 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Efficient Real-Time Camera Based Estimation of Heart Rate and Its Variability
Sep 03, 2019
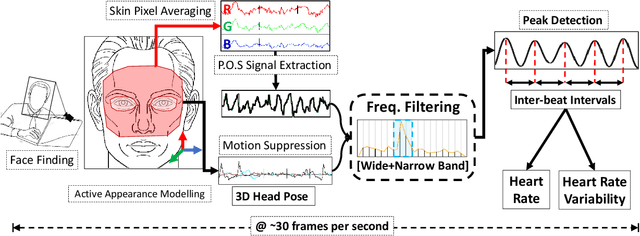
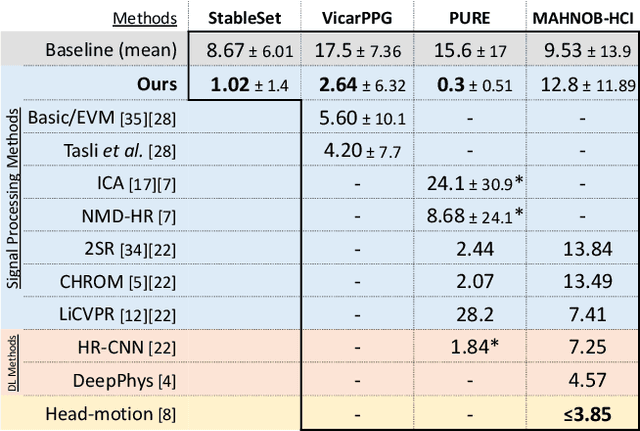
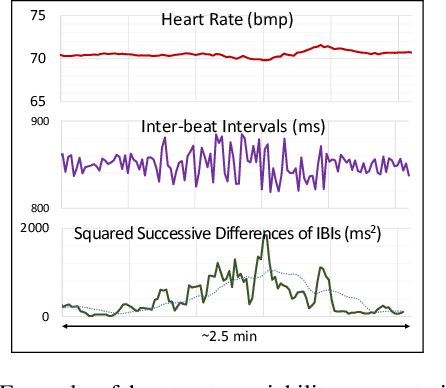

Remote photo-plethysmography (rPPG) uses a remotely placed camera to estimating a person's heart rate (HR). Similar to how heart rate can provide useful information about a person's vital signs, insights about the underlying physio/psychological conditions can be obtained from heart rate variability (HRV). HRV is a measure of the fine fluctuations in the intervals between heart beats. However, this measure requires temporally locating heart beats with a high degree of precision. We introduce a refined and efficient real-time rPPG pipeline with novel filtering and motion suppression that not only estimates heart rate more accurately, but also extracts the pulse waveform to time heart beats and measure heart rate variability. This method requires no rPPG specific training and is able to operate in real-time. We validate our method on a self-recorded dataset under an idealized lab setting, and show state-of-the-art results on two public dataset with realistic conditions (VicarPPG and PURE).
Inverse Rendering Techniques for Physically Grounded Image Editing
Dec 25, 2019From a single picture of a scene, people can typically grasp the spatial layout immediately and even make good guesses at materials properties and where light is coming from to illuminate the scene. For example, we can reliably tell which objects occlude others, what an object is made of and its rough shape, regions that are illuminated or in shadow, and so on. It is interesting how little is known about our ability to make these determinations; as such, we are still not able to robustly "teach" computers to make the same high-level observations as people. This document presents algorithms for understanding intrinsic scene properties from single images. The goal of these inverse rendering techniques is to estimate the configurations of scene elements (geometry, materials, luminaires, camera parameters, etc) using only information visible in an image. Such algorithms have applications in robotics and computer graphics. One such application is in physically grounded image editing: photo editing made easier by leveraging knowledge of the physical space. These applications allow sophisticated editing operations to be performed in a matter of seconds, enabling seamless addition, removal, or relocation of objects in images.
Learning Visual Storylines with Skipping Recurrent Neural Networks
Jul 26, 2016


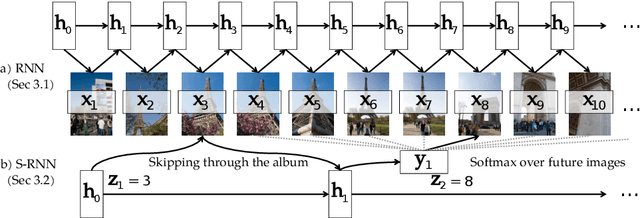
What does a typical visit to Paris look like? Do people first take photos of the Louvre and then the Eiffel Tower? Can we visually model a temporal event like "Paris Vacation" using current frameworks? In this paper, we explore how we can automatically learn the temporal aspects, or storylines of visual concepts from web data. Previous attempts focus on consecutive image-to-image transitions and are unsuccessful at recovering the long-term underlying story. Our novel Skipping Recurrent Neural Network (S-RNN) model does not attempt to predict each and every data point in the sequence, like classic RNNs. Rather, S-RNN uses a framework that skips through the images in the photo stream to explore the space of all ordered subsets of the albums via an efficient sampling procedure. This approach reduces the negative impact of strong short-term correlations, and recovers the latent story more accurately. We show how our learned storylines can be used to analyze, predict, and summarize photo albums from Flickr. Our experimental results provide strong qualitative and quantitative evidence that S-RNN is significantly better than other candidate methods such as LSTMs on learning long-term correlations and recovering latent storylines. Moreover, we show how storylines can help machines better understand and summarize photo streams by inferring a brief personalized story of each individual album.
Perceptual Image Super-Resolution with Progressive Adversarial Network
Mar 19, 2020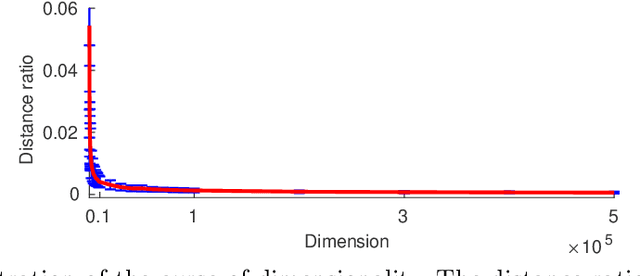
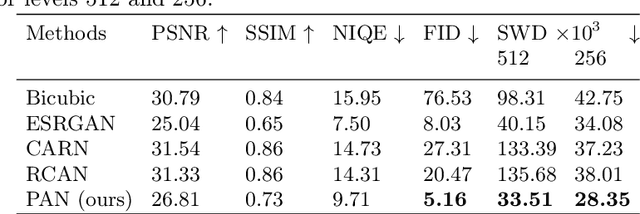
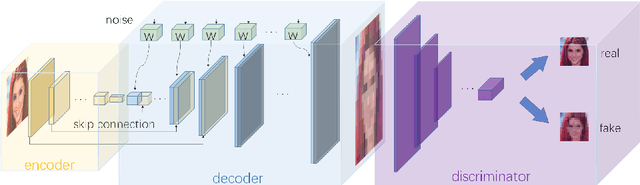
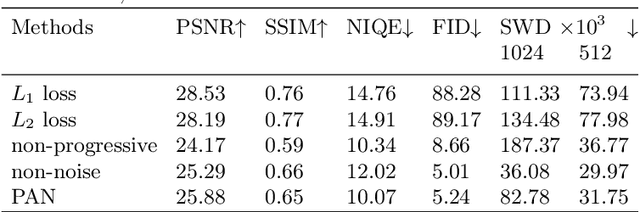
Single Image Super-Resolution (SISR) aims to improve resolution of small-size low-quality image from a single one. With popularity of consumer electronics in our daily life, this topic has become more and more attractive. In this paper, we argue that the curse of dimensionality is the underlying reason of limiting the performance of state-of-the-art algorithms. To address this issue, we propose Progressive Adversarial Network (PAN) that is capable of coping with this difficulty for domain-specific image super-resolution. The key principle of PAN is that we do not apply any distance-based reconstruction errors as the loss to be optimized, thus free from the restriction of the curse of dimensionality. To maintain faithful reconstruction precision, we resort to U-Net and progressive growing of neural architecture. The low-level features in encoder can be transferred into decoder to enhance textural details with U-Net. Progressive growing enhances image resolution gradually, thereby preserving precision of recovered image. Moreover, to obtain high-fidelity outputs, we leverage the framework of the powerful StyleGAN to perform adversarial learning. Without the curse of dimensionality, our model can super-resolve large-size images with remarkable photo-realistic details and few distortions. Extensive experiments demonstrate the superiority of our algorithm over state-of-the-arts both quantitatively and qualitatively.
AADS: Augmented Autonomous Driving Simulation using Data-driven Algorithms
Jan 23, 2019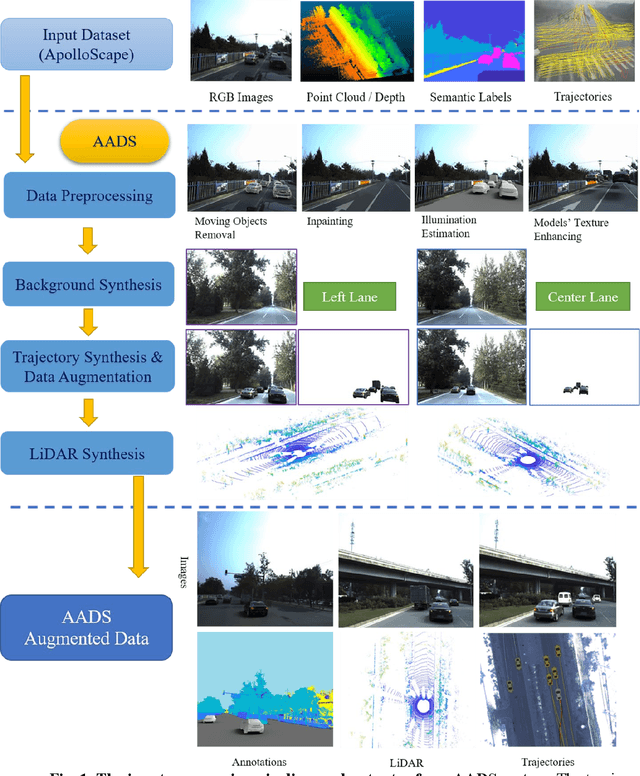
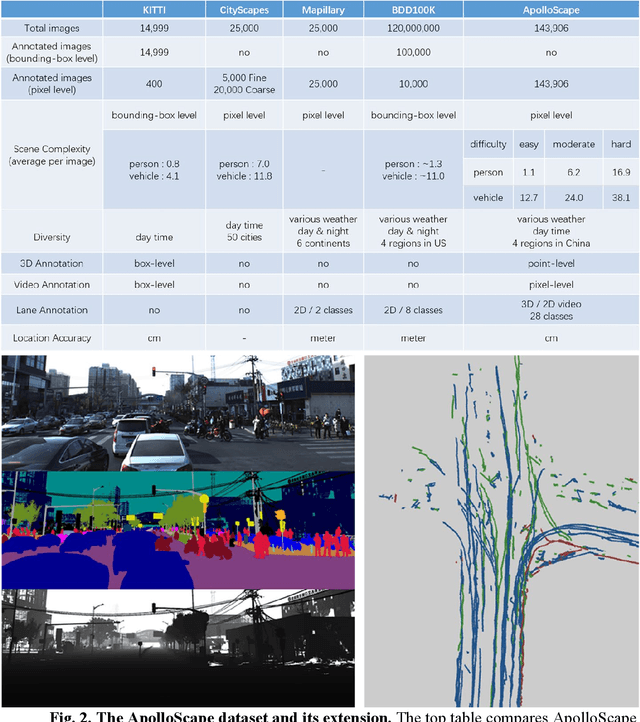

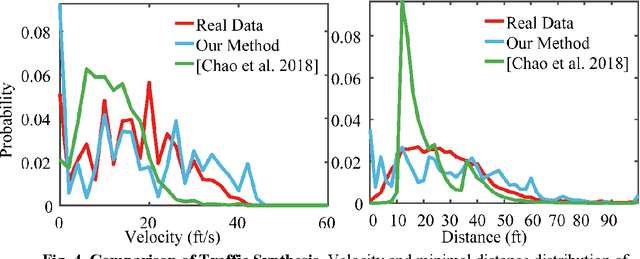
Simulation systems have become an essential component in the development and validation of autonomous driving technologies. The prevailing state-of-the-art approach for simulation is to use game engines or high-fidelity computer graphics (CG) models to create driving scenarios. However, creating CG models and vehicle movements (e.g., the assets for simulation) remains a manual task that can be costly and time-consuming. In addition, the fidelity of CG images still lacks the richness and authenticity of real-world images and using these images for training leads to degraded performance. In this paper we present a novel approach to address these issues: Augmented Autonomous Driving Simulation (AADS). Our formulation augments real-world pictures with a simulated traffic flow to create photo-realistic simulation images and renderings. More specifically, we use LiDAR and cameras to scan street scenes. From the acquired trajectory data, we generate highly plausible traffic flows for cars and pedestrians and compose them into the background. The composite images can be re-synthesized with different viewpoints and sensor models. The resulting images are photo-realistic, fully annotated, and ready for end-to-end training and testing of autonomous driving systems from perception to planning. We explain our system design and validate our algorithms with a number of autonomous driving tasks from detection to segmentation and predictions. Compared to traditional approaches, our method offers unmatched scalability and realism. Scalability is particularly important for AD simulation and we believe the complexity and diversity of the real world cannot be realistically captured in a virtual environment. Our augmented approach combines the flexibility in a virtual environment (e.g., vehicle movements) with the richness of the real world to allow effective simulation of anywhere on earth.
Rotate-and-Render: Unsupervised Photorealistic Face Rotation from Single-View Images
Mar 18, 2020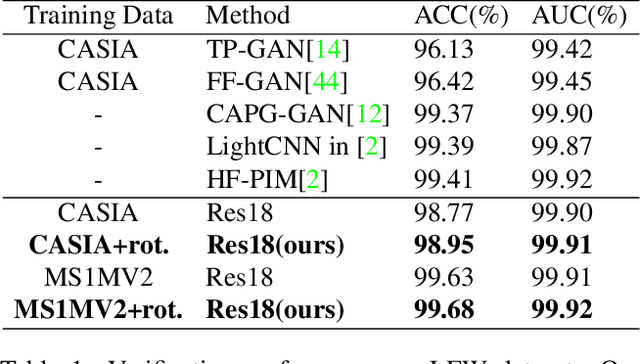
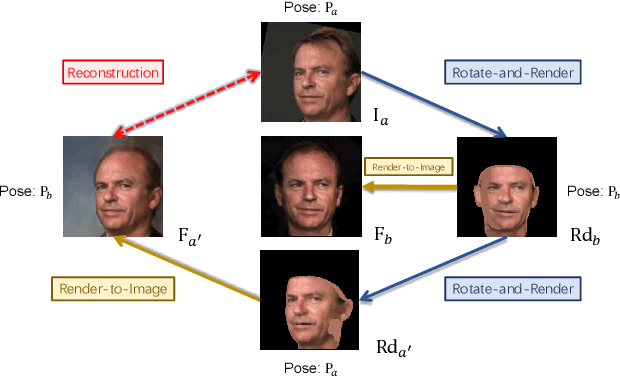

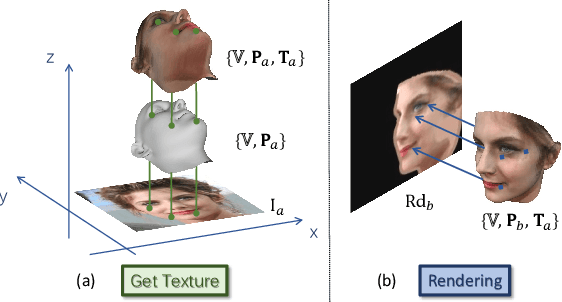
Though face rotation has achieved rapid progress in recent years, the lack of high-quality paired training data remains a great hurdle for existing methods. The current generative models heavily rely on datasets with multi-view images of the same person. Thus, their generated results are restricted by the scale and domain of the data source. To overcome these challenges, we propose a novel unsupervised framework that can synthesize photo-realistic rotated faces using only single-view image collections in the wild. Our key insight is that rotating faces in the 3D space back and forth, and re-rendering them to the 2D plane can serve as a strong self-supervision. We leverage the recent advances in 3D face modeling and high-resolution GAN to constitute our building blocks. Since the 3D rotation-and-render on faces can be applied to arbitrary angles without losing details, our approach is extremely suitable for in-the-wild scenarios (i.e. no paired data are available), where existing methods fall short. Extensive experiments demonstrate that our approach has superior synthesis quality as well as identity preservation over the state-of-the-art methods, across a wide range of poses and domains. Furthermore, we validate that our rotate-and-render framework naturally can act as an effective data augmentation engine for boosting modern face recognition systems even on strong baseline models.
CIE XYZ Net: Unprocessing Images for Low-Level Computer Vision Tasks
Jun 23, 2020



Cameras currently allow access to two image states: (i) a minimally processed linear raw-RGB image state (i.e., raw sensor data) or (ii) a highly-processed nonlinear image state (e.g., sRGB). There are many computer vision tasks that work best with a linear image state, such as image deblurring and image dehazing. Unfortunately, the vast majority of images are saved in the nonlinear image state. Because of this, a number of methods have been proposed to "unprocess" nonlinear images back to a raw-RGB state. However, existing unprocessing methods have a drawback because raw-RGB images are sensor-specific. As a result, it is necessary to know which camera produced the sRGB output and use a method or network tailored for that sensor to properly unprocess it. This paper addresses this limitation by exploiting another camera image state that is not available as an output, but it is available inside the camera pipeline. In particular, cameras apply a colorimetric conversion step to convert the raw-RGB image to a device-independent space based on the CIE XYZ color space before they apply the nonlinear photo-finishing. Leveraging this canonical image state, we propose a deep learning framework, CIE XYZ Net, that can unprocess a nonlinear image back to the canonical CIE XYZ image. This image can then be processed by any low-level computer vision operator and re-rendered back to the nonlinear image. We demonstrate the usefulness of the CIE XYZ Net on several low-level vision tasks and show significant gains that can be obtained by this processing framework. Code and dataset are publicly available at https://github.com/mahmoudnafifi/CIE_XYZ_NET.
Environment-agnostic Multitask Learning for Natural Language Grounded Navigation
Mar 12, 2020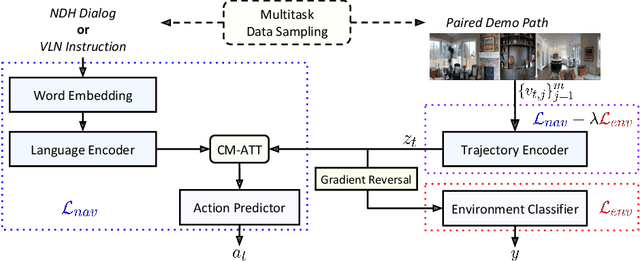
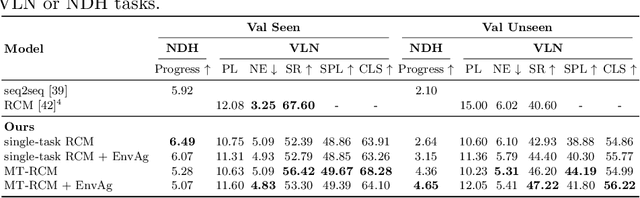
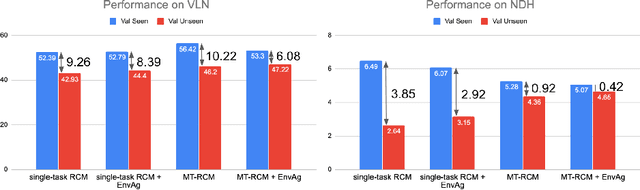
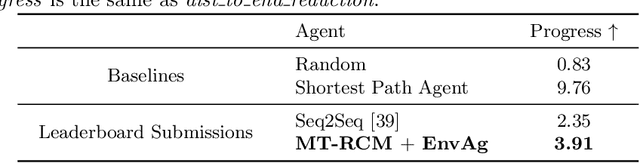
Recent research efforts enable study for natural language grounded navigation in photo-realistic environments, e.g., following natural language instructions or dialog. However, existing methods tend to overfit training data in seen environments and fail to generalize well in previously unseen environments. In order to close the gap between seen and unseen environments, we aim at learning a generalized navigation model from two novel perspectives: (1) we introduce a multitask navigation model that can be seamlessly trained on both Vision-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks, which benefits from richer natural language guidance and effectively transfers knowledge across tasks; (2) we propose to learn environment-agnostic representations for the navigation policy that are invariant among the environments seen during training, thus generalizing better on unseen environments. Extensive experiments show that training with environment-agnostic multitask learning objective significantly reduces the performance gap between seen and unseen environments and the navigation agent so trained outperforms the baselines on unseen environments by 16% (relative measure on success rate) on VLN and 120% (goal progress) on NDH. Our submission to the CVDN leaderboard establishes a new state-of-the-art for the NDH task outperforming the existing best model by more than 66% (goal progress) on the holdout test set. The code for training the navigation model using environment-agnostic multitask learning is available at https://github.com/google-research/valan.
Face Destylization
Feb 05, 2018
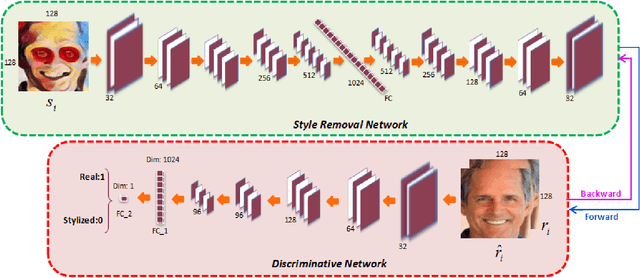


Numerous style transfer methods which produce artistic styles of portraits have been proposed to date. However, the inverse problem of converting the stylized portraits back into realistic faces is yet to be investigated thoroughly. Reverting an artistic portrait to its original photo-realistic face image has potential to facilitate human perception and identity analysis. In this paper, we propose a novel Face Destylization Neural Network (FDNN) to restore the latent photo-realistic faces from the stylized ones. We develop a Style Removal Network composed of convolutional, fully-connected and deconvolutional layers. The convolutional layers are designed to extract facial components from stylized face images. Consecutively, the fully-connected layer transfers the extracted feature maps of stylized images into the corresponding feature maps of real faces and the deconvolutional layers generate real faces from the transferred feature maps. To enforce the destylized faces to be similar to authentic face images, we employ a discriminative network, which consists of convolutional and fully connected layers. We demonstrate the effectiveness of our network by conducting experiments on an extensive set of synthetic images. Furthermore, we illustrate our network can recover faces from stylized portraits and real paintings for which the stylized data was unavailable during the training phase.