 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Deep Video Color Propagation
Aug 09, 2018

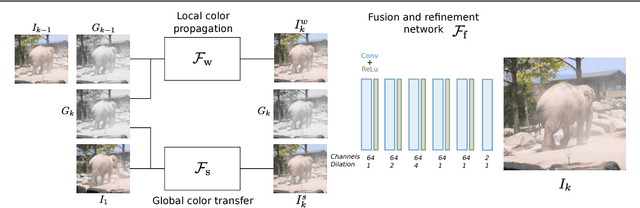
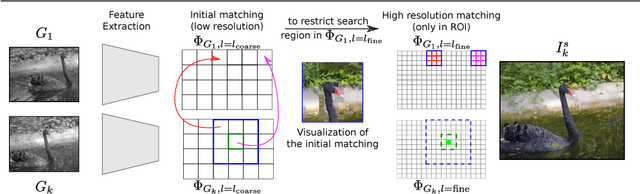

Traditional approaches for color propagation in videos rely on some form of matching between consecutive video frames. Using appearance descriptors, colors are then propagated both spatially and temporally. These methods, however, are computationally expensive and do not take advantage of semantic information of the scene. In this work we propose a deep learning framework for color propagation that combines a local strategy, to propagate colors frame-by-frame ensuring temporal stability, and a global strategy, using semantics for color propagation within a longer range. Our evaluation shows the superiority of our strategy over existing video and image color propagation methods as well as neural photo-realistic style transfer approaches.
What Will Your Child Look Like? DNA-Net: Age and Gender Aware Kin Face Synthesizer
Nov 16, 2019
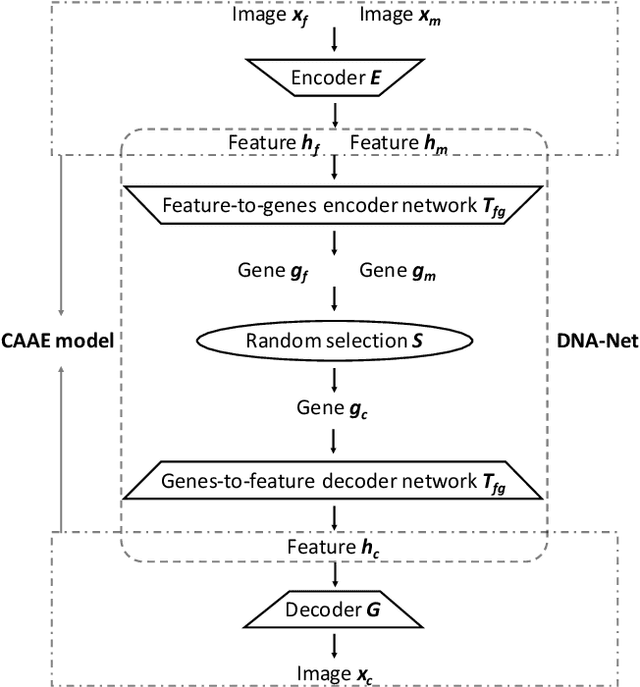
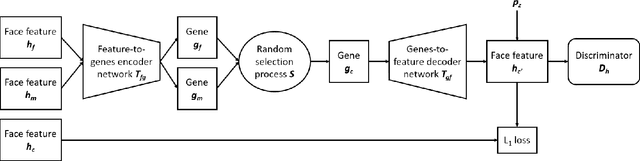

Visual kinship recognition aims to identify blood relatives from facial images. Its practical application-- like in law-enforcement, video surveillance, automatic family album management, and more-- has motivated many researchers to put forth effort on the topic as of recent. In this paper, we focus on a new view of visual kinship technology: kin-based face generation. Specifically, we propose a two-stage kin-face generation model to predict the appearance of a child given a pair of parents. The first stage includes a deep generative adversarial autoencoder conditioned on ages and genders to map between facial appearance and high-level features. The second stage is our proposed DNA-Net, which serves as a transformation between the deep and genetic features based on a random selection process to fuse genes of a parent pair to form the genes of a child. We demonstrate the effectiveness of the proposed method quantitatively and qualitatively: quantitatively, pre-trained models and human subjects perform kinship verification on the generated images of children; qualitatively, we show photo-realistic face images of children that closely resemble the given pair of parents. In the end, experiments validate that the proposed model synthesizes convincing kin-faces using both subjective and objective standards.
Attribute-Guided Deep Polarimetric Thermal-to-visible Face Recognition
Jul 27, 2019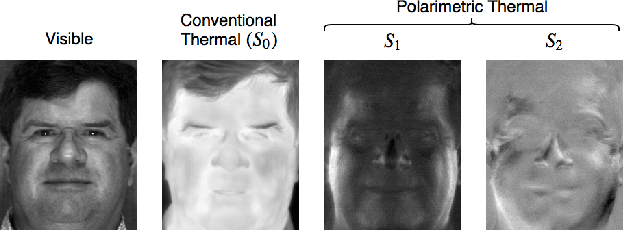
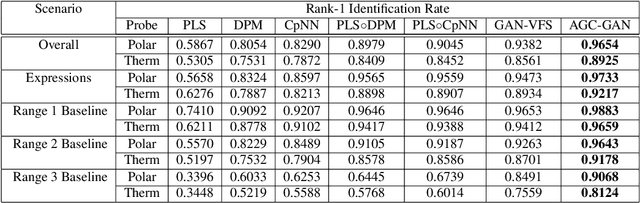
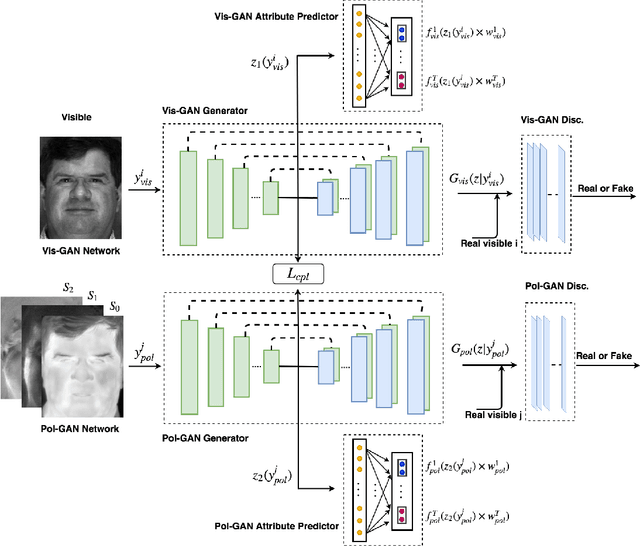

In this paper, we present an attribute-guided deep coupled learning framework to address the problem of matching polarimetric thermal face photos against a gallery of visible faces. The coupled framework contains two sub-networks, one dedicated to the visible spectrum and the second sub-network dedicated to the polarimetric thermal spectrum. Each sub-network is made of a generative adversarial network (GAN) architecture. We propose a novel Attribute-Guided Coupled Generative Adversarial Network (AGC-GAN) architecture which utilizes facial attributes to improve the thermal-to-visible face recognition performance. The proposed AGC-GAN exploits the facial attributes and leverages multiple loss functions in order to learn rich discriminative features in a common embedding subspace. To achieve a realistic photo reconstruction while preserving the discriminative information, we also add a perceptual loss term to the coupling loss function. An ablation study is performed to show the effectiveness of different loss functions for optimizing the proposed method. Moreover, the superiority of the model compared to the state-of-the-art models is demonstrated using polarimetric dataset.
Human Synthesis and Scene Compositing
Sep 23, 2019



Generating good quality and geometrically plausible synthetic images of humans with the ability to control appearance, pose and shape parameters, has become increasingly important for a variety of tasks ranging from photo editing, fashion virtual try-on, to special effects and image compression. In this paper, we propose HUSC, a HUman Synthesis and Scene Compositing framework for the realistic synthesis of humans with different appearance, in novel poses and scenes. Central to our formulation is 3d reasoning for both people and scenes, in order to produce realistic collages, by correctly modeling perspective effects and occlusion, by taking into account scene semantics and by adequately handling relative scales. Conceptually our framework consists of three components: (1) a human image synthesis model with controllable pose and appearance, based on a parametric representation, (2) a person insertion procedure that leverages the geometry and semantics of the 3d scene, and (3) an appearance compositing process to create a seamless blending between the colors of the scene and the generated human image, and avoid visual artifacts. The performance of our framework is supported by both qualitative and quantitative results, in particular state-of-the art synthesis scores for the DeepFashion dataset.
Face Hallucination with Finishing Touches
Feb 09, 2020



Obtaining a high-quality frontal face image from a low-resolution (LR) non-frontal face image is primarily important for many facial analysis applications. However, mainstreams either focus on super-resolving near-frontal LR faces or frontalizing non-frontal high-resolution (HR) faces. It is desirable to perform both tasks seamlessly for daily-life unconstrained face images. In this paper, we present a novel Vivid Face Hallucination Generative Adversarial Network (VividGAN) devised for simultaneously super-resolving and frontalizing tiny non-frontal face images. VividGAN consists of a Vivid Face Hallucination Network (Vivid-FHnet) and two discriminators, i.e., Coarse-D and Fine-D. The Vivid-FHnet first generates a coarse frontal HR face and then makes use of the structure prior, i.e., fine-grained facial components, to achieve a fine frontal HR face image. Specifically, we propose a facial component-aware module, which adopts the facial geometry guidance as clues to accurately align and merge the coarse frontal HR face and prior information. Meanwhile, the two-level discriminators are designed to capture both the global outline of the face as well as detailed facial characteristics. The Coarse-D enforces the coarse hallucinated faces to be upright and complete; while the Fine-D focuses on the fine hallucinated ones for sharper details. Extensive experiments demonstrate that our VividGAN achieves photo-realistic frontal HR faces, reaching superior performance in downstream tasks, i.e., face recognition and expression classification, compared with other state-of-the-art methods.
Neural Rerendering in the Wild
Apr 08, 2019
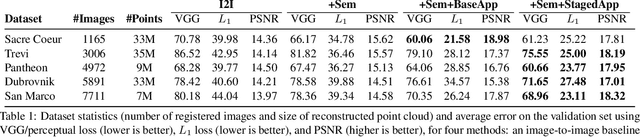

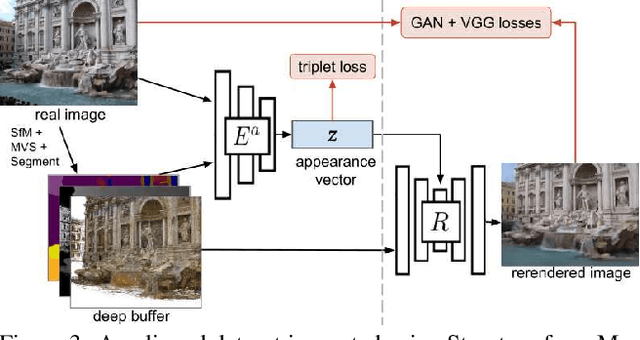
We explore total scene capture -- recording, modeling, and rerendering a scene under varying appearance such as season and time of day. Starting from internet photos of a tourist landmark, we apply traditional 3D reconstruction to register the photos and approximate the scene as a point cloud. For each photo, we render the scene points into a deep framebuffer, and train a neural network to learn the mapping of these initial renderings to the actual photos. This rerendering network also takes as input a latent appearance vector and a semantic mask indicating the location of transient objects like pedestrians. The model is evaluated on several datasets of publicly available images spanning a broad range of illumination conditions. We create short videos demonstrating realistic manipulation of the image viewpoint, appearance, and semantic labeling. We also compare results with prior work on scene reconstruction from internet photos.
Machine learning enables long time scale molecular photodynamics simulations
Nov 22, 2018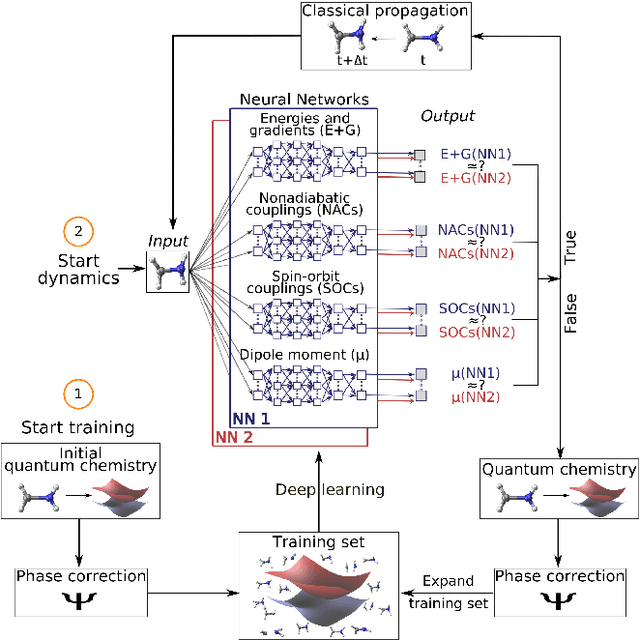
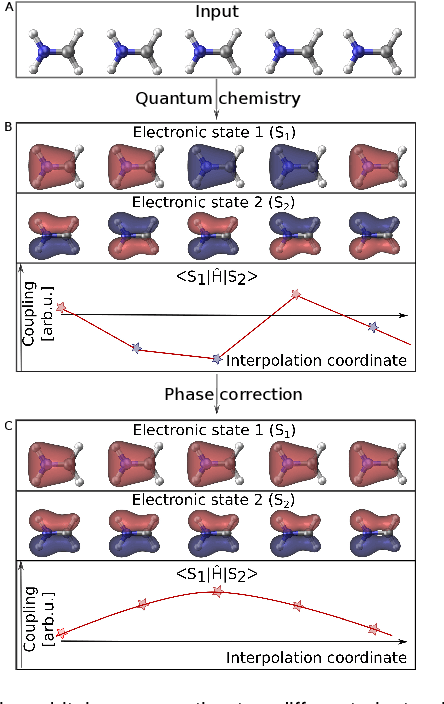
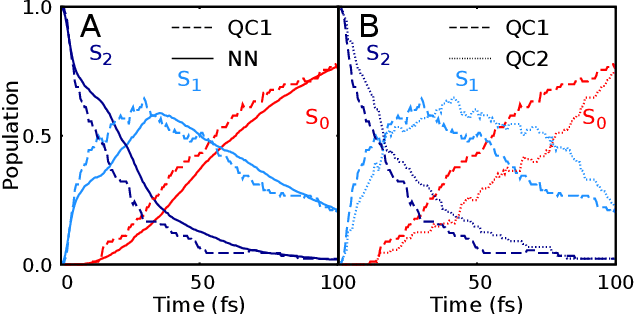
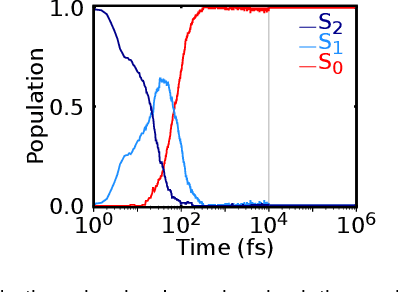
Photo-induced processes are fundamental in nature, but accurate simulations are seriously limited by the cost of the underlying quantum chemical calculations, hampering their application for long time scales. Here we introduce a method based on machine learning to overcome this bottleneck and enable accurate photodynamics on nanosecond time scales, which are otherwise out of reach with contemporary approaches. Instead of expensive quantum chemistry during molecular dynamics simulations, we use deep neural networks to learn the relationship between a molecular geometry and its high-dimensional electronic properties. As an example, the time evolution of the methylenimmonium cation for one nanosecond is used to demonstrate that machine learning algorithms can outperform standard excited-state molecular dynamics approaches in their computational efficiency while delivering the same accuracy.
Monocular Plan View Networks for Autonomous Driving
May 16, 2019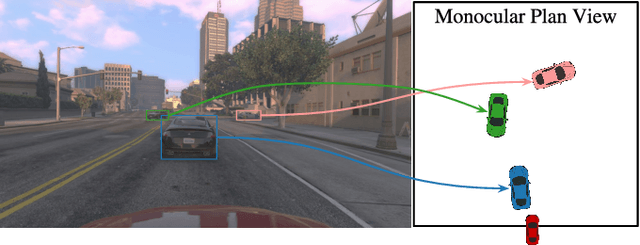

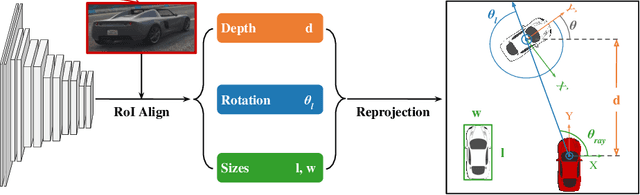
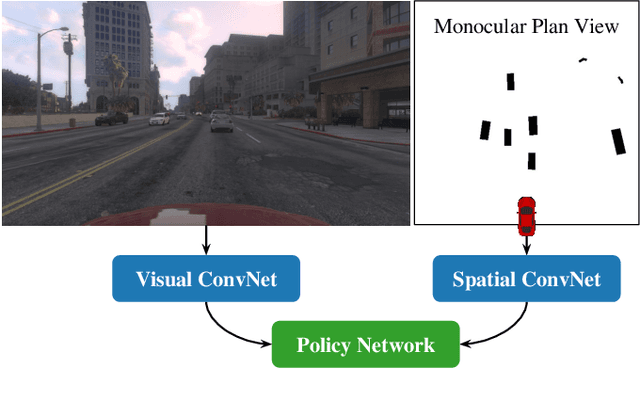
Convolutions on monocular dash cam videos capture spatial invariances in the image plane but do not explicitly reason about distances and depth. We propose a simple transformation of observations into a bird's eye view, also known as plan view, for end-to-end control. We detect vehicles and pedestrians in the first person view and project them into an overhead plan view. This representation provides an abstraction of the environment from which a deep network can easily deduce the positions and directions of entities. Additionally, the plan view enables us to leverage advances in 3D object detection in conjunction with deep policy learning. We evaluate our monocular plan view network on the photo-realistic Grand Theft Auto V simulator. A network using both a plan view and front view causes less than half as many collisions as previous detection-based methods and an order of magnitude fewer collisions than pure pixel-based policies.
Sacrificing information for the greater good: how to select photometric bands for optimal accuracy
Jul 06, 2016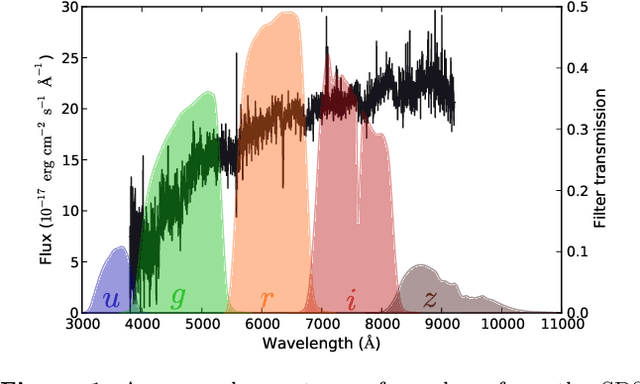

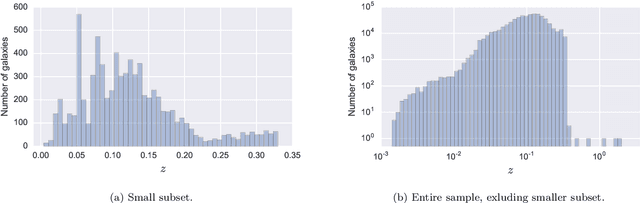
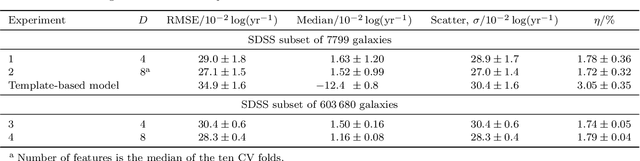
Large-scale surveys make huge amounts of photometric data available. Because of the sheer amount of objects, spectral data cannot be obtained for all of them. Therefore it is important to devise techniques for reliably estimating physical properties of objects from photometric information alone. These estimates are needed to automatically identify interesting objects worth a follow-up investigation as well as to produce the required data for a statistical analysis of the space covered by a survey. We argue that machine learning techniques are suitable to compute these estimates accurately and efficiently. This study promotes a feature selection algorithm, which selects the most informative magnitudes and colours for a given task of estimating physical quantities from photometric data alone. Using k nearest neighbours regression, a well-known non-parametric machine learning method, we show that using the found features significantly increases the accuracy of the estimations compared to using standard features and standard methods. We illustrate the usefulness of the approach by estimating specific star formation rates (sSFRs) and redshifts (photo-z's) using only the broad-band photometry from the Sloan Digital Sky Survey (SDSS). For estimating sSFRs, we demonstrate that our method produces better estimates than traditional spectral energy distribution (SED) fitting. For estimating photo-z's, we show that our method produces more accurate photo-z's than the method employed by SDSS. The study highlights the general importance of performing proper model selection to improve the results of machine learning systems and how feature selection can provide insights into the predictive relevance of particular input features.
PoshakNet: Framework for matching dresses from real-life photos using GAN and Siamese Network
Nov 11, 2019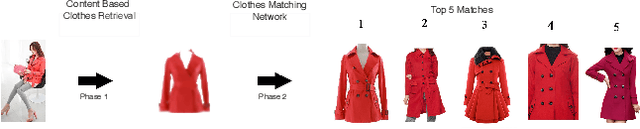

Online garment shopping has gained many customers in recent years. Describing a dress using keywords does not always yield the proper results, which in turn leads to dissatisfaction of customers. A visual search based system will be enormously beneficent to the industry. Hence, we propose a framework that can retrieve similar clothes that can be found in an image. The first task is to extract the garment from the input image (street photo). There are various challenges for that, including pose, illumination, and background clutter. We use a Generative Adversarial Network for the task of retrieving the garment that the person in the image was wearing. It has been shown that GAN can retrieve the garment very efficiently despite the challenges of street photos. Finally, a siamese based matching system takes the retrieved cloth image and matches it with the clothes in the dataset, giving us the top k matches. We take a pre-trained inception-ResNet v1 module as a siamese network (trained using triplet loss for face detection) and fine-tune it on the shopping dataset using center loss. The dataset has been collected inhouse. For training the GAN, we use the LookBook dataset, which is publically available.