 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Active Semantic Localization with Graph Neural Embedding
May 15, 2023
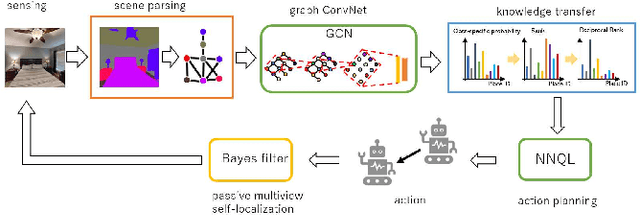
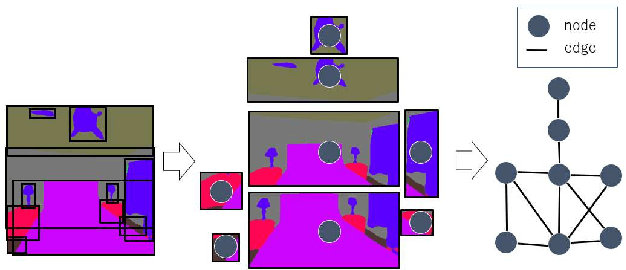


Semantic localization, i.e., robot self-localization with semantic image modality, is critical in recently emerging embodied AI applications such as point-goal navigation, object-goal navigation and vision language navigation. However, most existing works on semantic localization focus on passive vision tasks without viewpoint planning, or rely on additional rich modalities (e.g., depth measurements). Thus, the problem is largely unsolved. In this work, we explore a lightweight, entirely CPU-based, domain-adaptive semantic localization framework, called graph neural localizer.Our approach is inspired by two recently emerging technologies: (1) Scene graph, which combines the viewpoint- and appearance- invariance of local and global features; (2) Graph neural network, which enables direct learning/recognition of graph data (i.e., non-vector data). Specifically, a graph convolutional neural network is first trained as a scene graph classifier for passive vision, and then its knowledge is transferred to a reinforcement-learning planner for active vision. Experiments on two scenarios, self-supervised learning and unsupervised domain adaptation, using a photo-realistic Habitat simulator validate the effectiveness of the proposed method.
Style Transfer for 2D Talking Head Animation
Mar 17, 2023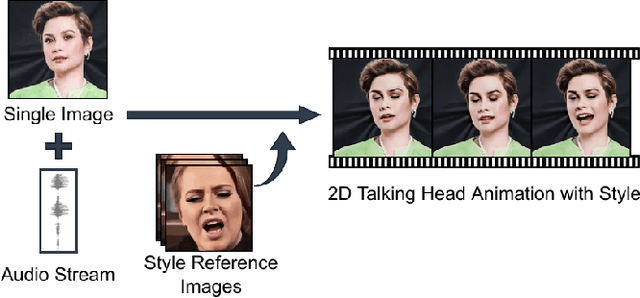
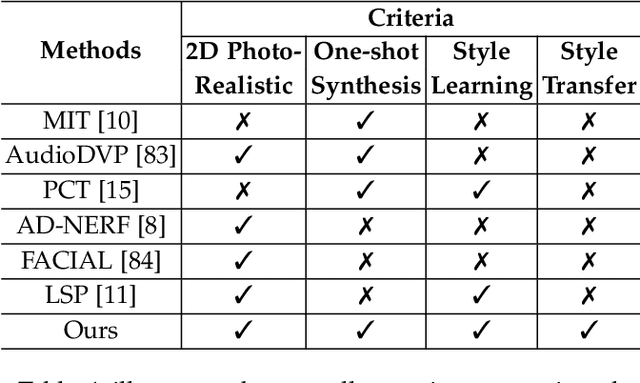
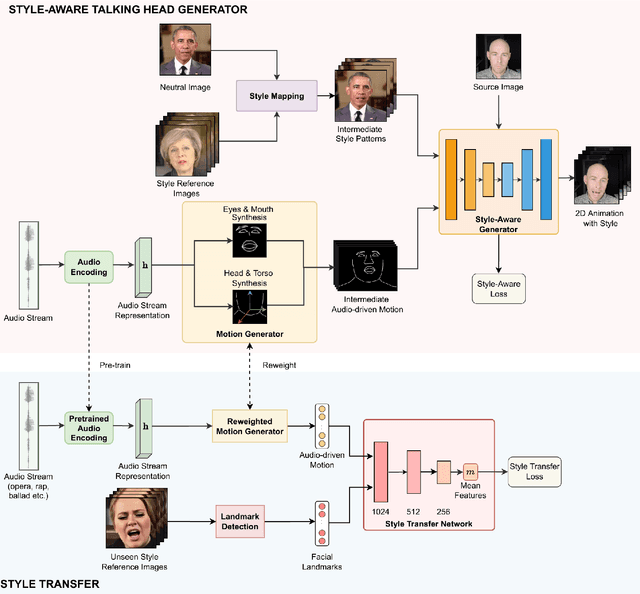
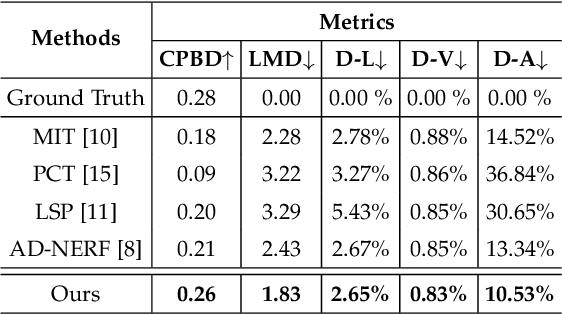
Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.
Adapt and Align to Improve Zero-Shot Sketch-Based Image Retrieval
May 18, 2023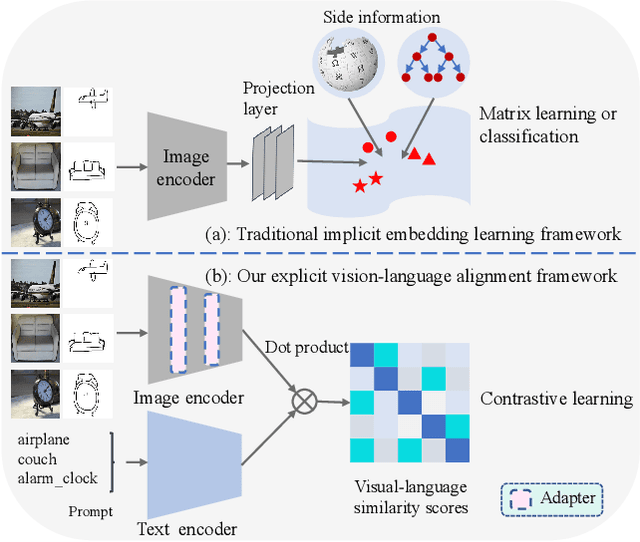
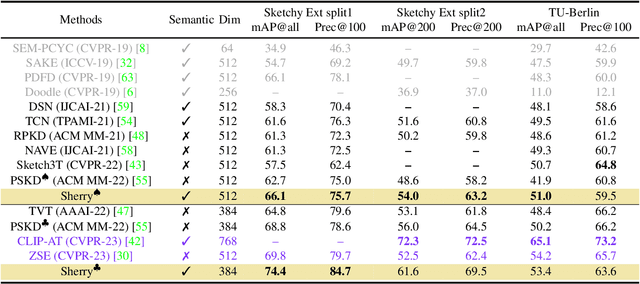
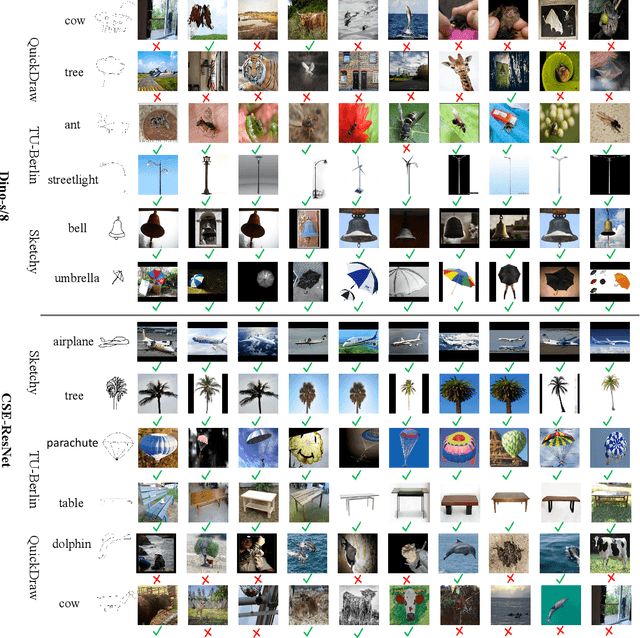
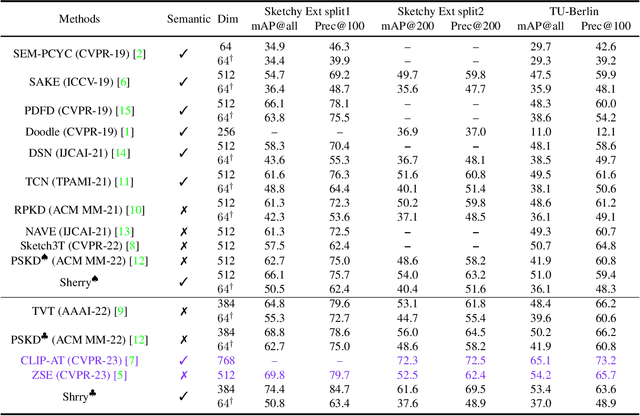
Zero-shot sketch-based image retrieval (ZS-SBIR) is challenging due to the cross-domain nature of sketches and photos, as well as the semantic gap between seen and unseen image distributions. Previous methods fine-tune pre-trained models with various side information and learning strategies to learn a compact feature space that is shared between the sketch and photo domains and bridges seen and unseen classes. However, these efforts are inadequate in adapting domains and transferring knowledge from seen to unseen classes. In this paper, we present an effective ``Adapt and Align'' approach to address the key challenges. Specifically, we insert simple and lightweight domain adapters to learn new abstract concepts of the sketch domain and improve cross-domain representation capabilities. Inspired by recent advances in image-text foundation models (e.g., CLIP) on zero-shot scenarios, we explicitly align the learned image embedding with a more semantic text embedding to achieve the desired knowledge transfer from seen to unseen classes. Extensive experiments on three benchmark datasets and two popular backbones demonstrate the superiority of our method in terms of retrieval accuracy and flexibility.
Learning to Evaluate the Artness of AI-generated Images
May 08, 2023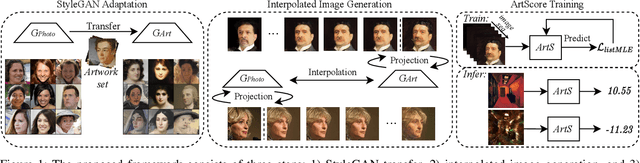
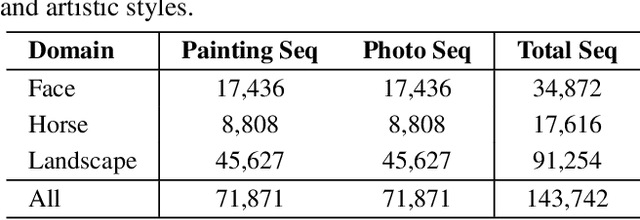
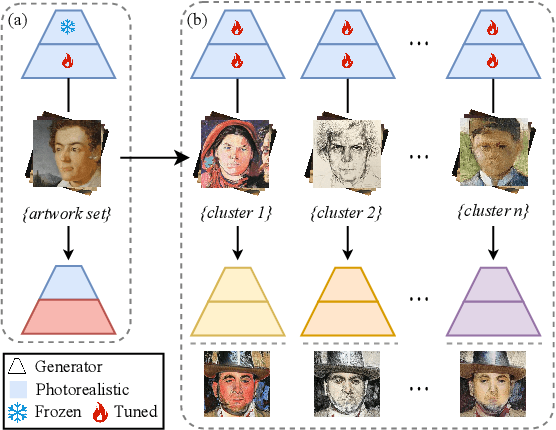
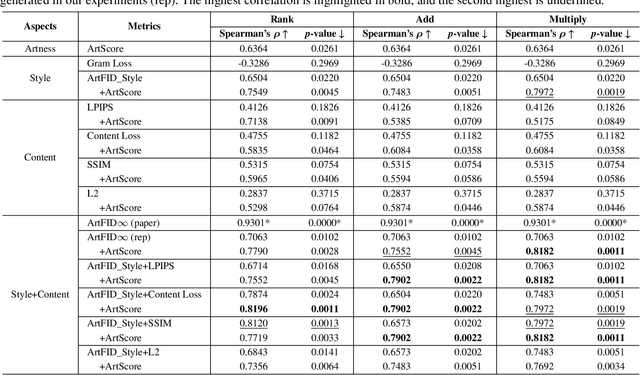
Assessing the artness of AI-generated images continues to be a challenge within the realm of image generation. Most existing metrics cannot be used to perform instance-level and reference-free artness evaluation. This paper presents ArtScore, a metric designed to evaluate the degree to which an image resembles authentic artworks by artists (or conversely photographs), thereby offering a novel approach to artness assessment. We first blend pre-trained models for photo and artwork generation, resulting in a series of mixed models. Subsequently, we utilize these mixed models to generate images exhibiting varying degrees of artness with pseudo-annotations. Each photorealistic image has a corresponding artistic counterpart and a series of interpolated images that range from realistic to artistic. This dataset is then employed to train a neural network that learns to estimate quantized artness levels of arbitrary images. Extensive experiments reveal that the artness levels predicted by ArtScore align more closely with human artistic evaluation than existing evaluation metrics, such as Gram loss and ArtFID.
Diffusion-HPC: Generating Synthetic Images with Realistic Humans
Mar 16, 2023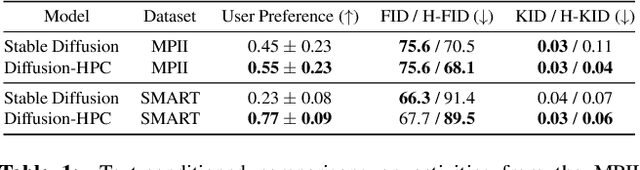
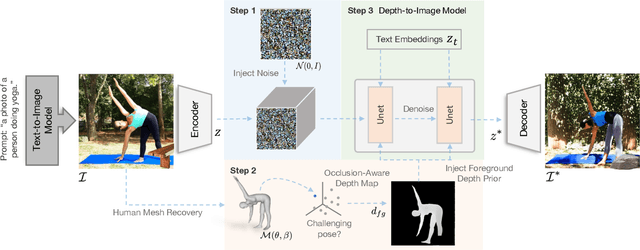
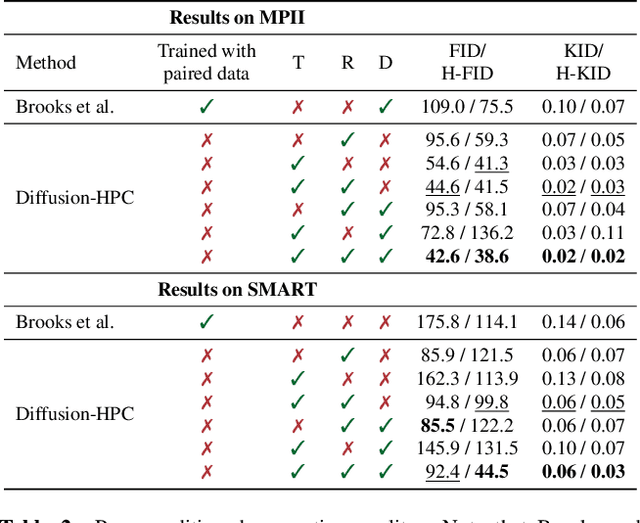

Recent text-to-image generative models have exhibited remarkable abilities in generating high-fidelity and photo-realistic images. However, despite the visually impressive results, these models often struggle to preserve plausible human structure in the generations. Due to this reason, while generative models have shown promising results in aiding downstream image recognition tasks by generating large volumes of synthetic data, they remain infeasible for improving downstream human pose perception and understanding. In this work, we propose Diffusion model with Human Pose Correction (Diffusion HPC), a text-conditioned method that generates photo-realistic images with plausible posed humans by injecting prior knowledge about human body structure. We show that Diffusion HPC effectively improves the realism of human generations. Furthermore, as the generations are accompanied by 3D meshes that serve as ground truths, Diffusion HPC's generated image-mesh pairs are well-suited for downstream human mesh recovery task, where a shortage of 3D training data has long been an issue.
DermSynth3D: Synthesis of in-the-wild Annotated Dermatology Images
May 22, 2023

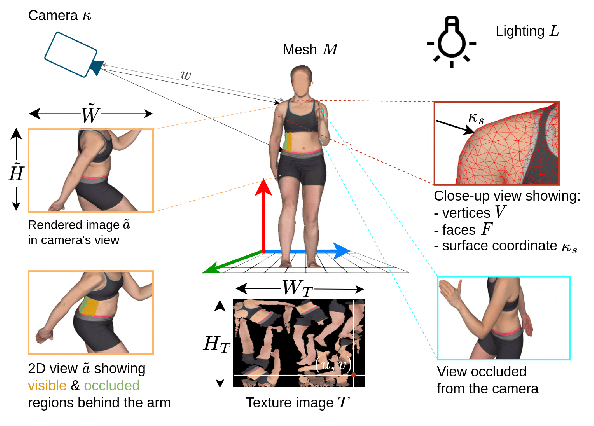

In recent years, deep learning (DL) has shown great potential in the field of dermatological image analysis. However, existing datasets in this domain have significant limitations, including a small number of image samples, limited disease conditions, insufficient annotations, and non-standardized image acquisitions. To address these shortcomings, we propose a novel framework called DermSynth3D. DermSynth3D blends skin disease patterns onto 3D textured meshes of human subjects using a differentiable renderer and generates 2D images from various camera viewpoints under chosen lighting conditions in diverse background scenes. Our method adheres to top-down rules that constrain the blending and rendering process to create 2D images with skin conditions that mimic in-the-wild acquisitions, ensuring more meaningful results. The framework generates photo-realistic 2D dermoscopy images and the corresponding dense annotations for semantic segmentation of the skin, skin conditions, body parts, bounding boxes around lesions, depth maps, and other 3D scene parameters, such as camera position and lighting conditions. DermSynth3D allows for the creation of custom datasets for various dermatology tasks. We demonstrate the effectiveness of data generated using DermSynth3D by training DL models on synthetic data and evaluating them on various dermatology tasks using real 2D dermatological images. We make our code publicly available at https://github.com/sfu-mial/DermSynth3D
AutoPhoto: Aesthetic Photo Capture using Reinforcement Learning
Sep 21, 2021
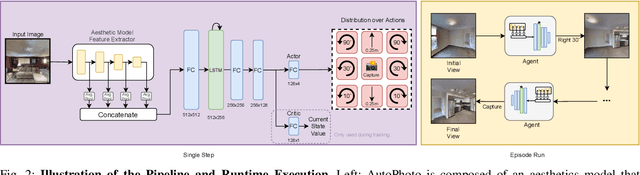


The process of capturing a well-composed photo is difficult and it takes years of experience to master. We propose a novel pipeline for an autonomous agent to automatically capture an aesthetic photograph by navigating within a local region in a scene. Instead of classical optimization over heuristics such as the rule-of-thirds, we adopt a data-driven aesthetics estimator to assess photo quality. A reinforcement learning framework is used to optimize the model with respect to the learned aesthetics metric. We train our model in simulation with indoor scenes, and we demonstrate that our system can capture aesthetic photos in both simulation and real world environments on a ground robot. To our knowledge, this is the first system that can automatically explore an environment to capture an aesthetic photo with respect to a learned aesthetic estimator.
OccCasNet: Occlusion-aware Cascade Cost Volume for Light Field Depth Estimation
May 28, 2023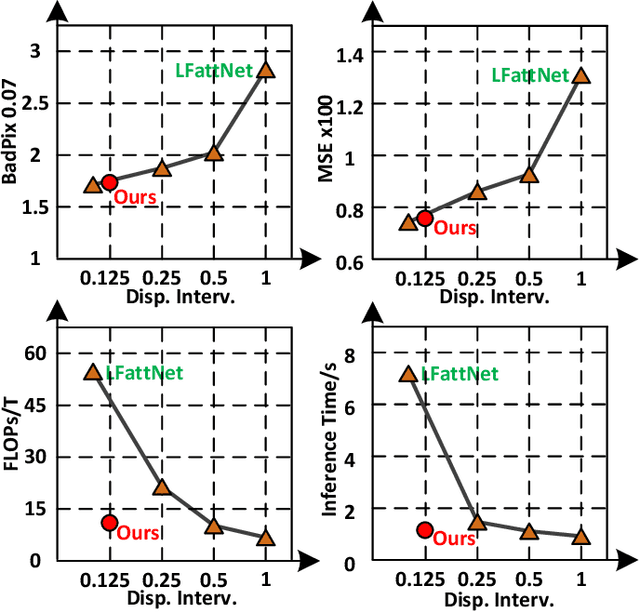
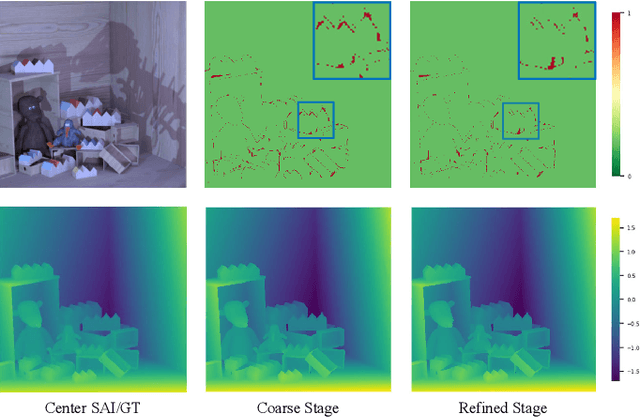


Light field (LF) depth estimation is a crucial task with numerous practical applications. However, mainstream methods based on the multi-view stereo (MVS) are resource-intensive and time-consuming as they need to construct a finer cost volume. To address this issue and achieve a better trade-off between accuracy and efficiency, we propose an occlusion-aware cascade cost volume for LF depth (disparity) estimation. Our cascaded strategy reduces the sampling number while keeping the sampling interval constant during the construction of a finer cost volume. We also introduce occlusion maps to enhance accuracy in constructing the occlusion-aware cost volume. Specifically, we first obtain the coarse disparity map through the coarse disparity estimation network. Then, the sub-aperture images (SAIs) of side views are warped to the center view based on the initial disparity map. Next, we propose photo-consistency constraints between the warped SAIs and the center SAI to generate occlusion maps for each SAI. Finally, we introduce the coarse disparity map and occlusion maps to construct an occlusion-aware refined cost volume, enabling the refined disparity estimation network to yield a more precise disparity map. Extensive experiments demonstrate the effectiveness of our method. Compared with state-of-the-art methods, our method achieves a superior balance between accuracy and efficiency and ranks first in terms of MSE and Q25 metrics among published methods on the HCI 4D benchmark. The code and model of the proposed method are available at https://github.com/chaowentao/OccCasNet.
Sequence-Agnostic Multi-Object Navigation
May 10, 2023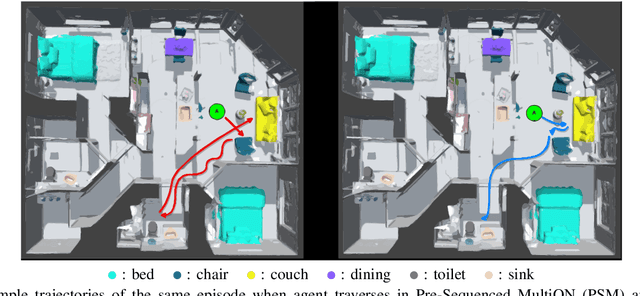
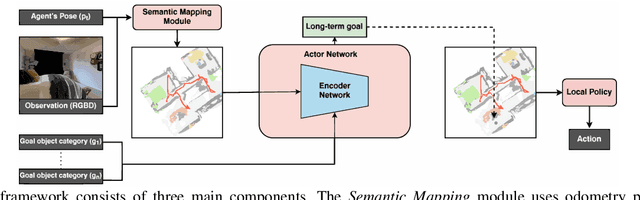
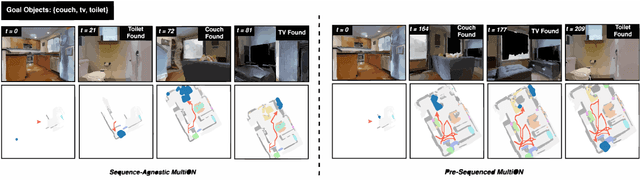
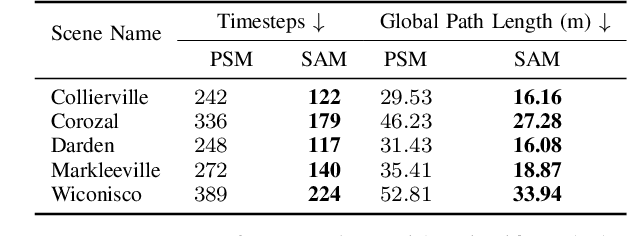
The Multi-Object Navigation (MultiON) task requires a robot to localize an instance (each) of multiple object classes. It is a fundamental task for an assistive robot in a home or a factory. Existing methods for MultiON have viewed this as a direct extension of Object Navigation (ON), the task of localising an instance of one object class, and are pre-sequenced, i.e., the sequence in which the object classes are to be explored is provided in advance. This is a strong limitation in practical applications characterized by dynamic changes. This paper describes a deep reinforcement learning framework for sequence-agnostic MultiON based on an actor-critic architecture and a suitable reward specification. Our framework leverages past experiences and seeks to reward progress toward individual as well as multiple target object classes. We use photo-realistic scenes from the Gibson benchmark dataset in the AI Habitat 3D simulation environment to experimentally show that our method performs better than a pre-sequenced approach and a state of the art ON method extended to MultiON.