source images. In the second part, to produce face visually dubbing, a feature decoder is responsible for adaptively incorporating mouth movements from the deformed feature maps and other attributes (i.e., head pose and upper facial expression) from the source feature maps together. Finally, DINet achieves face visually dubbing with rich textural details. We conduct qualitative and quantitative comparisons to validate our DINet on high-resolution videos. The experimental results show that our method outperforms state-of-the-art works.