 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Federated Few-shot Learning
Jun 22, 2023
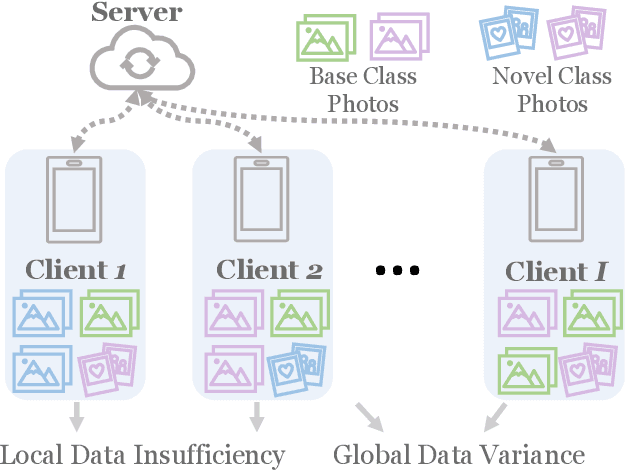
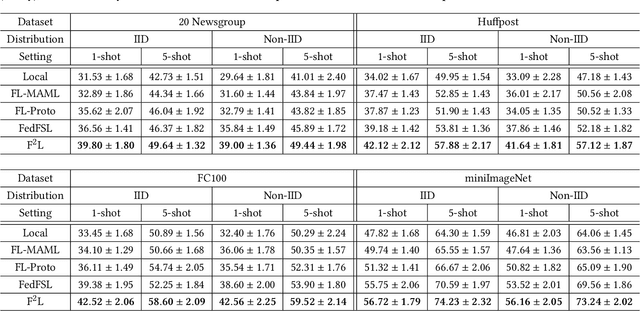
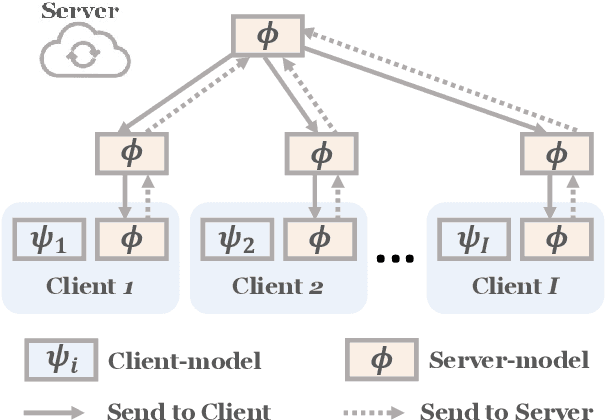

Federated Learning (FL) enables multiple clients to collaboratively learn a machine learning model without exchanging their own local data. In this way, the server can exploit the computational power of all clients and train the model on a larger set of data samples among all clients. Although such a mechanism is proven to be effective in various fields, existing works generally assume that each client preserves sufficient data for training. In practice, however, certain clients may only contain a limited number of samples (i.e., few-shot samples). For example, the available photo data taken by a specific user with a new mobile device is relatively rare. In this scenario, existing FL efforts typically encounter a significant performance drop on these clients. Therefore, it is urgent to develop a few-shot model that can generalize to clients with limited data under the FL scenario. In this paper, we refer to this novel problem as federated few-shot learning. Nevertheless, the problem remains challenging due to two major reasons: the global data variance among clients (i.e., the difference in data distributions among clients) and the local data insufficiency in each client (i.e., the lack of adequate local data for training). To overcome these two challenges, we propose a novel federated few-shot learning framework with two separately updated models and dedicated training strategies to reduce the adverse impact of global data variance and local data insufficiency. Extensive experiments on four prevalent datasets that cover news articles and images validate the effectiveness of our framework compared with the state-of-the-art baselines. Our code is provided at https://github.com/SongW-SW/F2L.
Deceptive-NeRF: Enhancing NeRF Reconstruction using Pseudo-Observations from Diffusion Models
May 24, 2023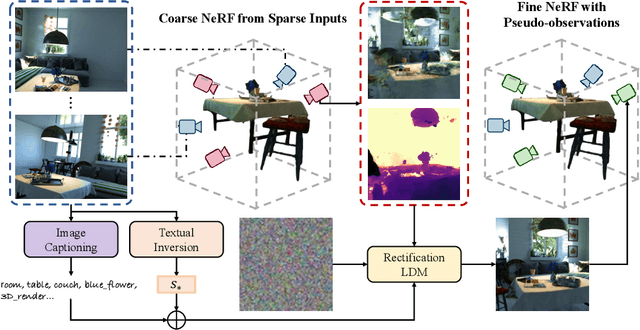



This paper introduces Deceptive-NeRF, a new method for enhancing the quality of reconstructed NeRF models using synthetically generated pseudo-observations, capable of handling sparse input and removing floater artifacts. Our proposed method involves three key steps: 1) reconstruct a coarse NeRF model from sparse inputs; 2) generate pseudo-observations based on the coarse model; 3) refine the NeRF model using pseudo-observations to produce a high-quality reconstruction. To generate photo-realistic pseudo-observations that faithfully preserve the identity of the reconstructed scene while remaining consistent with the sparse inputs, we develop a rectification latent diffusion model that generates images conditional on a coarse RGB image and depth map, which are derived from the coarse NeRF and latent text embedding from input images. Extensive experiments show that our method is effective and can generate perceptually high-quality NeRF even with very sparse inputs.
Control4D: Dynamic Portrait Editing by Learning 4D GAN from 2D Diffusion-based Editor
May 31, 2023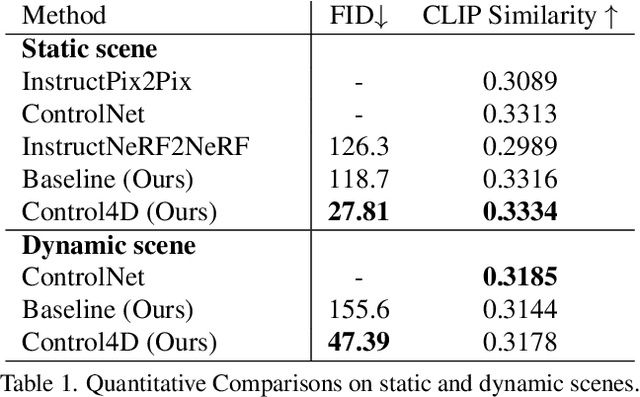
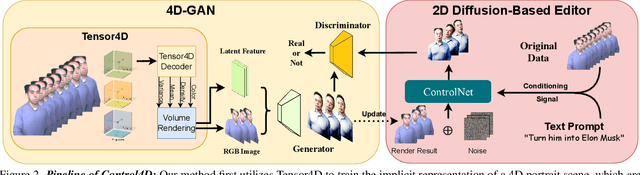
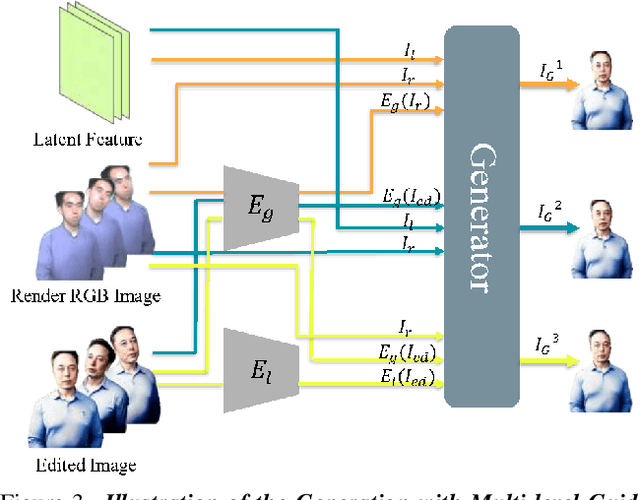

Recent years have witnessed considerable achievements in editing images with text instructions. When applying these editors to dynamic scene editing, the new-style scene tends to be temporally inconsistent due to the frame-by-frame nature of these 2D editors. To tackle this issue, we propose Control4D, a novel approach for high-fidelity and temporally consistent 4D portrait editing. Control4D is built upon an efficient 4D representation with a 2D diffusion-based editor. Instead of using direct supervisions from the editor, our method learns a 4D GAN from it and avoids the inconsistent supervision signals. Specifically, we employ a discriminator to learn the generation distribution based on the edited images and then update the generator with the discrimination signals. For more stable training, multi-level information is extracted from the edited images and used to facilitate the learning of the generator. Experimental results show that Control4D surpasses previous approaches and achieves more photo-realistic and consistent 4D editing performances. The link to our project website is https://control4darxiv.github.io.
Neural Projection Mapping Using Reflectance Fields
Jun 11, 2023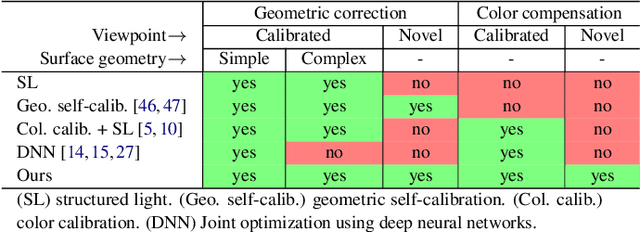
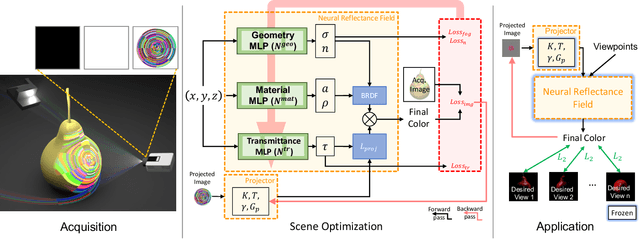
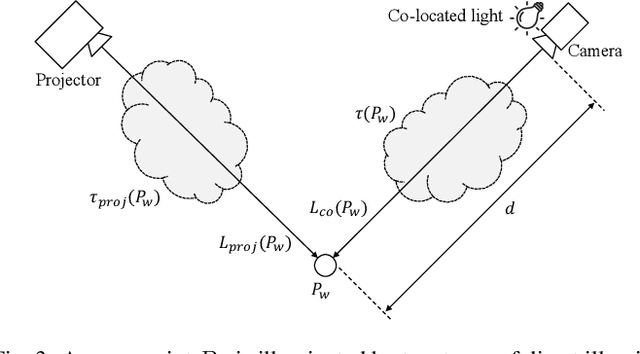
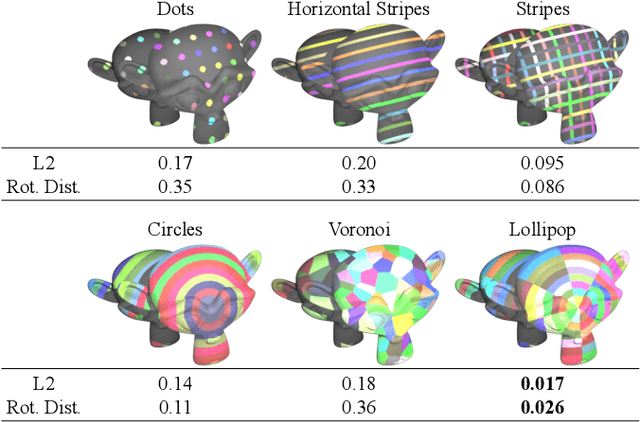
We introduce a high resolution spatially adaptive light source, or a projector, into a neural reflectance field that allows to both calibrate the projector and photo realistic light editing. The projected texture is fully differentiable with respect to all scene parameters, and can be optimized to yield a desired appearance suitable for applications in augmented reality and projection mapping. Our neural field consists of three neural networks, estimating geometry, material, and transmittance. Using an analytical BRDF model and carefully selected projection patterns, our acquisition process is simple and intuitive, featuring a fixed uncalibrated projected and a handheld camera with a co-located light source. As we demonstrate, the virtual projector incorporated into the pipeline improves scene understanding and enables various projection mapping applications, alleviating the need for time consuming calibration steps performed in a traditional setting per view or projector location. In addition to enabling novel viewpoint synthesis, we demonstrate state-of-the-art performance projector compensation for novel viewpoints, improvement over the baselines in material and scene reconstruction, and three simply implemented scenarios where projection image optimization is performed, including the use of a 2D generative model to consistently dictate scene appearance from multiple viewpoints. We believe that neural projection mapping opens up the door to novel and exciting downstream tasks, through the joint optimization of the scene and projection images.
Atmospheric Turbulence Correction via Variational Deep Diffusion
May 08, 2023

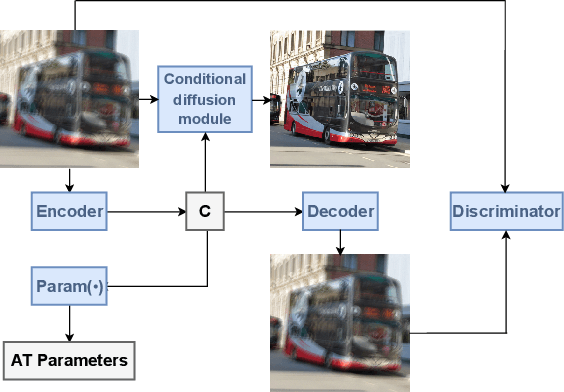
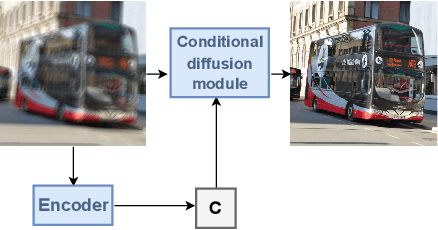
Atmospheric Turbulence (AT) correction is a challenging restoration task as it consists of two distortions: geometric distortion and spatially variant blur. Diffusion models have shown impressive accomplishments in photo-realistic image synthesis and beyond. In this paper, we propose a novel deep conditional diffusion model under a variational inference framework to solve the AT correction problem. We use this framework to improve performance by learning latent prior information from the input and degradation processes. We use the learned information to further condition the diffusion model. Experiments are conducted in a comprehensive synthetic AT dataset. We show that the proposed framework achieves good quantitative and qualitative results.
Adding 3D Geometry Control to Diffusion Models
Jun 13, 2023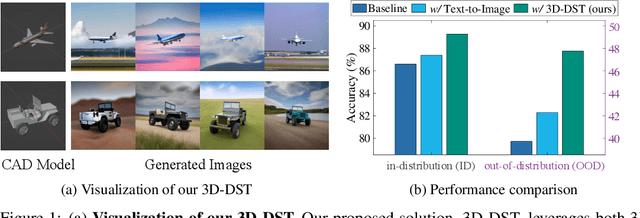
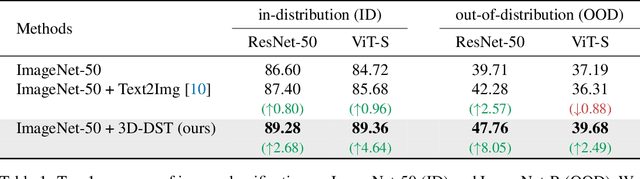
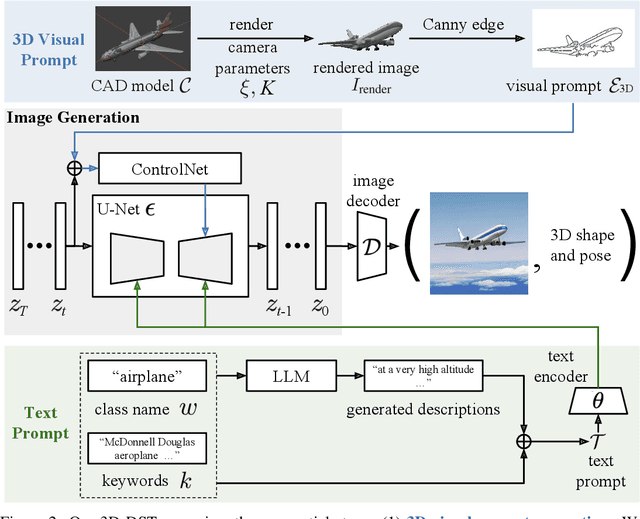
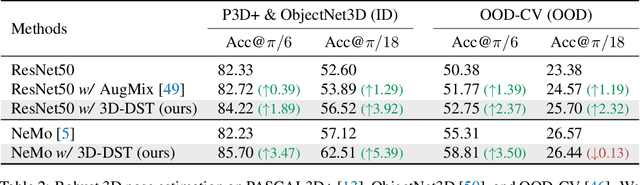
Diffusion models have emerged as a powerful method of generative modeling across a range of fields, capable of producing stunning photo-realistic images from natural language descriptions. However, these models lack explicit control over the 3D structure of the objects in the generated images. In this paper, we propose a novel method that incorporates 3D geometry control into diffusion models, making them generate even more realistic and diverse images. To achieve this, our method exploits ControlNet, which extends diffusion models by using visual prompts in addition to text prompts. We generate images of 3D objects taken from a 3D shape repository (e.g., ShapeNet and Objaverse), render them from a variety of poses and viewing directions, compute the edge maps of the rendered images, and use these edge maps as visual prompts to generate realistic images. With explicit 3D geometry control, we can easily change the 3D structures of the objects in the generated images and obtain ground-truth 3D annotations automatically. This allows us to use the generated images to improve a lot of vision tasks, e.g., classification and 3D pose estimation, in both in-distribution (ID) and out-of-distribution (OOD) settings. We demonstrate the effectiveness of our method through extensive experiments on ImageNet-50, ImageNet-R, PASCAL3D+, ObjectNet3D, and OOD-CV datasets. The results show that our method significantly outperforms existing methods across multiple benchmarks (e.g., 4.6 percentage points on ImageNet-50 using ViT and 3.5 percentage points on PASCAL3D+ and ObjectNet3D using NeMo).
InpaintNeRF360: Text-Guided 3D Inpainting on Unbounded Neural Radiance Fields
May 24, 2023
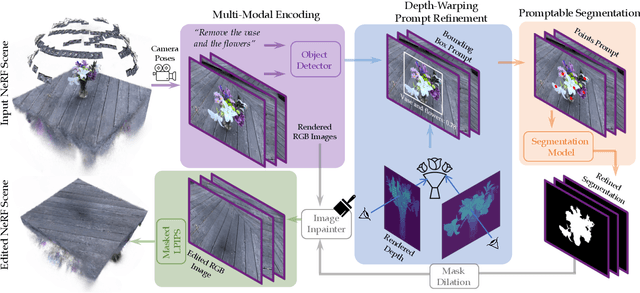
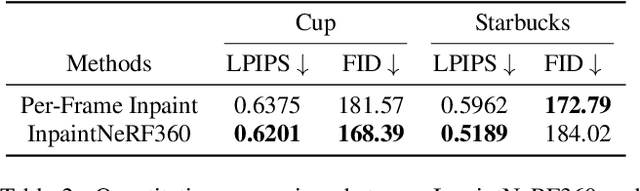

Neural Radiance Fields (NeRF) can generate highly realistic novel views. However, editing 3D scenes represented by NeRF across 360-degree views, particularly removing objects while preserving geometric and photometric consistency, remains a challenging problem due to NeRF's implicit scene representation. In this paper, we propose InpaintNeRF360, a unified framework that utilizes natural language instructions as guidance for inpainting NeRF-based 3D scenes.Our approach employs a promptable segmentation model by generating multi-modal prompts from the encoded text for multiview segmentation. We apply depth-space warping to enforce viewing consistency in the segmentations, and further refine the inpainted NeRF model using perceptual priors to ensure visual plausibility. InpaintNeRF360 is capable of simultaneously removing multiple objects or modifying object appearance based on text instructions while synthesizing 3D viewing-consistent and photo-realistic inpainting. Through extensive experiments on both unbounded and frontal-facing scenes trained through NeRF, we demonstrate the effectiveness of our approach and showcase its potential to enhance the editability of implicit radiance fields.
PyNet-V2 Mobile: Efficient On-Device Photo Processing With Neural Networks
Nov 08, 2022

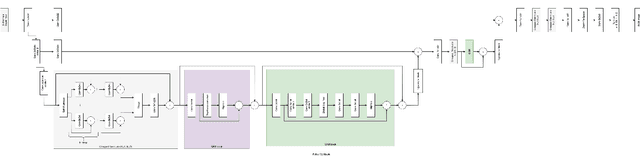

The increased importance of mobile photography created a need for fast and performant RAW image processing pipelines capable of producing good visual results in spite of the mobile camera sensor limitations. While deep learning-based approaches can efficiently solve this problem, their computational requirements usually remain too large for high-resolution on-device image processing. To address this limitation, we propose a novel PyNET-V2 Mobile CNN architecture designed specifically for edge devices, being able to process RAW 12MP photos directly on mobile phones under 1.5 second and producing high perceptual photo quality. To train and to evaluate the performance of the proposed solution, we use the real-world Fujifilm UltraISP dataset consisting on thousands of RAW-RGB image pairs captured with a professional medium-format 102MP Fujifilm camera and a popular Sony mobile camera sensor. The results demonstrate that the PyNET-V2 Mobile model can substantially surpass the quality of tradition ISP pipelines, while outperforming the previously introduced neural network-based solutions designed for fast image processing. Furthermore, we show that the proposed architecture is also compatible with the latest mobile AI accelerators such as NPUs or APUs that can be used to further reduce the latency of the model to as little as 0.5 second. The dataset, code and pre-trained models used in this paper are available on the project website: https://github.com/gmalivenko/PyNET-v2
Understanding Aesthetics with Language: A Photo Critique Dataset for Aesthetic Assessment
Jun 17, 2022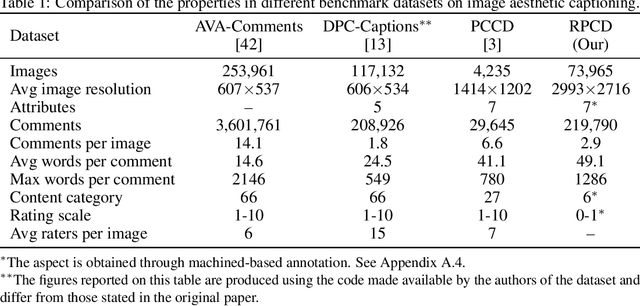

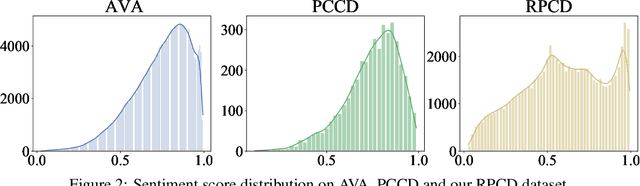
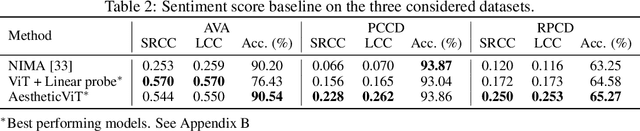
Computational inference of aesthetics is an ill-defined task due to its subjective nature. Many datasets have been proposed to tackle the problem by providing pairs of images and aesthetic scores based on human ratings. However, humans are better at expressing their opinion, taste, and emotions by means of language rather than summarizing them in a single number. In fact, photo critiques provide much richer information as they reveal how and why users rate the aesthetics of visual stimuli. In this regard, we propose the Reddit Photo Critique Dataset (RPCD), which contains tuples of image and photo critiques. RPCD consists of 74K images and 220K comments and is collected from a Reddit community used by hobbyists and professional photographers to improve their photography skills by leveraging constructive community feedback. The proposed dataset differs from previous aesthetics datasets mainly in three aspects, namely (i) the large scale of the dataset and the extension of the comments criticizing different aspects of the image, (ii) it contains mostly UltraHD images, and (iii) it can easily be extended to new data as it is collected through an automatic pipeline. To the best of our knowledge, in this work, we propose the first attempt to estimate the aesthetic quality of visual stimuli from the critiques. To this end, we exploit the polarity of the sentiment of criticism as an indicator of aesthetic judgment. We demonstrate how sentiment polarity correlates positively with the aesthetic judgment available for two aesthetic assessment benchmarks. Finally, we experiment with several models by using the sentiment scores as a target for ranking images. Dataset and baselines are available (https://github.com/mediatechnologycenter/aestheval).