 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Rethinking Fully Convolutional Networks for the Analysis of Photoluminescence Wafer Images
Mar 01, 2020

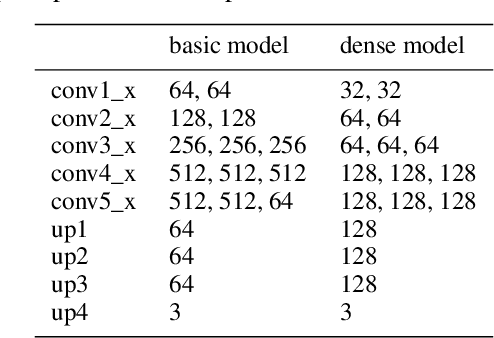
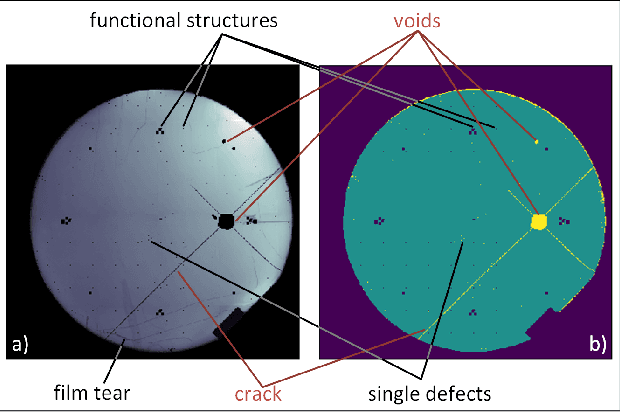
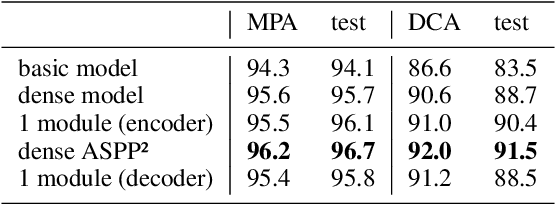
The manufacturing of light-emitting diodes is a complex semiconductor-manufacturing process, interspersed with different measurements. Among the employed measurements, photoluminescence imaging has several advantages, namely being a non-destructive, fast and thus cost-effective measurement. On a photoluminescence measurement image of an LED wafer, every pixel corresponds to an LED chip's brightness after photo-excitation, revealing chip performance information. However, generating a chip-fine defect map of the LED wafer, based on photoluminescence images, proves challenging for multiple reasons: on the one hand, the measured brightness values vary from image to image, in addition to local spots of differing brightness. On the other hand, certain defect structures may assume multiple shapes, sizes and brightness gradients, where salient brightness values may correspond to defective LED chips, measurement artefacts or non-defective structures. In this work, we revisit the creation of chip-fine defect maps using fully convolutional networks and show that the problem of segmenting objects at multiple scales can be improved by the incorporation of densely connected convolutional blocks and atrous spatial pyramid pooling modules. We also share implementation details and our experiences with training networks with small datasets of measurement images. The proposed architecture significantly improves the segmentation accuracy of highly variable defect structures over our previous version.
Visual Attribute Transfer through Deep Image Analogy
Jun 06, 2017

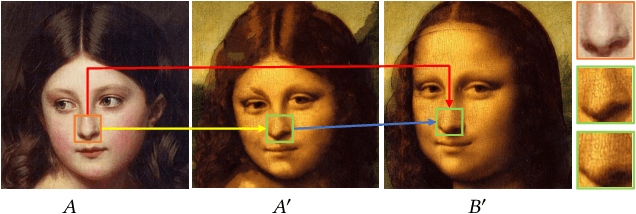

We propose a new technique for visual attribute transfer across images that may have very different appearance but have perceptually similar semantic structure. By visual attribute transfer, we mean transfer of visual information (such as color, tone, texture, and style) from one image to another. For example, one image could be that of a painting or a sketch while the other is a photo of a real scene, and both depict the same type of scene. Our technique finds semantically-meaningful dense correspondences between two input images. To accomplish this, it adapts the notion of "image analogy" with features extracted from a Deep Convolutional Neutral Network for matching; we call our technique Deep Image Analogy. A coarse-to-fine strategy is used to compute the nearest-neighbor field for generating the results. We validate the effectiveness of our proposed method in a variety of cases, including style/texture transfer, color/style swap, sketch/painting to photo, and time lapse.
Environment-agnostic Multitask Learning for Natural Language Grounded Navigation
Mar 01, 2020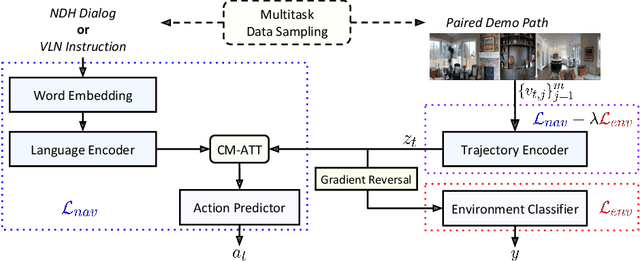
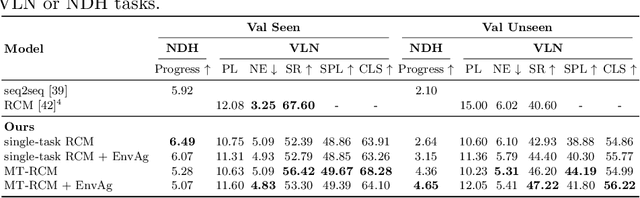
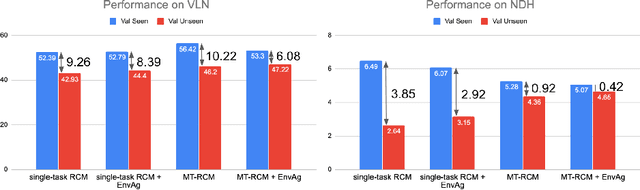
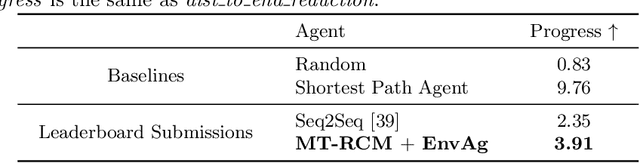
Recent research efforts enable study for natural language grounded navigation in photo-realistic environments, e.g., following natural language instructions or dialog. However, existing methods tend to overfit training data in seen environments and fail to generalize well in previously unseen environments. In order to close the gap between seen and unseen environments, we aim at learning a generalized navigation model from two novel perspectives: (1) we introduce a multitask navigation model that can be seamlessly trained on both Vision-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks, which benefits from richer natural language guidance and effectively transfers knowledge across tasks; (2) we propose to learn environment-agnostic representations for the navigation policy that are invariant among the environments seen during training, thus generalizing better on unseen environments. Extensive experiments show that our navigation model trained using environment-agnostic multitask learning significantly reduces the performance gap between seen and unseen environments and outperforms the baselines on unseen environments by 16% (relative measure on success rate) on VLN and 120% (goal progress) on NDH, establishing a new state-of-the-art for the NDH task. The code for training the navigation model using environment-agnostic multitask learning is available at https://github.com/google-research/valan.
Real-time Burst Photo Selection Using a Light-Head Adversarial Network
Mar 20, 2018
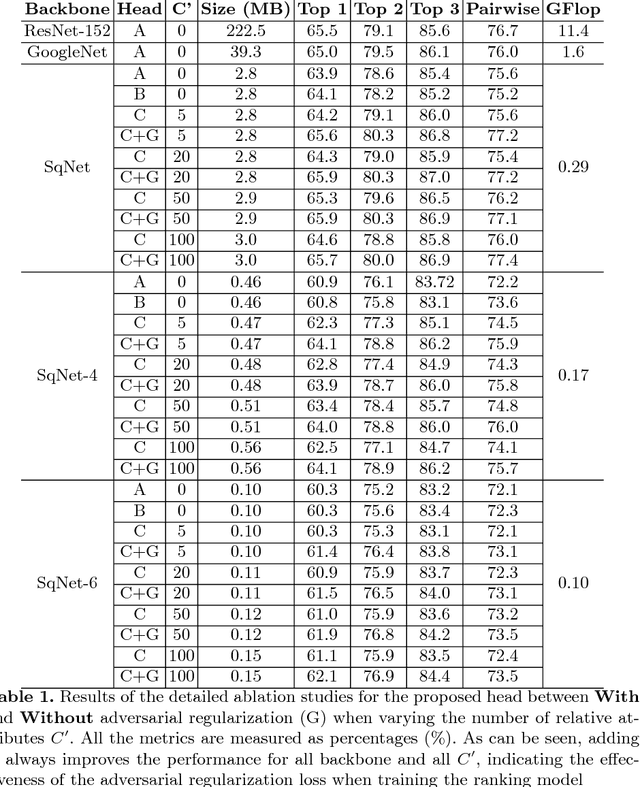
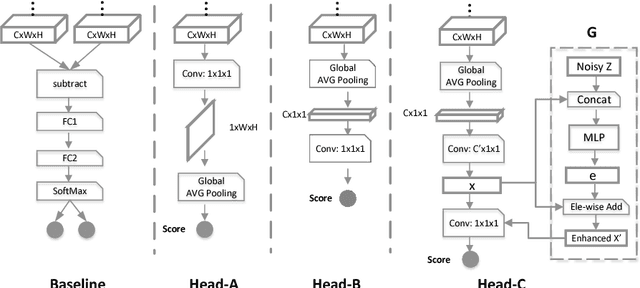
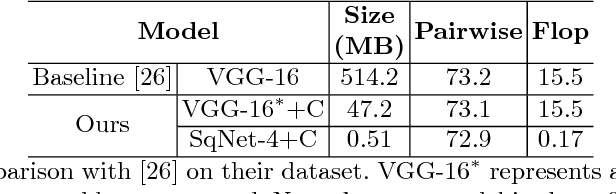
We present an automatic moment capture system that runs in real-time on mobile cameras. The system is designed to run in the viewfinder mode and capture a burst sequence of frames before and after the shutter is pressed. For each frame, the system predicts in real-time a "goodness" score, based on which the best moment in the burst can be selected immediately after the shutter is released, without any user interference. To solve the problem, we develop a highly efficient deep neural network ranking model, which implicitly learns a "latent relative attribute" space to capture subtle visual differences within a sequence of burst images. Then the overall goodness is computed as a linear aggregation of the goodnesses of all the latent attributes. The latent relative attributes and the aggregation function can be seamlessly integrated in one fully convolutional network and trained in an end-to-end fashion. To obtain a compact model which can run on mobile devices in real-time, we have explored and evaluated a wide range of network design choices, taking into account the constraints of model size, computational cost, and accuracy. Extensive studies show that the best frame predicted by our model hit users' top-1 (out of 11 on average) choice for $64.1\%$ cases and top-3 choices for $86.2\%$ cases. Moreover, the model(only 0.47M Bytes) can run in real time on mobile devices, e.g. only 13ms on iPhone 7 for one frame prediction.
One-to-one Mapping for Unpaired Image-to-image Translation
Sep 16, 2019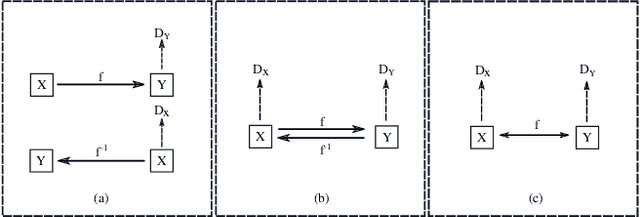



Recently image-to-image translation has attracted significant interests in the literature, starting from the successful use of the generative adversarial network (GAN), to the introduction of cyclic constraint, to extensions to multiple domains. However, in existing approaches, there is no guarantee that the mapping between two image domains is unique or one-to-one. Here we propose a self-inverse network learning approach for unpaired image-to-image translation. Building on top of CycleGAN, we learn a self-inverse function by simply augmenting the training samples by switching inputs and outputs during training. The outcome of such learning is a proven one-to-one mapping function. Our extensive experiments on a variety of detests, including cross-modal medical image synthesis, object transfiguration, and semantic labeling, consistently demonstrate clear improvement over the CycleGAN method both qualitatively and quantitatively. Especially our proposed method reaches the state-of-the-art result on the label to photo direction of the cityscapes benchmark dataset.
Help, Anna! Visual Navigation with Natural Multimodal Assistance via Retrospective Curiosity-Encouraging Imitation Learning
Sep 15, 2019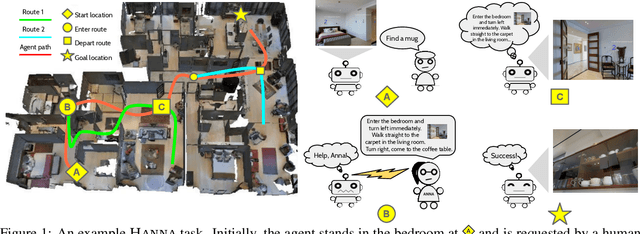
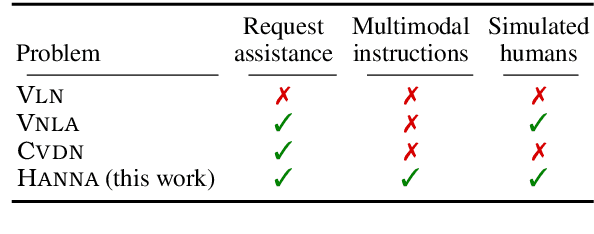
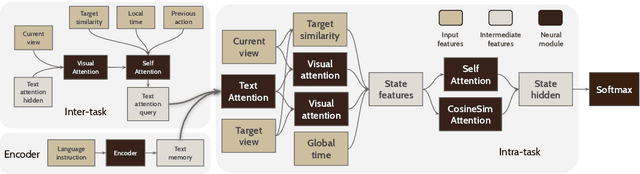
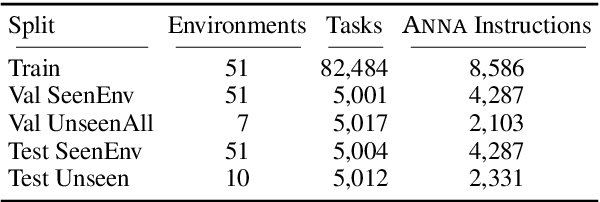
Mobile agents that can leverage help from humans can potentially accomplish more complex tasks than they could entirely on their own. We develop "Help, Anna!" (HANNA), an interactive photo-realistic simulator in which an agent fulfills object-finding tasks by requesting and interpreting natural language-and-vision assistance. An agent solving tasks in a HANNA environment can leverage simulated human assistants, called ANNA (Automatic Natural Navigation Assistants), which, upon request, provide natural language and visual instructions to direct the agent towards the goals. To address the HANNA problem, we develop a memory-augmented neural agent that hierarchically models multiple levels of decision-making, and an imitation learning algorithm that teaches the agent to avoid repeating past mistakes while simultaneously predicting its own chances of making future progress. Empirically, our approach is able to ask for help more effectively than competitive baselines and, thus, attains higher task success rate on both previously seen and previously unseen environments. We publicly release code and data at https://github.com/khanhptnk/hanna .
LSMI-Sinkhorn: Semi-supervised Squared-Loss Mutual Information Estimation with Optimal Transport
Sep 05, 2019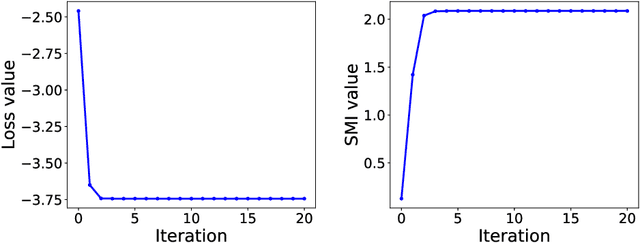
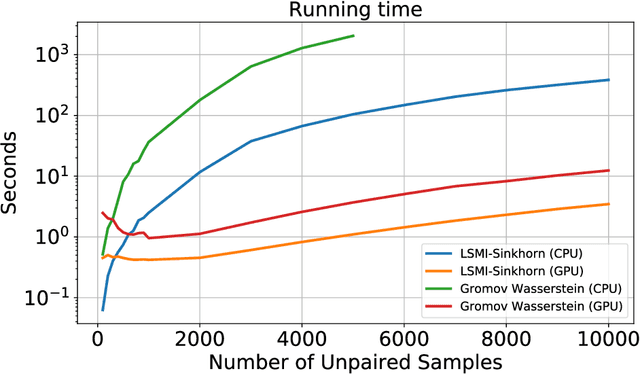
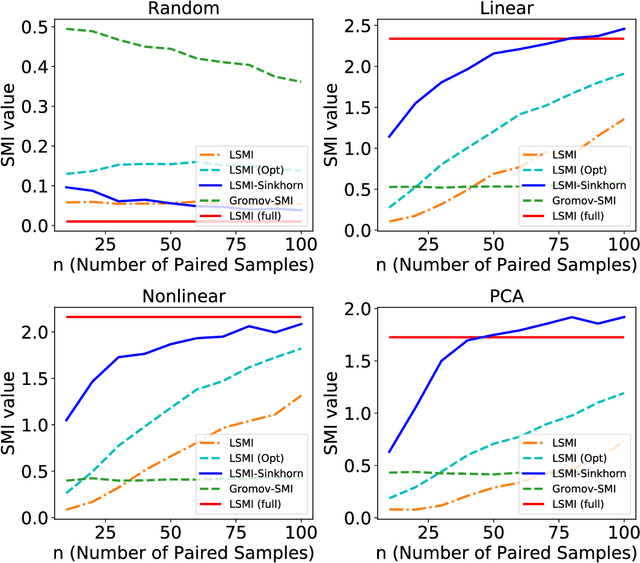
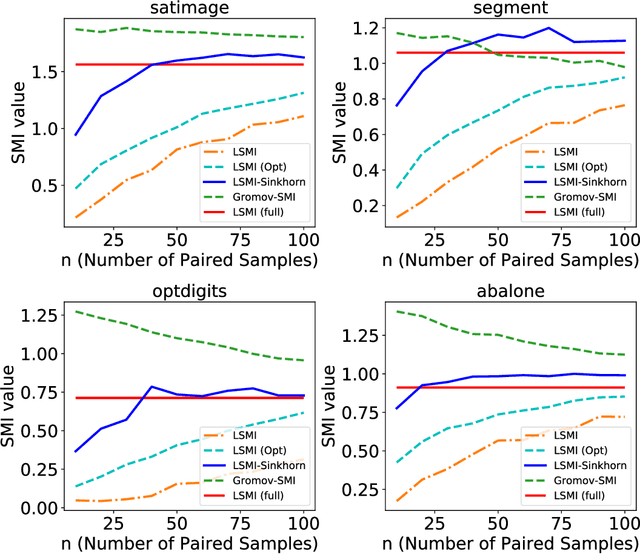
Estimating mutual information is an important machine learning and statistics problem. To estimate the mutual information from data, a common practice is preparing a set of paired samples. However, in some cases, it is difficult to obtain a large number of data pairs. To address this problem, we propose squared-loss mutual information (SMI) estimation using a small number of paired samples and the available unpaired ones. We first represent SMI through the density ratio function, where the expectation is approximated by the samples from marginals and its assignment parameters. The objective is formulated using the optimal transport problem and quadratic programming. Then, we introduce the least-square mutual information-Sinkhorn algorithm (LSMI-Sinkhorn) for efficient optimization. Through experiments, we first demonstrate that the proposed method can estimate the SMI without a large number of paired samples. We also evaluate and show the effectiveness of the proposed LSMI-Sinkhorn on various types of machine learning problems such as image matching and photo album summarization.
Content and Colour Distillation for Learning Image Translations with the Spatial Profile Loss
Aug 01, 2019



Generative adversarial networks has emerged as a defacto standard for image translation problems. To successfully drive such models, one has to rely on additional networks e.g., discriminators and/or perceptual networks. Training these networks with pixel based losses alone are generally not sufficient to learn the target distribution. In this paper, we propose a novel method of computing the loss directly between the source and target images that enable proper distillation of shape/content and colour/style. We show that this is useful in typical image-to-image translations allowing us to successfully drive the generator without relying on additional networks. We demonstrate this on many difficult image translation problems such as image-to-image domain mapping, single image super-resolution and photo realistic makeup transfer. Our extensive evaluation shows the effectiveness of the proposed formulation and its ability to synthesize realistic images. [Code release: https://github.com/ssarfraz/SPL]
Speech-Driven Facial Reenactment Using Conditional Generative Adversarial Networks
Mar 20, 2018



We present a novel approach to generating photo-realistic images of a face with accurate lip sync, given an audio input. By using a recurrent neural network, we achieved mouth landmarks based on audio features. We exploited the power of conditional generative adversarial networks to produce highly-realistic face conditioned on a set of landmarks. These two networks together are capable of producing a sequence of natural faces in sync with an input audio track.