 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Zero-Shot Everything Sketch-Based Image Retrieval, and in Explainable Style
Mar 25, 2023
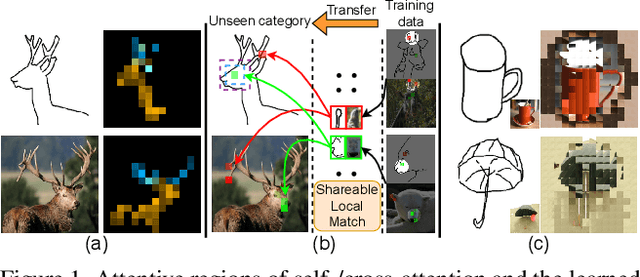
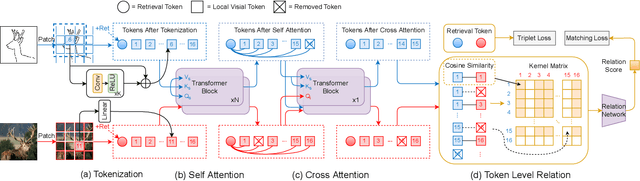
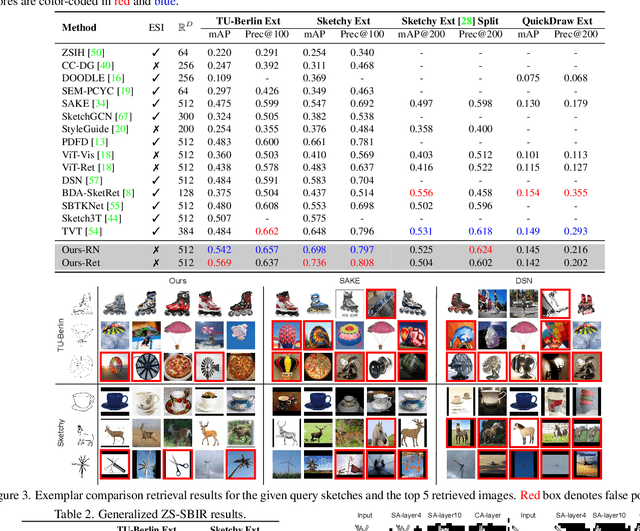
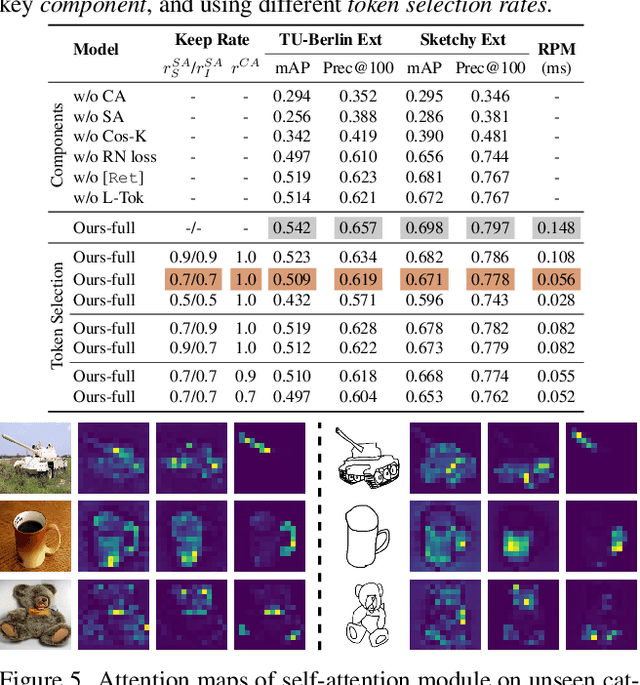
This paper studies the problem of zero-short sketch-based image retrieval (ZS-SBIR), however with two significant differentiators to prior art (i) we tackle all variants (inter-category, intra-category, and cross datasets) of ZS-SBIR with just one network (``everything''), and (ii) we would really like to understand how this sketch-photo matching operates (``explainable''). Our key innovation lies with the realization that such a cross-modal matching problem could be reduced to comparisons of groups of key local patches -- akin to the seasoned ``bag-of-words'' paradigm. Just with this change, we are able to achieve both of the aforementioned goals, with the added benefit of no longer requiring external semantic knowledge. Technically, ours is a transformer-based cross-modal network, with three novel components (i) a self-attention module with a learnable tokenizer to produce visual tokens that correspond to the most informative local regions, (ii) a cross-attention module to compute local correspondences between the visual tokens across two modalities, and finally (iii) a kernel-based relation network to assemble local putative matches and produce an overall similarity metric for a sketch-photo pair. Experiments show ours indeed delivers superior performances across all ZS-SBIR settings. The all important explainable goal is elegantly achieved by visualizing cross-modal token correspondences, and for the first time, via sketch to photo synthesis by universal replacement of all matched photo patches. Code and model are available at \url{https://github.com/buptLinfy/ZSE-SBIR}.
DesCo: Learning Object Recognition with Rich Language Descriptions
Jun 24, 2023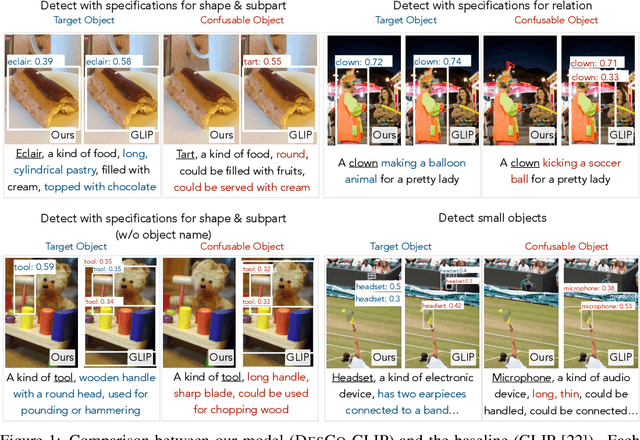
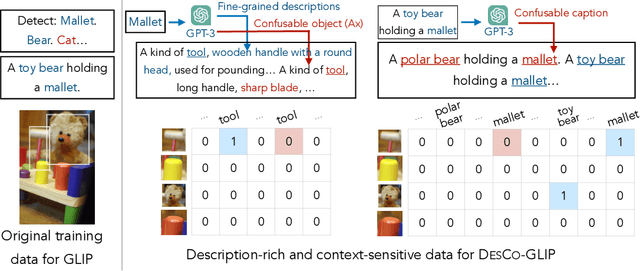
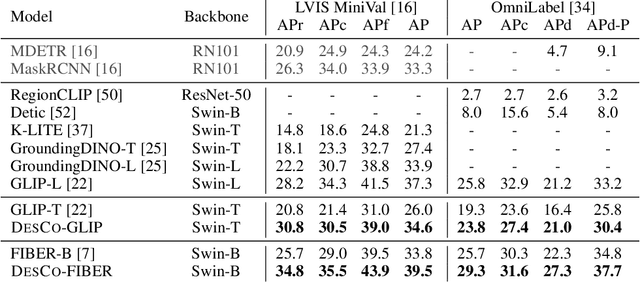

Recent development in vision-language approaches has instigated a paradigm shift in learning visual recognition models from language supervision. These approaches align objects with language queries (e.g. "a photo of a cat") and improve the models' adaptability to identify novel objects and domains. Recently, several studies have attempted to query these models with complex language expressions that include specifications of fine-grained semantic details, such as attributes, shapes, textures, and relations. However, simply incorporating language descriptions as queries does not guarantee accurate interpretation by the models. In fact, our experiments show that GLIP, the state-of-the-art vision-language model for object detection, often disregards contextual information in the language descriptions and instead relies heavily on detecting objects solely by their names. To tackle the challenges, we propose a new description-conditioned (DesCo) paradigm of learning object recognition models with rich language descriptions consisting of two major innovations: 1) we employ a large language model as a commonsense knowledge engine to generate rich language descriptions of objects based on object names and the raw image-text caption; 2) we design context-sensitive queries to improve the model's ability in deciphering intricate nuances embedded within descriptions and enforce the model to focus on context rather than object names alone. On two novel object detection benchmarks, LVIS and OminiLabel, under the zero-shot detection setting, our approach achieves 34.8 APr minival (+9.1) and 29.3 AP (+3.6), respectively, surpassing the prior state-of-the-art models, GLIP and FIBER, by a large margin.
Single-Shot Implicit Morphable Faces with Consistent Texture Parameterization
May 04, 2023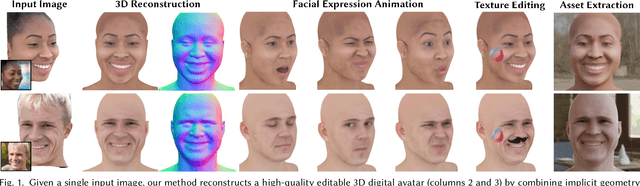

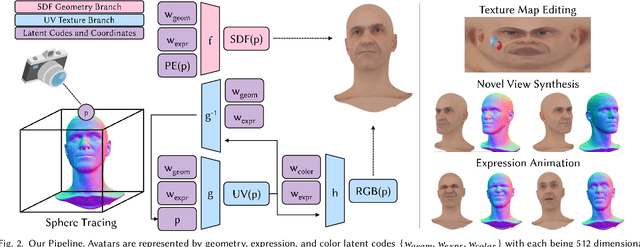
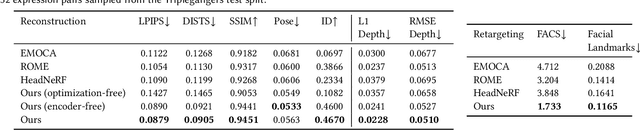
There is a growing demand for the accessible creation of high-quality 3D avatars that are animatable and customizable. Although 3D morphable models provide intuitive control for editing and animation, and robustness for single-view face reconstruction, they cannot easily capture geometric and appearance details. Methods based on neural implicit representations, such as signed distance functions (SDF) or neural radiance fields, approach photo-realism, but are difficult to animate and do not generalize well to unseen data. To tackle this problem, we propose a novel method for constructing implicit 3D morphable face models that are both generalizable and intuitive for editing. Trained from a collection of high-quality 3D scans, our face model is parameterized by geometry, expression, and texture latent codes with a learned SDF and explicit UV texture parameterization. Once trained, we can reconstruct an avatar from a single in-the-wild image by leveraging the learned prior to project the image into the latent space of our model. Our implicit morphable face models can be used to render an avatar from novel views, animate facial expressions by modifying expression codes, and edit textures by directly painting on the learned UV-texture maps. We demonstrate quantitatively and qualitatively that our method improves upon photo-realism, geometry, and expression accuracy compared to state-of-the-art methods.
Zero-Shot 3D Shape Sketch View Similarity and Retrieval
Jun 14, 2023
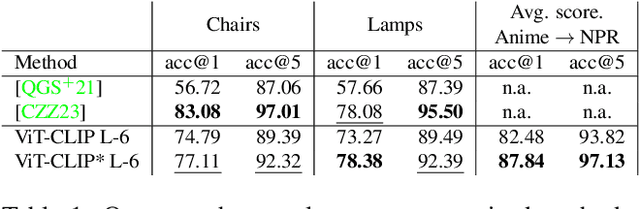
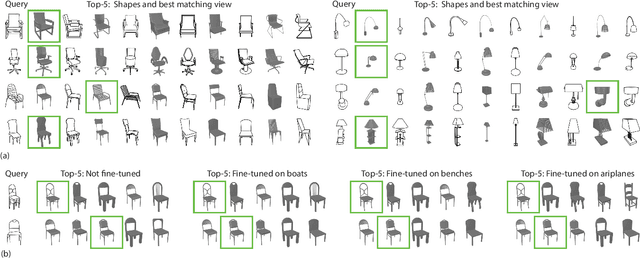
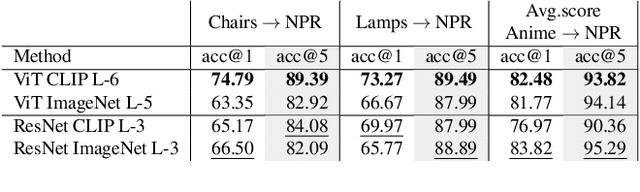
We conduct a detailed study of the ability of pretrained on pretext tasks ViT and ResNet feature layers to quantify the similarity between pairs of 2D sketch views of individual 3D shapes. We assess the performance in terms of the models' abilities to retrieve similar views and ground-truth 3D shapes. Going beyond naive zero-shot performance study, we investigate alternative fine-tuning strategies on one or several shape classes, and their generalization to other shape classes. Leveraging progress in NPR (Non-Photo Realistic) rendering, we generate synthetic sketch views in several styles which we use to fine-tune pretrained foundation models using contrastive learning. We study how the scale of an object in a sketch affects the similarity of features at different network layers. We observe that depending on the scale, different feature layers can be more indicative of shape similarities in sketch views. However, we find that similar object scales result in the best performance of ViT and ResNet. In summary, we show that careful selection of a fine-tuning strategy allows us to obtain consistent improvement in zero-shot shape retrieval accuracy. We believe that our work will have a significant impact on research in the sketch domain, providing insights and guidance on how to adopt large pretrained models as perceptual losses.
GBSD: Generative Bokeh with Stage Diffusion
Jun 14, 2023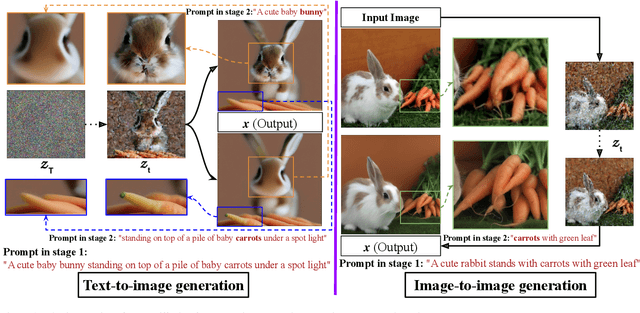
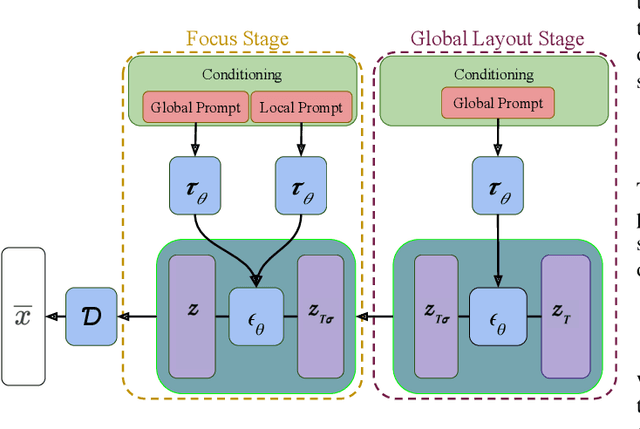


The bokeh effect is an artistic technique that blurs out-of-focus areas in a photograph and has gained interest due to recent developments in text-to-image synthesis and the ubiquity of smart-phone cameras and photo-sharing apps. Prior work on rendering bokeh effects have focused on post hoc image manipulation to produce similar blurring effects in existing photographs using classical computer graphics or neural rendering techniques, but have either depth discontinuity artifacts or are restricted to reproducing bokeh effects that are present in the training data. More recent diffusion based models can synthesize images with an artistic style, but either require the generation of high-dimensional masks, expensive fine-tuning, or affect global image characteristics. In this paper, we present GBSD, the first generative text-to-image model that synthesizes photorealistic images with a bokeh style. Motivated by how image synthesis occurs progressively in diffusion models, our approach combines latent diffusion models with a 2-stage conditioning algorithm to render bokeh effects on semantically defined objects. Since we can focus the effect on objects, this semantic bokeh effect is more versatile than classical rendering techniques. We evaluate GBSD both quantitatively and qualitatively and demonstrate its ability to be applied in both text-to-image and image-to-image settings.
Improving Handwritten OCR with Training Samples Generated by Glyph Conditional Denoising Diffusion Probabilistic Model
May 31, 2023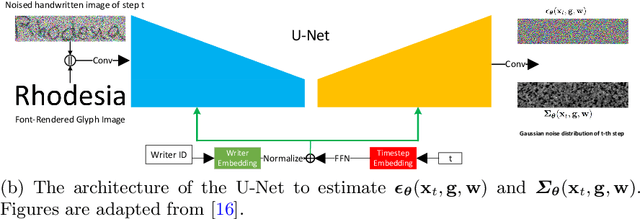
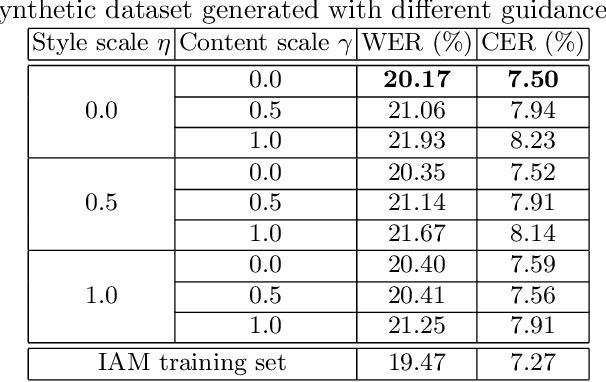

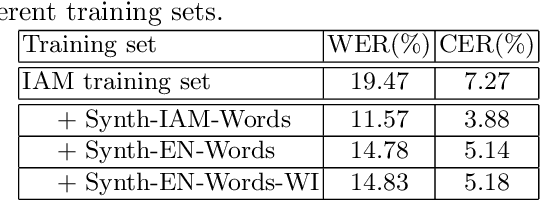
Constructing a highly accurate handwritten OCR system requires large amounts of representative training data, which is both time-consuming and expensive to collect. To mitigate the issue, we propose a denoising diffusion probabilistic model (DDPM) to generate training samples. This model conditions on a printed glyph image and creates mappings between printed characters and handwritten images, thus enabling the generation of photo-realistic handwritten samples with diverse styles and unseen text contents. However, the text contents in synthetic images are not always consistent with the glyph conditional images, leading to unreliable labels of synthetic samples. To address this issue, we further propose a progressive data filtering strategy to add those samples with a high confidence of correctness to the training set. Experimental results on IAM benchmark task show that OCR model trained with augmented DDPM-synthesized training samples can achieve about 45% relative word error rate reduction compared with the one trained on real data only.
Exploiting Unlabelled Photos for Stronger Fine-Grained SBIR
Mar 24, 2023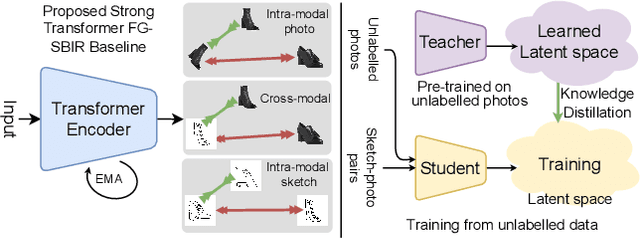
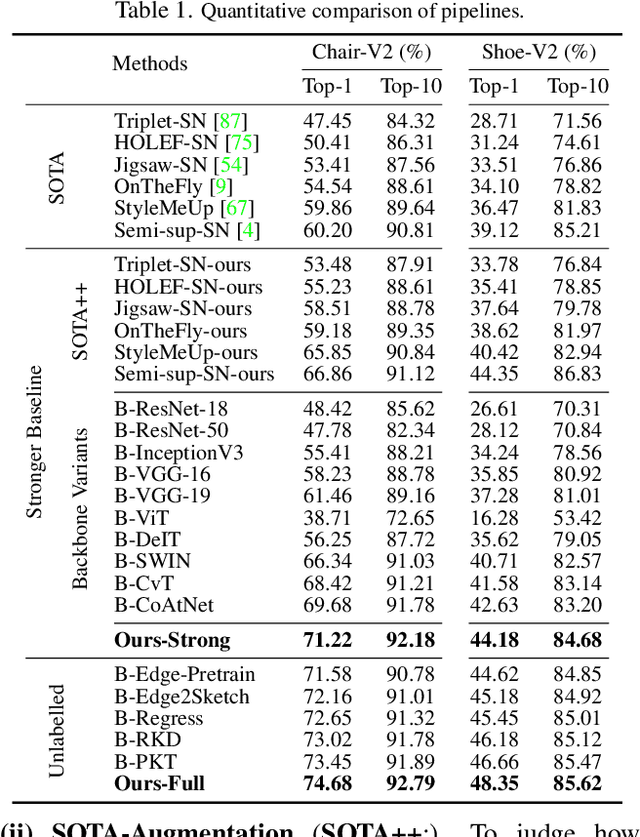
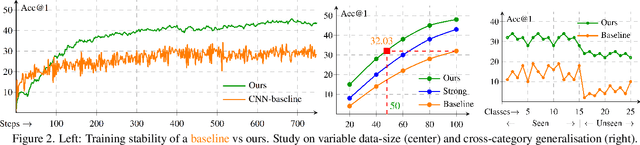
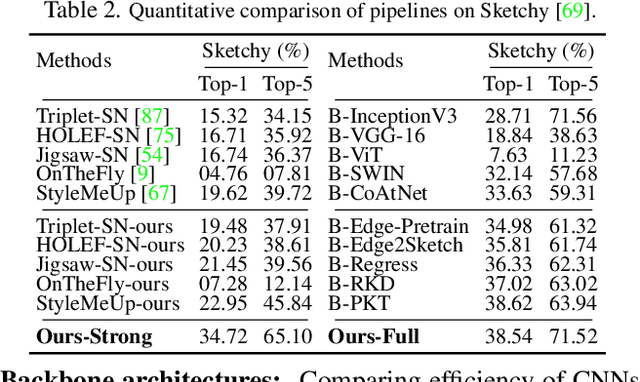
This paper advances the fine-grained sketch-based image retrieval (FG-SBIR) literature by putting forward a strong baseline that overshoots prior state-of-the-arts by ~11%. This is not via complicated design though, but by addressing two critical issues facing the community (i) the gold standard triplet loss does not enforce holistic latent space geometry, and (ii) there are never enough sketches to train a high accuracy model. For the former, we propose a simple modification to the standard triplet loss, that explicitly enforces separation amongst photos/sketch instances. For the latter, we put forward a novel knowledge distillation module can leverage photo data for model training. Both modules are then plugged into a novel plug-n-playable training paradigm that allows for more stable training. More specifically, for (i) we employ an intra-modal triplet loss amongst sketches to bring sketches of the same instance closer from others, and one more amongst photos to push away different photo instances while bringing closer a structurally augmented version of the same photo (offering a gain of ~4-6%). To tackle (ii), we first pre-train a teacher on the large set of unlabelled photos over the aforementioned intra-modal photo triplet loss. Then we distill the contextual similarity present amongst the instances in the teacher's embedding space to that in the student's embedding space, by matching the distribution over inter-feature distances of respective samples in both embedding spaces (delivering a further gain of ~4-5%). Apart from outperforming prior arts significantly, our model also yields satisfactory results on generalising to new classes. Project page: https://aneeshan95.github.io/Sketch_PVT/
What Can Human Sketches Do for Object Detection?
Mar 27, 2023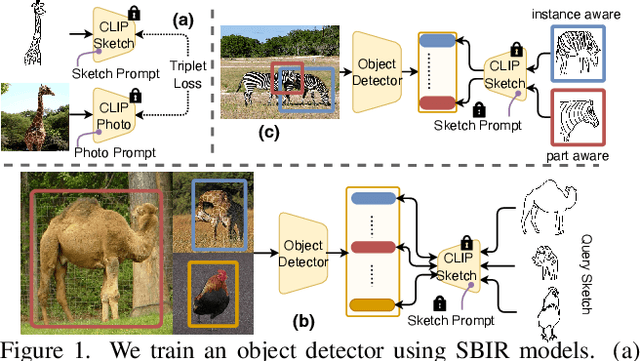
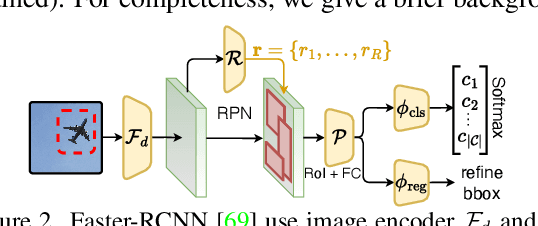
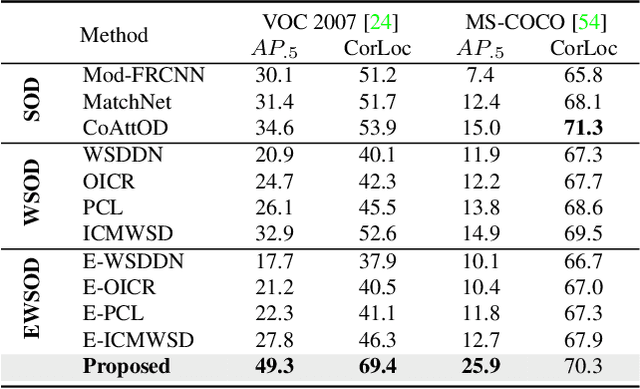
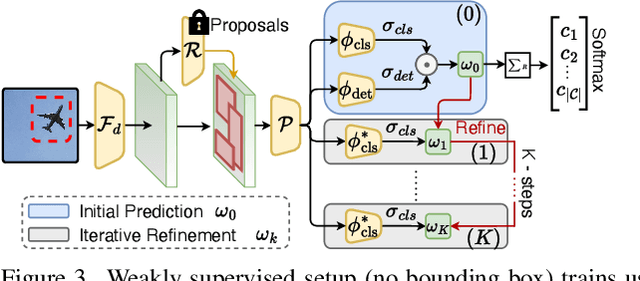
Sketches are highly expressive, inherently capturing subjective and fine-grained visual cues. The exploration of such innate properties of human sketches has, however, been limited to that of image retrieval. In this paper, for the first time, we cultivate the expressiveness of sketches but for the fundamental vision task of object detection. The end result is a sketch-enabled object detection framework that detects based on what \textit{you} sketch -- \textit{that} ``zebra'' (e.g., one that is eating the grass) in a herd of zebras (instance-aware detection), and only the \textit{part} (e.g., ``head" of a ``zebra") that you desire (part-aware detection). We further dictate that our model works without (i) knowing which category to expect at testing (zero-shot) and (ii) not requiring additional bounding boxes (as per fully supervised) and class labels (as per weakly supervised). Instead of devising a model from the ground up, we show an intuitive synergy between foundation models (e.g., CLIP) and existing sketch models build for sketch-based image retrieval (SBIR), which can already elegantly solve the task -- CLIP to provide model generalisation, and SBIR to bridge the (sketch$\rightarrow$photo) gap. In particular, we first perform independent prompting on both sketch and photo branches of an SBIR model to build highly generalisable sketch and photo encoders on the back of the generalisation ability of CLIP. We then devise a training paradigm to adapt the learned encoders for object detection, such that the region embeddings of detected boxes are aligned with the sketch and photo embeddings from SBIR. Evaluating our framework on standard object detection datasets like PASCAL-VOC and MS-COCO outperforms both supervised (SOD) and weakly-supervised object detectors (WSOD) on zero-shot setups. Project Page: \url{https://pinakinathc.github.io/sketch-detect}
Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
Mar 20, 2023
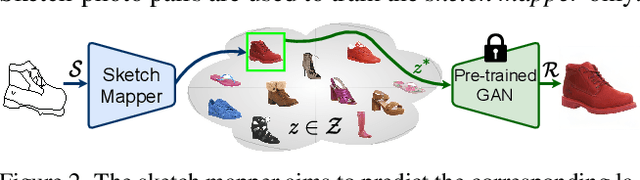
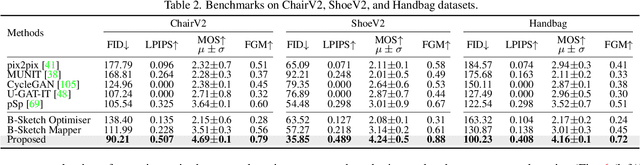
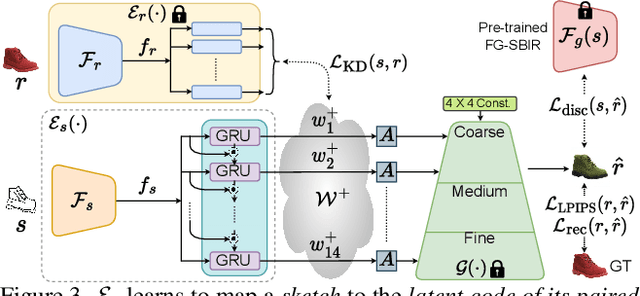
Given an abstract, deformed, ordinary sketch from untrained amateurs like you and me, this paper turns it into a photorealistic image - just like those shown in Fig. 1(a), all non-cherry-picked. We differ significantly from prior art in that we do not dictate an edgemap-like sketch to start with, but aim to work with abstract free-hand human sketches. In doing so, we essentially democratise the sketch-to-photo pipeline, "picturing" a sketch regardless of how good you sketch. Our contribution at the outset is a decoupled encoder-decoder training paradigm, where the decoder is a StyleGAN trained on photos only. This importantly ensures that generated results are always photorealistic. The rest is then all centred around how best to deal with the abstraction gap between sketch and photo. For that, we propose an autoregressive sketch mapper trained on sketch-photo pairs that maps a sketch to the StyleGAN latent space. We further introduce specific designs to tackle the abstract nature of human sketches, including a fine-grained discriminative loss on the back of a trained sketch-photo retrieval model, and a partial-aware sketch augmentation strategy. Finally, we showcase a few downstream tasks our generation model enables, amongst them is showing how fine-grained sketch-based image retrieval, a well-studied problem in the sketch community, can be reduced to an image (generated) to image retrieval task, surpassing state-of-the-arts. We put forward generated results in the supplementary for everyone to scrutinise.
ReactFace: Multiple Appropriate Facial Reaction Generation in Dyadic Interactions
May 25, 2023
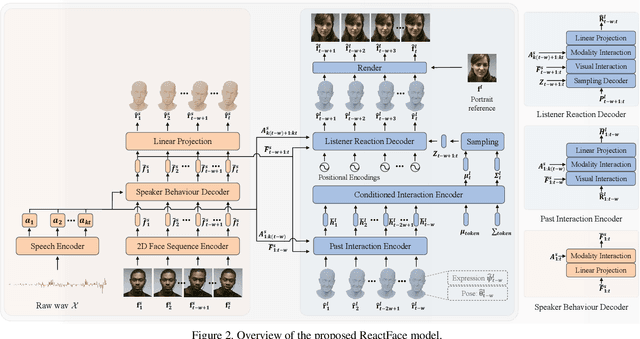

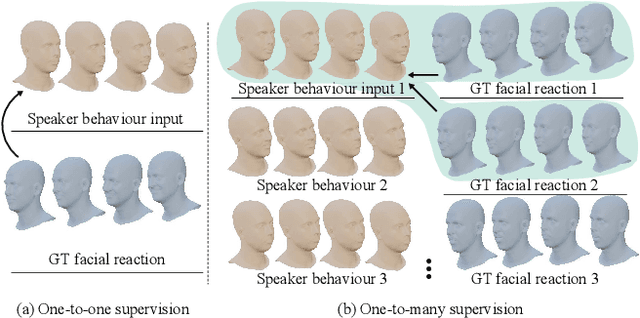
In dyadic interaction, predicting the listener's facial reactions is challenging as different reactions may be appropriate in response to the same speaker's behaviour. This paper presents a novel framework called ReactFace that learns an appropriate facial reaction distribution from a speaker's behaviour rather than replicating the real facial reaction of the listener. ReactFace generates multiple different but appropriate photo-realistic human facial reactions by (i) learning an appropriate facial reaction distribution representing multiple appropriate facial reactions; and (ii) synchronizing the generated facial reactions with the speaker's verbal and non-verbal behaviours at each time stamp, resulting in realistic 2D facial reaction sequences. Experimental results demonstrate the effectiveness of our approach in generating multiple diverse, synchronized, and appropriate facial reactions from each speaker's behaviour, with the quality of the generated reactions being influenced by the speaker's speech and facial behaviours. Our code is made publicly available at \url{https://github.com/lingjivoo/ReactFace}.