 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
From NeRFLiX to NeRFLiX++: A General NeRF-Agnostic Restorer Paradigm
Jun 10, 2023

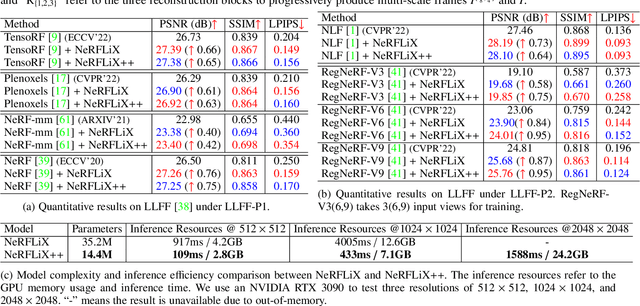
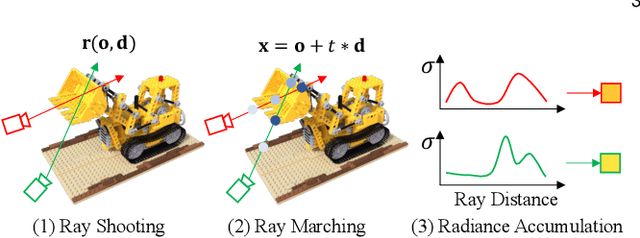
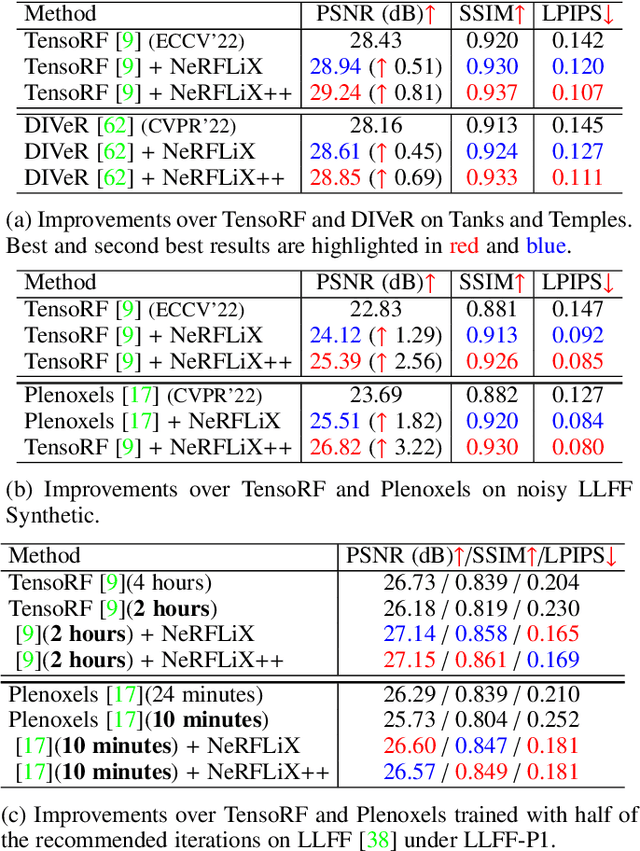
Neural radiance fields (NeRF) have shown great success in novel view synthesis. However, recovering high-quality details from real-world scenes is still challenging for the existing NeRF-based approaches, due to the potential imperfect calibration information and scene representation inaccuracy. Even with high-quality training frames, the synthetic novel views produced by NeRF models still suffer from notable rendering artifacts, such as noise and blur. To address this, we propose NeRFLiX, a general NeRF-agnostic restorer paradigm that learns a degradation-driven inter-viewpoint mixer. Specially, we design a NeRF-style degradation modeling approach and construct large-scale training data, enabling the possibility of effectively removing NeRF-native rendering artifacts for deep neural networks. Moreover, beyond the degradation removal, we propose an inter-viewpoint aggregation framework that fuses highly related high-quality training images, pushing the performance of cutting-edge NeRF models to entirely new levels and producing highly photo-realistic synthetic views. Based on this paradigm, we further present NeRFLiX++ with a stronger two-stage NeRF degradation simulator and a faster inter-viewpoint mixer, achieving superior performance with significantly improved computational efficiency. Notably, NeRFLiX++ is capable of restoring photo-realistic ultra-high-resolution outputs from noisy low-resolution NeRF-rendered views. Extensive experiments demonstrate the excellent restoration ability of NeRFLiX++ on various novel view synthesis benchmarks.
Aria Digital Twin: A New Benchmark Dataset for Egocentric 3D Machine Perception
Jun 13, 2023
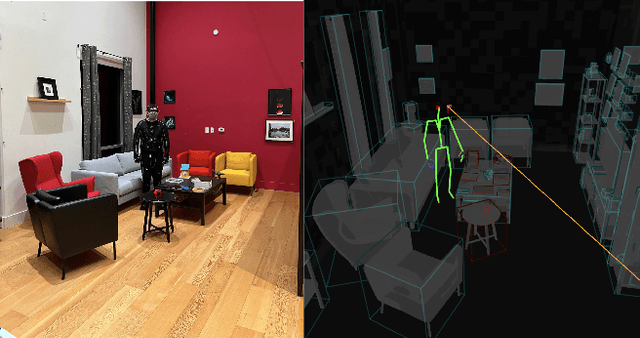
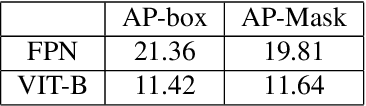
We introduce the Aria Digital Twin (ADT) - an egocentric dataset captured using Aria glasses with extensive object, environment, and human level ground truth. This ADT release contains 200 sequences of real-world activities conducted by Aria wearers in two real indoor scenes with 398 object instances (324 stationary and 74 dynamic). Each sequence consists of: a) raw data of two monochrome camera streams, one RGB camera stream, two IMU streams; b) complete sensor calibration; c) ground truth data including continuous 6-degree-of-freedom (6DoF) poses of the Aria devices, object 6DoF poses, 3D eye gaze vectors, 3D human poses, 2D image segmentations, image depth maps; and d) photo-realistic synthetic renderings. To the best of our knowledge, there is no existing egocentric dataset with a level of accuracy, photo-realism and comprehensiveness comparable to ADT. By contributing ADT to the research community, our mission is to set a new standard for evaluation in the egocentric machine perception domain, which includes very challenging research problems such as 3D object detection and tracking, scene reconstruction and understanding, sim-to-real learning, human pose prediction - while also inspiring new machine perception tasks for augmented reality (AR) applications. To kick start exploration of the ADT research use cases, we evaluated several existing state-of-the-art methods for object detection, segmentation and image translation tasks that demonstrate the usefulness of ADT as a benchmarking dataset.
Deep Optimal Transport: A Practical Algorithm for Photo-realistic Image Restoration
Jun 04, 2023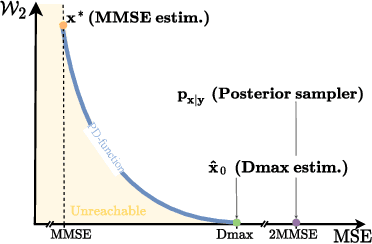
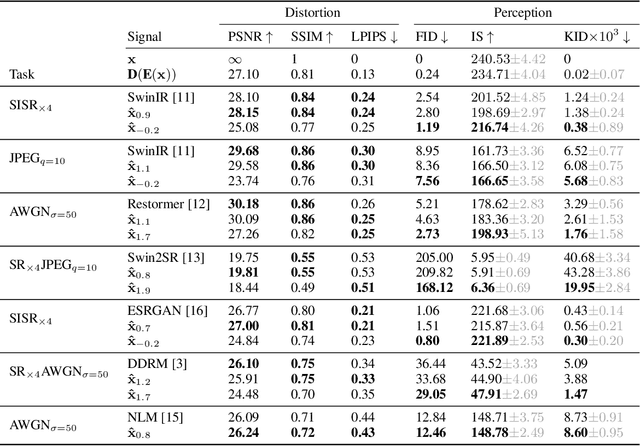

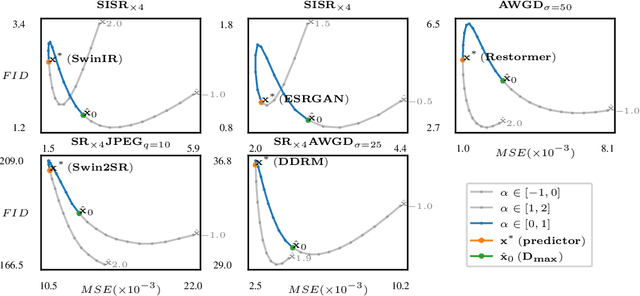
We propose an image restoration algorithm that can control the perceptual quality and/or the mean square error (MSE) of any pre-trained model, trading one over the other at test time. Our algorithm is few-shot: Given about a dozen images restored by the model, it can significantly improve the perceptual quality and/or the MSE of the model for newly restored images without further training. Our approach is motivated by a recent theoretical result that links between the minimum MSE (MMSE) predictor and the predictor that minimizes the MSE under a perfect perceptual quality constraint. Specifically, it has been shown that the latter can be obtained by optimally transporting the output of the former, such that its distribution matches the source data. Thus, to improve the perceptual quality of a predictor that was originally trained to minimize MSE, we approximate the optimal transport by a linear transformation in the latent space of a variational auto-encoder, which we compute in closed-form using empirical means and covariances. Going beyond the theory, we find that applying the same procedure on models that were initially trained to achieve high perceptual quality, typically improves their perceptual quality even further. And by interpolating the results with the original output of the model, we can improve their MSE on the expense of perceptual quality. We illustrate our method on a variety of degradations applied to general content images of arbitrary dimensions.
Switching Head-Tail Funnel UNITER for Dual Referring Expression Comprehension with Fetch-and-Carry Tasks
Jul 14, 2023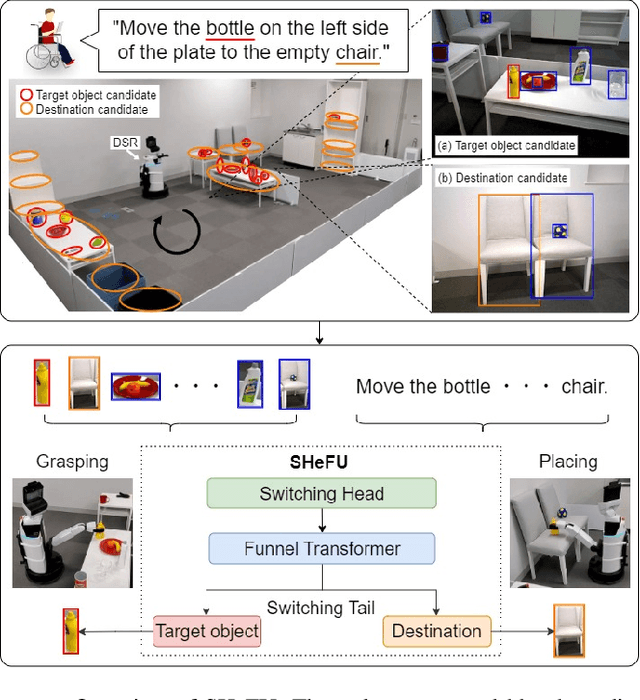
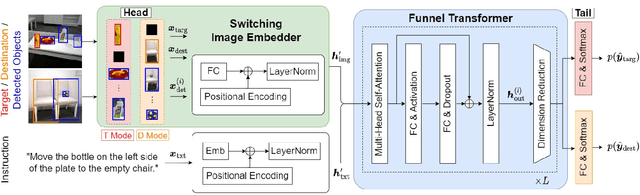
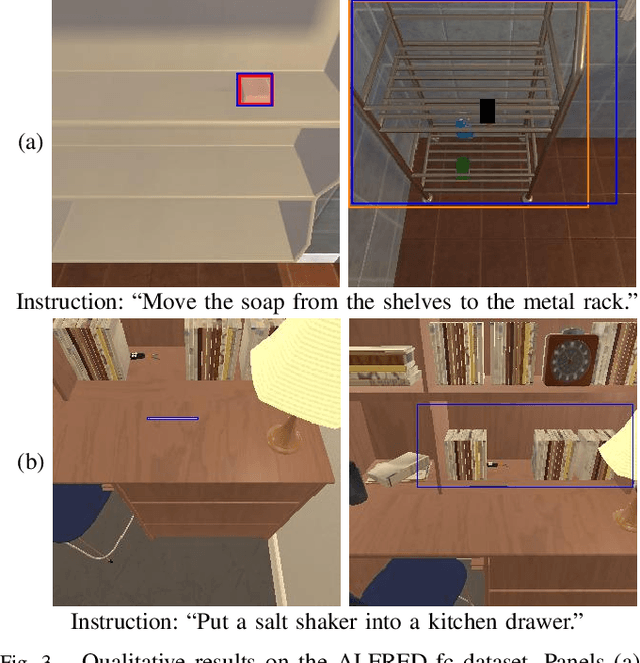

This paper describes a domestic service robot (DSR) that fetches everyday objects and carries them to specified destinations according to free-form natural language instructions. Given an instruction such as "Move the bottle on the left side of the plate to the empty chair," the DSR is expected to identify the bottle and the chair from multiple candidates in the environment and carry the target object to the destination. Most of the existing multimodal language understanding methods are impractical in terms of computational complexity because they require inferences for all combinations of target object candidates and destination candidates. We propose Switching Head-Tail Funnel UNITER, which solves the task by predicting the target object and the destination individually using a single model. Our method is validated on a newly-built dataset consisting of object manipulation instructions and semi photo-realistic images captured in a standard Embodied AI simulator. The results show that our method outperforms the baseline method in terms of language comprehension accuracy. Furthermore, we conduct physical experiments in which a DSR delivers standardized everyday objects in a standardized domestic environment as requested by instructions with referring expressions. The experimental results show that the object grasping and placing actions are achieved with success rates of more than 90%.
Urban Radiance Field Representation with Deformable Neural Mesh Primitives
Jul 20, 2023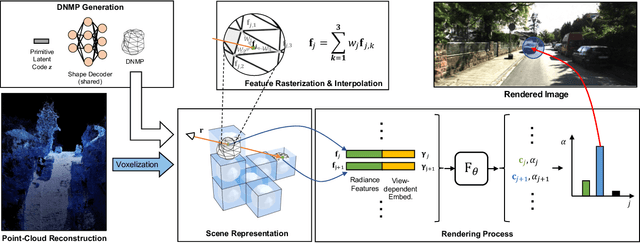
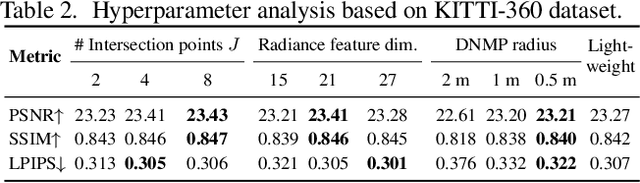
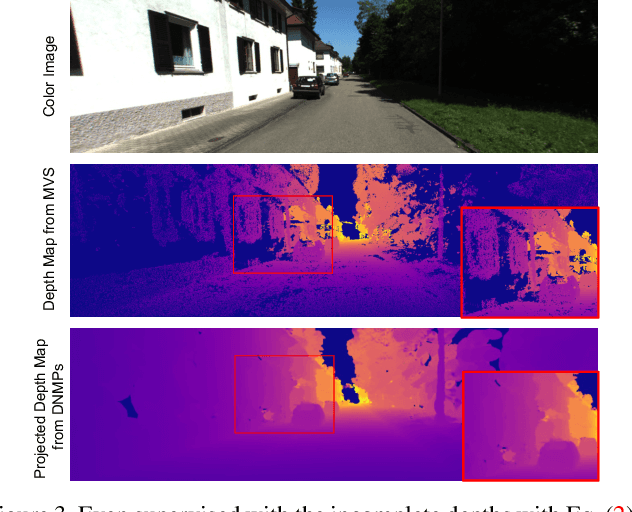

Neural Radiance Fields (NeRFs) have achieved great success in the past few years. However, most current methods still require intensive resources due to ray marching-based rendering. To construct urban-level radiance fields efficiently, we design Deformable Neural Mesh Primitive~(DNMP), and propose to parameterize the entire scene with such primitives. The DNMP is a flexible and compact neural variant of classic mesh representation, which enjoys both the efficiency of rasterization-based rendering and the powerful neural representation capability for photo-realistic image synthesis. Specifically, a DNMP consists of a set of connected deformable mesh vertices with paired vertex features to parameterize the geometry and radiance information of a local area. To constrain the degree of freedom for optimization and lower the storage budgets, we enforce the shape of each primitive to be decoded from a relatively low-dimensional latent space. The rendering colors are decoded from the vertex features (interpolated with rasterization) by a view-dependent MLP. The DNMP provides a new paradigm for urban-level scene representation with appealing properties: $(1)$ High-quality rendering. Our method achieves leading performance for novel view synthesis in urban scenarios. $(2)$ Low computational costs. Our representation enables fast rendering (2.07ms/1k pixels) and low peak memory usage (110MB/1k pixels). We also present a lightweight version that can run 33$\times$ faster than vanilla NeRFs, and comparable to the highly-optimized Instant-NGP (0.61 vs 0.71ms/1k pixels). Project page: \href{https://dnmp.github.io/}{https://dnmp.github.io/}.
FlipNeRF: Flipped Reflection Rays for Few-shot Novel View Synthesis
Jul 16, 2023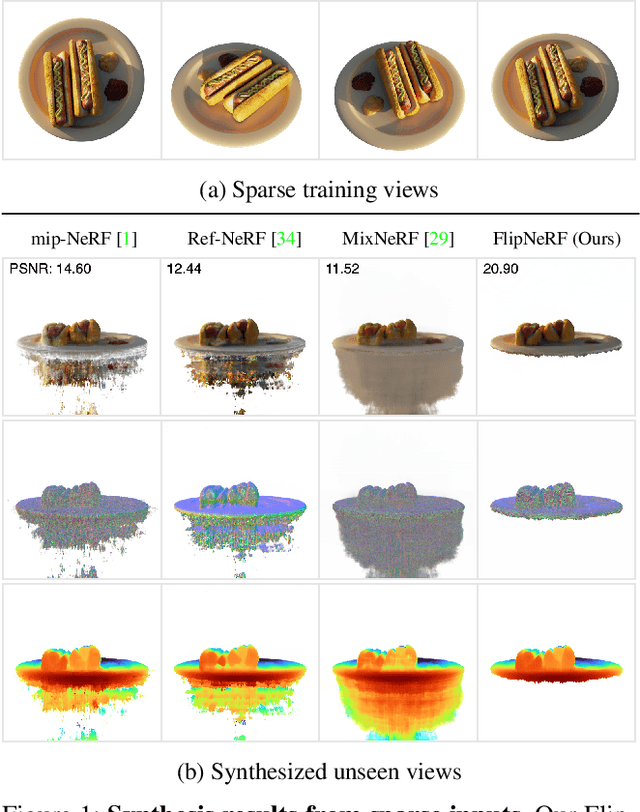
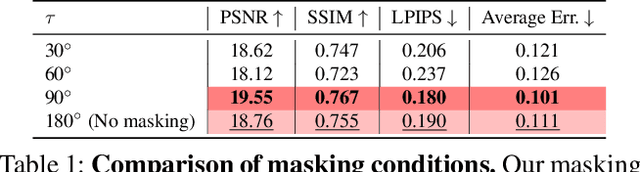
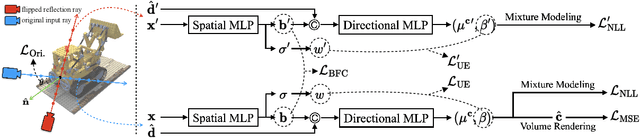
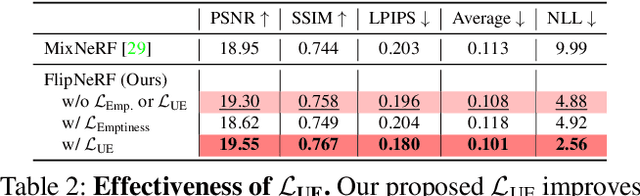
Neural Radiance Field (NeRF) has been a mainstream in novel view synthesis with its remarkable quality of rendered images and simple architecture. Although NeRF has been developed in various directions improving continuously its performance, the necessity of a dense set of multi-view images still exists as a stumbling block to progress for practical application. In this work, we propose FlipNeRF, a novel regularization method for few-shot novel view synthesis by utilizing our proposed flipped reflection rays. The flipped reflection rays are explicitly derived from the input ray directions and estimated normal vectors, and play a role of effective additional training rays while enabling to estimate more accurate surface normals and learn the 3D geometry effectively. Since the surface normal and the scene depth are both derived from the estimated densities along a ray, the accurate surface normal leads to more exact depth estimation, which is a key factor for few-shot novel view synthesis. Furthermore, with our proposed Uncertainty-aware Emptiness Loss and Bottleneck Feature Consistency Loss, FlipNeRF is able to estimate more reliable outputs with reducing floating artifacts effectively across the different scene structures, and enhance the feature-level consistency between the pair of the rays cast toward the photo-consistent pixels without any additional feature extractor, respectively. Our FlipNeRF achieves the SOTA performance on the multiple benchmarks across all the scenarios.
ParGANDA: Making Synthetic Pedestrians A Reality For Object Detection
Jul 21, 2023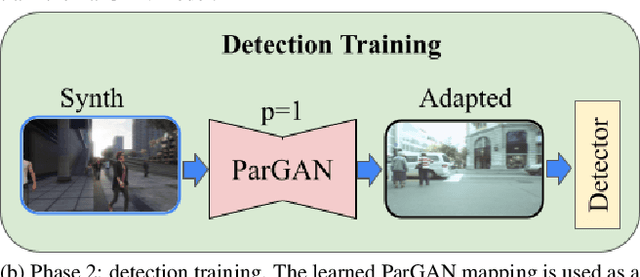



Object detection is the key technique to a number of Computer Vision applications, but it often requires large amounts of annotated data to achieve decent results. Moreover, for pedestrian detection specifically, the collected data might contain some personally identifiable information (PII), which is highly restricted in many countries. This label intensive and privacy concerning task has recently led to an increasing interest in training the detection models using synthetically generated pedestrian datasets collected with a photo-realistic video game engine. The engine is able to generate unlimited amounts of data with precise and consistent annotations, which gives potential for significant gains in the real-world applications. However, the use of synthetic data for training introduces a synthetic-to-real domain shift aggravating the final performance. To close the gap between the real and synthetic data, we propose to use a Generative Adversarial Network (GAN), which performsparameterized unpaired image-to-image translation to generate more realistic images. The key benefit of using the GAN is its intrinsic preference of low-level changes to geometric ones, which means annotations of a given synthetic image remain accurate even after domain translation is performed thus eliminating the need for labeling real data. We extensively experimented with the proposed method using MOTSynth dataset to train and MOT17 and MOT20 detection datasets to test, with experimental results demonstrating the effectiveness of this method. Our approach not only produces visually plausible samples but also does not require any labels of the real domain thus making it applicable to the variety of downstream tasks.
Iris super-resolution using CNNs: is photo-realism important to iris recognition?
Oct 24, 2022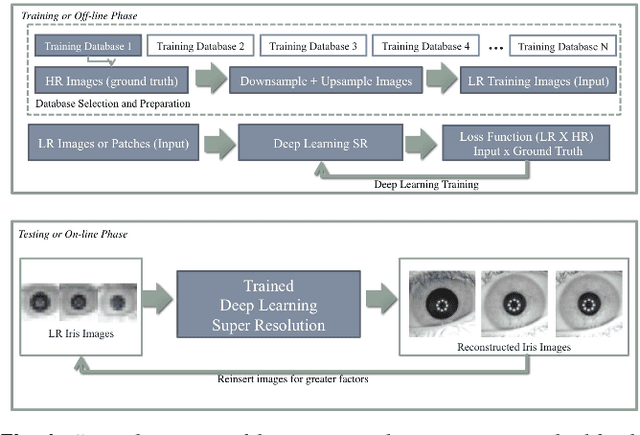

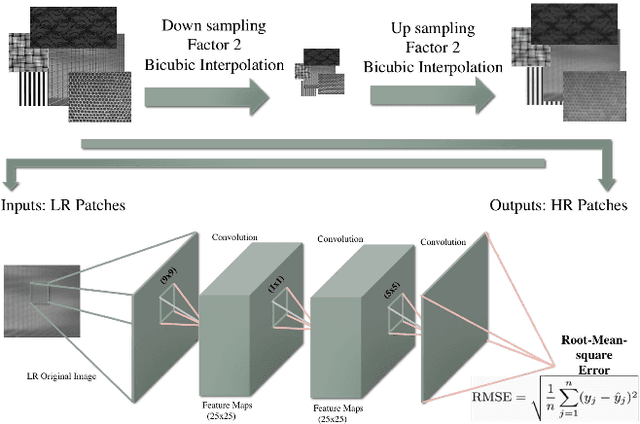
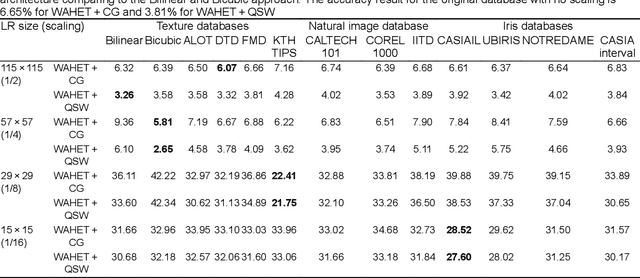
The use of low-resolution images adopting more relaxed acquisition conditions such as mobile phones and surveillance videos is becoming increasingly common in iris recognition nowadays. Concurrently, a great variety of single image super-resolution techniques are emerging, especially with the use of convolutional neural networks (CNNs). The main objective of these methods is to try to recover finer texture details generating more photo-realistic images based on the optimisation of an objective function depending basically on the CNN architecture and training approach. In this work, the authors explore single image super-resolution using CNNs for iris recognition. For this, they test different CNN architectures and use different training databases, validating their approach on a database of 1.872 near infrared iris images and on a mobile phone image database. They also use quality assessment, visual results and recognition experiments to verify if the photo-realism provided by the CNNs which have already proven to be effective for natural images can reflect in a better recognition rate for iris recognition. The results show that using deeper architectures trained with texture databases that provide a balance between edge preservation and the smoothness of the method can lead to good results in the iris recognition process.
Defocus to focus: Photo-realistic bokeh rendering by fusing defocus and radiance priors
Jun 07, 2023

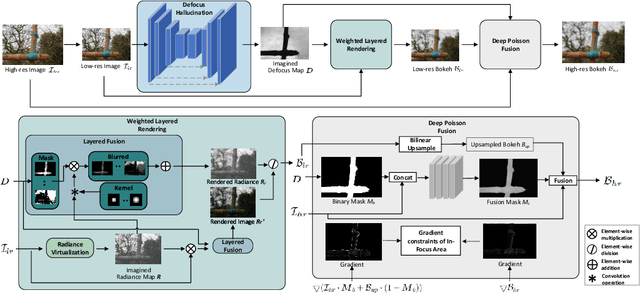
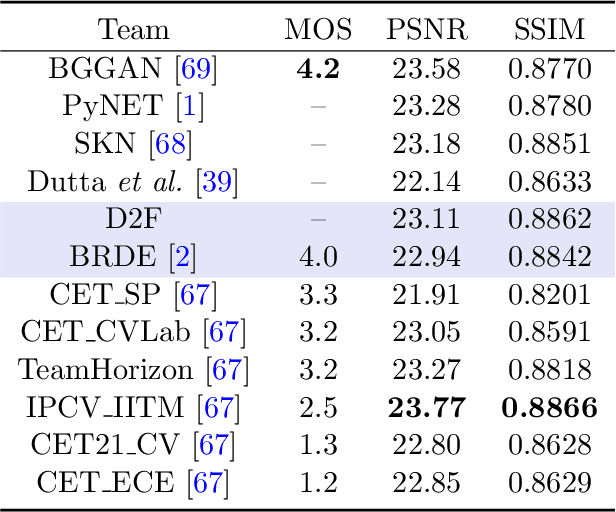
We consider the problem of realistic bokeh rendering from a single all-in-focus image. Bokeh rendering mimics aesthetic shallow depth-of-field (DoF) in professional photography, but these visual effects generated by existing methods suffer from simple flat background blur and blurred in-focus regions, giving rise to unrealistic rendered results. In this work, we argue that realistic bokeh rendering should (i) model depth relations and distinguish in-focus regions, (ii) sustain sharp in-focus regions, and (iii) render physically accurate Circle of Confusion (CoC). To this end, we present a Defocus to Focus (D2F) framework to learn realistic bokeh rendering by fusing defocus priors with the all-in-focus image and by implementing radiance priors in layered fusion. Since no depth map is provided, we introduce defocus hallucination to integrate depth by learning to focus. The predicted defocus map implies the blur amount of bokeh and is used to guide weighted layered rendering. In layered rendering, we fuse images blurred by different kernels based on the defocus map. To increase the reality of the bokeh, we adopt radiance virtualization to simulate scene radiance. The scene radiance used in weighted layered rendering reassigns weights in the soft disk kernel to produce the CoC. To ensure the sharpness of in-focus regions, we propose to fuse upsampled bokeh images and original images. We predict the initial fusion mask from our defocus map and refine the mask with a deep network. We evaluate our model on a large-scale bokeh dataset. Extensive experiments show that our approach is capable of rendering visually pleasing bokeh effects in complex scenes. In particular, our solution receives the runner-up award in the AIM 2020 Rendering Realistic Bokeh Challenge.
* Published at Information Fusion 2023 https://www.sciencedirect.com/science/article/pii/S1566253522001221
NOFA: NeRF-based One-shot Facial Avatar Reconstruction
Jul 07, 2023
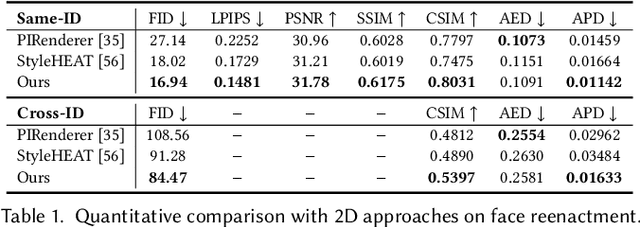
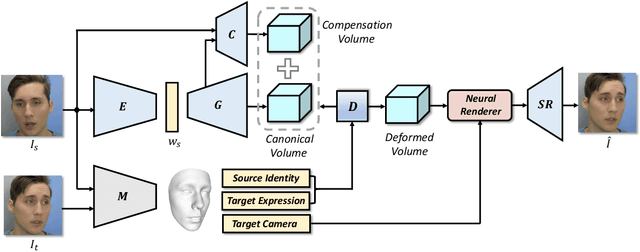
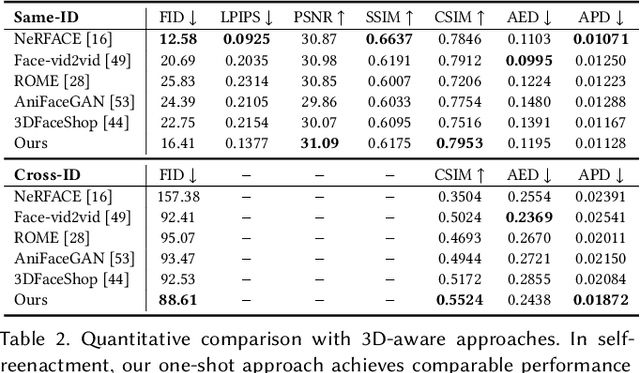
3D facial avatar reconstruction has been a significant research topic in computer graphics and computer vision, where photo-realistic rendering and flexible controls over poses and expressions are necessary for many related applications. Recently, its performance has been greatly improved with the development of neural radiance fields (NeRF). However, most existing NeRF-based facial avatars focus on subject-specific reconstruction and reenactment, requiring multi-shot images containing different views of the specific subject for training, and the learned model cannot generalize to new identities, limiting its further applications. In this work, we propose a one-shot 3D facial avatar reconstruction framework that only requires a single source image to reconstruct a high-fidelity 3D facial avatar. For the challenges of lacking generalization ability and missing multi-view information, we leverage the generative prior of 3D GAN and develop an efficient encoder-decoder network to reconstruct the canonical neural volume of the source image, and further propose a compensation network to complement facial details. To enable fine-grained control over facial dynamics, we propose a deformation field to warp the canonical volume into driven expressions. Through extensive experimental comparisons, we achieve superior synthesis results compared to several state-of-the-art methods.