 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Closing the Loop on Runtime Monitors with Fallback-Safe MPC
Sep 15, 2023
When we rely on deep-learned models for robotic perception, we must recognize that these models may behave unreliably on inputs dissimilar from the training data, compromising the closed-loop system's safety. This raises fundamental questions on how we can assess confidence in perception systems and to what extent we can take safety-preserving actions when external environmental changes degrade our perception model's performance. Therefore, we present a framework to certify the safety of a perception-enabled system deployed in novel contexts. To do so, we leverage robust model predictive control (MPC) to control the system using the perception estimates while maintaining the feasibility of a safety-preserving fallback plan that does not rely on the perception system. In addition, we calibrate a runtime monitor using recently proposed conformal prediction techniques to certifiably detect when the perception system degrades beyond the tolerance of the MPC controller, resulting in an end-to-end safety assurance. We show that this control framework and calibration technique allows us to certify the system's safety with orders of magnitudes fewer samples than required to retrain the perception network when we deploy in a novel context on a photo-realistic aircraft taxiing simulator. Furthermore, we illustrate the safety-preserving behavior of the MPC on simulated examples of a quadrotor. We open-source our simulation platform and provide videos of our results at our project page: \url{https://tinyurl.com/fallback-safe-mpc}.
Chasing Consistency in Text-to-3D Generation from a Single Image
Sep 07, 2023

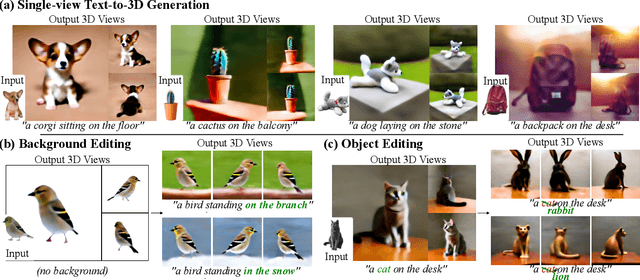
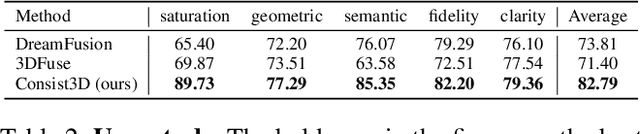
Text-to-3D generation from a single-view image is a popular but challenging task in 3D vision. Although numerous methods have been proposed, existing works still suffer from the inconsistency issues, including 1) semantic inconsistency, 2) geometric inconsistency, and 3) saturation inconsistency, resulting in distorted, overfitted, and over-saturated generations. In light of the above issues, we present Consist3D, a three-stage framework Chasing for semantic-, geometric-, and saturation-Consistent Text-to-3D generation from a single image, in which the first two stages aim to learn parameterized consistency tokens, and the last stage is for optimization. Specifically, the semantic encoding stage learns a token independent of views and estimations, promoting semantic consistency and robustness. Meanwhile, the geometric encoding stage learns another token with comprehensive geometry and reconstruction constraints under novel-view estimations, reducing overfitting and encouraging geometric consistency. Finally, the optimization stage benefits from the semantic and geometric tokens, allowing a low classifier-free guidance scale and therefore preventing oversaturation. Experimental results demonstrate that Consist3D produces more consistent, faithful, and photo-realistic 3D assets compared to previous state-of-the-art methods. Furthermore, Consist3D also allows background and object editing through text prompts.
Point2Pix: Photo-Realistic Point Cloud Rendering via Neural Radiance Fields
Mar 29, 2023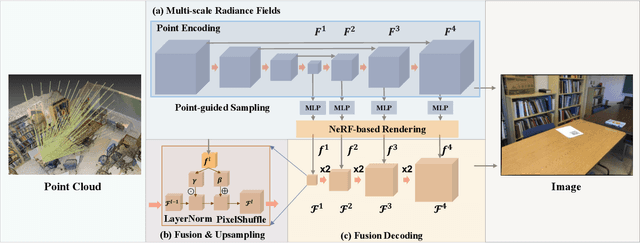
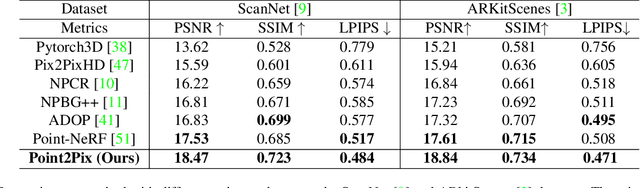
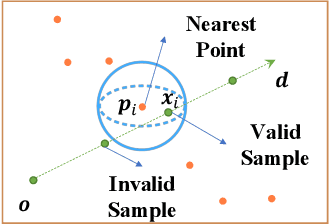
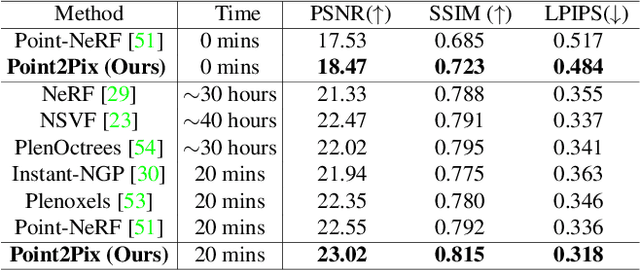
Synthesizing photo-realistic images from a point cloud is challenging because of the sparsity of point cloud representation. Recent Neural Radiance Fields and extensions are proposed to synthesize realistic images from 2D input. In this paper, we present Point2Pix as a novel point renderer to link the 3D sparse point clouds with 2D dense image pixels. Taking advantage of the point cloud 3D prior and NeRF rendering pipeline, our method can synthesize high-quality images from colored point clouds, generally for novel indoor scenes. To improve the efficiency of ray sampling, we propose point-guided sampling, which focuses on valid samples. Also, we present Point Encoding to build Multi-scale Radiance Fields that provide discriminative 3D point features. Finally, we propose Fusion Encoding to efficiently synthesize high-quality images. Extensive experiments on the ScanNet and ArkitScenes datasets demonstrate the effectiveness and generalization.
StyleAvatar: Real-time Photo-realistic Portrait Avatar from a Single Video
May 01, 2023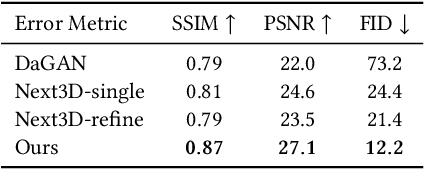
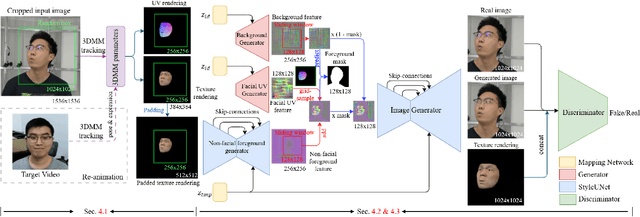
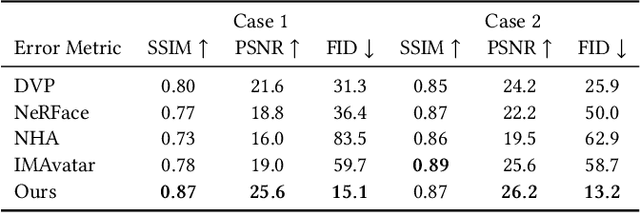

Face reenactment methods attempt to restore and re-animate portrait videos as realistically as possible. Existing methods face a dilemma in quality versus controllability: 2D GAN-based methods achieve higher image quality but suffer in fine-grained control of facial attributes compared with 3D counterparts. In this work, we propose StyleAvatar, a real-time photo-realistic portrait avatar reconstruction method using StyleGAN-based networks, which can generate high-fidelity portrait avatars with faithful expression control. We expand the capabilities of StyleGAN by introducing a compositional representation and a sliding window augmentation method, which enable faster convergence and improve translation generalization. Specifically, we divide the portrait scenes into three parts for adaptive adjustments: facial region, non-facial foreground region, and the background. Besides, our network leverages the best of UNet, StyleGAN and time coding for video learning, which enables high-quality video generation. Furthermore, a sliding window augmentation method together with a pre-training strategy are proposed to improve translation generalization and training performance, respectively. The proposed network can converge within two hours while ensuring high image quality and a forward rendering time of only 20 milliseconds. Furthermore, we propose a real-time live system, which further pushes research into applications. Results and experiments demonstrate the superiority of our method in terms of image quality, full portrait video generation, and real-time re-animation compared to existing facial reenactment methods. Training and inference code for this paper are at https://github.com/LizhenWangT/StyleAvatar.
LoGoPrompt: Synthetic Text Images Can Be Good Visual Prompts for Vision-Language Models
Sep 03, 2023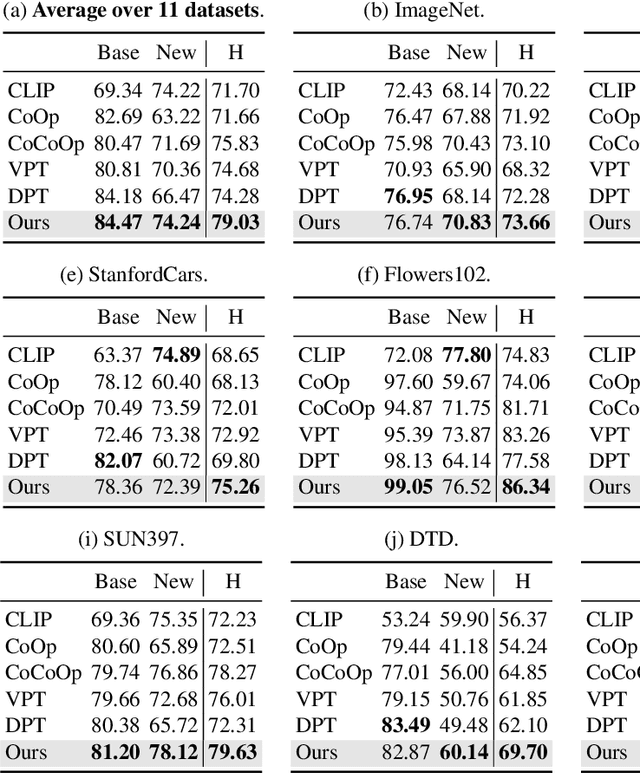

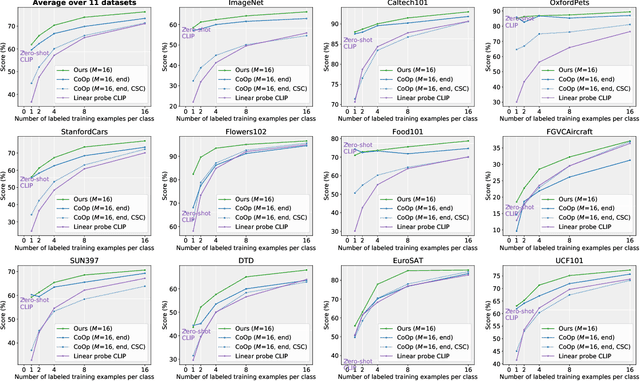
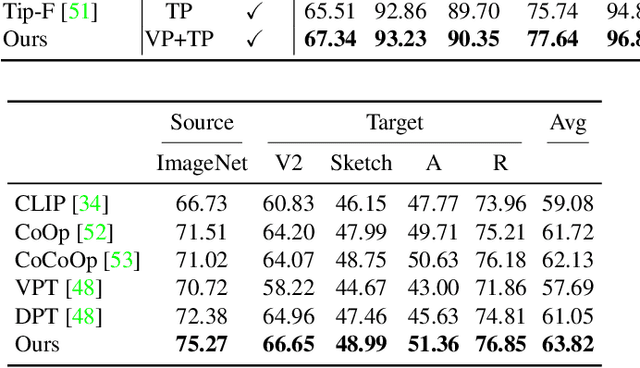
Prompt engineering is a powerful tool used to enhance the performance of pre-trained models on downstream tasks. For example, providing the prompt ``Let's think step by step" improved GPT-3's reasoning accuracy to 63% on MutiArith while prompting ``a photo of" filled with a class name enables CLIP to achieve $80$\% zero-shot accuracy on ImageNet. While previous research has explored prompt learning for the visual modality, analyzing what constitutes a good visual prompt specifically for image recognition is limited. In addition, existing visual prompt tuning methods' generalization ability is worse than text-only prompting tuning. This paper explores our key insight: synthetic text images are good visual prompts for vision-language models! To achieve that, we propose our LoGoPrompt, which reformulates the classification objective to the visual prompt selection and addresses the chicken-and-egg challenge of first adding synthetic text images as class-wise visual prompts or predicting the class first. Without any trainable visual prompt parameters, experimental results on 16 datasets demonstrate that our method consistently outperforms state-of-the-art methods in few-shot learning, base-to-new generalization, and domain generalization.
Human-Inspired Facial Sketch Synthesis with Dynamic Adaptation
Sep 01, 2023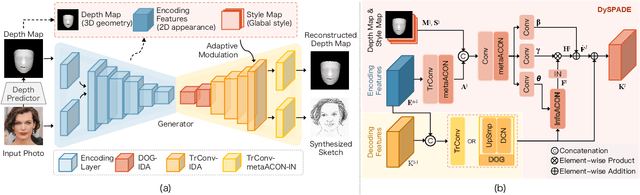
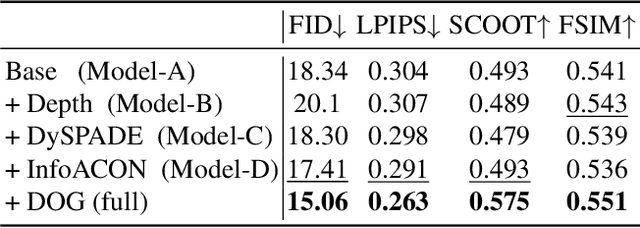
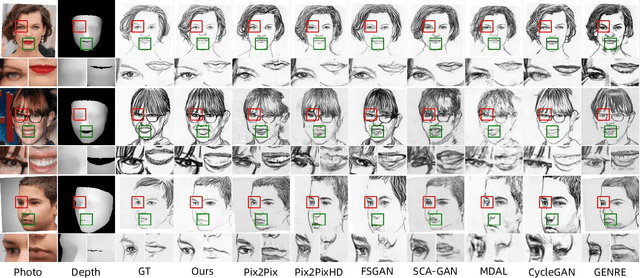
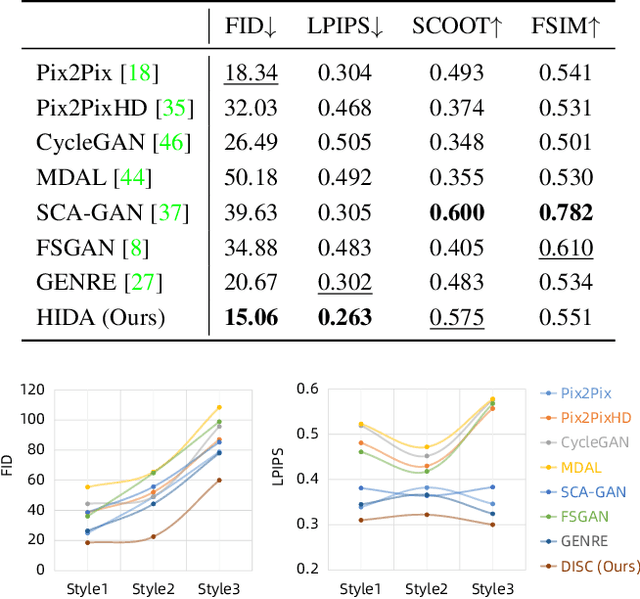
Facial sketch synthesis (FSS) aims to generate a vivid sketch portrait from a given facial photo. Existing FSS methods merely rely on 2D representations of facial semantic or appearance. However, professional human artists usually use outlines or shadings to covey 3D geometry. Thus facial 3D geometry (e.g. depth map) is extremely important for FSS. Besides, different artists may use diverse drawing techniques and create multiple styles of sketches; but the style is globally consistent in a sketch. Inspired by such observations, in this paper, we propose a novel Human-Inspired Dynamic Adaptation (HIDA) method. Specially, we propose to dynamically modulate neuron activations based on a joint consideration of both facial 3D geometry and 2D appearance, as well as globally consistent style control. Besides, we use deformable convolutions at coarse-scales to align deep features, for generating abstract and distinct outlines. Experiments show that HIDA can generate high-quality sketches in multiple styles, and significantly outperforms previous methods, over a large range of challenging faces. Besides, HIDA allows precise style control of the synthesized sketch, and generalizes well to natural scenes and other artistic styles. Our code and results have been released online at: https://github.com/AiArt-HDU/HIDA.
PersonNeRF: Personalized Reconstruction from Photo Collections
Feb 16, 2023
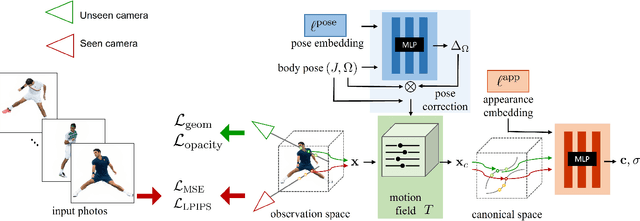

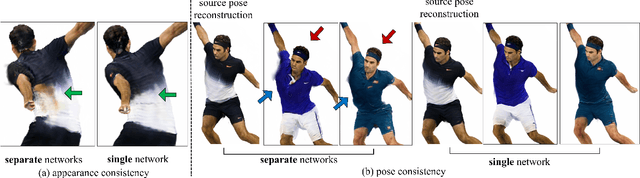
We present PersonNeRF, a method that takes a collection of photos of a subject (e.g. Roger Federer) captured across multiple years with arbitrary body poses and appearances, and enables rendering the subject with arbitrary novel combinations of viewpoint, body pose, and appearance. PersonNeRF builds a customized neural volumetric 3D model of the subject that is able to render an entire space spanned by camera viewpoint, body pose, and appearance. A central challenge in this task is dealing with sparse observations; a given body pose is likely only observed by a single viewpoint with a single appearance, and a given appearance is only observed under a handful of different body poses. We address this issue by recovering a canonical T-pose neural volumetric representation of the subject that allows for changing appearance across different observations, but uses a shared pose-dependent motion field across all observations. We demonstrate that this approach, along with regularization of the recovered volumetric geometry to encourage smoothness, is able to recover a model that renders compelling images from novel combinations of viewpoint, pose, and appearance from these challenging unstructured photo collections, outperforming prior work for free-viewpoint human rendering.
Improving the Accuracy of Beauty Product Recommendations by Assessing Face Illumination Quality
Sep 07, 2023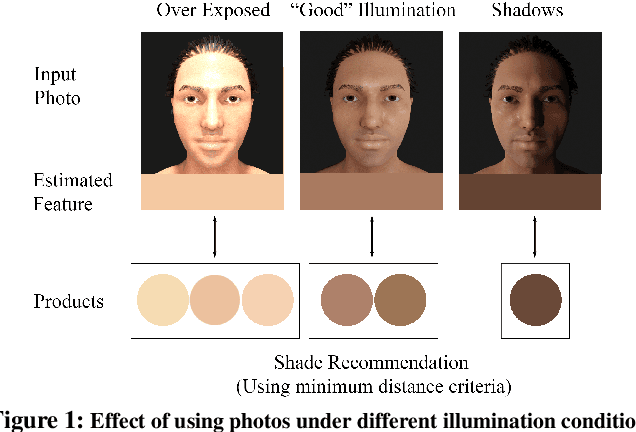
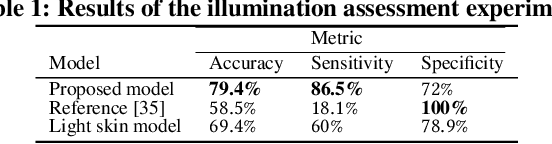
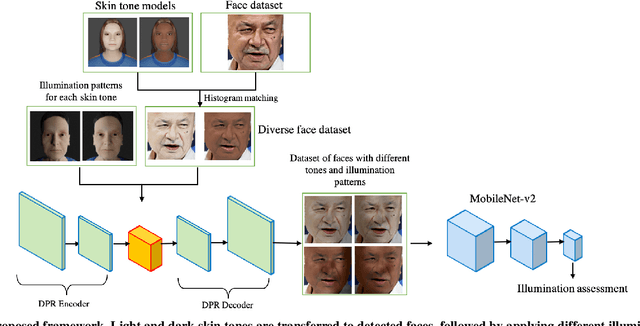
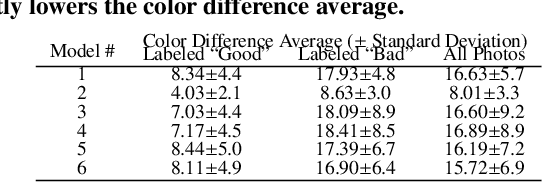
We focus on addressing the challenges in responsible beauty product recommendation, particularly when it involves comparing the product's color with a person's skin tone, such as for foundation and concealer products. To make accurate recommendations, it is crucial to infer both the product attributes and the product specific facial features such as skin conditions or tone. However, while many product photos are taken under good light conditions, face photos are taken from a wide range of conditions. The features extracted using the photos from ill-illuminated environment can be highly misleading or even be incompatible to be compared with the product attributes. Hence bad illumination condition can severely degrade quality of the recommendation. We introduce a machine learning framework for illumination assessment which classifies images into having either good or bad illumination condition. We then build an automatic user guidance tool which informs a user holding their camera if their illumination condition is good or bad. This way, the user is provided with rapid feedback and can interactively control how the photo is taken for their recommendation. Only a few studies are dedicated to this problem, mostly due to the lack of dataset that is large, labeled, and diverse both in terms of skin tones and light patterns. Lack of such dataset leads to neglecting skin tone diversity. Therefore, We begin by constructing a diverse synthetic dataset that simulates various skin tones and light patterns in addition to an existing facial image dataset. Next, we train a Convolutional Neural Network (CNN) for illumination assessment that outperforms the existing solutions using the synthetic dataset. Finally, we analyze how the our work improves the shade recommendation for various foundation products.
Instance-level Heterogeneous Domain Adaptation for Limited-labeled Sketch-to-Photo Retrieval
Dec 06, 2022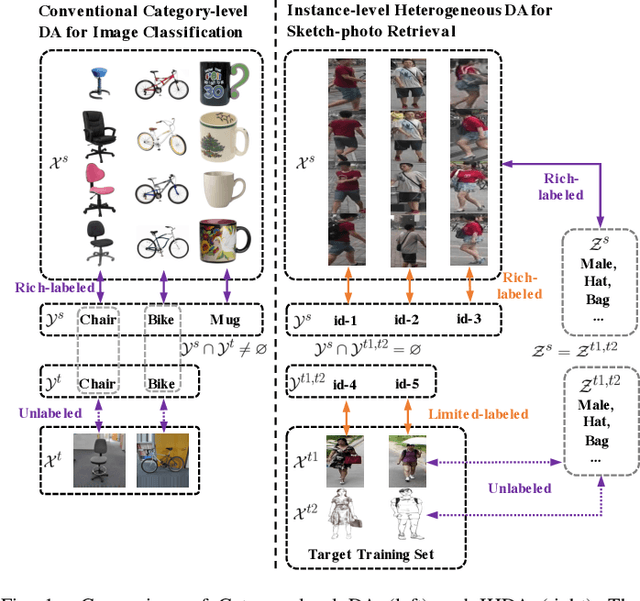
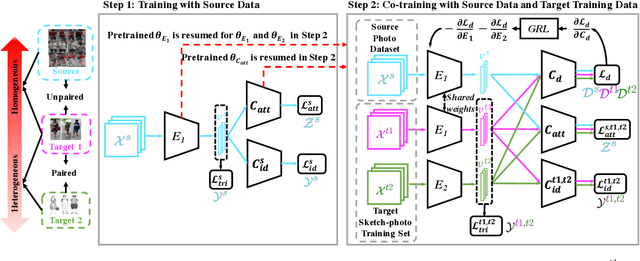

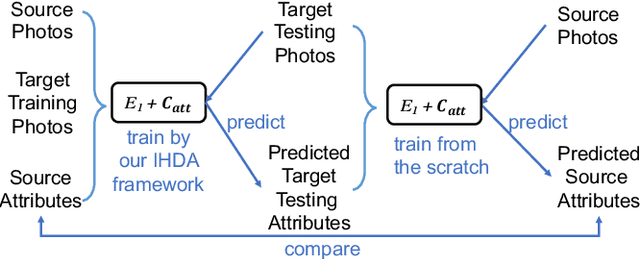
Although sketch-to-photo retrieval has a wide range of applications, it is costly to obtain paired and rich-labeled ground truth. Differently, photo retrieval data is easier to acquire. Therefore, previous works pre-train their models on rich-labeled photo retrieval data (i.e., source domain) and then fine-tune them on the limited-labeled sketch-to-photo retrieval data (i.e., target domain). However, without co-training source and target data, source domain knowledge might be forgotten during the fine-tuning process, while simply co-training them may cause negative transfer due to domain gaps. Moreover, identity label spaces of source data and target data are generally disjoint and therefore conventional category-level Domain Adaptation (DA) is not directly applicable. To address these issues, we propose an Instance-level Heterogeneous Domain Adaptation (IHDA) framework. We apply the fine-tuning strategy for identity label learning, aiming to transfer the instance-level knowledge in an inductive transfer manner. Meanwhile, labeled attributes from the source data are selected to form a shared label space for source and target domains. Guided by shared attributes, DA is utilized to bridge cross-dataset domain gaps and heterogeneous domain gaps, which transfers instance-level knowledge in a transductive transfer manner. Experiments show that our method has set a new state of the art on three sketch-to-photo image retrieval benchmarks without extra annotations, which opens the door to train more effective models on limited-labeled heterogeneous image retrieval tasks. Related codes are available at https://github.com/fandulu/IHDA.
Strata-NeRF : Neural Radiance Fields for Stratified Scenes
Aug 20, 2023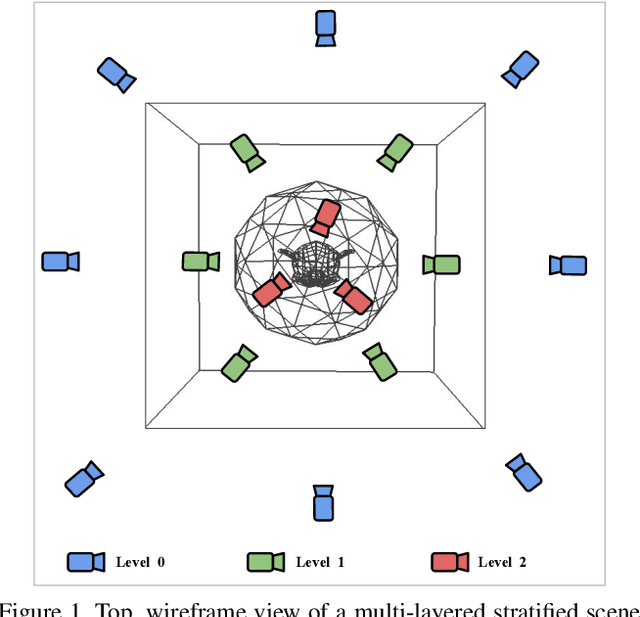
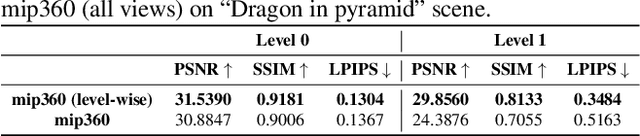

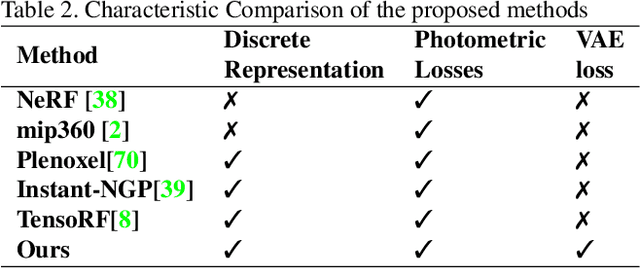
Neural Radiance Field (NeRF) approaches learn the underlying 3D representation of a scene and generate photo-realistic novel views with high fidelity. However, most proposed settings concentrate on modelling a single object or a single level of a scene. However, in the real world, we may capture a scene at multiple levels, resulting in a layered capture. For example, tourists usually capture a monument's exterior structure before capturing the inner structure. Modelling such scenes in 3D with seamless switching between levels can drastically improve immersive experiences. However, most existing techniques struggle in modelling such scenes. We propose Strata-NeRF, a single neural radiance field that implicitly captures a scene with multiple levels. Strata-NeRF achieves this by conditioning the NeRFs on Vector Quantized (VQ) latent representations which allow sudden changes in scene structure. We evaluate the effectiveness of our approach in multi-layered synthetic dataset comprising diverse scenes and then further validate its generalization on the real-world RealEstate10K dataset. We find that Strata-NeRF effectively captures stratified scenes, minimizes artifacts, and synthesizes high-fidelity views compared to existing approaches.