 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
NeRFLiX: High-Quality Neural View Synthesis by Learning a Degradation-Driven Inter-viewpoint MiXer
Mar 13, 2023
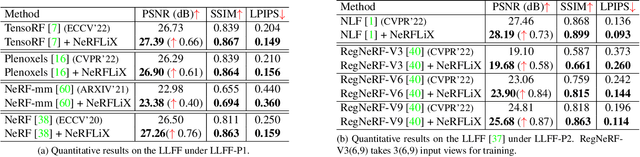
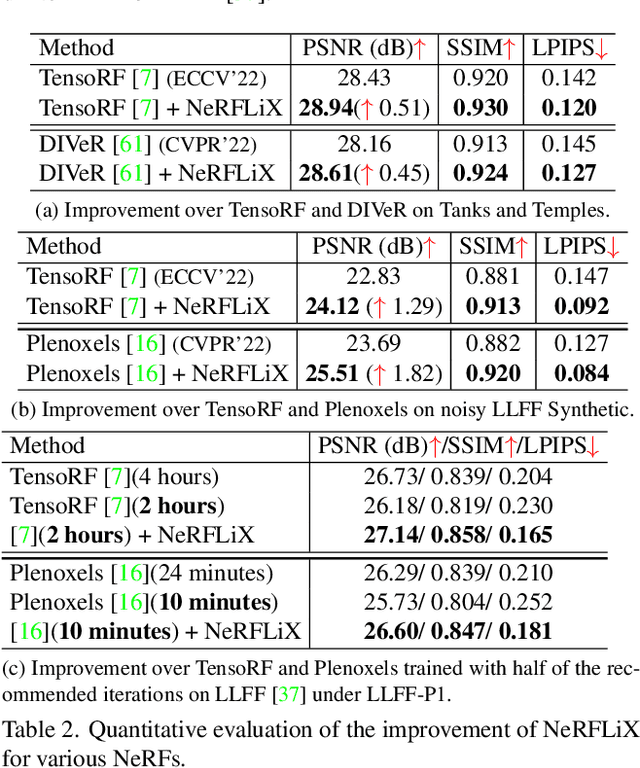
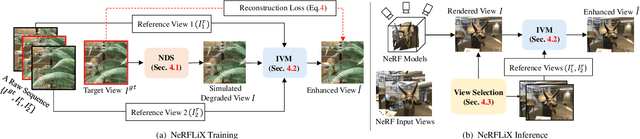
Neural radiance fields (NeRF) show great success in novel view synthesis. However, in real-world scenes, recovering high-quality details from the source images is still challenging for the existing NeRF-based approaches, due to the potential imperfect calibration information and scene representation inaccuracy. Even with high-quality training frames, the synthetic novel views produced by NeRF models still suffer from notable rendering artifacts, such as noise, blur, etc. Towards to improve the synthesis quality of NeRF-based approaches, we propose NeRFLiX, a general NeRF-agnostic restorer paradigm by learning a degradation-driven inter-viewpoint mixer. Specially, we design a NeRF-style degradation modeling approach and construct large-scale training data, enabling the possibility of effectively removing NeRF-native rendering artifacts for existing deep neural networks. Moreover, beyond the degradation removal, we propose an inter-viewpoint aggregation framework that is able to fuse highly related high-quality training images, pushing the performance of cutting-edge NeRF models to entirely new levels and producing highly photo-realistic synthetic views.
$α$Surf: Implicit Surface Reconstruction for Semi-Transparent and Thin Objects with Decoupled Geometry and Opacity
Mar 17, 2023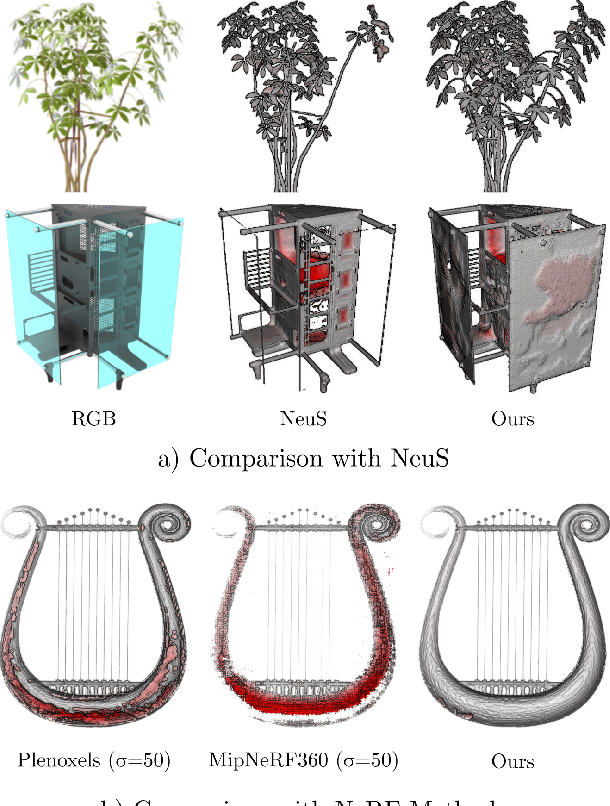
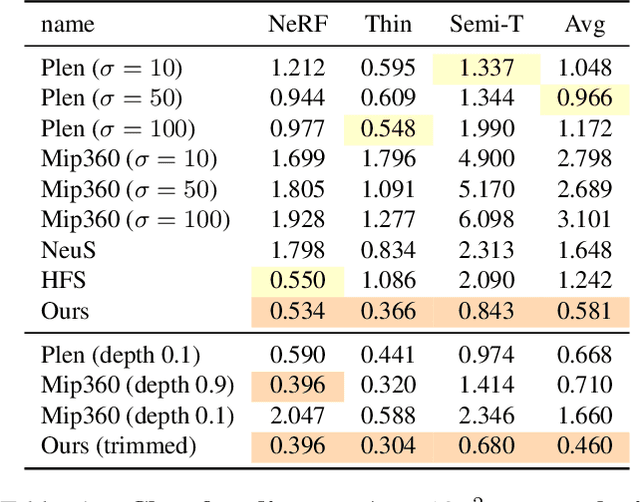
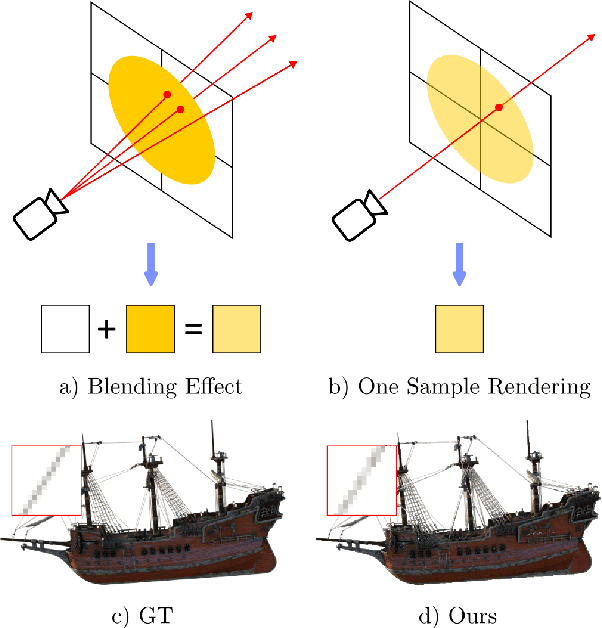
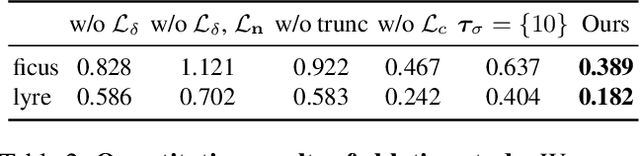
Implicit surface representations such as the signed distance function (SDF) have emerged as a promising approach for image-based surface reconstruction. However, existing optimization methods assume solid surfaces and are therefore unable to properly reconstruct semi-transparent surfaces and thin structures, which also exhibit low opacity due to the blending effect with the background. While neural radiance field (NeRF) based methods can model semi-transparency and achieve photo-realistic quality in synthesized novel views, their volumetric geometry representation tightly couples geometry and opacity, and therefore cannot be easily converted into surfaces without introducing artifacts. We present $\alpha$Surf, a novel surface representation with decoupled geometry and opacity for the reconstruction of semi-transparent and thin surfaces where the colors mix. Ray-surface intersections on our representation can be found in closed-form via analytical solutions of cubic polynomials, avoiding Monte-Carlo sampling and is fully differentiable by construction. Our qualitative and quantitative evaluations show that our approach can accurately reconstruct surfaces with semi-transparent and thin parts with fewer artifacts, achieving better reconstruction quality than state-of-the-art SDF and NeRF methods. Website: https://alphasurf.netlify.app/
MVTrans: Multi-View Perception of Transparent Objects
Feb 22, 2023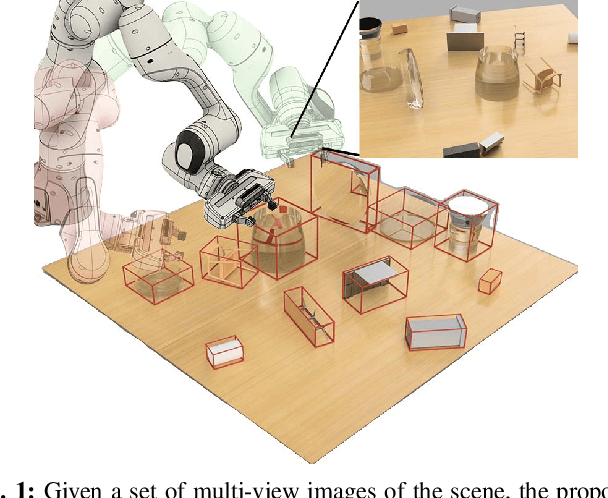

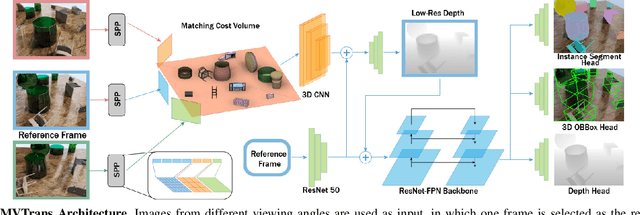

Transparent object perception is a crucial skill for applications such as robot manipulation in household and laboratory settings. Existing methods utilize RGB-D or stereo inputs to handle a subset of perception tasks including depth and pose estimation. However, transparent object perception remains to be an open problem. In this paper, we forgo the unreliable depth map from RGB-D sensors and extend the stereo based method. Our proposed method, MVTrans, is an end-to-end multi-view architecture with multiple perception capabilities, including depth estimation, segmentation, and pose estimation. Additionally, we establish a novel procedural photo-realistic dataset generation pipeline and create a large-scale transparent object detection dataset, Syn-TODD, which is suitable for training networks with all three modalities, RGB-D, stereo and multi-view RGB. Project Site: https://ac-rad.github.io/MVTrans/
Semi-supervised Hand Appearance Recovery via Structure Disentanglement and Dual Adversarial Discrimination
Mar 11, 2023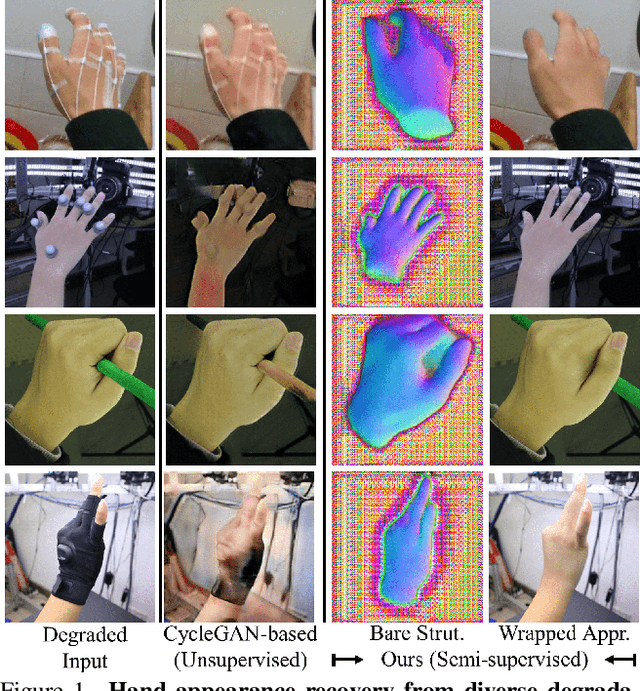
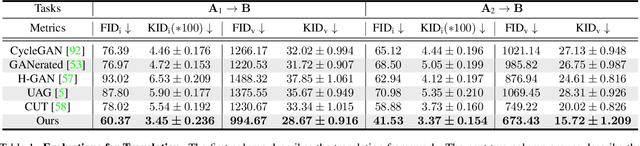

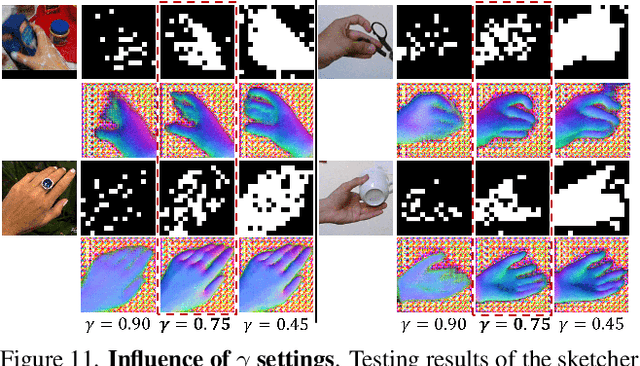
Enormous hand images with reliable annotations are collected through marker-based MoCap. Unfortunately, degradations caused by markers limit their application in hand appearance reconstruction. A clear appearance recovery insight is an image-to-image translation trained with unpaired data. However, most frameworks fail because there exists structure inconsistency from a degraded hand to a bare one. The core of our approach is to first disentangle the bare hand structure from those degraded images and then wrap the appearance to this structure with a dual adversarial discrimination (DAD) scheme. Both modules take full advantage of the semi-supervised learning paradigm: The structure disentanglement benefits from the modeling ability of ViT, and the translator is enhanced by the dual discrimination on both translation processes and translation results. Comprehensive evaluations have been conducted to prove that our framework can robustly recover photo-realistic hand appearance from diverse marker-contained and even object-occluded datasets. It provides a novel avenue to acquire bare hand appearance data for other downstream learning problems.The codes will be publicly available at https://www.yangangwang.com
RSFNet: A White-Box Image Retouching Approach using Region-Specific Color Filters
Mar 15, 2023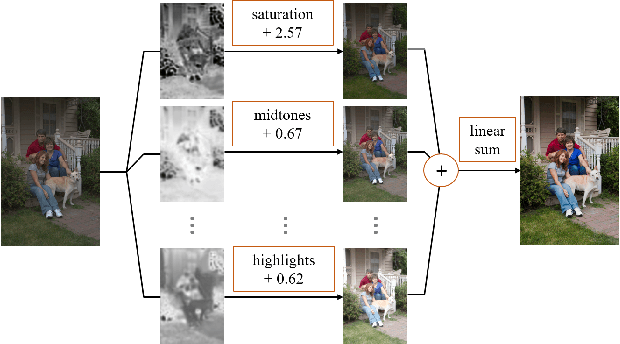
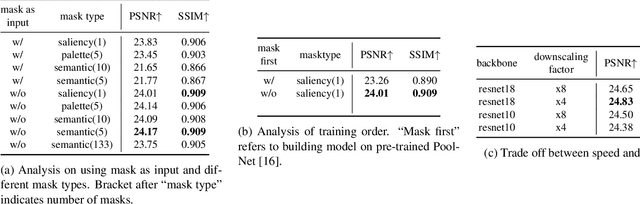
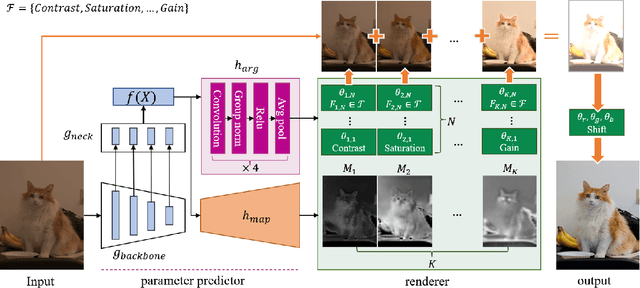
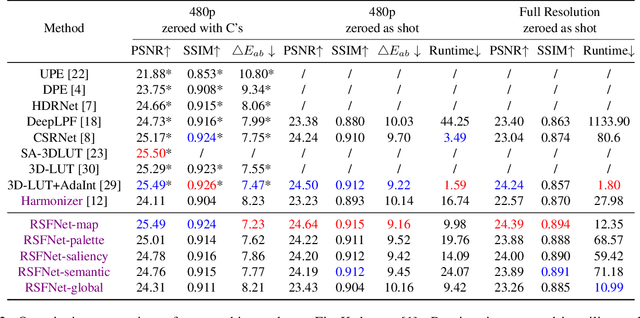
Retouching images is an essential aspect of enhancing the visual appeal of photos. Although users often share common aesthetic preferences, their retouching methods may vary based on their individual preferences. Therefore, there is a need for white-box approaches that produce satisfying results and enable users to conveniently edit their images simultaneously. Recent white-box retouching methods rely on cascaded global filters that provide image-level filter arguments but cannot perform fine-grained retouching. In contrast, colorists typically use a divide-and-conquer approach, performing a series of region-specific fine-grained enhancements when using traditional tools like Davinci Resolve. We draw on this insight to develop a white-box framework for photo retouching using parallel region-specific filters, called RSFNet. Our model generates filter arguments (e.g., saturation, contrast, hue) and attention maps of regions for each filter simultaneously. Instead of cascading filters, RSFNet employs linear summations of filters, allowing for a more diverse range of filter classes that can be trained more easily. Our experiments demonstrate that RSFNet achieves state-of-the-art results, offering satisfying aesthetic appeal and greater user convenience for editable white-box retouching.
NeRF-DS: Neural Radiance Fields for Dynamic Specular Objects
Mar 25, 2023
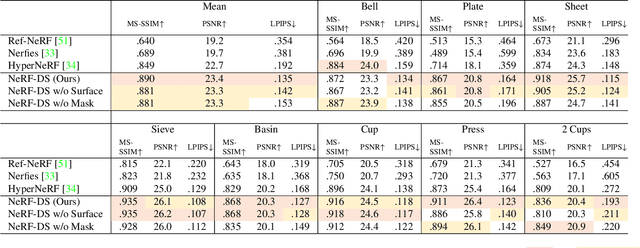
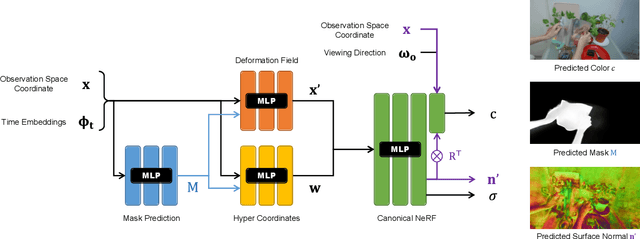
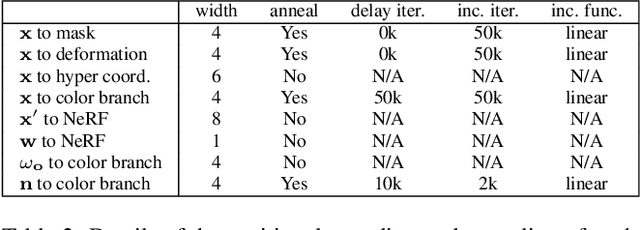
Dynamic Neural Radiance Field (NeRF) is a powerful algorithm capable of rendering photo-realistic novel view images from a monocular RGB video of a dynamic scene. Although it warps moving points across frames from the observation spaces to a common canonical space for rendering, dynamic NeRF does not model the change of the reflected color during the warping. As a result, this approach often fails drastically on challenging specular objects in motion. We address this limitation by reformulating the neural radiance field function to be conditioned on surface position and orientation in the observation space. This allows the specular surface at different poses to keep the different reflected colors when mapped to the common canonical space. Additionally, we add the mask of moving objects to guide the deformation field. As the specular surface changes color during motion, the mask mitigates the problem of failure to find temporal correspondences with only RGB supervision. We evaluate our model based on the novel view synthesis quality with a self-collected dataset of different moving specular objects in realistic environments. The experimental results demonstrate that our method significantly improves the reconstruction quality of moving specular objects from monocular RGB videos compared to the existing NeRF models. Our code and data are available at the project website https://github.com/JokerYan/NeRF-DS.
Unsupervised Contrastive Photo-to-Caricature Translation based on Auto-distortion
Nov 10, 2020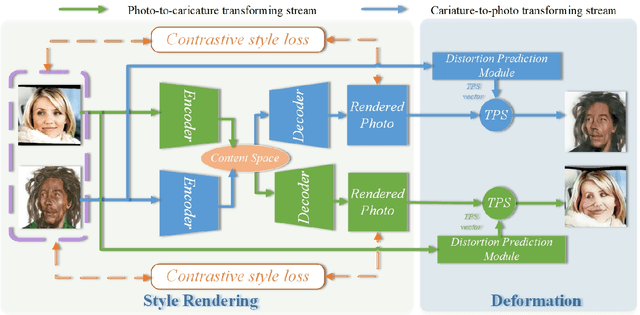
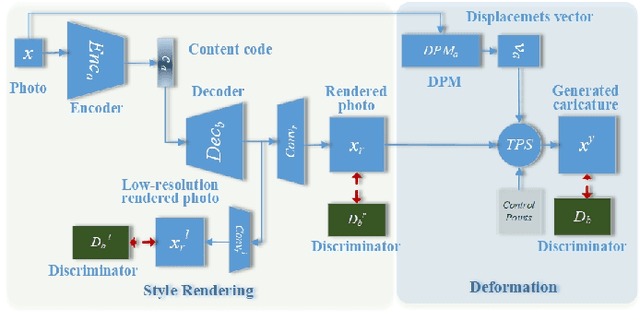

Photo-to-caricature translation aims to synthesize the caricature as a rendered image exaggerating the features through sketching, pencil strokes, or other artistic drawings. Style rendering and geometry deformation are the most important aspects in photo-to-caricature translation task. To take both into consideration, we propose an unsupervised contrastive photo-to-caricature translation architecture. Considering the intuitive artifacts in the existing methods, we propose a contrastive style loss for style rendering to enforce the similarity between the style of rendered photo and the caricature, and simultaneously enhance its discrepancy to the photos. To obtain an exaggerating deformation in an unpaired/unsupervised fashion, we propose a Distortion Prediction Module (DPM) to predict a set of displacements vectors for each input image while fixing some controlling points, followed by the thin plate spline interpolation for warping. The model is trained on unpaired photo and caricature while can offer bidirectional synthesizing via inputting either a photo or a caricature. Extensive experiments demonstrate that the proposed model is effective to generate hand-drawn like caricatures compared with existing competitors.
AgileGAN3D: Few-Shot 3D Portrait Stylization by Augmented Transfer Learning
Mar 24, 2023
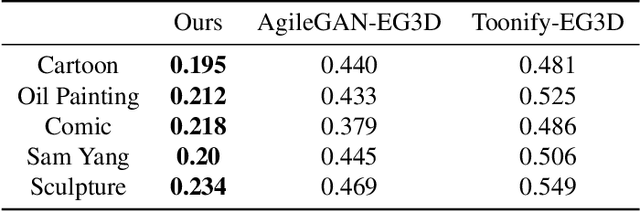
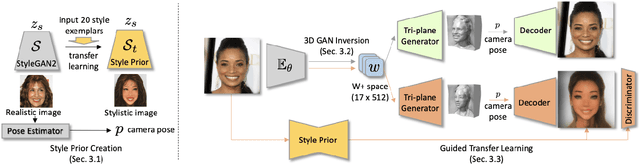

While substantial progresses have been made in automated 2D portrait stylization, admirable 3D portrait stylization from a single user photo remains to be an unresolved challenge. One primary obstacle here is the lack of high quality stylized 3D training data. In this paper, we propose a novel framework \emph{AgileGAN3D} that can produce 3D artistically appealing and personalized portraits with detailed geometry. New stylization can be obtained with just a few (around 20) unpaired 2D exemplars. We achieve this by first leveraging existing 2D stylization capabilities, \emph{style prior creation}, to produce a large amount of augmented 2D style exemplars. These augmented exemplars are generated with accurate camera pose labels, as well as paired real face images, which prove to be critical for the downstream 3D stylization task. Capitalizing on the recent advancement of 3D-aware GAN models, we perform \emph{guided transfer learning} on a pretrained 3D GAN generator to produce multi-view-consistent stylized renderings. In order to achieve 3D GAN inversion that can preserve subject's identity well, we incorporate \emph{multi-view consistency loss} in the training of our encoder. Our pipeline demonstrates strong capability in turning user photos into a diverse range of 3D artistic portraits. Both qualitative results and quantitative evaluations have been conducted to show the superior performance of our method. Code and pretrained models will be released for reproduction purpose.
Efficient Meshy Neural Fields for Animatable Human Avatars
Mar 23, 2023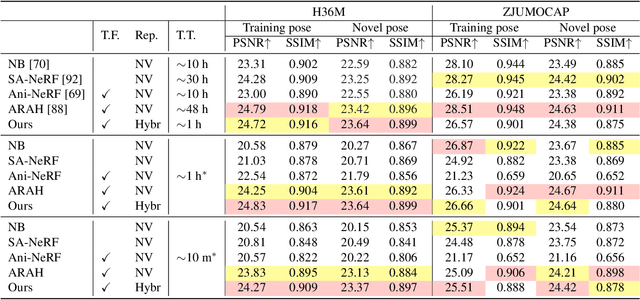
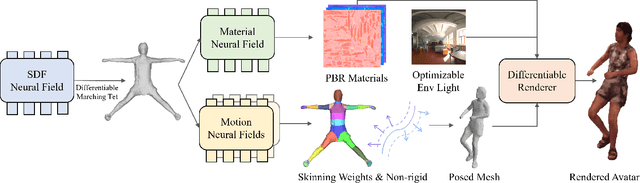
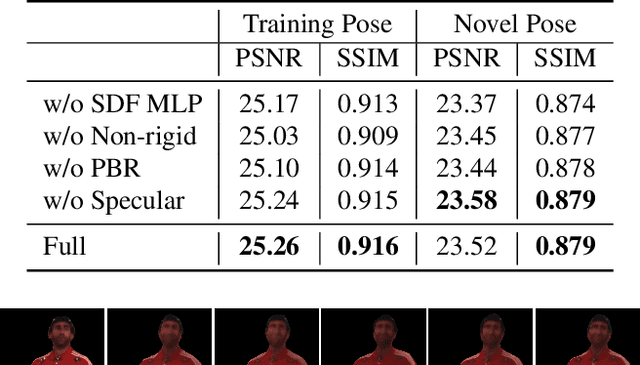

Efficiently digitizing high-fidelity animatable human avatars from videos is a challenging and active research topic. Recent volume rendering-based neural representations open a new way for human digitization with their friendly usability and photo-realistic reconstruction quality. However, they are inefficient for long optimization times and slow inference speed; their implicit nature results in entangled geometry, materials, and dynamics of humans, which are hard to edit afterward. Such drawbacks prevent their direct applicability to downstream applications, especially the prominent rasterization-based graphic ones. We present EMA, a method that Efficiently learns Meshy neural fields to reconstruct animatable human Avatars. It jointly optimizes explicit triangular canonical mesh, spatial-varying material, and motion dynamics, via inverse rendering in an end-to-end fashion. Each above component is derived from separate neural fields, relaxing the requirement of a template, or rigging. The mesh representation is highly compatible with the efficient rasterization-based renderer, thus our method only takes about an hour of training and can render in real-time. Moreover, only minutes of optimization is enough for plausible reconstruction results. The disentanglement of meshes enables direct downstream applications. Extensive experiments illustrate the very competitive performance and significant speed boost against previous methods. We also showcase applications including novel pose synthesis, material editing, and relighting. The project page: https://xk-huang.github.io/ema/.
Using Decoupled Features for Photo-realistic Style Transfer
Dec 05, 2022

In this work we propose a photorealistic style transfer method for image and video that is based on vision science principles and on a recent mathematical formulation for the deterministic decoupling of sample statistics. The novel aspects of our approach include matching decoupled moments of higher order than in common style transfer approaches, and matching a descriptor of the power spectrum so as to characterize and transfer diffusion effects between source and target, which is something that has not been considered before in the literature. The results are of high visual quality, without spatio-temporal artifacts, and validation tests in the form of observer preference experiments show that our method compares very well with the state-of-the-art. The computational complexity of the algorithm is low, and we propose a numerical implementation that is amenable for real-time video application. Finally, another contribution of our work is to point out that current deep learning approaches for photorealistic style transfer don't really achieve photorealistic quality outside of limited examples, because the results too often show unacceptable visual artifacts.