 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Neural Image Re-Exposure
May 23, 2023
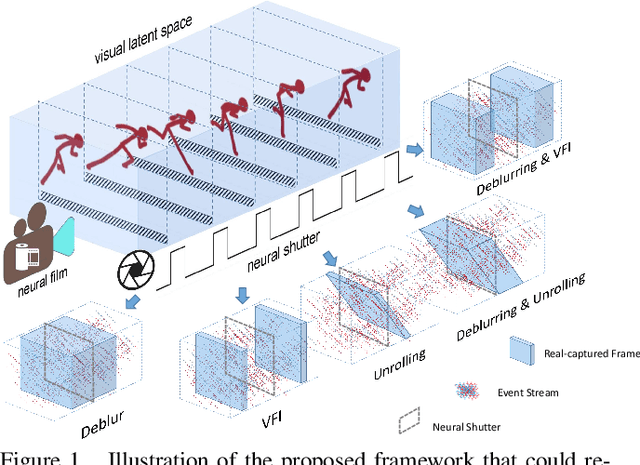
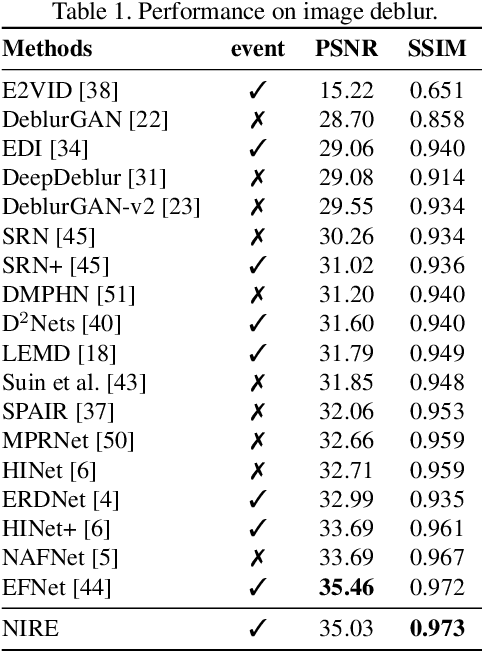
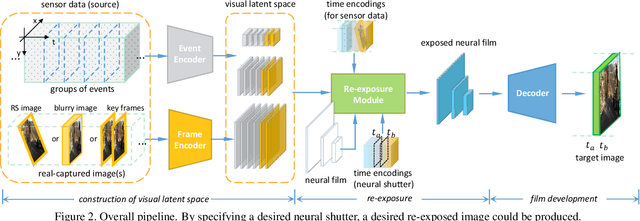
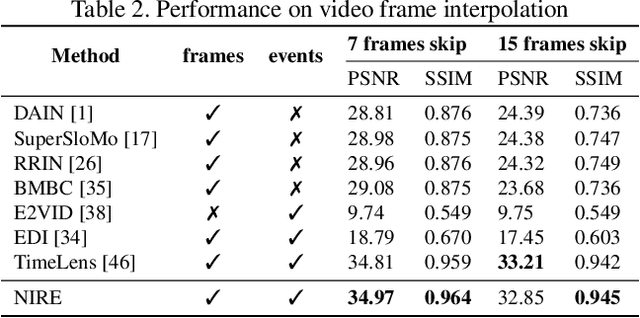
The shutter strategy applied to the photo-shooting process has a significant influence on the quality of the captured photograph. An improper shutter may lead to a blurry image, video discontinuity, or rolling shutter artifact. Existing works try to provide an independent solution for each issue. In this work, we aim to re-expose the captured photo in post-processing to provide a more flexible way of addressing those issues within a unified framework. Specifically, we propose a neural network-based image re-exposure framework. It consists of an encoder for visual latent space construction, a re-exposure module for aggregating information to neural film with a desired shutter strategy, and a decoder for 'developing' neural film into a desired image. To compensate for information confusion and missing frames, event streams, which can capture almost continuous brightness changes, are leveraged in computing visual latent content. Both self-attention layers and cross-attention layers are employed in the re-exposure module to promote interaction between neural film and visual latent content and information aggregation to neural film. The proposed unified image re-exposure framework is evaluated on several shutter-related image recovery tasks and performs favorably against independent state-of-the-art methods.
Photo-Realistic Out-of-domain GAN inversion via Invertibility Decomposition
Dec 19, 2022
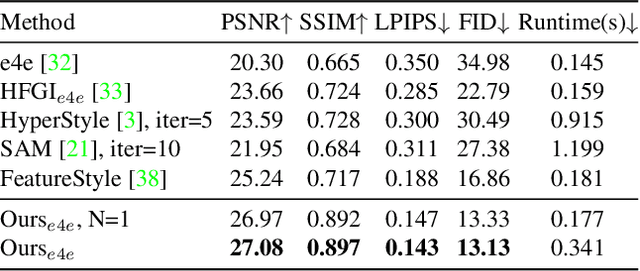
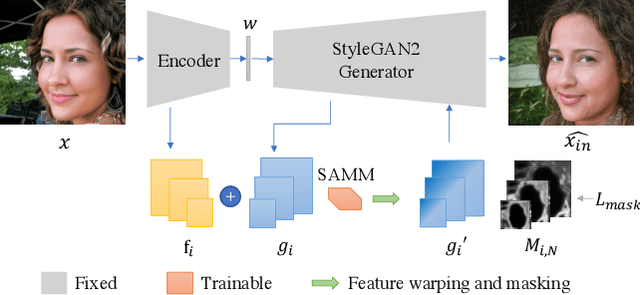
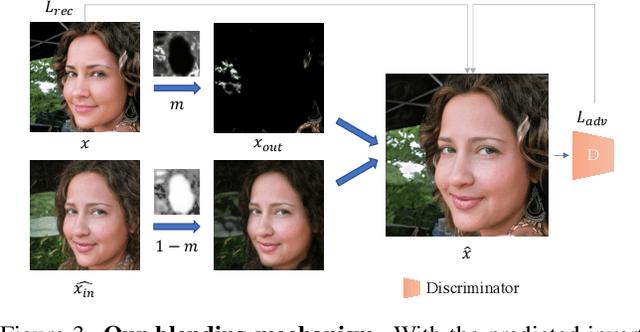
The fidelity of Generative Adversarial Networks (GAN) inversion is impeded by Out-Of-Domain (OOD) areas (e.g., background, accessories) in the image. Detecting the OOD areas beyond the generation ability of the pretrained model and blending these regions with the input image can enhance fidelity. The ``invertibility mask" figures out these OOD areas, and existing methods predict the mask with the reconstruction error. However, the estimated mask is usually inaccurate due to the influence of the reconstruction error in the In-Domain (ID) area. In this paper, we propose a novel framework that enhances the fidelity of human face inversion by designing a new module to decompose the input images to ID and OOD partitions with invertibility masks. Unlike previous works, our invertibility detector is simultaneously learned with a spatial alignment module. We iteratively align the generated features to the input geometry and reduce the reconstruction error in the ID regions. Thus, the OOD areas are more distinguishable and can be precisely predicted. Then, we improve the fidelity of our results by blending the OOD areas from the input image with the ID GAN inversion results. Our method produces photo-realistic results for real-world human face image inversion and manipulation. Extensive experiments demonstrate our method's superiority over existing methods in the quality of GAN inversion and attribute manipulation.
A Recipe for Efficient SBIR Models: Combining Relative Triplet Loss with Batch Normalization and Knowledge Distillation
May 30, 2023
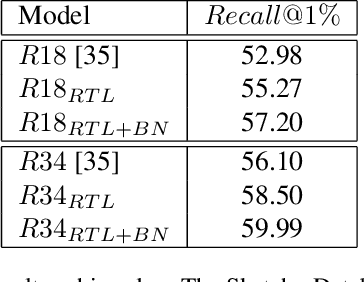
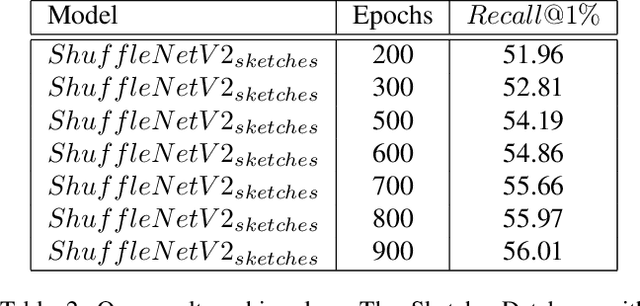
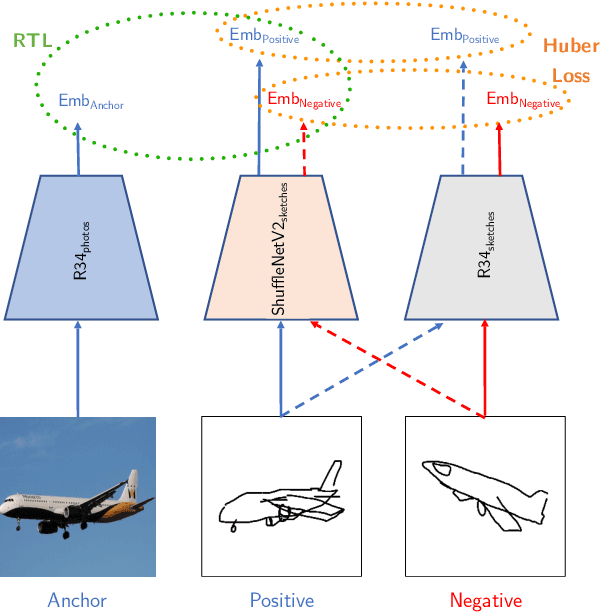
Sketch-Based Image Retrieval (SBIR) is a crucial task in multimedia retrieval, where the goal is to retrieve a set of images that match a given sketch query. Researchers have already proposed several well-performing solutions for this task, but most focus on enhancing embedding through different approaches such as triplet loss, quadruplet loss, adding data augmentation, and using edge extraction. In this work, we tackle the problem from various angles. We start by examining the training data quality and show some of its limitations. Then, we introduce a Relative Triplet Loss (RTL), an adapted triplet loss to overcome those limitations through loss weighting based on anchors similarity. Through a series of experiments, we demonstrate that replacing a triplet loss with RTL outperforms previous state-of-the-art without the need for any data augmentation. In addition, we demonstrate why batch normalization is more suited for SBIR embeddings than l2-normalization and show that it improves significantly the performance of our models. We further investigate the capacity of models required for the photo and sketch domains and demonstrate that the photo encoder requires a higher capacity than the sketch encoder, which validates the hypothesis formulated in [34]. Then, we propose a straightforward approach to train small models, such as ShuffleNetv2 [22] efficiently with a marginal loss of accuracy through knowledge distillation. The same approach used with larger models enabled us to outperform previous state-of-the-art results and achieve a recall of 62.38% at k = 1 on The Sketchy Database [30].
Modernizing Old Photos Using Multiple References via Photorealistic Style Transfer
Apr 10, 2023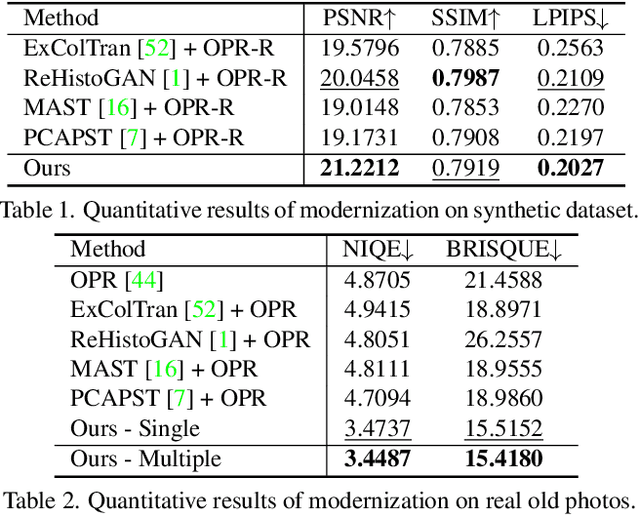
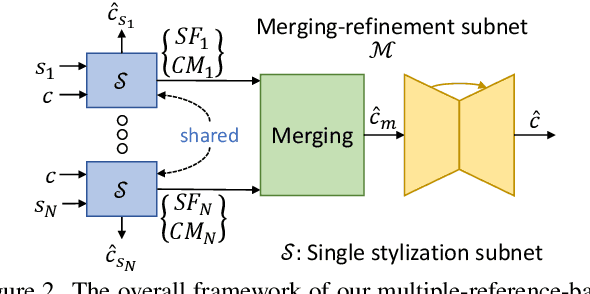
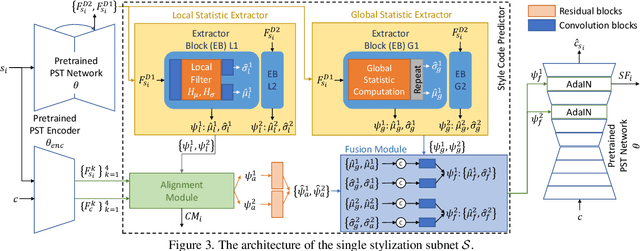
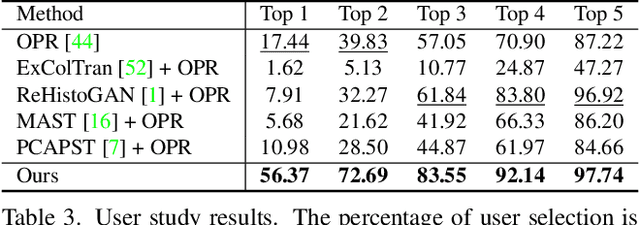
This paper firstly presents old photo modernization using multiple references by performing stylization and enhancement in a unified manner. In order to modernize old photos, we propose a novel multi-reference-based old photo modernization (MROPM) framework consisting of a network MROPM-Net and a novel synthetic data generation scheme. MROPM-Net stylizes old photos using multiple references via photorealistic style transfer (PST) and further enhances the results to produce modern-looking images. Meanwhile, the synthetic data generation scheme trains the network to effectively utilize multiple references to perform modernization. To evaluate the performance, we propose a new old photos benchmark dataset (CHD) consisting of diverse natural indoor and outdoor scenes. Extensive experiments show that the proposed method outperforms other baselines in performing modernization on real old photos, even though no old photos were used during training. Moreover, our method can appropriately select styles from multiple references for each semantic region in the old photo to further improve the modernization performance.
Unsupervised Learning of Style-Aware Facial Animation from Real Acting Performances
Jun 16, 2023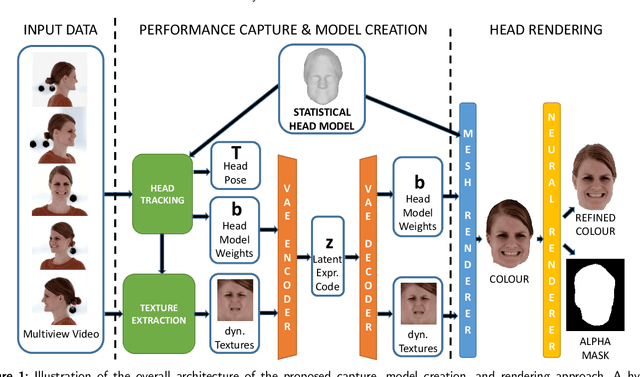
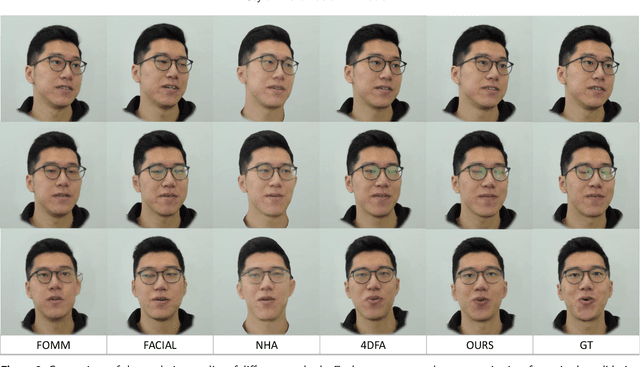


This paper presents a novel approach for text/speech-driven animation of a photo-realistic head model based on blend-shape geometry, dynamic textures, and neural rendering. Training a VAE for geometry and texture yields a parametric model for accurate capturing and realistic synthesis of facial expressions from a latent feature vector. Our animation method is based on a conditional CNN that transforms text or speech into a sequence of animation parameters. In contrast to previous approaches, our animation model learns disentangling/synthesizing different acting-styles in an unsupervised manner, requiring only phonetic labels that describe the content of training sequences. For realistic real-time rendering, we train a U-Net that refines rasterization-based renderings by computing improved pixel colors and a foreground matte. We compare our framework qualitatively/quantitatively against recent methods for head modeling as well as facial animation and evaluate the perceived rendering/animation quality in a user-study, which indicates large improvements compared to state-of-the-art approaches
NeRF synthesis with shading guidance
Jun 20, 2023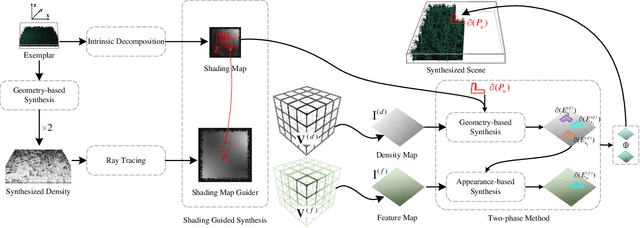
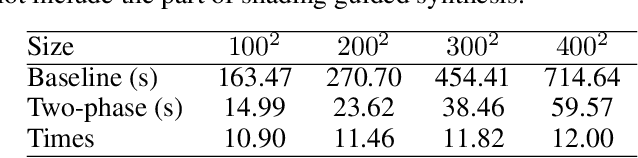

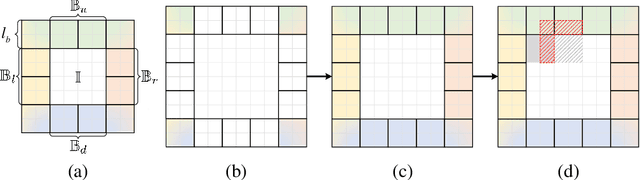
The emerging Neural Radiance Field (NeRF) shows great potential in representing 3D scenes, which can render photo-realistic images from novel view with only sparse views given. However, utilizing NeRF to reconstruct real-world scenes requires images from different viewpoints, which limits its practical application. This problem can be even more pronounced for large scenes. In this paper, we introduce a new task called NeRF synthesis that utilizes the structural content of a NeRF patch exemplar to construct a new radiance field of large size. We propose a two-phase method for synthesizing new scenes that are continuous in geometry and appearance. We also propose a boundary constraint method to synthesize scenes of arbitrary size without artifacts. Specifically, we control the lighting effects of synthesized scenes using shading guidance instead of decoupling the scene. We have demonstrated that our method can generate high-quality results with consistent geometry and appearance, even for scenes with complex lighting. We can also synthesize new scenes on curved surface with arbitrary lighting effects, which enhances the practicality of our proposed NeRF synthesis approach.
Conditional Human Sketch Synthesis with Explicit Abstraction Control
Jun 15, 2023
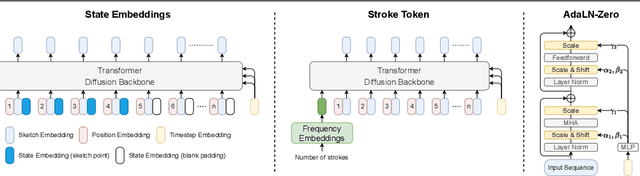
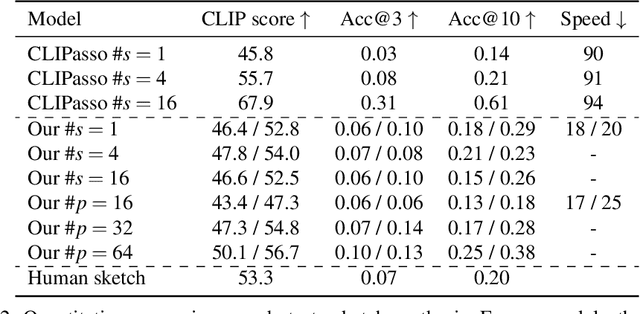

This paper presents a novel free-hand sketch synthesis approach addressing explicit abstraction control in class-conditional and photo-to-sketch synthesis. Abstraction is a vital aspect of sketches, as it defines the fundamental distinction between a sketch and an image. Previous works relied on implicit control to achieve different levels of abstraction, leading to inaccurate control and synthesized sketches deviating from human sketches. To resolve this challenge, we propose two novel abstraction control mechanisms, state embeddings and the stroke token, integrated into a transformer-based latent diffusion model (LDM). These mechanisms explicitly provide the required amount of points or strokes to the model, enabling accurate point-level and stroke-level control in synthesized sketches while preserving recognizability. Outperforming state-of-the-art approaches, our method effectively generates diverse, non-rigid and human-like sketches. The proposed approach enables coherent sketch synthesis and excels in representing human habits with desired abstraction levels, highlighting the potential of sketch synthesis for real-world applications.
FlipNeRF: Flipped Reflection Rays for Few-shot Novel View Synthesis
Jun 30, 2023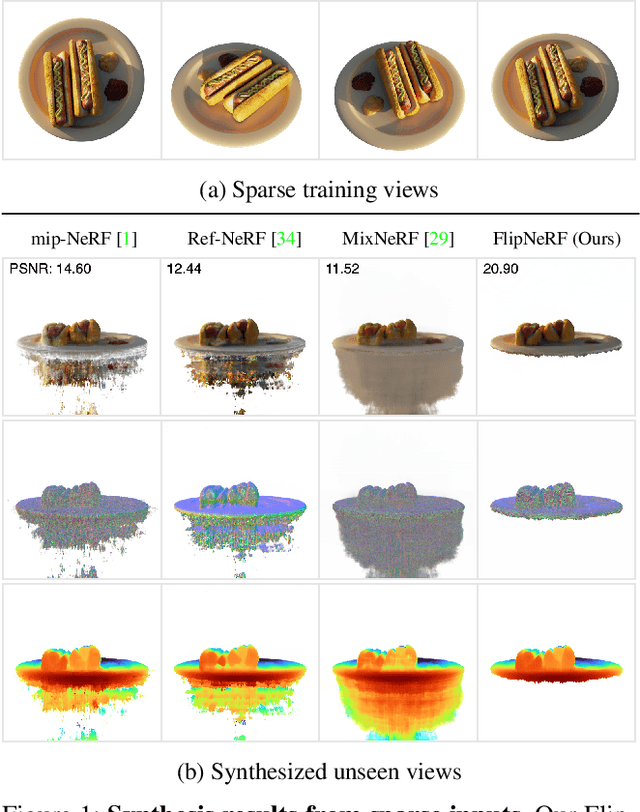
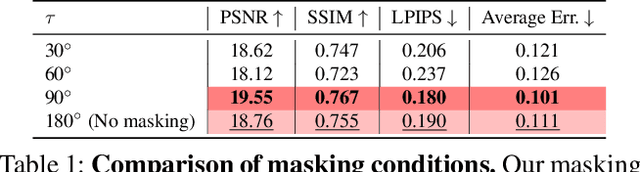
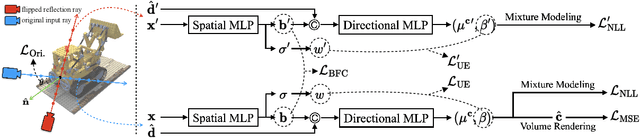
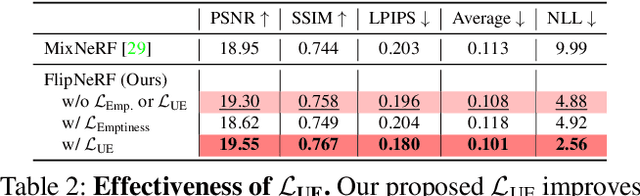
Neural Radiance Field (NeRF) has been a mainstream in novel view synthesis with its remarkable quality of rendered images and simple architecture. Although NeRF has been developed in various directions improving continuously its performance, the necessity of a dense set of multi-view images still exists as a stumbling block to progress for practical application. In this work, we propose FlipNeRF, a novel regularization method for few-shot novel view synthesis by utilizing our proposed flipped reflection rays. The flipped reflection rays are explicitly derived from the input ray directions and estimated normal vectors, and play a role of effective additional training rays while enabling to estimate more accurate surface normals and learn the 3D geometry effectively. Since the surface normal and the scene depth are both derived from the estimated densities along a ray, the accurate surface normal leads to more exact depth estimation, which is a key factor for few-shot novel view synthesis. Furthermore, with our proposed Uncertainty-aware Emptiness Loss and Bottleneck Feature Consistency Loss, FlipNeRF is able to estimate more reliable outputs with reducing floating artifacts effectively across the different scene structures, and enhance the feature-level consistency between the pair of the rays cast toward the photo-consistent pixels without any additional feature extractor, respectively. Our FlipNeRF achieves the SOTA performance on the multiple benchmarks across all the scenarios.
Deep Learning for Cancer Prognosis Prediction Using Portrait Photos by StyleGAN Embedding
Jun 28, 2023

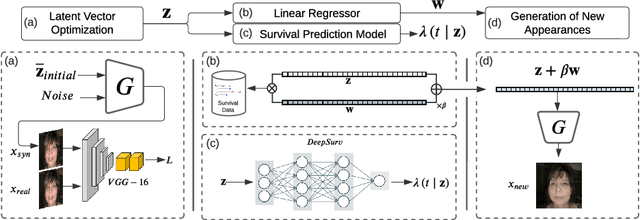

Survival prediction for cancer patients is critical for optimal treatment selection and patient management. Current patient survival prediction methods typically extract survival information from patients' clinical record data or biological and imaging data. In practice, experienced clinicians can have a preliminary assessment of patients' health status based on patients' observable physical appearances, which are mainly facial features. However, such assessment is highly subjective. In this work, the efficacy of objectively capturing and using prognostic information contained in conventional portrait photographs using deep learning for survival predication purposes is investigated for the first time. A pre-trained StyleGAN2 model is fine-tuned on a custom dataset of our cancer patients' photos to empower its generator with generative ability suitable for patients' photos. The StyleGAN2 is then used to embed the photographs to its highly expressive latent space. Utilizing the state-of-the-art survival analysis models and based on StyleGAN's latent space photo embeddings, this approach achieved a C-index of 0.677, which is notably higher than chance and evidencing the prognostic value embedded in simple 2D facial images. In addition, thanks to StyleGAN's interpretable latent space, our survival prediction model can be validated for relying on essential facial features, eliminating any biases from extraneous information like clothing or background. Moreover, a health attribute is obtained from regression coefficients, which has important potential value for patient care.
ClothFit: Cloth-Human-Attribute Guided Virtual Try-On Network Using 3D Simulated Dataset
Jun 24, 2023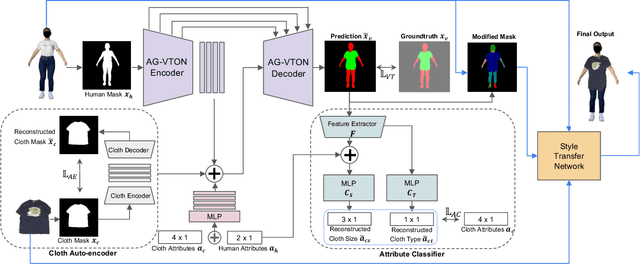
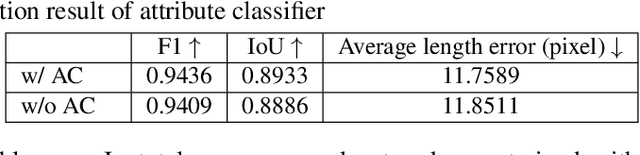
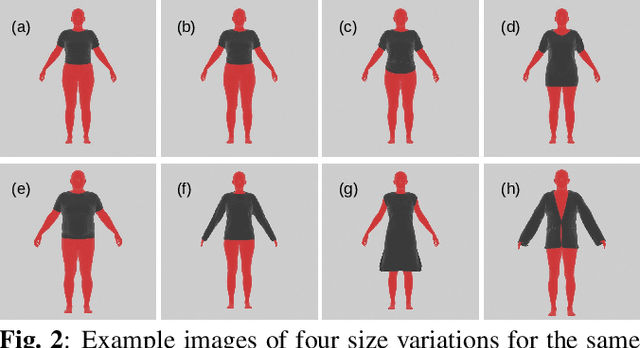

Online clothing shopping has become increasingly popular, but the high rate of returns due to size and fit issues has remained a major challenge. To address this problem, virtual try-on systems have been developed to provide customers with a more realistic and personalized way to try on clothing. In this paper, we propose a novel virtual try-on method called ClothFit, which can predict the draping shape of a garment on a target body based on the actual size of the garment and human attributes. Unlike existing try-on models, ClothFit considers the actual body proportions of the person and available cloth sizes for clothing virtualization, making it more appropriate for current online apparel outlets. The proposed method utilizes a U-Net-based network architecture that incorporates cloth and human attributes to guide the realistic virtual try-on synthesis. Specifically, we extract features from a cloth image using an auto-encoder and combine them with features from the user's height, weight, and cloth size. The features are concatenated with the features from the U-Net encoder, and the U-Net decoder synthesizes the final virtual try-on image. Our experimental results demonstrate that ClothFit can significantly improve the existing state-of-the-art methods in terms of photo-realistic virtual try-on results.