 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Semantically-aware Mask CycleGAN for Translating Artistic Portraits to Photo-realistic Visualizations
Jun 11, 2023


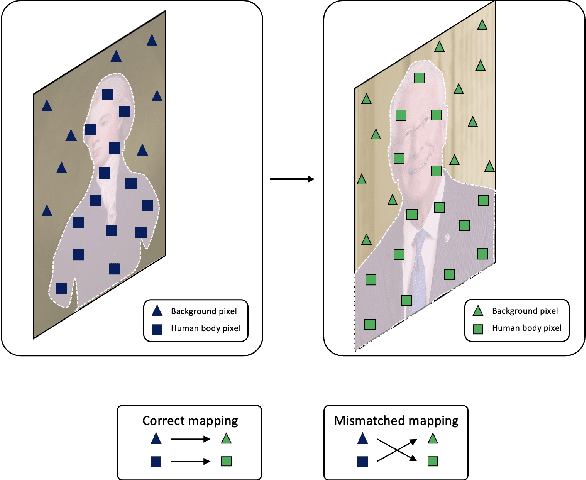

Image-to-image translation (I2I) is defined as a computer vision task where the aim is to transfer images in a source domain to a target domain with minimal loss or alteration of the content representations. Major progress has been made since I2I was proposed with the invention of a variety of revolutionary generative models. Among them, GAN-based models perform exceptionally well as they are mostly tailor-made for specific domains or tasks. However, few works proposed a tailor-made method for the artistic domain. In this project, I propose the Semantic-aware Mask CycleGAN (SMCycleGAN) architecture which can translate artistic portraits to photo-realistic visualizations. This model can generate realistic human portraits by feeding the discriminators semantically masked fake samples, thus enforcing them to make discriminative decisions with partial information so that the generators can be optimized to synthesize more realistic human portraits instead of increasing the similarity of other irrelevant components, such as the background. Experiments have shown that the SMCycleGAN generate images with significantly increased realism and minimal loss of content representations.
GETAvatar: Generative Textured Meshes for Animatable Human Avatars
Oct 04, 2023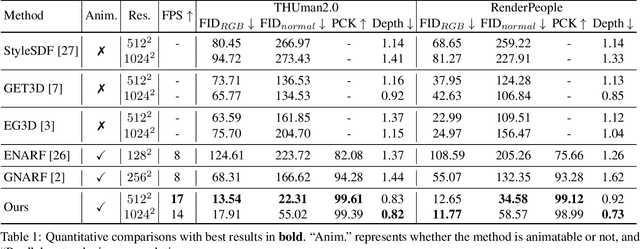
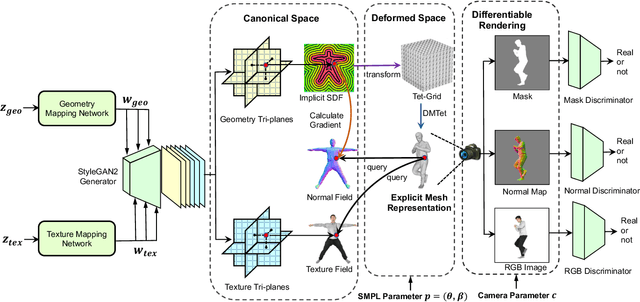
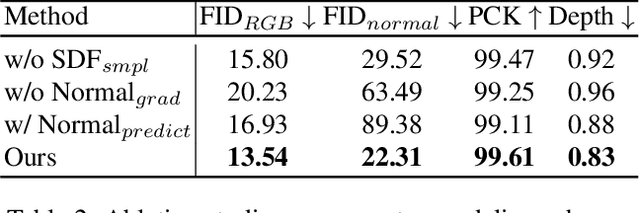

We study the problem of 3D-aware full-body human generation, aiming at creating animatable human avatars with high-quality textures and geometries. Generally, two challenges remain in this field: i) existing methods struggle to generate geometries with rich realistic details such as the wrinkles of garments; ii) they typically utilize volumetric radiance fields and neural renderers in the synthesis process, making high-resolution rendering non-trivial. To overcome these problems, we propose GETAvatar, a Generative model that directly generates Explicit Textured 3D meshes for animatable human Avatar, with photo-realistic appearance and fine geometric details. Specifically, we first design an articulated 3D human representation with explicit surface modeling, and enrich the generated humans with realistic surface details by learning from the 2D normal maps of 3D scan data. Second, with the explicit mesh representation, we can use a rasterization-based renderer to perform surface rendering, allowing us to achieve high-resolution image generation efficiently. Extensive experiments demonstrate that GETAvatar achieves state-of-the-art performance on 3D-aware human generation both in appearance and geometry quality. Notably, GETAvatar can generate images at 512x512 resolution with 17FPS and 1024x1024 resolution with 14FPS, improving upon previous methods by 2x. Our code and models will be available.
A Framework for Fast Prototyping of Photo-realistic Environments with Multiple Pedestrians
Apr 14, 2023
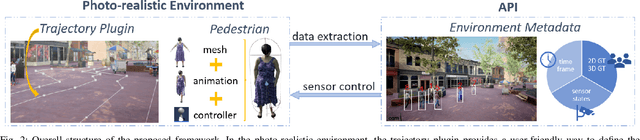
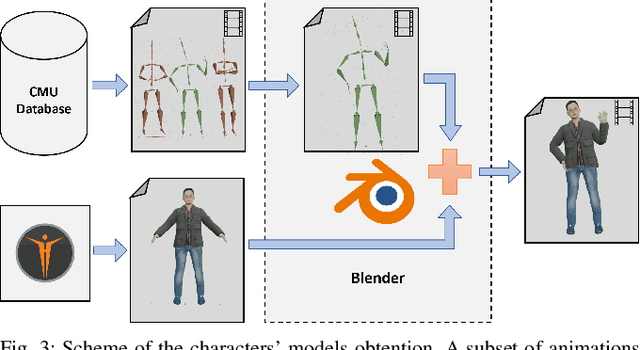
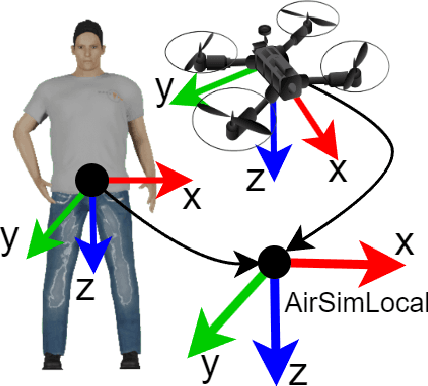
Robotic applications involving people often require advanced perception systems to better understand complex real-world scenarios. To address this challenge, photo-realistic and physics simulators are gaining popularity as a means of generating accurate data labeling and designing scenarios for evaluating generalization capabilities, e.g., lighting changes, camera movements or different weather conditions. We develop a photo-realistic framework built on Unreal Engine and AirSim to generate easily scenarios with pedestrians and mobile robots. The framework is capable to generate random and customized trajectories for each person and provides up to 50 ready-to-use people models along with an API for their metadata retrieval. We demonstrate the usefulness of the proposed framework with a use case of multi-target tracking, a popular problem in real pedestrian scenarios. The notable feature variability in the obtained perception data is presented and evaluated.
Automatic Animation of Hair Blowing in Still Portrait Photos
Sep 25, 2023
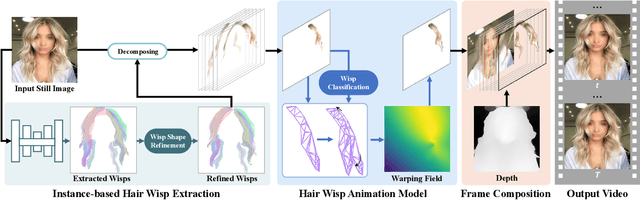

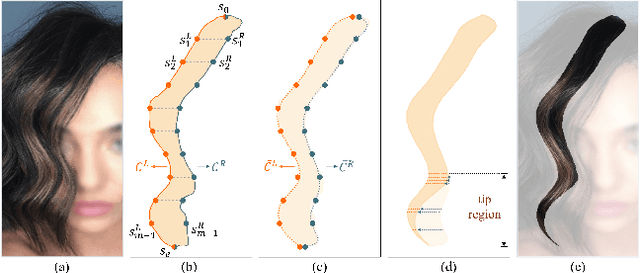
We propose a novel approach to animate human hair in a still portrait photo. Existing work has largely studied the animation of fluid elements such as water and fire. However, hair animation for a real image remains underexplored, which is a challenging problem, due to the high complexity of hair structure and dynamics. Considering the complexity of hair structure, we innovatively treat hair wisp extraction as an instance segmentation problem, where a hair wisp is referred to as an instance. With advanced instance segmentation networks, our method extracts meaningful and natural hair wisps. Furthermore, we propose a wisp-aware animation module that animates hair wisps with pleasing motions without noticeable artifacts. The extensive experiments show the superiority of our method. Our method provides the most pleasing and compelling viewing experience in the qualitative experiments and outperforms state-of-the-art still-image animation methods by a large margin in the quantitative evaluation. Project url: \url{https://nevergiveu.github.io/AutomaticHairBlowing/}
Drag View: Generalizable Novel View Synthesis with Unposed Imagery
Oct 05, 2023

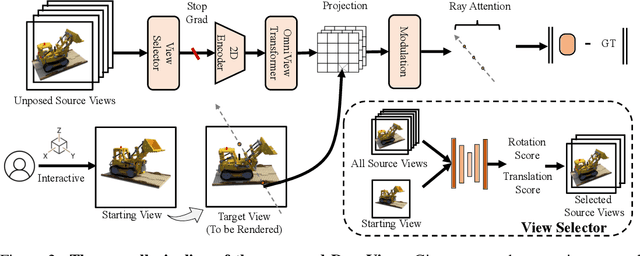
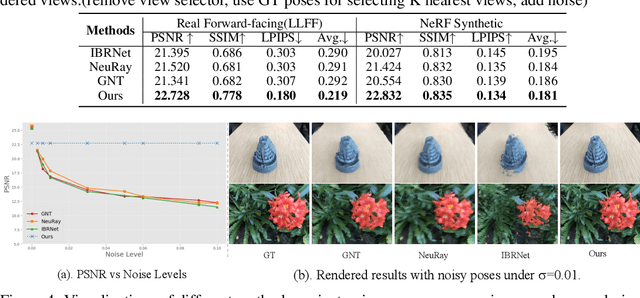
We introduce DragView, a novel and interactive framework for generating novel views of unseen scenes. DragView initializes the new view from a single source image, and the rendering is supported by a sparse set of unposed multi-view images, all seamlessly executed within a single feed-forward pass. Our approach begins with users dragging a source view through a local relative coordinate system. Pixel-aligned features are obtained by projecting the sampled 3D points along the target ray onto the source view. We then incorporate a view-dependent modulation layer to effectively handle occlusion during the projection. Additionally, we broaden the epipolar attention mechanism to encompass all source pixels, facilitating the aggregation of initialized coordinate-aligned point features from other unposed views. Finally, we employ another transformer to decode ray features into final pixel intensities. Crucially, our framework does not rely on either 2D prior models or the explicit estimation of camera poses. During testing, DragView showcases the capability to generalize to new scenes unseen during training, also utilizing only unposed support images, enabling the generation of photo-realistic new views characterized by flexible camera trajectories. In our experiments, we conduct a comprehensive comparison of the performance of DragView with recent scene representation networks operating under pose-free conditions, as well as with generalizable NeRFs subject to noisy test camera poses. DragView consistently demonstrates its superior performance in view synthesis quality, while also being more user-friendly. Project page: https://zhiwenfan.github.io/DragView/.
OceanChat: Piloting Autonomous Underwater Vehicles in Natural Language
Sep 27, 2023
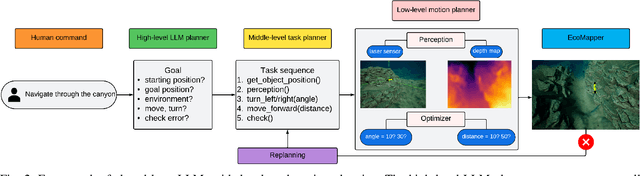


In the trending research of fusing Large Language Models (LLMs) and robotics, we aim to pave the way for innovative development of AI systems that can enable Autonomous Underwater Vehicles (AUVs) to seamlessly interact with humans in an intuitive manner. We propose OceanChat, a system that leverages a closed-loop LLM-guided task and motion planning framework to tackle AUV missions in the wild. LLMs translate an abstract human command into a high-level goal, while a task planner further grounds the goal into a task sequence with logical constraints. To assist the AUV with understanding the task sequence, we utilize a motion planner to incorporate real-time Lagrangian data streams received by the AUV, thus mapping the task sequence into an executable motion plan. Considering the highly dynamic and partially known nature of the underwater environment, an event-triggered replanning scheme is developed to enhance the system's robustness towards uncertainty. We also build a simulation platform HoloEco that generates photo-realistic simulation for a wide range of AUV applications. Experimental evaluation verifies that the proposed system can achieve improved performance in terms of both success rate and computation time. Project website: \url{https://sites.google.com/view/oceanchat}
RenderIH: A Large-scale Synthetic Dataset for 3D Interacting Hand Pose Estimation
Sep 27, 2023
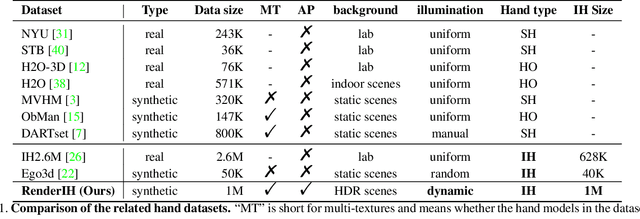

The current interacting hand (IH) datasets are relatively simplistic in terms of background and texture, with hand joints being annotated by a machine annotator, which may result in inaccuracies, and the diversity of pose distribution is limited. However, the variability of background, pose distribution, and texture can greatly influence the generalization ability. Therefore, we present a large-scale synthetic dataset RenderIH for interacting hands with accurate and diverse pose annotations. The dataset contains 1M photo-realistic images with varied backgrounds, perspectives, and hand textures. To generate natural and diverse interacting poses, we propose a new pose optimization algorithm. Additionally, for better pose estimation accuracy, we introduce a transformer-based pose estimation network, TransHand, to leverage the correlation between interacting hands and verify the effectiveness of RenderIH in improving results. Our dataset is model-agnostic and can improve more accuracy of any hand pose estimation method in comparison to other real or synthetic datasets. Experiments have shown that pretraining on our synthetic data can significantly decrease the error from 6.76mm to 5.79mm, and our Transhand surpasses contemporary methods. Our dataset and code are available at https://github.com/adwardlee/RenderIH.
Detecting internal disorders in fruit by CT. Part 1: Joint 2D to 3D image registration workflow for comparing multiple slice photographs and CT scans of apple fruit
Oct 03, 2023A large percentage of apples are affected by internal disorders after long-term storage, which makes them unacceptable in the supply chain. CT imaging is a promising technique for in-line detection of these disorders. Therefore, it is crucial to understand how different disorders affect the image features that can be observed in CT scans. This paper presents a workflow for creating datasets of image pairs of photographs of apple slices and their corresponding CT slices. By having CT and photographic images of the same part of the apple, the complementary information in both images can be used to study the processes underlying internal disorders and how internal disorders can be measured in CT images. The workflow includes data acquisition, image segmentation, image registration, and validation methods. The image registration method aligns all available slices of an apple within a single optimization problem, assuming that the slices are parallel. This method outperformed optimizing the alignment separately for each slice. The workflow was applied to create a dataset of 1347 slice photographs and their corresponding CT slices. The dataset was acquired from 107 'Kanzi' apples that had been stored in controlled atmosphere (CA) storage for 8 months. In this dataset, the distance between annotations in the slice photograph and the matching CT slice was, on average, $1.47 \pm 0.40$ mm. Our workflow allows collecting large datasets of accurately aligned photo-CT image pairs, which can help distinguish internal disorders with a similar appearance on CT. With slight modifications, a similar workflow can be applied to other fruits or MRI instead of CT scans.
IFT: Image Fusion Transformer for Ghost-free High Dynamic Range Imaging
Sep 26, 2023Multi-frame high dynamic range (HDR) imaging aims to reconstruct ghost-free images with photo-realistic details from content-complementary but spatially misaligned low dynamic range (LDR) images. Existing HDR algorithms are prone to producing ghosting artifacts as their methods fail to capture long-range dependencies between LDR frames with large motion in dynamic scenes. To address this issue, we propose a novel image fusion transformer, referred to as IFT, which presents a fast global patch searching (FGPS) module followed by a self-cross fusion module (SCF) for ghost-free HDR imaging. The FGPS searches the patches from supporting frames that have the closest dependency to each patch of the reference frame for long-range dependency modeling, while the SCF conducts intra-frame and inter-frame feature fusion on the patches obtained by the FGPS with linear complexity to input resolution. By matching similar patches between frames, objects with large motion ranges in dynamic scenes can be aligned, which can effectively alleviate the generation of artifacts. In addition, the proposed FGPS and SCF can be integrated into various deep HDR methods as efficient plug-in modules. Extensive experiments on multiple benchmarks show that our method achieves state-of-the-art performance both quantitatively and qualitatively.
ExBluRF: Efficient Radiance Fields for Extreme Motion Blurred Images
Sep 21, 2023

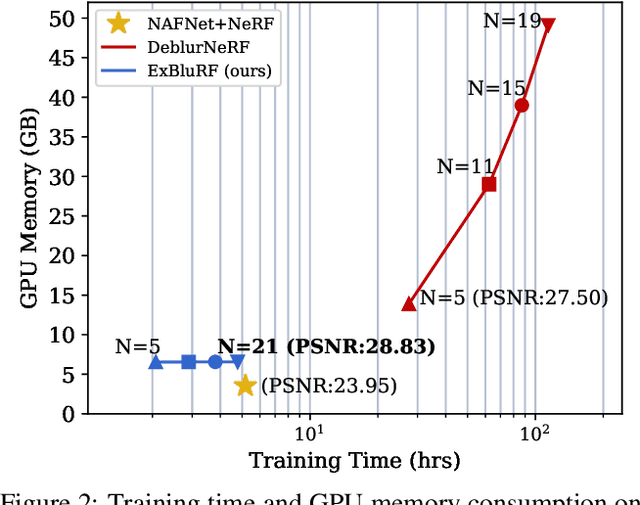
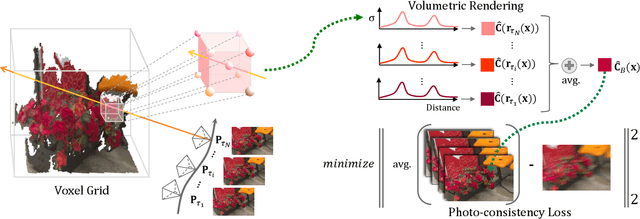
We present ExBluRF, a novel view synthesis method for extreme motion blurred images based on efficient radiance fields optimization. Our approach consists of two main components: 6-DOF camera trajectory-based motion blur formulation and voxel-based radiance fields. From extremely blurred images, we optimize the sharp radiance fields by jointly estimating the camera trajectories that generate the blurry images. In training, multiple rays along the camera trajectory are accumulated to reconstruct single blurry color, which is equivalent to the physical motion blur operation. We minimize the photo-consistency loss on blurred image space and obtain the sharp radiance fields with camera trajectories that explain the blur of all images. The joint optimization on the blurred image space demands painfully increasing computation and resources proportional to the blur size. Our method solves this problem by replacing the MLP-based framework to low-dimensional 6-DOF camera poses and voxel-based radiance fields. Compared with the existing works, our approach restores much sharper 3D scenes from challenging motion blurred views with the order of 10 times less training time and GPU memory consumption.