 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Series Photo Selection via Multi-view Graph Learning
Mar 18, 2022

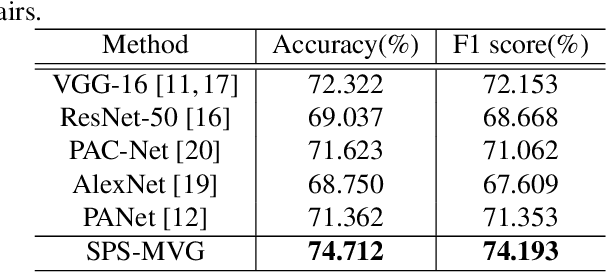
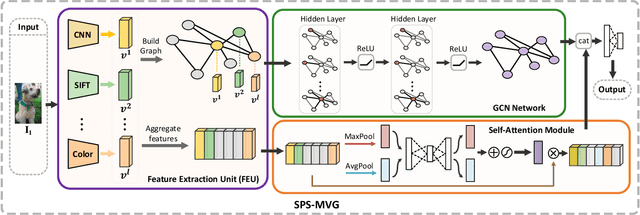
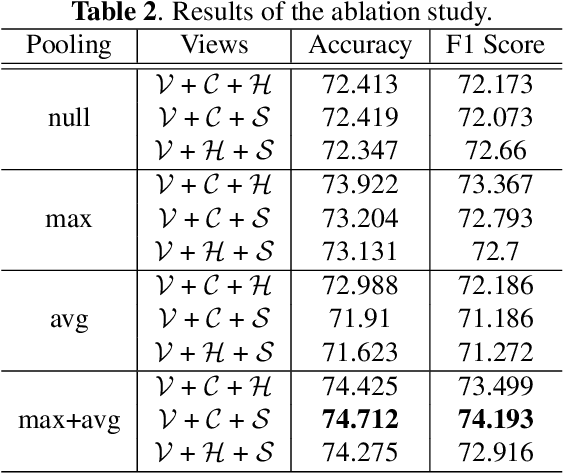
Series photo selection (SPS) is an important branch of the image aesthetics quality assessment, which focuses on finding the best one from a series of nearly identical photos. While a great progress has been observed, most of the existing SPS approaches concentrate solely on extracting features from the original image, neglecting that multiple views, e.g, saturation level, color histogram and depth of field of the image, will be of benefit to successfully reflecting the subtle aesthetic changes. Taken multi-view into consideration, we leverage a graph neural network to construct the relationships between multi-view features. Besides, multiple views are aggregated with an adaptive-weight self-attention module to verify the significance of each view. Finally, a siamese network is proposed to select the best one from a series of nearly identical photos. Experimental results demonstrate that our model accomplish the highest success rates compared with competitive methods.
Head3D: Complete 3D Head Generation via Tri-plane Feature Distillation
Mar 28, 2023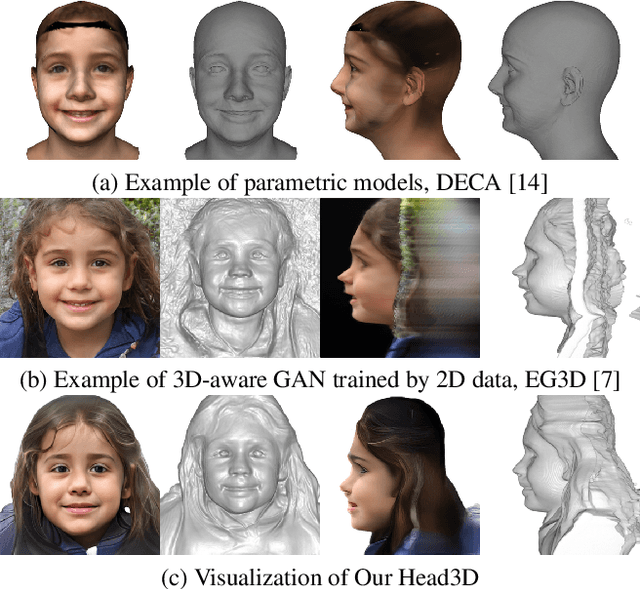

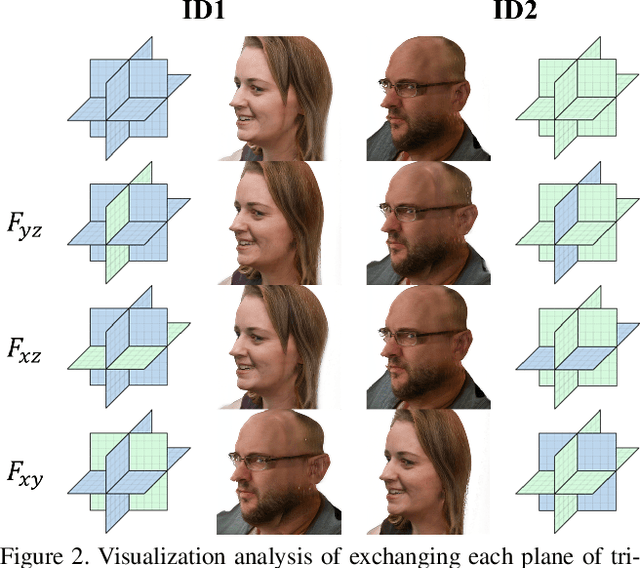

Head generation with diverse identities is an important task in computer vision and computer graphics, widely used in multimedia applications. However, current full head generation methods require a large number of 3D scans or multi-view images to train the model, resulting in expensive data acquisition cost. To address this issue, we propose Head3D, a method to generate full 3D heads with limited multi-view images. Specifically, our approach first extracts facial priors represented by tri-planes learned in EG3D, a 3D-aware generative model, and then proposes feature distillation to deliver the 3D frontal faces into complete heads without compromising head integrity. To mitigate the domain gap between the face and head models, we present dual-discriminators to guide the frontal and back head generation, respectively. Our model achieves cost-efficient and diverse complete head generation with photo-realistic renderings and high-quality geometry representations. Extensive experiments demonstrate the effectiveness of our proposed Head3D, both qualitatively and quantitatively.
NPR: Nocturnal Place Recognition in Street
Apr 01, 2023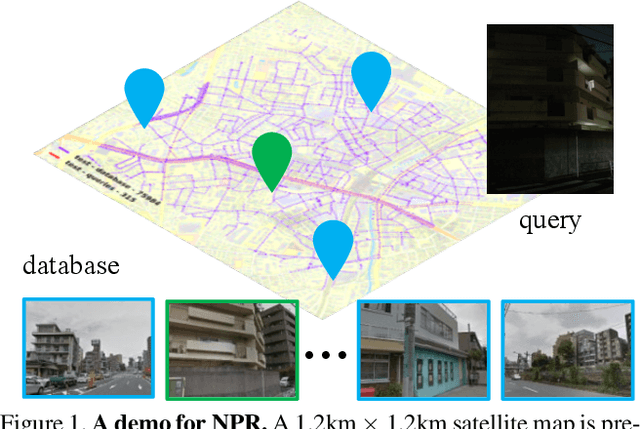
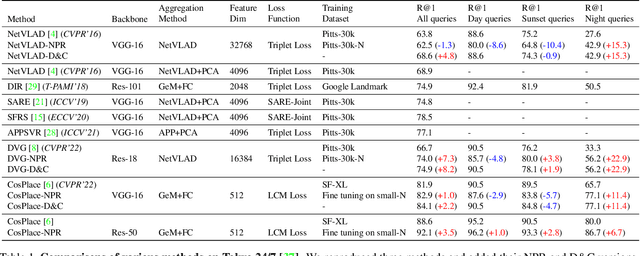


Visual Place Recognition (VPR) is the task of retrieving database images similar to a query photo by comparing it to a large database of known images. In real-world applications, extreme illumination changes caused by query images taken at night pose a significant obstacle that VPR needs to overcome. However, a training set with day-night correspondence for city-scale, street-level VPR does not exist. To address this challenge, we propose a novel pipeline that divides VPR and conquers Nocturnal Place Recognition (NPR). Specifically, we first established a street-level day-night dataset, NightStreet, and used it to train an unpaired image-to-image translation model. Then we used this model to process existing large-scale VPR datasets to generate the VPR-Night datasets and demonstrated how to combine them with two popular VPR pipelines. Finally, we proposed a divide-and-conquer VPR framework and provided explanations at the theoretical, experimental, and application levels. Under our framework, previous methods can significantly improve performance on two public datasets, including the top-ranked method.
PhotoChat: A Human-Human Dialogue Dataset with Photo Sharing Behavior for Joint Image-Text Modeling
Jul 06, 2021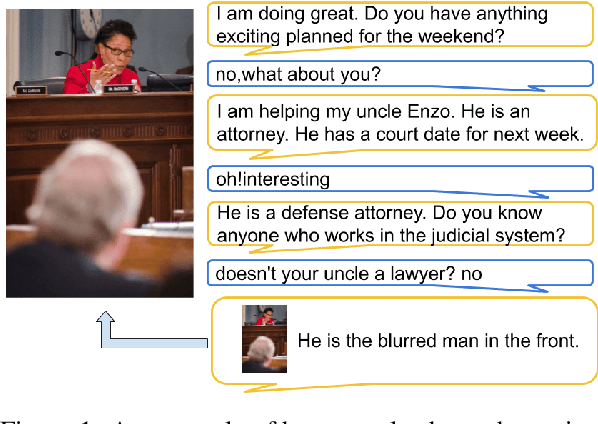
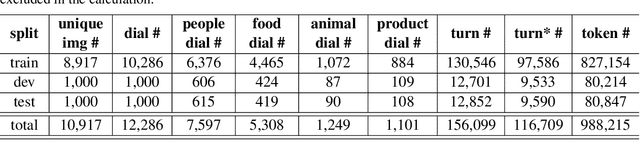
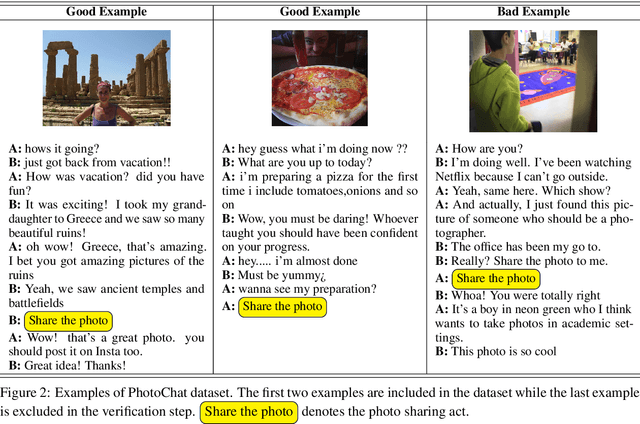
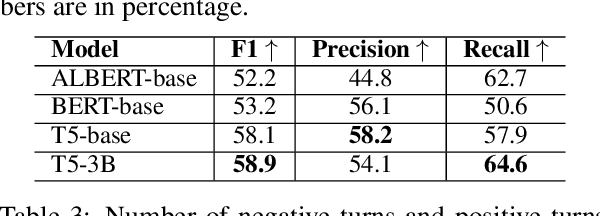
We present a new human-human dialogue dataset - PhotoChat, the first dataset that casts light on the photo sharing behavior in onlin emessaging. PhotoChat contains 12k dialogues, each of which is paired with a user photo that is shared during the conversation. Based on this dataset, we propose two tasks to facilitate research on image-text modeling: a photo-sharing intent prediction task that predicts whether one intends to share a photo in the next conversation turn, and a photo retrieval task that retrieves the most relevant photo according to the dialogue context. In addition, for both tasks, we provide baseline models using the state-of-the-art models and report their benchmark performances. The best image retrieval model achieves 10.4% recall@1 (out of 1000 candidates) and the best photo intent prediction model achieves 58.1% F1 score, indicating that the dataset presents interesting yet challenging real-world problems. We are releasing PhotoChat to facilitate future research work among the community.
StyleGAN Salon: Multi-View Latent Optimization for Pose-Invariant Hairstyle Transfer
Apr 05, 2023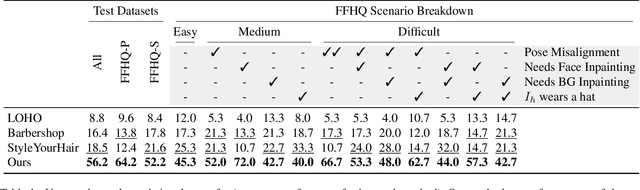
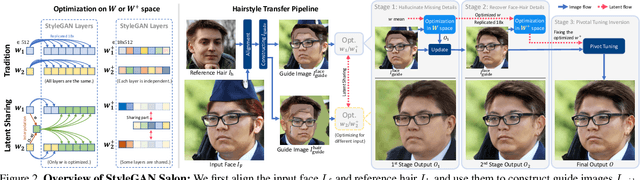
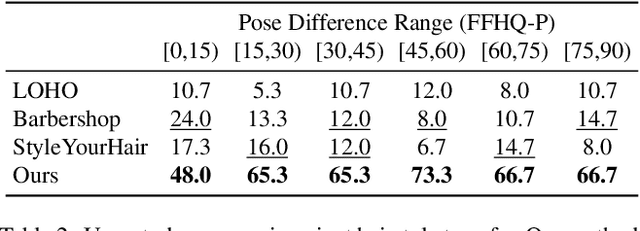

Our paper seeks to transfer the hairstyle of a reference image to an input photo for virtual hair try-on. We target a variety of challenges scenarios, such as transforming a long hairstyle with bangs to a pixie cut, which requires removing the existing hair and inferring how the forehead would look, or transferring partially visible hair from a hat-wearing person in a different pose. Past solutions leverage StyleGAN for hallucinating any missing parts and producing a seamless face-hair composite through so-called GAN inversion or projection. However, there remains a challenge in controlling the hallucinations to accurately transfer hairstyle and preserve the face shape and identity of the input. To overcome this, we propose a multi-view optimization framework that uses "two different views" of reference composites to semantically guide occluded or ambiguous regions. Our optimization shares information between two poses, which allows us to produce high fidelity and realistic results from incomplete references. Our framework produces high-quality results and outperforms prior work in a user study that consists of significantly more challenging hair transfer scenarios than previously studied. Project page: https://stylegan-salon.github.io/.
Few-shot Semantic Image Synthesis with Class Affinity Transfer
Apr 05, 2023
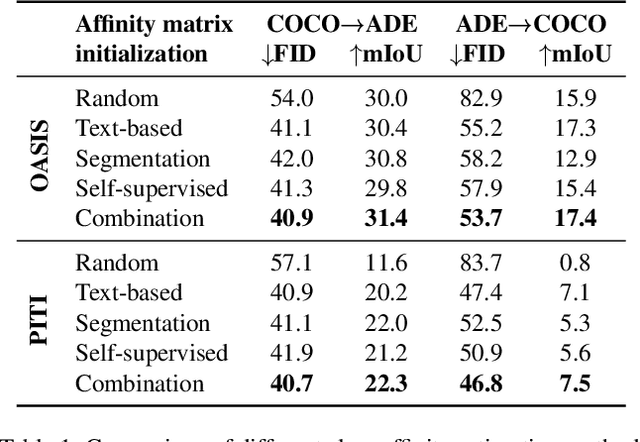
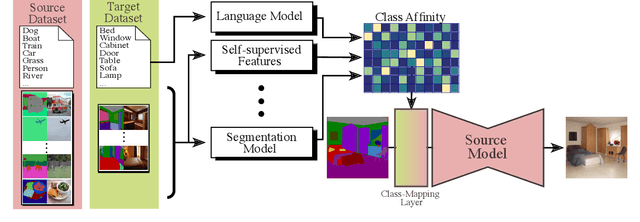
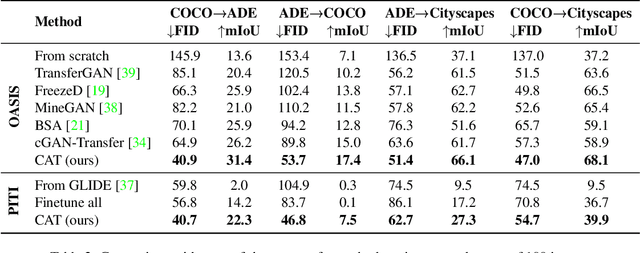
Semantic image synthesis aims to generate photo realistic images given a semantic segmentation map. Despite much recent progress, training them still requires large datasets of images annotated with per-pixel label maps that are extremely tedious to obtain. To alleviate the high annotation cost, we propose a transfer method that leverages a model trained on a large source dataset to improve the learning ability on small target datasets via estimated pairwise relations between source and target classes. The class affinity matrix is introduced as a first layer to the source model to make it compatible with the target label maps, and the source model is then further finetuned for the target domain. To estimate the class affinities we consider different approaches to leverage prior knowledge: semantic segmentation on the source domain, textual label embeddings, and self-supervised vision features. We apply our approach to GAN-based and diffusion-based architectures for semantic synthesis. Our experiments show that the different ways to estimate class affinity can be effectively combined, and that our approach significantly improves over existing state-of-the-art transfer approaches for generative image models.
If At First You Don't Succeed: Test Time Re-ranking for Zero-shot, Cross-domain Retrieval
Mar 30, 2023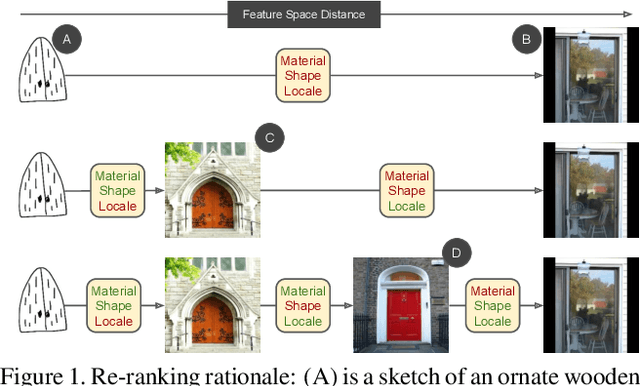
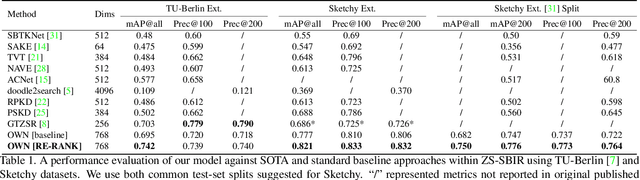
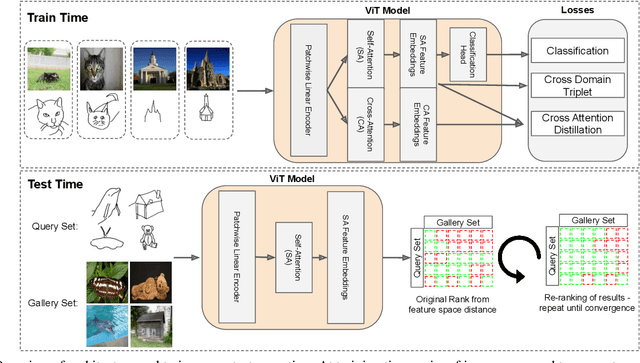
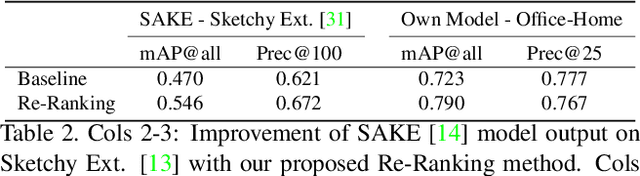
In this paper we propose a novel method for zero-shot, cross-domain image retrieval in which we make two key contributions. The first is a test-time re-ranking procedure that enables query-gallery pairs, without meaningful shared visual features, to be matched by incorporating gallery-gallery ranks into an iterative re-ranking process. The second is the use of cross-attention at training time and knowledge distillation to encourage cross-attention-like features to be extracted at test time from a single image. When combined with the Vision Transformer architecture and zero-shot retrieval losses, our approach yields state-of-the-art results on the Sketchy and TU-Berlin sketch-based image retrieval benchmarks. However, unlike many previous methods, none of the components in our approach are engineered specifically towards the sketch-based image retrieval task - it can be generally applied to any cross-domain, zero-shot retrieval task. We therefore also show results on zero-shot cartoon-to-photo retrieval using the Office-Home dataset.
DINAR: Diffusion Inpainting of Neural Textures for One-Shot Human Avatars
Mar 17, 2023
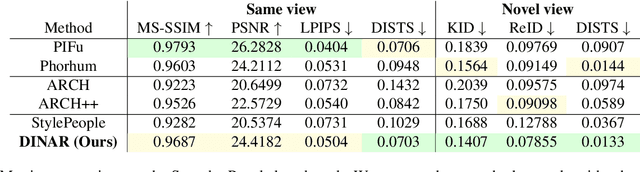
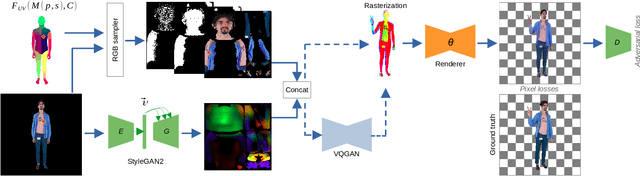
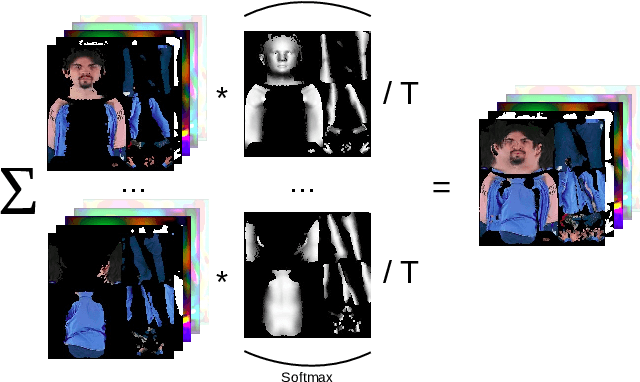
We present DINAR, an approach for creating realistic rigged fullbody avatars from single RGB images. Similarly to previous works, our method uses neural textures combined with the SMPL-X body model to achieve photo-realistic quality of avatars while keeping them easy to animate and fast to infer. To restore the texture, we use a latent diffusion model and show how such model can be trained in the neural texture space. The use of the diffusion model allows us to realistically reconstruct large unseen regions such as the back of a person given the frontal view. The models in our pipeline are trained using 2D images and videos only. In the experiments, our approach achieves state-of-the-art rendering quality and good generalization to new poses and viewpoints. In particular, the approach improves state-of-the-art on the SnapshotPeople public benchmark.
Deep Photo Scan: Semi-supervised learning for dealing with the real-world degradation in smartphone photo scanning
Feb 11, 2021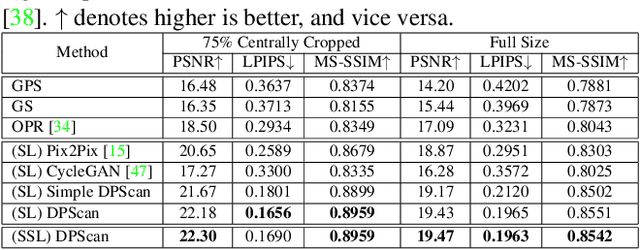
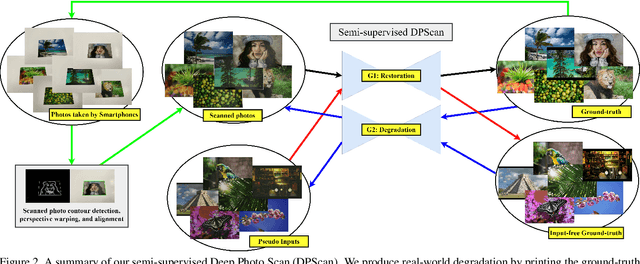
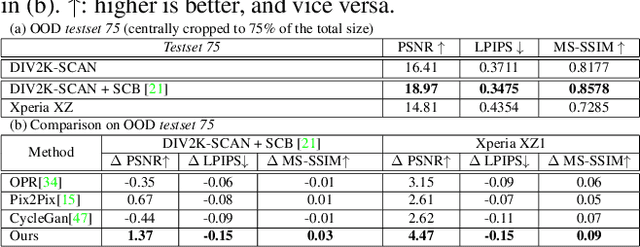
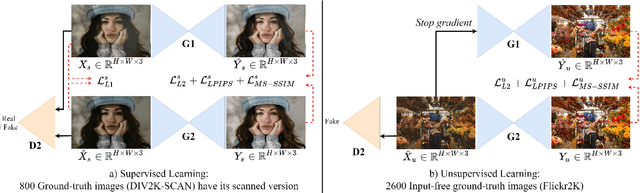
Physical photographs now can be conveniently scanned by smartphones and stored forever as a digital version, but the scanned photos are not restored well. One solution is to train a supervised deep neural network on many digital photos and the corresponding scanned photos. However, human annotation costs a huge resource leading to limited training data. Previous works create training pairs by simulating degradation using image processing techniques. Their synthetic images are formed with perfectly scanned photos in latent space. Even so, the real-world degradation in smartphone photo scanning remains unsolved since it is more complicated due to real lens defocus, lighting conditions, losing details via printing, various photo materials, and more. To solve these problems, we propose a Deep Photo Scan (DPScan) based on semi-supervised learning. First, we present the way to produce real-world degradation and provide the DIV2K-SCAN dataset for smartphone-scanned photo restoration. Second, by using DIV2K-SCAN, we adopt the concept of Generative Adversarial Networks to learn how to degrade a high-quality image as if it were scanned by a real smartphone, then generate pseudo-scanned photos for unscanned photos. Finally, we propose to train on the scanned and pseudo-scanned photos representing a semi-supervised approach with a cycle process as: high-quality images --> real-/pseudo-scanned photos --> reconstructed images. The proposed semi-supervised scheme can balance between supervised and unsupervised errors while optimizing to limit imperfect pseudo inputs but still enhance restoration. As a result, the proposed DPScan quantitatively and qualitatively outperforms its baseline architecture, state-of-the-art academic research, and industrial products in smartphone photo scanning.
TriVol: Point Cloud Rendering via Triple Volumes
Mar 29, 2023
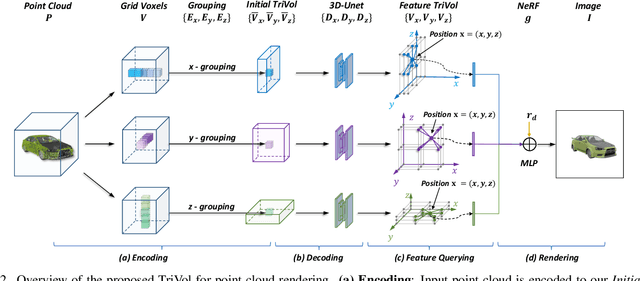
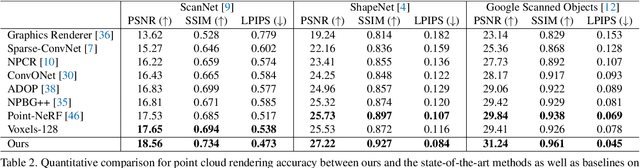
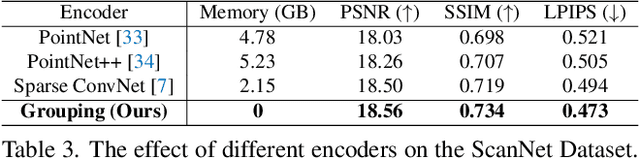
Existing learning-based methods for point cloud rendering adopt various 3D representations and feature querying mechanisms to alleviate the sparsity problem of point clouds. However, artifacts still appear in rendered images, due to the challenges in extracting continuous and discriminative 3D features from point clouds. In this paper, we present a dense while lightweight 3D representation, named TriVol, that can be combined with NeRF to render photo-realistic images from point clouds. Our TriVol consists of triple slim volumes, each of which is encoded from the point cloud. TriVol has two advantages. First, it fuses respective fields at different scales and thus extracts local and non-local features for discriminative representation. Second, since the volume size is greatly reduced, our 3D decoder can be efficiently inferred, allowing us to increase the resolution of the 3D space to render more point details. Extensive experiments on different benchmarks with varying kinds of scenes/objects demonstrate our framework's effectiveness compared with current approaches. Moreover, our framework has excellent generalization ability to render a category of scenes/objects without fine-tuning.