 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Cycle In Cycle Generative Adversarial Networks for Keypoint-Guided Image Generation
Sep 14, 2019

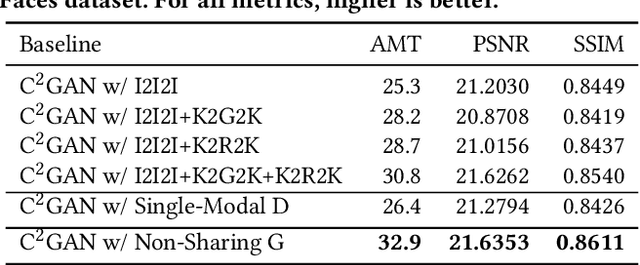
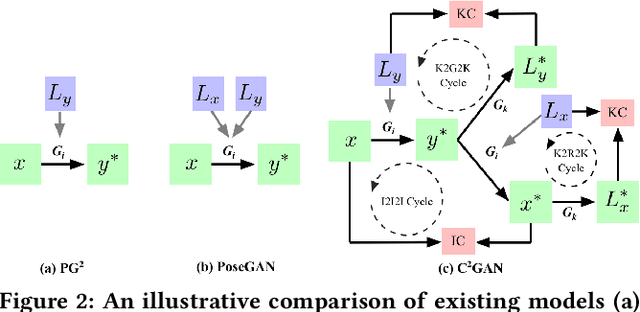
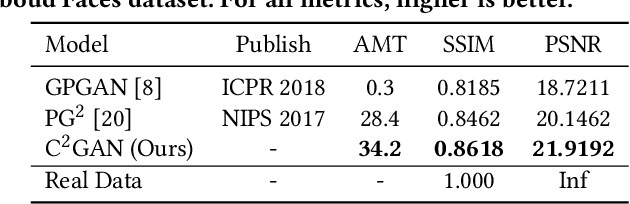
In this work, we propose a novel Cycle In Cycle Generative Adversarial Network (C$^2$GAN) for the task of keypoint-guided image generation. The proposed C$^2$GAN is a cross-modal framework exploring a joint exploitation of the keypoint and the image data in an interactive manner. C$^2$GAN contains two different types of generators, i.e., keypoint-oriented generator and image-oriented generator. Both of them are mutually connected in an end-to-end learnable fashion and explicitly form three cycled sub-networks, i.e., one image generation cycle and two keypoint generation cycles. Each cycle not only aims at reconstructing the input domain, and also produces useful output involving in the generation of another cycle. By so doing, the cycles constrain each other implicitly, which provides complementary information from the two different modalities and brings extra supervision across cycles, thus facilitating more robust optimization of the whole network. Extensive experimental results on two publicly available datasets, i.e., Radboud Faces and Market-1501, demonstrate that our approach is effective to generate more photo-realistic images compared with state-of-the-art models.
* 9 pages, 8 figures, accepted to ACM MM 2019
Do GANs leave artificial fingerprints?
Dec 31, 2018

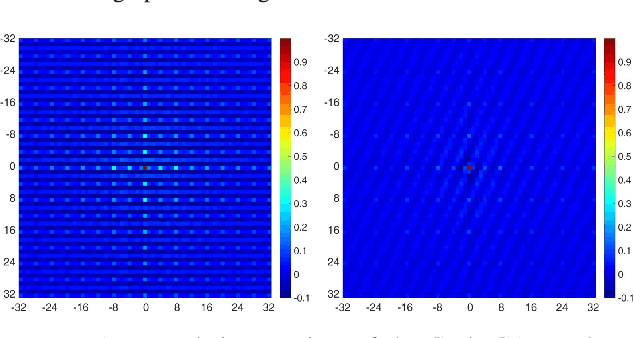
In the last few years, generative adversarial networks (GAN) have shown tremendous potential for a number of applications in computer vision and related fields. With the current pace of progress, it is a sure bet they will soon be able to generate high-quality images and videos, virtually indistinguishable from real ones. Unfortunately, realistic GAN-generated images pose serious threats to security, to begin with a possible flood of fake multimedia, and multimedia forensic countermeasures are in urgent need. In this work, we show that each GAN leaves its specific fingerprint in the images it generates, just like real-world cameras mark acquired images with traces of their photo-response non-uniformity pattern. Source identification experiments with several popular GANs show such fingerprints to represent a precious asset for forensic analyses.
A Novel Method for Vectorization
Mar 04, 2014


Vectorization of images is a key concern uniting computer graphics and computer vision communities. In this paper we are presenting a novel idea for efficient, customizable vectorization of raster images, based on Catmull Rom spline fitting. The algorithm maintains a good balance between photo-realism and photo abstraction, and hence is applicable to applications with artistic concerns or applications where less information loss is crucial. The resulting algorithm is fast, parallelizable and can satisfy general soft realtime requirements. Moreover, the smoothness of the vectorized images aesthetically outperforms outputs of many polygon-based methods
SurReal: enhancing Surgical simulation Realism using style transfer
Nov 07, 2018

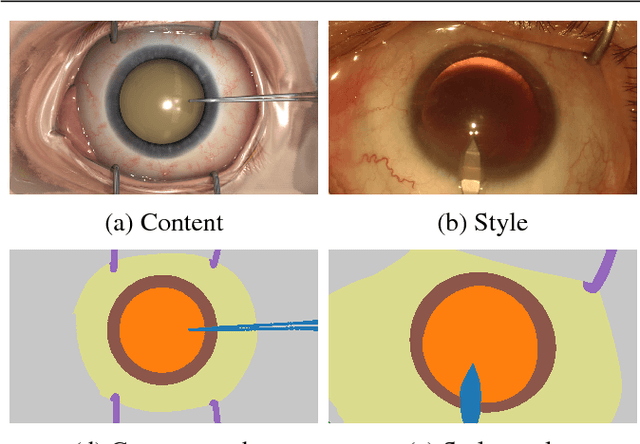

Surgical simulation is an increasingly important element of surgical education. Using simulation can be a means to address some of the significant challenges in developing surgical skills with limited time and resources. The photo-realistic fidelity of simulations is a key feature that can improve the experience and transfer ratio of trainees. In this paper, we demonstrate how we can enhance the visual fidelity of existing surgical simulation by performing style transfer of multi-class labels from real surgical video onto synthetic content. We demonstrate our approach on simulations of cataract surgery using real data labels from an existing public dataset. Our results highlight the feasibility of the approach and also the powerful possibility to extend this technique to incorporate additional temporal constraints and to different applications.
Head Reconstruction from Internet Photos
Sep 13, 2018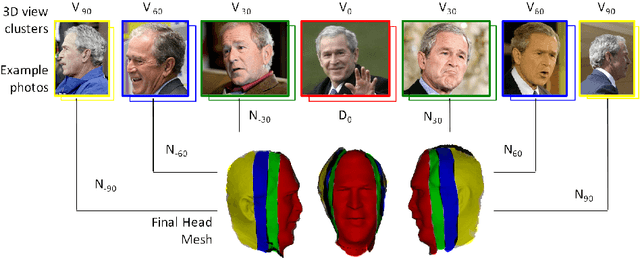
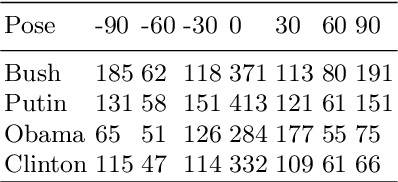


3D face reconstruction from Internet photos has recently produced exciting results. A person's face, e.g., Tom Hanks, can be modeled and animated in 3D from a completely uncalibrated photo collection. Most methods, however, focus solely on face area and mask out the rest of the head. This paper proposes that head modeling from the Internet is a problem we can solve. We target reconstruction of the rough shape of the head. Our method is to gradually "grow" the head mesh starting from the frontal face and extending to the rest of views using photometric stereo constraints. We call our method boundary-value growing algorithm. Results on photos of celebrities downloaded from the Internet are presented.
DeepRacing: Parameterized Trajectories for Autonomous Racing
May 06, 2020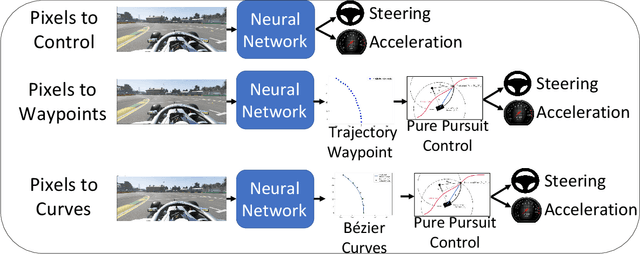
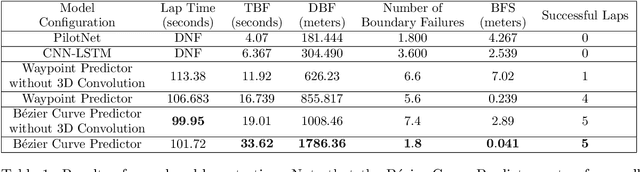
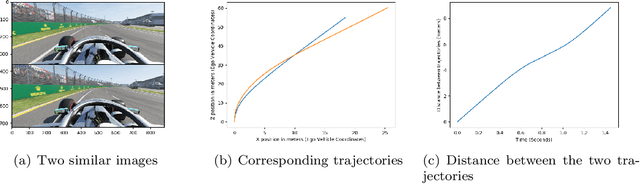
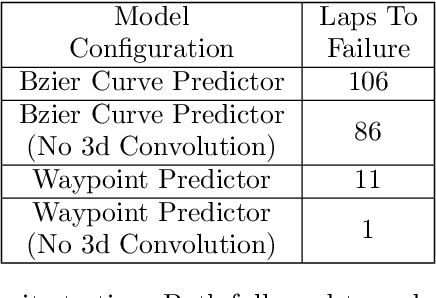
We consider the challenging problem of high speed autonomous racing in a realistic Formula One environment. DeepRacing is a novel end-to-end framework, and a virtual testbed for training and evaluating algorithms for autonomous racing. The virtual testbed is implemented using the realistic F1 series of video games, developed by Codemasters, which many Formula One drivers use for training. This virtual testbed is released under an open-source license both as a standalone C++ API and as a binding to the popular Robot Operating System 2 (ROS2) framework. This open-source API allows anyone to use the high fidelity physics and photo-realistic capabilities of the F1 game as a simulator, and without hacking any game engine code. We use this framework to evaluate several neural network methodologies for autonomous racing. Specifically, we consider several fully end-to-end models that directly predict steering and acceleration commands for an autonomous race car as well as a model that predicts a list of waypoints to follow in the car's local coordinate system, with the task of selecting a steering/throttle angle left to a classical control algorithm. We also present a novel method of autonomous racing by training a deep neural network to predict a parameterized representation of a trajectory rather than a list of waypoints. We evaluate these models performance in our open-source simulator and show that trajectory prediction far outperforms end-to-end driving. Additionally, we show that open-loop performance for an end-to-end model, i.e. root-mean-square error for a model's predicted control values, does not necessarily correlate with increased driving performance in the closed-loop sense, i.e. actual ability to race around a track. Finally, we show that our proposed model of parameterized trajectory prediction outperforms both end-to-end control and waypoint prediction.
Im2Pencil: Controllable Pencil Illustration from Photographs
Mar 20, 2019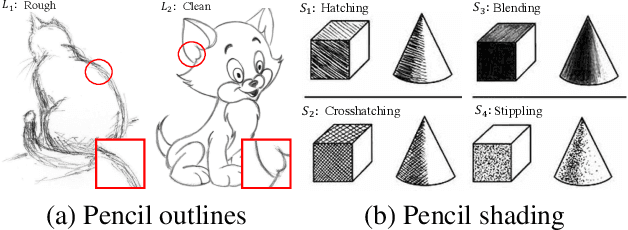


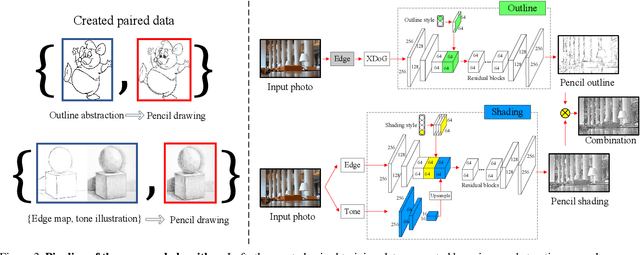
We propose a high-quality photo-to-pencil translation method with fine-grained control over the drawing style. This is a challenging task due to multiple stroke types (e.g., outline and shading), structural complexity of pencil shading (e.g., hatching), and the lack of aligned training data pairs. To address these challenges, we develop a two-branch model that learns separate filters for generating sketchy outlines and tonal shading from a collection of pencil drawings. We create training data pairs by extracting clean outlines and tonal illustrations from original pencil drawings using image filtering techniques, and we manually label the drawing styles. In addition, our model creates different pencil styles (e.g., line sketchiness and shading style) in a user-controllable manner. Experimental results on different types of pencil drawings show that the proposed algorithm performs favorably against existing methods in terms of quality, diversity and user evaluations.
ELF: Embedded Localisation of Features in pre-trained CNN
Jul 07, 2019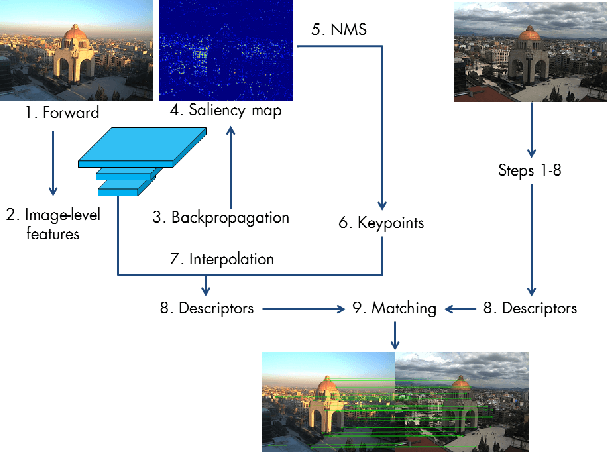
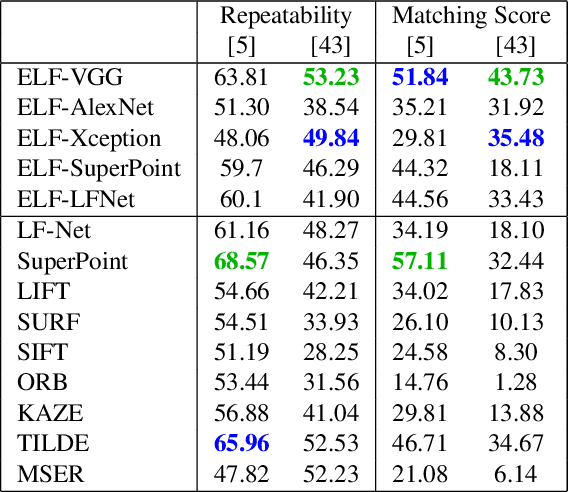

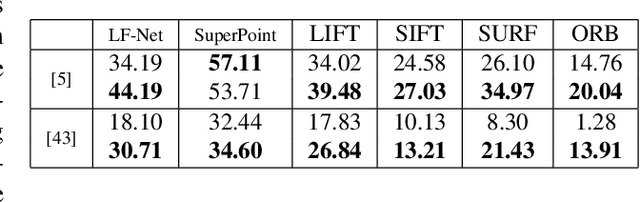
This paper introduces a novel feature detector based only on information embedded inside a CNN trained on standard tasks (e.g. classification). While previous works already show that the features of a trained CNN are suitable descriptors, we show here how to extract the feature locations from the network to build a detector. This information is computed from the gradient of the feature map with respect to the input image. This provides a saliency map with local maxima on relevant keypoint locations. Contrary to recent CNN-based detectors, this method requires neither supervised training nor finetuning. We evaluate how repeatable and how matchable the detected keypoints are with the repeatability and matching scores. Matchability is measured with a simple descriptor introduced for the sake of the evaluation. This novel detector reaches similar performances on the standard evaluation HPatches dataset, as well as comparable robustness against illumination and viewpoint changes on Webcam and photo-tourism images. These results show that a CNN trained on a standard task embeds feature location information that is as relevant as when the CNN is specifically trained for feature detection.
On the Role of Event Boundaries in Egocentric Activity Recognition from Photostreams
Sep 06, 2018
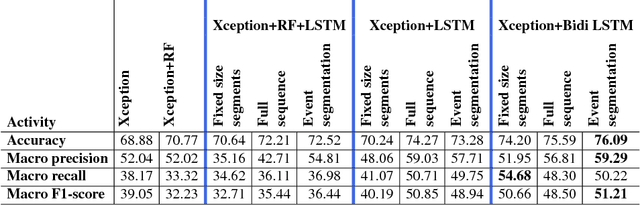

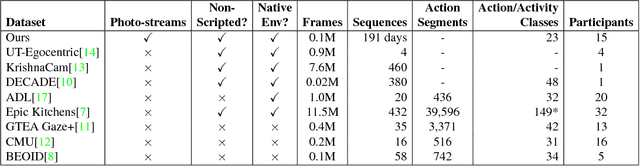
Event boundaries play a crucial role as a pre-processing step for detection, localization, and recognition tasks of human activities in videos. Typically, although their intrinsic subjectiveness, temporal bounds are provided manually as input for training action recognition algorithms. However, their role for activity recognition in the domain of egocentric photostreams has been so far neglected. In this paper, we provide insights of how automatically computed boundaries can impact activity recognition results in the emerging domain of egocentric photostreams. Furthermore, we collected a new annotated dataset acquired by 15 people by a wearable photo-camera and we used it to show the generalization capabilities of several deep learning based architectures to unseen users.
ClsGAN: Selective Attribute Editing Based On Classification Adversarial Network
Oct 25, 2019

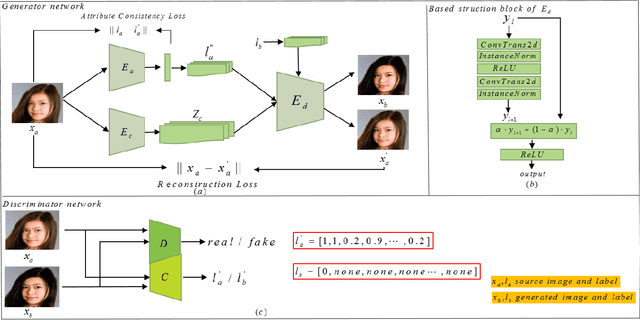

Attribution editing has shown remarking progress by the incorporating of encoder-decoder structure and generative adversarial network. However, there are still some challenges in the quality and attribute transformation of the generated images. Encoder-decoder structure leads to blurring of images and the skip-connection of encoder-decoder structure weakens the attribute transfer ability. To address these limitations, we propose a classification adversarial model(Cls-GAN) that can balance between attribute transfer and generated photo-realistic images. Considering that the transfer images are affected by the original attribute using skip-connection, we introduce upper convolution residual network(Tr-resnet) to selectively extract information from the source image and target label. Specially, we apply to the attribute classification adversarial network to learn about the defects of attribute transfer images so as to guide the generator. Finally, to meet the requirement of multimodal and improve reconstruction effect, we build two encoders including the content and style network, and select a attribute label approximation between source label and the output of style network. Experiments that operates at the dataset of CelebA show that images are superiority against the existing state-of-the-art models in image quality and transfer accuracy. Experiments on wikiart and seasonal datasets demonstrate that ClsGAN can effectively implement styel transfer.