 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Take-A-Photo: 3D-to-2D Generative Pre-training of Point Cloud Models
Jul 27, 2023
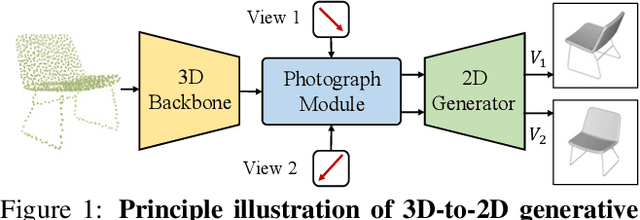
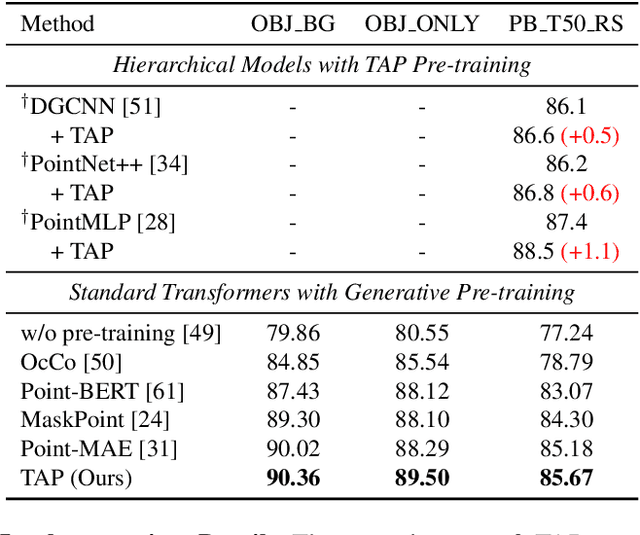
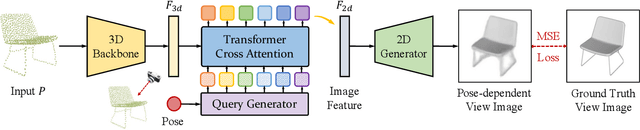
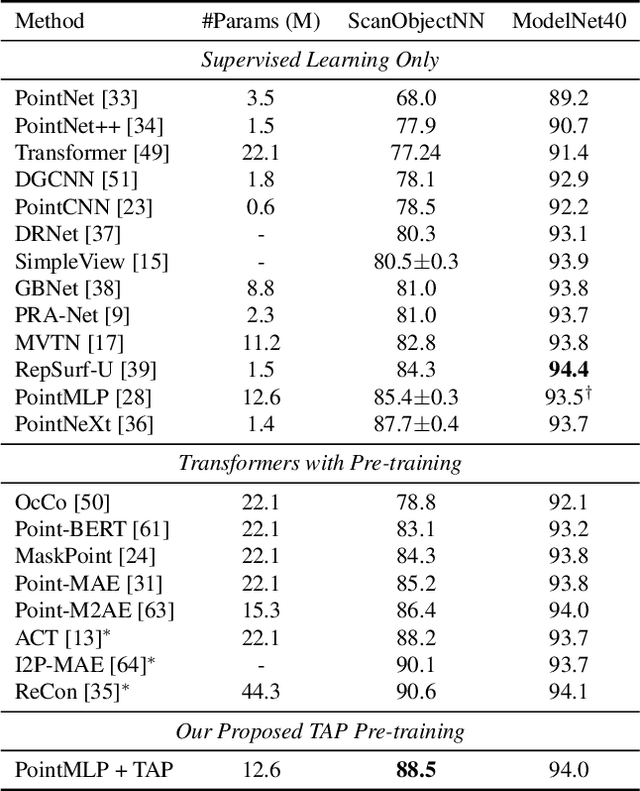
With the overwhelming trend of mask image modeling led by MAE, generative pre-training has shown a remarkable potential to boost the performance of fundamental models in 2D vision. However, in 3D vision, the over-reliance on Transformer-based backbones and the unordered nature of point clouds have restricted the further development of generative pre-training. In this paper, we propose a novel 3D-to-2D generative pre-training method that is adaptable to any point cloud model. We propose to generate view images from different instructed poses via the cross-attention mechanism as the pre-training scheme. Generating view images has more precise supervision than its point cloud counterpart, thus assisting 3D backbones to have a finer comprehension of the geometrical structure and stereoscopic relations of the point cloud. Experimental results have proved the superiority of our proposed 3D-to-2D generative pre-training over previous pre-training methods. Our method is also effective in boosting the performance of architecture-oriented approaches, achieving state-of-the-art performance when fine-tuning on ScanObjectNN classification and ShapeNetPart segmentation tasks. Code is available at https://github.com/wangzy22/TAP.
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 11, 2023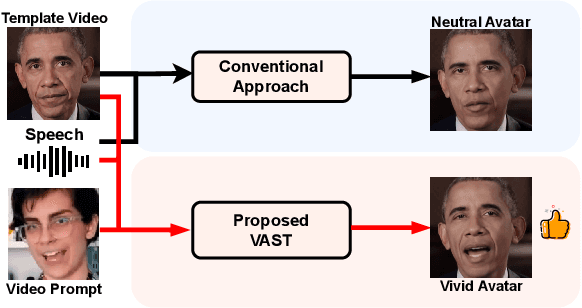

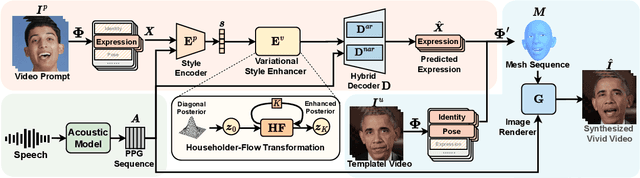
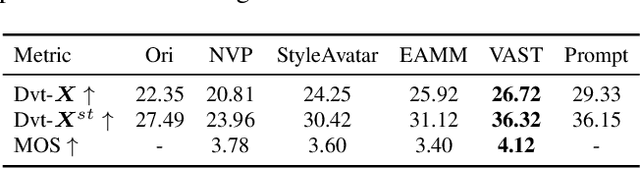
Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.
Instance-level Heterogeneous Domain Adaptation for Limited-labeled Sketch-to-Photo Retrieval
Nov 26, 2022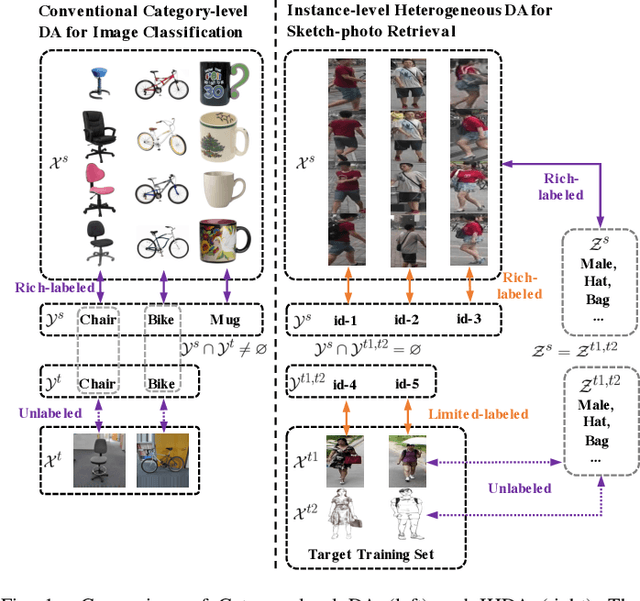
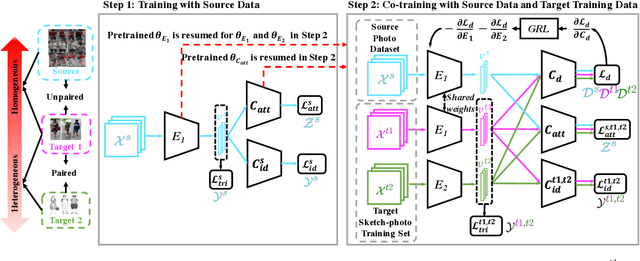

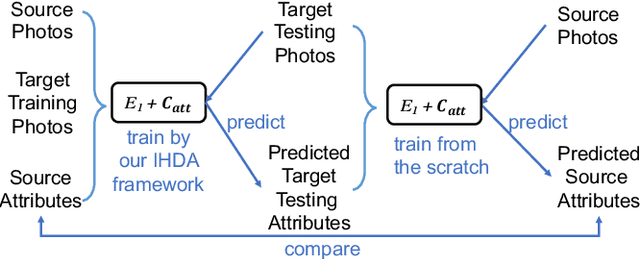
Although sketch-to-photo retrieval has a wide range of applications, it is costly to obtain paired and rich-labeled ground truth. Differently, photo retrieval data is easier to acquire. Therefore, previous works pre-train their models on rich-labeled photo retrieval data (i.e., source domain) and then fine-tune them on the limited-labeled sketch-to-photo retrieval data (i.e., target domain). However, without co-training source and target data, source domain knowledge might be forgotten during the fine-tuning process, while simply co-training them may cause negative transfer due to domain gaps. Moreover, identity label spaces of source data and target data are generally disjoint and therefore conventional category-level Domain Adaptation (DA) is not directly applicable. To address these issues, we propose an Instance-level Heterogeneous Domain Adaptation (IHDA) framework. We apply the fine-tuning strategy for identity label learning, aiming to transfer the instance-level knowledge in an inductive transfer manner. Meanwhile, labeled attributes from the source data are selected to form a shared label space for source and target domains. Guided by shared attributes, DA is utilized to bridge cross-dataset domain gaps and heterogeneous domain gaps, which transfers instance-level knowledge in a transductive transfer manner. Experiments show that our method has set a new state of the art on three sketch-to-photo image retrieval benchmarks without extra annotations, which opens the door to train more effective models on limited-labeled heterogeneous image retrieval tasks. Related codes are available at \url{https://github.com/fandulu/IHDA.
Photo-realistic Neural Domain Randomization
Oct 23, 2022Synthetic data is a scalable alternative to manual supervision, but it requires overcoming the sim-to-real domain gap. This discrepancy between virtual and real worlds is addressed by two seemingly opposed approaches: improving the realism of simulation or foregoing realism entirely via domain randomization. In this paper, we show that the recent progress in neural rendering enables a new unified approach we call Photo-realistic Neural Domain Randomization (PNDR). We propose to learn a composition of neural networks that acts as a physics-based ray tracer generating high-quality renderings from scene geometry alone. Our approach is modular, composed of different neural networks for materials, lighting, and rendering, thus enabling randomization of different key image generation components in a differentiable pipeline. Once trained, our method can be combined with other methods and used to generate photo-realistic image augmentations online and significantly more efficiently than via traditional ray-tracing. We demonstrate the usefulness of PNDR through two downstream tasks: 6D object detection and monocular depth estimation. Our experiments show that training with PNDR enables generalization to novel scenes and significantly outperforms the state of the art in terms of real-world transfer.
Intriguing Properties of Diffusion Models: A Large-Scale Dataset for Evaluating Natural Attack Capability in Text-to-Image Generative Models
Aug 30, 2023


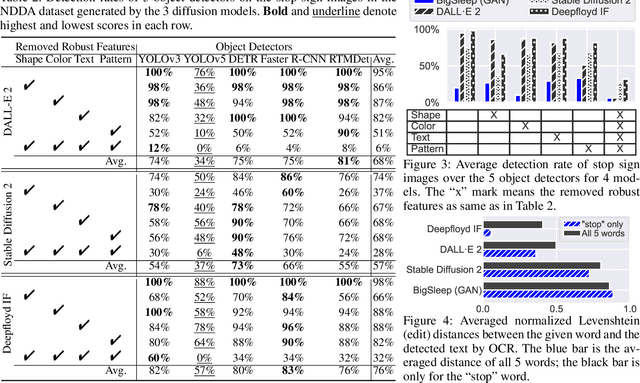
Denoising probabilistic diffusion models have shown breakthrough performance that can generate more photo-realistic images or human-level illustrations than the prior models such as GANs. This high image-generation capability has stimulated the creation of many downstream applications in various areas. However, we find that this technology is indeed a double-edged sword: We identify a new type of attack, called the Natural Denoising Diffusion (NDD) attack based on the finding that state-of-the-art deep neural network (DNN) models still hold their prediction even if we intentionally remove their robust features, which are essential to the human visual system (HVS), by text prompts. The NDD attack can generate low-cost, model-agnostic, and transferrable adversarial attacks by exploiting the natural attack capability in diffusion models. Motivated by the finding, we construct a large-scale dataset, Natural Denoising Diffusion Attack (NDDA) dataset, to systematically evaluate the risk of the natural attack capability of diffusion models with state-of-the-art text-to-image diffusion models. We evaluate the natural attack capability by answering 6 research questions. Through a user study to confirm the validity of the NDD attack, we find that the NDD attack can achieve an 88% detection rate while being stealthy to 93% of human subjects. We also find that the non-robust features embedded by diffusion models contribute to the natural attack capability. To confirm the model-agnostic and transferrable attack capability, we perform the NDD attack against an AD vehicle and find that 73% of the physically printed attacks can be detected as a stop sign. We hope that our study and dataset can help our community to be aware of the risk of diffusion models and facilitate further research toward robust DNN models.
Towards Automatic Cetacean Photo-Identification: A Framework for Fine-Grain, Few-Shot Learning in Marine Ecology
Dec 07, 2022

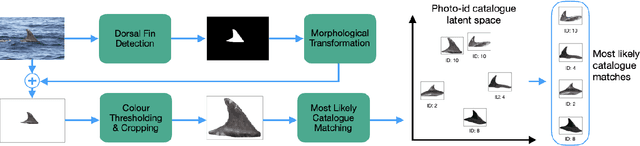
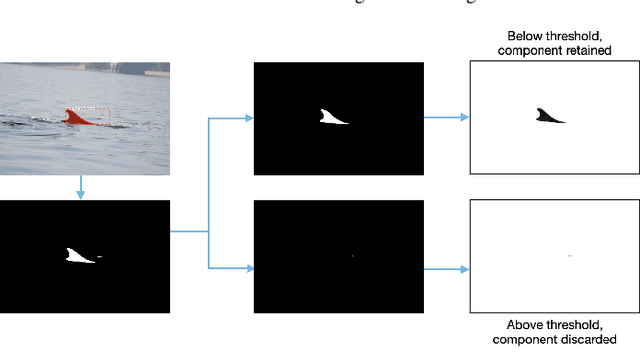
Photo-identification (photo-id) is one of the main non-invasive capture-recapture methods utilised by marine researchers for monitoring cetacean (dolphin, whale, and porpoise) populations. This method has historically been performed manually resulting in high workload and cost due to the vast number of images collected. Recently automated aids have been developed to help speed-up photo-id, although they are often disjoint in their processing and do not utilise all available identifying information. Work presented in this paper aims to create a fully automatic photo-id aid capable of providing most likely matches based on all available information without the need for data pre-processing such as cropping. This is achieved through a pipeline of computer vision models and post-processing techniques aimed at detecting cetaceans in unedited field imagery before passing them downstream for individual level catalogue matching. The system is capable of handling previously uncatalogued individuals and flagging these for investigation thanks to catalogue similarity comparison. We evaluate the system against multiple real-life photo-id catalogues, achieving mAP@IOU[0.5] = 0.91, 0.96 for the task of dorsal fin detection on catalogues from Tanzania and the UK respectively and 83.1, 97.5% top-10 accuracy for the task of individual classification on catalogues from the UK and USA.
ChatSim: Underwater Simulation with Natural Language Prompting
Aug 09, 2023
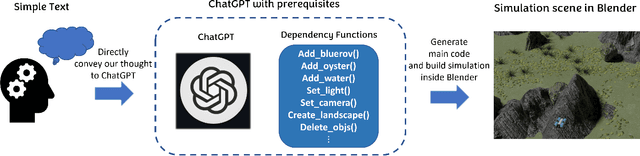
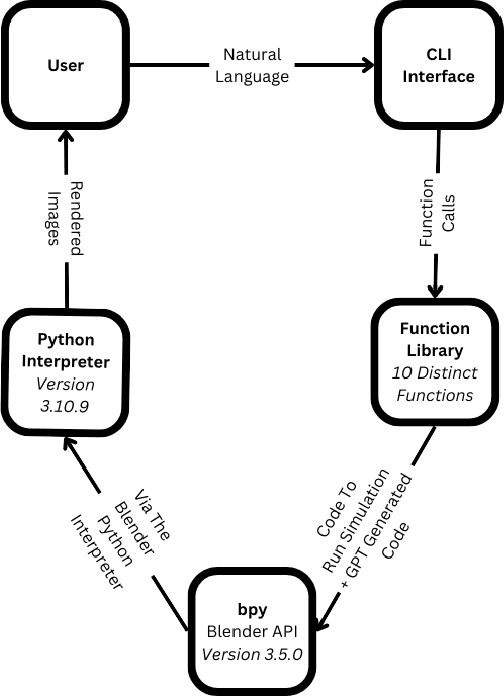

Robots are becoming an essential part of many operations including marine exploration or environmental monitoring. However, the underwater environment presents many challenges, including high pressure, limited visibility, and harsh conditions that can damage equipment. Real-world experimentation can be expensive and difficult to execute. Therefore, it is essential to simulate the performance of underwater robots in comparable environments to ensure their optimal functionality within practical real-world contexts.OysterSim generates photo-realistic images and segmentation masks of objects in marine environments, providing valuable training data for underwater computer vision applications. By integrating ChatGPT into underwater simulations, users can convey their thoughts effortlessly and intuitively create desired underwater environments without intricate coding. \invis{Moreover, researchers can realize substantial time and cost savings by evaluating their algorithms across diverse underwater conditions in the simulation.} The objective of ChatSim is to integrate Large Language Models (LLM) with a simulation environment~(OysterSim), enabling direct control of the simulated environment via natural language input. This advancement can greatly enhance the capabilities of underwater simulation, with far-reaching benefits for marine exploration and broader scientific research endeavors.
Non-invasive Diabetes Detection using Gabor Filter: A Comparative Analysis of Different Cameras
Jul 28, 2023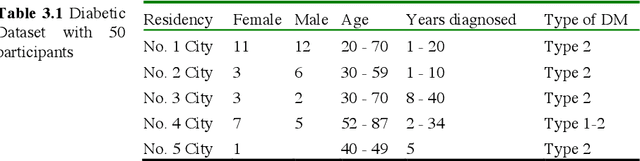

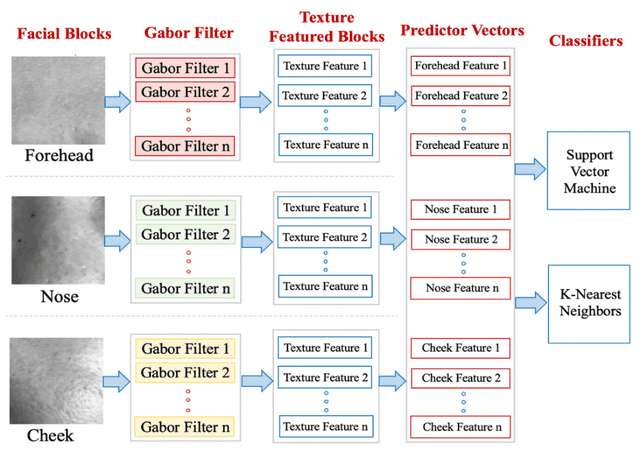
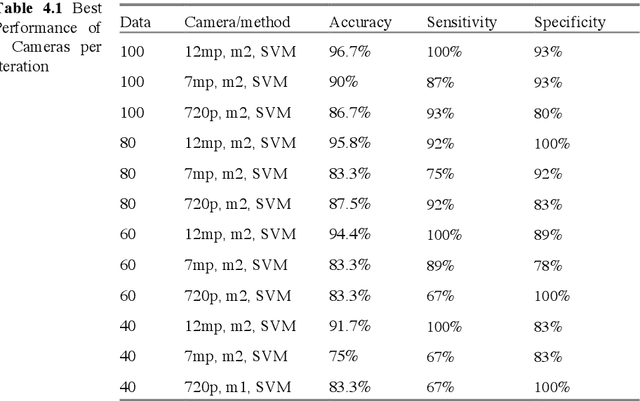
This paper compares and explores the performance of both mobile device camera and laptop camera as convenient tool for capturing images for non-invasive detection of Diabetes Mellitus (DM) using facial block texture features. Participants within age bracket 20 to 79 years old were chosen for the dataset. 12mp and 7mp mobile cameras, and a laptop camera were used to take the photo under normal lighting condition. Extracted facial blocks were classified using k-Nearest Neighbors (k-NN) and Support Vector Machine (SVM). 100 images were captured, preprocessed, filtered using Gabor, and iterated. Performance of the system was measured in terms of accuracy, specificity, and sensitivity. Best performance of 96.7% accuracy, 100% sensitivity, and 93% specificity were achieved from 12mp back camera using SVM with 100 images.
Circumventing Concept Erasure Methods For Text-to-Image Generative Models
Aug 03, 2023
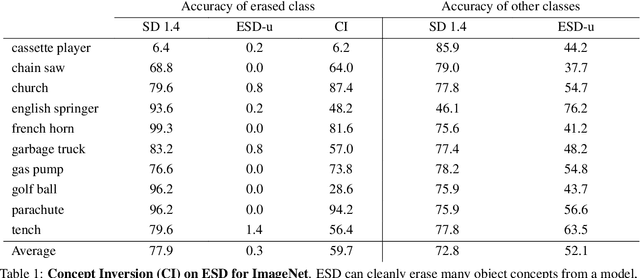


Text-to-image generative models can produce photo-realistic images for an extremely broad range of concepts, and their usage has proliferated widely among the general public. On the flip side, these models have numerous drawbacks, including their potential to generate images featuring sexually explicit content, mirror artistic styles without permission, or even hallucinate (or deepfake) the likenesses of celebrities. Consequently, various methods have been proposed in order to "erase" sensitive concepts from text-to-image models. In this work, we examine five recently proposed concept erasure methods, and show that targeted concepts are not fully excised from any of these methods. Specifically, we leverage the existence of special learned word embeddings that can retrieve "erased" concepts from the sanitized models with no alterations to their weights. Our results highlight the brittleness of post hoc concept erasure methods, and call into question their use in the algorithmic toolkit for AI safety.