 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
DiffusionRig: Learning Personalized Priors for Facial Appearance Editing
Apr 13, 2023
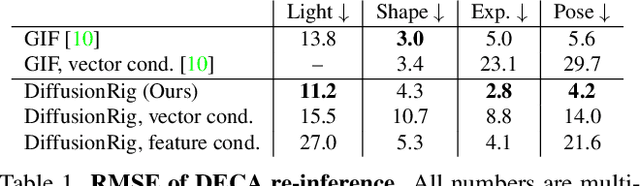

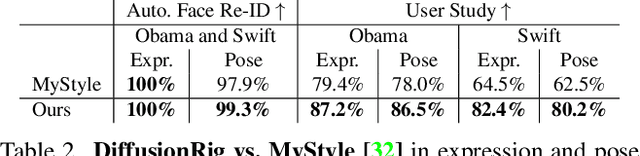
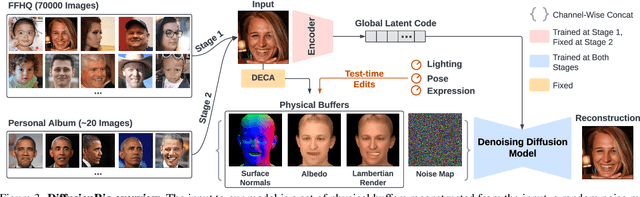
We address the problem of learning person-specific facial priors from a small number (e.g., 20) of portrait photos of the same person. This enables us to edit this specific person's facial appearance, such as expression and lighting, while preserving their identity and high-frequency facial details. Key to our approach, which we dub DiffusionRig, is a diffusion model conditioned on, or "rigged by," crude 3D face models estimated from single in-the-wild images by an off-the-shelf estimator. On a high level, DiffusionRig learns to map simplistic renderings of 3D face models to realistic photos of a given person. Specifically, DiffusionRig is trained in two stages: It first learns generic facial priors from a large-scale face dataset and then person-specific priors from a small portrait photo collection of the person of interest. By learning the CGI-to-photo mapping with such personalized priors, DiffusionRig can "rig" the lighting, facial expression, head pose, etc. of a portrait photo, conditioned only on coarse 3D models while preserving this person's identity and other high-frequency characteristics. Qualitative and quantitative experiments show that DiffusionRig outperforms existing approaches in both identity preservation and photorealism. Please see the project website: https://diffusionrig.github.io for the supplemental material, video, code, and data.
Emotional Talking Head Generation based on Memory-Sharing and Attention-Augmented Networks
Jun 06, 2023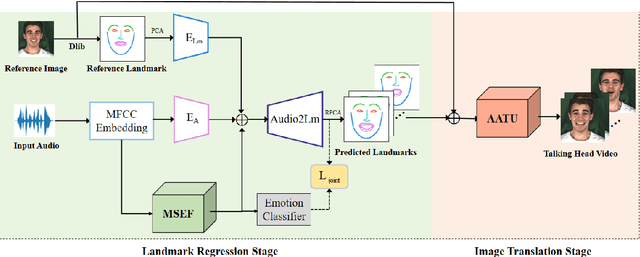
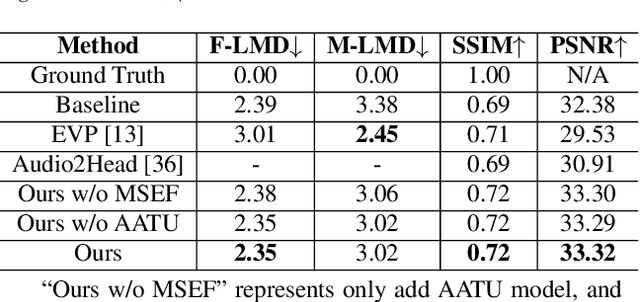
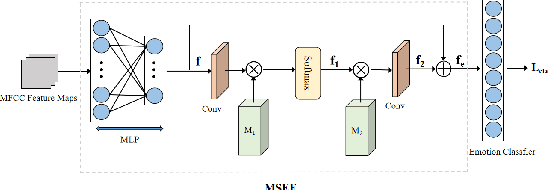
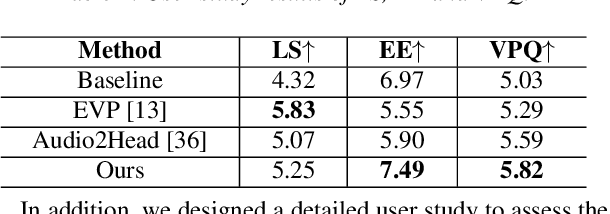
Given an audio clip and a reference face image, the goal of the talking head generation is to generate a high-fidelity talking head video. Although some audio-driven methods of generating talking head videos have made some achievements in the past, most of them only focused on lip and audio synchronization and lack the ability to reproduce the facial expressions of the target person. To this end, we propose a talking head generation model consisting of a Memory-Sharing Emotion Feature extractor (MSEF) and an Attention-Augmented Translator based on U-net (AATU). Firstly, MSEF can extract implicit emotional auxiliary features from audio to estimate more accurate emotional face landmarks.~Secondly, AATU acts as a translator between the estimated landmarks and the photo-realistic video frames. Extensive qualitative and quantitative experiments have shown the superiority of the proposed method to the previous works. Codes will be made publicly available.
Federated Few-shot Learning
Jul 02, 2023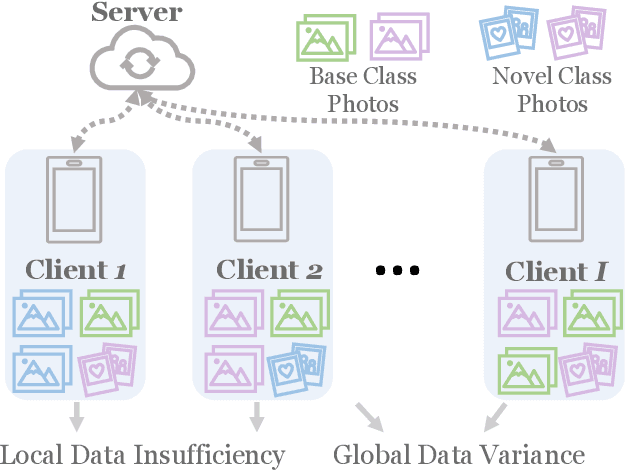
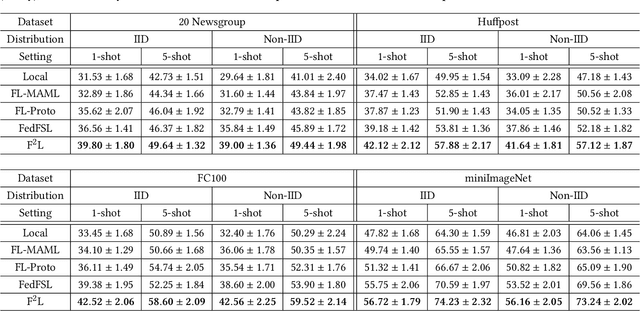
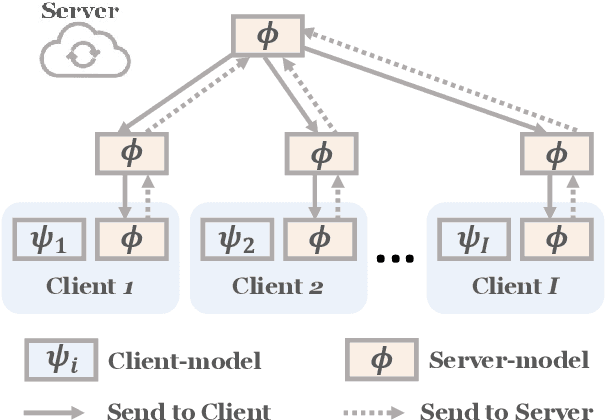

Federated Learning (FL) enables multiple clients to collaboratively learn a machine learning model without exchanging their own local data. In this way, the server can exploit the computational power of all clients and train the model on a larger set of data samples among all clients. Although such a mechanism is proven to be effective in various fields, existing works generally assume that each client preserves sufficient data for training. In practice, however, certain clients may only contain a limited number of samples (i.e., few-shot samples). For example, the available photo data taken by a specific user with a new mobile device is relatively rare. In this scenario, existing FL efforts typically encounter a significant performance drop on these clients. Therefore, it is urgent to develop a few-shot model that can generalize to clients with limited data under the FL scenario. In this paper, we refer to this novel problem as federated few-shot learning. Nevertheless, the problem remains challenging due to two major reasons: the global data variance among clients (i.e., the difference in data distributions among clients) and the local data insufficiency in each client (i.e., the lack of adequate local data for training). To overcome these two challenges, we propose a novel federated few-shot learning framework with two separately updated models and dedicated training strategies to reduce the adverse impact of global data variance and local data insufficiency. Extensive experiments on four prevalent datasets that cover news articles and images validate the effectiveness of our framework compared with the state-of-the-art baselines. Our code is provided at https://github.com/SongW-SW/F2L.
Conditional Text Image Generation with Diffusion Models
Jun 19, 2023


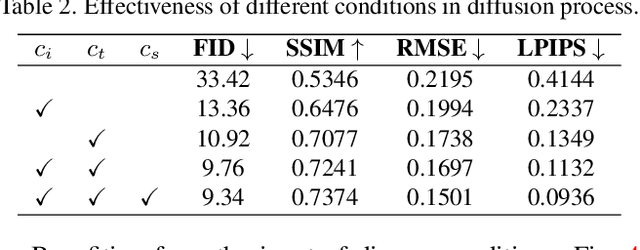
Current text recognition systems, including those for handwritten scripts and scene text, have relied heavily on image synthesis and augmentation, since it is difficult to realize real-world complexity and diversity through collecting and annotating enough real text images. In this paper, we explore the problem of text image generation, by taking advantage of the powerful abilities of Diffusion Models in generating photo-realistic and diverse image samples with given conditions, and propose a method called Conditional Text Image Generation with Diffusion Models (CTIG-DM for short). To conform to the characteristics of text images, we devise three conditions: image condition, text condition, and style condition, which can be used to control the attributes, contents, and styles of the samples in the image generation process. Specifically, four text image generation modes, namely: (1) synthesis mode, (2) augmentation mode, (3) recovery mode, and (4) imitation mode, can be derived by combining and configuring these three conditions. Extensive experiments on both handwritten and scene text demonstrate that the proposed CTIG-DM is able to produce image samples that simulate real-world complexity and diversity, and thus can boost the performance of existing text recognizers. Besides, CTIG-DM shows its appealing potential in domain adaptation and generating images containing Out-Of-Vocabulary (OOV) words.
Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
Mar 30, 2023
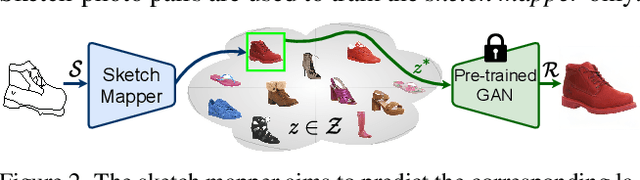
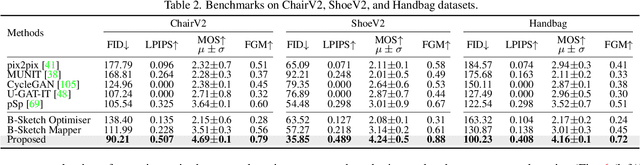
Given an abstract, deformed, ordinary sketch from untrained amateurs like you and me, this paper turns it into a photorealistic image - just like those shown in Fig. 1(a), all non-cherry-picked. We differ significantly from prior art in that we do not dictate an edgemap-like sketch to start with, but aim to work with abstract free-hand human sketches. In doing so, we essentially democratise the sketch-to-photo pipeline, "picturing" a sketch regardless of how good you sketch. Our contribution at the outset is a decoupled encoder-decoder training paradigm, where the decoder is a StyleGAN trained on photos only. This importantly ensures that generated results are always photorealistic. The rest is then all centred around how best to deal with the abstraction gap between sketch and photo. For that, we propose an autoregressive sketch mapper trained on sketch-photo pairs that maps a sketch to the StyleGAN latent space. We further introduce specific designs to tackle the abstract nature of human sketches, including a fine-grained discriminative loss on the back of a trained sketch-photo retrieval model, and a partial-aware sketch augmentation strategy. Finally, we showcase a few downstream tasks our generation model enables, amongst them is showing how fine-grained sketch-based image retrieval, a well-studied problem in the sketch community, can be reduced to an image (generated) to image retrieval task, surpassing state-of-the-arts. We put forward generated results in the supplementary for everyone to scrutinise.
HiFA: High-fidelity Text-to-3D with Advanced Diffusion Guidance
May 31, 2023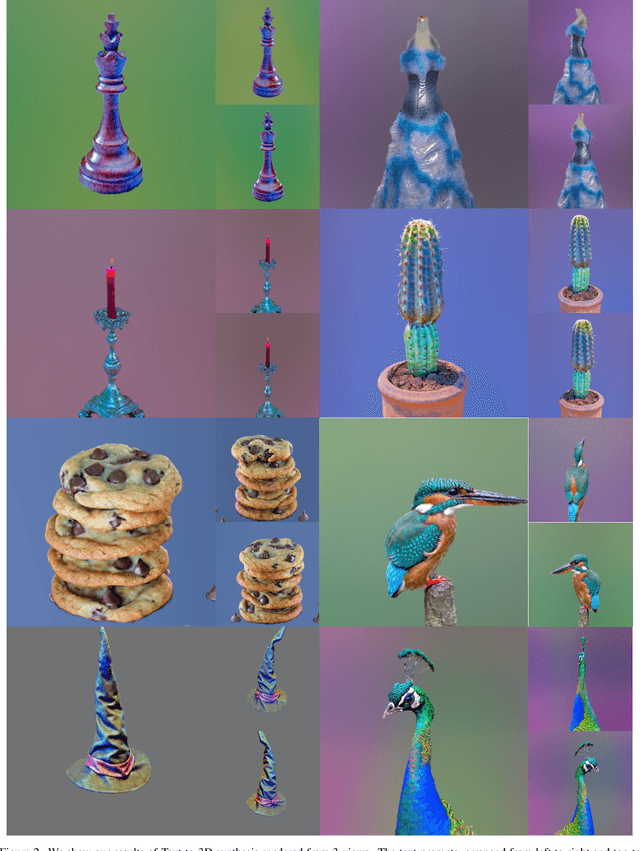
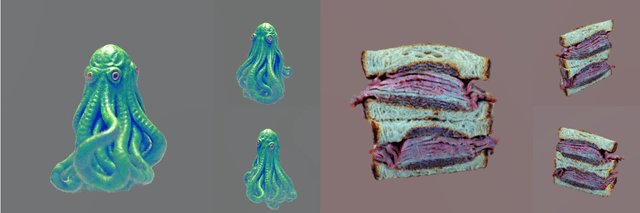

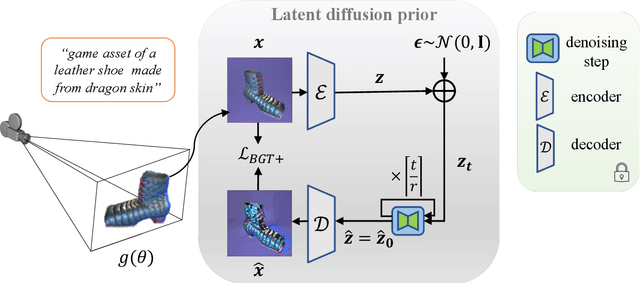
Automatic text-to-3D synthesis has achieved remarkable advancements through the optimization of 3D models. Existing methods commonly rely on pre-trained text-to-image generative models, such as diffusion models, providing scores for 2D renderings of Neural Radiance Fields (NeRFs) and being utilized for optimizing NeRFs. However, these methods often encounter artifacts and inconsistencies across multiple views due to their limited understanding of 3D geometry. To address these limitations, we propose a reformulation of the optimization loss using the diffusion prior. Furthermore, we introduce a novel training approach that unlocks the potential of the diffusion prior. To improve 3D geometry representation, we apply auxiliary depth supervision for NeRF-rendered images and regularize the density field of NeRFs. Extensive experiments demonstrate the superiority of our method over prior works, resulting in advanced photo-realism and improved multi-view consistency.
Is Synthetic Data From Diffusion Models Ready for Knowledge Distillation?
May 22, 2023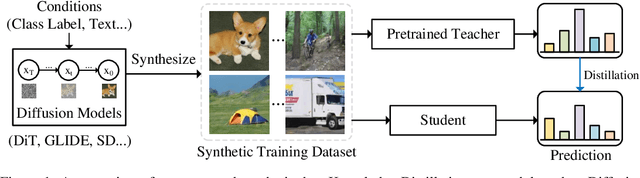

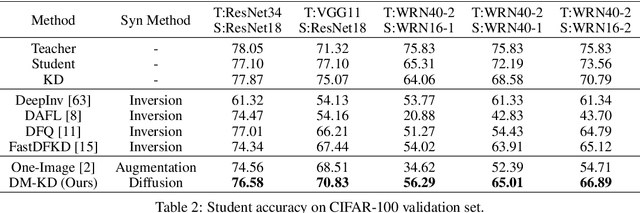

Diffusion models have recently achieved astonishing performance in generating high-fidelity photo-realistic images. Given their huge success, it is still unclear whether synthetic images are applicable for knowledge distillation when real images are unavailable. In this paper, we extensively study whether and how synthetic images produced from state-of-the-art diffusion models can be used for knowledge distillation without access to real images, and obtain three key conclusions: (1) synthetic data from diffusion models can easily lead to state-of-the-art performance among existing synthesis-based distillation methods, (2) low-fidelity synthetic images are better teaching materials, and (3) relatively weak classifiers are better teachers. Code is available at https://github.com/zhengli97/DM-KD.
Ladder: A software to label images, detect objects and deploy models recurrently for object detection
Jun 17, 2023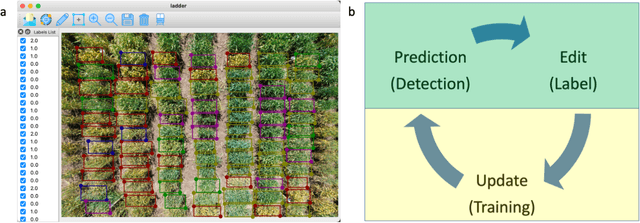
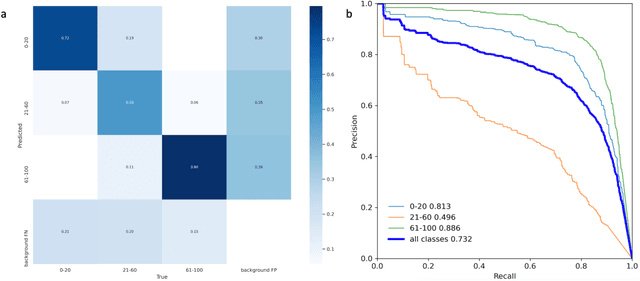
Object Detection (OD) is a computer vision technology that can locate and classify objects in images and videos, which has the potential to significantly improve efficiency in precision agriculture. To simplify OD application process, we developed Ladder - a software that provides users with a friendly graphic user interface (GUI) that allows for efficient labelling of training datasets, training OD models, and deploying the trained model. Ladder was designed with an interactive recurrent framework that leverages predictions from a pre-trained OD model as the initial image labeling. After adding human labels, the newly labeled images can be added into the training data to retrain the OD model. With the same GUI, users can also deploy well-trained OD models by loading the model weight file to detect new images. We used Ladder to develop a deep learning model to access wheat stripe rust in RGB (red, green, blue) images taken by an Unmanned Aerial Vehicle (UAV). Ladder employs OD to directly evaluate different severity levels of wheat stripe rust in field images, eliminating the need for photo stitching process for UAVs-based images. The accuracy for low, medium and high severity scores were 72%, 50% and 80%, respectively. This case demonstrates how Ladder empowers OD in precision agriculture and crop breeding.
Neural Scene Chronology
Jun 13, 2023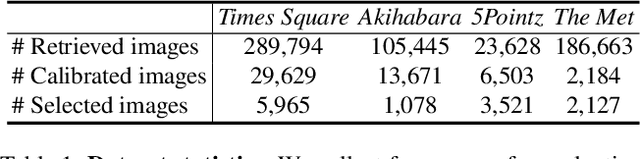
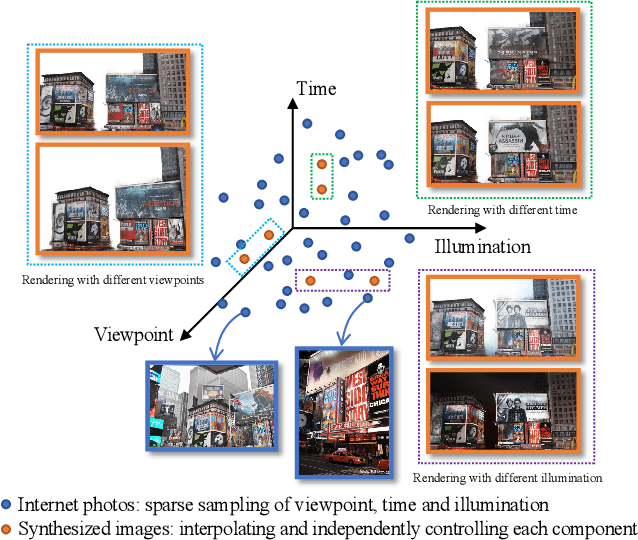
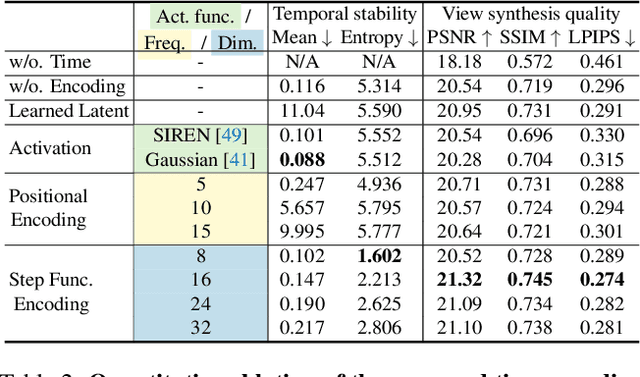
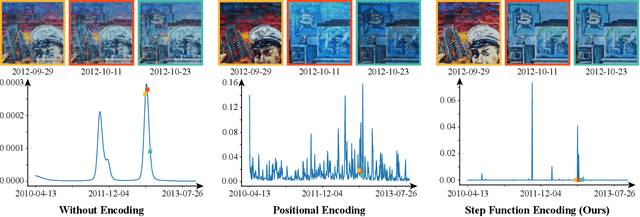
In this work, we aim to reconstruct a time-varying 3D model, capable of rendering photo-realistic renderings with independent control of viewpoint, illumination, and time, from Internet photos of large-scale landmarks. The core challenges are twofold. First, different types of temporal changes, such as illumination and changes to the underlying scene itself (such as replacing one graffiti artwork with another) are entangled together in the imagery. Second, scene-level temporal changes are often discrete and sporadic over time, rather than continuous. To tackle these problems, we propose a new scene representation equipped with a novel temporal step function encoding method that can model discrete scene-level content changes as piece-wise constant functions over time. Specifically, we represent the scene as a space-time radiance field with a per-image illumination embedding, where temporally-varying scene changes are encoded using a set of learned step functions. To facilitate our task of chronology reconstruction from Internet imagery, we also collect a new dataset of four scenes that exhibit various changes over time. We demonstrate that our method exhibits state-of-the-art view synthesis results on this dataset, while achieving independent control of viewpoint, time, and illumination.
Zero-Shot Everything Sketch-Based Image Retrieval, and in Explainable Style
Mar 25, 2023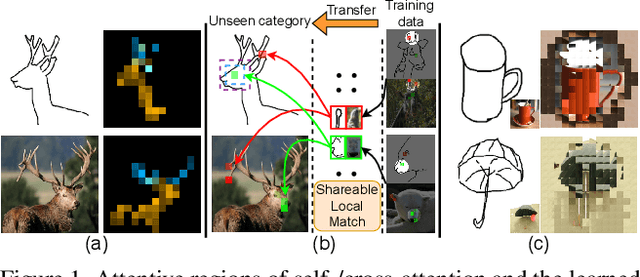
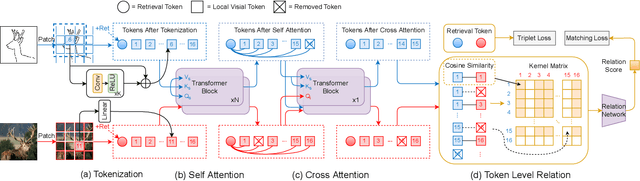
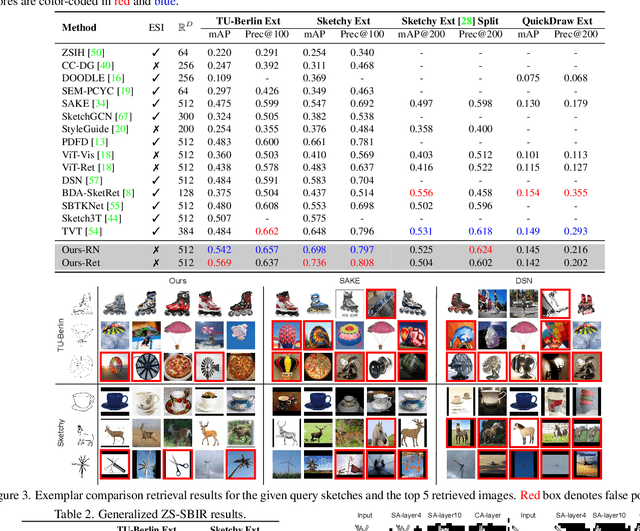
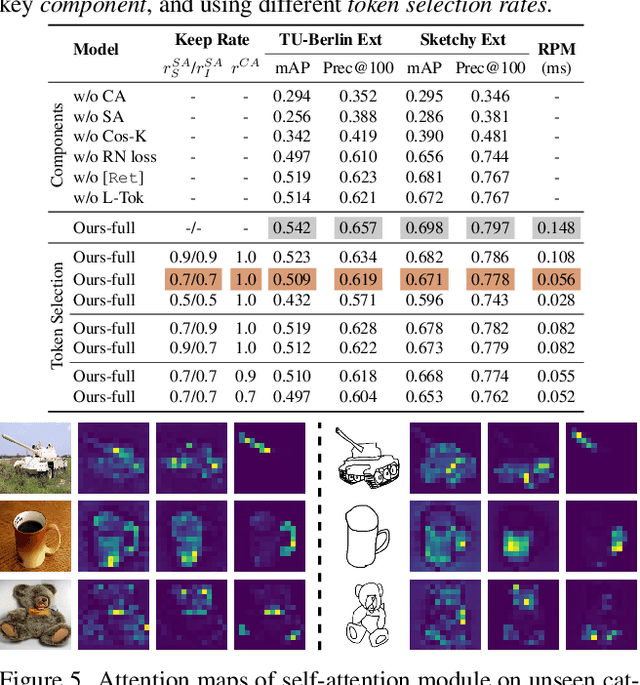
This paper studies the problem of zero-short sketch-based image retrieval (ZS-SBIR), however with two significant differentiators to prior art (i) we tackle all variants (inter-category, intra-category, and cross datasets) of ZS-SBIR with just one network (``everything''), and (ii) we would really like to understand how this sketch-photo matching operates (``explainable''). Our key innovation lies with the realization that such a cross-modal matching problem could be reduced to comparisons of groups of key local patches -- akin to the seasoned ``bag-of-words'' paradigm. Just with this change, we are able to achieve both of the aforementioned goals, with the added benefit of no longer requiring external semantic knowledge. Technically, ours is a transformer-based cross-modal network, with three novel components (i) a self-attention module with a learnable tokenizer to produce visual tokens that correspond to the most informative local regions, (ii) a cross-attention module to compute local correspondences between the visual tokens across two modalities, and finally (iii) a kernel-based relation network to assemble local putative matches and produce an overall similarity metric for a sketch-photo pair. Experiments show ours indeed delivers superior performances across all ZS-SBIR settings. The all important explainable goal is elegantly achieved by visualizing cross-modal token correspondences, and for the first time, via sketch to photo synthesis by universal replacement of all matched photo patches. Code and model are available at \url{https://github.com/buptLinfy/ZSE-SBIR}.